爬虫模块—每日行情数据/交易日期/公司信息获取(01)
这里我们获取到了基本的数据,后面我们会介绍将这些数据入库,还有就是我们提到了这里有三张表的数据我们当作维度表维护,等到了数仓环节我们会介绍如何去维护维度表。
首先我们获取每天的行情数据,因为我们的模型最终需要根据行情数据进行优化,也就是说行情数据就是判断模型好坏的标准。当然我们也会对这个数据本身进行分析,例如涨停板的分析,连续涨停的分析。
这里我们的数据获取是通过tushare 完成的,当然你可以可以通过一些券商平台提供提供的接口完成,我这里使用的tushare,它提供了Python,Java 的接口,不过使用之前你需要去注册一个账号,然后获取到一个token ,由于代码很简单就不解释。
所以这里你的先安装Python 的tushare 模块,直接执行pip install tushare 即可,关于Api 的基本使用可以去看官网,这里就不解释了
每日行情数据获取
这个代码很简单我们就不解释了
# 导入tushare
import datetime
import time
import tushare as ts
# 初始化pro接口
pro = ts.pro_api('xxxxxxxx',timeout=130)
basePath="/Users/kingcall/workspace/tmp/量化交易/trade/{0}.csv"
def getDataByDate(date):
path =basePath.format(date)
try:
df = pro.daily(trade_date=date)
df.to_csv(path, header=True,index=None)
print(date,path)
except (ConnectionError, TimeoutError):
try:
time.sleep(3)
df = pro.bak_basic(trade_date=date)
df.to_csv(path)
except Exception:
print("错误:{0}".format(date))
except Exception as e:
print(e)
print("错误:{0}".format(date))
if __name__ == '__main__':
# 获取过去多少天的
for i in range(20):
# 从那一天开始
day=datetime.date(2022,10,30)-datetime.timedelta(days=i)
# 时间格式化
date=day.strftime("%Y%m%d")
getDataByDate(date)
输出的字段含义如下
| 名称 | 类型 | 描述 |
|---|---|---|
| ts_code | str | 股票代码 |
| trade_date | str | 交易日期 |
| open | float | 开盘价 |
| high | float | 最高价 |
| low | float | 最低价 |
| close | float | 收盘价 |
| pre_close | float | 昨收价(前复权) |
| change | float | 涨跌额 |
| pct_chg | float | 涨跌幅 (未复权,如果是复权请用 通用行情接口 ) |
| vol | float | 成交量 (手) |
| amount | float | 成交额 (千元) |
我们将获取到的数据放到/Users/kingcall/workspace/tmp/量化交易/trade 文件夹下
运行日志如下
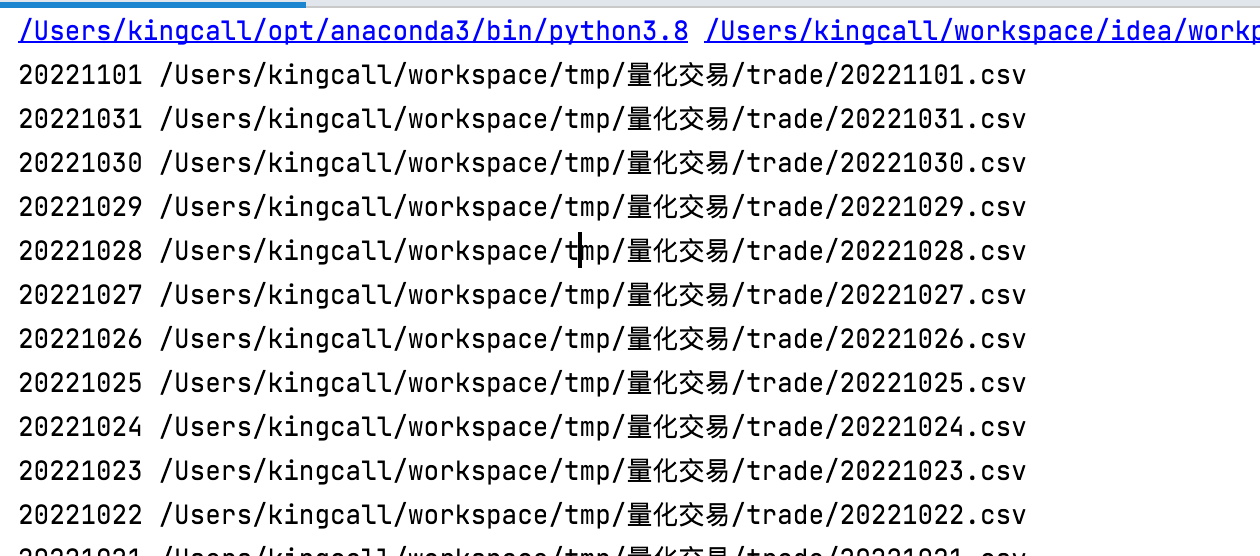
数据文件目录如下

