对自己使用各种信号处理和特征提取方法跑BCI IV 2a数据集的记录
前言
- 鄙人脑机接口小白一枚,最近正在尝试入门eeg信号处理,由于eeg信号处理和特征提取的方法很多而且新老版本很多,故尝试以BCI IV 2a数据集作为标准,对各种方法进行练习和评判。
- 因为是一直写,所以文章比较长,建议配合目录使用。
- 如有错误,欢迎指正!
- 该练习中涉及的代码都分享到github仓库:github.com/Shurlin/eeg/
资料分享
以下是我学习eeg的一些参考资料
MNE-Python专辑 (2) MNE中数据结构Raw及其用法简介(更新)
※ 记录第一次ANN跑BCI Competition iv 2a过程
BCI IV 2a数据集介绍
数据集官方链接:BCI Competition IV
数据集中文介绍:BCI Competition 2008 – Graz dataset A个人翻译(附MATLAB安装BioSig)
Anaconda3与Python环境安装与配置
数据处理
加载数据集
import mne
import matplotlib.pyplot as plt
import numpy as np
filename = "../data/BCICIV_2a_gdf/A02T.gdf"
raw = mne.io.read_raw_gdf(filename)
# Pre-load the data
raw.load_data()
fs = raw.info['sfreq'] # 250Hz注:9名受试者数据中,4号受试者数据不全,故我测试时会排除4号受试者数据。先导测试使用2号受试者训练数据,进行预测准确度评估时会使用8名受试者的数据。
mapping = {
'EEG-Fz': 'eeg',
'EEG-0': 'eeg',
'EEG-1': 'eeg',
'EEG-2': 'eeg',
'EEG-3': 'eeg',
'EEG-4': 'eeg',
'EEG-5': 'eeg',
'EEG-C3': 'eeg',
'EEG-6': 'eeg',
'EEG-Cz': 'eeg',
'EEG-7': 'eeg',
'EEG-C4': 'eeg',
'EEG-8': 'eeg',
'EEG-9': 'eeg',
'EEG-10': 'eeg',
'EEG-11': 'eeg',
'EEG-12': 'eeg',
'EEG-13': 'eeg',
'EEG-14': 'eeg',
'EEG-Pz': 'eeg',
'EEG-15': 'eeg',
'EEG-16': 'eeg',
'EOG-left': 'eog',
'EOG-central': 'eog',
'EOG-right': 'eog'
}
raw.set_channel_types(mapping)
electrode_names = [
'Fz', 'FC3', 'FC1', 'FCz', 'FC2', 'FC4', 'C5', 'C3', 'C1', 'Cz',
'C2', 'C4', 'C6', 'CP3', 'CP1', 'CPz', 'CP2', 'CP4', 'P1', 'Pz',
'P2', 'POz'
]
raw.rename_channels({raw.ch_names[i]: electrode_names[i] for i in range(22)})
raw.set_montage('standard_1005')2a数据集的一些补丁,使其数据标签完整。
picks = mne.pick_types(raw.info, meg=False, eeg=True, eog=False)2a数据集中有3个用于校准的eog通道,22个普通eeg通道,后续数据处理排除eog通道。
滤波
我们先观察下前100s脑电数据的功率谱密度PSD:
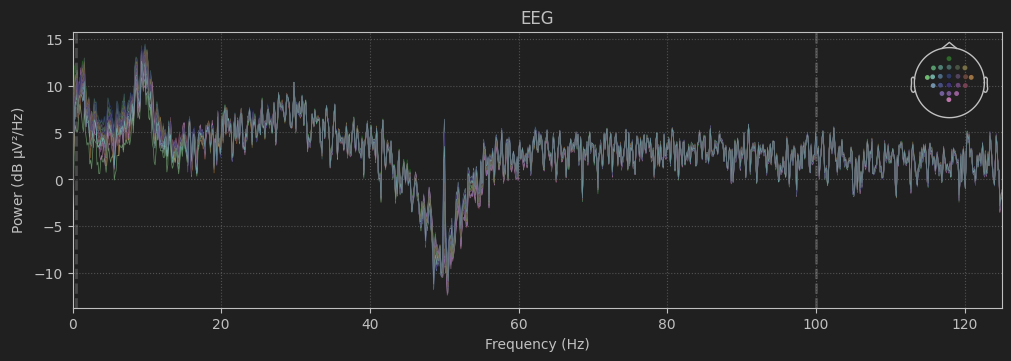
可以看到,数据已经进行了50Hz的陷阱滤波。因为数据采集地位于欧洲,电源频率为50Hz,故需要排除此工频干扰。
raw.notch_filter(np.arange(50, 251, 50), fir_design='firwin')以上为一种陷阱滤波的方法,本项目中不使用。
raw.filter(0.5, 45., picks=picks, fir_design='firwin')我们对原始脑电数据进行0.5-45Hz的带通滤波。
独立成分分析ICA去除眼影伪迹
raw.plot(start=1040, n_channels=8, scalings=0.0001, duration=60)我们取一段eeg脑电数据观察
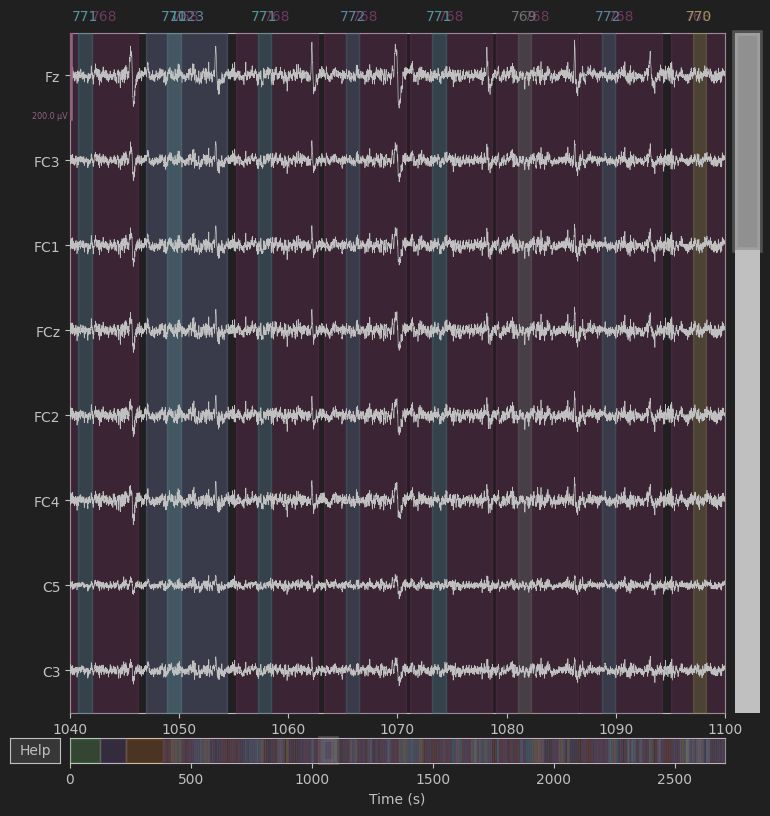
我们发现存在比较明显的由眨眼引起的眼影伪迹干扰,故需要使用独立成分分析ICA去除眼影伪迹。
ica = mne.preprocessing.ICA(n_components=15, random_state=97, max_iter=800)
ica.fit(raw)第一次尝试,我们将以n_components = 15来运行ICA,该数据可作调整。同时ICA拟合不是确定性的,因此我们还指定了一个随机种子。
ica.plot_sources(raw, show_scrollbars=False, start=1040, stop = 1100)ICA拟合完成后,我们预览一下与之前预览的脑电数据同一时间窗口捕获的独立成分。
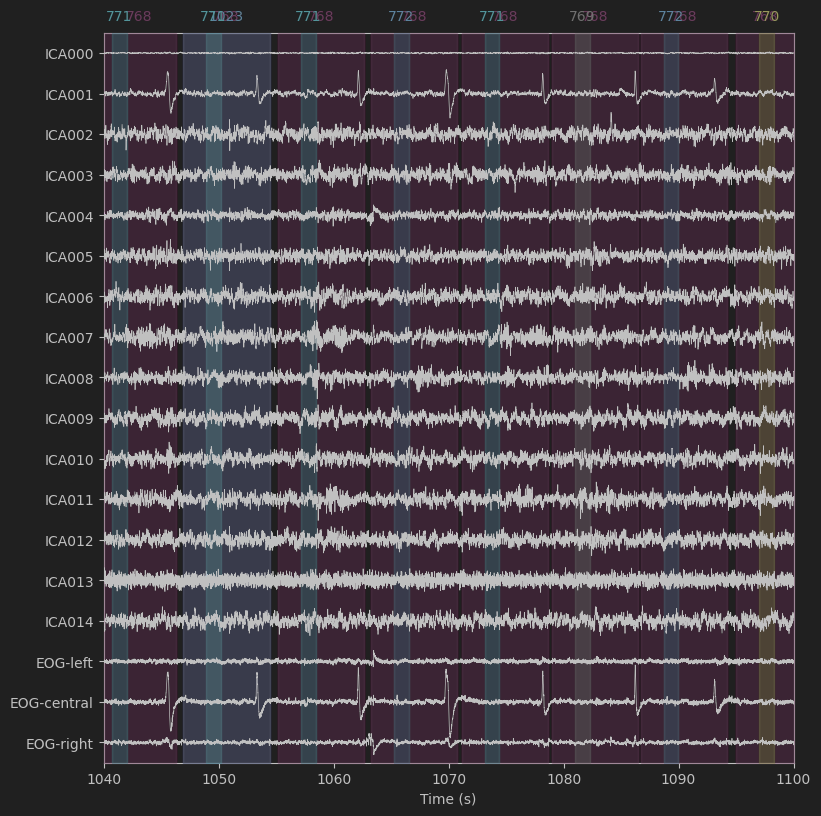
可以判断ICA001则是捕获了眼影伪迹,我们需要去除。理论上ica也能获取心电的伪迹(一般是ICA002),不过2a数据集中不明显。
ica.exclude = [1]
ica.apply(raw)去除独立成分1,应用到原始数据,此时我们来看看去除眼影伪迹后的同一时间窗口脑电图。
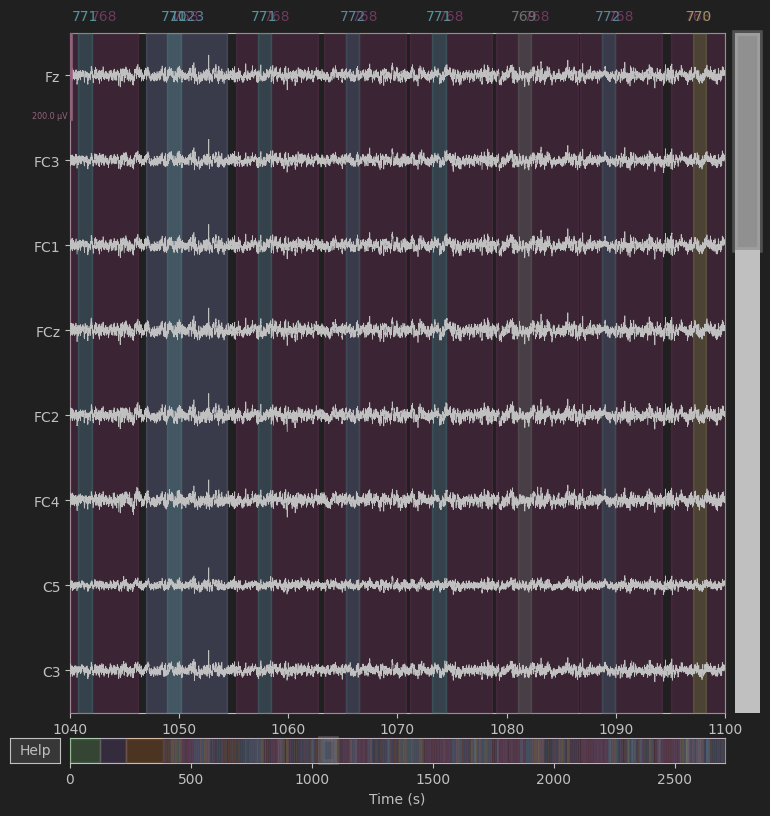
ICA参考:Python专栏 | 独立成分分析(ICA)的实例应用:消除伪影信号
数据分割
events, _ = mne.events_from_annotations(raw)获取该试验中的事件时间戳,即休息/发出运动想象提示cue等事件的时间节点,以便对原始脑电数据进行分割。
