【Pandas篇】纵横数据江湖:Pandas核心秘籍全解
本文系统拆解Pandas数据处理九大核心:从DataFrame/Series数据结构筑基,到索引操控、缺失值清洗的实战技法;详解数据合并、分组聚合高阶策略,结合链家房价分析、泰坦尼克生存预测双案例,演绎apply函数与时间序列的化形之术。附赠Pandas性能调优心法,助你5分钟突破数据清洗、转换、分析全链路瓶颈,打造结构化数据处理的「人剑合一」境界。文末开放论剑区,诚邀共探数据江湖疑难!
目录
引言
📊 数据操控如履薄冰?
✧ DataFrame与Series有何乾坤?
✧ 数据清洗如何化腐为奇?
✧ 分组聚合怎样一剑封喉?
✧ 时间序列迷雾如何拨云见日?
🚀 本文剑指结构化数据七重秘境:
▸ 数据结构双璧 → 索引操控绝学 → 缺失值破阵之道
▸ 合并连接兵法 → 分组聚合奥义 → 可视化降维打击
▸ 实战apply函数炼金术
💻 以「链家数据实战」为沙盘,复现泰坦尼克生存预测!文末附Pandas性能调优+数据规整秘籍,5分钟解锁高效数据处理流!
🌟 若代码跃然屏上,❤️⭐️📦三连助阵,数据江湖从此纵横无界!
一、环境配置与基础操作
1. 安装指南
# Windows/Mac通用安装命令
pip install pandas
# Mac系统备用命令
pip3 install pandas2. 标准导入方式
import pandas as pd # 行业标准简写二、Pandas数据结构
1. 介绍
Pandas(Panel Data的缩写)是一个开源的Python数据处理库,它提供了高性能、易用的数据结构和数据分析工具,用于处理和分析结构化数据。
Pandas的核心数据结构是DataFrame和Series,它们使数据的清理、转换、分析和可视化变得非常便捷。
图解 Series 与 DataFrame 的结构差异
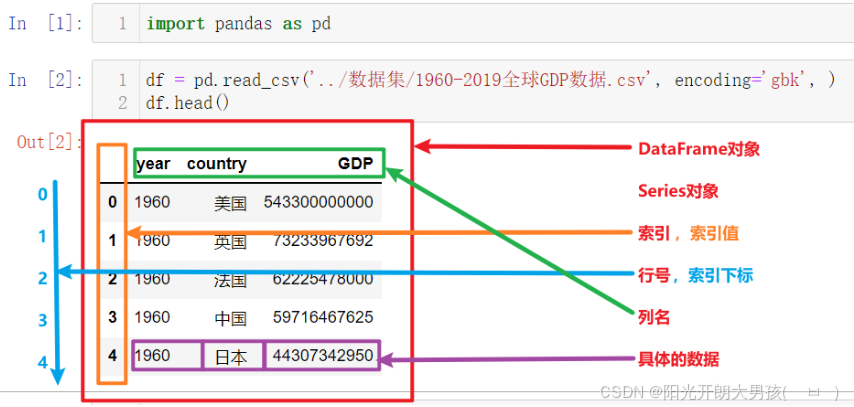
-
DataFrame
可以把DataFrame看作由Series对象组成的字典,其中key是列名,值是Series
-
Series
Series和Python中的列表非常相似,但是它的每个元素的数据类型必须相同
注意:
Pandas中只有列 或者 二维表, 没有行的数据结构(即使是行的数据, 也会通过列的方式展示).
2. Series对象
Series是Pandas中的最基本的数据结构对象,也是DataFrame的列对象或者行对象,series本身也具有行索引。
Series是一种类似于一维数组的对象,由下面两个部分组成:
- values:一组数据(numpy.ndarray类型)
- index:相关的数据行索引标签;如果没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。
(1)通过numpy创建
numpy的ndarray => Series对象
import numpy as np
import pandas as pd
# 创建numpy.ndarray对象
n1 = np.array([1, 2, 3])
print(n1)
print(type(n1))
# 将上述的 ndarray对象 转成 Series对象
s1 = pd.Series(data=n1)
print(s1)
print(type(s1))

(2)Python列表构建
直接传入Python列表
# 这种方式可以创建Series对象, 但是没有指定 行索引值, 默认是: 0 ~ n
# s2 = pd.Series(data=['乔峰', '男', 33])
s2 = pd.Series(['乔峰', '男', 33])
# data参数名可以省略不写. print(s2) print(type(s2))
# <class 'pandas.core.series.Series'>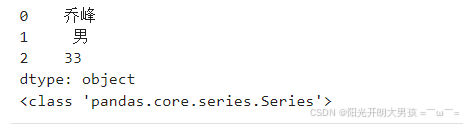
传入列表之后还能指定索引
# s3 = pd.Series(data=['乔峰', '男', 33], index=['name', 'gender', 'age']) # data参数名可以省略不写.
s3 = pd.Series(['乔峰', '男', 33], index=['name', 'gender', 'age']) # data参数名可以省略不写.
# s3 = pd.Series(['乔峰', '男', 33], ['name', 'gender', 'age']) # 参数名可以省略不写.
print(s3)
print(type(s3)) # <class 'pandas.core.series.Series'>
(3)元组和字典创建
# 使用元组
tuple1 = (1, 2, 3)
s1 = pd.Series(tuple1)
print(s1)
# 使用字典 字典中的key值是Series对象的索引值,value值是Series对象的数据值
dict1 = {'A': 1, 'B': 2, 'C': 3}
s2 = pd.Series(dict1)
print(s2)
3. DataFrame对象
DataFrame是一个表格型的==结构化==数据结构,它含有一组或多组有序的列(Series),每列可以是不同的值类型(数值、字符串、布尔值等)。
DataFrame是Pandas中的最基本的数据结构对象,简称df;可以认为df就是一个二维数据表,这个表有行有列有索引
DataFrame是Pandas中最基本的数据结构,Series的许多属性和方法在DataFrame中也一样适用.
(1)字典方式创建
# 1. 创建字典, 记录数据.
dict_data = {
'id': [1, 2, 3],
'name': ['乔峰', '虚竹', '段誉'],
'age': [33, 29, 21]
}
# 2. 基于上述的字典, 构建df对象.
# df1 = pd.DataFrame(dict_data)
# df1 = pd.DataFrame(dict_data, index=['A', 'B', 'C']) # 指定行索引
# index:指定行索引, columns:指定列名(的顺序), 如果写的列名不存在, 则该列值为 NaN
df1 = pd.DataFrame(dict_data, index=['A', 'B', 'C'], columns=['id', 'age', 'name'])
# 3. 打印结果.
print(df1)
print(type(df1)) # <class 'pandas.core.frame.DataFrame'>
(2)列表+元组方式创建
# 1. 基于列表 + 元组, 构建数据集. 一个元组 = 一行数据
list_data = [(1, '乔峰', 33), (2, '虚竹', 29), (3, '段誉', 21)]
# 2. 构建df对象.
# df2 = pd.DataFrame(list_data, index=['X', 'Y', 'Z'], columns=['id', 'age', 'name']) # 以行的方式传入数据, columns是设置: 列名.
df2 = pd.DataFrame(list_data, index=['X', 'Y', 'Z'], columns=['id', 'name', 'age']) # 以行的方式传入数据, columns是设置: 列名.
# 3. 打印结果.
print(df2)
print(type(df2))
三、Series常见操作
1. 常用属性
| 属性 | 说明 |
| loc | 使用索引值取子集 |
| iloc | 使用索引位置取子集 |
| dtype或dtypes | Series内容的类型 |
| T | Series的转置矩阵 |
| shape | 数据的维数 |
| size | Series中元素的数量 |
| values | Series的值 |
| index | Series的索引值 |
代码演示
# 1. 读取 nobel_prizes.csv 文件的内容, 获取df对象.
df = pd.read_csv('data/nobel_prizes.csv', index_col='id')
# index_col: 设置表中的某列为 索引列. df.head() # 默认获取前 5 条数据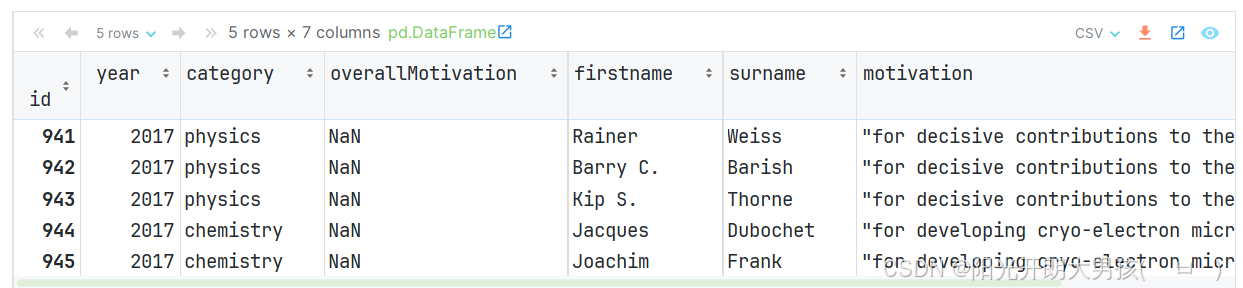 (1)loc属性
(1)loc属性
first_row = data.loc[941]
print(first_row) # 获取第一行数据, 但是是以列的方式展示的
print(type(first_row)) # <class 'pandas.core.series.Series'>
(2)iloc属性
first_row = data.iloc[0] # 使用索引位置获取自己
print(first_row) # 获取第一行数据, 但是是以列的方式展示的
print(type(first_row)) # <class 'pandas.core.series.Series'> (3)dtype 或者 dtypes
(3)dtype 或者 dtypes
print(first_row.dtype) # 打印Series的元素类型, object表示字符串
print(first_row['year'].dtype) # 打印Series的year列的元素类型, int64
# 打印Series的year列的元素类型, 该列值为字符串, 字符串没有dtype属性, 所以报错.
print(first_row['firstname'].dtype) 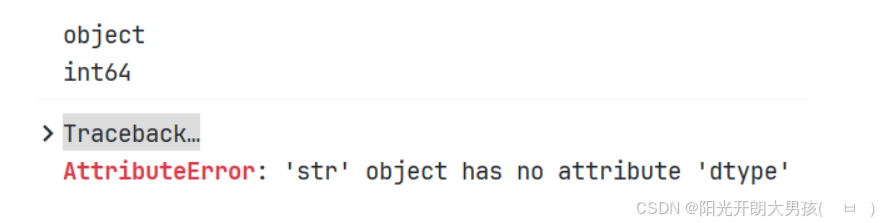 (4)shape 和 size属性
(4)shape 和 size属性
print(first_row.shape) # 维度
# 结果为: (7,) 因为有7列元素
print(first_row.size) # 元素个数: 7(5)values 属性
print(first_row.values) # 获取Series的元素值 (6)index属性
(6)index属性
print(first_row.index) # 获取Series的索引
print(first_row.keys()) # Series对象的keys()方法, 效果同上. 2. 常用方法
2. 常用方法
| 方法 | 说明 |
| append | 连接两个或多个Series |
| corr | 计算与另一个Series的相关系数 |
| cov | 计算与另一个Series的协方差 |
| describe | 计算常见统计量 |
| drop_duplicates | 返回去重之后的Series |
| equals | 判断两个Series是否相同 |
| get_values | 获取Series的值,作用与values属性相同 |
| hist | 绘制直方图 |
| isin | Series中是否包含某些值 |
| min | 返回最小值 |
| max | 返回最大值 |
| mean | 返回算术平均值 |
| median | 返回中位数 |
| mode | 返回众数 |
| quantile | 返回指定位置的分位数 |
| replace | 用指定值代替Series中的值 |
| sample | 返回Series的随机采样值 |
| sort_values | 对值进行排序 |
| to_frame | 把Series转换为DataFrame |
| unique | 去重返回数组 |
| value_counts | 统计不同值数量 |
| keys | 获取索引值 |
| head | 查看前5个值 |
| tail | 查看后5个值 |
代码演示
# 1. 构建Series对象.
s1 = pd.Series([1, 2, 3, 4, 2, 3], index=['A', 'B', 'C', 'D', 'E', 'F'])
print(s1)# 2. 演示Series对象的 常用方法.
