机器学习(深度学习)
Python语言机器学习工具Scikit-learn包括许多智能的机器学习算法的实现Scikit-learn文档完善,容易上手,丰富的API接口函数sklearnscikit-learn中文社区数据量小,数据在sklearn库的本地,只要安装了sklearn,不用上网就可以获取数据量大,数据只能通过网络获取。
1 机器学习介绍及定义
1. 1 机器学习定义
机器学习(Machine Learning)本质上就是让计算机自己在数据中学习规律,并根据所得到的规律对未来数据进行预测。
机器学习包括如聚类、分类、决策树、贝叶斯、神经网络、深度学习(Deep Learning)等算法。
机器学习的基本思路是模仿人类学习行为的过程,如我们在现实中的新问题一般是通过经验归纳,总结规律,从而预测未来的过程。机器学习的基本过程如下:
- 数据收集:从各种数据源收集相关数据,数据的质量和数量对机器学习模型的性能有重要影响。
- 数据预处理:对收集到的数据进行清洗、转换、归一化等操作,去除噪声、处理缺失值,将数据转换为适合模型输入的格式。
- 模型选择与训练:根据任务的特点选择合适的机器学习模型,然后使用训练数据对模型进行训练,调整模型的参数,使其能够最好地拟合训练数据。
- 模型评估:使用测试数据对训练好的模型进行评估,常用的评估指标有准确率、召回率、F1 值、均方误差等,以衡量模型的性能。
- 模型优化与部署:根据评估结果对模型进行优化,如调整模型参数、选择更合适的特征等。优化后的模型可以部署到实际应用中,为用户提供服务。
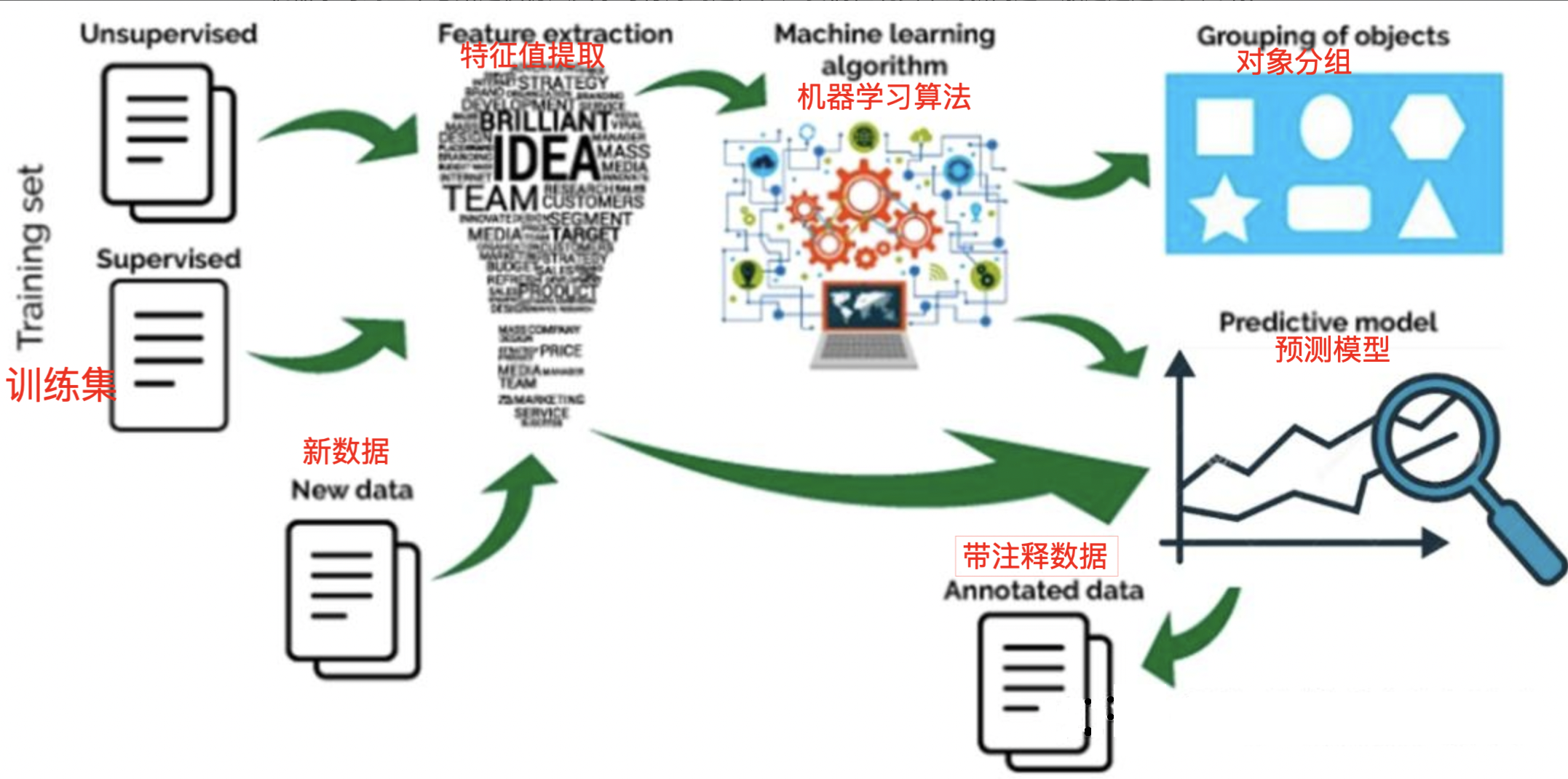
1.3 机器学习分类
机器学习经过几十年的发展,衍生出了很多种分类方法,这里按学习模式的不同,可分为监督学习、半监督学习、无监督学习和强化学习。
1.3.1 监督学习
监督学习(Supervised Learning)是从有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签。如果分类标签精确度越高,则学习模型准确度越高,预测结果越精确。
监督学习主要用于回归和分类。
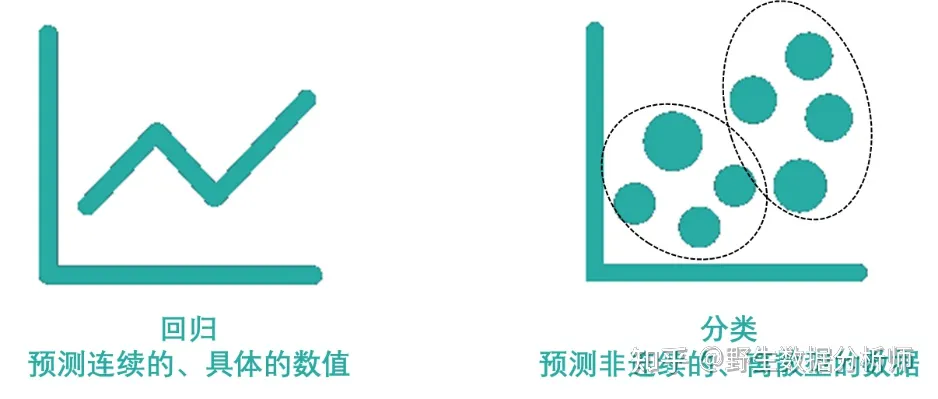
常见的监督学习的回归算法有线性回归、回归树、K邻近、Adaboost、神经网络等。
常见的监督学习的分类算法有朴素贝叶斯、决策树、SVM、逻辑回归、K邻近、Adaboost、神经网络等。
1.3.2 半监督学习
半监督学习(Semi-Supervised Learning)是利用少量标注数据和大量无标注数据进行学习的模式。
半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类。
常见的半监督学习算法有Pseudo-Label、Π-Model、Temporal Ensembling、Mean Teacher、VAT、UDA、MixMatch、ReMixMatch、FixMatch等。
1.3.3 无监督学习
无监督学习(Unsupervised Learning)是从未标注数据中寻找隐含结构的过程。
无监督学习主要用于关联分析、聚类和降维。
常见的无监督学习算法有稀疏自编码(Sparse Auto-Encoder)、主成分分析(Principal Component Analysis, PCA)、K-Means算法(K均值算法)、DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)、最大期望算法(Expectation-Maximization algorithm, EM)等。
1.3.4 强化学习
强化学习(Reinforcement Learning)类似于监督学习,但未使用样本数据进行训练,是是通过不断试错进行学习的模式。
在强化学习中,有两个可以进行交互的对象:智能体(Agnet)和环境(Environment),还有四个核心要素:策略(Policy)、回报函数(收益信号,Reward Function)、价值函数(Value Function)和环境模型(Environment Model),其中环境模型是可选的。
强化学习常用于机器人避障、棋牌类游戏、广告和推荐等应用场景中。
1.4 机器学习需要具备的基础的知识
机器学习涉及到线性代数、微积分、概率和统计。
学习机器学习需要掌握一定的数学和编程基础。以下是一些建议,帮助您开始学习机器学习:
学习数学基础:了解线性代数、概率论和统计学等数学概念。这些概念在机器学习中非常重要,可以帮助您理解算法和模型背后的原理。
学习编程语言:掌握至少一种常用的编程语言,如Python或R。这些语言在机器学习中广泛使用,具有丰富的机器学习库和工具。
学习机器学习算法:了解常见的机器学习算法,如线性回归、决策树、支持向量机、神经网络等。学习它们的原理、应用和优缺点。