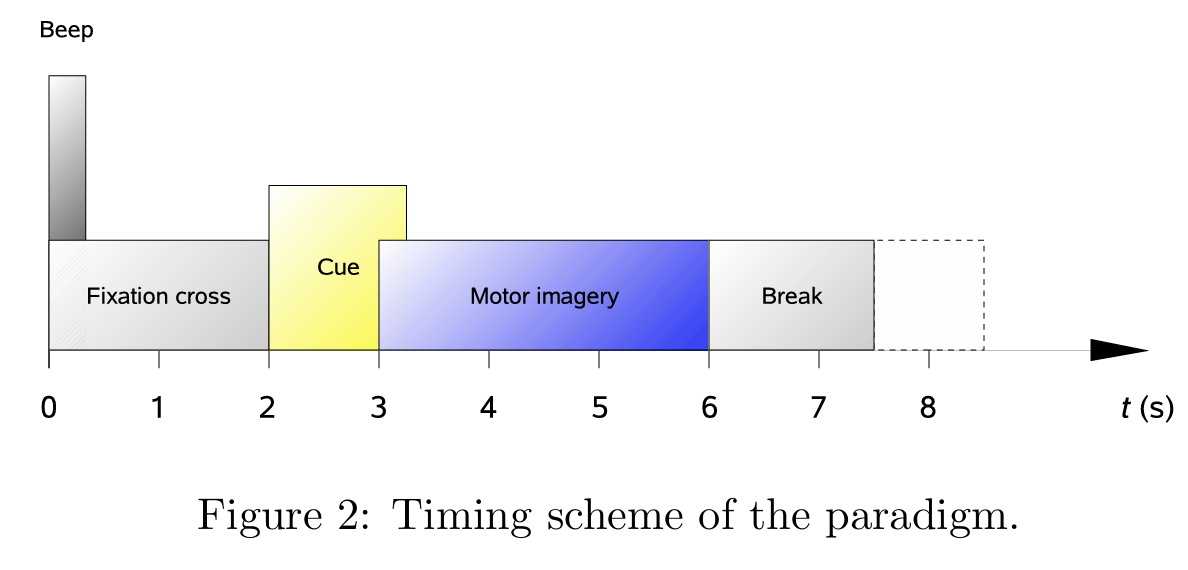
阅读2a数据集介绍可知,这四类事件的mark起始于时间轴的第2s,我们取cue出现前1s的数据作基线校准,取时间轴上1~6s的数据为一epoch(因为event从第2s开始算,所以代码是-1s~4s)
event_id = dict({'769': 7,'770': 8,'771': 9,'772': 10})
epochs = mne.Epochs(raw, events, event_id, tmin=-1., tmax=4., proj=True, picks=picks,
baseline=(-1.0, 0), preload=True)阅读2a数据集介绍,event_id存在如下对应关系:
| 运动意图提示 | raw里的event type | events第3列 | labels对应标签 |
|---|---|---|---|
| 左手 | 769 | 7 | 0 |
| 右手 | 770 | 8 | 1 |
| 脚 | 771 | 9 | 2 |
| 舌头 | 772 | 10 | 3 |
data = epochs.get_data()
labels = epochs.events[:,-1] - 7获取脑电数据与标签。其中,data为288*22*1251的numpy数组:288次测试,每种意图72次;22通道;脑电数据采集频率250Hz,1~6s间5s共1250个数据点,算上一头一尾为1251。labels为288维的numpy数组,0、1、2、3分别对应左手、右手、脚、舌头,设置成0开头的数组是为了方便后续作为分类标签。
特征提取
时域特征
事件相关电位 (Event-Related Potentials, ERPs):
在特定事件(如视觉、听觉刺激或运动指令)前后锁定EEG片段进行多次叠加平均,消除背景噪声,突出与事件相关的神经响应。叠加后的脑电波图形称为一个evoked。
all_evoked = epochs.average() # (22, 1251)
plt.plot(all_evoked.times, all_evoked.data.T)我们可以直接使用mne包的功能,获取22个通道在288次测试平均下的一次evoked。
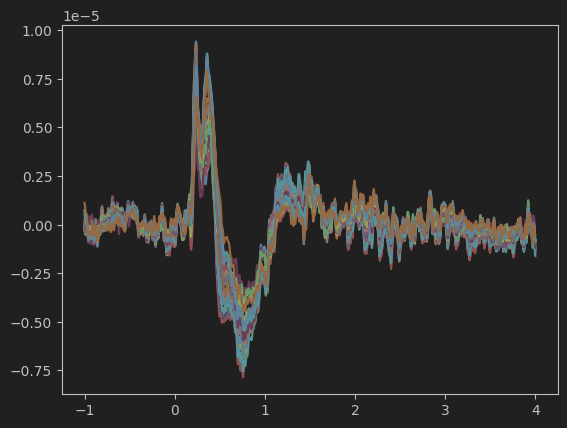
plt.plot(all_evoked.times[200:750], all_evoked.data.T[200:750,:])我们也可以关注从-0.2s-2s的脑电波图:
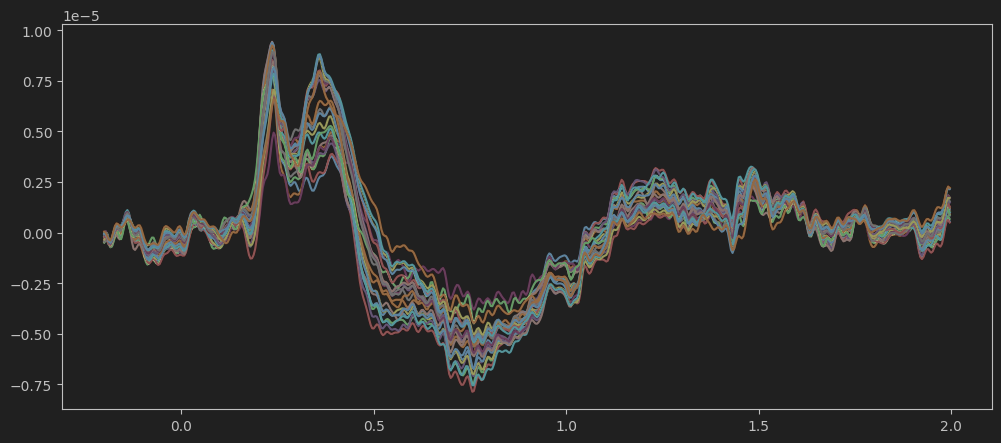
可以看到,刺激出现后300ms左右产生了明显的正偏转,这个就是P300事件相关电位。
我们可以通过evoked绘制脑地形图Topo Map:
该图展现的是该evoked在某一时间点各通道电位差异的热图。
all_evoked.plot_topomap(times=[-0.2, 0.0, 0.5, 1.0, 1.5])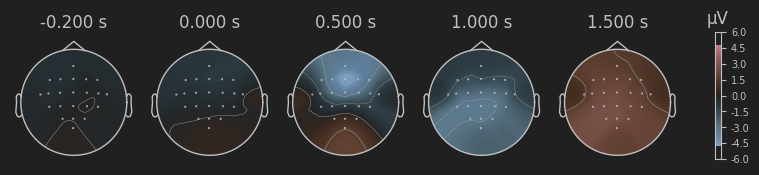
我们尝试分离不同运动意图提示下的ERP:
data_dif = np.array([data[labels == i, :, :] for i in range(4)])分离不同意图后,我们将72次测试22通道的脑电数据进行叠加平均,通过plot预览。
cues = ['Left', 'Right', 'Foot', 'Tongue']
plt.plot(all_evoked.times, data_dif.mean(axis=1).mean(axis=1).T, label=cues)
plt.legend(loc='upper right')可以看到不同运动意图提示下的erp差异不大,难以区分,这时候我们就需要更多的特征。
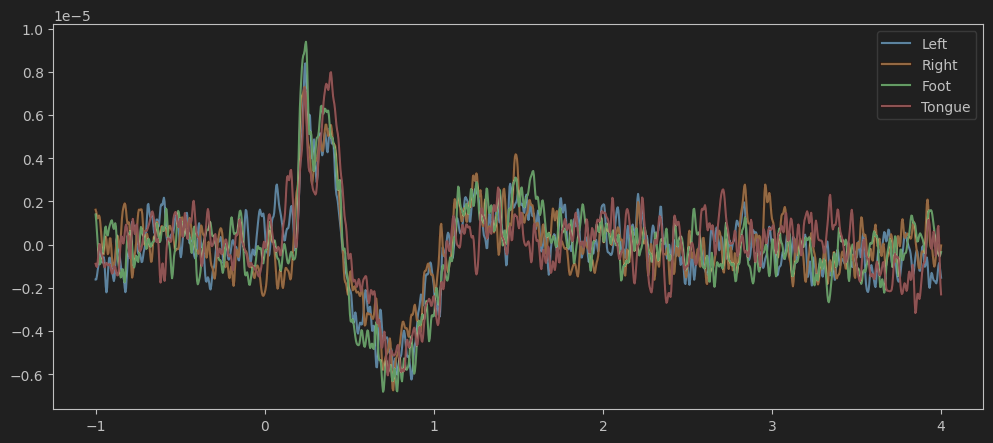
要注意的是,后续模型训练的数据不需要提前将脑电数据按cues进行分类, 我最开始因为一直用分了四类的数据做特征提取变得很麻烦,实际上只需要模型训练时以labels作为参数输入即可。
erp_data = data.mean(axis = 1)我们只需将22个通道的数据进行融合即可,作为后续训练的数据。
其余统计学特征:
时域信息除了均值外,还有一系列的统计学特征:
频域特征
功率谱密度 (Power Spectral Density, PSD)
使用傅里叶变换将信号分解为不同频率的正弦波分量,计算每个频率分量上的功率(幅值平方)。
psd = raw.compute_psd(method='welch', tmin=400, tmax=700, fmin=0.5, fmax=45)
psds = psd.data # 形状为 (n_channels, n_freqs)
freqs = psd.freqs # 形状为 (n_freqs, )使用mne自带的compute_psd功能可以计算出一定时间窗口内的功率谱密度,因为2a数据集中穿插有休息所以不宜使用全数据集提取PSD。 这一功能一般只能针对整一个任务窗口的频域特征进行分析,若需引入时间维度进行分析会稍显麻烦。
plt.plot(freqs, psds.T[:, :5])我们可以预览下前5个通道的PSD
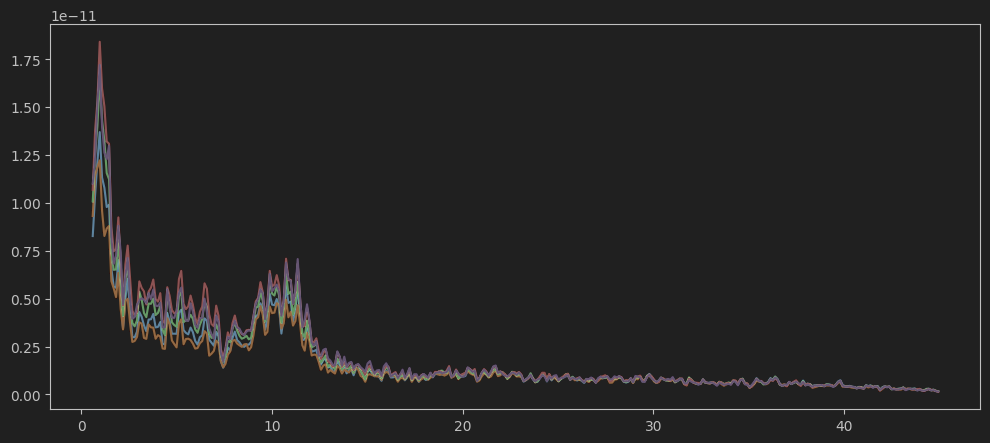
我们可以根据脑电波按频率的划分(α波、β波、θ波) 来获取不同波的强度
freq_bands = {
'Delta (0.5-4Hz)': (0.5, 4),
'Theta (4-8Hz)': (4, 8),
'Alpha (8-13Hz)': (8, 13),
'Beta (13-30Hz)': (13, 30),
'Gamma (30-45Hz)': (30, 45)
}
band_powers = {}
for band_name, (f_low, f_high) in freq_bands.items():
freq_mask = (freqs >= f_low) & (freqs <= f_high)
band_powers[band_name] = psds[:, freq_mask].mean(axis=1)使用matlibplot预览前5个通道的脑电波强度:
