数据预处理-数据清洗(缺失值、重复值、异常值)
·
数据清洗
1、处理缺失值
2、处理重复值
3、处理异常值
4、文本数据清洗
数据处理
1、特征工程支持
2、数据格式标准化
3、数据合并与拆分
一、含义
1、处理缺失值
- 检测:自动识别数据中的空值、NaN、占位符(如"NULL"、“NA”)。
- 解决方案:
删除:直接删除含有缺失值的行或列。这种方法适用于缺失值较少且对整体数据分析影响不大的情况。
插值:根据其他样本的值估计缺失值。常用的插值方法包括均值插值、中位数插值、众数插值等。
使用默认值:为缺失值设定一个合理的默认值,如0、平均值或某个特定代码。
预测:根据数据的趋势预测缺失值。
2、处理重复值
- 检测:基于完整行或关键列(如ID)去重。
- 解决方案:
保留首行/末行:在存在重复行的情况下,选择保留每组重复行的首行或末行数据,并删除其余行。
自定义:根据业务需求,定义自定义方法来处理重复项,如合并重复项中的某些字段。
3、处理异常值
- 检测:
统计方法:通过计算数据的均值、标准差等统计量来判断哪些值偏离正常范围。例如,将超出均值±3倍标准差的值视为异常值。
可视化方法:利用箱线图、散点图等可视化工具直观地发现异常值。 - 解决方案:
修正(如截断到合理范围)。
可以删除异常值,或者将异常值替换为正常范围内的值(如均值、阈值或中位数)。
4、文本数据清洗
- 基础处理:
去除HTML标签、特殊字符、停用词、敏感词或无意义词。
正则表达式匹配替换(如邮箱、电话号码脱敏)。 - 高级功能:
拼写纠正、词干提取(英文)、分词(中文)。
情感符号/表情处理。
5、特征工程支持
- 数值特征:
归一化(Min-Max)、标准化(Z-score)。
分箱、对数变换。 - 分类特征:
处理类别不平衡(过采样/欠采样)。
稀有类别合并。
6、数据格式标准化
- 统一格式:日期时间(如YYYY-MM-DD)。文本(大小写、空格、缩写标准化)。数值(单位统一,如千克→克)。
- 类型转换:字符串转数值。
7、数据合并与拆分
- 将多个数据源的数据合并到一起,或者将一个数据集拆分成多个子集(如训练集、验证集和测试集)。
- 拆分数据时,可以根据比例(如 70% 训练集、15% 验证集、15% 测试集)随机拆分,也可以根据特定的条件(如时间顺序)进行拆分。
二、工具
-
工具:

-
地址:https://www.spsspro.com/analysis/index
1、导入本地数据

2、数据处理
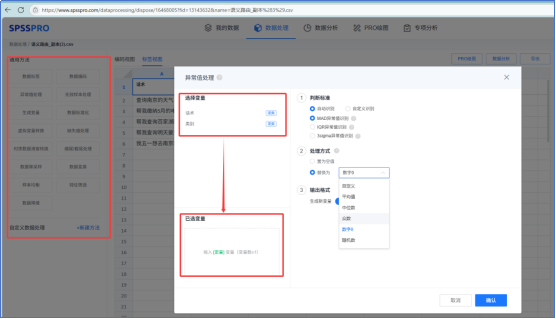
通用方法:异常值处理、无效样本处理、缺失值处理、样本均衡等;
自定义数据处理:编写代码,直接对数据处理。
- 通用方法
- 自定义算法
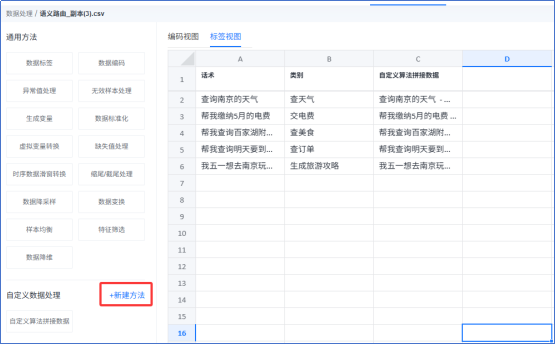
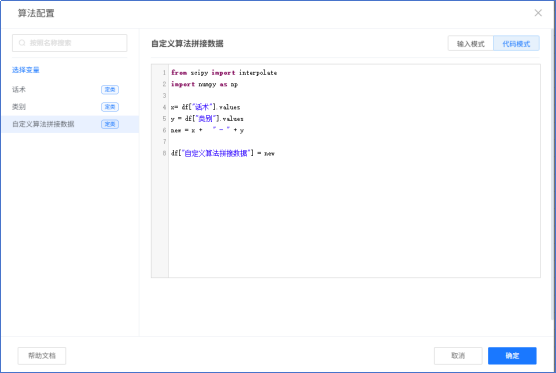
局限性:
1、限制导入文件的格式,只能导入Excel、CSV、SPSS等格式,无法导入TXT文件;
2、默认文件首行为表头;
3、通用方法主要是对数值型数据进行处理;
4、自定义方法需编写代码,对非技术用户不友好。
三、代码
from flask import Flask, request, jsonify
import pandas as pd
import numpy as np
import re
from sklearn.impute import SimpleImputer, KNNImputer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.model_selection import train_test_split
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
import jieba # 中文分词
from spellchecker import SpellChecker
import logging
from typing import Union, Dict, List
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
app = Flask(__name__)
logging.basicConfig(level=logging.INFO)
# 初始化工具
stemmer = PorterStemmer()
spell = SpellChecker()
# 获取停用词
try:
stop_words = set(stopwords.words('english'))
except:
import nltk
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
def convert_to_dataframe(data: Union[Dict, List[Dict]]) -> pd.DataFrame:
"""将输入数据转换为DataFrame"""
if isinstance(data, dict):
return pd.DataFrame([data])
elif isinstance(data, list):
return pd.DataFrame(data)
else:
raise ValueError("输入数据必须是字典或字典列表")
@app.route('/clean', methods=['POST'])
def data_cleaning():
try:
# 获取前端数据
input_data = request.json
df = convert_to_dataframe(input_data['data'])
operations = input_data.get('operations', {})
# 1. 处理缺失值
if operations.get('handle_missing'):
