Python网络爬虫实战:爬取豆瓣电影评论数据
网络爬虫是自动化获取网页数据的核心技术,广泛应用于数据分析、市场调研等领域。本文以豆瓣电影《封神第二部:战火西岐》的短评数据为例,展示如何通过Python的。:若页面数据通过JavaScript加载,可使用。:用户名、赞同数、评论时间、IP地址、评论内容。通过本文,你可以快速掌握基础爬虫的实现逻辑。库实现评论数据的爬取,并整理为结构化数据。:豆瓣电影《封神第二部:战火西岐》短评页面。Beautif
目录
3.2 使用开发者工具中分析网页结构,定位短评数据在html中的位置
1. 引言
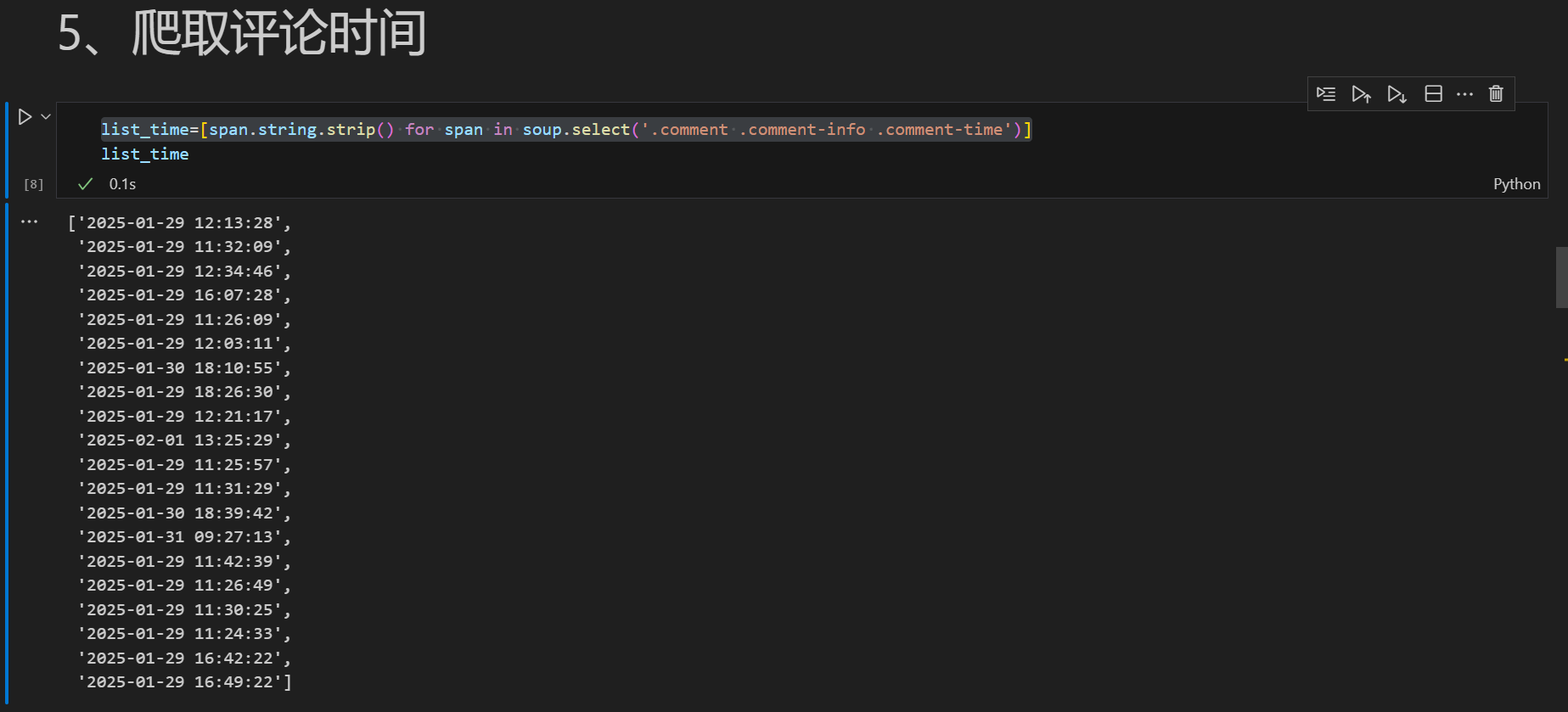
网络爬虫是自动化获取网页数据的核心技术,广泛应用于数据分析、市场调研等领域。本文以豆瓣电影《封神第二部:战火西岐》的短评数据为例,展示如何通过Python的requests和BeautifulSoup库实现评论数据的爬取,并整理为结构化数据。