for i, (band_name, powers) in enumerate(band_powers.items()):
for j in range(5):
plt.bar(i-j*0.18+0.45, height=powers[j], width=0.18)
plt.xticks(np.arange(5), band_powers.keys())
plt.show()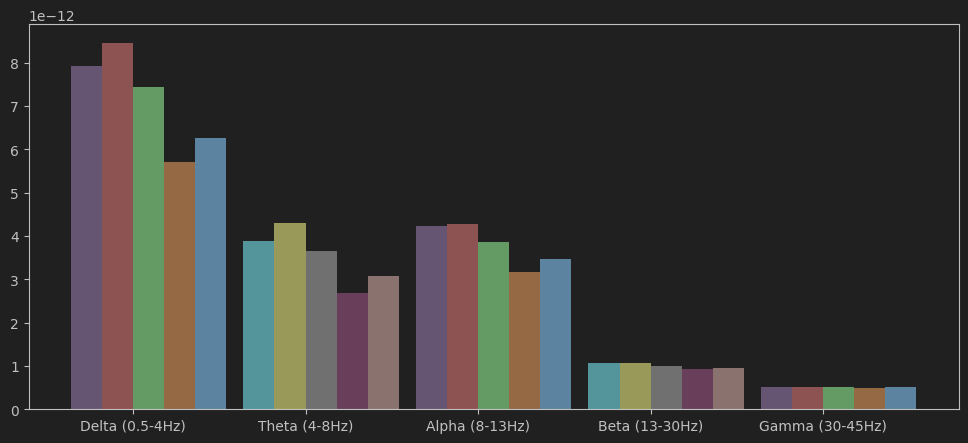
相对功率 (Relative Power): 某个频带的绝对功率占总功率(或特定频段范围总功率)的百分比。反映不同频带活动的比例关系(如Alpha/Theta比)。
略
时频域特征 (Time-Frequency Domain Features)
短时傅里叶变换 (Short-Time Fourier Transform, STFT)
将信号分成短时重叠的窗口,在每个窗口内进行傅里叶变换。结果是一个时频谱图。时间分辨率和频率分辨率受限于窗长(Heisenberg不确定性原理),无法同时获得高时频分辨率。
rfft_test_data1 = data[0, 1, 250:500]
rfft_test_data3 = data[0, 1, 250:1000]我们先从之前获取的数据中取一个测试样例中的一个通道中的0-1s和0-3s的数据,作测试用。
from scipy.signal import detrend
from scipy.fft import rfftfreq, rfft
freqs1 = rfftfreq(len(rfft_test_data1), d=1/fs)
freqs3 = rfftfreq(len(rfft_test_data3), d=1/fs)获取对两个数据的快速傅里叶变化得到的频率点,发现频率点受到数据频率和数据窗口长度的影响。
freqs1 ->
array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.,
11., 12., ..., 123., 124., 125.])
freqs3 -> array([ 0. , 0.3333, 0.6667, 1. , 1.3333,
1.6667, 2. , 2.3333, 2.6667, 3. , ...
123.6667, 124. , 124.3333, 124.6667, 125. ])所以如果频率和窗口长度不相等的情况下,如果需要计算x~(x+1)Hz的频率数据需要累加。 以下是参考代码:
for i in range(5, 45):
band_mask = (freqs >= i) & (freqs < i+1)
fft_band[:, i-5] = np.sum(fft_vals[:, band_mask], axis=1)摸清rfft的一些用法后,我打算构建一个函数来完成对源数据的快速傅里叶变化,函数输入为一次测试中采集的22通道数据,输出为该测试22通道在每一个时间窗口的频域特征。本次窗口和步长选取1s和0.2s,即250帧和50帧的数据。
from scipy.signal import detrend
from scipy.fft import rfftfreq, rfft
def rfft_eeg(eeg_signal, fs=250):
"""
输入 eeg_signal: shape = (n_channels, n_times)
返回: PSD feature, shape = (n_channels, n_freqs)
"""
eeg_signal = detrend(eeg_signal, axis=1) # 去趋势
freqs = rfftfreq(eeg_signal.shape[1], d=1/fs) # 根据时间窗口而定,为250
fft_vals = np.abs(rfft(eeg_signal, axis=1))
return fft_vals[:, 1:46]因为窗口长度和频率相等,所以快速傅里叶变化得到的频率点为整数频率点。因为已经进行了0.5Hz~45Hz的滤波,所以结果需选取1-45Hz的频率点。
如果需要将得到的频域数据进行进一步分析,可以采用对数化、标准化等手段统一数据范围,消除噪声干扰。如果后续数据用于机器学习或神经网络的训练,可进行展开。
from scipy.signal import detrend
from scipy.fft import rfftfreq, rfft
def rfft_eeg(eeg_signal, fs=250):
"""
输入 eeg_signal: shape = (n_channels, n_times)
返回: flattened PSD feature, shape = (n_channels, n_freqs)
"""
eeg_signal = detrend(eeg_signal, axis=1) # 去趋势
freqs = rfftfreq(eeg_signal.shape[1], d=1/fs) # 根据时间窗口而定,为250
fft_vals = np.abs(rfft(eeg_signal, axis=1))[:, 1:46]
fft_band = np.log1p(fft_vals)
fft_band = ((fft_band - np.mean(fft_band, axis = 1, keepdims=True)) /
(np.std(fft_band, axis = 1, keepdims=True) + 1e-6))
# fft_band = fft_band.flatten()
return fft_band构建好针对一段eeg信号的rfft后,我们尝试对全部数据提取时域信息。
rfft_data = np.empty((288, 11, 22, 45))
window = int(fs * 1.0) # 250
step = int(fs * 0.2) # 50
for i in range(data.shape[0]):
t = 500
s = 0
while t+window < data.shape[2]:
rfft_data[i, s] = rfft_eeg(data[i, :, t:t+window])