missing_config = operations['handle_missing']
# 首先识别占位符并转换为NaN
placeholders = missing_config.get('placeholders', ['NULL', 'NA', 'NaN', ''])
for col in df.columns: # 遍历列名
df[col] = df[col].replace(placeholders, np.nan)
strategy = missing_config.get('strategy', 'drop') # "mean"
if strategy == 'drop':
how = missing_config.get('how', 'any') # 'any'(默认):如果任何一个值是 NaN,就删除该行或列。 'all':只有全部值是 NaN 时才删除该行或列。
axis = missing_config.get('axis', 0) # axis 参数控制删除方向:0 或 'index'(默认):删除行;1 或 'columns':删除列
df = df.dropna(how=how, axis=axis)
elif strategy in ['mean', 'median', 'most_frequent', 'constant']: # 均值/中位数/众数/常量
imputer = SimpleImputer(
strategy=strategy,
fill_value=missing_config.get('fill_value') # fill_value(仅当 strategy='constant' 时有效),获取用户指定的填充值
)
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns) # fit:计算每列的均值/中位数/众数,transform:用计算出的值填充 NaN
elif strategy == 'knn': # 基于K近邻的插值
imputer = KNNImputer(n_neighbors=missing_config.get('n_neighbors', 5)) # n_neighbors指定用于计算插值的邻居数量
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)
# 2. 处理重复值
if operations.get('handle_duplicates'):
dup_config = operations['handle_duplicates']
subset = dup_config.get('subset', None) # None(默认):比较整行是否完全相同
keep = dup_config.get('keep', 'first') # 'first'(默认):保留第一条;'last':保留最后一条;False:删除所有重复行(只保留完全不重复的行)
df = df.drop_duplicates(subset=subset, keep=keep)
# 3. 处理异常值
if operations.get('handle_outliers'):
outlier_config = operations['handle_outliers']
method = outlier_config.get('method', 'zscore') # 异常值检测方法,默认 'zscore'(Z分数法),可选 'iqr'(IQR四分位距法)
columns = outlier_config.get('columns', df.select_dtypes(include=np.number).columns) # 默认自动选择所有数值型列(np.number 类型)
for col in columns:
if method == 'zscore': # Z-score(标准差法):数据点与均值的距离超过 threshold 倍标准差时,视为异常值。适用场景:数据近似服从正态分布时效果较好
mean = df[col].mean()
std = df[col].std()
threshold = outlier_config.get('threshold', 3)
lower, upper = mean - threshold * std, mean + threshold * std
elif method == 'iqr': # 异常值定义为低于 Q1 - 1.5*IQR 或高于 Q3 + 1.5*IQR 的值。适用于非正态分布数据,抗干扰性强。
Q1 = df[col].quantile(0.25) # 第一四分位数
Q3 = df[col].quantile(0.75) # 第三四分位数
IQR = Q3 - Q1 # 四分位距
lower, upper = Q1 - 1.5 * IQR, Q3 + 1.5 * IQR
action = outlier_config.get('action', 'clip') # 'clip'(默认):将异常值截断到边界值;'remove':直接删除包含异常值的行;'replace':用指定值替换异常值。
if action == 'clip':
df[col] = df[col].clip(lower, upper)
elif action == 'remove':
df = df[(df[col] >= lower) & (df[col] <= upper)]
elif action == 'replace':
replace_with = outlier_config.get('replace_with', 'mean')
if replace_with == 'mean':
replacement = df[col].mean()
elif replace_with == 'median':
