大数据学习(Hadoop、Hive)
目录
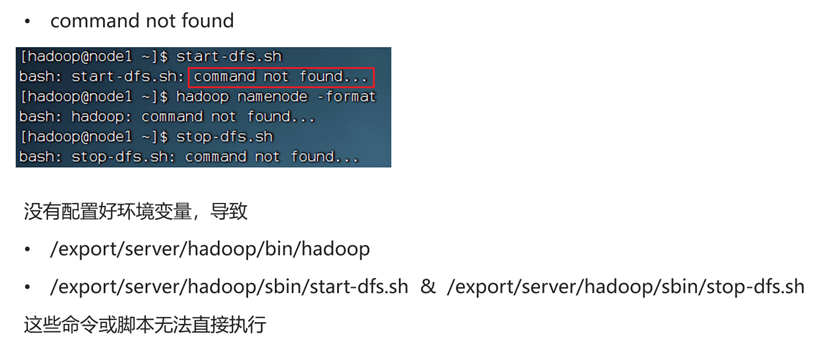
关闭集群(必须,且务必在namenode节点的hadoop用户下执行)
脚本1:$HADOOP_HOME/sbin/hadoop-daemon.sh
大数据入门
数据导论

大数据诞生

大数据概述

大数据软件生态

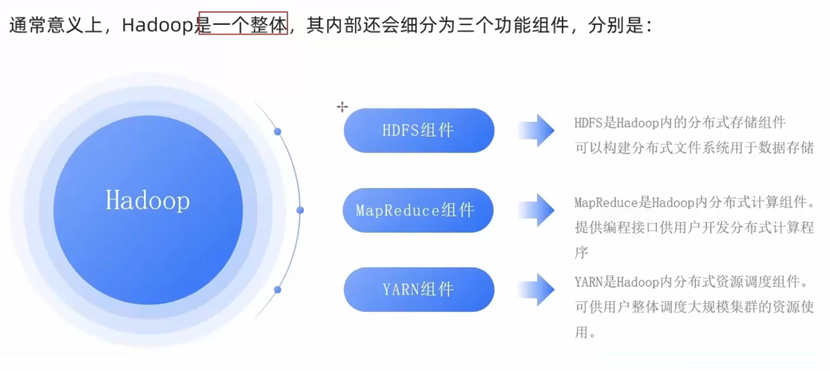
Hadoop概述
什么是hadoop

Why Hadoop

Hadoop的功能
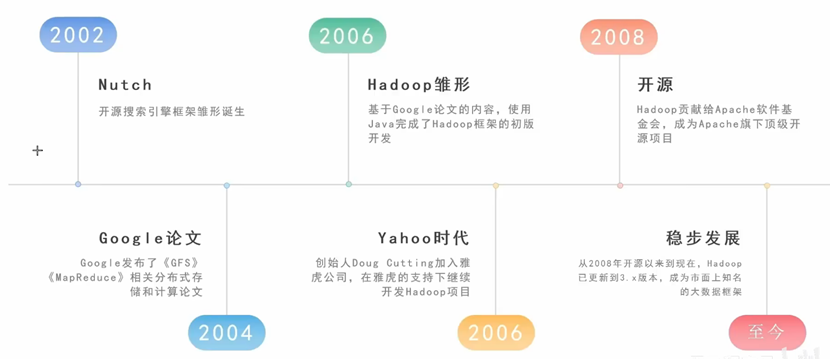
Hadoop的发展

Hadoop的发行版本

Hadoop HDFS(分布式文件系统)
为什么需要分布式存储

分布式的基础框架分析
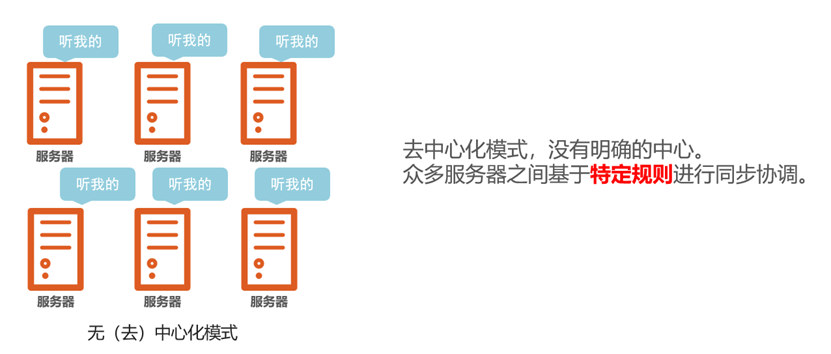
分布式调度的常见组织框架
去中心化模式
中心化模式
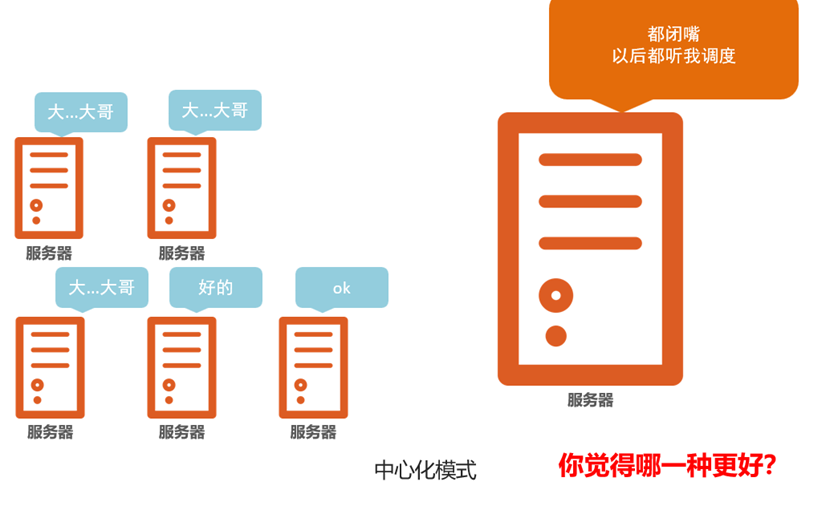
主从模式(Hadoop的模式)
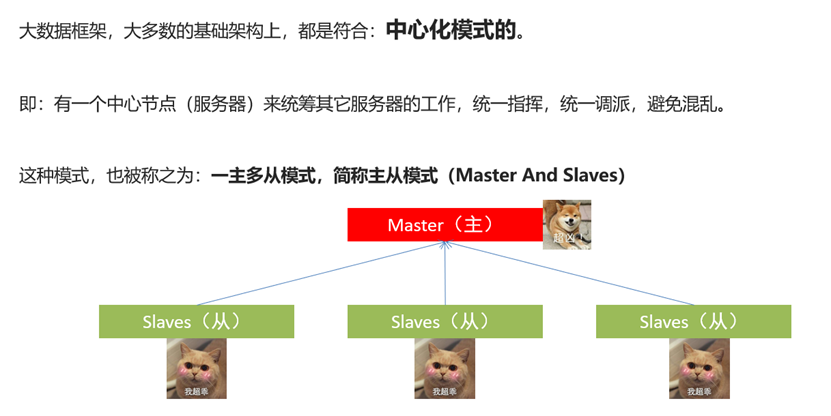
总结

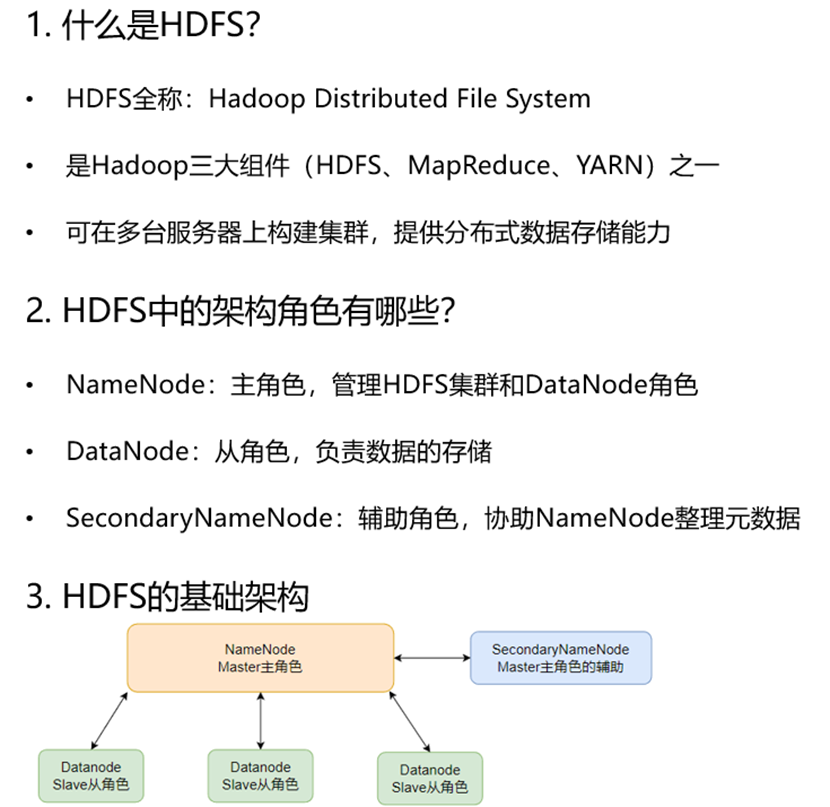
HDFS的基础架构
什么是HDFS

HDFS架构中的角色
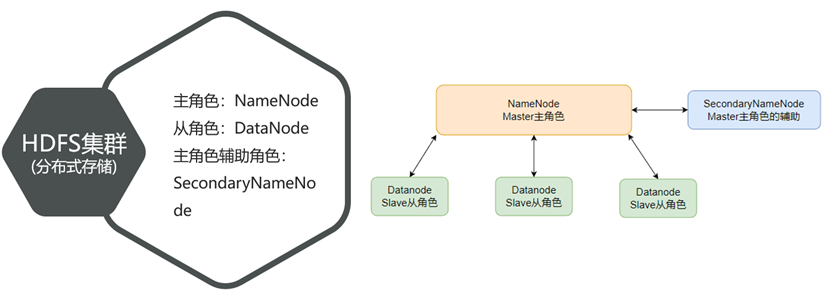
NameNode

DataNode

SecondaryNameNode

一个典型的HDFS集群
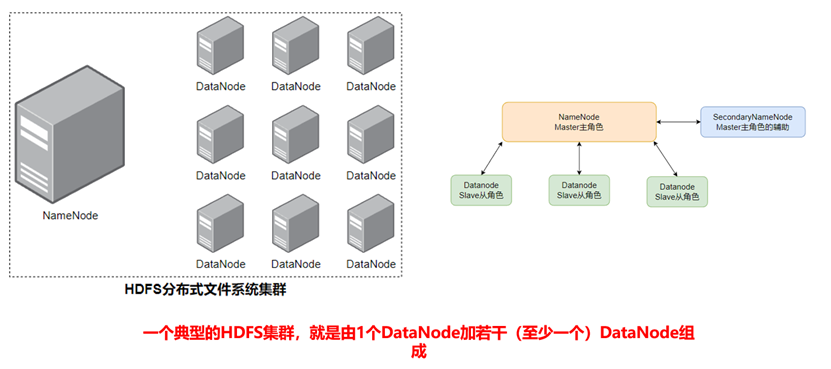
总结
HDFS集群环境部署(虚拟机部署)
安装包下载
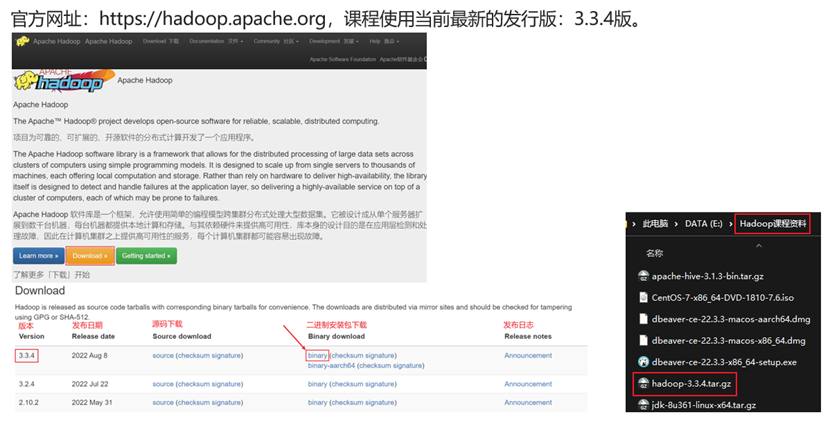
集群规划
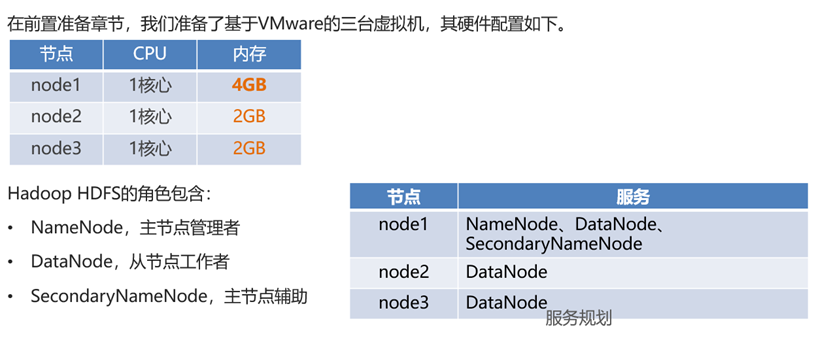
上传 & 解压 & 进入hadoop安装包
注意,以下过程均在node1节点进行!
注意事项

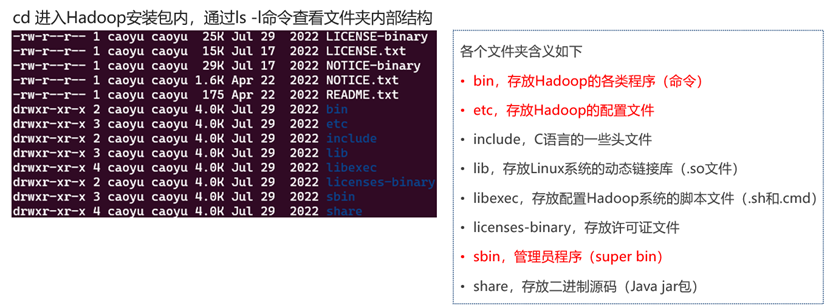
Hadoop安装包目录结构
修改配置文件,应用自定义设置

注意,这些文件位于hadoop/etc/hadoop文件夹中,而不是在第一级hadoop文件夹中!
配置workers文件

进入目标文件
# 进入配置文件目录
cd etc/hadoop
# 编辑workers文件
vim workers配置内容
# 填入如下内容
node1
node2
node3配置hadoop-env.sh文件

进入目标文件
#编辑hadoop-env.sh文件
vim hadoop-env.sh配置内容
# 填入如下内容
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs配置core-site.xml文件

进入目标文件
#编辑core-site.xml文件
vim core-site.xml配置内容
#在文件内部填入如下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>配置hdfs-site.xml文件
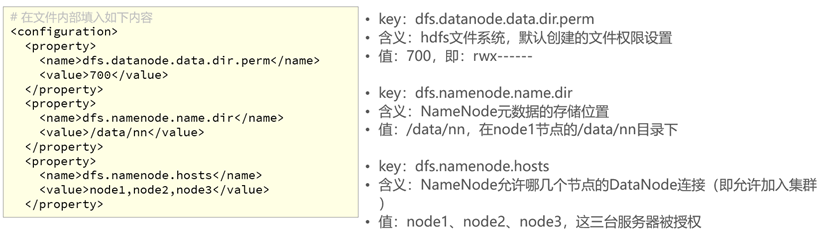

进入目标文件
#编辑hdfs-site.xml文件
vim hdfs-site.xml配置内容
# 在文件内部填入如下内容
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
# 续接左部
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>准备数据目录
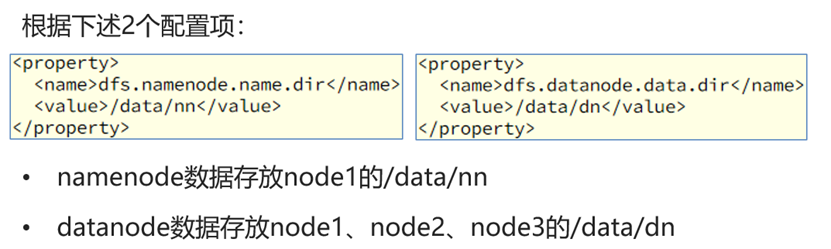
由于我们规划将node1作为namenode节点,将node1、node2、node3作为datanode节点,所以对于namenode存放数据的文件夹必须要在node1创建,而datanode存放数据的文件夹必须要在这三个node上均创建。
node1
mkdir -p /data/nn
mkdir /data/dnnode2、node3
mkdir -p /data/dn分发hadoop文件夹

分发
分析分发文件
这是node1的/export/server目录:

我们之前有提到过,软连接相当于建立了一个快捷方式,因此我们使用scp进行分发时,只能够将原文件发送给另外两个节点,否则就相当于仅仅是复制了快捷方式而没有其余程序,hadoop将无法运行!
在node1上执行分发命令
# 在node1执行如下命令
cd /export/server
scp -r hadoop-3.3.4 node2:`pwd`/
scp -r hadoop-3.3.4 node3:`pwd`/配置软连接
在node2、node3上执行建立软连接命令
# 在node2、node3执行如下命令
ln -s /export/server/hadoop-3.3.4 /export/server/Hadoop配置环境变量
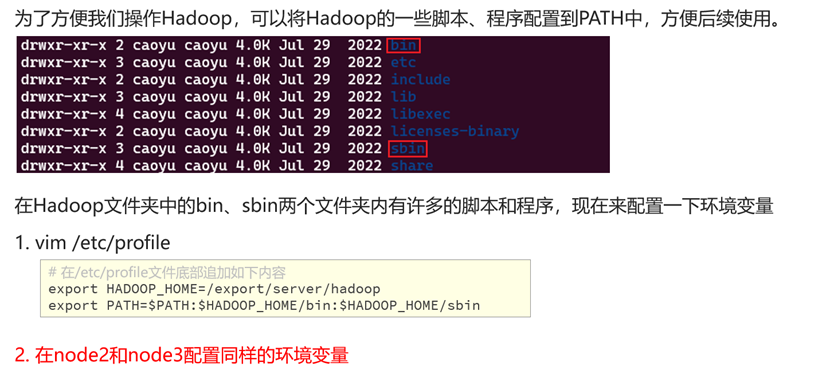
进入目标文件
vim /etc/profile配置内容
# 在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin刷新环境变量
source /etc/profile授权为hadoop用户
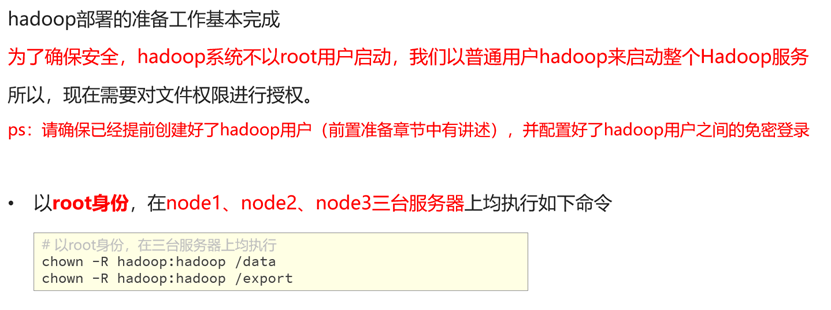
授权原因

我们不能直接通过root用户直接操作hadoop,否则若遭遇攻击,那么最高权限就将被获取,这是极其危险的。所以我们需要使用我们先前创建的hadoop用户去操作hadoop。
但是我们通过“ll”查看/export/server目录会发现,hadoop文件夹的所属权和操作权均属于root用户,这就代表了hadoop用户是无法对其进行操作的。因此我们需要以root身份对hadoop用户进行授权,使其可以操作hadoop。
执行命令
# 以root身份,在三台服务器上均执行
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export启动hadoop
初始化文件系统
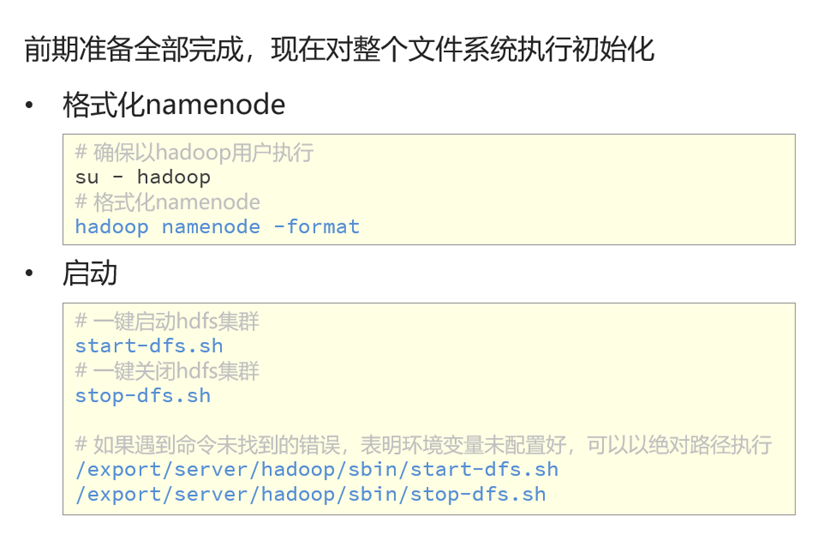
格式化namenode(在node1上)
# 确保以hadoop用户执行
su - hadoop
# 格式化namenode
hadoop namenode -format启动hdfs集群(在node1上一键启动)
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh
# 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh启动成功的提示

