hive 计算表中的空值数目_hive--整理
hive窗口函数1、Over子句在深入研究Over字句之前,一定要注意:在SQL处理中,窗口函数都是最后一步执行,而且仅位于Order by字句之前。统计2019年4月份每个人的购买记录次数select name,count(*) over ()from odistwhere otime = '2019-04'group by name-------执行结果mart 2jack ...
- hive窗口函数
1、Over子句
在深入研究Over字句之前,一定要注意:在SQL处理中,窗口函数都是最后一步执行,而且仅位于Order by字句之前。
统计2019年4月份每个人的购买记录次数
select name,count(*) over ()
from odist
where otime = '2019-04'
group by name
-------执行结果
mart 2
jack 2
》》执行
select name,count(*)
from odist
where otime = '2019-04'
group by name
-----》》输出结果
mart 1
jack 1
mart 1
jack 12、partition by子句
Over子句之后第一个提到的就是Partition By.Partition By子句也可以称为查询分区子句,非常类似于Group By,都是将数据按照边界值分组,而Over之前的函数在每一个分组之内进行,如果超出了分组,则函数会重新计算.
统计顾客的购买明细及月购买总额
select name,otime,cost,sum(cost) over(partition by month(otime))
from odist
--------查询结果:
name otime cost sum_window_0
jack 2015-01-01 10 76
jack 2015-01-08 10 76
jack 2015-01-07 10 76
jack 2015-01-05 46 76
jack 2015-02-03 23 23
neil 2015-05-10 12 12
neil 2015-06-12 80 803、order by子句
order by子句会让输入的数据强制排序
select name,otime,cost,sum(cost) over(partition by month(otime) order by otime )
from odist- hive 数据倾斜
1、空值产生的数据倾斜
解决方案 1:user_id 为空的不参与关联
解决方案 2:赋予空值新的 key 值
2、不同数据类型关联产生数据倾斜
用户表中 user_id 字段为 int,log 表中 user_id 为既有 string 也有 int 的类型, 当按照两个表的 user_id 进行 join 操作的时候,
默认的 hash 操作会按照 int 类型的 id 进 行分配,这样就会导致所有的 string 类型的 id 就被分到同一个 reducer 当中。
解决方案: 把数字类型 id 转换成 string 类型的 id。
3、大小表关联查询产生数据倾斜
注意:使用map join解决小表关联大表造成的数据倾斜问题。这个方法使用的频率很高。
map join 概念:将其中做连接的小表(全量数据)分发到所有 MapTask 端进行 Join,从 而避免了 reduceTask,前提要求是内存足以装下该全量数据。
在 hive0.11 版本以后会自动开启 map join 优化,由两个参数控制:
set hive.auto.convert.join=true; //设置 MapJoin 优化自动开启
set hive.mapjoin.smalltable.filesize=25000000 //设置小表不超过多大时开启 mapjoin 优化
如果是大大表关联呢?那就大事化小,小事化了。把大表切分成小表,然后分别 map join
- map join和reduce join
1、hive 中的join可分为俩类,一种是common join(也叫Reduce join或shuffle join),另一种是 map join,
后者是对hive join的一个优化,利用本地的task对较小的表hash生产一个hashtable文件,然后直接和map出来另一个表进行匹配,最终完成join.
2、set hive.auto.convert.join = false 在0.7.0到0.10.0版本默认是false,表示不使用优化
3、set hive.auto.convert.join = true在0.11.0到之后的版本是ture,代表使用优化reducejoin
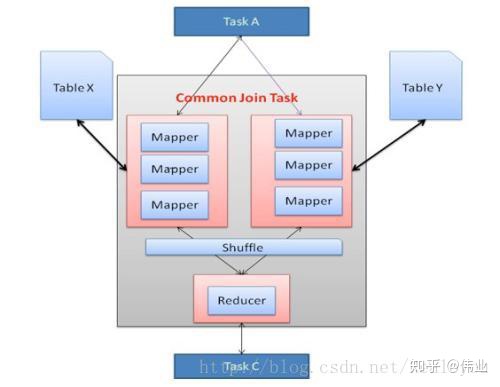
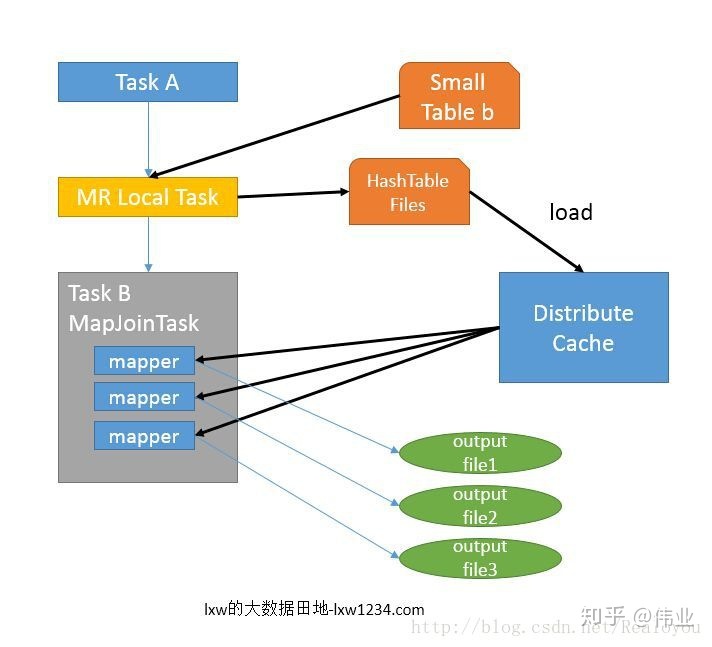
MapJoin
1、通过执行计划可以看出,正常的join是使用俩个map和一个reduce来完成join,因为过程中有shuffle,所以会有网络io,执行效率相对较小。
2、使用优化的map join过程中没有shuffle,是通过本地的一个task hash较小的表(较小的表的识别可以通过元数据信息判断)生成hashtable file文件,并保存到hdfs的临时缓存当中,然后通过与map出来的另一个表进行直接匹配,得出结果,因此过程中没有shuffle,不需要网络,所以效率相对来说较快,即为优化。
参见:
CSDN-专业IT技术社区-登录blog.csdn.net4、

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)