2. 准备工作
2.1 安装依赖库
pip install requests beautifulsoup4 pandas2.2 目标分析
-
目标网址:豆瓣电影《封神第二部:战火西岐》短评页面
-
目标字段:用户名、赞同数、评论时间、IP地址、评论内容
-
反爬策略:需添加
User-Agent请求头模拟浏览器访问。
3. 核心代码实现
3.1 发送HTTP请求
# 导入必要的库
# requests用于发送HTTP请求获取网页内容
import requests
# BeautifulSoup用于解析HTML文档内容
from bs4 import BeautifulSoup
# 定义目标URL(豆瓣电影短评页面)
url = 'https://movie.douban.com/subject/30181250/comments?status=P'
# 设置请求头信息(模拟浏览器访问)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
html_content = response.text代码运行结果图:
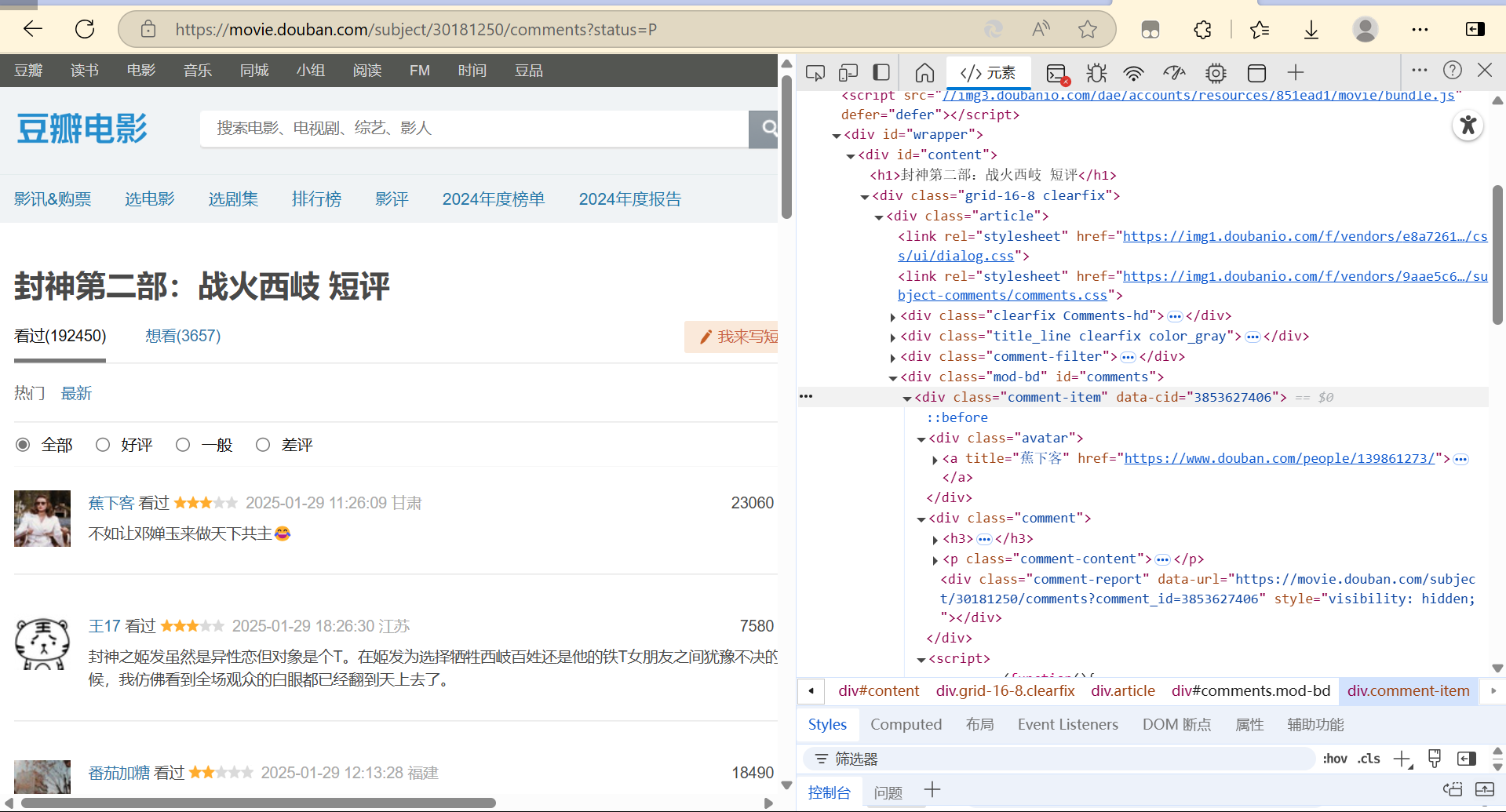
3.2 使用开发者工具中分析网页结构,定位短评数据在html中的位置
3.3 解析HTML内容
# 使用BeautifulSoup解析HTML文档
# 参数说明:
# html_content: 需要解析的HTML内容
# 'lxml': 指定使用lxml解析器(需要先安装:pip install lxml)
soup = BeautifulSoup(html_content, 'lxml')