通过”jps“查看启动后运行的java进程
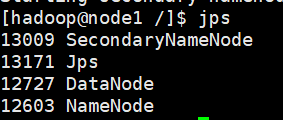
可以看到,node1节点中,SecondaryNameNode、NameNode、DataNode,这与我们对node1的规划是相符的。
同理可以查看node2、node3:
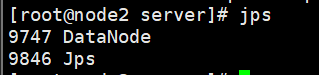
DataNode进程成功运行,说明hdfs启动成功!
查看HDFS WEBUI
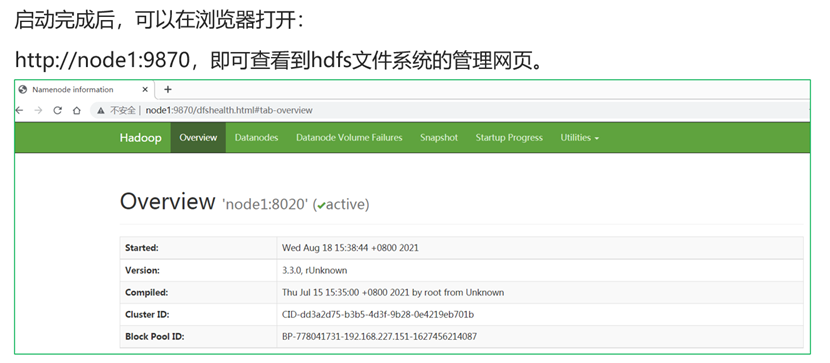
注意,这个网站位于namenode服务器的9870端口。由于我们之前配置了主机名映射(即可以通过主机名找到IP),因此此处直接访问node1:9870即可(node1为namenode所在节点)。
准备快照
关闭集群(必须,且务必在namenode节点的hadoop用户下执行)
# 一键关闭hdfs集群
stop-dfs.sh退回root账户 & 关机
#退回root账户
su –
#关机
init 0快照拍摄
常见问题汇总
权限

环境变量
workers文件

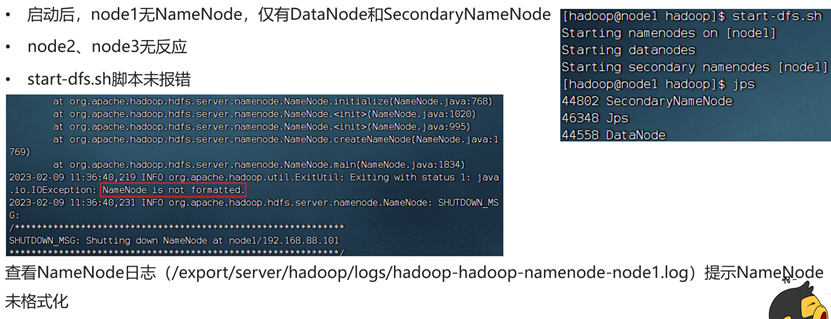
未格式化
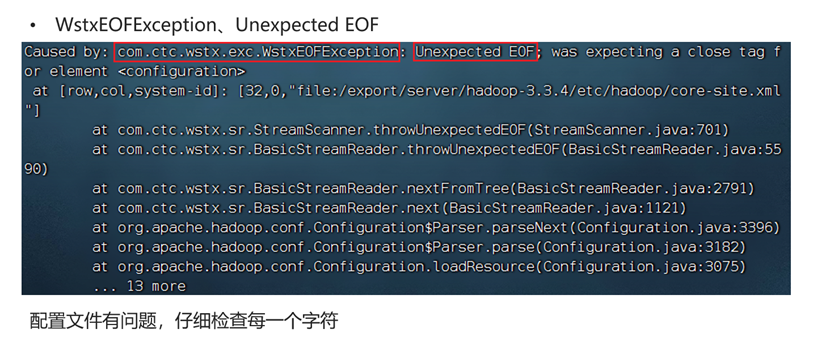
配置文件错误
HDFS的shell操作
进程启停管理
一键启停脚本
$HADOOP_HOME/sbin/stop-dfs.sh一键启动
$HADOOP_HOME/sbin/start-dfs.sh一键停止
$HADOOP_HOME/sbin/stop-dfs.sh脚本原理
回顾我们集群的规划以及配置文件的内容:我们将node1作为namenode、secondarynode节点的所在服务器,在hadoop集群所有服务器的workers文件中指定了集群所有的datanode,并且在集群所有服务器的core-site.xml核心配置文件中指定了集群节点的namenode(也就是node1)。
当我们执行一键启动脚本时,将会首先开启secondarynode(与启动其余服务器关联实际不大,但在脚本中设置了优先启动),然后读取core-site.xml核心配置文件找到namenode节点然后启动,最后读取workers配置文件启动所有的datanode。
当我们执行一键停止脚本时,将会关闭secondarynode,读取core-site.xml找到namenoode然后停止,最后读取workers配置文件关闭所有的datanode。
单进程启停

脚本1:$HADOOP_HOME/sbin/hadoop-daemon.sh
使用方法:
hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode)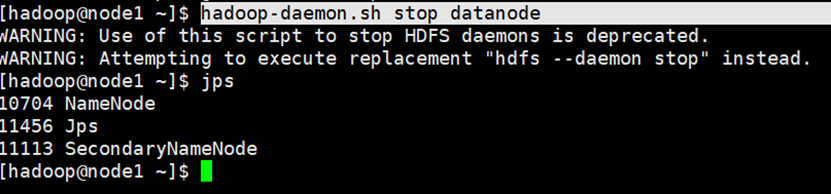
脚本2:$HADOOP_HOME/bin/hdfs
使用方法:
hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)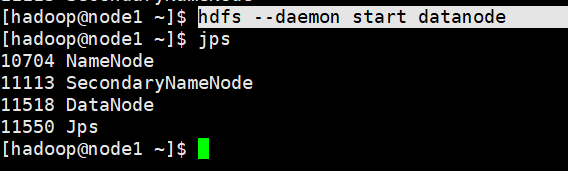
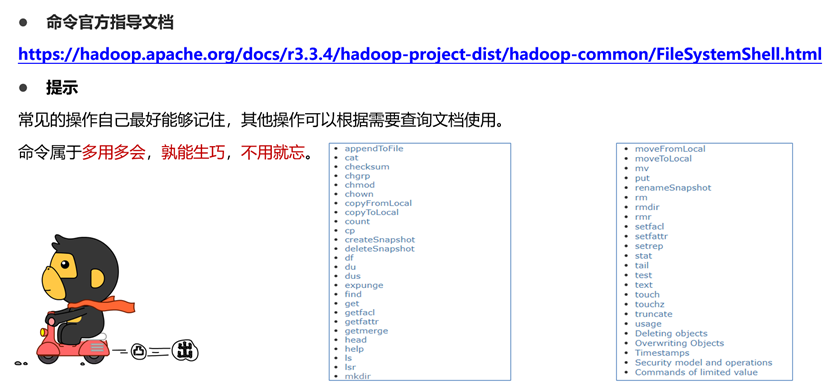
文件系统操作命令
HDFS文件系统基本信息
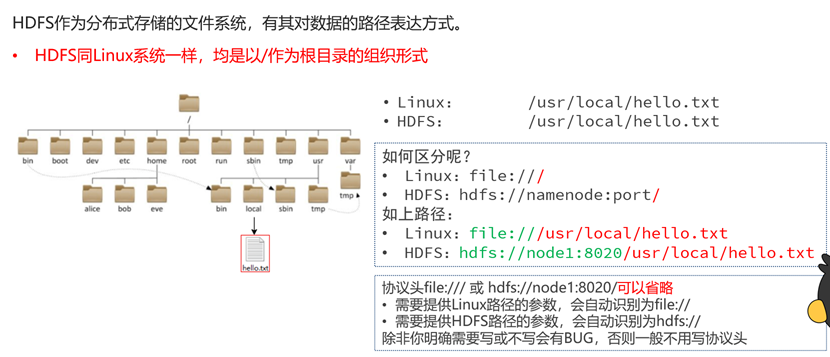
协议头可以省略的原因
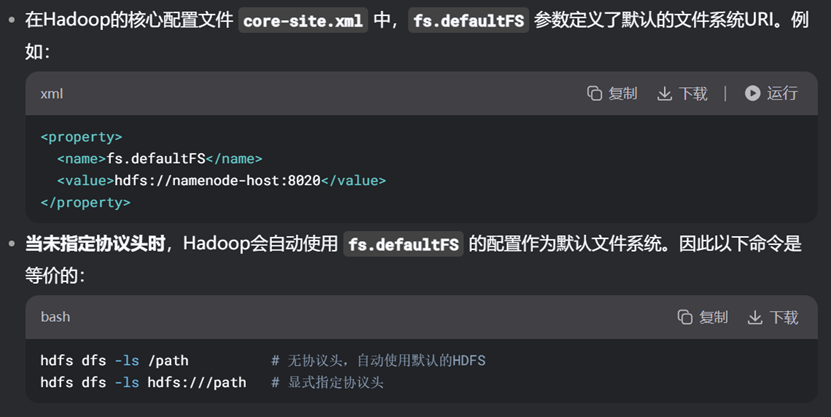 我们在core-site.xml的namenode配置中同时指定了使用fs.defaultFS配置作为默认文件系统,而该配置会自动识别是否为hdfs环境的文件,若是则会自动补全协议头。
我们在core-site.xml的namenode配置中同时指定了使用fs.defaultFS配置作为默认文件系统,而该配置会自动识别是否为hdfs环境的文件,若是则会自动补全协议头。
我们可以简单理解为:当我们在hdfs环境中,想要操作hdfs环境内文件则无需携带协议头;但若想操作linux系统文件,则需要携带linux协议头。
常用基础操作命令
介绍

创建文件夹

命令
老版:hadoop fs -mkdir [-p] <path> ...
新版:hdfs dfs -mkdir [-p] <path> ...演示

我们没有加协议头,因此次文件夹将会被默认建立在hdfs系统中。
查看指定目录下内容
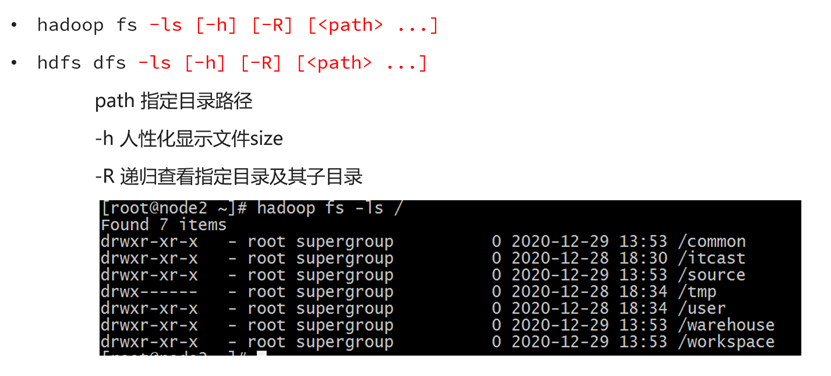
命令
老版:hadoop fs -ls [-h] [-R] [<path> ...]
新版:hdfs dfs -ls [-h] [-R] [<path> ...]演示

上传本地文件到hdfs指定文件目录下

命令
老版:hadoop fs -put [-f] [-p] <localsrc> ... <dst>
新版:hdfs dfs -put [-f] [-p] <localsrc> ... <dst>演示

由于此处想要将linux系统下的文件上传到hdfs系统,所以为两个路径都加上了协议头用以区分。
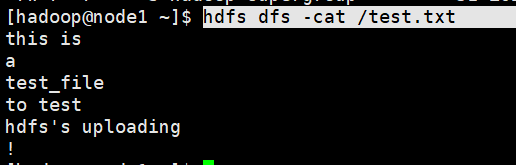
查看hdfs文件内容
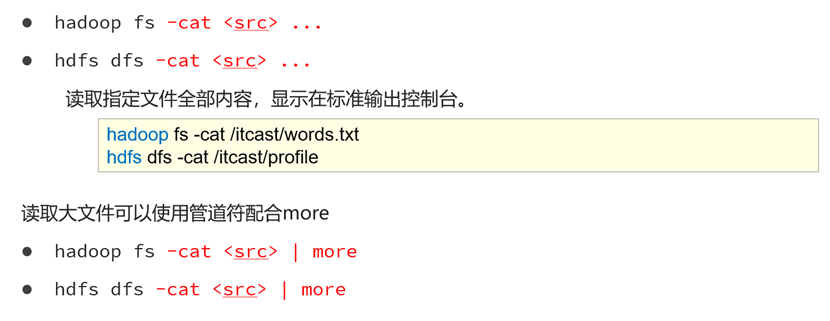
命令
老版:hadoop fs -cat <src> ...
新版:hdfs dfs -cat <src> ...演示
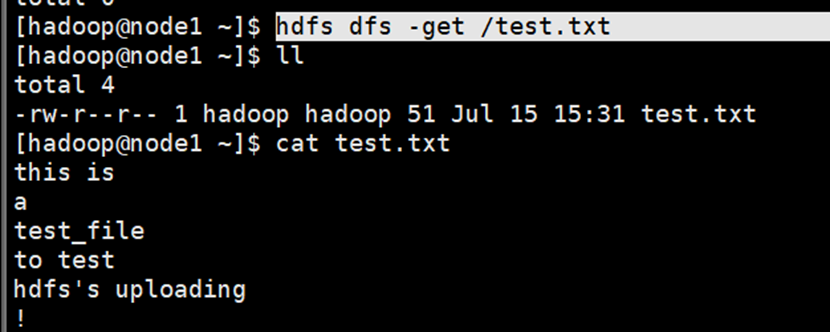
下载hdfs文件到本地目录
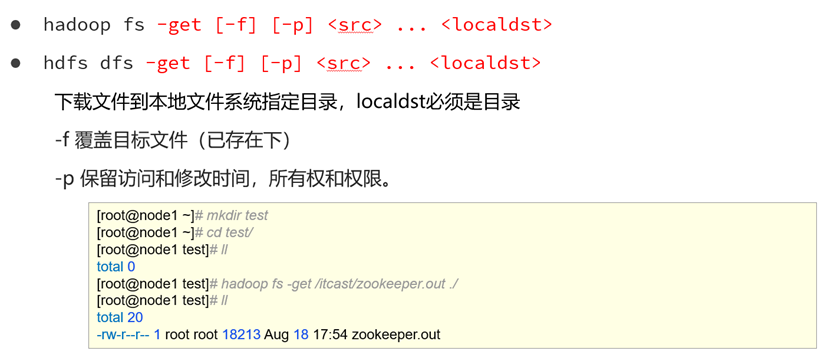
命令
老版:hadoop fs -get [-f] [-p] <src> ... <localdst>
新版:hdfs dfs -get [-f] [-p] <src> ... <localdst>演示
在hdfs中拷贝hdfs文件
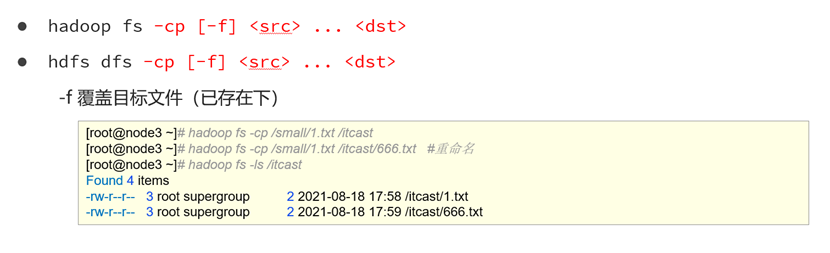
注意!拷贝文件只能在hdfs内部进行,也就是说只能将hdfs内文件拷贝都hdfs路径!
命令
老版:hadoop fs -cp [-f] <src> ... <dst>
新版:hdfs dfs -cp [-f] <src> ... <dst>演示

此处不仅拷贝,同时对文件进行了更名。
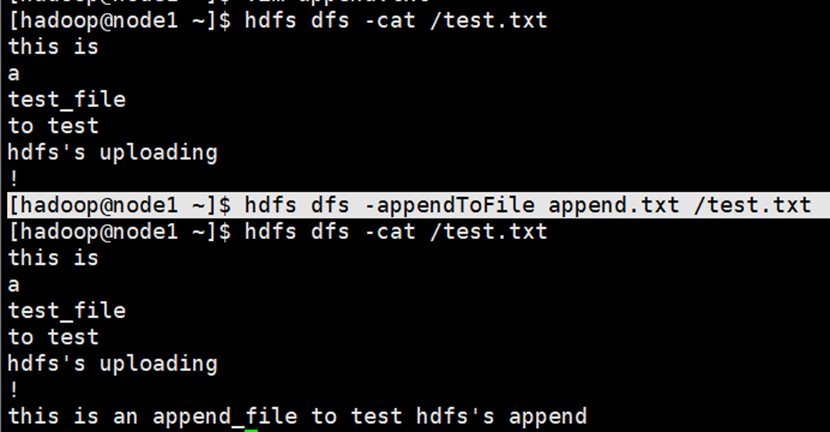
追加本地文件数据到hdfs文件中
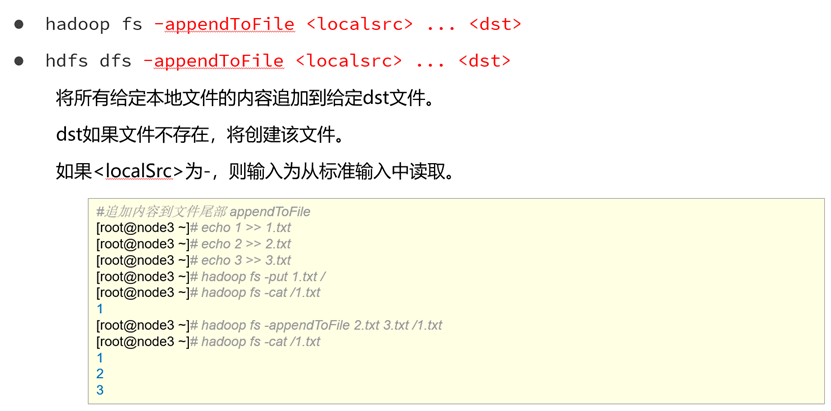
需要注意的是,hdfs中无法对文件的某一行进行修改,只能通过追加或者删除文件来达到修改文件的效果。
命令
老版:hadoop fs -appendToFile <localsrc> ... <dst>
新版:hdfs dfs -appendToFile <localsrc> ... <dst>演示
移动 & 重命名hdfs文件

命令
老版:hadoop fs -mv <src> ... <dst>
新版:hdfs dfs -mv <src> ... <dst>演示

删除hdfs数据

若是删除文件夹,记得加上”-r”递归删除文件夹所有内容!
命令
老版:hadoop fs -rm -r [-skipTrash] URI [URI ...]
新版:hdfs dfs -rm -r [-skipTrash] URI [URI ...]演示

hdfs shell其他命令
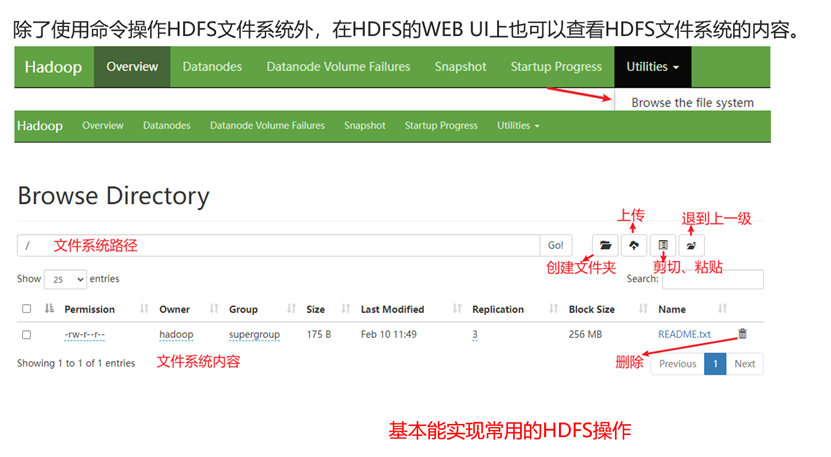
通过HDFS WEBUI操作文件系统
基础文件操作
HDFS WEBUI的权限问题
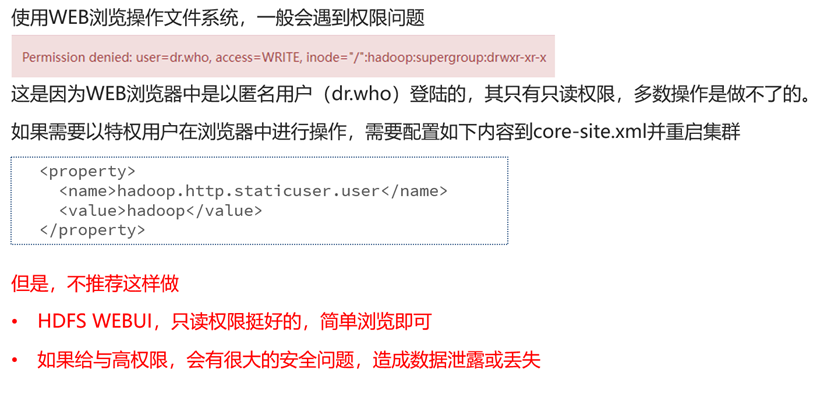
HDFS权限不足问题
HDFS超级用户