t += step
s += 1我们假设提示出现后1s-4s范围内运动意图最强烈,故只提取500帧到1250帧的数据,250帧的窗口和50帧的步长在750帧的数据中可以提取11段时域信息。
小波变换(Wavelet Transform, WT)和小波包变换
使用一系列可伸缩和平移的母小波函数来分析信号。用树的结构将原始信号一层一层的分解。小波变换只对信号的低频部分进一步分解,而小波包分解则兼顾高频部分。此二者能更好地适应EEG这种非平稳信号,提供局部时频信息,分辨率灵活。
参考资料:
小波与小波包、小波包分解与信号重构、小波包能量特征提取 暨 小波包分解后实现按频率大小分布重新排列(Matlab 程序详解)-CSDN博客
用python进行小波包分解_pywt.waveletpacket-CSDN博客
由于希望关注更多维度的频率信息,我这次主要采用小波包变换,以下是一张小波包变换的原理图。假设原始数据是采样率是256Hz,根据采样定理,奈奎斯特采样频率是128Hz,第一层就分解为0-64Hz的低频数据和64-128Hz的高频数据,逐层进行二分,到第4层就是每一个节点为8Hz频带的数据。就像运动意图所涉及的脑电数据主要是8-16Hz和16-24Hz的,我们就可以关注这两个频段的数据。这是小波包变换提取的频域信息。
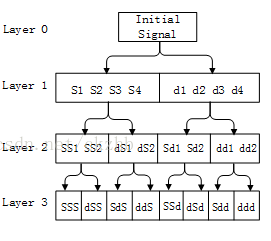
每一层变换,数据点的长度会接近减半。其中的数据不体现电压辐值,而是与小波基函数计算得到的小波系数,系数的顺序对应时间分辨率降低的时间顺序,体现时域信息。
注意,python的处理小波(包)变换的包下载与引用包名不同
import pywtpip3 install PyWavelets
conda install PyWavelets
根据前面观察的evoked的时域数据,我们可以选取0-512帧约2s的数据(方便计算,扩大窗口或可提高信噪比和准确度)奈奎斯特采样频率为256Hz,构建5层的小波包变换二叉树,第5层每个节点频带为8Hz,选取8-16、16-24、24-32Hz三个节点作后续分析。
wp_data = np.empty((288, 22, 3, 22))
for i in range(data.shape[0]): # 288 tests
for j in range(data.shape[1]): # 22 channels
wp = pywt.WaveletPacket(data[i, j, 250:762], 'db4', mode='symmetric', maxlevel=5)
for b in range(3):
wp_data[i, j, b, :] = wp[wp.get_level(5, 'freq')[b+1].path].data288测试点,22通道,3个频带,22个数据点。
第5层有32个节点,直觉上第五层节点的数据点长度应该是512/32=16,但是存在一些向上取整和算上头尾的操作使得偏移到了22个。
'db4'是小波基函数的类型,应该可改。[b+1].path是为了排除0-8Hz的节点。
wp.get_level(5, 'freq')
wp.get_level(5, 'natural') # == wp.get_level(5)这是两种遍历第五层节点的方法,前者是按频谱顺序依次递增;后者是节点遍历的默认方法,而它却并不是严格按照频谱顺序排列的,要注意。
模型训练【机器学习&神经网络训练】
回忆一下,我们通过各种特征提取的办法获得了如下的数据:
- 事件相关电位ERPs:erp_data (288, 1251)
- 功率谱密度PSD(全谱):不具标签分类性,不考虑
- 短时傅里叶变换STFT:rfft_data (288, 11, 22, 45)
- 小波包变换WPD:wp_data (288, 22, 3, 22)
在训练之前,我将信号预处理和特征提取的方法集成到了py文件中。里面是如下的结构,省略的部分为前文信号预处理和特征提取的部分。
class Features:
def __init__(self, i, evaluate=False):
...
def get_erp(self):
...
return erp_data # (288, 1251)
def get_rfft(self):
...
return rfft_data # (288, 11, 22, 45)
def get_wp(self):
...
return wp_data # (288, 22, 3, 22)本次模型训练与评估,统一使用A01T~A03T、A05T~A09T作为训练集,A01E~A03E、A05E~A09E作为测试集。测试数据集只含有原始脑电数据,不含有标签,标签需要另外下载。
标签需下载地址:https://www.bbci.de/competition/iv/results/ds2a/true_labels.zip
模型加载模式化可使用类似代码:
def load(i=1, evaluate=False):
filename = f'../data/BCICIV_2a_gdf/A0{i}{'E' if evaluate else 'T'}.gdf'
raw = mne.io.read_raw_gdf(filename)
raw.load_data()因为E训练集的gdf文件中没有769、770、771、772等提示事件的事件戳,只有768事件标志着一次测试的开始(比提示早2s),所以在信号预处理需要一些改动。以下是我集成的features.py中的改动方案。
event_id = dict({'768': 6}) \
if evaluate else dict({'769': 7, '770': 8, '771': 9, '772': 10})
tmin = 1. if evaluate else -1.
tmax = 6. if evaluate else 4.
epochs = mne.Epochs(raw, events, event_id, tmin=tmin, tmax=tmax, proj=True, picks=picks,
baseline=(tmin, tmin + 1.0), preload=True)
self.fs = raw.info['sfreq']
self.data = epochs.get_data()