replacement = df[col].median()
else:
replacement = replace_with
df.loc[(df[col] < lower) | (df[col] > upper), col] = replacement
# 4. 文本数据清洗
if operations.get('text_cleaning'):
text_config = operations['text_cleaning']
columns = text_config.get('columns', df.select_dtypes(include='object').columns) # 默认选择所有 object 类型的列(通常是字符串)。
for col in columns:
# 基础处理
if text_config.get('remove_html'):
df[col] = df[col].apply(lambda x: re.sub(r'<[^>]+>', '', str(x))) # 匹配所有HTML标签(如 <b>, </p>)
if text_config.get('remove_special_chars'):
df[col] = df[col].apply(lambda x: re.sub(r'[^\w\s]', '', str(x))) # 匹配所有非字母、数字、下划线或空格的字符
if text_config.get('lowercase'): # 转换为小写
df[col] = df[col].str.lower()
if text_config.get('remove_stopwords'): # 去除停用词
df[col] = df[col].apply(
lambda x: ' '.join([word for word in str(x).split() if word not in stop_words]))
if text_config.get('stemming') and text_config.get('language') == 'en': # 词干提取
df[col] = df[col].apply(lambda x: ' '.join([stemmer.stem(word) for word in str(x).split()])) # 将单词还原为词干形式(如 "running" → "run")
if text_config.get('spell_check'): # 拼写检查,纠正拼写错误(如 "helo" → "hello"),但可能误判专有名词或缩写。
df[col] = df[col].apply(lambda x: ' '.join([spell.correction(word) for word in str(x).split()]))
if text_config.get('chinese_segmentation') and text_config.get('language') == 'zh': # 中文分词,将连续的中文文本分割为词语
df[col] = df[col].apply(lambda x: ' '.join(jieba.cut(str(x))))
if text_config.get('desensitize'): # 敏感信息脱敏
# 邮箱脱敏
df[col] = df[col].apply(lambda x: re.sub(r'(\w+)(@\w+\.\w+)', r'*****\2', str(x))) # 匹配邮箱,替换为:*****@example.com(保留域名)
# 电话号码脱敏
df[col] = df[col].apply(lambda x: re.sub(r'(\d{3})\d{4}(\d{4})', r'\1****\2', str(x))) # 匹配11位手机号,替换保留前3位和后4位)
# 5. 特征工程
if operations.get('feature_engineering'):
fe_config = operations['feature_engineering']
# 数值特征处理
if fe_config.get('numeric_features'):
num_config = fe_config['numeric_features']
columns = num_config.get('columns', df.select_dtypes(include=np.number).columns) # 指定要处理的数值列,默认选择所有数值列。
# 归一化
if num_config.get('normalization') == 'minmax': # 最小-最大归一化,结果范围:[0, 1]
scaler = MinMaxScaler()
df[columns] = scaler.fit_transform(df[columns])
elif num_config.get('normalization') == 'zscore': # Z-score标准化,结果范围:均值为 0,标准差为 1
scaler = StandardScaler()
df[columns] = scaler.fit_transform(df[columns])
# 分箱,将连续数值离散化为若干个区间(如年龄分组)
if num_config.get('binning'):
for col, bins in num_config['binning'].items():
if col in df.columns:
df[col + '_binned'] = pd.cut(df[col], bins=bins, labels=False) # bins:分箱边界(如 [0, 18, 35, 60, 100]),labels=False:返回箱的编号(0, 1, 2...)