HDFS修改权限

#修改所属用户和组:
老版:hadoop fs -chown [-R] root:root /xxx.txt
新版:hdfs dfs -chown [-R] root:root /xxx.txt
#修改权限
老版:hadoop fs -chmod [-R] 777 /xxx.txt
新版:hdfs dfs -chmod [-R] 777 /xxx.txt总结

HDFS客户端
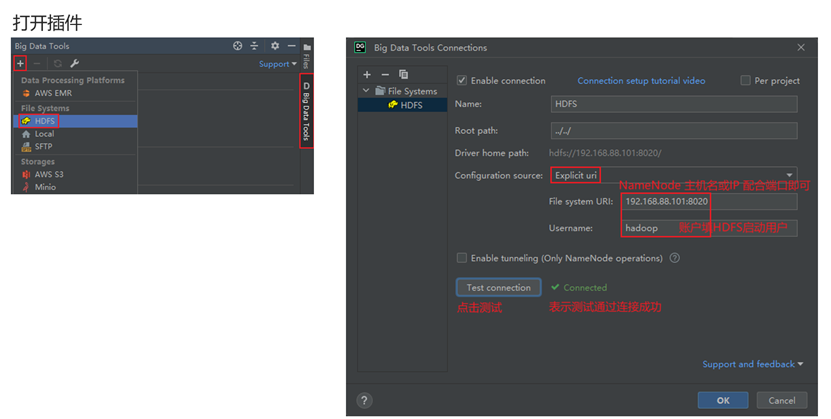
Jetbrins插件产品:Big Data Tools
Big Data Tools

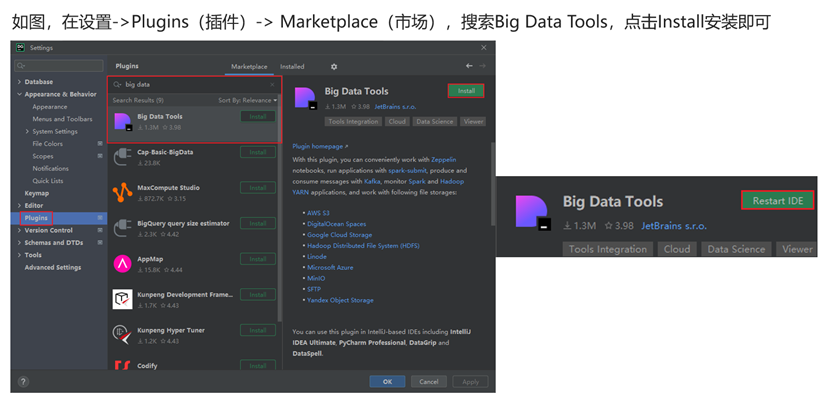
配置windows

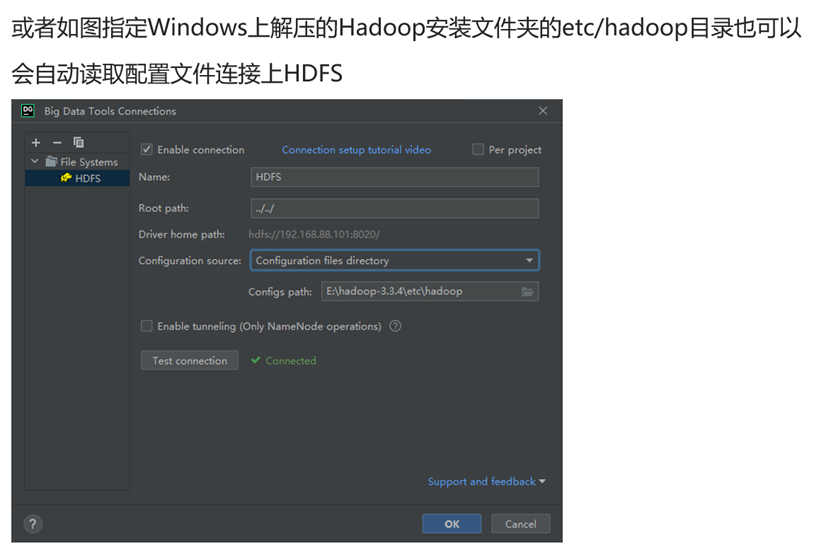
配置Big Data Tools插件
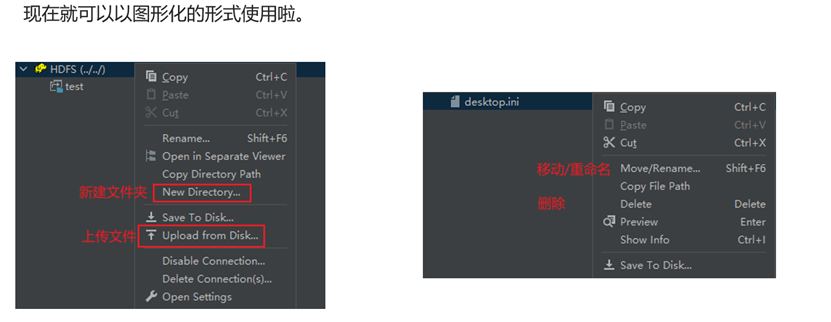
使用Big Data Tools插件
NFS
NFS介绍
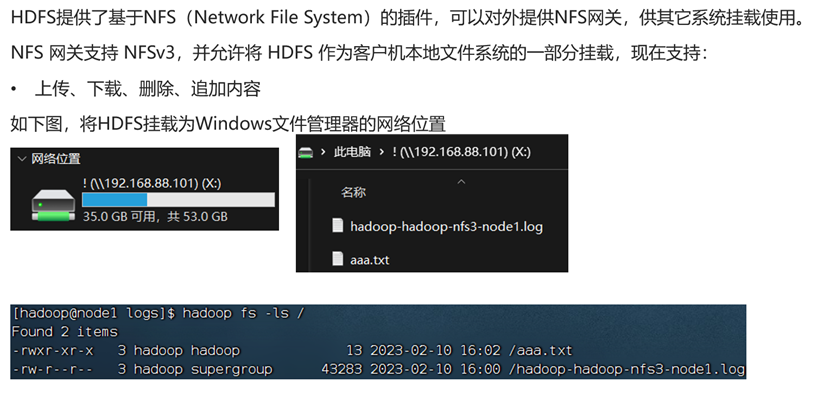
配置NFS
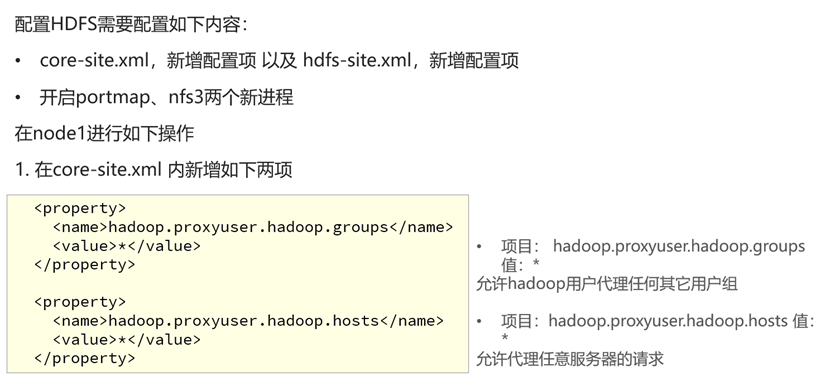
启动NFS功能

检查NFS是否正常

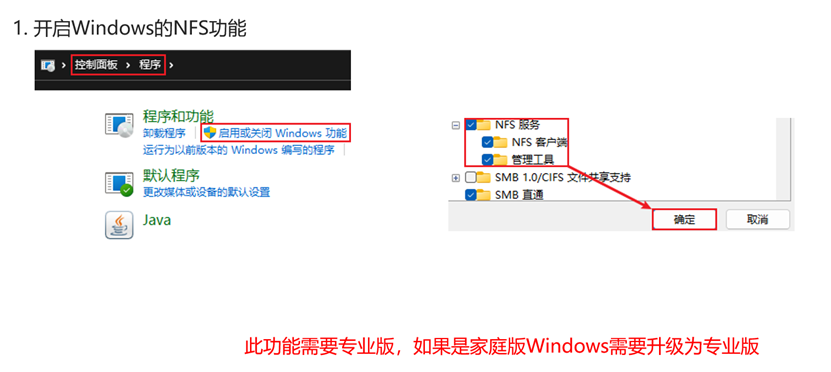
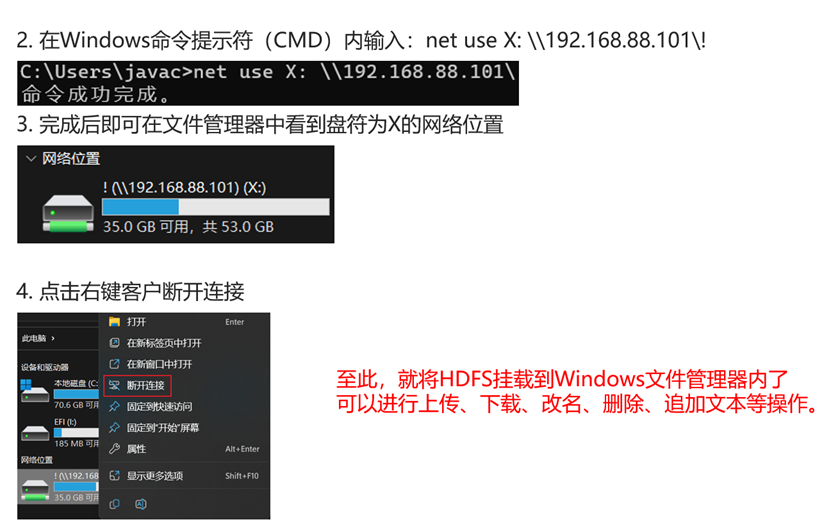
在windows配置NFS
HDFS的存储原理
存储原理
- 数据存入HDFS时是分布式存储,每个服务器节点负责数据的一部分。假设我有一个3MB大小的文件,此时HDFS集群有三台服务器,那么每台服务器就可以负责存储1MB的数据(大小可以不固定)。在取出数据时,就从三台服务器分别获取数据,再进行整合即可。
- 数据不仅在存入HDFS时是分布式存储,每一部分数据在当前服务器中也是分block块存储的。在1中我们已经将3MB文件分为了三个1MB文件,那么对于每一个1MB的文件,可以划分为4个block块,每一块负责存储一部分数据。
- 为了避免服务器宕机导致数据丢失,可以为block块设置备份,即副本。但需要注意,这些备份不应存放于同一服务器上!
Fsck命令
配置HDFS数据块的副本数量
默认HDFS的副本数量

配置内容
#hdfs-site.xml中
<property>
<name>dfs.replication</name>
<value>3</value>
</property>设置临时副本数

新文件的临时副本数指定
hadoop fs -D dfs.replication=临时副本数 -put 上传到hdfs的文件名 上传的指定目录已有文件的副本数修改
hadoop fs -setrep [-R] 存储副本数 path演示
以2个临时副本数上传

修改已有文件的副本数

通过fsck命令检查文件副本数

命令
hdfs fsck path [-files [-blocks [-locations]]]演示
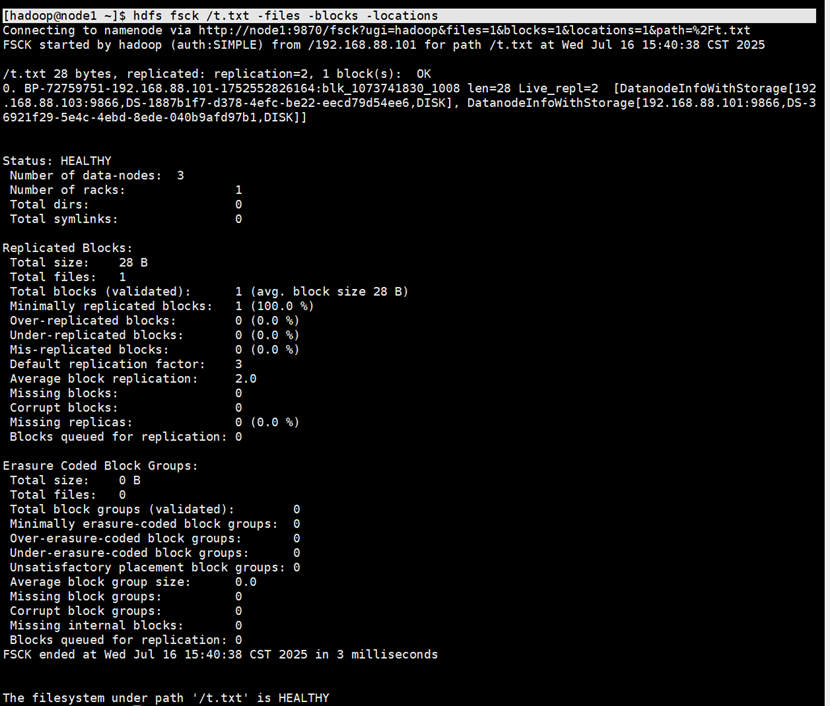
设置块的大小

配置内容
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description>设置HDFS块大小,单位是b</description>
</property>总结

NameNode元数据
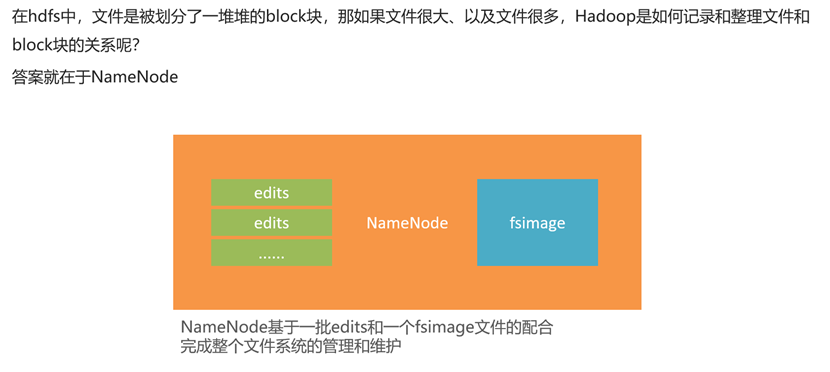
edits文件

我们可以将edits文件同redis的aof文件进行类比,是一个记录hdfs操作的日志文件。当服务器宕机或其他错误情况发生,就可以通过查看edits文件对hdfs进行恢复。

那么既然edits会记录每一次进行的操作,随着时间推移,edits文件必然是逐渐增大的。而edits又是hdfs检索的重要依据,若查看的edits过大,就会浪费检索时间。

因此我们需保证hdfs不能过大,就需要多个edits文件进行拓展。然而,虽然多个edits文件能够保证hdfs检索时间的缩短,但是假设若同一个文件被多次操作,且操作信息被记录到了不同的edits文件中,我们就不能只检索一个edits文件,而需要对所有edits文件进行检索,效率也非常之低。
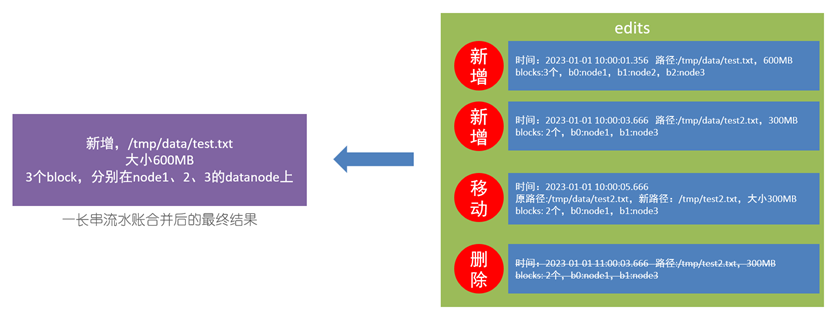
我们将多个edits文件进行合并,来获取对文件的完整操作。而edits文件合并后的文件,就是fsimage文件,也就是下文的介绍对象。
fsimage文件
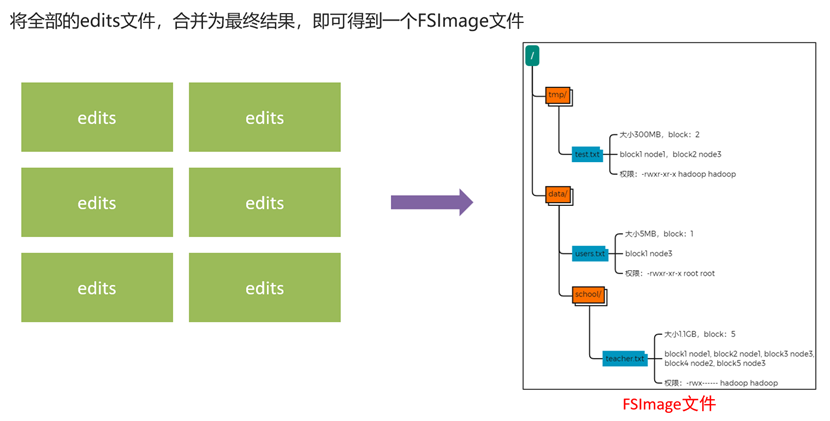
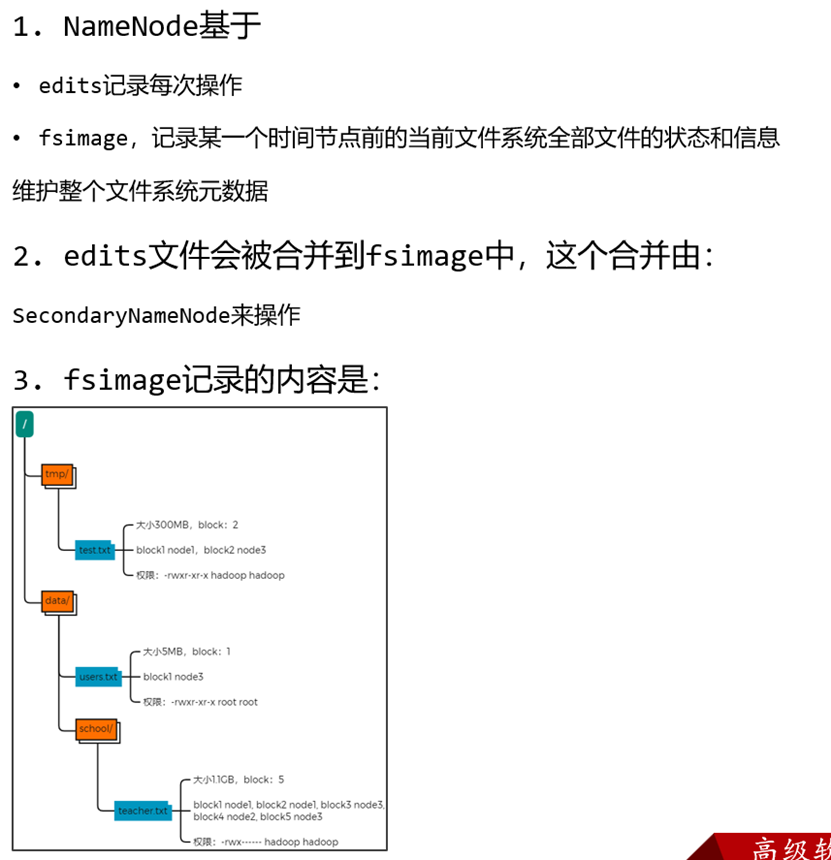
我们可以将其理解为某个时间点下hdfs的状态,包括各个文件数、所在位置、文件大小等等。
NameNode元数据管理
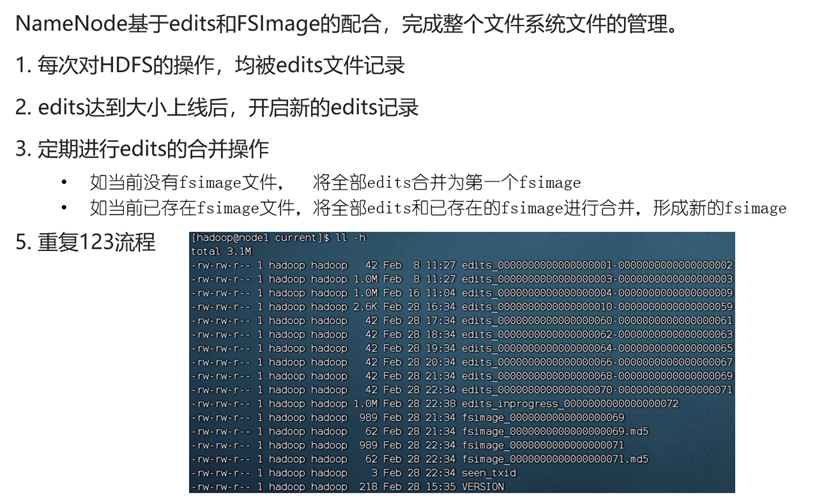
fsimage文件只会存在一个,每一次都是将旧的fsimage文件与所有edits文件合成,以形成新的fsimage文件。
元数据合并的定期参数

