关于MySQL索引底层数据结构与算法
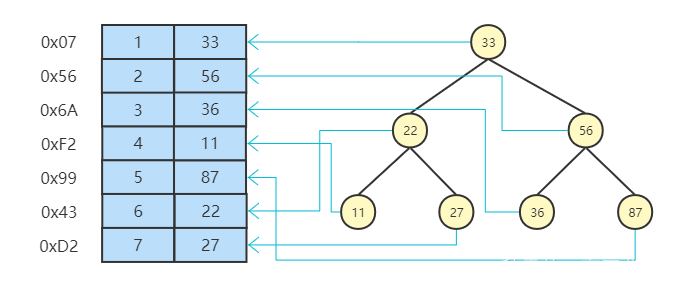
0x56为Alice对应的磁盘文件地址,例如查询name为Alice时,会先通过hash运算得到结果桶2,再去遍历桶2的链表,最终查询到Alice,包括所对应的磁盘文件地址。根据最左前缀原则,若比较大小会看比较name,若相等,则比较age,若再相等,则比较position,再根据叶子节点存储的主键进行回表查找对应的主键数据。③若不使用自增主键,则在加入新的数据时,可能会多次将数据插入到前面已经放
一、索引
概念
索引 是帮助 MySQL 高效获取数据的 排好序 的 数据结构
索引数据结构
- 二叉树
- 红黑树
- Hash 表
- B Tree
二叉树
二叉树的缺点是单边增长,对查找的效率并没有提升多少
红黑树
实现了自平衡的二叉排序树。
自平衡条件
- 节点是红色或黑色
- 根节点是黑色
- 所有叶子节点是黑色(叶子节点是NIL节点)
- 每个红节点的两个子节点都是黑色(从每个叶子到根的所有路径上不能有两个连续红节点)
- 从任意一个节点到其每个叶子节点所经历的简单路径上包含黑节点的个数相同(简称黑高)
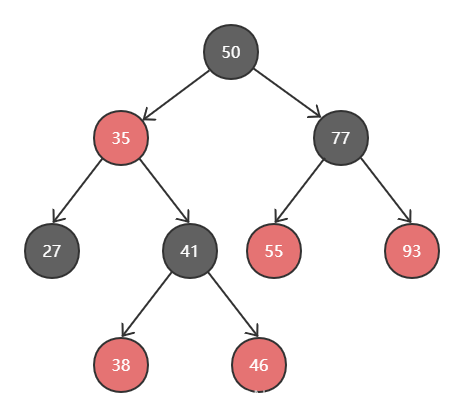
红黑树的缺点是数据量大的时候,对树的高度不可控,高度太高也会影响查询效率
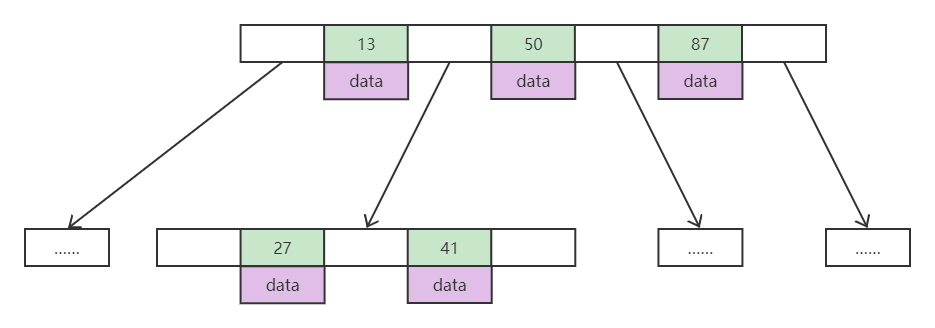
B Tree
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
B+Tree(B Tree变种)
InooDB 常用的索引方法。