print(len(s1)) # 长度: 6
print(s1.size) # 长度: 6
print(s1.head()) # 默认获取前 5 条
print(s1.head(n=2)) # 指定, 获取前2条
print(s1.tail()) # 默认获取后 5条
print(s1.tail(n=3)) # 指定, 获取后3条
print(s1.keys()) # 获取Series的索引
print(s1.index) # 获取Series的索引
print(s1.tolist()) # 转列表
print(s1.to_list()) # 效果同上
print(type(s1.tolist())) # <class 'list'>
print(s1.to_frame()) # 转成df对象
print(type(s1.to_frame())) # <class 'pandas.core.frame.DataFrame'>
print(s1.describe()) # 查看Series的详细信息, 例如: 最大值, 最小值, 平均值, 标准差等...
print(s1.max())
print(s1.min())
print(s1.mean())
print(s1.std()) # 标准差
print(s1.drop_duplicates()) # 去重, 返回Series对象
print(s1.unique()) # 去重, 返回数组, <class 'numpy.ndarray'>
print(s1.sort_values()) # 根据 值 排序, 默认: 升序(ascending=True)
print(s1.sort_values(ascending=False)) # 根据 值 排序, 降序
print(s1.sort_index()) # 根据 索引 排序, 默认: 升序
print(s1.sort_index(ascending=False)) # 根据 索引 排序, 降序
print(s1.value_counts()) # 统计每个值出现的次数, 类似于: SQL的 group by + count()
s1.hist() # 绘制: 直方图(柱状图)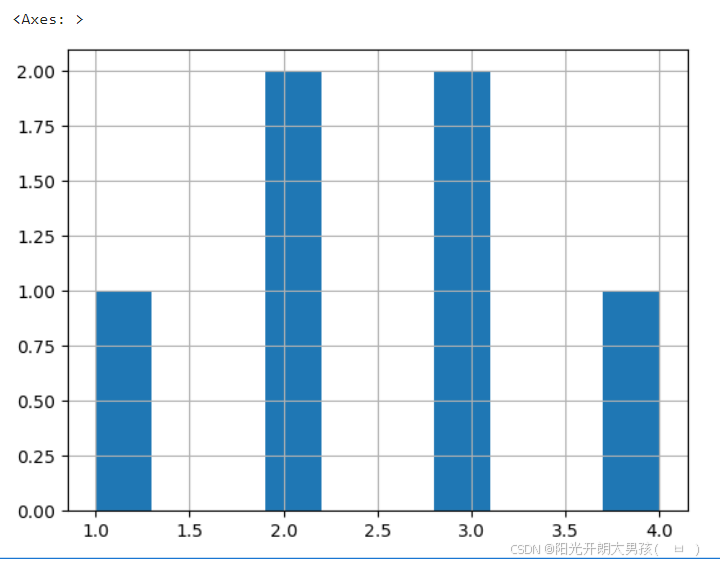 小案例: 电影数据
小案例: 电影数据
# 1. 加载数据源, 获取df对象.
movie_df = pd.read_csv('data/movie.csv')
movie_df.head()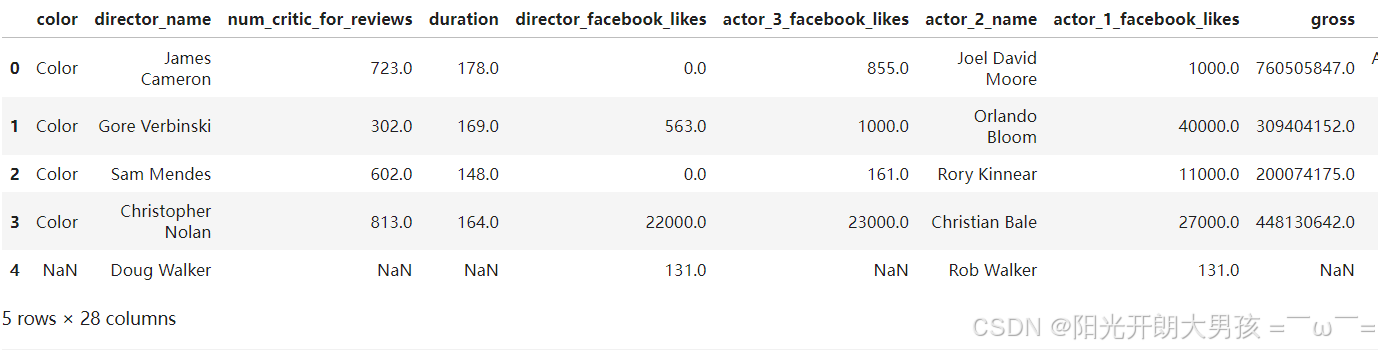
# 2. 从df对象中, 获取到 Seires对象.
# direcctor = movie_df.director_name # 获取: 导演名字
direcctor = movie_df['director_name'] # 效果同上.
print(direcctor)
actor_1_fb_likes = movie_df.actor_1_facebook_likes # 获取主演的facebook点赞数
print(actor_1_fb_likes)
# 3. 统计不同导演指导的电影数量, 即: 各导演的总数.
direcctor.value_counts()
# 4. 统计主演各个点赞数 数量. 即: 1000点赞有几个, 10000点赞有几个
# actor_1_fb_likes.value_counts()
# 5. 统计有多少空值.
# direcctor.count() # 4814, 统计所有的非空值
# direcctor.shape # (4916, ), 总量
len(direcctor.shape) # 4916# 6. 打印描述信息
# 查看描述信息, 例如: 最大值, 最小值, 平均值, 标准差...
actor_1_fb_likes.describe()
# 查看描述信息, 因为是: object(字符串类型), 所以信息没那么多.
direcctor.describe()
整合
# 加载电影数据
movie = pd.read_csv('data/movie.csv')
movie.head()
# 获取 导演名(列)
director = movie.director_name # 导演名
director = movie['director_name'] # 导演名, 效果同上
director
# 获取 主演在脸书的点赞数(列)
actor_1_fb_likes = movie.actor_1_facebook_likes # 主演在脸书的点赞数
actor_1_fb_likes.head()
# 统计相关
director.value_counts() # 不同导演的 电影数
director.count() # 统计非空值(即: 有导演名的电影, 共有多少), 4814
director.shape # 总数(包括null值), (4916,)
# 查看详情
actor_1_fb_likes.describe() # 显示主演在脸书点击量的详细信息: 总数,平均值,方差等...
director.describe() # 因为是字符串, 只显示部分统计信息3. Series的布尔索引
Series布尔索引通过布尔条件数组精准筛选目标数据,是高效处理复杂数据筛选需求的核心利器。
通过以下案例介绍
要求:从
scientists.csv数据集中,列出大于Age列的平均值的具体值,具体步骤如下:
加载并观察数据集
import pandas as pd
df = pd.read_csv('data/scientists.csv')
print(df)
# print(df.head())
# 输出结果如下
Name Born Died Age Occupation
0 Rosaline Franklin 1920-07-25 1958-04-16 37 Chemist
1 William Gosset 1876-06-13 1937-10-16 61 Statistician
2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse
3 Marie Curie 1867-11-07 1934-07-04 66 Chemist
4 Rachel Carson 1907-05-27 1964-04-14 56 Biologist
5 John Snow 1813-03-15 1858-06-16 45 Physician
6 Alan Turing 1912-06-23 1954-06-07 41 Computer Scientist
7 Johann Gauss 1777-04-30 1855-02-23 77 Mathematicia
# 演示下, 如何通过布尔值获取元素.
bool_values = [False, True, True, False, False, False, True, False]
df[bool_values]
# 输出结果如下
Name Born Died Age Occupation
1 William Gosset 1876-06-13 1937-10-16 61 Statistician
2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse
6 Alan Turing 1912-06-23 1954-06-07 41 Computer Scientist
基于条件的筛选
- 计算
Age列的平均值
# 获取一列数据 df[列名]
ages = df['Age']
print(ages)
print(type(ages))
print(ages.mean())
# 输出结果如下
0 37
1 61
2 90
3 66
4 56
5 45
6 41
7 77
Name: Age, dtype: int64
<class 'pandas.core.series.Series'>
59.125- 输出大于
Age列的平均值的具体值
print(ages[ages > ages.mean()])
# 输出结果如下
1 61
2 90
3 66
7 77
Name: Age, dtype: int64布尔数组直接筛选
# 上述格式, 可以用一行代码搞定, 具体如下
df[ages > avg_age] # 筛选(活的)年龄 大于 平均年龄的科学家信息
df[df['Age'] > df.Age.mean()] # 合并版写法.4. Series的运算
Series和数值型变量计算时,变量会与Series中的每个元素逐一进行计算;
两个Series之间计算时,索引值相同的元素之间会进行计算;索引值不同的元素的计算结果会用NaN值(缺失值)填充。
(1)Series和数值运算
数值会和Series的每个值进行运算.
ages_series + 10
ages_series * 2
(2)两个Series之间计算
长度一致时,按照对应的元素进行逐个计算
ages_series + ages_series
长度不一致时, 对应元素计算, 不匹配的元素用NaN填充
ages_series + pd.Series([1, 10])
- Series之间进行计算, 会尽可能依据 索引来计算, 即: 优先计算索引一样的数据.
# 1. 对 源数据(ages_series), 按照 年龄 降序排列, 获取新的Series对象.
rev_series = ages_series.sort_values(ascending=False)
rev_series
# 2. 查看原始Series对象
ages_series
# 3. 具体的计算过程
ages_series + rev_series
四、DataFrame常见操作
1. 常用属性
代码演示
import pandas as pd
# 加载数据集, 得到df对象
df = pd.read_csv('data/scientists.csv')
# 查看维度, 返回元组类型 -> (行数, 列数), 元素个数代表维度数
print(df.shape)
# 查看数据值个数, 行数*列数, NaN值也算
print(df.size)
# 查看数据值, 返回numpy的ndarray类型
print(df.values)
# 查看维度数
print(df.ndim)
# 返回列名和列数据类型
print(df.dtypes)
# 查看索引值, 返回索引值对象
print(df.index)
# 查看列名, 返回列名对象
print(df.columns)2. 常用方法
代码演示
import pandas as pd
# 加载数据集, 得到df对象
df = pd.read_csv('data/scientists.csv')
# 查看前5行数据
print(df.head())
# 查看后5行数据
print(df.tail())
# 查看df的基本信息
df.info()
# 查看df对象中所有数值列的描述统计信息
print(df.describe())
# 查看df对象中所有非数值列的描述统计信息
# exclude:不包含指定类型列
print(df.describe(exclude=['int', 'float']))
# 查看df对象中所有列的描述统计信息
# include:包含指定类型列, all代表所有类型
print(df.describe(include='all'))
# 查看df的行数
print(len(df))
# 查看df各列的最小值
print(df.min())
# 查看df各列的非空值个数
print(df.count())
# 查看df数值列的平均值
print(df.mean())3. 布尔索引
用上面的小案例介绍(电影数据)
# 小案例, 同上, 主演脸书点赞量 > 主演脸书平均点赞量的
movie[movie['actor_1_facebook_likes'] > movie['actor_1_facebook_likes'].mean()]
# df也支持索引操作
movie.head()[[True, True, False, True, False]]
3. DataFrame的运算
类似Series的运算(可以回到上面细看)
scientists * 2 # 每个元素, 分别和数值运算
scientists + scientists # 根据索引进行对应运算
scientists + scientists[:4] # 根据索引进行对应运算, 索引不匹配, 返回NAN4. DataFrame的索引操作
Pandas中99%关于DF和Series调整的API, 都会默认在副本上进行修改, 调用修改的方法后, 会把这个副本返回
这类API都有一个共同的参数: inplace, 默认值是False
如果把inplace的值改为True, 就会直接修改原来的数据, 此时这个方法就没有返回值
(1)设置索引
通过 set_index()函数 设置行索引名字
# 读取文件, 不指定索引, Pandas会自动加上从0开始的索引
movie = pd.read_csv('data/movie.csv')
movie.head()
