小红书最新开源语音转文本模型FireRedASR,本地部署教程
最近在做项目时遇到了语音转文字的需求,搜索了一下看到了年初小红书开源的FireRedASR模型,特地来使用体验了一下,对于中文方言的转换率还不错,但是速度比较慢,下面是整体配置过程和使用。
·
最近在做项目时遇到了语音转文字的需求,搜索了一下看到了年初小红书开源的FireRedASR模型,特地来使用体验了一下,对于中文方言的转换率还不错,但是速度比较慢,下面是整体配置过程和使用。
第一步 下载文件和配置环境
git clone https://github.com/FireRedTeam/FireRedASR.git #下载代码库
cd FireRedASR-main
pip install -r requirements.txt #按照运行所需环境
pip install modelscope #按照模型下载工具
modelscope download --model pengzhendong/FireRedASR-AED-L --local_dir ./pretrained_models #下载模型
按顺序运行如上命令,等待安装完毕
第二步 调试代码
修改部分代码
打开/fireredasr/models 文件夹下的fireredasr.py文件,修改load_fireredasr_aed_model方法下的第一行
改成如下内容:
package = torch.load(model_path, map_location=lambda storage, loc: storage, weights_only=False)
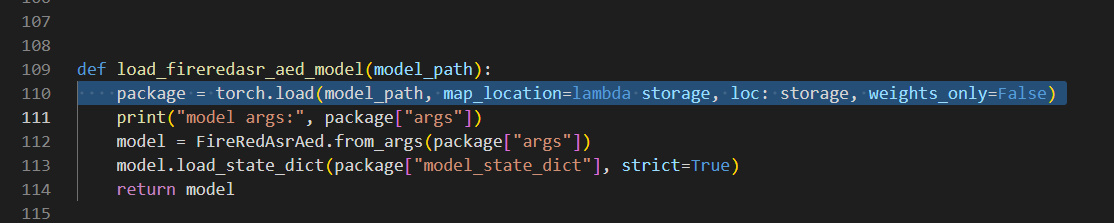
此处修改是为了应对torch2.7以上版本将weight_only默认设为True的解决方式
创建启动文件
回到项目主目录,创建main.py文件,将下面代码复制进去,根据自己的需求进行更改
from fireredasr.models.fireredasr import FireRedAsr
batch_uttid = ["BAC009S0764W0121"]
batch_wav_path = ["录音文件名称"] #录音文件最好是16kHz 16-bit PCM 格式
model = FireRedAsr.from_pretrained("aed", "pretrained_models/FireRedASR-AED-L")
results = model.transcribe(
batch_uttid,
batch_wav_path,
{
"use_gpu": 0,
"beam_size": 3,
"nbest": 1,
"decode_max_len": 0,
"softmax_smoothing": 1.0,
"aed_length_penalty": 0.0,
"eos_penalty": 1.0
}
)
print(results)
录音文件格式转换代码(注:此处需要安装mmpeg 可以搜索安装教程)
ffmpeg -i 你的录音文件名 -ar 16000 -ac 1 -acodec pcm_s16le -f wav output.wav
运行成功将生成转换成功的文件output.wav
第三步 运行项目
按自己需求修改完代码,直接使用python运行main.py即可
运行结果如下:
到此最基础的FireRedASR模型运行已经完成。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)