if not evaluate:
self.labels = epochs.events[:, -1] - 7
self.data_dif = [self.data[self.labels == i, :, :] for i in range(4)]从另外下载的标签文件中加载可以参考如下代码:
from scipy.io import loadmat
e1_labels = loadmat('../data/BCICIV_2a_gdf/true_labels/A01E.mat')
y_test = e1_labels['classlabel'].reshape(288) - 1需要注意的是,标签文件中的左手/右手/脚/舌头提示对应标签为1/2/3/4,如果像我一样使用0/1/2/3的需要 - 1
K最邻近(KNN,K-NearestNeighbor)分类算法
拿到这么多数据,我们先不用热门的神经网络来训练,我们用机器学习最基础的算法kNN做一次分类试试。
tests = [1, 2, 3, 5, 6, 7, 8, 9]
knn = KNeighborsClassifier(n_neighbors=5) # 5/40
X_train = []
y_train = []
for i in tests:
features = Features(i)
X_train.append(features.get_erp())
y_train.append(features.labels)
X_train = np.vstack(X_train)
y_train = np.hstack(y_train)将测试集的数据进行合并,然后进行knn的训练和评估。
knn.fit(X_train, y_train)
scores = []
# Predict
for i in tests:
evaluation = Features(i, True)
X_test = evaluation.get_erp()
e1_labels = loadmat(f'../data/BCICIV_2a_gdf/true_labels/A0{i}E.mat')
y_test = e1_labels['classlabel'].reshape(288) - 1
scores.append(knn.score(X_test, y_test))
print(scores)
print(np.mean(scores))因为对特征提取进行结构化编程,我们只需如下改动就可以使用STFT和WPD的数据:
X_train.append(features.get_rfft().reshape((288, -1))) # get_wp
X_test = evaluation.get_rfft().reshape((288, -1))
分别选取k=5/k=40,对三种特征数据进行评估。
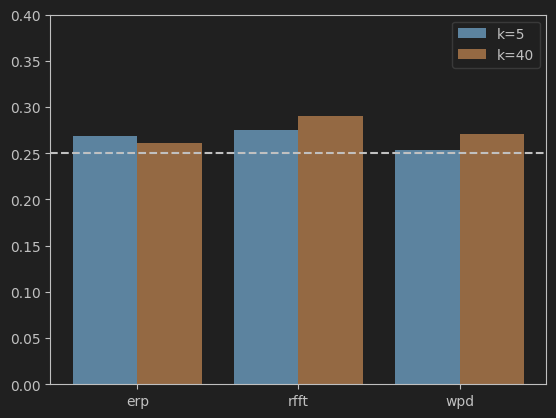
可以看到结果并不理想,只比随机预测的1/4略高。
共空间模式CSP(Communicating Sequential Processes)
其实CSP并不是一种机器学习的算法或者一种神经网络的架构,它是一种空间滤波的特征提取方法。其通过寻找最优的空间滤波器(投影方向),使得分类任务(如左手 vs 右手运动想象)的EEG信号方差差异最大化。此外,CSP还能降维。因为他可以在之前提到的基础特征提取方法之上在提取一次特征,所以放到这里。
CSP的原理:共空间模式CSP在脑机接口中的应用与Python实现-CSDN博客
我们先构建一个基础的四分类的csp分类器
from mne.decoding import CSP
csp = CSP(n_components=4, reg=None, log=True, norm_trace=False)因为csp的数据需要包含通道数据(n_test, n_channels, n_times),所以在获取训练数据集的erp数据时需要一些改动:
X_train.append(features.data)mne库中的csp包使用也比较简单,只需使用带标签的训练数据进行拟合,然后transform即可。
csp.fit(X_train, y_train)
X_train_csp = csp.transform(X_train)
X_test_csp = csp.transform(X_test)我们使用经过csp滤波后的数据再跑一次最简单的knn,平均准确率来到了0.325,并且有3个数据集的准确率有0.4及以上。
接下来尝试STFT和WPD的数据,不过STFT的数据通道数并不在数组的第二个维度,需要一些处理。当然也可以在获取stft数据时使得n_channels在第二个维度。
def reshape(X): # from (288, 11, 22, 45) to (288, 22, 11*45)
return np.stack([np.vstack(np.concatenate(item, axis=1)).reshape(22, -1) for item in X])- 平均准确率0.304。
WPD的处理有两种方法,一种的将三个频带的数据reshape,一种是每一个频带构建一个CSP分类器,transform之后再合并。
X_train.append(features.get_wp().reshape((288, 22, -1))) # 1 csp- 平均准确率0.368,A09E准确率来到0.625。
csp = [CSP(n_components=4, reg=None, log=True, norm_trace=False) for _ in range(3)]
for i in tests:
features = Features(i)
X_train.append(features.get_wp()) # (288, 22, 3, 22)
y_train.append(features.labels)
X_train = np.vstack(X_train)
y_train = np.hstack(y_train)
X_train_csp = np.empty((2304, 3, 4))
for i in range(3):
X_train_band = X_train[:, :, i, :]