由于fsimage是定期合成的,且fsimage可以理解为某个时刻的hdfs状态,因此在进行某个时段数据检索时,将会优先查看fsimage文件,若fsimage文件中没有相关信息,才会去查询edits文件。
如:最新的fsimage记录的是5min前的hdfs状态,那么查看5min前的hdfs状态只需要查看fsimage即可,因为它代表了5min前的最终状态。但若想要查看1min前的hdfs状态,由于fsimage并没有记录,因此只能将edits文件进行检索。
SecondaryNameNode的作用
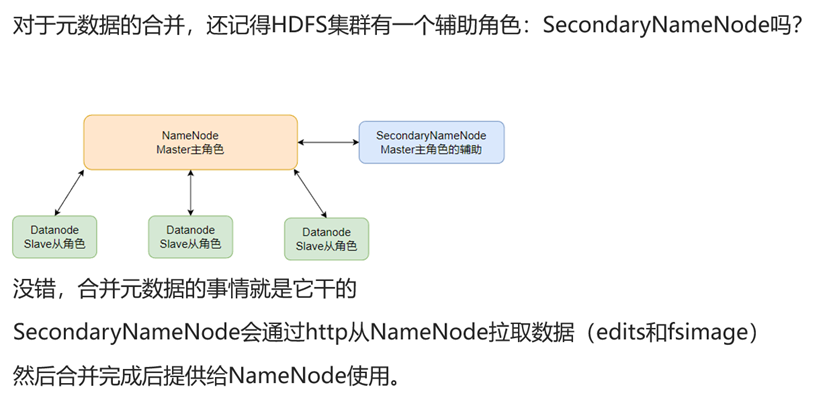
NameNode只负责将操作写入edits文件,不负责将edits合成为fsimage,这些是由SecondaryNameNode进行的。
SecondaryNameNode会通过http协议从NameNode拉取edits和已经生成的fsimage,然后合并为新的fsimage提供给NameNode使用。
SecondaryNameNode是非常重要的,如没有SecondaryNameNode,edits将会不断增多,且无法被合并。这就能够解释在一键启停时,为什么是先启动SecondaryNameNode,然后才是启动NameNode和DataNode。
总结
HDFS数据的读写流程
数据写入流程
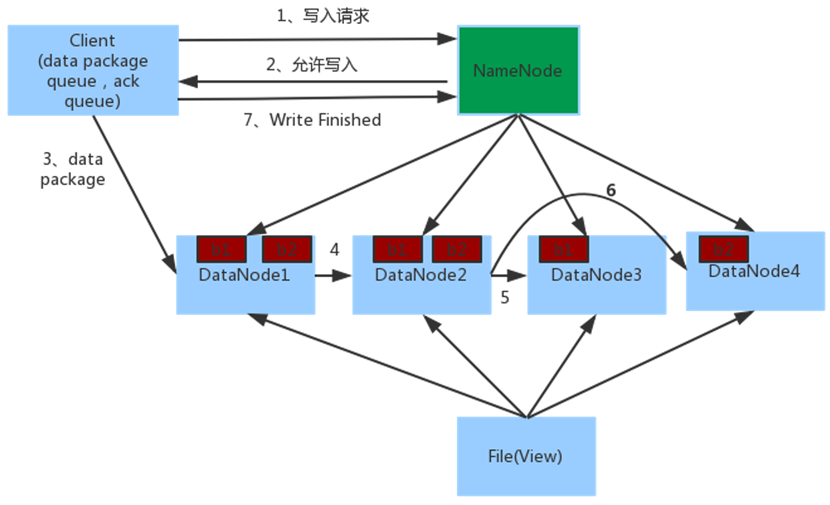
流程解析
- 首先,客户端需要向NameNode发起数据写入的请求。
- NameNode审核客户端是否有写入权限、hdfs空间是否充足等条件后,如条件允许,那么就允许客户端写入,同时将其管理的其中一个DataNode地址给客户端。
- 客户端接收到DataNode地址后,向该DataNode进行数据写入。
- 被写入数据的DataNode接收数据并且准备副本,开始将这些数据同步给其余DataNode。
- 这些数据不仅由一个DataNode完成传播,这几个DataNode之间可以通过pipeline进行通信,互相传递副本信息。
- 写入完成后,客户端将会通知NameNode,然后NameNode开始向edits文件中写入信息,记录日志。
关键要点
- NameNode并不负责数据的写入,他只负责对客户端的审核以及元数据的记录。
- 既然NameNode不负责数据写入,那么客户端就会直接对DataNode进行数据写入。同时,这个DataNode将会是离客户端网络距离最近的。
- 数据副本的传递由DataNode之间自行完成。构建一个PipLine,按顺序复制分发。
数据读取流程
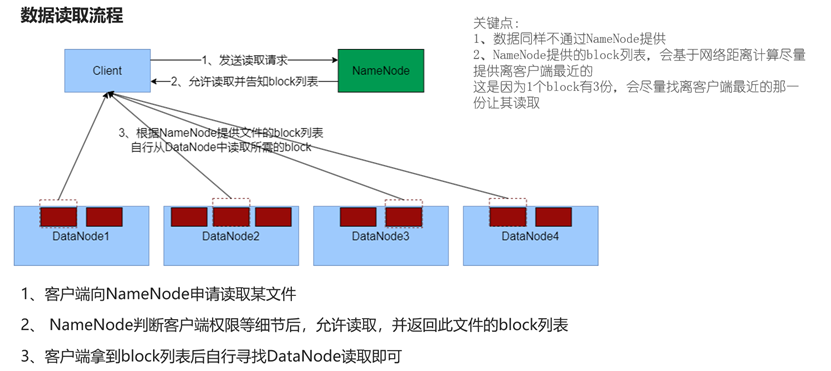
由于hdfs内部,文件将会被分为到不同的block进行存储,因此当想要读取完整文件时,就需要存储了该文件的所有block块信息,也就是block列表。
同样的,NameNode不提供数据,仅负责审核、提供block列表,由通过审核后的客户端自行读取数据。而由于block是存在数据副本的,所以这个block可能会在多个DataNode上,因此这份block列表将会由NameNode根据离客户端的网络距离进行提供(提供最近的)。
由于读取操作不涉及对hdfs文件的变动,因此NameNode不需要记录edits文件。
总结

分布式计算和资源调度
分布式计算概述
什么是计算

什么是分布式计算

分布式计算模式

分散——>汇总模式
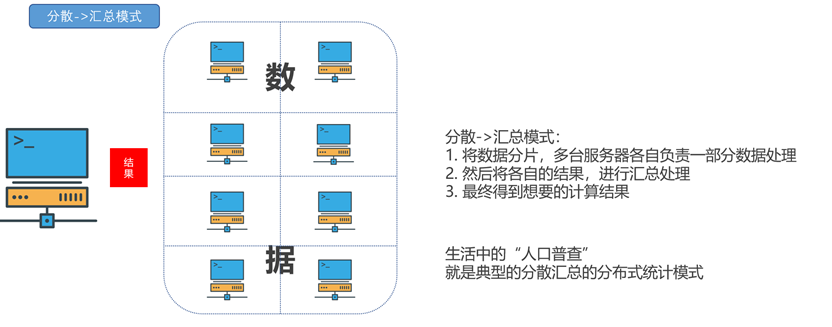
对数据分片,每台机器负责一部分数据,最后将数据汇总整合作为计算结果。适合逻辑较简单的数据计算任务。
Hadoop的MapReduce属于该模式。
中心调度——>步骤执行模式
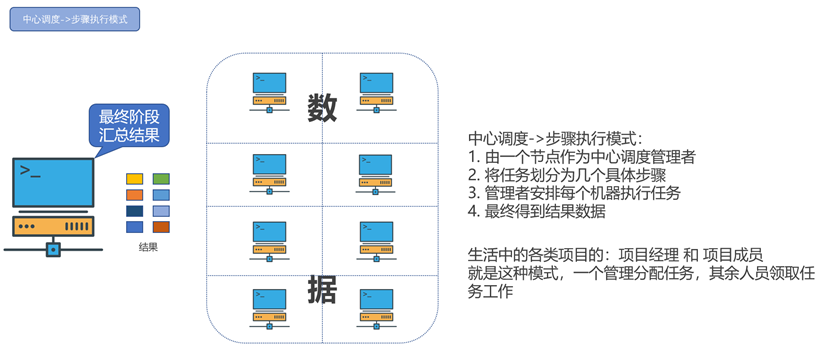
此模式与分散汇总的区别在于,其存在多次的服务器间中间计算结果的交换。此模式下,中心调度者为每个服务器分配不同的计算任务,作为当前步骤所需执行的任务。当服务器计算完成后,交换数据,进行下一步任务,直到最后的数据汇总。
Spark、Flink框架等属于该模式。
总结

MapReduce概述
MapReduce与Hadoop的关系
为Hadoop三大组件中的分布式计算组件。
MapReduce介绍

可以类比java的stream流。可以通过.map()方法对流中的数据进行自定义的操作,然后通过.collection()对操作后的数据进行封装,并且终结这个流。
MapReduce执行原理
需求案例
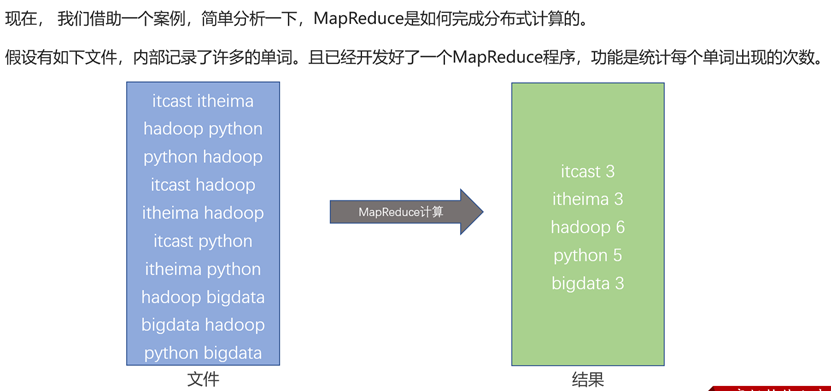
执行过程
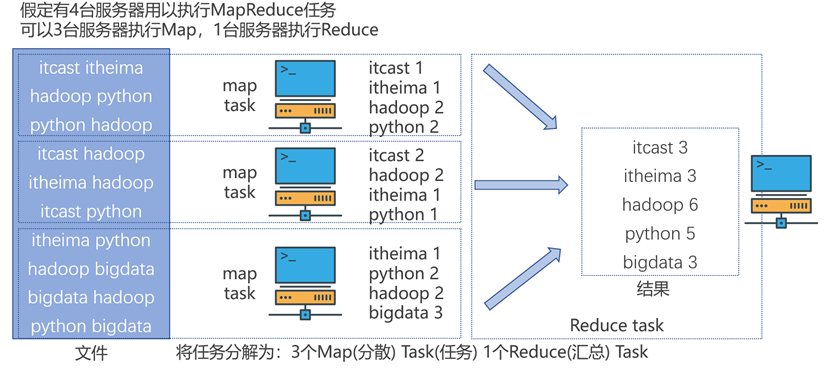
- 进行服务器规划:4台服务器,使用3台执行map,1台执行reduce。
- Map任务:将文件分为3部分(对应3台map服务器),每个服务器分别统计这部分文件中的单词出现次数。
- Reduce任务:3台服务器的map任务(即统计单词次数)执行完成后,将各部分结果汇总给汇总服务器,汇总服务器执行reduce任务,将各部分的词进行整合、统计,作为最终结果返回。
总结



YARN概述
MapReduce & YARN的关系前瞻

YARN与Hadoop的关系

关于资源调度
什么是资源调度

资源调度的意义

程序的资源调度

由于不同程序对于每个资源使用情况不同,但是其自身并不会按需拿去,而是有多少用多少。为了提供资源的利用率,就需要对程序进行调度,为不同程序分配最合适的资源,来提升资源利用率。
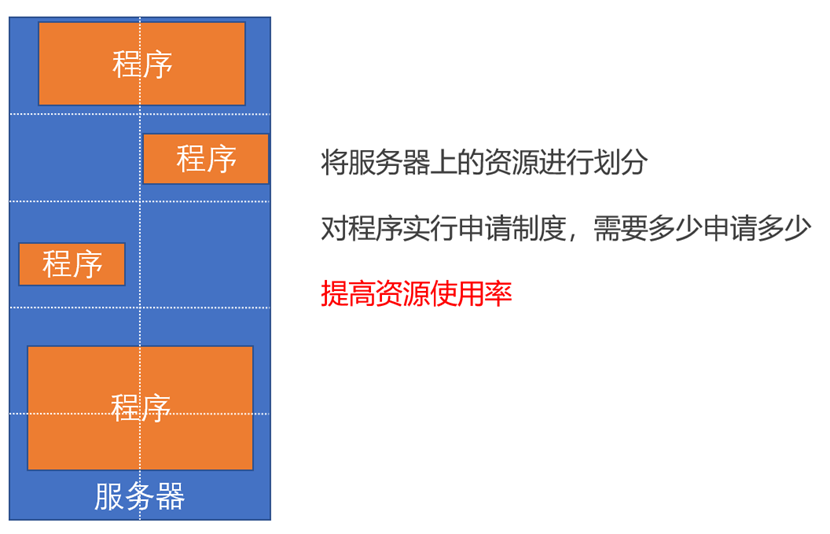
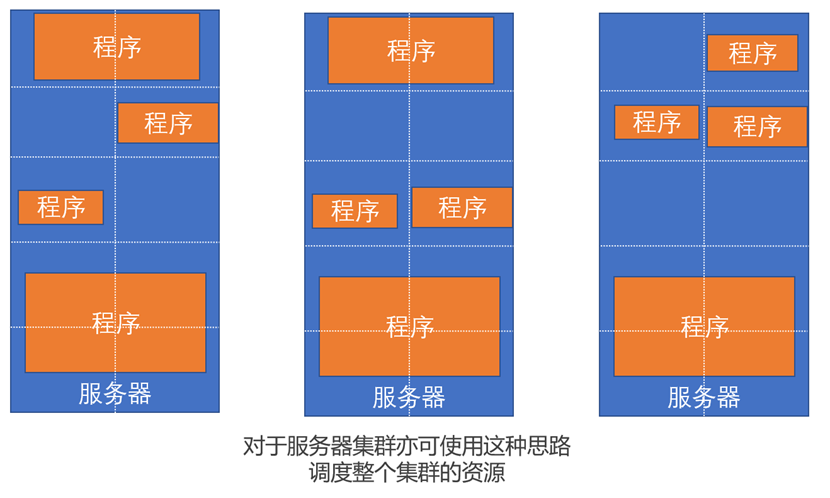
由于程序对资源需求不同,但是程序不会按需拿去,所以我们需要对资源进行划分,不同数量的资源对应需要这些数量资源的程序。对于程序而言,其需要事先告知管理者所需的资源数,然后由管理者分配对应资源。
这个资源分配不仅在单机环境可以实现,在服务器集群中也可以实现。不过在服务器集群中,管理者不仅仅需要对每个服务器的进程进行资源调度,也要对多个服务器进行资源调度。在Hadoop集群中,这个管理者角色就是由YARN所扮演的。
YARN的资源调度

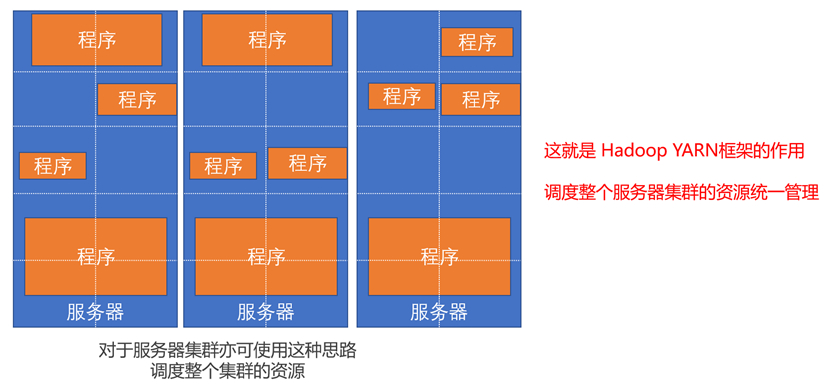
YARN & MapReduce协作的需求案例

资源调度流程
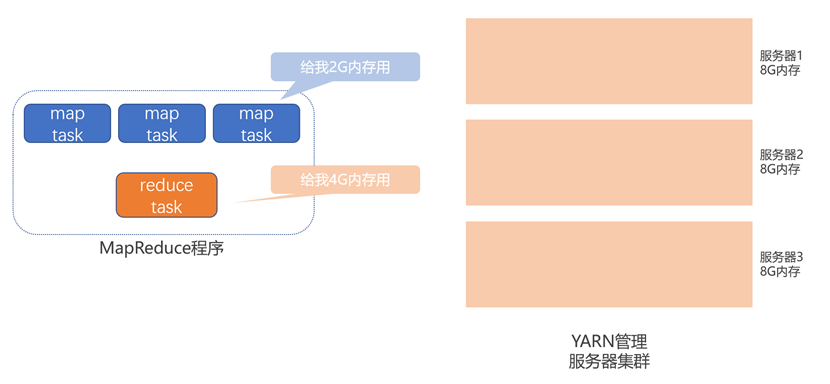
Map任务和Reduce任务程序分别向YARN申请资源。
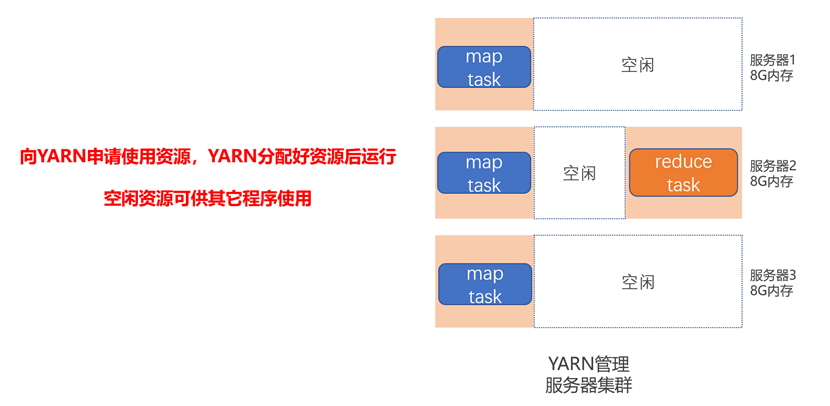
YARN接收到程序对资源的请求后,检查空间资源并且进行划分,然后调度相应的map & reduce任务程序运行。
总结