# 提取用户名
list_name=[a.string for a in soup.select('.comment .comment-info a')]
# 提取赞同数
list_title=[span.string for span in soup.select('.comment .comment-vote span')]
# 提取评论时间和IP地址
list_time=[span.string.strip() for span in soup.select('.comment .comment-info .comment-time')]
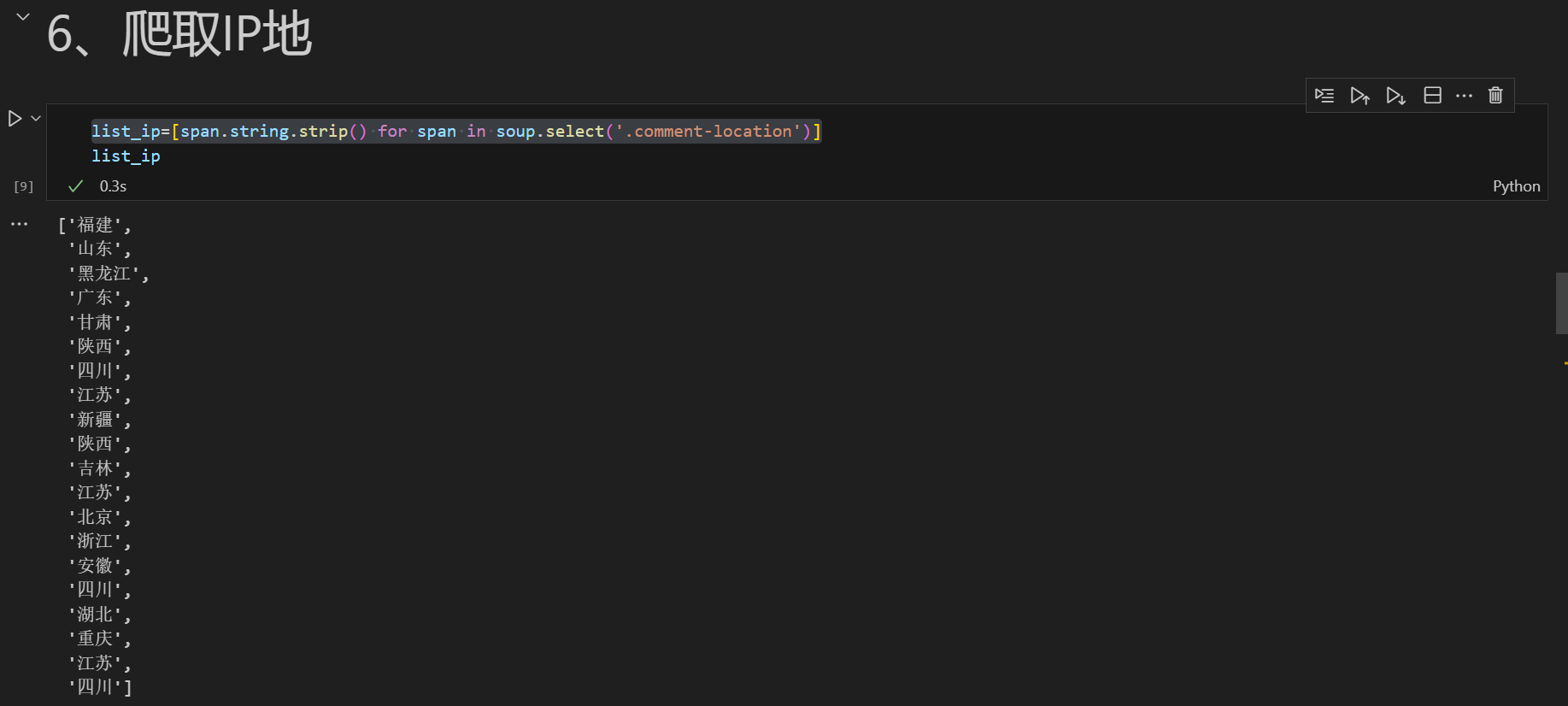
list_ip=[span.string.strip() for span in soup.select('.comment-location')]
# 提取评论内容
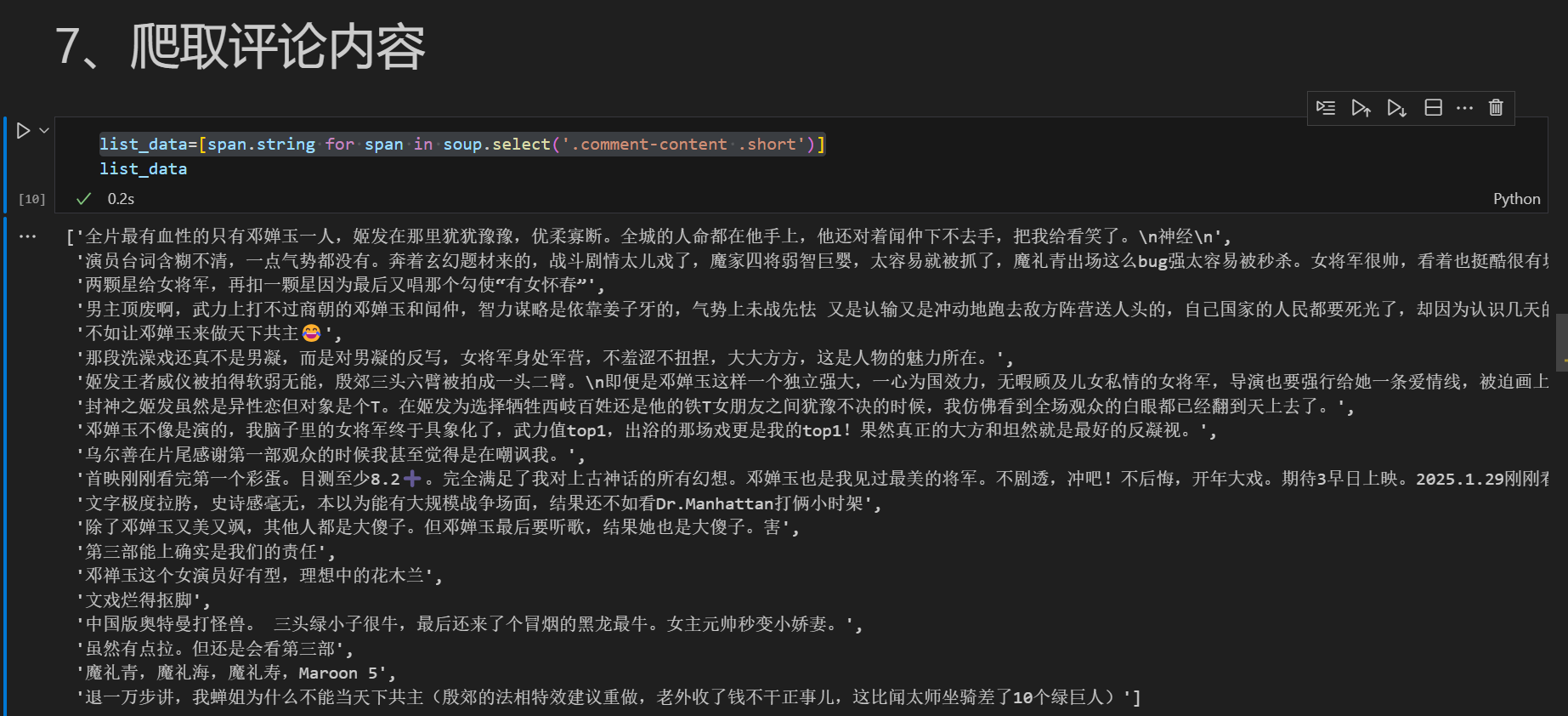