# 设置 电影名 为索引列.
movie1 = movie.set_index('movie_title')
movie1.head()
# 如果加上 inplace=True, 则会修改原始的df对象
movie.set_index('movie_title', inplace=True)
movie.head() # 原始的数据并没有发生改变. 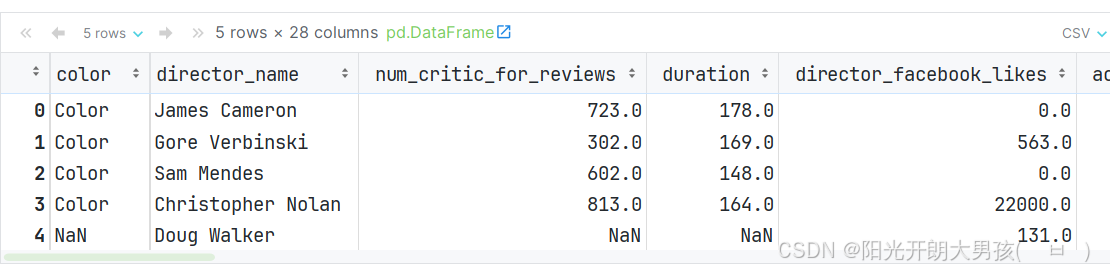
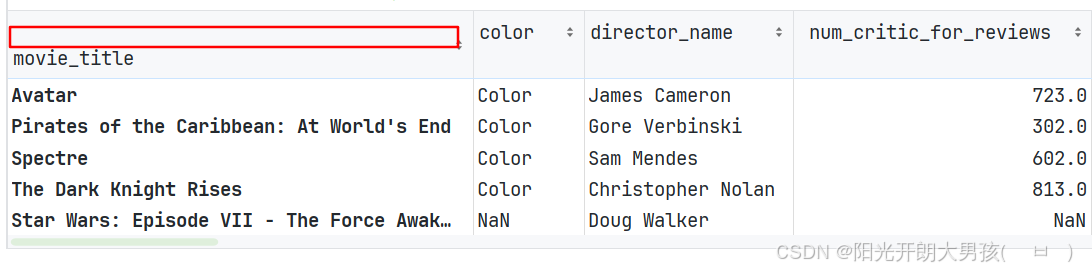
加载数据的时候, 直接指定索引列
# 1. 读取数据源文件, 获取 df对象, 指定 电影名为 行索引
movie2 = pd.read_csv('data/movie.csv', index_col='movie_title')
movie2.head()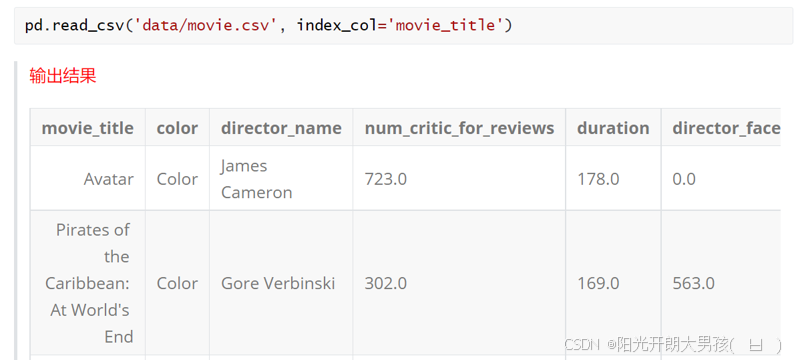
通过reset_index()函数, 可以重置索引
# 加上inplace, 就是直接修改 源数据.
movie.reset_index(inplace=True)
movie.head()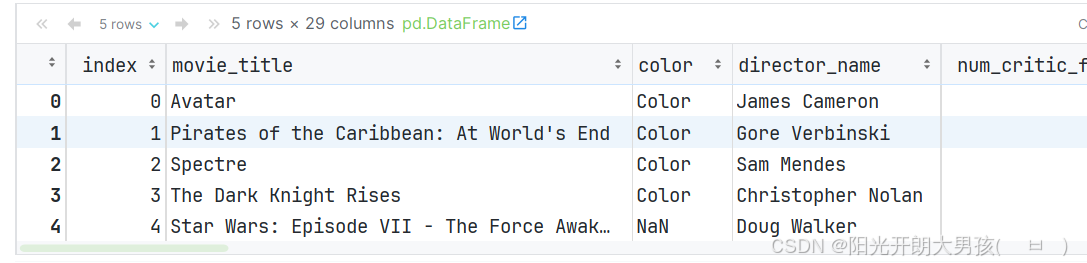 (2)修改行索引和列名
(2)修改行索引和列名
# 1. 读取数据源文件, 获取 df对象, 指定 电影名为 行索引
movie = pd.read_csv('data/movie.csv', index_col='movie_title')
movie.head()方式1:rename()函数直接修改
# 2. 获取 前5个列名, 方便稍后修改.
# ['Avatar', 'Pirates of the Caribbean: At World's End', 'Spectre', 'The Dark Knight Rises', 'Star Wars: Episode VII - The Force Awakens']
movie.index[:5]
# 3. 获取 前5个行索引值, 方便稍后修改.
movie.columns[:5] # ['color', 'director_name', 'num_critic_for_reviews', 'duration', 'director_facebook_likes']
# 4. 具体的修改 列名 和 行索引的动作.
idx_name = {'Avatar': '阿凡达', "Pirates of the Caribbean: At World's End": '加勒比海盗: 直到世界尽头'}
col_name = {'color': '颜色', 'director_name': '导演名'}
movie.rename(index=idx_name, columns=col_name, inplace=True)
# 5. 查看修改后的数据
movie.head()

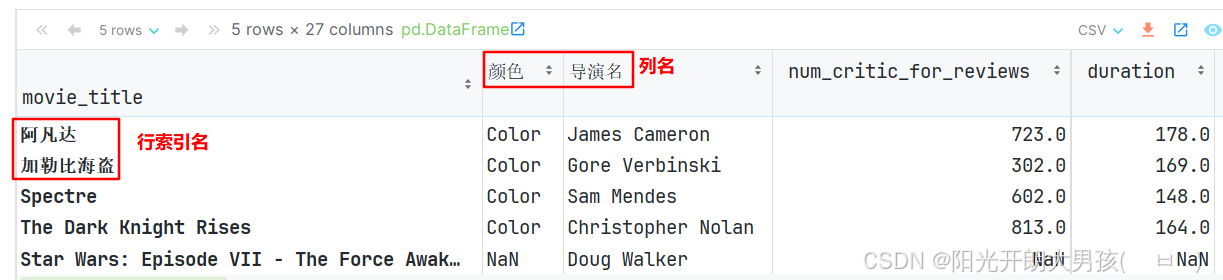
方式2:将 index 和 column属性提取出来, 修改之后, 再放回去
# 1. 从 df中获取 行索引 和 列名的信息, 并转成列表.
idx_list = movie.index.tolist() # 行索引信息, ['Avatar', "Pirates of the Caribbean: At World's End", 'Spectre', ...]
col_list = movie.columns.tolist() # 列名, ['color', 'director_name', 'num_critic_for_reviews', ...]
# 2. 修改上述的 列表(即: 行索引, 列名)信息.
idx_list[0] = '阿凡达'
idx_list[2] = '007幽灵'
col_list[0] = '颜色'
col_list[1] = '导演名'
# 3. 把上述修改后的内容, 当做新的 行索引 和 列名.
movie.index = idx_list
movie.columns = col_list
# 4. 查看结果.
movie.head()
(3)添加, 删除, 插入列
添加列
# 1. 添加列, 格式为: df['列名'] = 列值
# 新增1列, has_seen = 0, 表示是否看过这个电影. 0: 没看过, 1:看过
movie['has_seen'] = 0
# 新增1列, 总点赞量 = 导演 + 演员的 脸书点赞量
movie['director_actor_facebook_likes'] = movie['director_facebook_likes'] + movie['actor_3_facebook_likes'] + movie[
'actor_2_facebook_likes'] + movie['actor_1_facebook_likes']
# 2. 查看结果.
movie.head()
删除列或者行
# movie.drop('has_seen') # 报错, 需要指定方式, 按行删, 还是按列删.
# movie.drop('has_seen', axis='columns') # 按列删
# movie.drop('has_seen', axis=1) # 按列删, 这里的1表示: 列
movie.head().drop([0, 1]) # 按行索引删, 即: 删除索引为0和1的行
插入列
有点特殊, 没有inplace参数, 默认就是在原始df对象上做插入的.
# insert() 表示插入列.
#参数解释: loc:插入位置(从索引0开始计数), column=列名, value=值
# 总利润 = 总收入 - 总预算
movie.insert(loc=1, column='profit', value=movie['gross'] - movie['budget'])
movie.head()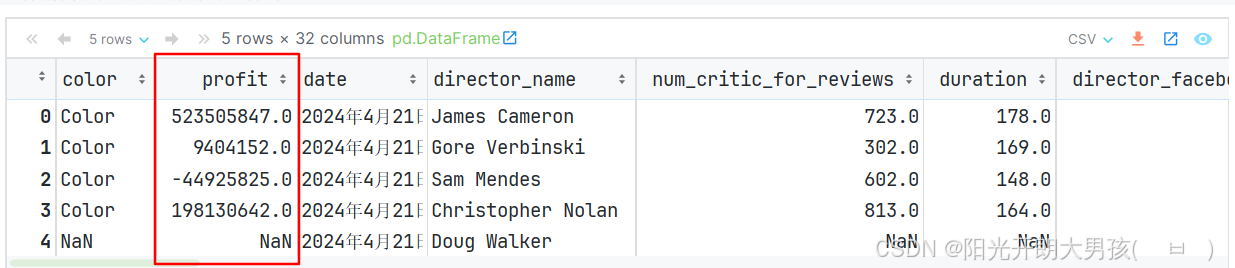
五、Pandas数据分析入门
1. 保存数据到文件
格式
df对象.to_数据格式(路径)
例如:
#df对象.to_数据格式(路径)
df.to_csv('data/abc.csv')
代码演示
如要保存的对象是计算的中间结果,或者以后会在Python中复用,推荐保存成pickle文件
如果保存成pickle文件,只能在python中使用, 文件的扩展名可以是
.p,.pkl,.pickl
# output文件夹必须存在
df.to_pickle('output/scientists.pickle') # 保存为 pickle文件
df.to_csv('output/scientists.csv') # 保存为 csv文件
df.to_excel('output/scientists.xlsx') # 保存为 Excel文件
df.to_excel('output/scientists_noindex.xlsx', index=False) # 保存为 Excel文件
df.to_csv('output/scientists_noindex.csv', index=False) # 保存为 Excel文件
df.to_csv('output/scientists_noindex.tsv', index=False, sep='\t')
print('保存成功')
注意:pandas读写excel需要额外安装如下三个包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlwt
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple openpyxl
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlrd
2. 读取文件数据
格式
pd对象.read_数据格式(路径)
例如:
#pd对象.read_数据格式(路径)
pd.read_csv('data/movie.csv')
代码演示
# pd.read_pickle('output/scientists.pickle') # 读取Pickle文件中的内容
# pd.read_excel('output/scientists.xlsx') # 多1个索引列
# pd.read_csv('output/scientists.csv') # 多1个索引列
pd.read_csv('output/scientists_noindex.csv') # 正常数据
3. 加载部分数据
做数据分析首先要加载数据,并查看其结构和内容,对数据有初步的了解,如:
- 查看行,列数据分布情况
- 查看每一列中存储信息的类型
回顾 DataFrame 和 Series概念
- Pandas是用于数据分析的开源Python库,可以实现数据加载,清洗,转换,统计处理,可视化等功能
- DataFrame和Series是Pandas最基本的两种数据结构
- DataFrame用来处理结构化数据(SQL数据表,Excel表格)
- Series用来处理单列数据,也可以把DataFrame看作由Series对象组成的字典或集合
(1)按列加载数据
代码演示
import pandas as pd
# 1. 加载数据
df = pd.read_csv('data/gapminder.tsv', sep='\t') # 指定切割符为\t
df.head()
# 2. # 查看df类型
type(df)
df.shape # (1704, 6)
df.columns # Index(['country', 'continent', 'year', 'lifeExp', 'pop', 'gdpPercap'], dtype='object')
df.index # RangeIndex(start=0, stop=1704, step=1)
df.dtypes # 查看df对象 每列的数据类型
df.info() # 查看df对象 详细信息
# 3. 加载一列数据
# country_series = df['country']
country_series = df.country # 效果同上
country_series.head() # 查看前5条数据
# 细节: 如果写 df['country'] 则是Series对象, 如果写 df[['country']]则是df对象
# 4. 加载多列数据
subset = df[['country', 'continent', 'year']] # df对象
print(subset.tail())
(2)按行加载数据
代码演示
# 1. 按行加载数据
df.head() # 获取前5条, 最左侧是一列行号, 也是 df的行索引, 即: Pandas默认使用行号作为 行索引.