学习机器学习工具和框架:熟悉常用的机器学习工具和框架,如scikit-learn、TensorFlow、PyTorch等。掌握它们的使用方法和基本操作。
实践项目:通过实践项目来应用所学的知识。选择一些小型的机器学习项目,从数据收集和预处理到模型训练和评估,逐步提升自己的实践能力。
学习资源:利用在线教程、课程、书籍和开放资源来学习机器学习。有很多免费和付费的学习资源可供选择,如Coursera、Kaggle、GitHub上的机器学习项目等。
参与机器学习社区:加入机器学习社区,与其他学习者和专业人士交流经验和学习资源。参与讨论、阅读博客、参加线下活动等,扩展自己的学习网络。
持续学习和实践:机器学习是一个不断发展的领域,保持学习的态度并持续实践非常重要。跟随最新的研究成果、参与竞赛和项目,不断提升自己的技能。
记住,机器学习是一个广阔的领域,需要不断的学习和实践才能掌握。持续投入时间和精力,逐步积累经验和知识,便会逐渐掌握机器学习的技能。
1.5 机器学习的应用场合
机器学习的应用场景非常广泛,几乎涵盖了各个行业和领域。以下是一些常见的机器学习应用场景的示例:
-
自然语言处理(NLP)
自然语言处理是人工智能中的重要领域之一,涉及计算机与人类自然语言的交互。NLP技术可以实现语音识别、文本分析、情感分析等任务,为智能客服、聊天机器人、语音助手等提供支持。
-
医疗诊断与影像分析
机器学习在医疗领域有着广泛的应用,包括医疗图像分析、疾病预测、药物发现等。深度学习模型在医疗影像诊断中的表现引人注目。
-
金融风险管理
机器学习在金融领域的应用越来越重要,尤其是在风险管理方面。模型可以分析大量的金融数据,预测市场波动性、信用风险等。
-
预测与推荐系统
机器学习在预测和推荐系统中也有广泛的应用,如销售预测、个性化推荐等。协同过滤和基于内容的推荐是常用的技术。
-
制造业和物联网
物联网(IoT)在制造业中的应用越来越广泛,机器学习可用于处理和分析传感器数据,实现设备预测性维护和质量控制。
-
能源管理与环境保护
机器学习可以帮助优化能源管理,减少能源浪费,提高能源利用效率。通过分析大量的能源数据,识别优化的机会。
-
决策支持与智能分析
机器学习在决策支持系统中的应用也十分重要,可以帮助分析大量数据,辅助决策制定。基于数据的决策可以更加准确和有据可依。
-
图像识别与计算机视觉
图像识别和计算机视觉是另一个重要的机器学习应用领域,它使计算机能够理解和解释图像。深度学习模型如卷积神经网络(CNN)在图像分类、目标检测等任务中取得了突破性进展。
1.7 机器学习项目开发步骤
有5个基本步骤用于执行机器学习任务:
-
收集数据:无论是来自excel,access,文本文件等的原始数据,这一步(收集过去的数据)构成了未来学习的基础。相关数据的种类,密度和数量越多,机器的学习前景就越好。
-
准备数据:任何分析过程都会依赖于使用的数据质量如何。人们需要花时间确定数据质量,然后采取措施解决诸如缺失的数据和异常值的处理等问题。探索性分析可能是一种详细研究数据细微差别的方法,从而使数据的质量迅速提高。
-
训练模型:此步骤涉及以模型的形式选择适当的算法和数据表示。清理后的数据分为两部分 - 训练和测试(比例视前提确定); 第一部分(训练数据)用于开发模型。第二部分(测试数据)用作参考依据。
-
评估模型:为了测试准确性,使用数据的第二部分(保持/测试数据)。此步骤根据结果确定算法选择的精度。检查模型准确性的更好测试是查看其在模型构建期间根本未使用的数据的性能。
-
提高性能:此步骤可能涉及选择完全不同的模型或引入更多变量来提高效率。这就是为什么需要花费大量时间进行数据收集和准备的原因。
无论是任何模型,这5个步骤都可用于构建技术,当我们讨论算法时,您将找到这五个步骤如何出现在每个模型中!
2 scikit-learn工具介绍
-
Python语言机器学习工具
-
Scikit-learn包括许多智能的机器学习算法的实现
-
Scikit-learn文档完善,容易上手,丰富的API接口函数
-
Scikit-learn官网:scikit-learn: machine learning in Python — scikit-learn 1.6.1 documentation
-
Scikit-learn中文文档:sklearn
2.1 scikit-learn安装
参考以下安装教程:https://www.sklearncn.cn/62/
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn2.2 Scikit-learn包含的内容
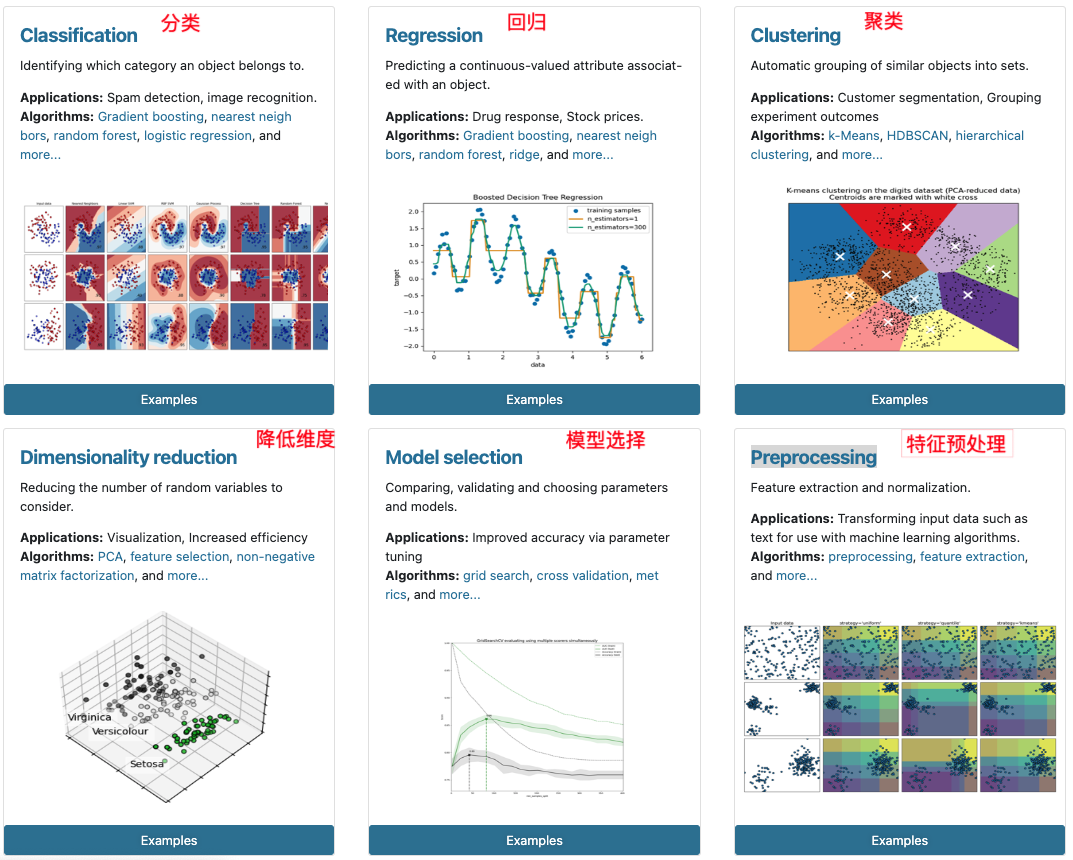
3 数据集
3.1 sklearn玩具数据集介绍
数据量小,数据在sklearn库的本地,只要安装了sklearn,不用上网就可以获取 
3.2 sklearn现实世界数据集介绍
数据量大,数据只能通过网络获取
3.3 sklearn加载玩具数据集