YARN架构
YARN的核心架构
YARN架构 & HDFS架构类比
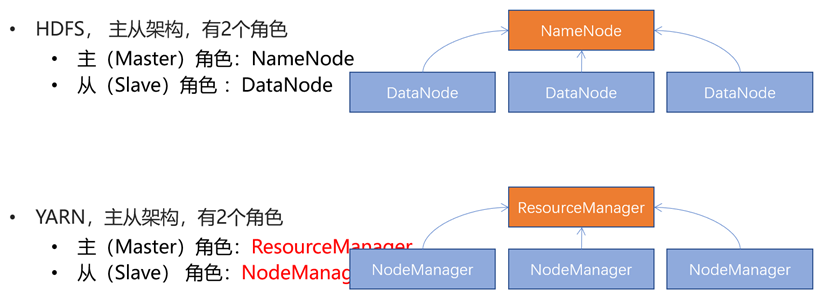
YARN核心架构角色解析
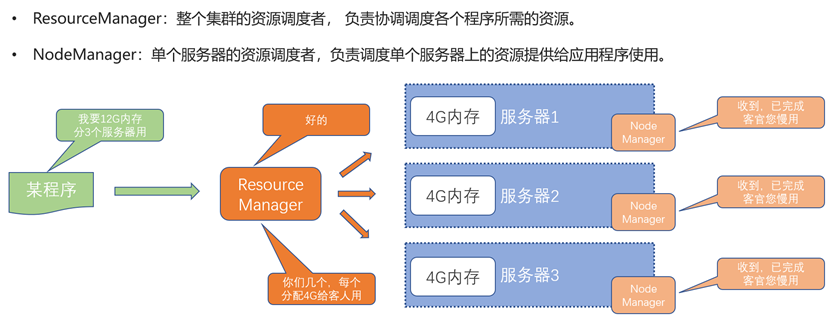
一个集群是由多个服务器构成的,而服务器内又有独自运行的程序。这就需要对不同服务器进行资源调度(将总资源划分给不同服务器),对服务器内不同程序进行资源调度(将服务器资源划分给不同程序)。
ResourceManager负责集群全部资源的管理,由其分配不同大小的资源给不同的服务器。不同服务器上的NodeManager获取到分配的资源后,就负责管理这些资源,分配给服务器上不同程序。
YARN资源调度的实现分析
YARN资源调度的疑问
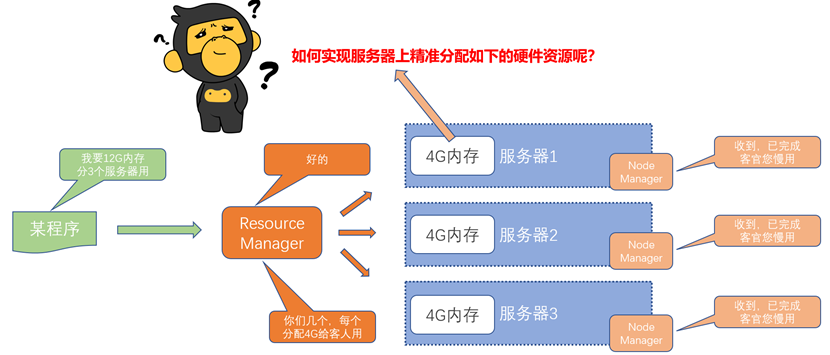
YARN容器
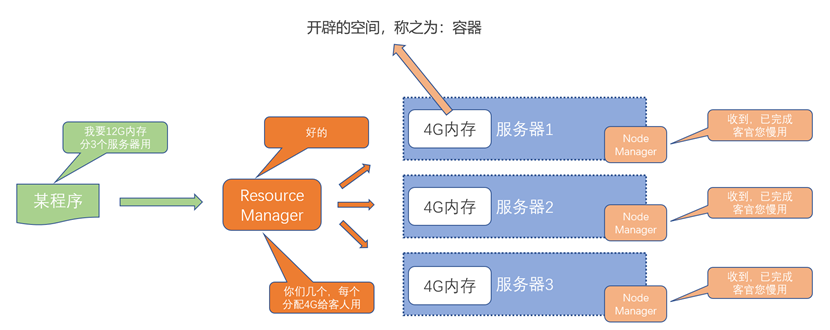
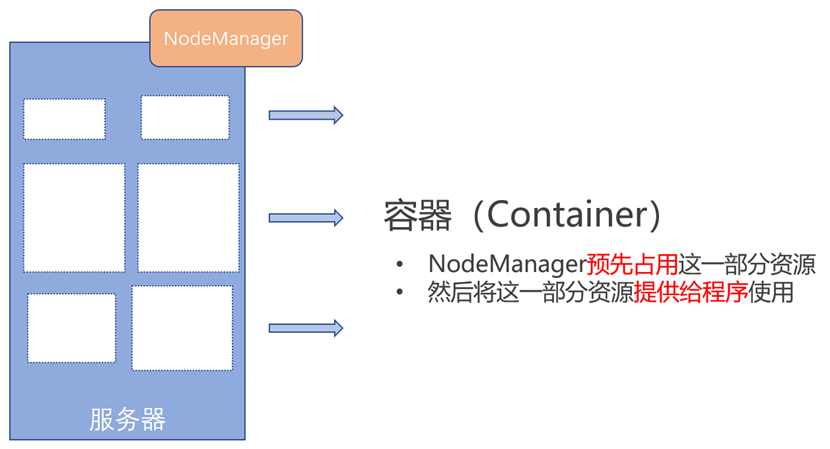
YARN通过NodeManager提前占用服务器所需资源,来进行资源的分配。我们可以理解为,NodeManager根据服务器、程序需求提前占据了资源,形成一个容器,防止其余服务器、程序抢占这部分资源。然后等目标服务器、程序到来,进入抢占的资源内部使用这些资源。
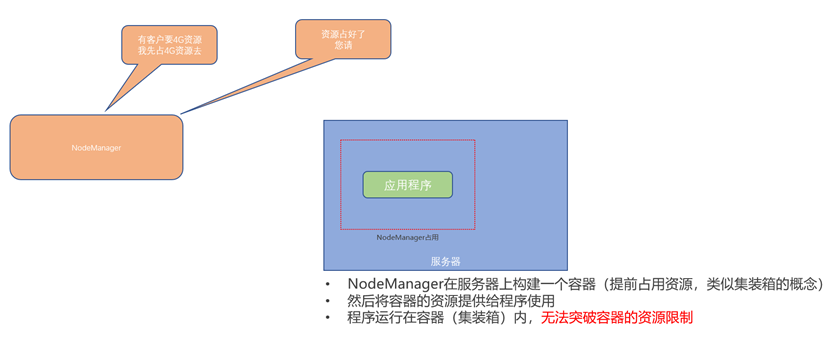
需要注意的是,服务器内程序运行时,是无法向容器外申请资源的。可以理解为,容器不仅提前占据资源防止其余程序抢占,也同时限制了当前程序对资源的使用。
总结

YARN的辅助架构
YARN的辅助架构介绍

YARN的辅助架构角色
代理服务器(ProxyServer)
功能介绍

部署介绍

历史服务器(JobHistoryServer)
功能介绍

关于历史服务器的疑问分析
疑问

疑问分析——YARN运行机制
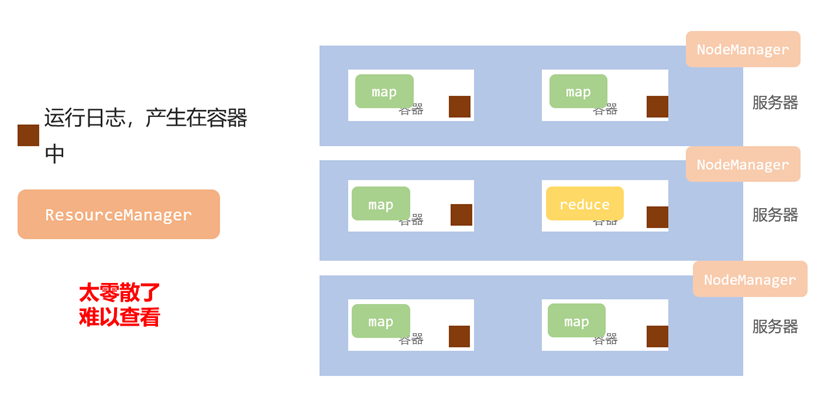
我们知道,YARN的资源调度实际上就是为每个服务器、每个程序分配容器,所以相应的,这些操作日志都将会产生在容器中,对于程序员来说需要根据命令对不同容器的日志进行获取,十分繁琐。为了解决这一问题,才诞生了历史服务器。
历史服务器对YARN运行机制的解决
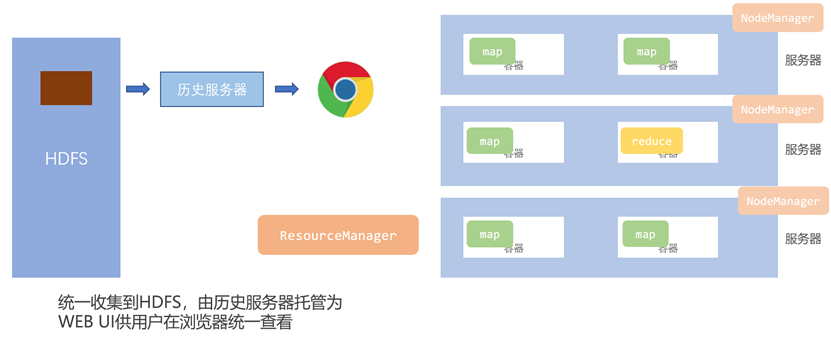
通过历史服务器,可以将不同容器的日志收集到HDFS中,让我们可以直接在WEB UI中进行查看。
部署介绍

总结

MapReduce & YARN的部署
部署前瞻
YARN & MapReduce需要启动的配置


我们前面提到,YARN是由核心架构(ResourceManager管理集群资源、NodeManager管理服务器资源)和辅助架构(ProxyServer用于提供网络代理、JobHistoryServer用于提供容器内的元数据“),所以我们需要对YARN配置这些进程。
但由于我们在这里把MapReduce放在了YARN环境下运行,也就是将MapReduce交给YARN管理,因此对于MapReduce来说,仅需修改配置,但无需启动任何进程。
Hadoop组件配置汇总

部署规划

我们会首先在node1服务器完成配置,然后将配置分配给node2、node3。
部署流程
首先进入hadoop文件夹
cd /export/server/hadoop/etc/hadoop/配置MapReduce

配置mapred-env.sh文件
export JAVA_HOME=/export/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA配置mapred-site.xml文件
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description></description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>配置YARN


配置yarn-env.sh
#设置JDK路径环境变量
export JAVA_HOME=/export/server/jdk
#设置HADOOP_HOME环境变量
export HADOOP_HOME=/export/server/Hadoop
#设置配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/Hadoop
#设置日志文件路径的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs配置yarn-site.xml
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<description></description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>node1:8089</value>
<description>proxy server hostname and port</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description></description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>Comma-separated list of paths on the local filesystem where logs are written.</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduce applications.</description>
</property>分配配置文件

scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3:`pwd`/YARN集群启动相关命令

一键启停脚本
#一键启动
$HADOOP_HOME/sbin/start-yarn.sh
#一键停止
$HADOOP_HOME/sbin/stop-yarn.sh原理
该原理与hdfs启动类似,会首先根据yarn-site.xml中配置的resourcemanager所在主机来启动ResourceManager,然后根据workers配置来启动NodeManager。
单机启停
#单机启停ResourceManager、NodeManager、ProxyServer
$HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager| proxyserver
#单机启停JobHistoryServser
$HADOOP_HOME/bin/mapred --daemon start|stop historyserver启动YARN集群实例
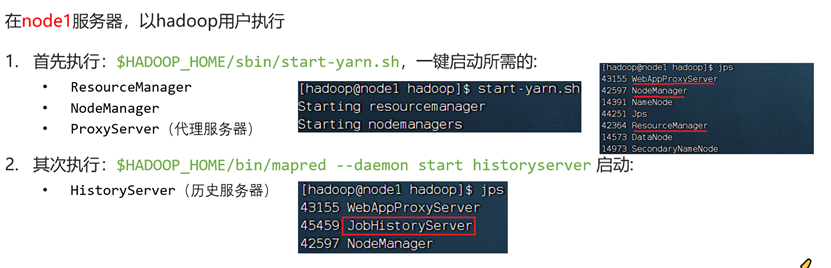
#node1执行
$HADOOP_HOME/sbin/start-yarn.sh
#node1、node2、node3执行
$HADOOP_HOME/bin/mapred --daemon start historyserver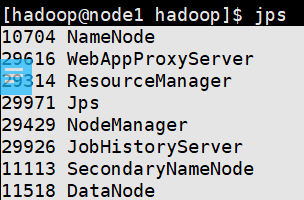
查看YARN WEBUI界面 & 快照保存

MapReduce & YARN的初步使用
YARN集群启动相关命令

一键启停脚本
一键启动
$HADOOP_HOME/sbin/start-yarn.sh
一键停止
$HADOOP_HOME/sbin/stop-yarn.sh原理
该原理与hdfs启动类似,会首先根据yarn-site.xml中配置的resourcemanager所在主机来启动ResourceManager,然后根据workers配置来启动NodeManager。
单机启停
单机启停ResourceManager、NodeManager、ProxyServer
$HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager| proxyserver
单机启停JobHistoryServser
$HADOOP_HOME/bin/mapred --daemon start|stop historyserver注意事项
JobHistoryServer只能够单独启动,包括一键启停脚本,也必须单独再启动JobHistoryServer。
启动YARN集群实例
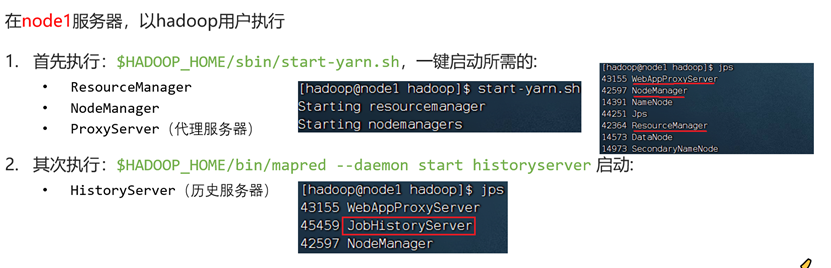
#node1执行一键启动脚本
$HADOOP_HOME/sbin/start-yarn.sh
#node1、node2、node3执行历史服务器启动
$HADOOP_HOME/bin/mapred --daemon start historyserver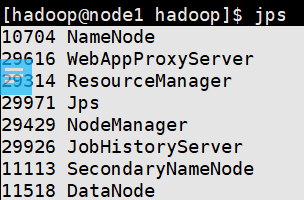
提交MapReduce任务到YARN中执行
常见的运行在YARN框架的程序

MapReduce预制代码


程序位置
cd /export/server/hadoop/share/hadoop/mapreduce/
运行程序命令
hadoop jar 程序文件 java类名 [程序参数] ... [程序参数]单词计数器wordcount
单词计数器功能分析

测试单词计数器

准备测试文件
vim words.txt
#文件内容
darren name darren
adizero marathon darren
hadoop yarn mapreduce
darren yarn hadoop mapreduce创建hdfs文件夹用于存储测试文件 & 输出文件

hdfs dfs -mkdir -p /input/wordcount
hdfs dfs -mkdir -p /output将测试文件上传到hdfs中的input文件夹,作为测试数据

hdfs dfs -put words.txt /input/wordcount执行命令,运行程序
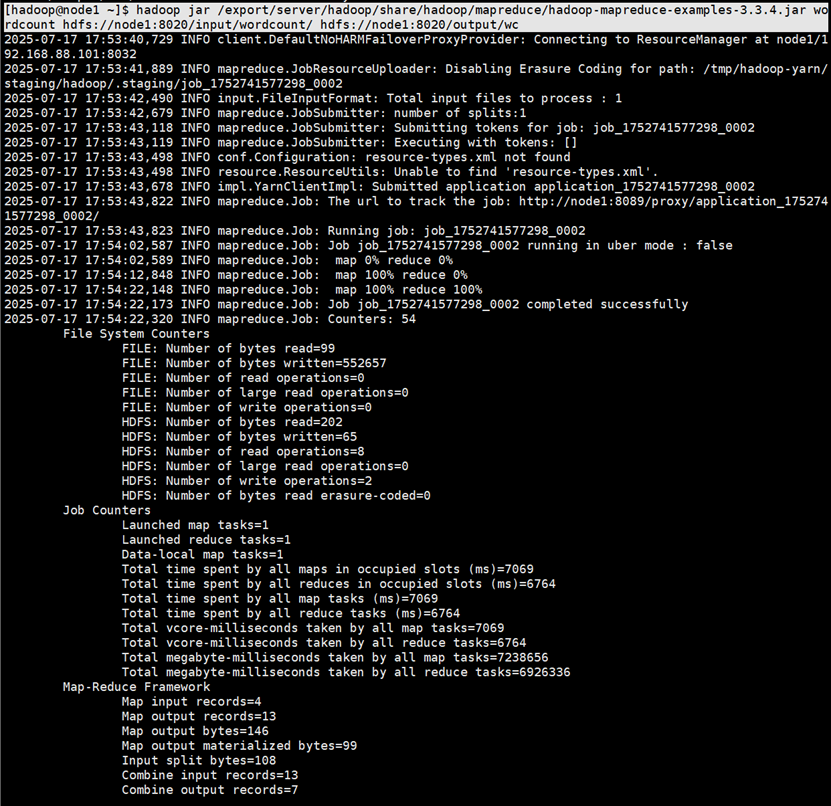
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount hdfs://node1:8020/input/wordcount/ hdfs://node1:8020/output/wc查看运行程序
查看测试结果
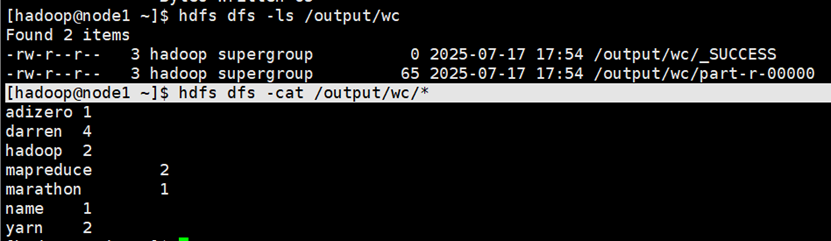
注意:

查看历史服务器 & 详细日志信息
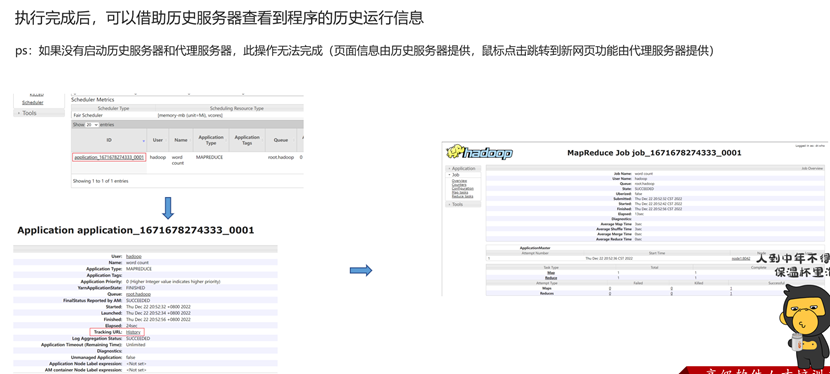
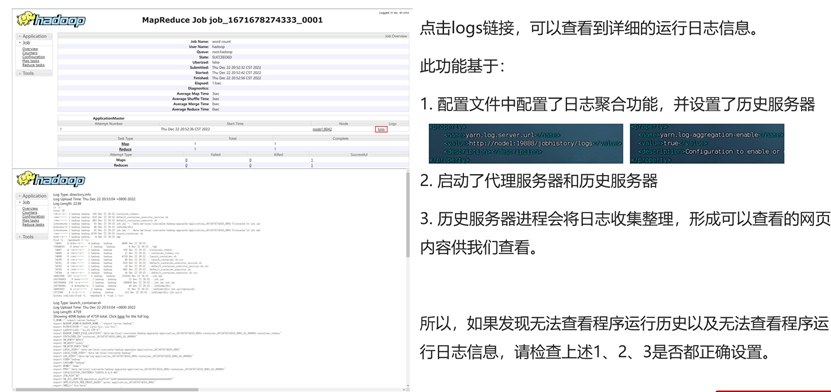
蒙特卡洛求解圆周率
程序测试

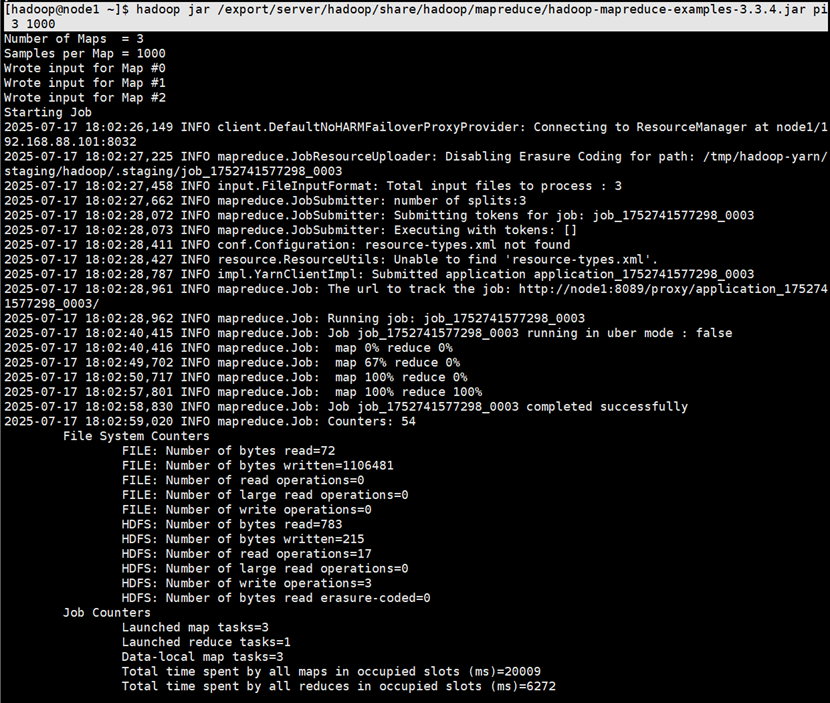
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 3 1000![]()
蒙特卡洛计算圆周率详解
原理分析