# 2. 使用 tail()方法, 获取最后一行数据
df.tail(n=1)
# 3. 演示 iloc属性 和 loc属性的区别, loc属性写的是: 行索引值. iloc写的是行号.
df.tail(n=1).loc[1703]
df.tail(n=1).iloc[0] # 效果同上.
# 4. loc属性 传入行索引, 来获取df的部分数据(一行, 或多行)
df.loc[0] # 获取 行索引为 0的行
df.loc[99] # 获取 行索引为 99的行
df.loc[[0, 99, 999]] # loc属性, 根据行索引值, 获取多条数据.
# 5. 获取最后一条数据
# df.loc[-1] # 报错
df.iloc[-1] # 正确
(3)获取指定行/列数据
代码演示
# 1. 获取指定 行|列 数据
df.loc[[0, 1, 2], ['country', 'year', 'lifeExp']] # 行索引, 列名
df.iloc[[0, 1, 2], [0, 2, 3]] # 行索引, 列的编号
# 2. 使用loc 获取所有行的, 某些列
df.loc[:, ['year', 'pop']] # 获取所有行的 year 和 pop列数据
# 3. 使用 iloc 获取所有行的, 某些列
df.iloc[:, [2, 3, -1]] # 获取所有行的, 索引为: 2, 3 以及 最后1列数据
# 4. loc只接收 行列名, iloc只接收行列序号, 搞反了, 会报错.
# df.loc[:, [2, 3, -1]] # 报错
# df.iloc[:, ['country', 'continent']] # 报错
# 5. 也可以通过 range()生成序号, 结合 iloc 获取连续多列数据.
df.iloc[:, range(1, 5, 2)]
df.iloc[:, list(range(1, 5, 2))] # 把range()转成列表, 再传入, 也可以.
# 6. 在iloc中, 使用切片语法 获取 n列数据.
df.iloc[:, 3:5] # 获取列编号为 3 ~ 5 区间的数据, 包左不包右, 即: 只获取索引为3, 4列的数据.
df.iloc[:, 0:6:2] # 获取列编号为 0 ~ 6 区间, 步长为2的数据, 即: 只获取索引为0, 2, 4列的数据.
# 7. 使用loc 和 iloc 获取指定行, 指定列的数据.
df.loc[42, 'country'] # 行索引为42, 列名为:country 的数据
df.iloc[42, 0] # 行号为42, 列编号为: 0 的数据
# 8. 获取多行多列
df.iloc[[0, 1, 2], [0, 2, 3]] # 行号, 列的编号
df.loc[2:6, ['country', 'lifeExp', 'gdpPercap']] # 行索引, 列名 推荐用法.
4. 分组聚合计算
概述
- 在我们使用Excel或者SQL进行数据处理时,Excel和SQL都提供了基本的统计计算功能
- 当我们再次查看gapminder数据的时候,可以根据数据提出几个问题
- 每一年的平均预期寿命是多少?
- 每一年的平均人口和平均GDP是多少?
- 如果我们按照大洲来计算,每年个大洲的平均预期寿命,平均人口,平均GDP情况又如何?
- 在数据中,每个大洲列出了多少个国家和地区?
分组方式
- 对于上面提出的问题,需要进行分组-聚合计算
- 先将数据分组(每一年的平均预期寿命问题 按照年份将相同年份的数据分成一组)
- 对每组的数据再去进行统计计算如,求平均,求每组数据条目数(频数)等
- 再将每一组计算的结果合并起来
- 可以使用DataFrame的groupby方法完成分组/聚合计算
语法格式
df.groupby('分组字段')['要聚合的字段'].聚合函数()
df.groupby(['分组字段','分组字段2'])[['要聚合的字段','要聚合的字段2']].聚合函数()
分组后默认会把分组字段作为结果的行索引(index)
如果是多字段分组, 得到的是MultiIndex(复合索引), 此时可以通过reset_index() 把复合索引变成普通的列
例如:
df.groupby([‘year’, ‘continent’])[[‘lifeExp’, ‘gdpPercap’]].mean().reset_index()基本代码调用的过程
- 通过df.groupby(‘year’)先创一个分组对象
- 从分组之后的数据DataFrameGroupBy中,传入列名进行进一步计算返回结果为一个 SeriesGroupBy ,其内容是分组后的数据
- 对分组后的数据计算平均值
代码演示
# 1. 统计每年, 平均预期寿命
# SQL写法: select year, avg(lifeExp) from 表名 group by year;
df.groupby('year')['lifeExp'].mean()
# 2. 上述代码, 拆解介绍.
df.groupby('year') # 它是1个 DataFrameGroupBy df分组对象.
df.groupby('year')['lifeExp'] # 从df分组对象中提取的 SeriesGroupBy Series分组对象(即: 分组后的数据)
df.groupby('year')['lifeExp'].mean() # 对 Series分组对象(即: 分组后的数据), 具体求平均值的动作.
# 3. 对多列值, 进行分组聚合操作.
# 需求: 按照年, 大洲分组, 统计每年, 每个大洲的 平均预期寿命, 平均gdp
df.groupby(['year', 'continent'])[['lifeExp', 'gdpPercap']].mean()
# 4. 统计每个大洲, 列出了多少个国家和地区.
df.groupby('continent')['country'].value_counts() # 频数计算, 即: 每个洲, 每个国家和地区 出现了多少次.
df.groupby('continent')['country'].nunique() # 唯一值计数, 即: 每个大洲, 共有多少个国家和地区 参与统计.
5. Pandas-基本绘图
概述
- 可视化在数据分析的每个步骤中都非常重要
- 在理解或清理数据时,可视化有助于识别数据中的趋势
语法格式
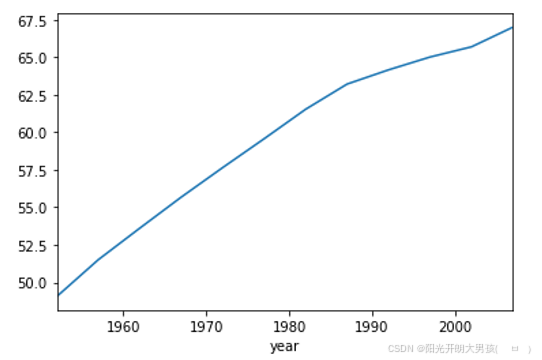
data = df.groupby('year')['lifeExp'].mean() # Series对象
data.plot() # 默认绘制的是: 折线图. 更复杂的绘图, 后续详解.
参考代码
6. Pandas-常用排序方法
| 方法 | 功能描述 | 示例代码 |
|---|---|---|
| sort_values() | 按列值排序 | df.sort_values('销量', ascending=False) |
| sort_index() | 按行/列索引排序 | df.sort_index(axis=1) (按列名排序) |
| nlargest() | 获取指定列最大的N个值 | df.nlargest(5, '销售额') |
| nsmallest() | 获取指定列最小的N个值 | df.nsmallest(3, '单价') |
| rank() | 计算数值排名(如第1名、第2名) | df['排名'] = df['销量'].rank(ascending=False) |
第1步: 加载并查看数据
import pandas as pd
# 1. 加载数据.
movie = pd.read_csv('data/movie.csv')
movie.head()
# 2. 查看数据字段说明.
movie.columns
# 3. 查看数据行列数
movie.shape # (4916, 28)
# 4. 统计数值列, 并进行转置.
movie.describe()
movie.describe().T # T表示转置操作, 即: 行列转换.
# 5. 统计对象 和 类型列
movie.describe(include='all') # 统计所有的列, 包括: 数值列, 类别类型, 字符串类型
movie.describe(include=object) # 类别类型, 字符串类型
# 6. 通过info() 方法了解不同字段的条目数量,数据类型,是否缺失及内存占用情况
movie.info()
第2步: 完整具体的需求
需求1:找到小成本, 高口碑电影. 即: 从最大的N个值中, 选取最小值.
# 需求1: 找到小成本, 高口碑电影.
# 即: 从最大的N个值中, 选取最小值.
# 1. 加载数据.
movie2 = movie[['movie_title', 'imdb_score', 'budget']] # 电影名, 电影评分, 成本(预算)
# nlargest(): 获取某个字段取值最大的前n条数据.
# nsmallest(): 获取某个字段取值最大的前n条数据.
# 2. 用 nlargest()方法, 选出 imdb_score 分数最高的100个数据.
movie2.nlargest(100, 'imdb_score')
# 3. 用 smallest()方法, 从上述数据中, 挑出预算最小的 5步电影.
movie2.nlargest(100, 'imdb_score').nsmallest(5, 'budget')
需求2: 找到每年imdb评分最高的电影
# 需求2: 找到每年imdb评分最高的电影
# 1. 获取数据.
movie3 = movie[['movie_title', 'title_year', 'imdb_score']] # 电影名, 上映年份, 电影评分
# 2. sort_values() 按照年排序.
movie3.sort_values('title_year', ascending=False).head() # 按年降序排列, 查看数据.
# 3. 同时对 title_year, imdb_score 两列进行排序.
# movie4 = movie3.sort_values(['title_year', 'imdb_score'], ascending=[False, False])
movie4 = movie3.sort_values(['title_year', 'imdb_score'], ascending=False) # 效果同上
movie4.head()
# 4. 用 drop_duplicates()去重, 只保留每年的第一条数据
# subset: 指定要考虑重复的列。
# keep: first/last/False 去重的时候, 保留第一条/保留最后一条/删除所有
movie4.drop_duplicates(subset='title_year').head()
7. Pandas案例-链家数据分析
准备数据
import pandas as pd
# 1. 加载数据
house_data = pd.read_csv('data/LJdata.csv')
# 2. 把列名替换为英文
# 2.1 查看原始列名
house_data.columns
# 2.2 替换原始列名.
house_data.columns = ['district', 'address', 'title', 'house_type', 'area', 'price', 'floor', 'build_time', 'direction', 'update_time', 'view_num', 'extra_info', 'link']
查看源数据
# 3. 查看数据
house_data.head() # 查看数据前 5 行
house_data.info() # 查看列数据 分布
house_data.describe() # 查看列统计指标
house_data.shape # 查看数据维度: (2760, 13)
完成具体需求
# 4. 需求1: 找到租金最低, 和租金最高的房子.
# 4.1 获取最低价格 和 最高价格. by:表示 根据哪列排序, ascending 表示升序或者降序
house_data.sort_values(by='price').head(1) # 1300元
house_data.sort_values(by='price').tail(1) # 210000元
# 4.2 查看具体的 租金最高 和 租金最低的房子.
house_data.loc[house_data['price'] == 210000]
house_data.loc[house_data['price'] == 1300]
# 5. 需求2: 找到最近新上的 10套房源.
house_data.sort_values(by='update_time', ascending=False).head(10)
# 6. 需求3: 查看所有更新时间.
house_data['update_time'].unique()
# 7. 需求4: 查看看房人数
house_data['view_num'].mean() # 平均值
house_data['view_num'].median() # 中位数
house_data.describe() # 可以查看上述值.
# 不同看房人数的房源数量, as_index=False 表示 分组字段不作为行索引(默认为True)
tmp_df = house_data.groupby('view_num', as_index=False)['district'].count()
tmp_df.columns = ['view_num', 'count']
tmp_df.head()
# 8. 需求5: 通过图表, 展示上述的数据.
tmp_df['count'].plot(kind='bar', figsize=(20,10)) # 柱状体, 宽, 高.