csp[i].fit(X_train_band, y_train)
X_train_csp[:, i, :] = csp[i].transform(X_train_band)
X_train_csp = X_train_csp.reshape((288 * len(tests), -1))
knn.fit(X_train_csp, y_train)
scores = []
# Predict
for i in tests:
evaluation = Features(i, True)
X_test = evaluation.get_wp()
X_test_csp = np.stack([csp[i].transform(X_test[:, :, i, :]) for i in range(3)], axis=1).reshape(288, -1)
e1_labels = loadmat(f'../data/BCICIV_2a_gdf/true_labels/A0{i}E.mat')
...- 平均准确率0.401,提升明显。 因此后面针对WPD数据使用该种csp。
csp练习完毕,集成功能到csp_features.py
class CspFeatures:
def __init__(self, type='erp', csp_on=True): # erp、 rfft、 wp
self.type = type
self.csp_on = csp_on
self.tests = [1, 2, 3, 5, 6, 7, 8, 9]
if type == 'wp':
...
def get_train(self):
...
if not self.csp_on:
return X_train.reshape((288 * len(self.tests), -1)), y_train
...
return X_train_csp, y_train
def get_test(self, features):
...
return X_test_cspSVM支持向量机
集成后特征提取变得方便,使用pipeline优化训练过程。pipeline是 scikit-learn 中用于组织和简化数据处理、模型训练与评估的一个工具。
Pipeline:Sklearn 管道(Pipeline) | 菜鸟教程
cf = CspFeatures('erp')
X_train_csp, y_train = cf.get_train()
pipeline = Pipeline([
('scaler', StandardScaler()), # 数据标准化
('svc', SVC()) # 支持向量机分类器
])
pipeline.fit(X_train_csp, y_train)
scores = []
# Predict
for i in cf.tests:
X_test_csp = cf.get_test(Features(i, True))
e1_labels = loadmat(f'../data/BCICIV_2a_gdf/true_labels/A0{i}E.mat')
y_test = e1_labels['classlabel'].reshape(288) - 1
scores.append(pipeline.score(X_test_csp, y_test))
...wpd使用8-32Hz的三频带数据经过csp做svc,平均准确率来到0.454。为了追求更高准确率,我尝试对wpd的数据提高利用率,将原本对8-32Hz三频带的关注提高为6、7、8个频带的关注,准确率来到0.478、0.487、0.491,但是关注8个频带0-64Hz后半段已经经历滤波了,为什么还会有差异呢,望大佬解答。
因为7频带的A01E的准确度最高,假设我是正式参赛,手上只有A01E的标签作评估,因此我选取了A01E准确度最高的7频带作WPD特征的2.0版本。
其他机器学习算法
集成后变得尤为方便,只需改动pipeline的构建就可以使用不同的算法/模型。这里就省略对于这几个算法的调参了,只使用默认超参。
决策树分类器DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
pipeline = Pipeline([
('scaler', StandardScaler()), # 数据标准化
('clf', DecisionTreeClassifier())
])随机森林RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
pipeline = Pipeline([
('scaler', StandardScaler()), # 数据标准化
('rf', RandomForestClassifier()) # 随机森林
])各种算法得分预览:
加入了将wpd数据关注频带扩展为0-56这7个频带的数据。
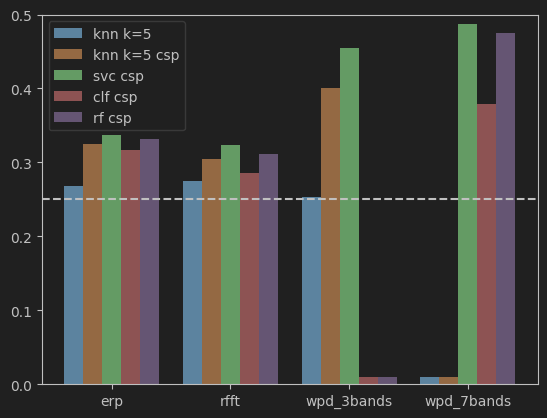
不由感叹,wpd和csp真是相依为命。
简单神经网络
尝试eeg领域的热门网络EEGNet之前,先使用tensorflow的Sequential()模块练手,顺便看一下性能。
...
X_train_csp, y_train = cf.get_train()
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(28),
tf.keras.layers.Dense(16, activation='sigmoid'),
tf.keras.layers.Dense(4, activation='softmax'),
tf.keras.layers.Dropout(0.2),
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
y_train_onehot = tf.keras.utils.to_categorical(y_train, num_classes=4)
model.fit(X_train_csp, y_train_onehot, batch_size=32, epochs=100)
scores = []
# Predict
for i in cf.tests:
...