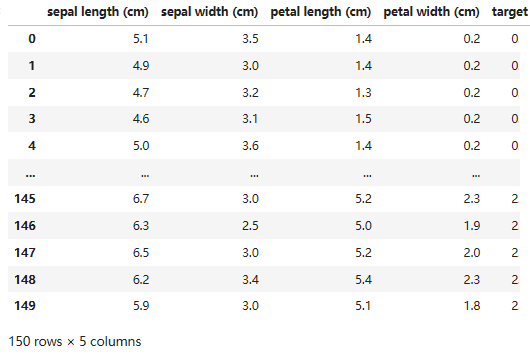
示例1:鸢尾花数据
from sklearn.datasets import load_iris
iris = load_iris()#鸢尾花数据鸢尾花数据集介绍
特征(feature)有:
花萼长 sepal length
花萼宽sepal width
花瓣长 petal length
花瓣宽 petal width
三分类(target):
0-Setosa山鸢尾
1-versicolor变色鸢尾
2-Virginica维吉尼亚鸢尾
鸢尾花数据集代码示例:
from sklearn.datasets import load_iris
iris = load_iris()#加载鸢尾花数据集
# print(iris)
data=iris.data#鸢尾花的特征数据集(x,data,特征)
print(data[:5])
print(type(data))
print(data.shape)
print(data.dtype)
print(iris.feature_names)#特征的名字
target=iris.target#鸢尾花的标签数据集(y,target,标签,labels,目标)
print(target)
print(type(target))
print(target.shape)
print(iris.target_names)#标签名称: 'setosa-山鸢尾' 'versicolor-变色鸢尾' 'virginica-维基利亚鸢尾'
print(iris.DESCR)#数据集的描述
print(iris.filename)#数据集的文件名下面使用pandas把特征和目标一起显示出来
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
feature = iris.data
target = iris.target
target.shape=(len(target), 1)
data = np.hstack([feature, target])
cols = iris.feature_names
cols.append("target")
pd.DataFrame(data,columns=cols)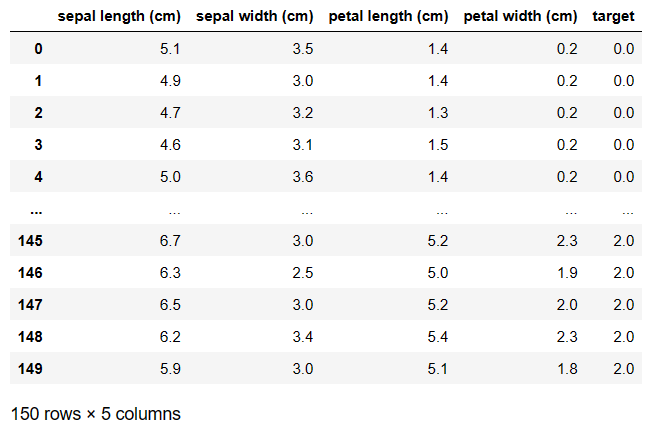
示例2:葡萄酒数据集
from sklearn.datasets import load_wine
wine=load_wine( )#输出葡萄酒数据集
# print(wine)
data=wine.data#葡萄酒的特征数据集(x,data,特征)
print(data[:4])
print(type(data))
print(data.shape)
print(data.dtype)
print(wine.feature_names)#葡萄酒数据集中的特征名
target=wine.target#葡萄酒的标签数据集(y,target,标签,labels,目标)
print(target)
print(type(target))
print(target.shape)
print(wine.target_names)#标签名称:三种类别葡萄酒的名称
print(wine.DESCR)#数据集的描述
# print(wine.filename) 数据集的文件名 该数据集没有filename属性下面使用pandas把特征和目标一起显示出来
import pandas as pd
import numpy as np
from sklearn.datasets import load_wine
wine=load_wine()
feature = wine.data
target = wine.target
target.shape=(len(target), 1)
data = np.hstack([feature, target])
cols = wine.feature_names
cols.append("target")
pd.DataFrame(data,columns=cols)3.4 sklearn获取现实世界数据集
(1)所有现实世界数据,通过网络才能下载后,默认保存的目录可以使用下面api获取。实际上就是保存到home目录
(2)下载时,有可能回为网络问题而出问题
(3)第一次下载会保存的硬盘中,如果第二次下载,因为硬盘中已经保存有了,所以不会再次下载就直接加载成功了。
示例:获取20分类新闻数据
使用函数:sklearn.datasets.fetch_20newsgroups(data_home,subset)
函数参数说明:
data_home:None是默认值,下载的文件路径为 “C:/Users/ADMIN/scikit_learn_data/20news-bydate_py3.pkz”