# 9. 需求6: 房租价格分布
house_data['price'].mean() # 平均值
house_data['price'].std() # 标准差
house_data['price'].median() # 中位数
# 10. 需求7: 看房人数最多的朝向.
popular_direction = house_data.groupby('direction', as_index=False)[['view_num']].sum()
house_data.groupby('direction', as_index=False)[['view_num']].max()
popular_direction[popular_direction['view_num'] == popular_direction['view_num'].max()]
# 11. 需求8: 房型分布情况.
# 设置正常显示汉字和负号
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示汉字
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# mac本设置如下
# plt.rcParams['font.family'] = 'Arial Unicode MS'
house_type_dis = house_data.groupby(['house_type']).count()
# %matplot inline
house_type_dis['district'].plot(kind='bar', figsize=(20, 10))
# 12. 需求9: 最受欢迎的房型.
tmp = house_data.groupby('house_type', as_index=False)['view_num'].sum()
tmp = house_data.groupby('house_type', as_index=False).agg({'view_num': 'sum'}) # 效果同上
tmp[tmp.view_num == tmp.view_num.max()]
# 13. 需求10: 房子的平均租房价格 (元/平米)
house_data.loc[:, 'price_per_m2'] = house_data['price'] / house_data['area']
house_data['price_per_m2'].mean()
# 14. 需求11: 热门小区
address_df = house_data[['address', 'view_num']].groupby(['address'], as_index=False).sum()
address_df.sort_values(by='view_num', ascending=False).head()
# 15. 需求12: 出租房源最多的小区.
tmp_df2 = house_data[['address', 'view_num']].groupby(['address'], as_index=False).count()
tmp_df2.columns = ['address', 'count']
tmp_df2.nlargest(columns = 'count', n = 1)六、Pandas数据组合
1. concat连接
概述
- 连接是指把某行或某列追加到数据中, 数据被分成了多份可以使用连接把数据拼接起来
- 把计算的结果追加到现有数据集,也可以使用连接
-
df对象与df对象拼接
行拼接参考: 列名, 列拼接参考: 行号
import pandas as pd # 1. 加载数据 df1 = pd.read_csv('data/concat_1.csv') df2 = pd.read_csv('data/concat_2.csv') df3 = pd.read_csv('data/concat_3.csv') # 2. 查看数据 df1 df2 df3 # 3. 通过concat()函数, 拼接上述的3个df对象. row_concat = pd.concat([df1, df2, df3]) # 默认是纵向拼接(行拼接), 结果为: 12行4列 row_concat = pd.concat([df1, df2, df3], axis='rows') # 效果同上 row_concat = pd.concat([df1, df2, df3], axis=0) # 效果同上, 0: 表示行, 1表示列. row_concat = pd.concat([df1, df2, df3], axis='columns') # 按列拼接, 4行12列 row_concat = pd.concat([df1, df2, df3], axis=1) # 效果同上, 0: 表示行, 1表示列. row_concat # 通过设置 ignore_case参数, 可以实现: 重置索引 # 行拼接, 重置索引, 结果为: 行索引变为 0 ~ n pd.concat([df1, df2, df3], ignore_index=True) # 列拼接, 重置索引, 结果为: 列名变为 0 ~ n pd.concat([df1, df2, df3], axis='columns', ignore_index=True) #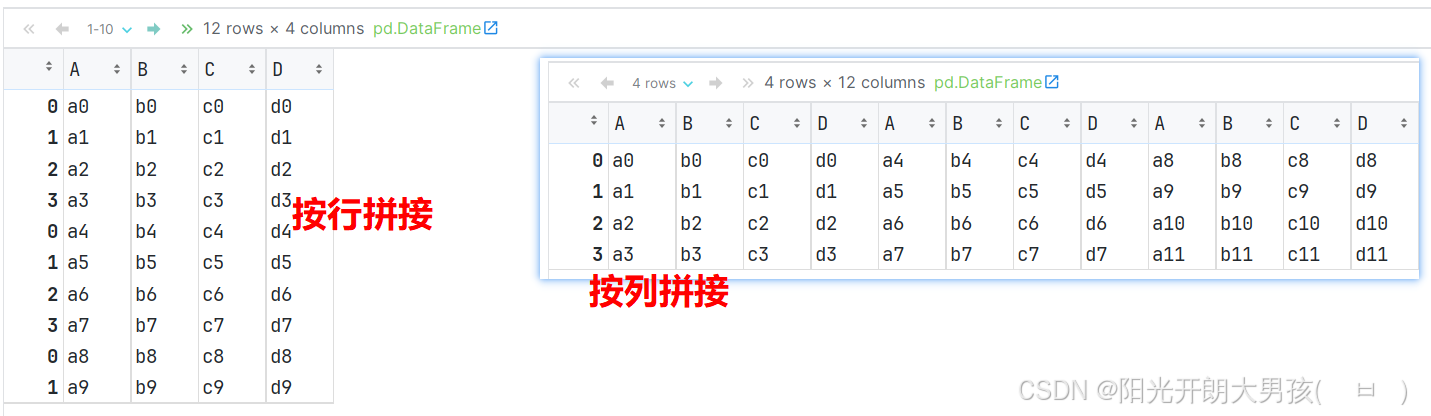
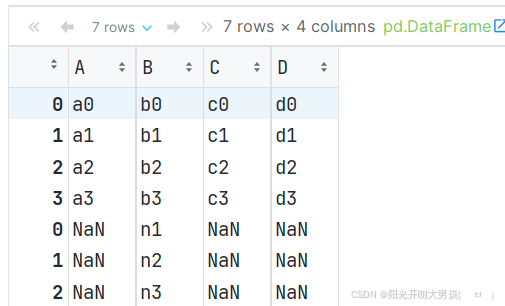
测试df按行拼接时, 参考: 列名
# 5. 自定义df对象, 设置列名, 然后拼接, 并观察结果.
df4 = pd.DataFrame(['n1', 'n2', 'n3'])
df4.columns = ['B'] # 加和不加该行, 观察效果.
pd.concat([df1, df4], axis=0) # 按行拼接, axis=0 可省略不写.
df对象和Series对象拼接
# 6. 使用concat连接 df 和 Series
new_series = pd.Series(['n1', 'n2', 'n3', 'n4'])
# 由于Series是列数据(没有行索引), concat()默认是添加行, 所以 它们拼接会新增一列. 缺值用NaN填充
pd.concat([df1, new_series], axis='rows') # 按行拼接
pd.concat([df1, new_series], axis=0) # 0: 行, 1: 列
pd.concat([df1, new_series], axis='columns') # 0: 行, 1: 列
pd.concat([df1, new_series], axis=1) # 0: 行, 1: 列
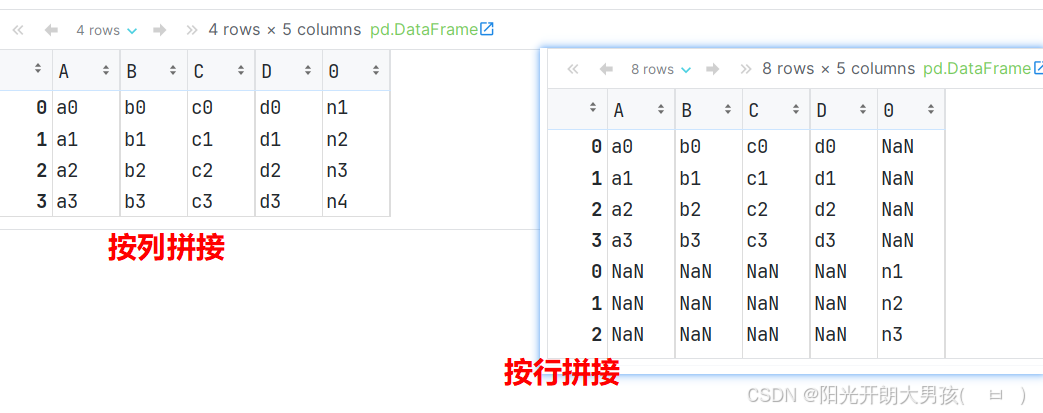
2. 添加行和列
如果想将[‘n1’,‘n2’,‘n3’,‘n4’]作为行连接到df1后,可以创建DataFrame并指定列名.
# 传入二维数组, 即: 1行4列数据.
df5 = pd.DataFrame([['n1', 'n2', 'n3', 'n4']], columns=['A', 'B', 'C', 'D'])
pd.concat([df1, df5])
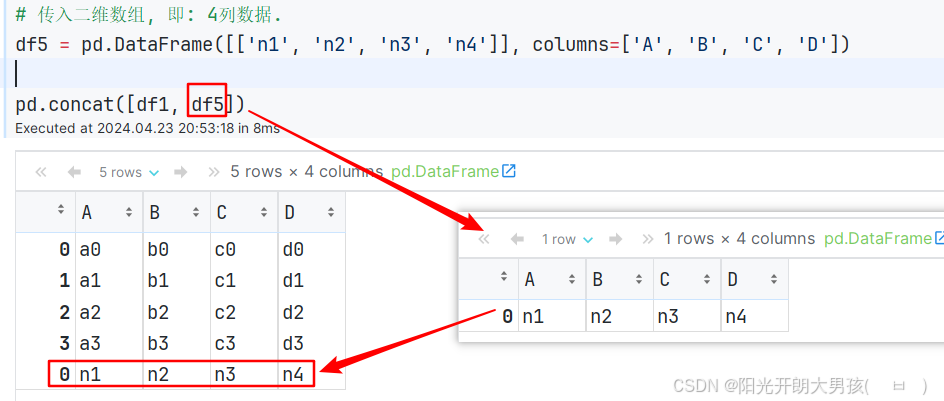
append函数演示
append()函数已过时, 它作用和concat()类似, 在新版的pandas中这个方法已经被删除了.
# concat可以连接多个对象, 例如: df1, df2, df3...
# 但如果只需要像现有的df对象, 添加1个对象, 可以使用 append()函数实现.
# 演示 append函数, 实现: 追加1个df对象 到 另1个df对象中.
df1.append(df2) # 只能行拼接, 且没有axis参数
# ignore_index: 忽略索引, 即: 索引会重置.
df1.append(df2, ignore_index=True)
# df对象 使用append追加一个字典时, 必须传入 ignore_index=True 参数
data_dict = {'A': 'n1', 'B': 'n2', 'C': 'n3'}
df1.append(data_dict, ignore_index=True)