- 非叶子节点不存储data(完整数据),只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
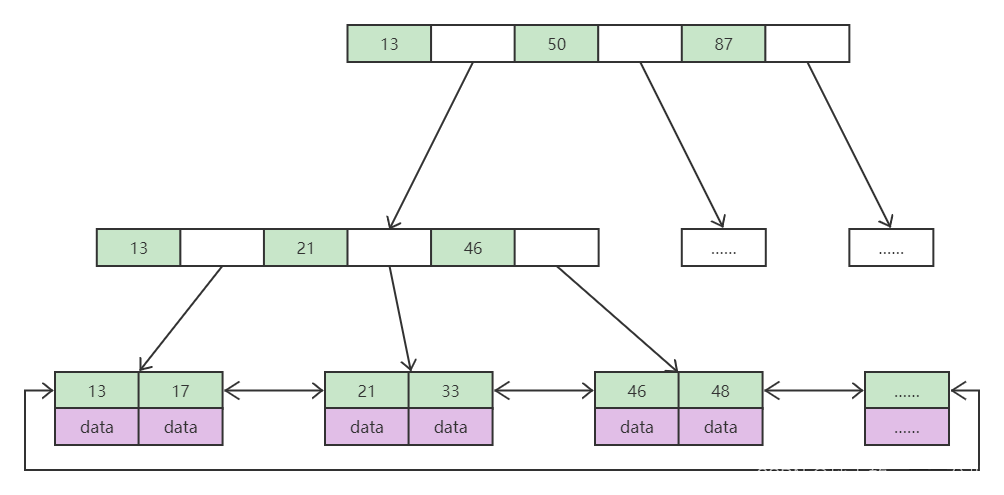
一排的节点称为 page(一页),一页的大小约为 16KB。
非叶子节点中,若索引为 bigint 类型,一条索引即 8 字节,存放的下一节点地址(即上图的空白格)再占 6 字节,可得一页 16KB 约可存储 1170 条索引。
叶子节点的一条索引加数据一般不会超过 1KB,因此叶子节点的一页约可存储 16 条索引加数据,因此当高度为 3 时,叶子节点可存放的所有元素约为 2 千多万(1170×1170×16),因此查找高度为 3 的任意元素只需查找 3 次。
相比之下若 B Tree 要存放 2 千多万元素,高度至少需要达到 6 到 7 层,效率远差于 B+Tree。
show global status like ‘Innodb_page_size’;
结果为 16384。
B+Tree 范围查询效率高:
- 先将根节点全部元素加载到 RAM(内存) 中,通过二分查找快速定位符合的范围;
- 再将范围内的下一节点全部元素加载到 RAM 中,再次快速定位;
- 以此类推,直到定位到满足要求的叶子节点上,由于叶子节点为递增排序,且依靠指针,因此可以快速查找到对应范围的数据,再根据其索引到磁盘上获取最终数据
相比之下若是 B Tree 的话,由于叶子节点不存在指针,因此超出范围时还需要重新从根节点出发再次查询。
Hash(一般不会选择使用hash索引)
InooDB 不常用的索引方法,一种自适应的优化机制,用于加速特定的查询。
优点