自定义路径,例如 “./src”, 下载的文件路径为“./20news-bydate_py3.pkz”
subset:“train”,只下载训练集
“test”,只下载测试集
“all”, 下载的数据包含了训练集和测试集
return_X_y,决定着返回值的情况:True,fFalse(默认值)
当参数return_X_y值为False时, 函数返回Bunch对象,Bunch对象中有以下属性
*data:特征数据集, 长度为18846的列表list, 每一个元素就是一篇新闻内容, 共有18846篇
*target:目标数据集,长度为18846的数组ndarray, 第一个元素是一个整数,整数值为[0,20)
*target_names:目标描述,长度为20的list
*filenames:长度为18846的ndarray, 元素为字符串,代表新闻的数据位置的路径
当参数return_X_y值为True时,函数返回值为元组,元组长度为2, 第一个元素值为特征数据集,第二个元素值为目标数据集
# 加载联网下载的数据集
from sklearn.datasets import fetch_20newsgroups
from sklearn import datasets
# path=datasets.get_data_home()#查看数据集默认的下载路径
# print(path)#C:\Users\JYL\scikit_learn_data
news=fetch_20newsgroups(data_home="./src",subset="train")#联网加载新闻数据集
print(len(news.data))
print(news.data[0:4])
print(news.target)
print(news.target_names)3.5 本地csv数据
(1) 创建csv文件
方式1:打开计事本,写出如下数据,数据之间使用英文下的逗号, 保存文件后把后缀名改为csv
csv文件可以使用excel打开
方式2:创建excel 文件, 填写数据,以csv为后缀保存文件
(2) pandas加载csv
使用pandas的read_csv(“文件路径”)函数可以加载csv文件,得到的结果为数据的DataFrame形式
pd.read_csv("./src/ss.csv")3.6 数据集的划分
from sklearn.model_selection import train_test_split
# 数据集划分1
# x=[1,2,3,4,5,6,7,8,9,10]
# x_train,x_test=train_test_split(x)
# print(x_train,x_test)#划分的数据运行一次就变一次
# 数据集划分2
x=[1,2,3,4,5,6,7,8,9,10]
# 划分的数据不会变
# x_train,x_test=train_test_split(x,train_size=0.8,shuffle=True,random_state=42)
# x_train,x_test=train_test_split(x,train_size=4,shuffle=True,random_state=42)
# x_train,x_test=train_test_split(x,test_size=0.8,shuffle=True,random_state=42)
# x_train,x_test=train_test_split(x,test_size=9,shuffle=True,random_state=42)
# print(x_train,x_test)
# 数据集划分3
x=[1,2,3,4,5,6,7,8,9,10]
y=[10,20,30,40,50,60,70,80,90,100]
x_train,x_test,y_train,y_test=train_test_split(x,y)
print(x_train,x_test)
print(y_train,y_test)4 特征工程
4.1 特征工程概念
特征工程:就是对特征进行相关的处理
一般使用pandas来进行数据清洗和数据处理、使用sklearn来进行特征工程
特征工程是将任意数据(如文本或图像)转换为可用于机器学习的数字特征,比如:字典特征提取(特征离散化)、文本特征提取、图像特征提取。
特征工程步骤为:
-
特征提取, 如果不是像dataframe那样的数据,要进行特征提取,比如字典特征提取,文本特征提取
-
无量纲化(预处理)
-
归一化
-
标准化
-
-
降维
-
底方差过滤特征选择
-
主成分分析-PCA降维
-
4.2 特征工程API
-
实例化转换器对象,转换器类有很多,都是Transformer的子类, 常用的子类有:
DictVectorizer 字典特征提取
CountVectorizer 文本特征提取
TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