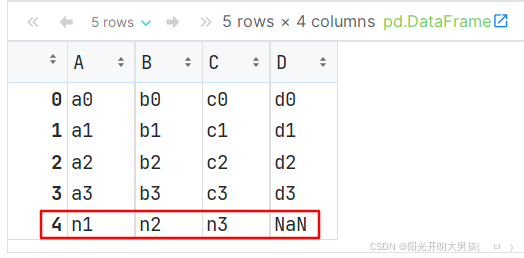
向DataFrame添加一列
# 方式1: 通过 df[列名] = [列值1, 列值2...] 的方式, 可以给 df添加列.
df1['new_col'] = ['n1', 'n2', 'n3', 'n4'] # 正确
# df1['new_col'] = ['n1', 'n2', 'n3', 'n4', 'n5'] # 报错, 值的个数 和 行数(4行)不匹配
# df1['new_col'] = ['n1', 'n2', 'n3'] # 报错, 值的个数 和 行数(4行)不匹配
df1
# 方式2: 通过 df[列名] = Series对象 的方式, 添加1列. # 值的个数和列的个数, 匹不匹配均可.
df1['new_col2'] = pd.Series(['n1', 'n2', 'n3'])
df1['new_col2'] = pd.Series(['n1', 'n2', 'n3', 'n4'])
df1['new_col2'] = pd.Series(['n1', 'n2', 'n3', 'n4', 'n5'])
df1
3. merge方式-一对一
概述
-
在使用concat连接数据时,涉及到了参数join(join = ‘inner’,join = ‘outer’)
-
数据库中可以依据共有数据把两个或者多个数据表组合起来,即join操作
-
DataFrame 也可以实现类似数据库的join操作
-
Pandas可以通过pd.join命令组合数据,
-
也可以通过pd.merge命令组合数据
merge更灵活,如果想依据行索引来合并DataFrame可以考虑使用join函数
-
-
配置PyCharm 连接 Sqlite, 步骤类似于: PyCharm连接MySQL
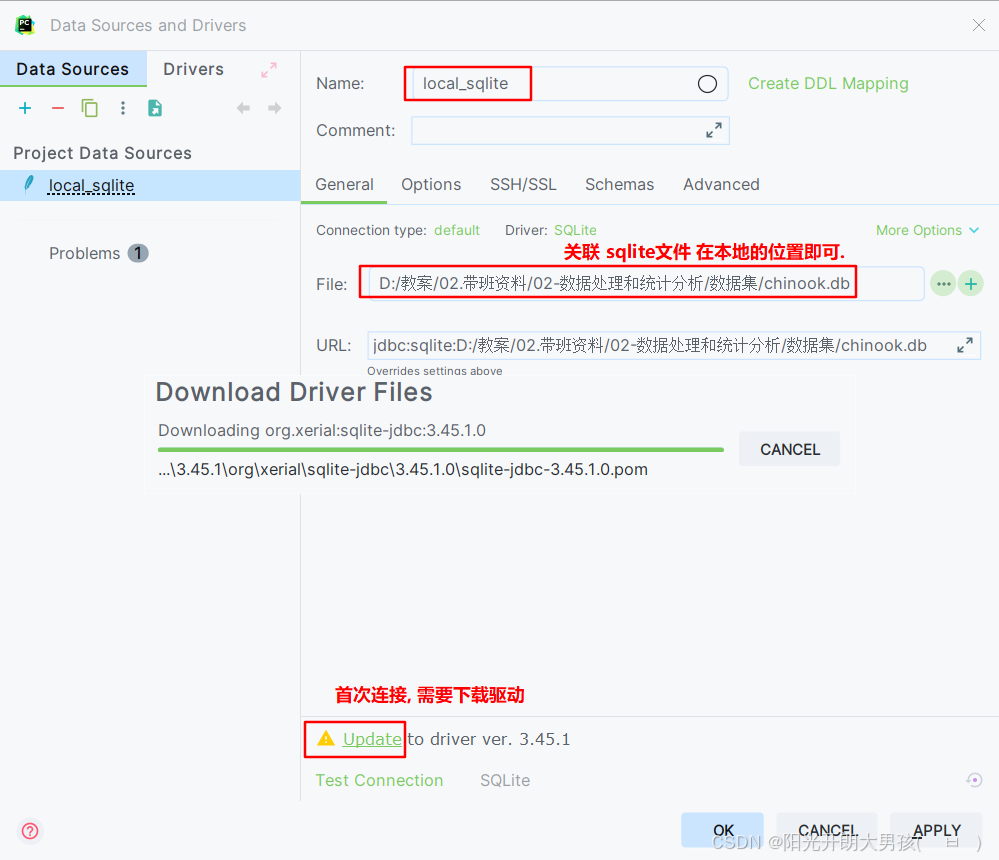
代码演示
准备数据
import sqlite3
# 1. 创建连接对象, 关联: Sqlite文件.
con = sqlite3.connect('data/chinook.db')
# 2. 读取SQL表数据, 参1: SQL语句, 参2: 连接对象
tracks = pd.read_sql_query('select * from tracks', con) # track: 歌曲表
# 3. 查看数据.
tracks.head()
# 4. read_sql_query()函数, 从数据库中读取表, 参1: SQL语句, 参2: 连接对象.
genres = pd.read_sql_query('select * from genres', con) #genre:(歌曲流派)歌曲类别表
genres.head() # 数据介绍, 列1: 风格id, 列2: 风格名(爵士乐, 金属...)
从歌曲表中, 抽取部分数据
# 5. 从track表(歌曲表)提取部分数据, 使其不含重复的'GenreID'值
tracks_subset = tracks.loc[[0, 62, 76, 98, 110, 193, 204, 281, 322, 359], ]
tracks_subset
一对一合并
# 歌曲分类表.merge(歌曲表子集的 歌曲id, 分类id, 歌曲时长) on表示关联字段, how表示连接方式
# left 类似于SQL的 左外连接, 即: 左表的全集 + 交集.
genre_track = genres.merge(tracks_subset[['TrackId', 'GenreId', 'Milliseconds']], on='GenreId', how='left')
# right 类似于SQL的 右外连接, 即: 右表的全集 + 交集.
genre_track = genres.merge(tracks_subset[['TrackId', 'GenreId', 'Milliseconds']], on='GenreId', how='right')
# outer 类似于SQL的 满外连接, 即: 左表的全集 + 右表全集 + 交集.
genre_track = genres.merge(tracks_subset[['TrackId', 'GenreId', 'Milliseconds']], on='GenreId', how='outer')
# inner 类似于SQL的 内连接, 即: 交集.
genre_track = genres.merge(tracks_subset[['TrackId', 'GenreId', 'Milliseconds']], on='GenreId', how='inner')
# 如果两张表有相同的列名, 则会分别给其加上 _x, _y的后缀, 来源于: merge()函数自带参数: suffixes, 如下代码, 加入 Name字段, 然后观察显示结果.
genre_track = genres.merge(tracks_subset[['TrackId', 'Name', 'GenreId', 'Milliseconds']], on='GenreId', how='inner')
genre_track
细节:
on 连接的字段, 如果左右两张表 连接的字段名字相同直接使用 on=‘关联字段名’
如果名字不同, left_on 写左表字段, right_on 写右表字段.
连接之后, 两张表中如果有相同名字的字段, 默认会加上后缀 默认值 _x, y
suffixes:(" x", “_ y”)
-
字段介绍

4. merge方式-多对一
需求: 计算每种类型音乐的 平均时长.
# 1. 获取连接数据, 本次是: tracks(歌曲表) 所有的数据
genre_track = genres.merge(tracks[['TrackId', 'GenreId', 'Milliseconds']], on='GenreId', how='left')
genre_track.head()
# 2. 转换时间单位.
# 需求1: 计算每种类型音乐的 平均时长.
# 2.1 根据 类型名分组, 统计时长 平均值即可.
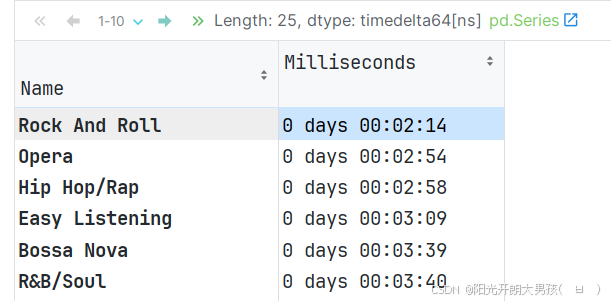
genre_time = genre_track.groupby('Name')['Milliseconds'].mean()
# 2.2 代码解释
# pd.to_timedelta(genre_time, unit='ms'): 把 genre_time 转成 timedelta 时间类型.
# dt.floor('s') 日期类型数据, 按指定单位截断数据, s 表示: 秒
pd.to_timedelta(genre_time, unit='ms').dt.floor('s').sort_values()
5. join方式
概述
- 使用join合并,可以是依据两个DataFrame的行索引,
- 或者一个DataFrame的行索引另一个DataFrame的列索引进行数据合并
代码演示
# 场景1: 依据两个DataFrame的行索引
# 如果合并的两个数据有相同的列名,需要通过lsuffix,和rsuffix,指定合并后的列名的后缀
stocks_2016.join(stocks_2017, lsuffix='_2016', rsuffix='_2017', how='outer') # 默认是: 左外连接.
# 场景2: 将两个DataFrame的Symbol设置为行索引,再次join数据
stocks_2016.set_index('Symbol').join(stocks_2018.set_index('Symbol'),lsuffix='_2016', rsuffix='_2018')
# 场景3: 将一个DataFrame的Symbol列设置为行索引,与另一个DataFrame的Symbol列进行join
stocks_2016.join(stocks_2018.set_index('Symbol'),lsuffix='_2016', rsuffix='_2018',on='Symbol')
# 回顾: merge(), concat() 也可以实现拼接.
stocks_2016.merge(stocks_2018, on='Symbol', how='left') # 左外连接
stocks_2016.merge(stocks_2018, on='Symbol', how='outer') # 满外连接

七、Pandas缺失值处理
1. 缺失值简介和判断
简介
好多数据集都含缺失数据。缺失数据有多重表现形式
- 数据库中,缺失数据表示为NULL
- 在某些编程语言中用NA表示
- 缺失值也可能是空字符串(’’)或数值
- 在Pandas中使用NaN表示缺失值
Pandas中的NaN值来自NumPy库,NumPy中缺失值有几种表示形式:
- NaN,NAN,nan,他们都一样
- 缺失值和其它类型的数据不同,它毫无意义,NaN不等于0,也不等于空串
数据中出现缺失值是很常见的
-
计算的过程中, 两个表join 可能会有缺失
-
原始的数据中也有可能直接带着缺失值
-
数据处理和模型训练的时候, 有很多场景要求必须先把缺失值处理掉,
-
想处理缺失值先要在数据中找到缺失值
代码演示
# 导包
import numpy as np
# 1. 缺失值不是 True, False, 空字符串, 0等, 它"毫无意义"
print(np.NaN == False)
print(np.NaN == True)
print(np.NaN == 0)
print(np.NaN == '')
# 2. np.nan np.NAN np.NaN 都是缺失值, 这个类型比较特殊, 不同通过 == 方式判断, 只能通过API
print(np.NaN == np.nan)
print(np.NaN == np.NAN)
print(np.nan == np.NAN)
# 3. Pandas 提供了 isnull() / isna()方法, 用于测试某个值是否为缺失值
import pandas as pd
print(pd.isnull(np.NaN)) # True
print(pd.isnull(np.nan)) # True
print(pd.isnull(np.NAN)) # True
print(pd.isna(np.NaN)) # True
print(pd.isna(np.nan)) # True
print(pd.isna(np.NAN)) # True
# isnull() / isna()方法 还可以判断数据.
print(pd.isnull(20)) # False
print(pd.isnull('abc')) # False
# 4. Pandas的notnull() / notna() 方法可以用于判断某个值是否为缺失值
print(pd.notnull(np.NaN)) # False
print(pd.notnull('abc')) # True
2. 加载缺失值
读取包含缺失值的数据
# 加载数据时可以通过keep_default_na 与 na_values 指定加载数据时的缺失值
pd.read_csv('data/survey_visited.csv')
# 加载数据,不包含默认缺失值,
# 参数解释: keep_default_na = False 表示加载数据时, 不加载缺失值.
pd.read_csv('data/survey_visited.csv', keep_default_na=False)
# 加载数据,手动指定缺失值, 例如: 指定619, 734为缺失值
# 参数解释: na_values=[值1, 值2...] 表示加载数据时, 设定哪些值为缺失值.
pd.read_csv('data/survey_visited.csv', na_values=['619', '734'], keep_default_na=False)
3. 缺失值可视化
代码演示
# 1. 加载数据
train = pd.read_csv('data/titanic_train.csv')
test = pd.read_csv('data/titanic_test.csv')
train.shape
train.head()
# 2. 查看是否获救数据.
train['Survived'].value_counts() # 0: 没获救. 1: 获救
# 3. 缺失值可视化(了解)
# 如果没有安装这个包, 需要先装一下.
# pip install missingnode
# 导包
import missingno as msno
# 柱状图, 展示: 每列的 非空值(即: 非缺失值)个数.
msno.bar(train)
# 绘制缺失值热力图, 发现缺失值之间是否有关联, 是不是A这一列缺失, B这一列也会缺失.
msno.heatmap(train)
表字段介绍

4. 非时序数据缺失值填充
删除缺失值
dropna()函数, 参数介绍如下:
subset=None 默认是: 删除有缺失值的行, 可以通过这个参数来指定, 哪些列有缺失值才会被删除
例如: subset = [‘Age’] 只有当年龄有缺失才会被删除
inplace=False 通用参数, 是否修改原始数据默认False
axis=0 通用参数 按行按列删除 默认行
how=‘any’ 只要有缺失就会删除 还可以传入’all’ 全部都是缺失值才会被删除
train.shape # 原始数据, 891行, 12列
# 方式1: 删除缺失值
# 删除缺失值会损失信息,并不推荐删除,当缺失数据占比较低的时候,可以尝试使用删除缺失值
# 按行删除: 删除包含缺失值的记录
# train.dropna().shape # 默认按行删(该行只要有空值, 就删除该行), 结果为: 183行, 12列
train.loc[:10].dropna() # 获取前11行数据, 删除包含空值的行.
