IndexTTS:B站开源最强中文TTS模型
摘要:最近,基于大型语言模型(LLM)的文本到语音(TTS)系统因其高自然度和强大的零样本文本到语音克隆能力,逐渐成为行业的主流。在这里,我们介绍IndexTTS系统,该系统主要基于XTTS和Tortoise模型,并增加了一些新的改进。具体来说,在中文场景中,我们采用了一种结合字符和拼音的混合建模方法,使多音字和长尾字符的发音变得可控。我们还对声学语音标记的码本利用进行了矢量量化(VQ)与有限标量量化(FSQ)的对比分析。为了进一步增强语音克隆的效果和稳定性,我们引入了基于Conformer的语音条件编码器,并用BigVGAN2替换了语音码解码器。与XTTS相比,它在自然度、内容一致性和零样本语音克隆方面取得了显著改进。对于流行的开源TTS系统,如Fish-Speech、CosyVoice2、FireRedTTS和F5-TTS,IndexTTS具有相对简单的训练过程、更可控的使用方式以及更快的推理速度。此外,其性能也超过了这些系统。
一、背景动机
论文题目:IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System
论文地址:IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System
代码地址:https://github.com/index-tts/index-tts
基于LLM 的 TTS 系统因其高自然度和强大的零样本语音克隆能力逐渐成为行业主流。然而,现有的 TTS 系统在实际应用中仍存在下述问题:
- 多音字和长尾字符的发音控制:在中文场景中,多音字和低频字符的发音难以控制,这在视频创作等实际场景中是一个常见问题。
- 编码器的稳定性:传统的矢量量化(VQ)方法可能会导致编码器的“坍塌”,即某些量化码本的利用率极低。
- 推理效率:一些 TTS 系统(如基于扩散模型的系统 cosyvoice)虽然生成高质量语音,但推理速度慢,不适合实时应用。
为了解决这些问题,文章提出了 IndexTTS 系统,该系统基于 XTTS 和 Tortoise 模型,相较于目前开源的如Fish-Speech、CosyVoice2、FireRedTTS和F5-TTS,IndexTTS具有相对简单的训练过程、更可控的使用方式以及更快的推理速度。此外,其性能也超过了这些系统。
二、核心贡献
- 字符-拼音混合建模方法:在中文场景中,提出了一种字符和拼音混合的建模方法,允许用户通过直接输入拼音来纠正多音字的发音。
- 改进的语音编码器和解码器:引入基于 Conformer 的语音条件编码器,并用 BigVGAN2 替换了原有的语音码解码器,显著提高了语音克隆的自然度和稳定性。
- 高效的量化方法:对矢量量化(VQ)和有限标量量化(FSQ)进行了比较分析,实现了接近 100% 的码本利用率。
- 简化的训练过程和快速推理速度:与现有的开源 TTS 系统相比,IndexTTS 的训练过程更简单,推理速度更快,且性能更优。
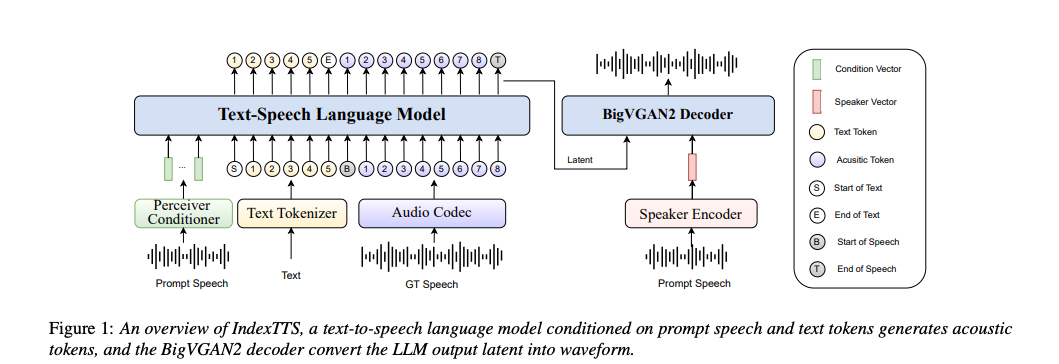
三、实现方法
3.1 系统架构
文本分词器(Text Tokenizer)
- 支持语言:目前系统支持中文和英文两种语言。
