数据无量纲化--归一化,标准化
数据的无量纲化可以是线性的或者非线性的。线性的无量纲化包括中心化处理和缩放处理。中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到某个位置。缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放。
在机器学习算法实践中,往往需要及那个不同规格的数据转换为同一规格,这种需求叫做“无量纲化”。在梯度和矩阵为核心的算法中,e.g.逻辑回归,支持向量机,神经网络,无量纲化可以加快求解速度;在距离类模型,e.g.k近邻,k-means聚类中,无量纲可以帮助提高模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。(一个特例时决策树和树的集成算法,对决策树不需要无量纲化,决策树可以把任意数据都处理得很好)
数据的无量纲化可以是线性的或者非线性的。线性的无量纲化包括中心化处理和缩放处理。中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到某个位置。缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放。
数据归一化
公式: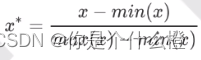
其中,z是标准化后的数据,x是原始数据,mu是原始数据的均值,sigma是原始数据的标准差。
在sklearn中,我们使用preprocessing.MinMaxScaler来实现这个功能。MinMaxScaler有一个参数feature_range,控制数据压缩到一定范围,默认是[0,1]。
sklearn实现
from sklearn.preprocessing import MinMaxScaler
data = [[-1,2],[-0.5,6],[0,10],[1,18]]
#实现归一化
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(data) #fit,在这里本质是生成min(x)和max(x)
result = scaler.transform(data) #通过接口导出结果,全部压缩到0-1之间
#上面两行可以用一行:scaler = scaler.fit_transform(data)
#可以逆转归一化后的结果
#scaler.inverse_transform(result)
data:
array([[-1. , 2. ],
[-0.5, 6. ],
[ 0. , 10. ],
[ 1. , 18. ]])
result:
array([[0. , 0. ],
[0.25, 0.25],
[0.5 , 0.5 ],
[1. , 1. ]])
使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中:
#使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中
data = [[-1,2],[-0.5,6],[0,10],[1,18]]
scaler = MinMaxScaler(feature_range =[5,10]) #实例化,并规定范围
result = scaler.fit_transform(data)
result:
array([[ 5. , 5. ],
[ 6.25, 6.25],
[ 7.5 , 7.5 ],
[10. , 10. ]])
注:当x中的特征数量非常多的时候,fit会报错并表示数据量太大计算不了。此时使用partial_fit作为训练接口,即scaler = scaler.partial_fit(data)
numpy实现
#使用numpy实现归一化
import numpy as np
#使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中
X = np.array([[-1,2],[-0.5,6],[0,10],[1,18]])
x_nor = (X - X.min(axis = 0))/ (X.max(axis = 0) - X.min(axis = 0))
x_nor:
array([[0. , 0. ],
[0.25, 0.25],
[0.5 , 0.5 ],
[1. , 1. ]])
#逆转归一化
x_returned= x_nor * (X.max(axis = 0) - X.min(axis = 0)) + X.min(axis = 0)
x_returned:
array([[-1. , 2. ],
[-0.5, 6. ],
[ 0. , 10. ],
[ 1. , 18. ]])
数据标准化
公式: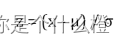
在sklearn中,我们使用preprocessing.StandardScaler来实现这个功能。
from sklearn.preprocessing import StandardScaler
data = [[-1,2],[-0.5,6],[0,10],[1,18]]
scaler = StandardScaler() #实例化
scaler.fit(data) #fit,本质是生成均值和方差
scaler.mean_ #查看均值的属性mean array([-0.125, 9. ])
scaler.var_ #查看方差的属性var_ array([ 0.546875, 35. ])
x_std = scaler.transform(data) #通过接口导出结果 或者可以使用fit_transform(data)一步达成结果
x_std:
array([[-1.18321596, -1.18321596],
[-0.50709255, -0.50709255],
[ 0.16903085, 0.16903085],
[ 1.52127766, 1.52127766]])
#使用inverse——transform逆转标准化
scaler.inverse_transform(x_std)
归一化(MinMaxScaler)和标准化(StandardScaler)选择哪一个用?
看情况。大多数的机器学习算法中,会选择标准化来进行特征缩放,因为归一化对异常值敏感。在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardScaler往往是最好的选择。
MinMaxScaler在不涉及距离度量、梯度、协方差计算以及数据需要压缩到特定区间时使用广泛。比如数字图像处理中量化像素强度时,都会使用MinMaxScaler将数据压缩到[0,1]中。
建议先试试看StandardScaler,效果不好就换MinMaxScaler。
更多数据无量纲化方法见:
https://www.bilibili.com/video/BV1Ch411x7xB?p=30&spm_id_from=pageDriver&vd_source=a684cd6cc5994e3aedf804d6795908b4

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)