list_data=[span.string for span in soup.select('.comment-content .short')]代码运行结果图:
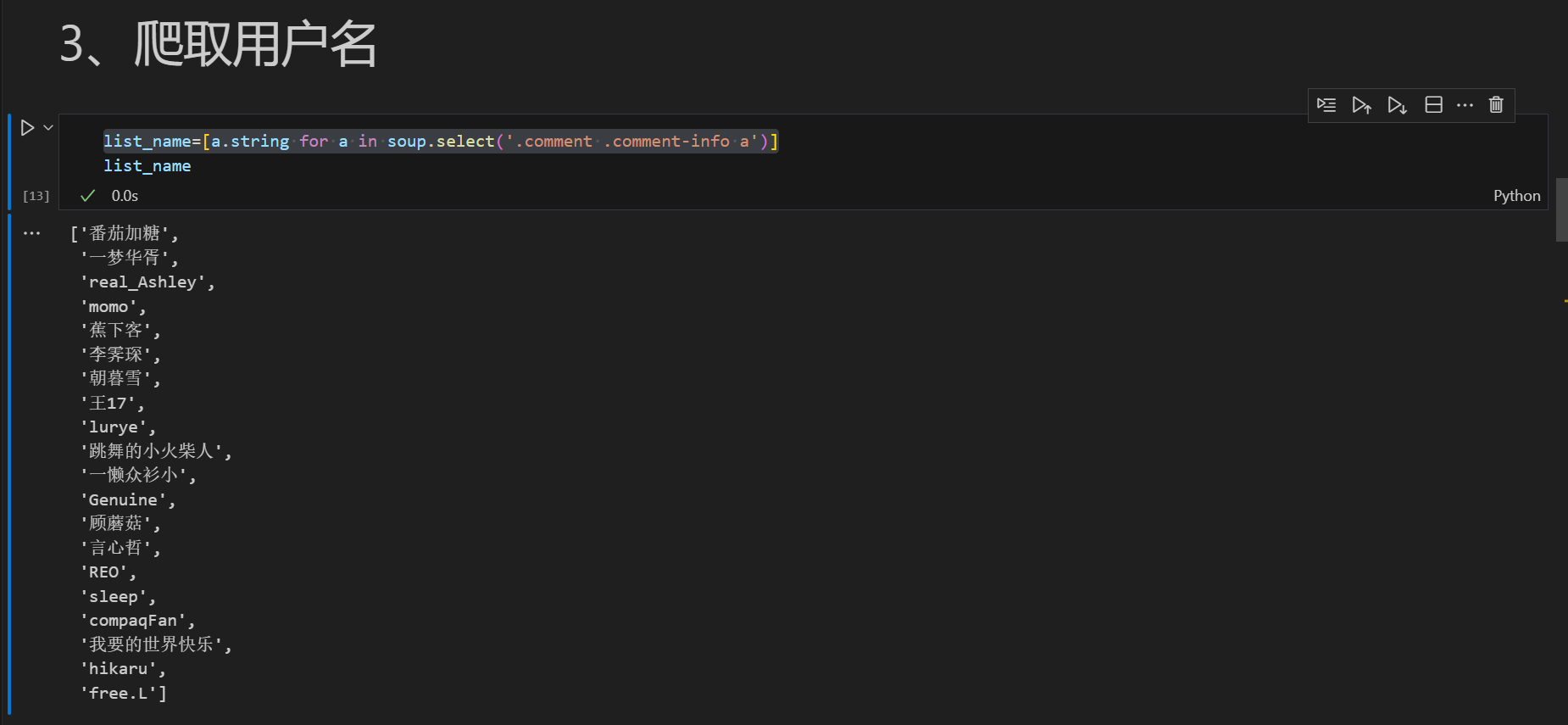
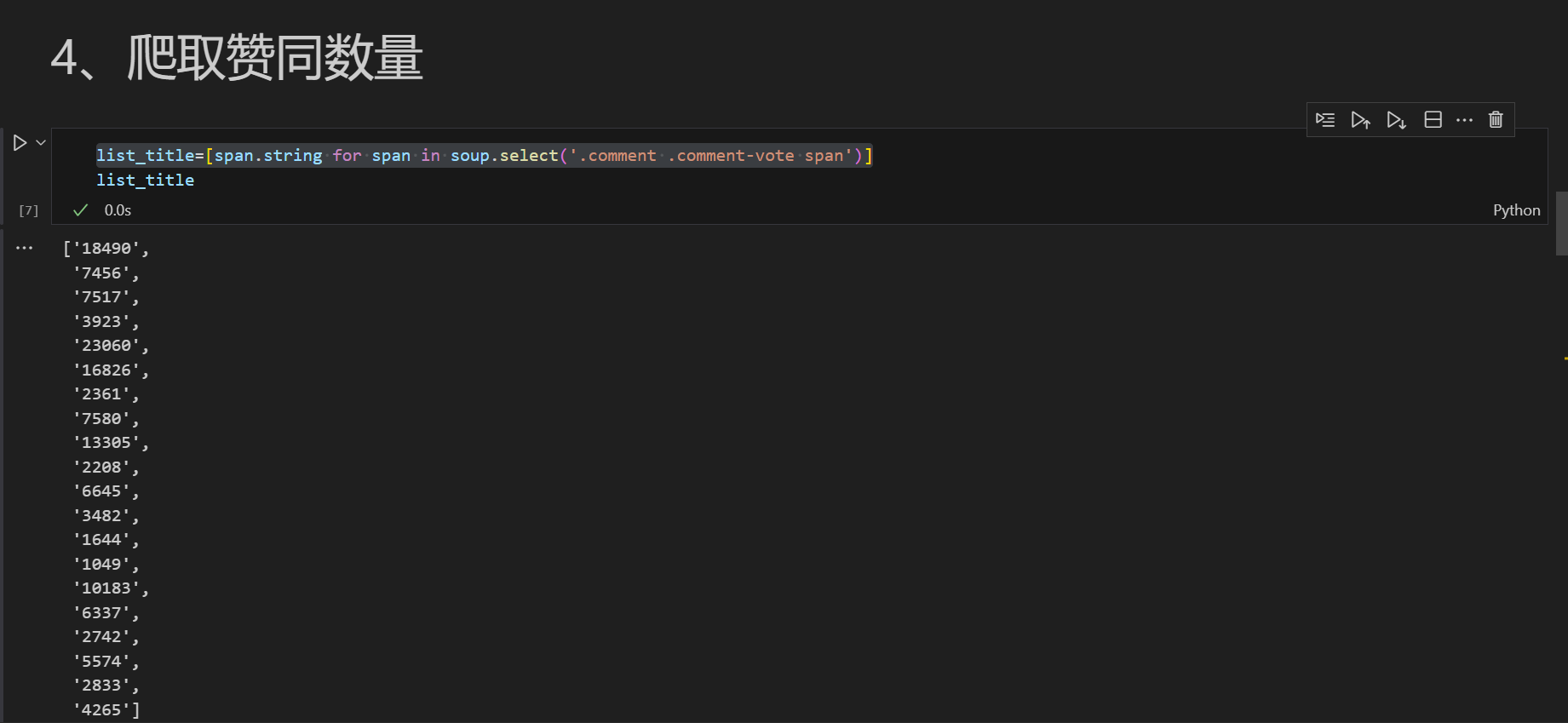
3.4 数据存储
import pandas as pd
df = pd.DataFrame({
'用户名': usernames,
'赞同数': votes,
'评论时间': times,
'IP地址': ips,
'评论内容': comments
})4. 结果展示
数据预览(表格)
| 用户名 | 赞同数 | 评论时间 | IP地址 | 评论内容摘要 |
|---|---|---|---|---|