● 对索引的 key 进行一次 hash 计算就可以定位出数据存储的位置
● 很多时候 Hash 索引要比 B+Tree 索引更高效
缺点
- 仅能满足 “=”,“IN”,即等值查询,不支持范围查询
- hash 冲突问题
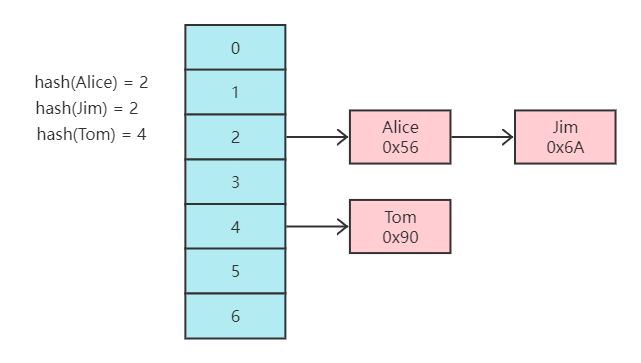
0x56 为 Alice 对应的磁盘文件地址,例如查询 name 为 Alice 时,会先通过 hash 运算得到结果桶 2,再去遍历桶 2 的链表,最终查询到 Alice,包括所对应的磁盘文件地址。
二、存储引擎
存储引擎是用来形容数据库的表。
MyISAM索引文件和数据文件是分离的(非聚簇)
数据存储在磁盘中,位于安装MySQL的路径下,例如:D:/mysql-5.6.33-win64/data
在磁盘中会生成三个文件:xxx.frm(表结构文件)、xxx.MYD(数据文件)、xxx.MYI(索引文件)
非聚簇索引:索引和数据存储在不同文件里
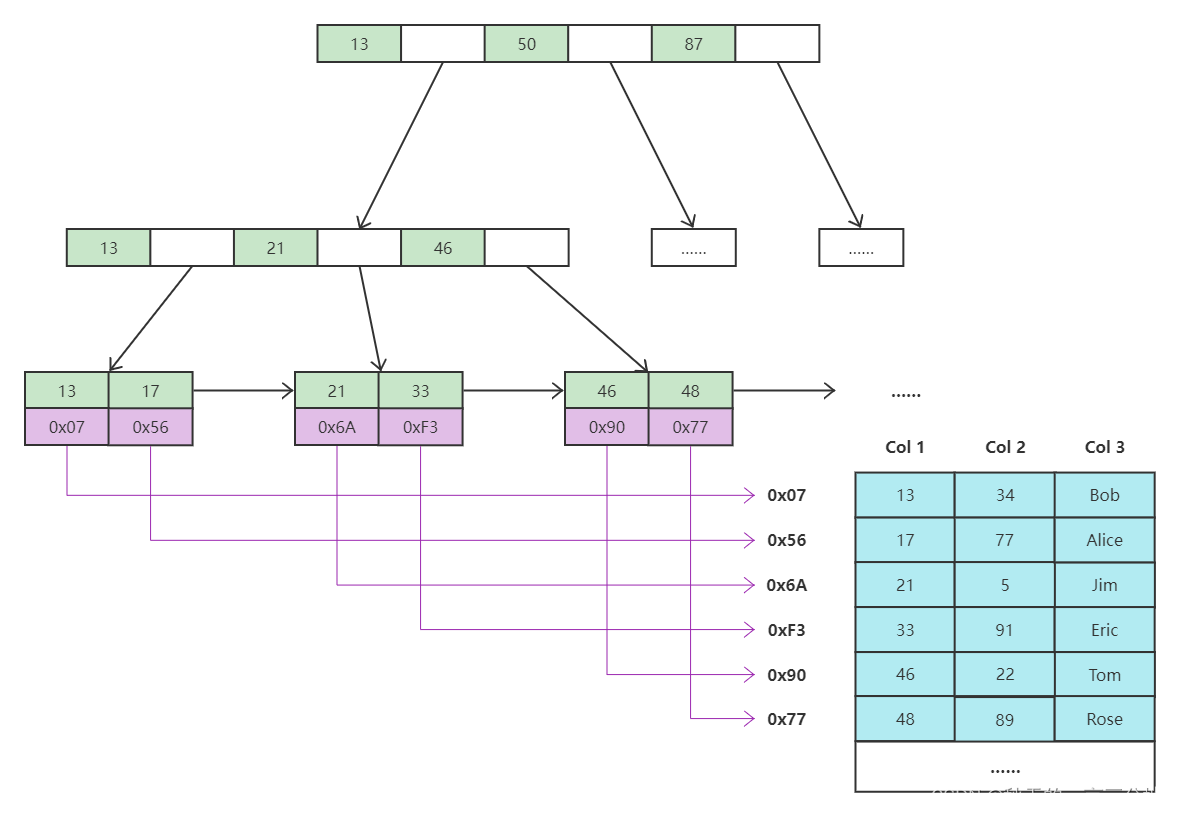
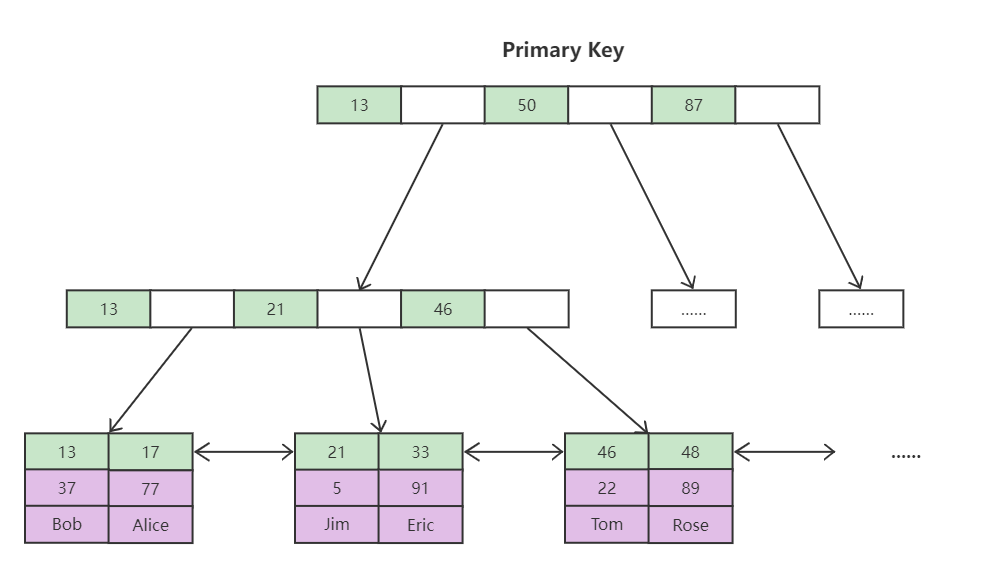
InnoDB索引实现(聚簇)
- 表数据文件本身就是按 B+Tree 组织的一个索引结构文件
- 聚簇索引(聚集索引):叶节点包含了完整的数据记录(都存储在 idb 文件里)
非聚簇索引结构叶子节点存储的是聚簇索引值
- 聚簇索引(聚集索引,大部分情况下也是主键索引),子节点存放聚簇索引,叶子节点存放具体数据,查询到则直接返回。
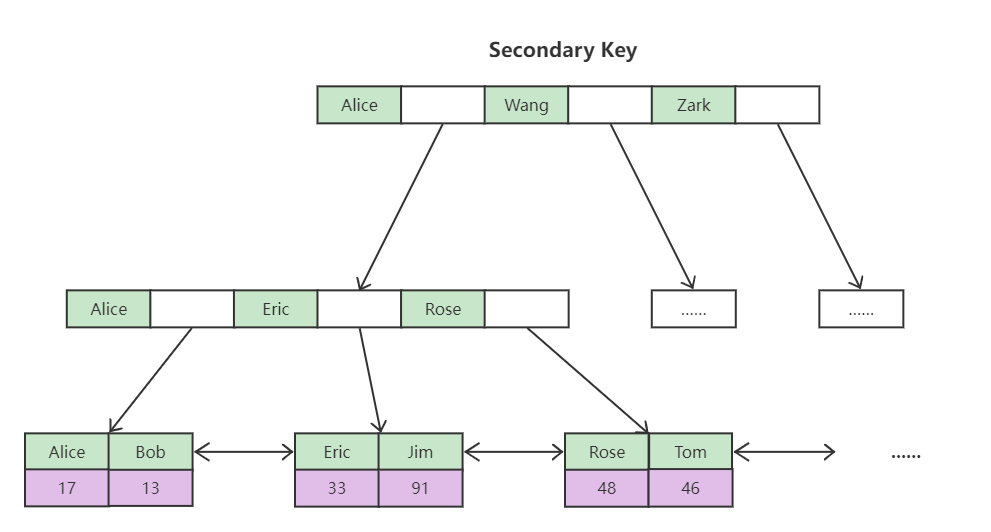