- 分词方式:直接使用原始文本作为输入,通过基于BPE(Byte Pair Encoding)的文本分词器进行分词。这种分词方式便于系统扩展到其他语言。
- 混合字符和拼音建模:针对中文场景,采用字符和拼音混合建模的方法。在训练时,随机将部分非多音字替换为拼音,使模型能够学习到正确的发音。例如,对于输入“晕眩是一种感觉”,可能会被替换为“晕 XUAN4 是 一 种 GAN3 觉”。

- 词汇表大小:文本分词器的词汇表大小为12,000,包括8,400个中文字符及其对应的1,721个拼音、英文词片段以及一些特殊符号。
神经语音分词器(Neural Speech Tokenizer)
-
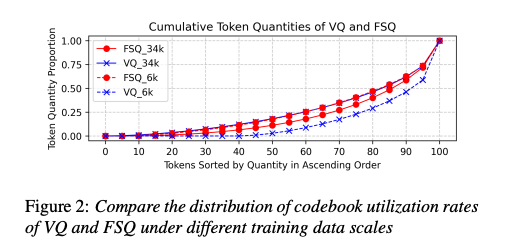
向量量化(VQ)与有限标量量化(FSQ):使用VQ或FSQ将音频信号转换为离散的声学标记。文章中对VQ和FSQ在码本利用率方面进行了比较分析,使用 6,000 小时训练数据时,VQ 的码本利用率仅为 55%,而 FSQ 接近 100%,使用 34,000 小时训练数据时,VQ 和 FSQ 的码本利用率接近,VQ 的利用率也可以达到 100%。
-
模型配置:使用变分自编码器(VAE)作为基础模型,参数量约为50M。VAE接收梅尔频谱图作为输入,并使用VQ或FSQ将其编码为大约8192个码本中的一个。输入音频的采样率为24kHz,语音分词器输出的标记速率为25Hz。
大语言模型(Large Language Model for TTS)
-
架构:基于仅解码器的Transformer架构,类似于XTTS。该模型从输入的文本标记序列生成一系列音频梅尔标记。
-
条件编码器:将基于Transformer的条件编码器替换为Conformer编码器,子采样率为2。这一替换可以增强音色相似性和训练稳定性。
-
输入序列结构:采用“speaker info, [BT], text, [ET], [BA], audio, [EA]”的形式,其中speaker info表示说话人的信息,[BT]和[ET]分别表示文本标记序列的开始和结束,[BA]和[EA]分别表示音频标记序列的开始和结束。这种结构不依赖提示文本,提高了跨语言语音克隆的可用性。
-
训练方式:在训练过程中,随机选择50%的训练样本,并随机将20%的中文字符替换为拼音。这样可以使模型在训练时学习到正确的发音。
语音解码器(Speech Decoder)
-
IndexTTS采用直接将语音编码器输出转换为最终的波形,其基于BigVGAN2声码器直接从语音编码器的输出重建音频。
-
语音编码器的输出基于说话人嵌入进行条件化,并直接输入到BigVGAN2声码器中。隐藏状态的采样率为25Hz,通过插值将其提升到100Hz,然后输入到BigVGAN2中。最终,BigVGAN2解码信号并以24kHz的频率输出。
3.2 训练数据
-
数据集:使用从互联网收集的120,000小时原始音频数据,经过语音分离、说话人分割和过滤后,得到34,000小时的高质量中英双语数据。其中,中文音频占25,000小时,英文音频占9,000小时。
-
伪标签生成:使用 ASR 为对应的音频生成伪标签。在ASR结果的基础上,根据文本语义和语音停顿添加标点符号,以创建最终的训练文本。这种方法允许用户灵活控制停顿,而不仅仅依赖于文本语义。