| 番茄加糖 | 18490 | 2025-01-29 12:13:28 | 福建 | 全片最有血性的只有邓婵玉一人... |
| 一梦华胥 | 7456 | 2025-01-29 11:32:09 | 山东 | 演员台词含糊不清,战斗剧情太儿戏... |
| .................................. | ||||
5.数据存储
# 导入SQLAlchemy的create_engine模块
# 用于创建数据库连接引擎
from sqlalchemy import create_engine
# 创建MySQL数据库引擎
# 格式说明:mysql+pymysql://用户名:密码@服务器地址:端口/数据库名
# root: 数据库用户名
# 123456: 数据库密码
# localhost: 数据库服务器地址
# 3306: MySQL默认端口
# test: 目标数据库名称
# charset=utf8mb4: 设置字符集支持中文
engine = create_engine(
'mysql+pymysql://root:123456@localhost:3306/test?charset=utf8mb4'
)
# 将DataFrame数据写入MySQL数据库
# 参数说明:
# 'douban':目标表名(会自动创建)
# engine:数据库连接引擎
# index=False:不写入DataFrame的索引列
# if_exists='append':如果表存在则追加数据(可选值:fail, replace, append)
# dtype:指定字段类型
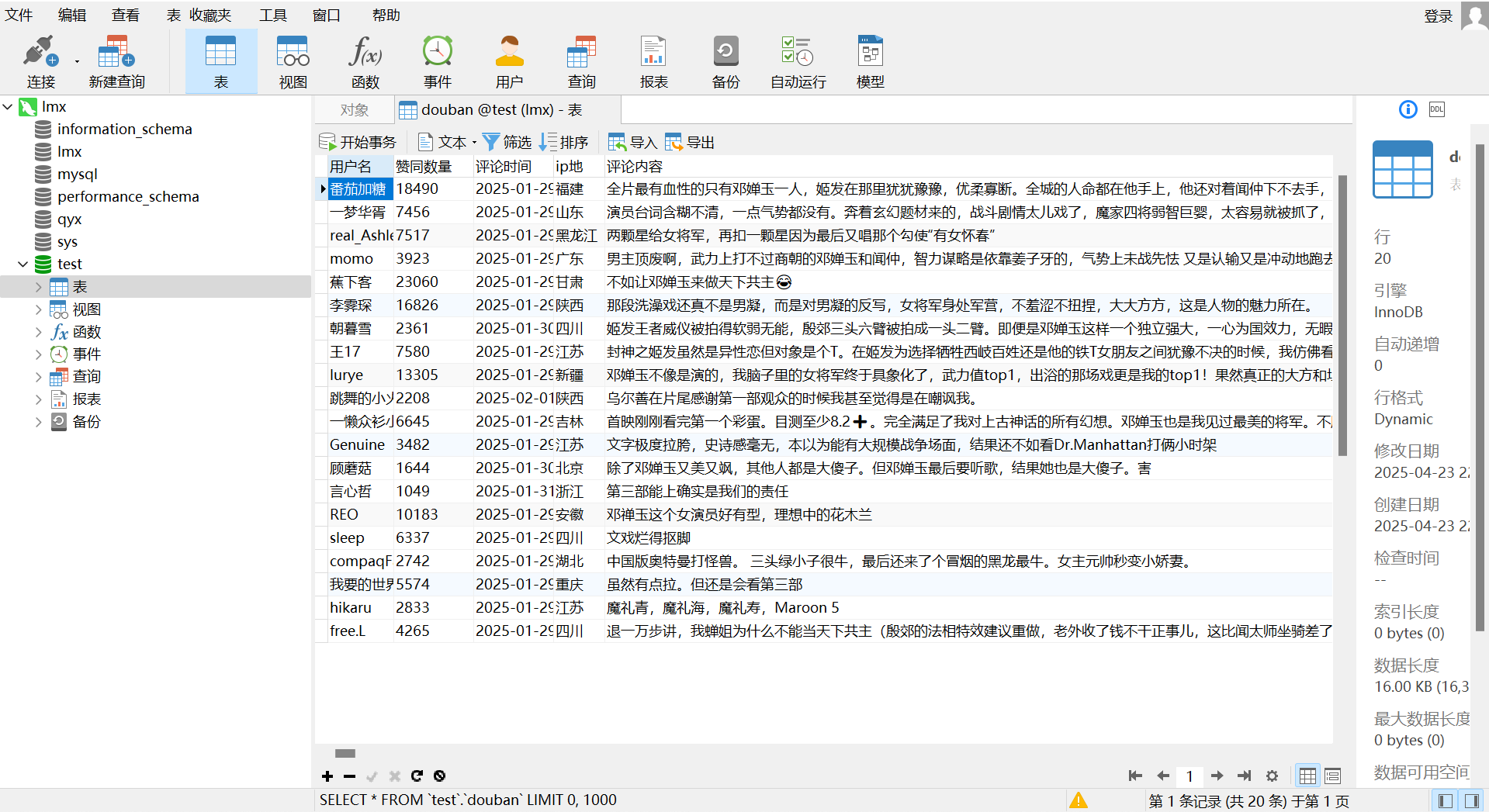
df.to_sql('douban', engine, index=False, if_exists='append')如图成功存储到MySQL表中:
6. 注意事项
-
反爬机制:
-
豆瓣可能限制高频访问,建议添加
time.sleep(2)延迟请求。 -
使用代理IP池应对IP封锁(推荐服务: ScraperAPI)。
-
-
法律合规:
-
遵守豆瓣的
robots.txt规则,避免爬取敏感信息。 -
控制爬取速度,减少服务器压力。
-
7. 扩展学习
-
多页爬取:通过分析分页URL规律(如
?start=20),实现循环翻页。 -
动态内容:若页面数据通过JavaScript加载,可使用
Selenium或Scrapy-Splash。 -
数据可视化:结合
Matplotlib或Tableau分析评论情感倾向。
8. 参考资源
通过本文,你可以快速掌握基础爬虫的实现逻辑。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)