MinMaxScaler 归一化
StandardScaler 标准化
VarianceThreshold 底方差过滤降维
PCA 主成分分析降维转换器对象调用fit_transform()进行转换, 其中fit用于计算数据,transform进行最终转换
fit_transform()可以使用fit()和transform()代替
data_new = transfer.fit_transform(data)
可写成
transfer.fit(data)
data_new = transfer.transform(data)4.3 DictVectorizer 字典列表特征提取
稀疏矩阵
稀疏矩阵是指一个矩阵中大部分元素为零,只有少数元素是非零的矩阵。在数学和计算机科学中,当一个矩阵的非零元素数量远小于总的元素数量,且非零元素分布没有明显的规律时,这样的矩阵就被认为是稀疏矩阵。例如,在一个1000 x 1000的矩阵中,如果只有1000个非零元素,那么这个矩阵就是稀疏的。
由于稀疏矩阵中零元素非常多,存储和处理稀疏矩阵时,通常会采用特殊的存储格式,以节省内存空间并提高计算效率。
三元组表 (Coordinate List, COO):三元组表就是一种稀疏矩阵类型数据,存储非零元素的行索引、列索引和值:
(行,列) 数据
(0,0) 10
(0,1) 20
(2,0) 90
(2,20) 8
(8,0) 70
表示除了列出的有值, 其余全是0
非稀疏矩阵(稠密矩阵)
非稀疏矩阵,或称稠密矩阵,是指矩阵中非零元素的数量与总元素数量相比接近或相等,也就是说矩阵中的大部分元素都是非零的。在这种情况下,矩阵的存储通常采用标准的二维数组形式,因为非零元素密集分布,不需要特殊的压缩或优化存储策略。
-
存储:稀疏矩阵使用特定的存储格式来节省空间,而稠密矩阵使用常规的数组存储所有元素,无论其是否为零。
-
计算:稀疏矩阵在进行计算时可以利用零元素的特性跳过不必要的计算,从而提高效率。而稠密矩阵在计算时需要处理所有元素,包括零元素。
-
应用领域:稀疏矩阵常见于大规模数据分析、图形学、自然语言处理、机器学习等领域,而稠密矩阵在数学计算、线性代数等通用计算领域更为常见。
在实际应用中,选择使用稀疏矩阵还是稠密矩阵取决于具体的问题场景和数据特性。
(1) api
-
创建转换器对象:
sklearn.feature_extraction.DictVectorizer(sparse=True)
参数:
sparse=True返回类型为csr_matrix的稀疏矩阵
sparse=False表示返回的是数组,数组可以调用.toarray()方法将稀疏矩阵转换为数组
-
转换器对象:
转换器对象调用fit_transform(data)函数,参数data为一维字典数组或一维字典列表,返回转化后的矩阵或数组
转换器对象get_feature_names_out()方法获取特征名
# 引入字典列表特征提取的工具 from sklearn.feature_extraction import DictVectorizer # 字典列表向量化 data=[{'city':'北京','temperature':40}, {'city':'上海','temperature':34}, {'city':'深圳','temperature':28}, {'city':'深圳','temperature':13}] # 创建一个字典列表特征提取工具 tool=DictVectorizer(sparse=True)#sparse=True表示返回稀疏矩阵(三元组表) # 字典列表特征提取 data=tool.fit_transform(data) print(data)#三元组表 print(data.toarray())#三元组表转数组 print(tool.feature_names_)4.4 CountVectorizer 文本特征提取
(1) API
sklearn.feature_extraction.text.CountVectorizer
构造函数关键字参数stop_words,值为list,表示词的黑名单(不提取的词)
fit_transform函数的返回值为稀疏矩阵
# 文本特征提取
from sklearn.feature_extraction.text import CountVectorizer
# 英文词频特征提取
data=['stu is well,stu is great','in other words']
cv=CountVectorizer()#创建词频特征提取器
data=cv.fit_transform(data)#特征提取
print(data.toarray())#三元组表转数组
print(cv.get_feature_names_out())
(3) 中文文本提取
a.中文文本不像英文文本,中文文本文字之间没有空格,所以要先分词,一般使用jieba分词.