y_pred_onehot = model.predict(X_test_csp)
y_pred = y_pred_onehot.argmax(axis=1)
scores.append(np.sum(y_pred == y_test) / 288)注意,标签数据需要转化为onehot编码。
针对wpd+csp得出的4x7维数据,简单MLP的准确率为0.461。
但是我们发现,经过csp的数据维度变得很小,一个csp分类器只会得出4维的数据,与神经网络能计算庞大数据的能力不符,所以我们再尝试一下原始数据。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(22, 1251)), # erp
# tf.keras.layers.Flatten(input_shape=(22, 495)), # rfft
# tf.keras.layers.Flatten(input_shape=(22, 7, 22)), # wpd
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(4, activation='softmax'),
])三种原始数据的输入层都有,切换注释即可。但是运行结果的准确率只有0.373(erp)、0.306(rfft)、0.309(wpd),非常低,不该是神经网络该有的样子,应该是哪里出了点问题。
如果想尝试对神经网络进行微调,可以用ipynb将数据存好方便训练,并用类似X_train的方法把X_test合并。因为之前发现每次运行最花时间的是从gdf文件加载raw。
X_test_csp = []
y_test = []
# Predict
for i in cf.tests:
X_test_csp.append(cf.get_test(Features(i, True)))
e1_labels = loadmat(f'../data/BCICIV_2a_gdf/true_labels/A0{i}E.mat')
y_test.append(e1_labels['classlabel'].reshape(288) - 1)
X_test_csp = np.vstack(X_test_csp)
y_test = np.hstack(y_test)EEGNet
专门为 EEG 分类设计的卷积神经网络架构。结构紧凑,参数少,泛化性好,非常适合 EEG 这种数据量通常不大的场景。它结合了时序卷积和空间卷积,能有效捕捉 EEG 信号的时空模式
文献翻译:EEGNet:一个小型的卷积神经网络,用于基于脑电的脑机接口 - 知乎
复现参考:EEGNet复现-CSDN博客
可见,在EEGNet提出的文献中,也使用了BCI IV 2a数据集进行测试。
模型复现比较复杂,直接帖源码了。deepseek写的
def EEGNet(input_shape, num_classes=4, sampling_rate=128, F1=8, D=2, F2=16,
dropout_rate=0.5, kernel_length=64, norm_rate=0.25):
"""
EEGNet模型实现 (兼容TF 2.17)
参数:
input_shape: 输入数据的形状 (channels, time_points)
num_classes: 分类数量
sampling_rate: 采样率 (Hz)
F1: 第一层卷积核数量
D: 深度乘数 (Depth multiplier)
F2: 第二层卷积核数量
dropout_rate: Dropout比例
kernel_length: 时间卷积核长度 (建议设为采样率的一半)
norm_rate: 权重约束的最大范数
"""
# 添加通道维度
input_layer = Input(shape=input_shape)
# 重塑为 (samples, channels, time_points, 1)
x = Reshape((input_shape[0], input_shape[1], 1))(input_layer)
# Block 1: 时间卷积
x = Conv2D(F1, (1, kernel_length), padding='same',
use_bias=False, kernel_constraint=max_norm(norm_rate))(x)
x = BatchNormalization(axis=1)(x)
# 深度卷积 (空间滤波)
x = DepthwiseConv2D((input_shape[0], 1), use_bias=False,
depth_multiplier=D,
depthwise_constraint=max_norm(norm_rate))(x)
x = BatchNormalization(axis=1)(x)
x = Activation('elu')(x)
# 平均池化
x = AveragePooling2D((1, 4))(x)
x = Dropout(dropout_rate)(x)
# Block 2: 可分离卷积
x = SeparableConv2D(
F2, (1, 16),
padding='same',
use_bias=False,
depthwise_constraint=max_norm(norm_rate),
pointwise_constraint=max_norm(norm_rate)
)(x)
x = BatchNormalization(axis=1)(x)
x = Activation('elu')(x)
# 平均池化
x = AveragePooling2D((1, 8))(x)
x = Dropout(dropout_rate)(x)
# 分类层
x = Flatten()(x)
x = Dense(num_classes, activation='softmax',
kernel_constraint=max_norm(norm_rate))(x)
return tf.keras.Model(inputs=input_layer, outputs=x)
def prepare_data(X, y, test_size=0.2, random_state=42):
"""
准备训练和验证数据
"""
# 转换为float32并标准化
X = X.astype('float32')
# 计算每个样本的均值和标准差
sample_means = np.mean(X, axis=(1, 2), keepdims=True)
sample_stds = np.std(X, axis=(1, 2), keepdims=True)
# 标准化数据 (避免除以零)
X = (X - sample_means) / (sample_stds + 1e-8)
# 拆分训练集和验证集
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=test_size, stratify=y, random_state=random_state
)
return X_train, X_val, y_train, y_val
def train_eegnet(X_train, y_train, X_val, y_val, input_shape,
epochs=300, batch_size=32, learning_rate=0.001):
"""
训练EEGNet模型 (兼容TF 2.17)
"""
# 创建模型
model = EEGNet(input_shape, num_classes=4, sampling_rate=128,
F1=8, D=2, F2=16, dropout_rate=0.5, kernel_length=64)
# 编译模型
model.compile(
optimizer=Adam(learning_rate=learning_rate),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 自定义回调系统 - 修复学习率属性问题
class CustomCallback:
def __init__(self, patience=30, min_lr=1e-6, lr_factor=0.5, lr_patience=10):
self.patience = patience
self.min_lr = min_lr
self.lr_factor = lr_factor
self.lr_patience = lr_patience
self.best_weights = None
self.best_val_loss = float('inf')
self.wait = 0
self.lr_wait = 0
self.current_lr = learning_rate
self.stopped_epoch = 0
def on_epoch_end(self, epoch, logs, model):
current_val_loss = logs['val_loss']
# 检查是否是最佳模型
if current_val_loss < self.best_val_loss:
self.best_val_loss = current_val_loss
self.best_weights = model.get_weights()
self.wait = 0
self.lr_wait = 0
else:
self.wait += 1
self.lr_wait += 1
# 检查学习率衰减
if self.lr_wait >= self.lr_patience:
# 计算新学习率
new_lr = max(self.min_lr, self.current_lr * self.lr_factor)
# 获取当前优化器配置
optimizer_config = model.optimizer.get_config()
# 更新学习率
optimizer_config['learning_rate'] = new_lr
# 创建新的优化器实例
new_optimizer = Adam.from_config(optimizer_config)
# 替换模型的优化器
model.optimizer = new_optimizer
# 更新当前学习率
self.current_lr = new_lr
print(f"学习率衰减至: {self.current_lr:.6f}")
self.lr_wait = 0
# 检查早停
if self.wait >= self.patience:
print(f"\n早停: 验证损失未改善超过 {self.patience} 轮")
model.stop_training = True
self.stopped_epoch = epoch
model.set_weights(self.best_weights)
# 创建回调实例
custom_cb = CustomCallback(patience=30)
# 训练历史记录
history = {'loss': [], 'val_loss': [], 'accuracy': [], 'val_accuracy': []}
# 训练模型
print("开始训练EEGNet模型...")