交易日期获取
这个数据我们不用每天都获取,可以看作是一个时间维表
import tushare as ts
basePath="/Users/kingcall/workspace/tmp/量化交易/{0}.csv"
pro = ts.pro_api('xxxx',timeout=130)
def loadDates():
df = pro.trade_cal(exchange='', start_date='20180101', end_date='20221230')
dataPath=basePath.format("dates")
print(dataPath)
df.to_csv(dataPath)
loadDates()
输出的字段含义如下
| 名称 | 类型 | 默认显示 | 描述 |
|---|---|---|---|
| exchange | str | Y | 交易所 SSE上交所 SZSE深交所 |
| cal_date | str | Y | 日历日期 |
| is_open | str | Y | 是否交易 0休市 1交易 |
| pretrade_date | str | Y | 上一个交易日 |
公司基本信息获取
这个信息也不是经常变化,我们也不用每天都去获取,只要每隔一段时间进行更新维护即可
def loadCompany():
# exchange交易所代码 ,SSE上交所 SZSE深交所
df1 = pro.stock_company(exchange='SZSE', fields='ts_code,exchange,chairman,manager,secretary,reg_capital,setup_date,province,city,introduction,website,email,office,employees,main_business,business_scope')
df2 = pro.stock_company(exchange='SSE', fields='ts_code,exchange,chairman,manager,secretary,reg_capital,setup_date,province,city,introduction,website,email,office,employees,main_business,business_scope')
# 由于国内的公司在国内只能在同一个交易所上市,要不是深交所要不是上交所,但是这个时候可以去港交所或者是纽交所的
# 所以我们直接合并就行
df=df1.append(df2)
dataPath=basePath.format("company")
print(dataPath)
df.to_csv(dataPath)
输出的字段含义如下
| 名称 | 类型 | 默认显示 | 描述 |
|---|---|---|---|
| ts_code | str | Y | 股票代码 |
| exchange | str | Y | 交易所代码 ,SSE上交所 SZSE深交所 |
| chairman | str | Y | 法人代表 |
| manager | str | Y | 总经理 |
| secretary | str | Y | 董秘 |
| reg_capital | float | Y | 注册资本 |
| setup_date | str | Y | 注册日期 |
| province | str | Y | 所在省份 |
| city | str | Y | 所在城市 |
| introduction | str | N | 公司介绍 |
| website | str | Y | 公司主页 |
| str | Y | 电子邮件 | |
| office | str | N | 办公室 |
| employees | int | Y | 员工人数 |
| main_business | str | N | 主要业务及产品 |
| business_scope | str | N | 经营范围 |
股票基本信息
股票基本信息也不是经常变化的,所以我们也是当作维表维护即可
def loadStocks():
df = pro.stock_basic(exchange='', list_status='L', fields='ts_code,symbol,name,area,industry,fullname,enname,cnspell,market,exchange,curr_type,list_status,list_date,delist_date,is_hs')
dataPath=basePath.format("stocks")
print(dataPath)
df.to_csv(dataPath)
输出的字段含义如下
| 名称 | 类型 | 默认显示 | 描述 |
|---|---|---|---|
| ts_code | str | Y | TS代码 |
| symbol | str | Y | 股票代码 |
| name | str | Y | 股票名称 |
| area | str | Y | 地域 |
| industry | str | Y | 所属行业 |
| fullname | str | N | 股票全称 |
| enname | str | N | 英文全称 |
| cnspell | str | N | 拼音缩写 |
| market | str | Y | 市场类型(主板/创业板/科创板/CDR) |
| exchange | str | N | 交易所代码 |
| curr_type | str | N | 交易货币 |
| list_status | str | N | 上市状态 L上市 D退市 P暂停上市 |
| list_date | str | Y | 上市日期 |
| delist_date | str | N | 退市日期 |
| is_hs | str | N | 是否沪深港通标的,N否 H沪股通 S深股通 |
完整代码与最终数据
我们上面的代码我们都是定义成方法的形式了,接下来调用这些方法即可
if __name__ == '__main__':
loadDates()
loadCompany()
loadStocks()
运行日志如下

数据如下

总结
这里我们获取到了基本的数据,后面我们会介绍将这些数据入库,还有就是我们提到了这里有三张表的数据我们当作维度表维护,等到了数仓环节我们会介绍如何去维护维度表。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)