b.下载jieba组件, (不要使用conda)
c.jieba的基础
使用jieba封装一个函数,功能是把汉语字符串中进行分词(会忽略长度小于等于1的词语,因为它们往往缺乏语义信息,不能很好地表达文本的特征)
# 引入jieba实现中文特征提取
import jieba
str="教育学会会长期间坚定支持民办教育事业!"
data=jieba.cut(str)#分词,返回可迭代对象
# print(next(data))
# print(next(data))
# print(next(data))
# print(next(data))
# print(next(data))
data=list(data)
print(data)
str1=" ".join(data)
print(str1)
4.5 TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
(1) 算法
词频(Term Frequency, TF), 表示一个词在当前篇文章中的重要性
逆文档频率(Inverse Document Frequency, IDF), 反映了词在整个文档集合中的稀有程度
 (2) API
(2) API
sklearn.feature_extraction.text.TfidfVectorizer()
构造函数关键字参数stop_words,表示词特征黑名单
fit_transform函数的返回值为稀疏矩阵
(3) 示例
# 稀有度(词语的重要程度)特征提取
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def fenci(str1):
return " ".join(list(jieba.cut(str1)))
data=["教育学会会长期间坚定支持民办教育事业事业!","热忱关心扶持民办学校发展","事业做出重大贡献!"]
data=[fenci(el) for el in data]
# print(data)
tool=TfidfVectorizer()#创建工具
tf_idf=tool.fit_transform(data)
print(tf_idf.toarray())
print(tool.get_feature_names_out())手动实现:
# 手动实现tf-idf
from sklearn.feature_extraction.text import CountVectorizer
import jieba
import numpy as np
from sklearn.preprocessing import normalize
def fenci(str1):
return " ".join(list(jieba.cut(str1)))
data=["教育学会会长期间坚定支持民办教育事业事业!","热忱关心扶持民办学校发展","事业做出重大贡献!"]
data=[fenci(el) for el in data]
# print(data)
def if_idf(x):
cv=CountVectorizer()
tf=cv.fit_transform(x).toarray()
print(tf)
# print(tf!=0)
fenzi=len(tf)+1
fenmu=np.sum(tf!=0,axis=0)+1
idf=np.log(fenzi/fenmu)+1
# print(idf)
tf_idf=tf*idf
tf_idf=normalize(tf_idf,norm="l2",axis=1)
print(tf_idf)
if_idf(data)4.6 无量纲化-预处理
无量纲,即没有单位的数据
无量纲化包括"归一化"和"标准化", 为什么要进行无量纲化呢?
这是一个男士的数据表: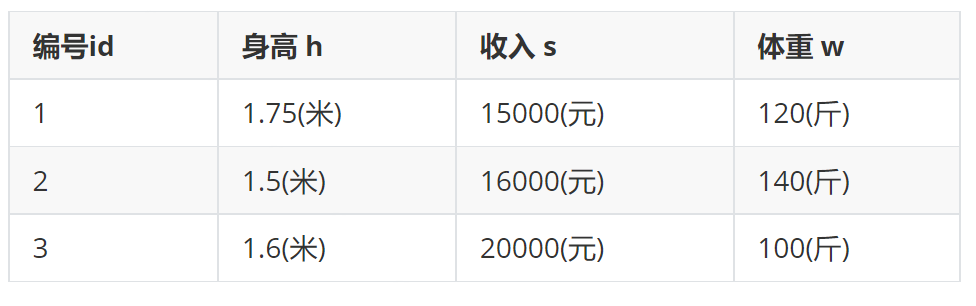
假设算法中需要求它们之间的欧式距离, 这里以编号1和编号2为示例:
从计算上来看, 发现身高对计算结果没有什么影响, 基本主要由收入来决定了,但是现实生活中,身高是比较重要的判断标准. 所以需要无量纲化.