# any: 只要有空值就删除该行|列, all: 该行|列 全为空才删除 subset: 参考哪些列的空值. inplace=True 在原表修改
train.dropna(subset=['Age'], how='any')
# 该列值只要有空, 就删除该列值.
train.dropna(how='any', axis=1) # 0(默认): 行, 1: 列
train.isnull().sum() # 快速计算是否包含缺失值
非时序数据填充
# 方式2: 填充缺失值, 填充缺失值是指用一个估算的值来去替代缺失数
# 场景1: 非时间序列数据, 可以使用常量来替换(默认值)
# 用 0 来填充 空值.
train.fillna(0)
# 查看填充后, 每列缺失值 情况.
train.fillna(0).isnull().sum()
# 需求: 用平均年龄, 来替换 年龄列的空值.
train['Age'].fillna(train['Age'].mean())
非时序数据的缺失值填充, 直接使用fillna(值, inplace=True)
- 可以使用统计量 众数 , 平均值, 中位数 …
- 也可以使用默认值来填充
5. 时序数据填充
代码演示
# 1. 加载时间序列数据,数据集为印度城市空气质量数据(2015-2020)
# parse_dates: 把某些列转成时间列.
# index_col: 设置指定列为 索引列
city_day = pd.read_csv('data/city_day.csv', parse_dates=['Date'], index_col='Date')
# 2. 查看缺失值情况.
city_day.isnull().sum()
# 3. 数据中有很多缺失值,比如 Xylene(二甲苯)和 PM10 有超过50%的缺失值
# 3.1 查看包含缺失数据的部分
city_day['Xylene'][50:64]
# 3.2 用固定值填充, 例如: 该列的平均值.
# 查看平均值.
city_day['Xylene'].mean() # 3.0701278234985114
# 用平均值来填充.
city_day.fillna(city_day['Xylene'].mean())[50:64]['Xylene']
# 3.3 使用ffill 填充,用时间序列中空值的上一个非空值填充
# NaN值的前一个非空值是0.81,可以看到所有的NaN都被填充为0.81
city_day.fillna(method='ffill')[50:64]['Xylene']
# 3.4 使用bfill填充,用时间序列中空值的下一个非空值填充
# NaN值的后一个非空值是209,可以看到所有的NaN都被填充为209
city_day.fillna(method='bfill')[50:64]['Xylene']
# 3.5 线性插值方法填充缺失值
# 时间序列数据,数据随着时间的变化可能会较大。使用bfill和ffill进行插补并不是解决缺失值问题的最优方案。
# 线性插值法是一种插补缺失值技术,它假定数据点之间存在线性关系,利用相邻数据点中的非缺失值来计算缺失数据点的值。
# 参数limit_direction: 表示线性填充时, 参考哪些值(forward: 向前, backward:向后, both:前后均参考)
city_day.interpolate(limit_direction="both")[50:64]['Xylene']
缺失值处理的套路
- 能不删就不删 , 如果某列数据, 有大量的缺失值(50% 以上是缺失值, 具体情况具体分析)
- 如果是类别型的, 可以考虑使用 ‘缺失’ 来进行填充
- 如果是数值型 可以用一些统计量 (均值/中位数/众数) 或者业务的默认值来填充
八、apply方法详解
1. Series的apply方法
概述
- 当Pandas自带的API不能满足需求, 例如: 我们需要遍历的对Series中的每一条数据/DataFrame中的一列或一行数据做相同的自定义处理, 就可以使用Apply自定义函数
- apply函数可以接收一个自定义函数, 可以将DataFrame的行/列数据传递给自定义函数处理
- apply函数类似于编写一个for循环, 遍历行/列的每一个元素,但比使用for循环效率高很多
-
代码演示
import pandas as pd # 1. 准备数据 df = pd.DataFrame({'a': [10, 20, 30], 'b': [20, 30, 40]}) df # 2. 创建1个自定义函数. def my_func(x): # 求平方 return x ** 2 def my_func2(x, e): # 求x的e次方 return x ** e # 3. apply方法有一个func参数, 把传入的函数应用于Series的每个元素 # 注意, 把 my_func 传递给apply的时候,不要加上小括号. df['a'].apply(my_func) # 传入函数对象. df['a'].apply(my_func2, e = 2) # 传入函数对象, e次幂(这里是平方) df['a'].apply(my_func2, e = 3) # 传入函数对象, e次幂(这里是立方)
2. DataFrame的apply方法
格式
df.apply(func, axis = )axis = 0 按列传递数据 传入一列数据(Series)
axis = 1 按行传递数据 传入一列数据(Series)
代码演示
# 1. 把上面创建的 my_func, 直接应用到整个DataFrame中
df.apply(my_func) # my_func函数会作用到 df对象的每一个值.
# 2. 报错, df对象是直接传入一列数据的, 并不是 一个值一个值传入的
def avg_3(x, y, z):
return (x + y + z) / 3
df.apply(avg_3)
# 3. 演示 df对象, 到底传入啥.
def my_func3(x):
print(x)
print(f'x的数据类型是: {type(x)}')
# 每次传入 1 列
# df.apply(my_func3, axis=0) # 0(默认): 列, 1: 行
# 每次传入 1 行
df.apply(my_func3, axis=1) # 0(默认): 列, 1: 行
3. apply应用练习
需求1: 计算泰坦尼克数据中, 每列的null值总数, 缺失值占比, 非缺失值占比
# 1. 加载数据
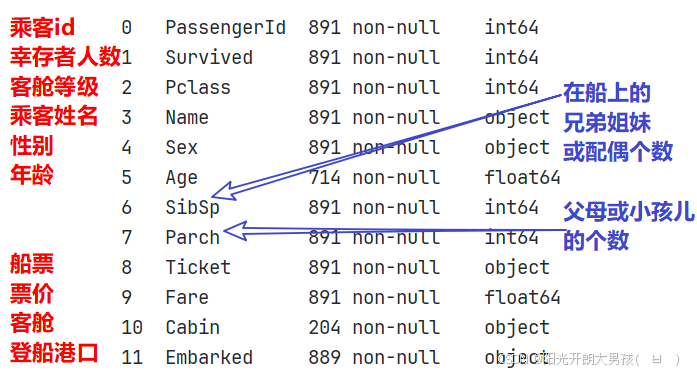
titanic = pd.read_csv('data/titanic_train.csv')
titanic.info()
# 2. 该数据集有891行,15列, 其中age 和 deck 两列中包含缺失值
# 2.1 定义函数, 计算: 数据中有多少null 或 NaN值
def count_missing(col):
# 计算一列中, 缺失值的个数.
return pd.isnull(col).sum()
# 2.2 缺失值占比
def prop_missing(col):
# 缺失值总数 / 该列数据总数
return count_missing(col) / col.size
# 2.3 非缺失值占比
def prop_complete(col):
# 缺失值总数 / 该列数据总数
return 1 - prop_missing(col)
# 3. 调用上述的函数.
titanic.apply(count_missing) # 不要加小括号, 传入的是: 函数对象.
titanic.apply(prop_missing) # 不要加小括号, 传入的是: 函数对象.
titanic.apply(prop_complete) # 不要加小括号, 传入的是: 函数对象.
需求2: 统计泰坦尼克 的数据中, 各年龄段总人数.
# 1. 定义函数, 实现把 年龄 转成 年龄段
def cut_age(age):
if age < 18:
return '未成年'
elif 18 <= age < 40:
return '青年'
elif 40 <= age < 60:
return '中年'
elif 60 <= age < 81:
return '老年'
else:
return '未知'
# 2. 调用上述的函数.
titanic['Age'].apply(cut_age)
# 3. 统计每个年龄段, 共有多少人.
titanic['Age'].apply(cut_age).value_counts()
需求3: 统计VIP 和 非VIP的客户总数
# 定义函数, 判断是否是VIP客户
# 条件: 乘客船舱等级为 1 并且 名字中带 'Master', 'Dr' 或者 'Sir'
def get_vip(x):
if x['Pclass'] == 1 and ('Master' in x['Name'] or 'Dr' in x['Name'] or 'Sir' in x['Name']):
return 'VIP'
else:
return 'Normal'
# axis = 1, 表示以行的方式传入.
titanic.apply(get_vip, axis=1).value_counts()九、Pandas日期类型处理
1. 日期时间类型简介
概述
- 和其它语言类似, Python内置了datetime对象,可以在datetime库中找到
- pandas的日期时间类型默认是 datetime64[ns]
-
Python中的-日期时间类型
实例代码
# 导包
from datetime import datetime # 这个是原生Python包的内容
import pandas as pd
# 场景1: 演示Python中的 日期时间类型
# 1. 获取当前时间
t1 = datetime.now()
t1 # datetime.datetime(2024, 4, 26, 20, 6, 8, 677626)
# 2. 可以手动设置日期.
t2 = datetime(2024, 5, 1)
t2 # datetime.datetime(2024, 5, 1, 0, 0)
# 3. 计算两个日期差.
t2 - t1 # datetime.timedelta(days=4, seconds=13935, microseconds=831597)
Pandas中的-日期时间类型
# 1. 加载: 疫情期间的 埃博拉数据.
ebola = pd.read_csv('data/country_timeseries.csv')
ebola.head()
# 2. 查看每列详情.
ebola.info() # 发现 Date是object(字符串类型)的
# 3. 把Date列转成 datetime类型的时间, 并添加到 ebola这个df对象中.
ebola['date_df'] = pd.to_datetime(ebola['Date'])
# 4. 再次查看 ebola 这个df对象的列信息.
# 发现 date_df列 是 datetime64[ns]日期类型(可以精确到纳秒, 准不准就是另一回事儿了)
ebola.info() # pandas 中默认的日期时间类型就是 datetime64[ns]
# 5. 也可以通过如下的函数, 直接封装日期时间类对象.
# 这个是: 日期时间戳 对象
pd.Timestamp(2024, 5, 1) # Timestamp('2024-05-01 00:00:00')
# 这个是: 日期时间 对象.
pd.datetime(2024, 5, 1) # datetime.datetime(2024, 5, 1, 0, 0), 结果是python的日期类型
# 6. pandas支持, 读取文件数据的时候, 把指定列转成日期列.
# 写列名 或者 写列的索引均可, 但是需要传入: 列表形式的数据, 因为可能要转换的列有多列.
ebola = pd.read_csv('data/country_timeseries.csv', parse_dates=['Date'])
# ebola = pd.read_csv('data/country_timeseries.csv', parse_dates=[0])
ebola.info()
2. 获取日期中不同部分
代码演示
# 1. 获取日期时间类型的 对象.
time_stamp = pd.to_datetime('2024-05-13') # 把字符串转成 Timestamp类型.
time_stamp # panda的日期时间类型(时间戳)
# 2. 获取年
time_stamp.year
time_stamp.month
time_stamp.day
time_stamp.dayofyear # 年中第几天
# 3. 获取埃博拉数据的年, 月, 日.
# .dt 是把Series对象转成 DatetimeProperties 对象, 然后就能获取不同的时间了.
ebola['year'] = ebola['Date'].dt.year
ebola['month'] = ebola['Date'].dt.month
ebola['day'] = ebola['Date'].dt.day
# 4. 查看ebola数据
ebola.info()
3. 日期运算
案例1: 埃博拉数据演示
# 1. 计算各个国家, 疫情爆发的天数
# 埃博拉数据中, Day表示各个国家, 疫情爆发的时间(第几天)
ebola['Date'] - ebola['Date'].min()
# 2. 给ebola这个df对象新增一列, 表示: 疫情天数, 即: 日期 - 爆发的哪一天
ebola['outbreak_d'] = ebola['Date'] - ebola['Date'].min()
# 3. 查看数据
ebola.head()
ebola.info() # 能看到 outbreak_d 列为: timedelta64[ns] (日期差类型)
案例2: 银行数据演示
# 1. 加载银行数据, 把最后两列转为: 日期列
banks = pd.read_csv('data/banklist.csv', parse_dates=[5, 6])
banks.info()
# 2. 计算银行倒闭的季度 和 年份, 并把该列值添加到 df中.
banks['Closing_Quarter'], banks['Closing_Year'] = (banks['Closing Date'].dt.quarter, banks['Closing Date'].dt.year)
banks
# 3. 统计每年倒闭的银行数.
banks['Closing_Year'].value_counts()
# 4. 计算每年, 每季度, 银行倒闭数.
banks.groupby(['Closing_Year', 'Closing_Quarter']).size() # 统计长度(个数).
banks.groupby(['Closing_Year', 'Closing_Quarter']).count() # 统计个数, 效果同上.