- 非聚簇索引(辅助索引/二级索引/非聚集索引/稀疏索引)的叶子节点存放的是聚簇索引值,原因:
- 操作过程中,完成聚簇索引的操作即可,非聚簇索引的增删操作不会影响数据的一致性
- 不需要重复存储相同的数据,节省存储空间
- 非聚簇索引进行查找时,叶子节点只存放聚簇索引值,再根据内存寻址查找到对应的数据,即回表操作。
在磁盘中会生成两个文件:xxx.frm(表结构文件)、xxx.ibd(表数据文件)
InnoDB表创建需要建主键,并且推荐使用整型的自增主键
①若不建主键,聚簇索引就无法对应成主键索引,会在创建表时,遍历每一列,选择其中为 唯一索引 且 不允许 null 的列作为聚簇索引,若不存在此列,则会自动创建一个隐藏列(rowId)作为聚簇索引进行维护,增加了数据库不必要的性能消耗。
②使用整型的主键,则在进行比较时效率最高,且占用内存最小。
③若不使用自增,则在加入新的数据时,可能会多次将数据插入到前面已经放满索引元素的节点,使其进行分裂调整,甚至会导致整棵树重新进行平衡,极大降低效率;使用自增则在每次加入新的数据时,都从末端插入数据,效率最高。
聚簇索引查询到获取数据的效率高于非聚簇索引
聚簇索引在单文件中即可完成查询与获取,而非聚簇索引需要跨文件获取数据(包括非聚簇索引的回表操作)。
索引最左前缀(左列)原则
联合索引(复合索引)底层存储结构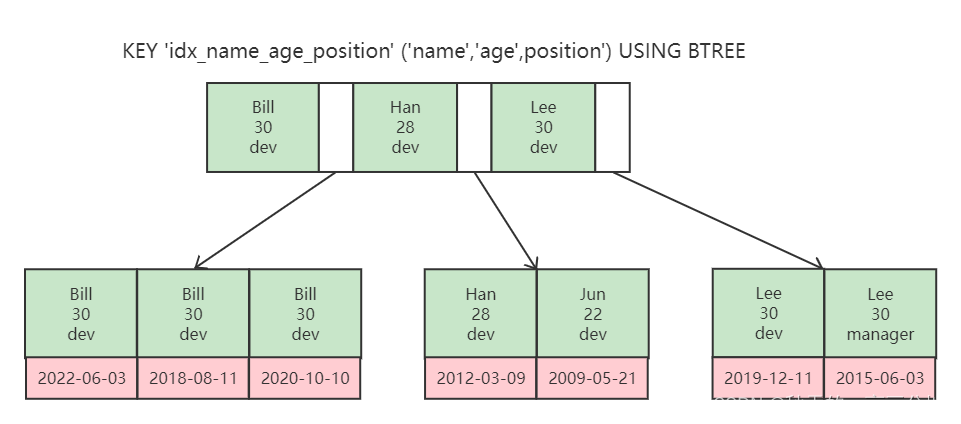
根据最左前缀原则,若比较大小会先比较 name,若相等,则比较 age,若再相等,则比较 position,再根据叶子节点存储的聚簇索引值进行回表查找对应的具体数据。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)