现在我们假设有一个边长为r的正方形,这个正方形刚好可以在四分之一的圆内。现在我们抓一把沙子,随机扔到这个正方形内,将出现部分沙子落在了四分之一圆内/外。我们统计落在圆内的沙子总数,那么根据其占据总沙子的比例,我们可以推断出这次测试结果中四分之一圆形的面积,也就是落在(落入四分之一圆中沙子数/总沙子数) * r^2,其中r^2为正方形面积。
这是一个典型的统计学方法。通过上述过程,我们可以知道圆面积近似即为4 * (四分之一圆中沙子数/总沙子数) * r^2,且其本身面积公式为Πr^2,通过二者近似相等,我们就可以反推出圆周率的大小了,为:4 * (落入四分之一圆的沙子数/总沙子数)。
程序示例
public static void main(String[] args) {
System.out.print("请输入总沙子数(样本数)");
float number = new Scanner(System.in).nextInt();
System.out.println();
float in_count = 0; //落入四分之一圆的沙子数统计
/*
我们假设存在一个r=1的正方形围住了这个四分之一圆
以(0,0)为原点,我们构造了直角坐标系
这个正方形内的所有点均会在(0,0) —— (1,1)之间
假设当前点坐标为(a,b)
由于该圆方程为:x^2 + y^2 = 1
那么只要a^2 + b^2 <= 1,这个点就会在四分之一圆内
*/
for (int i = 0; i < number; i++) { //计算样本中每一个沙子的情况
//a,b为当前样本落入的坐标
double a = Math.random();
double b = Math.random();
if (a*a + b*b <= 1) //当前样本在四分之一圆内
in_count++;
}
double pi = (in_count / number) * 4; //pi即为落入(四分之一圆数量/总数量) * 4
System.out.println("以" + number + "为样本计算出的圆周率Π为:" + pi);
}总结

Apache Hive初步了解
Apache Hive概述
分布式SQL计算


Hive

总结

模拟实现Hive功能
Hive架构的功能

元数据管理
场景需求

使用SQL查询hdfs结构化文件的问题

简而言之,就是一份hdfs中的文本文件,我们要如何为其映射为一个便于SQL执行查询的结构化数据库表?也就是说,有了这样一份hdfs中的结构化文件,我们如何为其中每个字段进行命名 & 归纳,使其可以构成一张有字段对应的类似数据库表的文件。
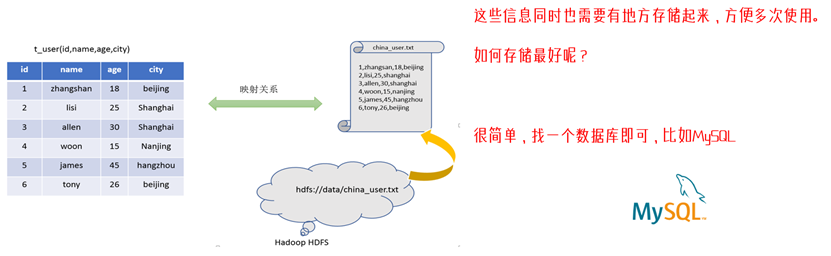
另一个问题是,由于这张结构化数据库表很有可能具有时间局部性,我们需要为其进行存储。那么既然我们将其映射为一张数据库表,不妨将其存储在数据库中。
元数据管理的作用

经过上述分析,构建Hive的第一个因素——元数据管理,就已经得以呈现了。在一个SQL语句中,我们要将表与hdfs中的文件进行对应,将hdfs文件映射为能让SQL进行查询的数据库表,同时也要解析每个字段的属性等。
SQL解析器

在已经能够将SQL中的表与hdfs元数据对应后,我们面临的下一个问题就是如何将SQL任务转换为MapReduce任务。
这就需要SQL解析器了。它可以为我们校验SQL语法正确性,完成SQL到MapReduce任务的转换,并且将MR任务提交给YARN运行,收集运行结果。
基于MapReduce完成SQL分布式计算的引擎基础结构

Hive架构
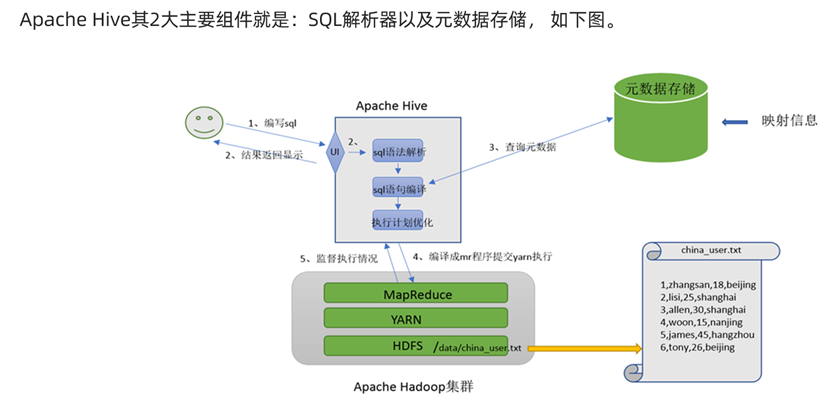
元数据存储负责SQL中数据映射,SQL解析器用于转换MapReduce任务。通过二者配合,Hive就能很好的实现基于MapReduce完成SQL分布式计算。
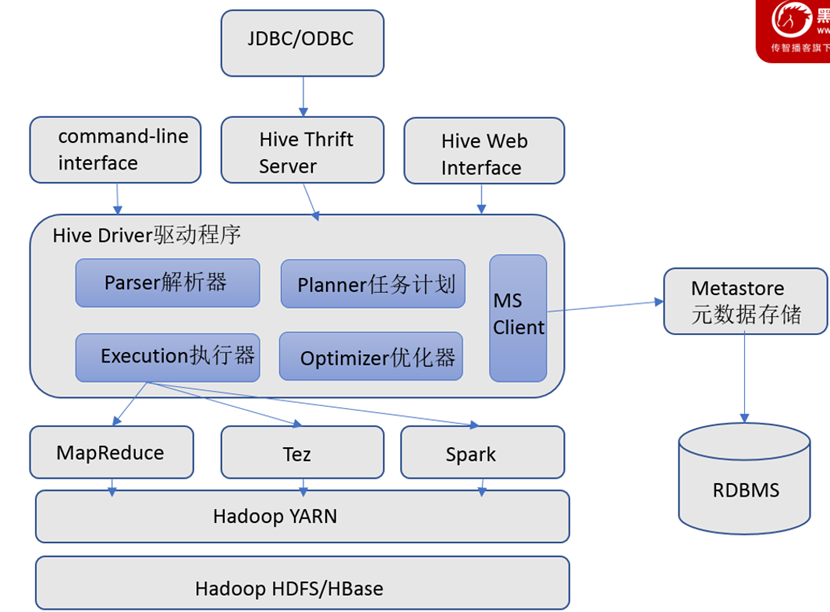
Hive基础架构
Hive结构图
Hive元数据存储
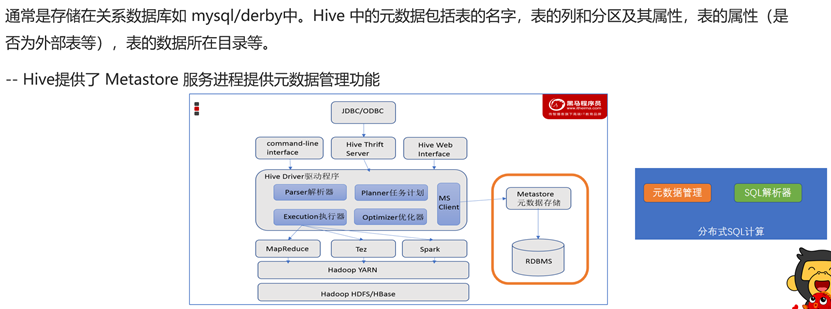
Metasotre服务会将hdfs文件存储在外置DB中(如MySQL等),便于HiveSQL查询数据。
Hive驱动程序
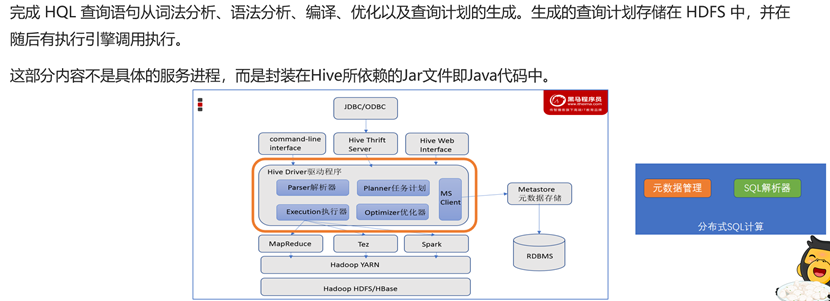
Hive用户接口
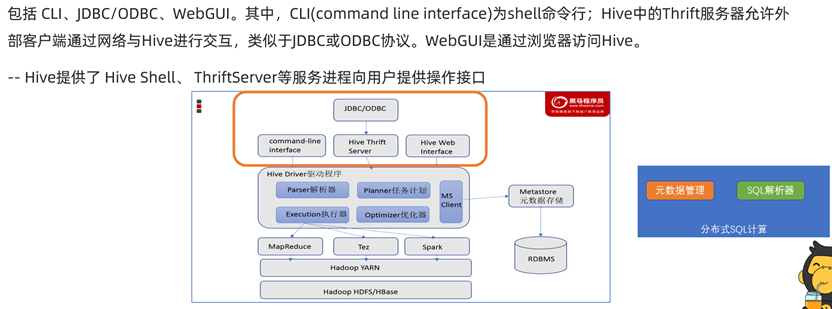
Hive部署(虚拟机部署)
问题思考:Hive是单机服务吗?
是的,Hive是单机服务。我们说过,Hive框架功能在于将SQL解析为MapReduce分布式任务提交运行,那么对于一条SQL的解析,完全没有必要分布式解析,这反而会降低其性能。我们只需要将SQL解析完成,然后将MapReduce分配给分布式节点进行运行即可。因此,Hive是一个可以提交分布式任务的单机服务!
Hive集群规划

部署Hive
安装MySQL5.7
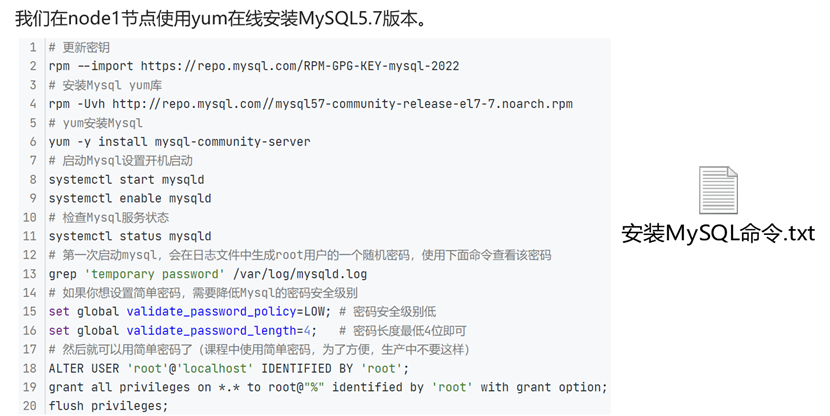
#####请务必确认使用root用户执行#####
# 更新密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
# 安装Mysql yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
# yum安装Mysql
yum -y install mysql-community-server
# 启动Mysql设置开机启动
systemctl start mysqld
systemctl enable mysqld
# 检查Mysql服务状态
systemctl status mysqld
# 第一次启动mysql,会在日志文件中生成root用户的一个随机密码,使用下面命令查看该密码
grep 'temporary password' /var/log/mysqld.log
# 修改root用户密码
mysql -u root -p -h localhost
Enter password:
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '{你的密码}';
# 如果你想设置简单密码,需要降低Mysql的密码安全级别
set global validate_password_policy=LOW; # 密码安全级别低
set global validate_password_length=4; # 密码长度最低4位即可
# 然后就可以用简单密码了(课程中使用简单密码,为了方便,生产中不要这样)
ALTER USER 'root'@'localhost' IDENTIFIED BY '{你的密码}';
/usr/bin/mysqladmin -u root password 'root'
grant all privileges on *.* to root@"%" identified by '{你的密码}' with grant option;
flush privileges;配置hadoop

#配置完成后,别忘记重启HDFS集群!!
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>#分发配置文件
scp core-site.xml node2:`pwd`/
scp core-site.xml node3:`pwd`/下载 & 解压Hive

为Hive提供Mysql驱动包

配置Hive
配置hive-env.sh文件

#将conf中的hive-env.sh.template模板改名为hive-env.sh
mv hive-env.sh.template hive-env.sh
#编辑hive-env.sh文件,加入下列内容
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib配置hive-site.xml文件
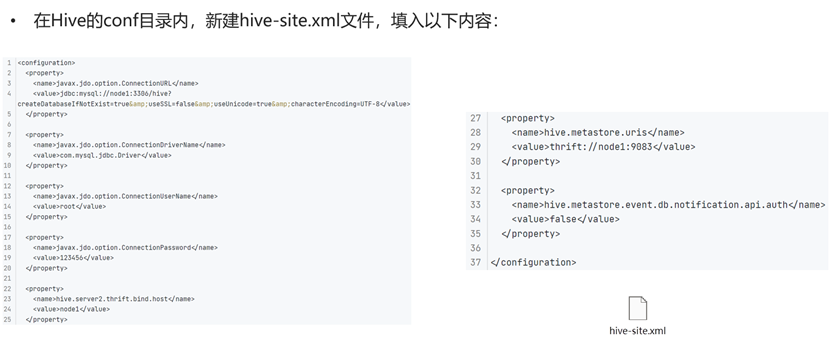
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>{你的密码}</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node1</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>初始化元数据库
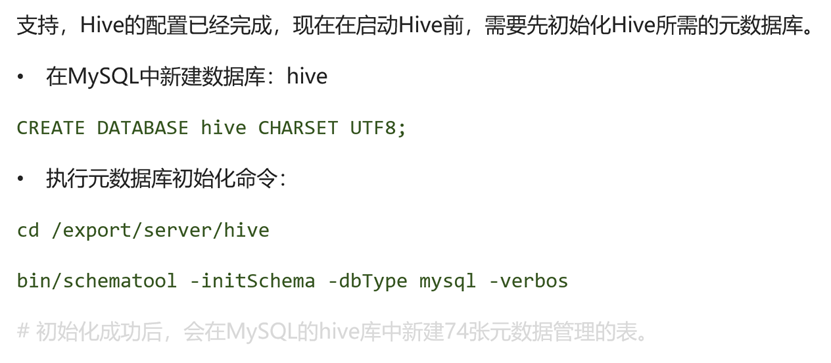
在MySQL中新建数据库Hive
mysql -uroot -p
CREATE DATABASE hive CHARSET UTF8;执行元数据库初始化命令
cd /export/server/hive/bin/
./schematool -initSchema -dbType mysql -verbos启动Hive

创建hive日志文件夹
mkdir /export/server/hive/logs启动元数据管理服务(必须)
前台启动:bin/hive --service metastore
后台启动:nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &启动客户端(任意一种均可)
#Hive Shell方式(可以直接写SQL):
bin/hive
#Hive ThriftServer方式(不可直接写SQL,需要外部客户端链接使用):
bin/hive --service hiveserver2部署总结