3.3 训练设置
- 字符和拼音混合训练:随机选择 50% 的训练样本,每个样本中随机选择 20% 的汉字,用对应的拼音替换。
- 语音编码器训练:用 FSQ 替换 VQ,其他模型配置保持不变。FSQ 的量化级别为 [8, 8, 8, 6, 5],VQ 码本维度为 512,包含 8192 个码。
- 评估设置:在四个测试集上评估 IndexTTS,包括 LibriSpeech、Aishell-1、CommonVoice 中文和英文测试集。使用 Paraformer ASR 识别中文测试集的合成结果,使用 Whisper-large V3 识别英文测试集的合成结果。
四、实验结论
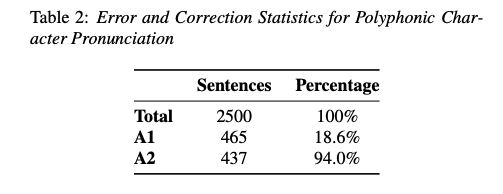
4.1 多音字的可控性
在包含多音字的2,500个句子的测试中,仅使用字符输入时,有18.6%的合成音频存在多音字发音错误。而在将正确的拼音作为混合输入后,94%的发音错误可以被准确纠正。
4.2 码本利用率
在6,000小时训练数据下,VQ的码本利用率仅为55%。当训练数据增加到34,000小时时,VQ和FSQ的码本利用率差异不大,VQ的利用率也能接近100%。
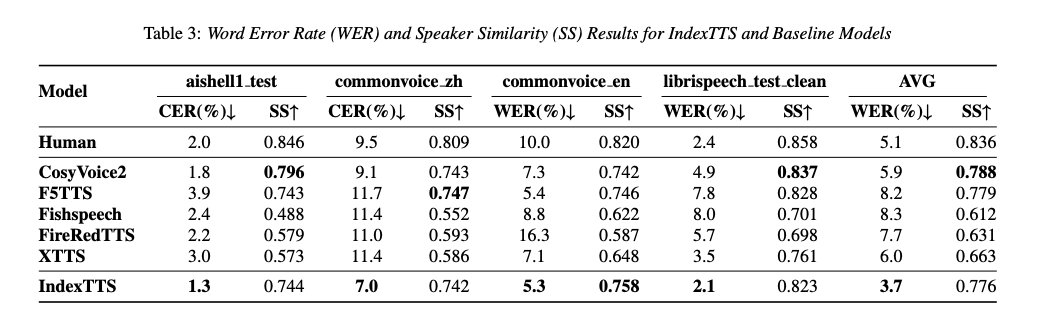
4.3 与基线模型的比较
-
客观评估:在四个测试集(Aishell-1、CommonVoice中文、CommonVoice英文、LibriSpeech测试集)上,IndexTTS在词错误率(WER)和说话人相似度(SS)方面均优于其他开源模型,如XTTS、CosyVoice2、FishSpeech、FireRedTTS和F5-TTS。
-
主观评估:在韵律、音色相似度和音质的平均意见得分(MOS)方面,IndexTTS在几乎所有评估维度上都优于基线模型,显示出在音色相似度和音质方面的显著优势。
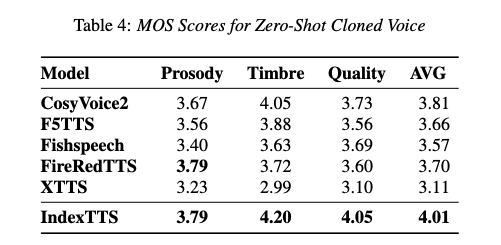
-
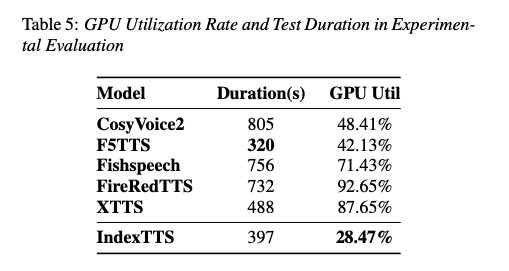
推理效率:在测试200个样本的合成时间和GPU资源消耗方面,IndexTTS的推理时间最短,GPU利用率最低,表现出较高的推理效率。
五、总结
文章提出的 IndexTTS 系统是一个基于 GPT 风格的零样本 TTS 模型,能够通过拼音纠正汉字发音,并通过标点符号控制停顿。该系统在多个模块上进行了改进,包括说话人条件特征表示的优化和 BigVGAN2 的集成,以提高音质。在数万小时的数据上训练后,IndexTTS 在性能上达到了行业领先水平,优于当前开源的 XTTS、CosyVoice2、Fish-Speech 和 F5-TTS 等 TTS 系统。
六、局限性
1、语言支持有限:目前仅支持中文和英文,未来计划扩展到更多语言。
2、情感表达不足:在丰富的情感表达方面能力有限,未来计划通过强化学习等方法增强情感复制能力。
3、非指令性语音生成:目前不支持指令性语音生成,未来计划增加这一功能。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 25
25 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)