print(f"训练样本数: {len(X_train)}, 验证样本数: {len(X_val)}")
print(f"批量大小: {batch_size}, 初始学习率: {learning_rate}")
for epoch in range(epochs):
print(f"\n轮次 {epoch+1}/{epochs}")
# 训练步骤
epoch_loss = []
epoch_acc = []
# 打乱训练数据
indices = np.arange(len(X_train))
np.random.shuffle(indices)
X_train_shuffled = X_train[indices]
y_train_shuffled = y_train[indices]
for i in range(0, len(X_train_shuffled), batch_size):
batch_end = min(i + batch_size, len(X_train_shuffled))
batch_X = X_train_shuffled[i:batch_end]
batch_y = y_train_shuffled[i:batch_end]
with tf.GradientTape() as tape:
predictions = model(batch_X, training=True)
loss = tf.keras.losses.sparse_categorical_crossentropy(batch_y, predictions)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, model.trainable_variables)
model.optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 计算准确率
acc = tf.reduce_mean(tf.keras.metrics.sparse_categorical_accuracy(batch_y, predictions))
epoch_loss.append(loss.numpy())
epoch_acc.append(acc.numpy())
# 计算平均训练损失和准确率
train_loss = np.mean(epoch_loss)
train_acc = np.mean(epoch_acc)
# 验证步骤
val_loss = []
val_acc = []
for i in range(0, len(X_val), batch_size):
batch_end = min(i + batch_size, len(X_val))
batch_X = X_val[i:batch_end]
batch_y = y_val[i:batch_end]
predictions = model(batch_X, training=False)
loss = tf.reduce_mean(tf.keras.losses.sparse_categorical_crossentropy(batch_y, predictions))
acc = tf.reduce_mean(tf.keras.metrics.sparse_categorical_accuracy(batch_y, predictions))
val_loss.append(loss.numpy())
val_acc.append(acc.numpy())
val_loss = np.mean(val_loss)
val_acc = np.mean(val_acc)
# 记录历史
history['loss'].append(train_loss)
history['accuracy'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_accuracy'].append(val_acc)
print(f"训练损失: {train_loss:.4f}, 训练准确率: {train_acc:.4f}")
print(f"验证损失: {val_loss:.4f}, 验证准确率: {val_acc:.4f}")
print(f"当前学习率: {custom_cb.current_lr:.6f}")
# 回调函数
logs = {'val_loss': val_loss}
custom_cb.on_epoch_end(epoch, logs, model)
# 检查是否早停
if hasattr(model, 'stop_training') and model.stop_training:
print(f"训练在轮次 {custom_cb.stopped_epoch+1} 因早停而终止")
break
# 恢复最佳权重
if custom_cb.best_weights is not None:
model.set_weights(custom_cb.best_weights)
return model, history
def plot_training_history(history):
"""
绘制训练历史
"""
if not history:
print("无训练历史可绘制")
return
plt.figure(figsize=(12, 5))
# 准确率曲线
plt.subplot(1, 2, 1)
if 'accuracy' in history and 'val_accuracy' in history:
plt.plot(history['accuracy'], label='训练准确率')
plt.plot(history['val_accuracy'], label='验证准确率')
plt.title('准确率曲线')
plt.ylabel('准确率')
plt.xlabel('训练轮次')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
else:
print("缺少准确率数据")
# 损失曲线
plt.subplot(1, 2, 2)
if 'loss' in history and 'val_loss' in history:
plt.plot(history['loss'], label='训练损失')
plt.plot(history['val_loss'], label='验证损失')
plt.title('损失曲线')
plt.ylabel('损失')
plt.xlabel('训练轮次')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
else:
print("缺少损失数据")
plt.tight_layout()
plt.show()
def evaluate_model(model, X_test, y_test, batch_size=32):
"""
评估模型性能
"""
if model is None:
print("模型未定义")
return 0.0
# 评估测试集
test_loss = []
test_acc = []
y_pred = []
for i in range(0, len(X_test), batch_size):
batch_end = min(i + batch_size, len(X_test))
batch_X = X_test[i:batch_end]
batch_y = y_test[i:batch_end]
predictions = model(batch_X, training=False)
loss = tf.reduce_mean(tf.keras.losses.sparse_categorical_crossentropy(batch_y, predictions))
acc = tf.reduce_mean(tf.keras.metrics.sparse_categorical_accuracy(batch_y, predictions))
test_loss.append(loss.numpy())
test_acc.append(acc.numpy())
y_pred.extend(tf.argmax(predictions, axis=1).numpy())
if test_loss:
test_loss = np.mean(test_loss)
test_acc = np.mean(test_acc)
else:
test_loss = 0.0
test_acc = 0.0
print(f"\n测试集准确率: {test_acc:.4f}")
print(f"测试集损失: {test_loss:.4f}")
# 混淆矩阵
if y_pred:
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
try:
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=['左手', '右手', '脚', '舌头']
)
disp.plot(cmap='Blues')
plt.title('EEGNet分类混淆矩阵')
plt.show()
except Exception as e:
print(f"绘制混淆矩阵时出错: {e}")
return test_acc
# 主程序
if __name__ == "__main__":
# 假设你已经加载了数据
# X: EEG数据 (samples, channels, time_points)
# y: 类别标签 (0-3)
# 示例数据形状: (576, 22, 1251) - 假设采样率250Hz, 3秒试验
# 实际使用你的数据加载代码
cf = CspFeatures('erp', False)
X_train, y_train = cf.get_train()
# 设置输入形状 (通道数, 时间点数)
input_shape = (X_train.shape[1], X_train.shape[2])
X_test = []
y_test = []
# Predict
for i in cf.tests:
X_test.append(cf.get_test(Features(i, True)))
e1_labels = loadmat(f'../data/BCICIV_2a_gdf/true_labels/A0{i}E.mat')
y_test.append(e1_labels['classlabel'].reshape(288) - 1)
X_test = np.vstack(X_test)
y_test = np.hstack(y_test)
# 训练模型
model, history = train_eegnet(
X_train, y_train,
X_test, y_test,
input_shape,
epochs=300,
batch_size=32,
learning_rate=0.001
)
# 可视化训练过程
plot_training_history(history)
# 评估模型
test_acc = evaluate_model(model, X_test, y_test)
# 保存模型
model.save('eegnet_bci_iv_2a.h5')
print("模型已保存为 'eegnet_bci_iv_2a.h5'")因为引入了早停机制,模型在第198轮停止训练。测试集准确率: 0.5304。一些plot如下:
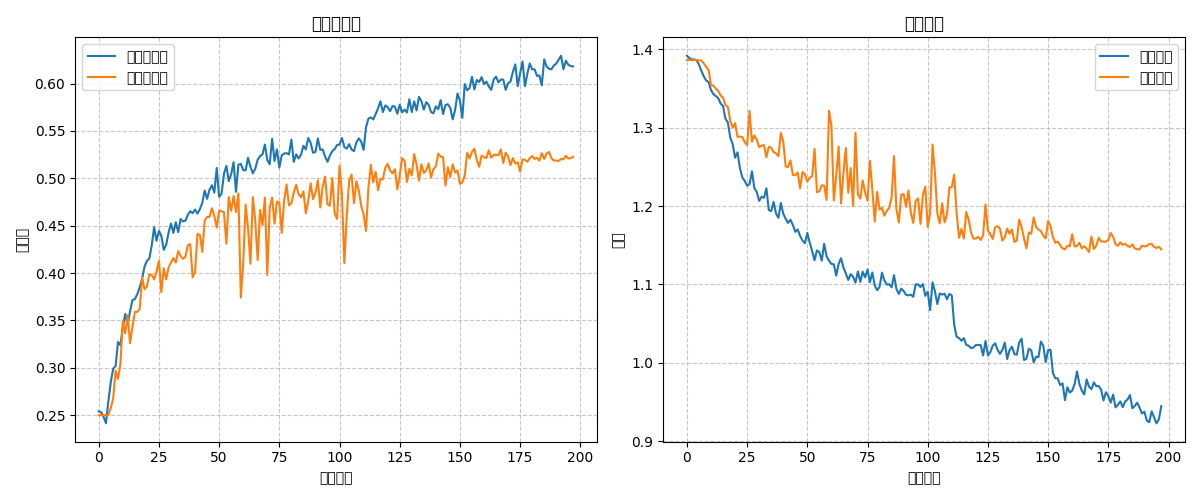
左边是准确率图,右边是loss图。蓝色是训练集,黄色是测试集。图例没弄好,因为是.py所以再跑一遍比较麻烦,直接说了。因为并没有使用四折交叉验证等优化算法,只是用最原始的数据跑模型,所以并没有达到原文献中60%多的准确率。
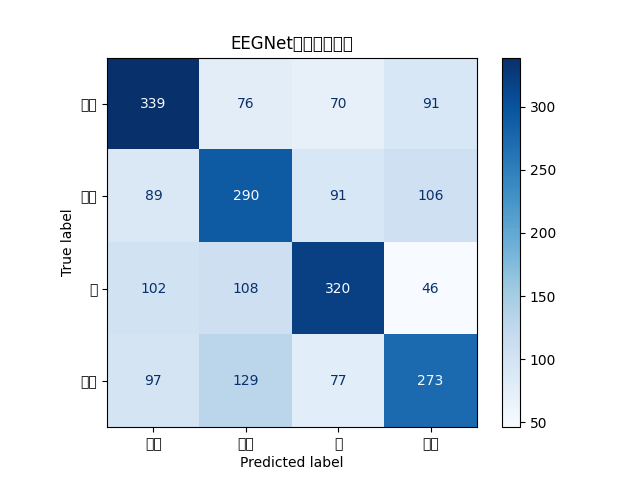
这个应该是四类标签的TN、FN、TP、FP。
本文先写到这吧,2w4的字,感觉把思路捋一遍清晰很多了,感觉自己还有很多需要学习和改进的地方,欢迎各路大佬指正!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 40
40 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)