(1) MinMaxScaler 归一化
通过对原始数据进行变换把数据映射到指定区间(默认为0-1)
<1>归一化公式: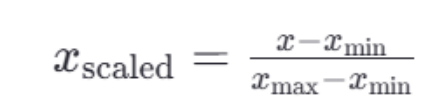
这里的 𝑥min 和 𝑥max 分别是每种特征中的最小值和最大值,而 𝑥是当前特征值,𝑥scaled 是归一化后的特征值。
若要缩放到其他区间,可以使用公式:x=x*(max-min)+min;
比如 [-1, 1]的公式为: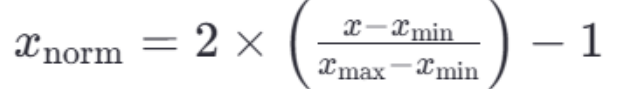
手算过程: 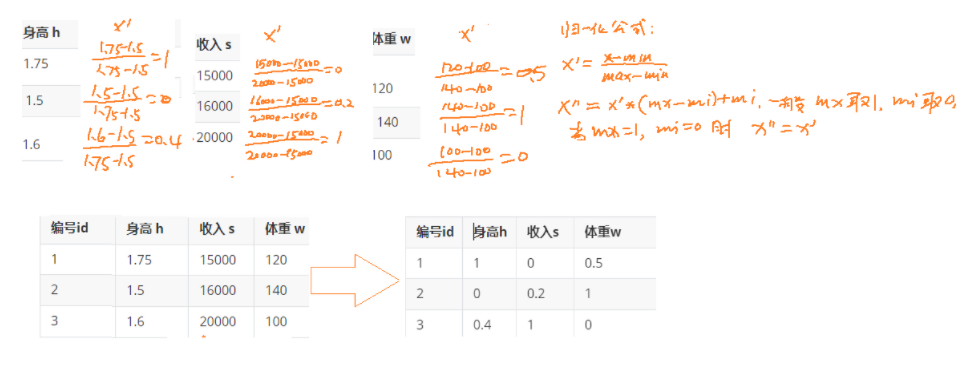
<2>归一化API
sklearn.preprocessing.MinMaxScaler(feature_range)
参数:feature_range=(0,1) 归一化后的值域,可以自己设定
fit_transform函数归一化的原始数据类型可以是list、DataFrame和ndarray, 不可以是稀疏矩阵
fit_transform函数的返回值为ndarray
<3>归一化示例
from sklearn.preprocessing import MinMaxScaler
# 最大值最小值归一化
x=[[100,2],
[800,3],
[300,7],
[2300,4]]
tool=MinMaxScaler(feature_range=(0,1))
x=tool.fit_transform(x)
print(x)<4>缺点
最大值和最小值容易受到异常点影响,所以鲁棒性较差。所以常使用标准化的无量钢化
(2)normalize归一化
API
from sklearn.preprocessing import normalize
normalize(data, norm='l2', axis=1)
#data是要归一化的数据
#norm是使用那种归一化:"l1" "l2" "max
#axis=0是列 axis=1是行<1> L1归一化
绝对值相加作为分母,特征值作为分子
<2> L2归一化
平方相加作为分母,特征值作为分子
<3> max归一化
max作为分母,特征值作为分子
# nomalize归一化
from sklearn.preprocessing import normalize
x=[[100,2],
[800,3],
[300,7],
[2300,4]]
# max归一化:max作为分母,特征值作为分子
x=normalize(x,norm="max",axis=0)#axis=0为列 axis=1为行
print(x)
# l1归一化:绝对值相加作为分母,特征值作为分子
x=normalize(x,norm="l1",axis=0)
print(x)
# l2归一化:平方相加作为分母,特征值作为分子
x=normalize(x,norm="l2",axis=0)
print(x)(3)StandardScaler 标准化
在机器学习中,标准化是一种数据预处理技术,也称为数据归一化或特征缩放。它的目的是将不同特征的数值范围缩放到统一的标准范围,以便更好地适应一些机器学习算法,特别是那些对输入数据的尺度敏感的算法。
<1>标准化公式
最常见的标准化方法是Z-score标准化,也称为零均值标准化。它通过对每个特征的值减去其均值,再除以其标准差,将数据转换为均值为0,标准差为1的分布。这可以通过以下公式计算: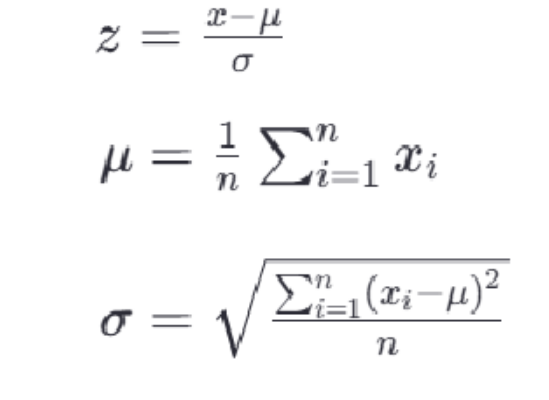
其中,z是转换后的数值,x是原始数据的值,μ是该特征的均值,σ是该特征的 标准差
<2> 标准化 API
sklearn.preprocessing.StandardScale
与MinMaxScaler一样,原始数据类型可以是list、DataFrame和ndarray
fit_transform函数的返回值为ndarray, 归一化后得到的数据类型都是ndarray
from sklearn.preprocessing import StandardScaler
#不能加参数feature_range=(0, 1)
transfer = StandardScaler()
data_new = transfer.fit_transform(data) #data_new的类型为ndarray<3>标准化示例
# 均值方差标准化
from sklearn.preprocessing import StandardScaler
x=[[100,2],
[800,3],
[300,7],
[2300,4]]
tool=StandardScaler()
x=tool.fit_transform(x)
print(x)<4> 注意点
在数据预处理中,特别是使用如StandardScaler这样的数据转换器时,fit、fit_transform和transform这三个方法的使用是至关重要的,它们各自有不同的作用:
-
fit:
-
这个方法用来计算数据的统计信息,比如均值和标准差(在
StandardScaler的情况下)。这些统计信息随后会被用于数据的标准化。 -
你应当仅在训练集上使用
fit方法。
-
-
fit_transform:
-
这个方法相当于先调用
fit再调用transform,但是它在内部执行得更高效。 -
它同样应当仅在训练集上使用,它会计算训练集的统计信息并立即应用到该训练集上。
-
-
transform:
-
这个方法使用已经通过
fit方法计算出的统计信息来转换数据。 -
它可以应用于任何数据集,包括训练集、验证集或测试集,但是应用时使用的统计信息必须来自于训练集。