'''
示例:
输入:age = [15, 25, 45, 70]
分箱边界:[0, 18, 35, 60, 100]
输出:[0, 1, 2, 3](分别对应[0 - 18), [18 - 35), [35 - 60), [60 - 100))
'''
if num_config.get('log_transform'): # 对数变换
for col in num_config['log_transform']:
if col in df.columns:
df[col + '_log'] = np.log1p(df[col]) # log1p(x) = log(1 + x)(避免 x=0 时出错)
# 分类特征处理)
if fe_config.get('categorical_features'):
cat_config = fe_config['categorical_features']
columns = cat_config.get('columns', df.select_dtypes(include='object').columns)
# 稀有类别合并
if cat_config.get('rare_category_handling') == 'merge': # 将出现频率低于 threshold(默认5%)的类别合并为 'RARE',防止稀有类别导致过拟合。
threshold = cat_config.get('threshold', 0.05)
for col in columns:
value_counts = df[col].value_counts(normalize=True)
rare_categories = value_counts[value_counts < threshold].index
df[col] = df[col].replace(rare_categories, 'RARE')
# 类别不平衡处理
for col in columns:
if cat_config.get(f'{col}_balance') == 'oversample': # 过采样
ros = RandomOverSampler()
df, _ = ros.fit_resample(df, df[col]) # 对数据进行过采样,使每个类别的样本数量相同。
elif cat_config.get(f'{col}_balance') == 'undersample': # 欠采样
rus = RandomUnderSampler()
df, _ = rus.fit_resample(df, df[col]) # 对数据进行欠采样,使每个类别的样本数量相同。
'''
cat_config = {
'columns': ['category1', 'category2'],
'rare_category_handling': 'merge',
'threshold': 0.05,
'category1_balance': 'oversample',
'category2_balance': 'undersample'
}
'''
# 6. 数据格式标准化
if operations.get('standardize_format'):
format_config = operations['standardize_format']
# 将不同格式的日期统一转换为 YYYY-MM-DD 格式。
if format_config.get('date_columns'):
for col, fmt in format_config['date_columns'].items():
if col in df.columns:
df[col] = pd.to_datetime(df[col], format=fmt).dt.strftime('%Y-%m-%d') # col:日期列名; fmt:原始日期格式
# 文本数据标准化
if format_config.get('text_columns'):
for col, action in format_config['text_columns'].items():
if col in df.columns:
if action == 'lower': # 转换为小写
df[col] = df[col].str.lower()
elif action == 'upper': # 转换为大写
df[col] = df[col].str.upper()
elif action == 'strip': # 去除首尾空格
df[col] = df[col].str.strip()
# 数值单位转换
if format_config.get('numeric_conversion'):
for col, numeric in format_config['numeric_conversion'].items():
if col in df.columns: # 数值单位转换
df[col] = df[col] * float(numeric)
# 类型转换
if format_config.get('type_conversion'):
for col, unit in format_config['type_conversion'].items():
if col in df.columns: # 类型转换
df[col] = df[col].astype(unit)
# 7. 数据合并与拆分
if operations.get('split_data'):
split_config = operations['split_data']
if split_config.get('split_type') == 'random':
train_size = split_config.get('train_size', 0.7)
test_size = split_config.get('test_size', 0.15)
val_size = split_config.get('val_size', 0.15)
# 先拆分训练集和剩余集
train, remaining = train_test_split(df, train_size=train_size, random_state=42)
# 再拆分验证集和测试集
test_size_adjusted = test_size / (1 - train_size)
val, test = train_test_split(remaining, test_size=test_size_adjusted, random_state=42)
result = {
'train': train.to_dict(orient='records'),
'val': val.to_dict(orient='records'),
'test': test.to_dict(orient='records')
}
return jsonify({'status': 'success', 'result': result})
# 返回清洗后的数据
return jsonify({
'status': 'success',
'result': df.to_dict(orient='records')
})
except Exception as e:
logging.error(f"数据处理错误: {str(e)}")
return jsonify({
'status': 'error',
'message': str(e)
}), 400
if __name__ == '__main__':
app.run(debug=True)
'''
处理缺失值
{
"data": [
{"id": 1, "age": 25, "income": 50000, "email": "test1@example.com"},
{"id": 2, "age": null, "income": null, "email": "NULL"},
{"id": 3, "age": 30, "income": 60000, "email": "test3@example.com"}
],
"operations": {
"handle_missing": {
"placeholders": ["NULL", "NA", "NaN", ""],
"strategy": "mean",
"columns": ["age", "income"]
}
}
}
处理重复值
{
"data": [
{"id": 1, "name": "Alice", "score": 85},
{"id": 1, "name": "Alice", "score": 85},
{"id": 2, "name": "Bob", "score": 90}
],
"operations": {
"handle_duplicates": {
"subset": ["id"],
"keep": "first"
}
}
}
文本清洗
{
"data": [
{"id": 1, "comment": "This is a <b>great</b> product! I love it!!!"},
{"id": 2, "comment": "The service was TERRIBLE. Never again."}
],
"operations": {
"text_cleaning": {
"columns": ["comment"],
"remove_html": true,
"remove_special_chars": true,
"lowercase": true,
"remove_stopwords": true,
"stemming": true,
"language": "en"
}
}
}
数据拆分
{
"data": [
{"id": 1, "feature": 0.5, "label": 1},
{"id": 2, "feature": 0.8, "label": 1},
{"id": 3, "feature": 0.2, "label": 0},
{"id": 4, "feature": 0.4, "label": 0},
{"id": 5, "feature": 0.9, "label": 1}
],
"operations": {
"split_data": {
"split_type": "random",
"train_size": 0.6,
"test_size": 0.2,
"val_size": 0.2
}
}
}
'''

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)