# 透视表方式实现, 效果同上.
banks.pivot_table(index=['Closing_Year', 'Closing_Quarter'], values='Bank Name', aggfunc='count')
# 5. 可视化展示
banks.pivot_table(index=['Closing_Year', 'Closing_Quarter'], values='Bank Name', aggfunc='count').plot(grid=True)
4. 日期时间索引
代码演示
# 1. 加载特斯拉股票数据.
tesla_stock = pd.read_csv('data/TSLA.csv', parse_dates=[0])
tesla_stock
# 2. 查看该df的列信息
tesla_stock.info()
# 3. 获取开盘价, 最小值, 最大值
tesla_stock['Open'].min()
tesla_stock['Open'].max()
# 4. 获取2015年, 8月的数据
# 方式1: 不使用日期索引, df对象[(条件1) & (条件2)]
# & 支持 Series 和 Series的比较
# and 不支持 Series 和 Series的比较
tesla_stock[(tesla_stock['Date'].dt.year == 2018) & (tesla_stock['Date'].dt.month == 8)]
# 方式2: 使用日期索引实现.
tesla_stock.set_index('Date', inplace=True)
# tesla_stock
tesla_stock.loc['2015-08']
# tesla_stock['2015-08'] 这种写法在2.0的版本已经被删除了
# 还可以使用 timedelta 类型-时间差类型 实现.
tesla_stock['ref_date'] = tesla_stock['Date'] - tesla_stock['Date'].min()
# 把timedelta设置为 index
# tesla_stock.set_index('ref_date')
tesla_stock.index = tesla_stock['ref_date'] # 效果同上
# 查看数据
tesla_stock.head()
# 基于ref_date 来选择数据
tesla_stock['0 days' : '5 days']
# 注意: 切片方式获取数据, (切片列)要求是要有序的
tesla_stock['5 days' : '0 days'] # 获取不到数据.
# 这个可以获取到数据.
tesla_stock.sort_index(ascending=False)['5 days' : '0 days']
5. 生成日期时间序列
格式
pd.date_range('起始时间','结束时间', freq= 生成时间序列的方式) # frequency:出现频次
参数freq可以取得值
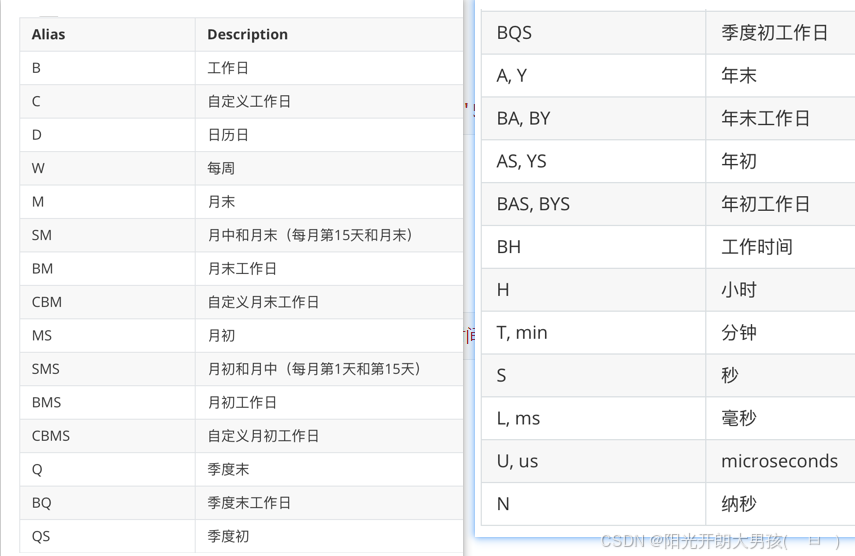
示例代码
# 1. 生成日期时间序列, 参1: 开始时间, 参2: 结束时间,
# 参3:freq(frequency) 出现频次, 默认是: D, 表示日历日
pd.date_range('2024-04-01','2024-05-31')
# 2. 隔一个工作日获取一个工作日(即: 周一 ~ 周五)
pd.date_range('2024-04-01','2024-05-31', freq='2B')
# 3. 每个月的第一个周四, Week Of Month, Thursday
pd.date_range('2024-04-01','2024-05-31', freq='WOM-1THU')
# 4. 每个月的第一个周五, Week Of Month, Friday
pd.date_range('2024-04-01','2024-05-31', freq='WOM-1Fri')
日期时间类型-总结
Pandas关于日期时间的数据 有如下几种数据类型
- TimeStamp 时间戳 就是一个时间点
- Datetime64 一列时间数据 →DatetimeIndex
- TimeDelta64 两列时间的差值 → TimedeltaIndex
如果数据中包含了日期时间的数据, 并且后续计算/数据的处理需要用到日期时间类型数据的特性需要把他转换成日期时间类型
- pd.to_datetime(一列数据)
- pd.read_csv(parse_dates= [列名/序号]) 加载的时候直接进行转换
还可以通过Pandas提供的API生成日期时间的序列
pd.date_range(‘起始时间’,‘结束时间’, freq= 生成时间序列的方式)
在特征处理/数据处理 看见日期时间类型数据需要马上反映出通过这一列数据,可以做出很多列特征来
- df[‘Date’].dt.year 年
- df[‘Date’].dt.month 月
- df[‘Date’].dt.quarter 季度
- df[‘Date’].dt.dayofweek 星期几
- 如果想快速的对日期进行切片/范围选取的操作, 可以把它转换成日期时间索引
6. 日期时间数据类型-练习
需求1: 获取某天或者某个时间段的报警记录
# 1. 加载数据源(报警记录数据).
# 字段为: 犯罪类型id, 犯罪类别id, 报警日期, 经度, 维度, 小区id, 是否犯罪, 是否是交通事故
crime = pd.read_csv('data/crime.csv', parse_dates=['REPORTED_DATE'], index_col='REPORTED_DATE')
crime
# 2. 查看犯罪类型id
# crime['OFFENSE_CATEGORY_ID'].value_counts()
# 3. 把报警时间设置为行索引, 如果加载数据时没有设置, 可以用如下方式.
# crime.set_index('REPORTED_DATE',inplace=True)
# 4. 获取某天的报警记录, 例如: 行索引为 '2016-05-11' 的数据
crime.loc['2016-05-11']
# 5. 获取一段时间内的报警记录
crime.loc['2015-3-1 12:57:00':'2016-01-13 15:26:00']
crime.loc['2015-03-01':'2016-03-01'].sort_index() # 不要时分秒.
# 6. 查询凌晨2点到凌晨5点的报警记录
# include_start: 是否包括起始值
# include_end: 是否包括结束值
crime.between_time('2:00','5:00',include_start=False)
# 7. 查看某个具体的时刻. 例如: 查看5:43分的报警记录
crime.at_time('5:43')
需求2: 获取某个时间段的报警记录, 效率对比
# 8. 获取某个时间段内的报警记录.
# 8.1 获取 根据行索引排序后的内容
crime_sorted = crime.sort_index()
crime_sorted
# 8.2 获取某个时间段内的报警记录.
crime_sorted.loc['2015-03-01':'2016-03-01']
# %timeit 是 ipython的魔术函数, 可用于计时特定代码段(计算代码执行时间).
%timeit crime.loc['2015-03-01':'2016-03-01'] # 8毫秒 +- 170微秒
%timeit crime_sorted.loc['2015-03-01':'2016-03-01'] # 1毫秒 +- 97微秒
需求3: 计算每周的犯罪记录
# 9. 计算每周的犯罪数量
# resample() 重采样, 可以按照 指定时间周期 分组
crime_sorted.resample('W') # DatetimeIndexResampler对象
# 结合size()函数, 查看分组大小.
weekly_crimes = crime_sorted.resample('W').size()
weekly_crimes
# 检验分组结果.
len(crime_sorted.loc[:'2012-1-8']) # 877条
len(crime_sorted.loc['2012-1-9':'2012-1-15']) # 1071条
# 也可以把 周四 作为每周的结束.
crime_sorted.resample('W-THU').size()
# 结果可视化
weekly_crimes.plot(figsize=(16, 4), title='丹佛犯罪情况')
需求4: 分析每季度的犯罪和交通事故数据
# 10. 分析每季度的犯罪和交通事故数据
# Q表示 季度末
crime_quarterly = crime_sorted.resample('Q')['IS_CRIME', 'IS_TRAFFIC'].sum()
crime_quarterly
# 所有日期都是该季度的最后一天, 使用QS生成每季度的第一天.
crime_sorted.resample('QS')['IS_CRIME', 'IS_TRAFFIC'].sum()
# 查看第2季度的数据, 检验结果.
crime_sorted.loc['2012-04-01':'2012-06-30', ['IS_CRIME', 'IS_TRAFFIC']].sum()
# 结果可视化
crime_quarterly.plot(figsize=(16, 4), color=['red', 'blue'], title='丹佛犯罪和交通事故数据')
需求5: 分析工作日的犯罪情况
# 11. 分析工作日的犯罪情况
# 加载数据源
crime = pd.read_csv('data/crime.csv', parse_dates=['REPORTED_DATE'])
# 按 工作日(周几) 来统计.
wd_counts = crime['REPORTED_DATE'].dt.weekday.value_counts()
wd_counts
# 数据可视化, barh: 水平柱状图
wd_counts.plot(kind='barh', title='丹佛犯罪和交通事故按周分析')
总结
把日期时间设置为Index 行索引之后, 可以使用
crime.between_time('2:00','5:00',include_start=False) crime.at_time('5:43')between_time 在两个时刻的范围内
at_time 在某个具体的时刻
crime.resample(‘W’) 将数据
按周进行分组 , 分组之后可以接聚合函数, 类似于groupby之后的聚合.crime.resample(‘M’) 将数据
按月份进行分组,分组之后可以接聚合函数, 类似于groupby之后的聚合,crime.resample(‘Q’) 将数据
按季度进行分组, 分组之后可以接聚合函数, 类似于groupby之后的聚合如果需要对DatetimeIndex这个类型的数据进行切片操作, 建议先排序, 再切片, 效率更高
📜 至此,【Pandas篇】纵横数据江湖:核心秘籍全解 的九重境界已尽数揭开! 历经本文锤炼,你已铸就:
✨ 数据内功根基:DataFrame与Series双剑合璧、索引操控凌波微步、缺失值破阵之道
✨ 乾坤运转术:合并连接兵法、分组聚合的乾坤大挪移、时间序列时空秘术
✨ 屠龙实战:链家房价洞察、泰坦尼克生存推演、apply函数化形法则
🔍 招式存疑?若遇「数据清洗迷阵」或「分组聚合数海迷踪」,速速在评论区「剑气破空」,共探数据奥义!
💡 进阶问道?若想参透「Pandas性能调优真经」或迎战「千万级数据炼狱」,留言即赠独门心法!
🗡️ 你的每一道 ❤️点赞|⭐收藏|📤分享 ,皆为斩断「数据混沌」的绝世剑气,助我等在算法江湖再攀巅峰! 🌟



DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 35
35 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)