-
当你在预处理数据时,首先需要在训练集X_train上使用fit_transform,这样做可以一次性完成统计信息的计算和数据的标准化。这是因为我们需要确保模型是基于训练数据的统计信息进行学习的,而不是整个数据集的统计信息。
一旦scaler对象在X_train上被fit,它就已经知道了如何将数据标准化。这时,对于测试集X_test,我们只需要使用transform方法,因为我们不希望在测试集上重新计算任何统计信息,也不希望测试集的信息影响到训练过程。如果我们对X_test也使用fit_transform,测试集的信息就可能会影响到训练过程。
总结来说:我们常常是先fit_transform(x_train)然后再transform(x_text)
# fit,transform,fit_transform 的用法
from sklearn.preprocessing import StandardScaler
x=[[100,2],
[800,3],
[300,7],
[2300,4]]
tool=StandardScaler()
tool.fit(x)
# print(tool.mean_)#均值
# print(tool.var_)#方差
# print(tool.scale_)#标准差
tool.transform(x)#使用x的均值,方差
x2=[[1,2],
[8,3],
[30,7],
[23,4]]
x2=tool.transform(x2)#用x中的均值和方差
print(x2)
x3=[[1,2]]
tool.fit_transform(x2)#计算x2的均值和方差,标准化
x3=tool.transform(x3)#用x2的均值和方差转化x3
print(x3)
4.7 特征降维
实际数据中,有时候特征很多,会增加计算量,降维就是去掉一些特征,或者转化多个特征为少量个特征
特征降维其目的:是减少数据集的维度,同时尽可能保留数据的重要信息。
特征降维的好处:
减少计算成本:在高维空间中处理数据可能非常耗时且计算密集。降维可以简化模型,降低训练时间和资源需求。
去除噪声:高维数据可能包含许多无关或冗余特征,这些特征可能引入噪声并导致过拟合。降维可以帮助去除这些不必要的特征。
特征降维的方式:
-
特征选择
-
从原始特征集中挑选出最相关的特征
-
-
主成份分析(PCA)
-
主成分分析就是把之前的特征通过一系列数学计算,形成新的特征,新的特征数量会小于之前特征数量
-
1 .特征选择
(a) VarianceThreshold 低方差过滤特征选择
-
Filter(过滤式): 主要探究特征本身特点, 特征与特征、特征与目标 值之间关联
-
方差选择法: 低方差特征过滤
如果一个特征的方差很小,说明这个特征的值在样本中几乎相同或变化不大,包含的信息量很少,模型很难通过该特征区分不同的对象,比如区分甜瓜子和咸瓜子还是蒜香瓜子,如果有一个特征是长度,这个特征相差不大可以去掉。
-
计算方差:对于每个特征,计算其在训练集中的方差(每个样本值与均值之差的平方,在求平均)。
-
设定阈值:选择一个方差阈值,任何低于这个阈值的特征都将被视为低方差特征。
-
过滤特征:移除所有方差低于设定阈值的特征
from sklearn.feature_selection import VarianceThreshold # 低方差过滤 tool=VarianceThreshold(threshold=1.5) #设置方差阈值,低于的被舍弃 x=[[10,2], [11,6], [10,8], [10,10], [10,19], [10,22], [10,28]] x=tool.fit_transform(x) print(x) # 第一列数据的方差低于方差阈值,从而被舍弃
-
-
(b) 根据相关系数的特征选择
<1>理论
正相关性(Positive Correlation)是指两个变量之间的一种统计关系,其中一个变量的增加通常伴随着另一个变量的增加,反之亦然。在正相关的关系中,两个变量的变化趋势是同向的。当我们说两个变量正相关时,意味着:
-
如果第一个变量增加,第二个变量也有很大的概率会增加。
-
同样,如果第一个变量减少,第二个变量也很可能会减少。
正相关性并不意味着一个变量的变化直接引起了另一个变量的变化,它仅仅指出了两个变量之间存在的一种统计上的关联性。这种关联性可以是因果关系,也可以是由第三个未观察到的变量引起的,或者是纯属巧合。
在数学上,正相关性通常用正值的相关系数来表示,这个值介于0和1之间。当相关系数等于1时,表示两个变量之间存在完美的正相关关系,即一个变量的值可以完全由另一个变量的值预测。
举个例子,假设我们观察到在一定范围内,一个人的身高与其体重呈正相关,这意味着在一般情况下,身高较高的人体重也会较重。但这并不意味着身高直接导致体重增加,而是可能由于营养、遗传、生活方式等因素共同作用的结果。
负相关性(Negative Correlation)与正相关性刚好相反,但是也说明相关,比如运动频率和BMI体重指数程负相关
不相关指两者的相关性很小,一个变量变化不会引起另外的变量变化,只是没有线性关系. 比如饭量和智商
皮尔逊相关系数(Pearson correlation coefficient)是一种度量两个变量之间线性相关性的统计量。它提供了两个变量间关系的方向(正相关或负相关)和强度的信息。皮尔逊相关系数的取值范围是 [−1,1],其中:

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 57
57 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)