Hive初步使用


Hive客户端
HiveServer2 & Beeline(内置)
HiveServer2服务介绍

我们可以将HiveServer2理解为一个“接口”,有了这个接口,第三方工具就可以通过这个接口连接hive,去使用hive分布式计算功能了。
Hive客户端体系
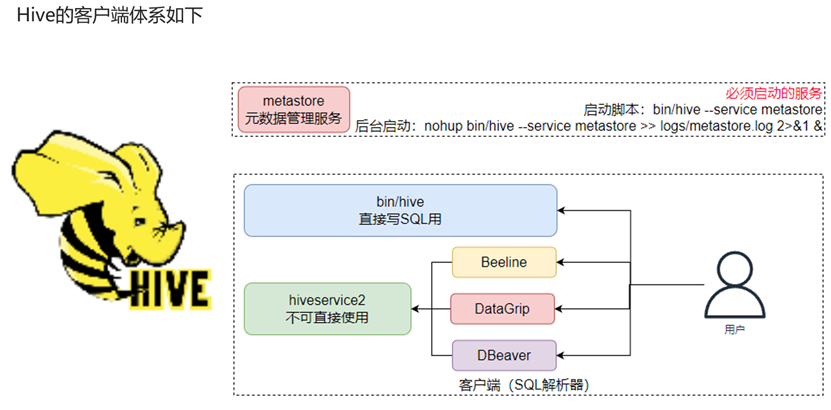
我们在Hive服务启动时介绍了两种方法:直接通过bin/hive启动、通过HiveServer2连接第三方客户端。第一种方式可以让我们直接在hive客户端内编写SQL,第二种方式则让我们可以有更多的可视化软件去进行大数据处理。
启动HiveServer2
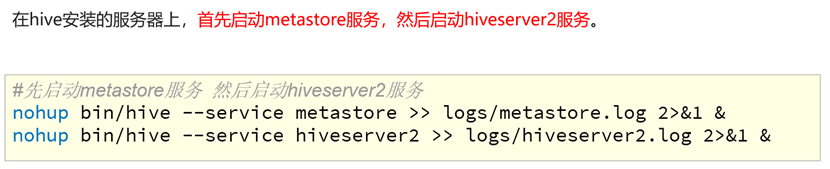
#先启动metastore服务 然后启动hiveserver2服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &通过HiveServer2连接Beeline客户端
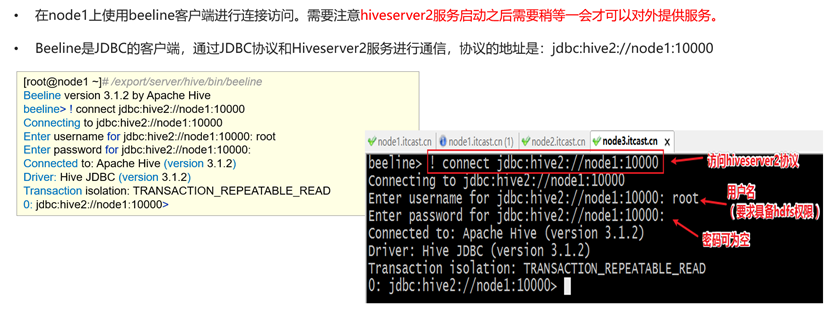
连接Beeline
#在hive目录下
bin/beeline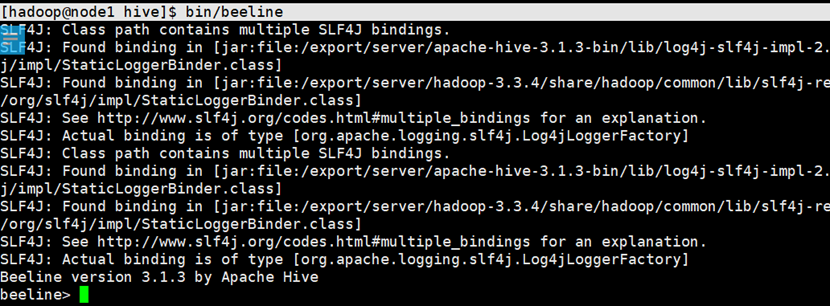
增加连接信息
! connect jdbc:hive2://node1:10000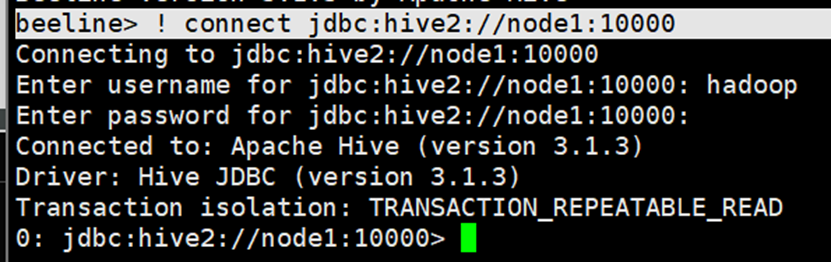
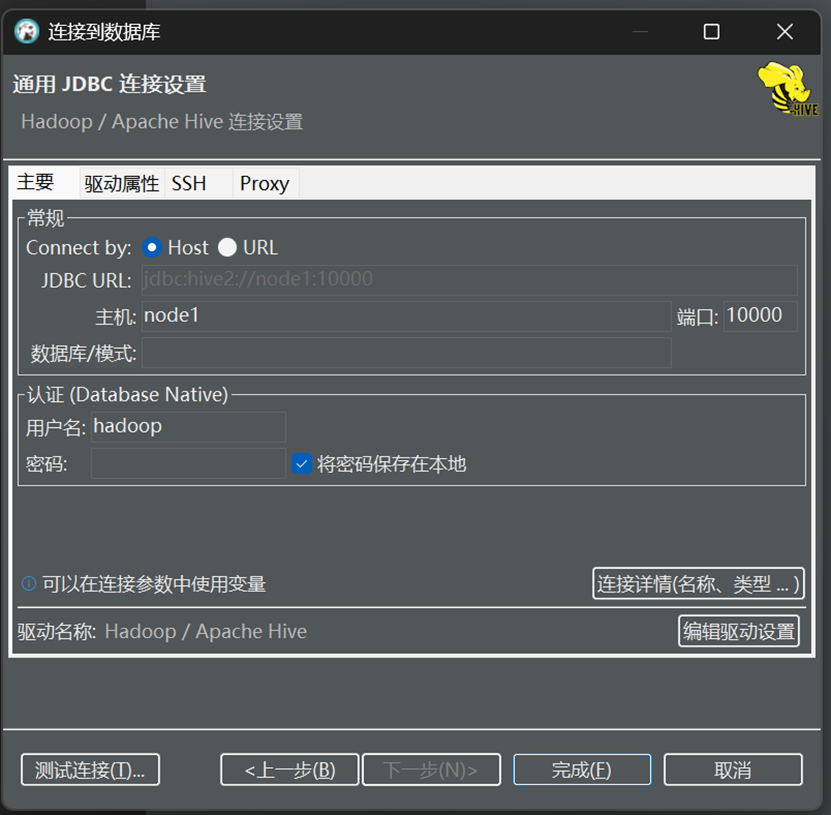
DataGrip & DBeaver(第三方)
Hive的第三方客户端
DataGrip连接Hive
创建新工程
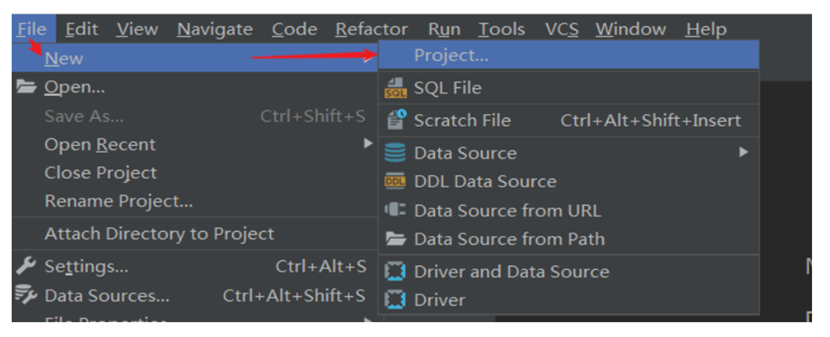
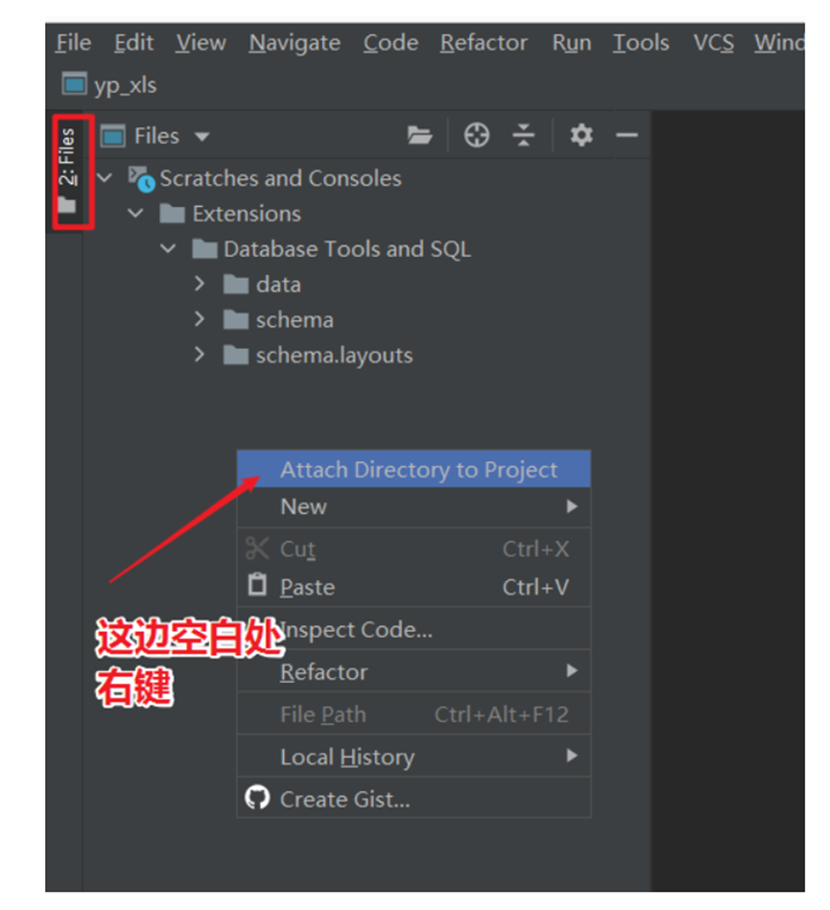
关联本地工程文件夹
连接Hive
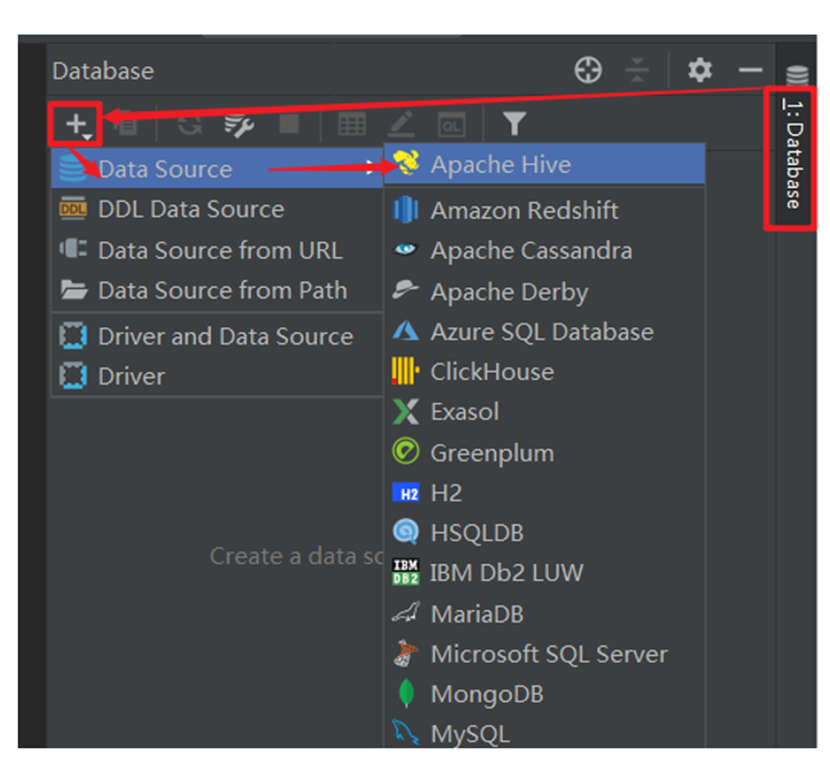
配置Hive JDBC连接驱动
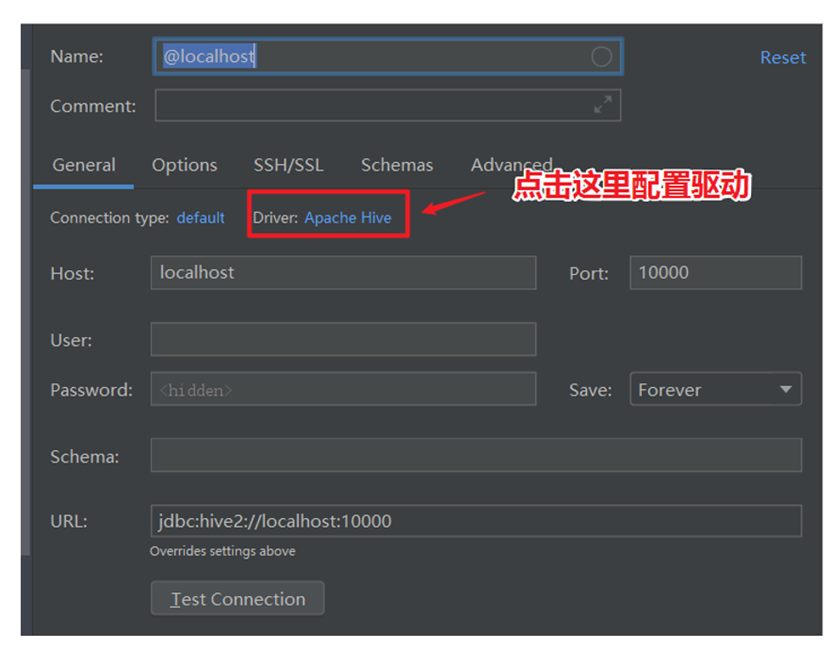
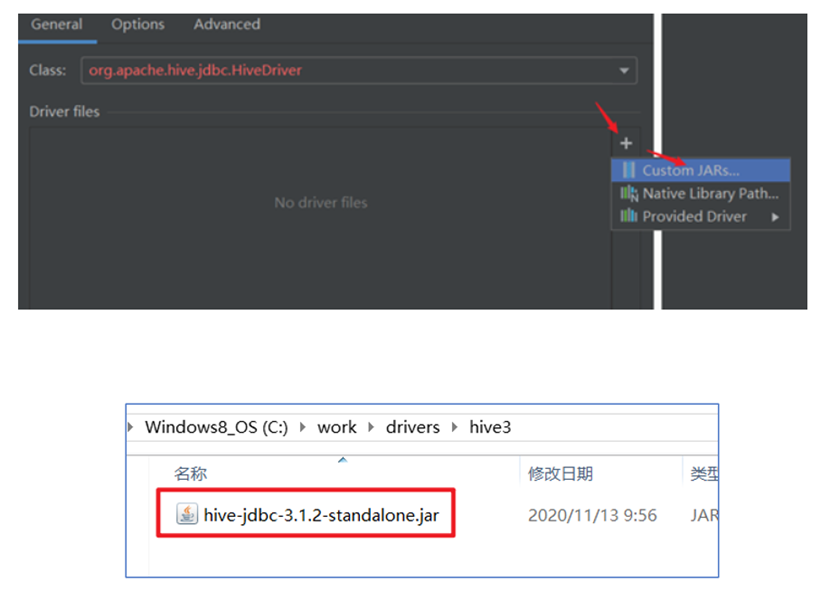
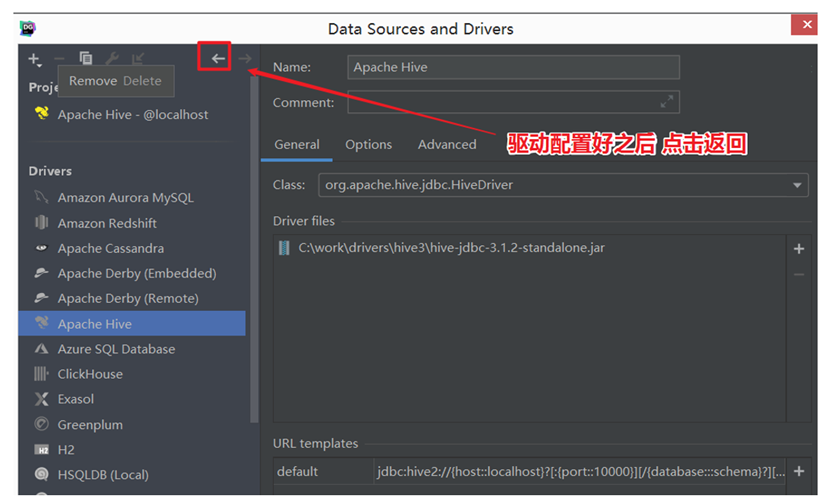
返回,配置HiveServer2连接信息
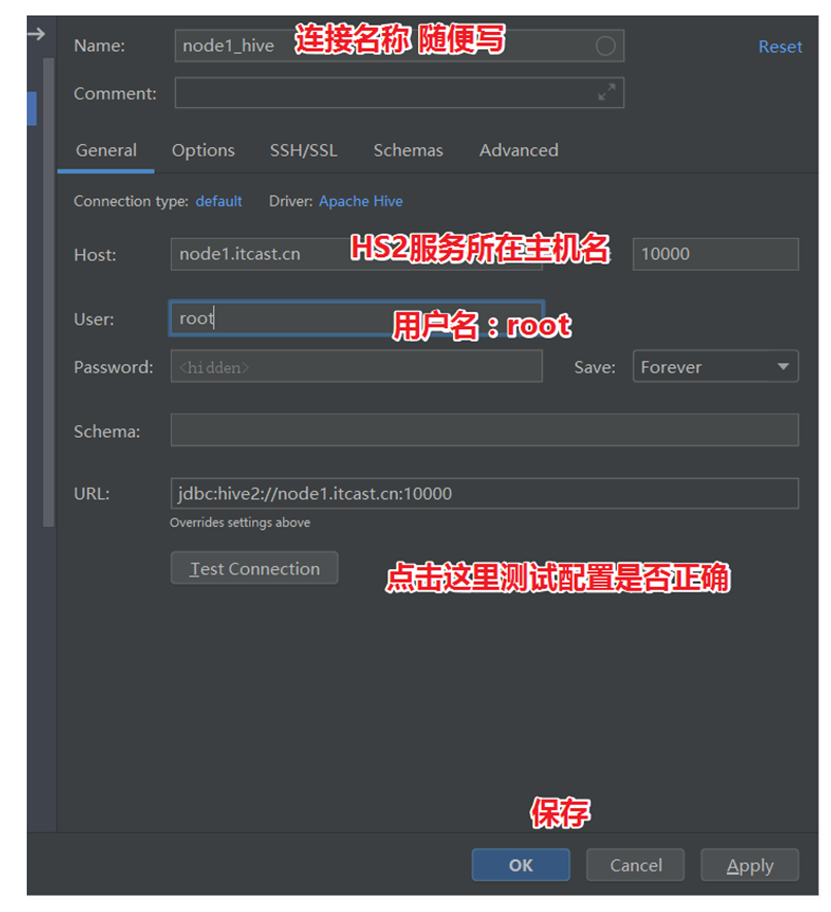
DBeaver连接Hive
新建数据库连接
选择Hive & 填写主机名、用户名
构建驱动
由于DBeaver内置驱动文件出现问题,因此我们需要手动配置驱动。
点击编辑驱动
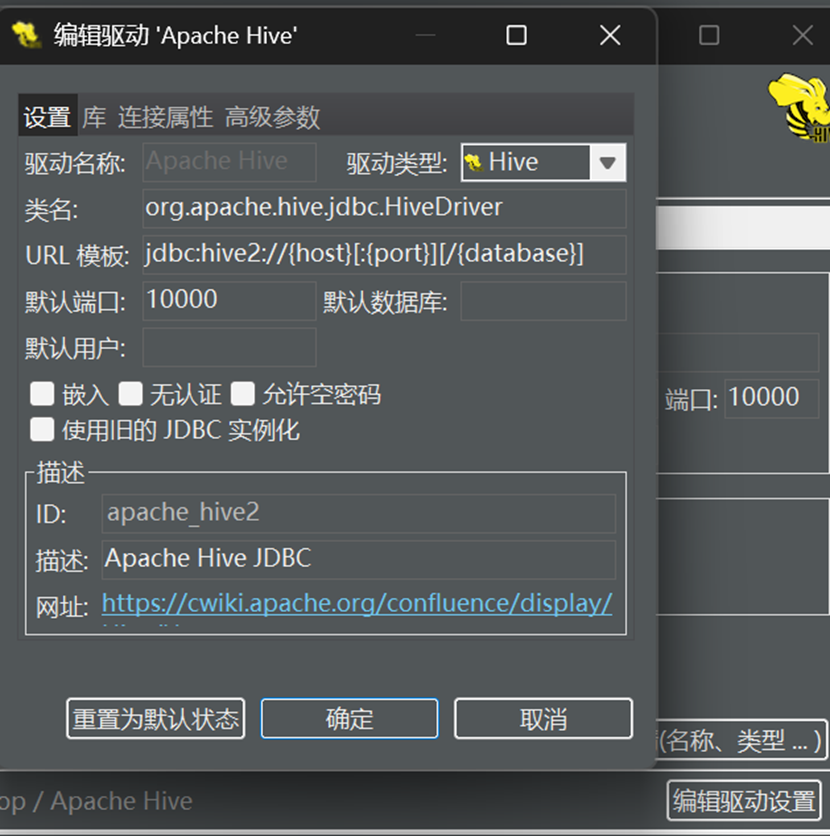
点击“库” & 删除其中内容
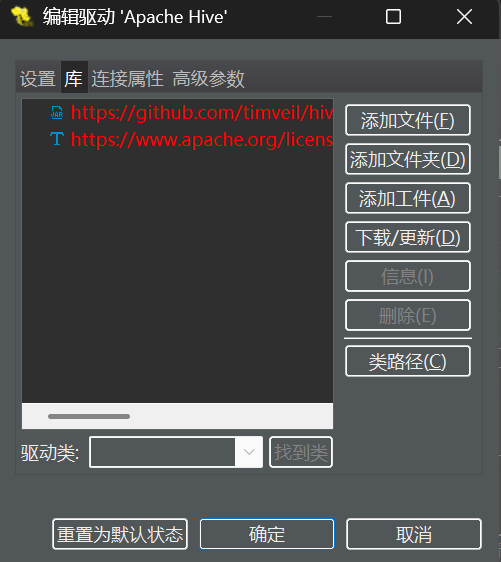
添加我们指定的驱动库
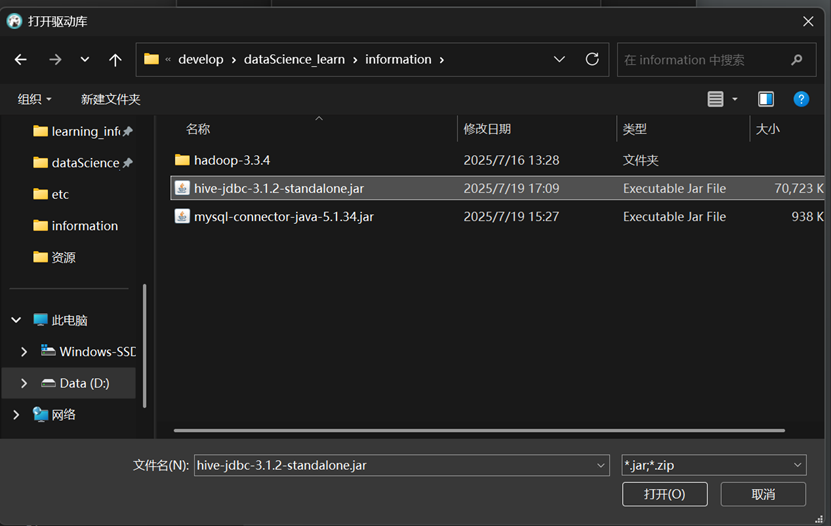
测试连接
Apache Hive使用语法与概念原理
数据库操作
SQL语法
创建数据库
CREATE DATABASE [IF NOT EXISTS] 数据库名;切换到对应数据库
USE 数据库名;查看数据库详细信息
DESC DATABASE 数据库名;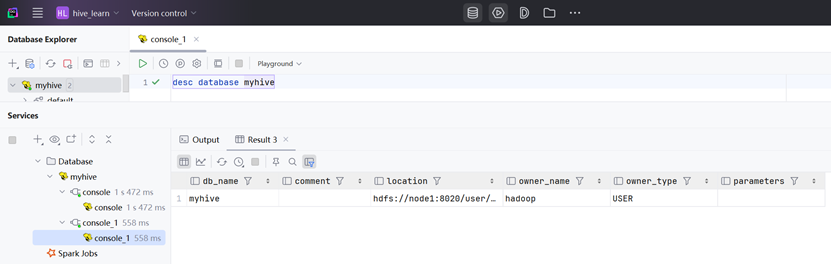
创建数据库并指定hdfs存储位置
CREATE DATABASE 数据库名 LOCATION ‘目标路径’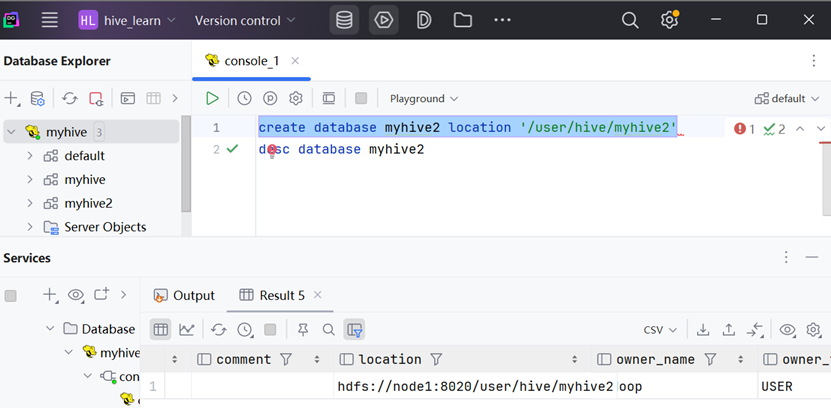
删除数据库
删除空数据库
DROP DATABASE 数据库名;强制删除数据库
DROP DATABASE 数据库名 CASECADE;数据库与hdfs关系

总结

数据表操作
创建表语法

数据类型

表分类

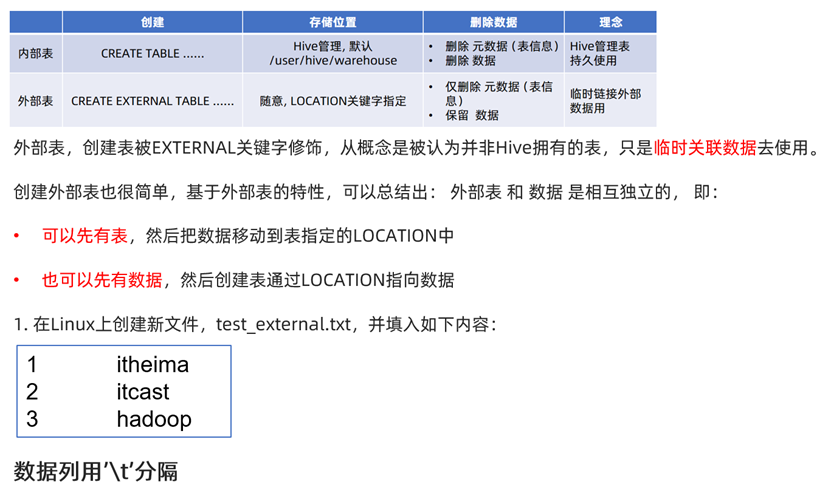
内部表 & 外部表


内部表最大的特性就在于其表数据删除是元数据(即相关文件信息)和存储数据全部删除,若表不存在那么内部的数据也将会都不存在;而外部表的特性在于删除表数据时,仅删除元数据,表中的数据仍然存在。
由两表的特性,外部表明显更适合与外部建立连接,因为即使对方删除了表信息,数据信息仍然存在于hive中;而内部表则适合自己使用,数据删除就是元数据和数据一起删除,因此内部表适合作为hive的管理表,并且持久使用。
内部表操作
创建内部表
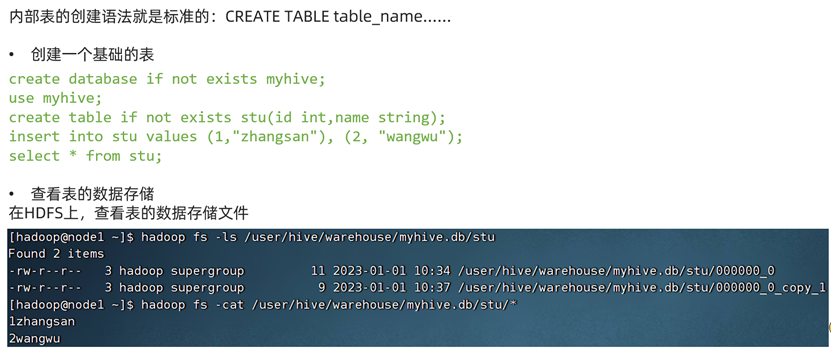
不加external关键字的基础表创建后就是内部表。
其他创建内部表的形式

数据分隔符
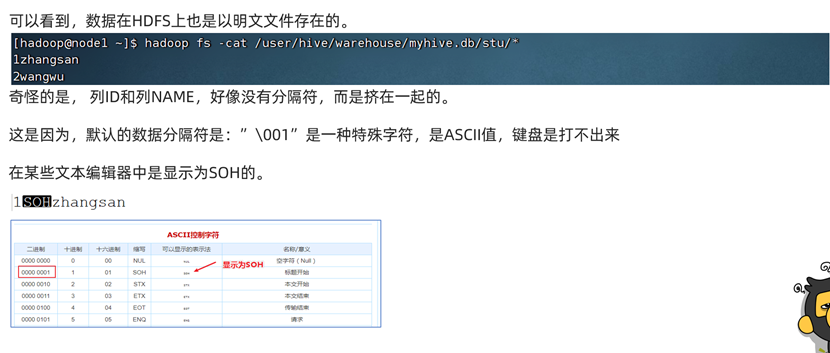
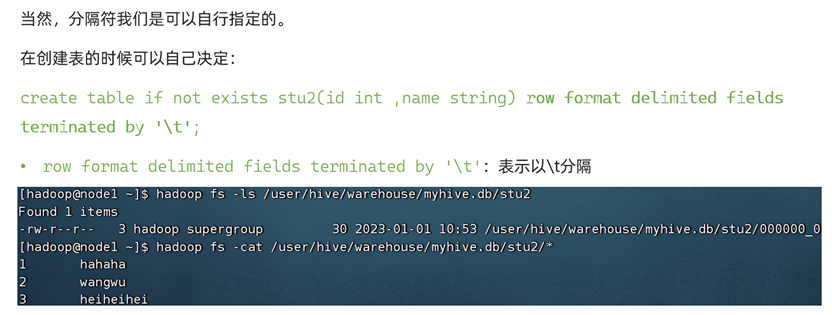
通过该命令即可在表创建时指定字段分隔符:row format delimited fields terminated by ‘{你需要的分隔符}’。需要注意的是,这个语句只能在建表时指定,无法通过alter关键字修改表。
删除内部表
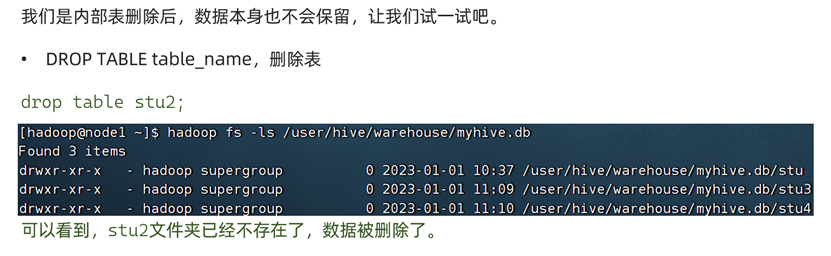
外部表操作
创建外部表
我们知道,在内部表中,数据实际上存储与内部表所在的hdfs目录下。而外部表的数据存储位置与外部表所在位置是无关的,只需要通过location关键字来将外部表指向数据即可。这就是为什么外部表删除时数据可以保留,因为数据并不在外部表的元数据中。
需要注意,在创建外部表时,必须手动指定自定义分隔符,和外部表的位置。其中,分隔符应与待处理的数据文件中的分隔符保持一致,比如此处文件中为”\t”,那么外部表中分隔符也应该为”\t”。
前置步骤——在linux中创建test_external.txt文件,内容如图
演示——先创建表,再移动数据

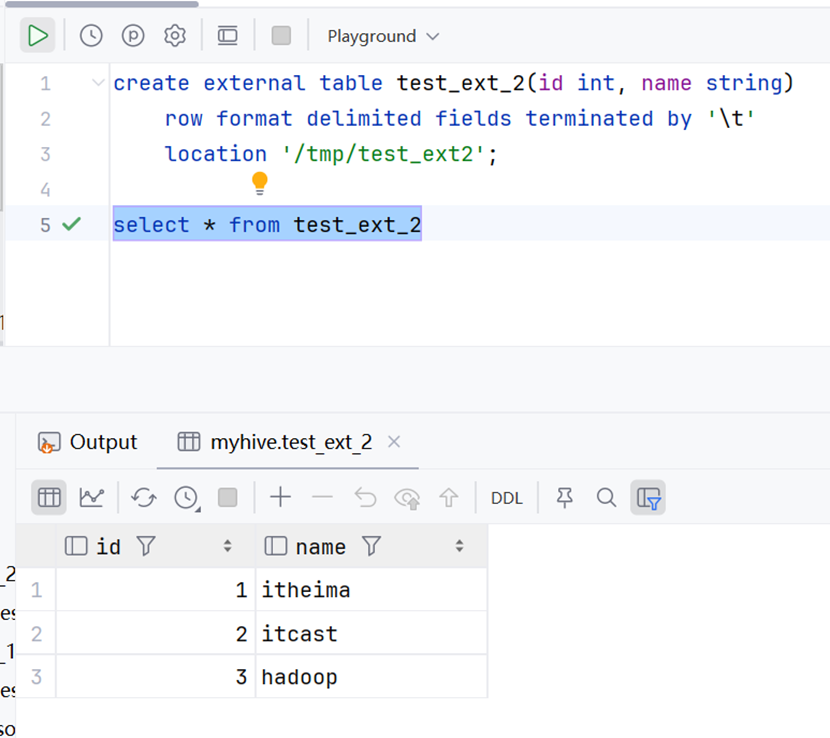
创建外部表
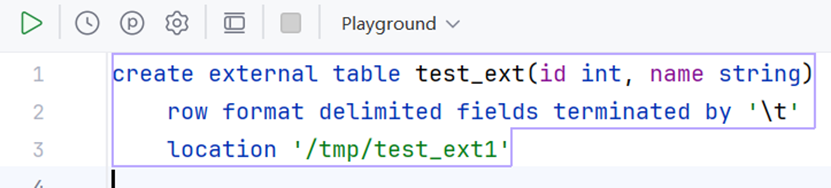
我们通过location指定了外部表所在的存储位置。我们前面提到,数据库表在hdfs系统中实际上就是一个文件夹,而其中的数据就位于该文件夹内部。也就是说,若我们将数据上传到外部表所在的文件夹中,就相当于为外部表指定了数据。
查看当前文件夹的数据

这说明外部表已经存在,只是其中没有数据。接下来我们就将数据上传,进一步进行测试。
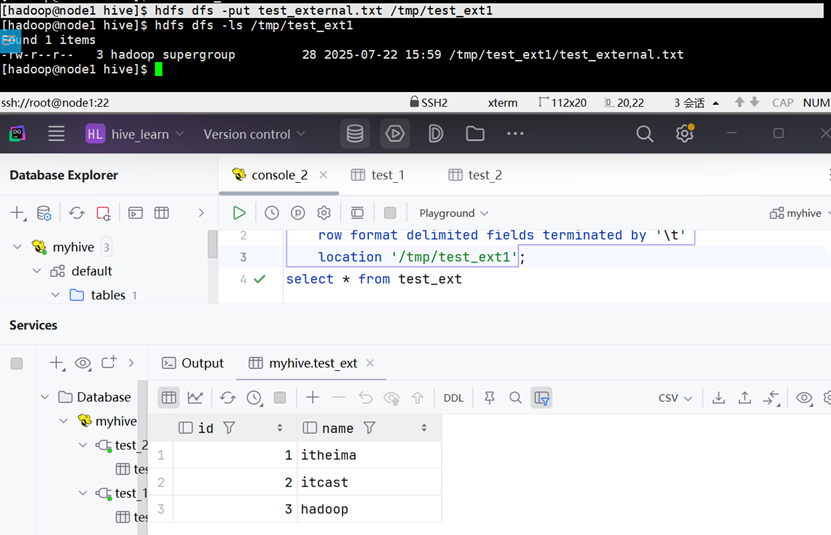
上传数据到外部表所在目录中 & 查看数据
演示——先有数据,再创建表

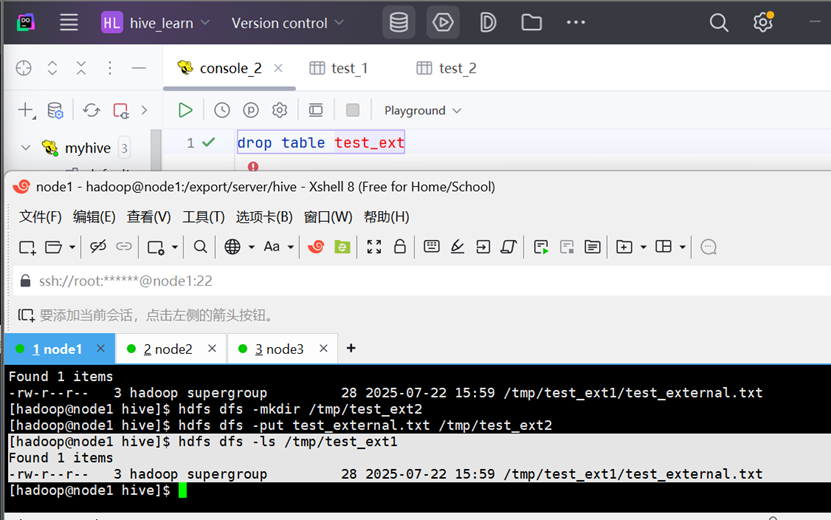
创建文件夹 & 上传数据

基于该数据所在文件夹创建外部表 & 查看数据
删除外部表

演示
可以发现,外部表删除之后,数据仍然不受影响。这充分证明了外部表与其数据是相互独立的。
内/外部表的转换
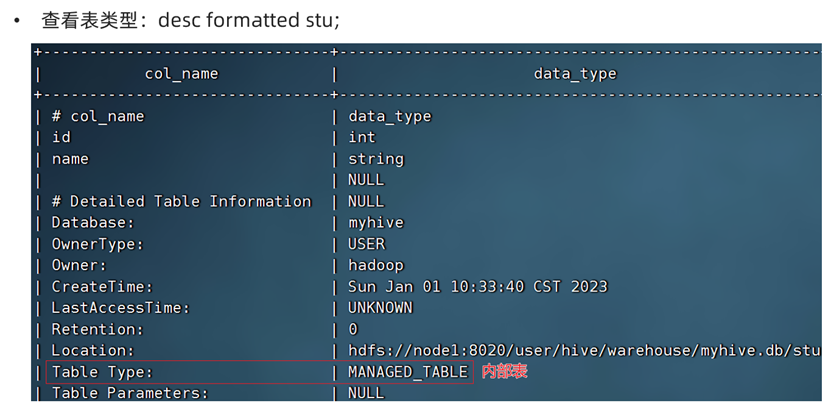
查看表类型
转换内/外部表

总结

数据加载和导出
数据加载
LOAD DATA语法
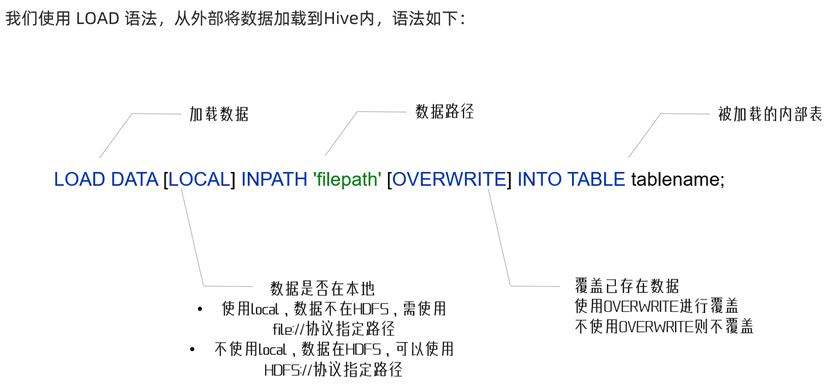
LOAD DATA [LOCAL] INPATH ‘你的数据路径’ [OVERWRITE] INTO TABLE 你的数据表;演示
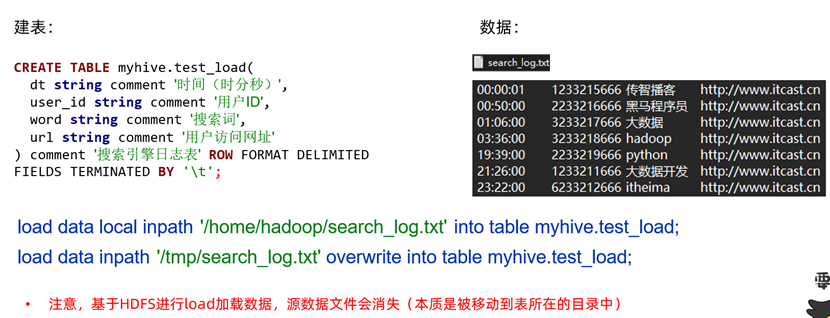
注:此处使用内部表进行演示,search_log.txt已经提前导入hadoop本地系统中。
在hive中创建测试表
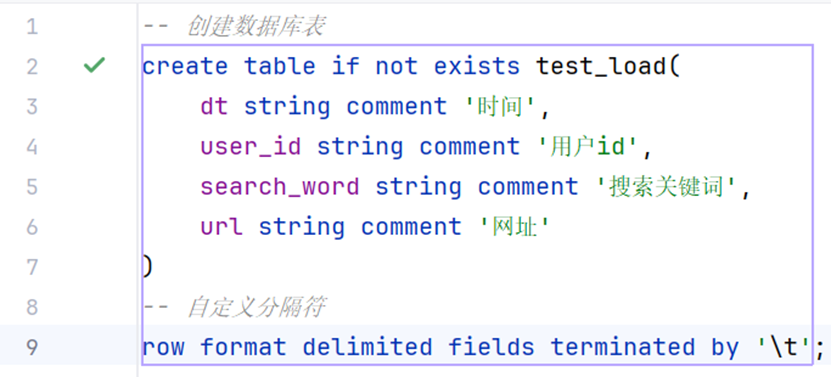
数据加载——本地上传
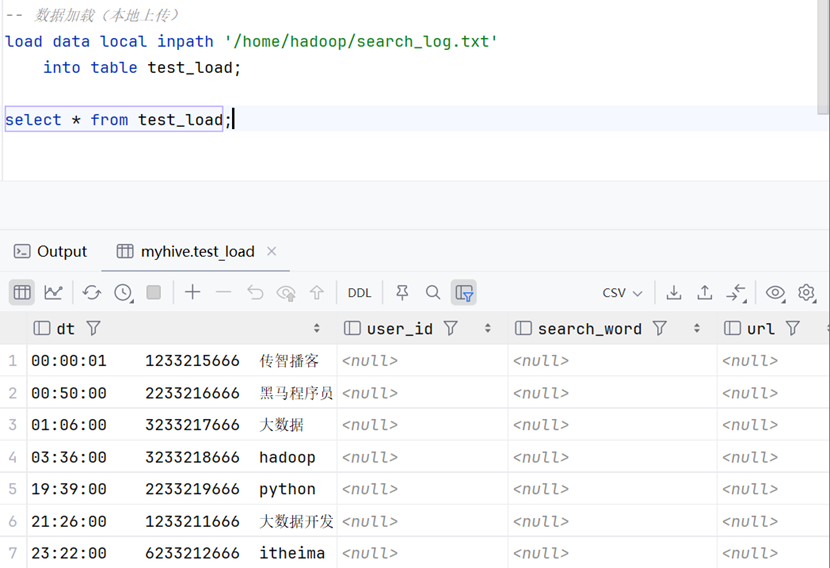
注意,从linux本地上传文件一定要加上‘local’关键字!否则hive将只会从hdfs系统中查询目标文件!
数据加载——hdfs上传
将文件上传至hdfs
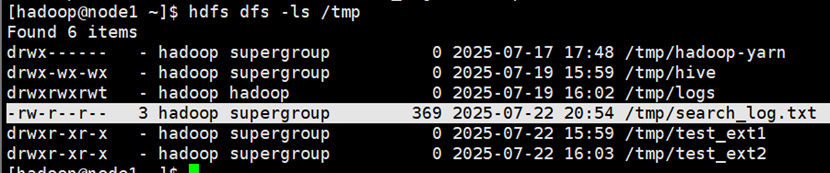
通过hive上传至数据库
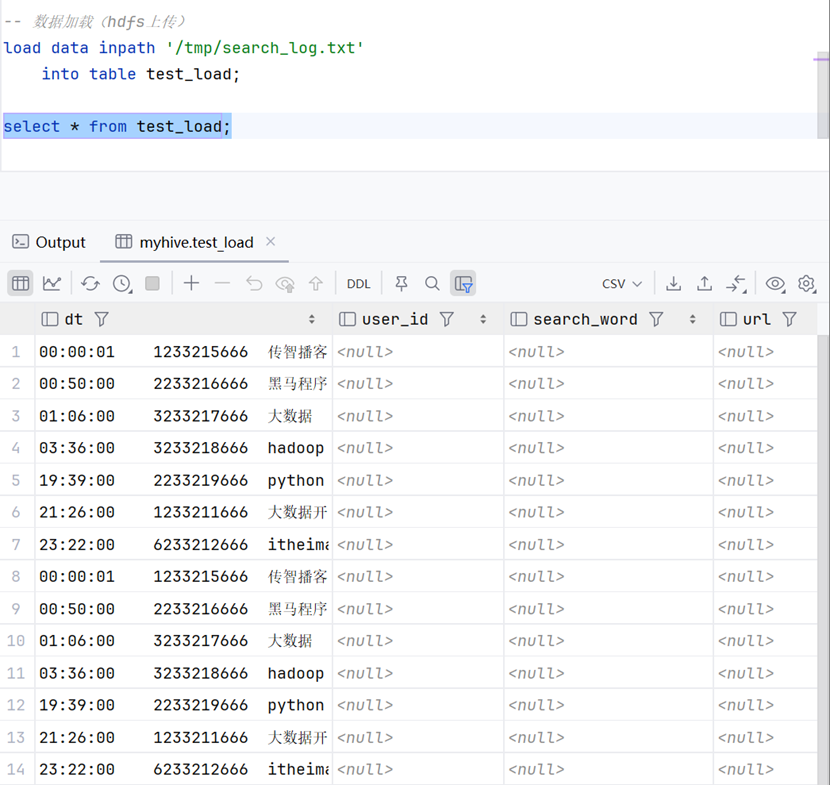
由于是从hdfs上传,所以我们可以不用加上‘local’关键字。且由于我们在上传时未指定overwrite,因此此数据上传后将会追加在原有数据后。
一个注意点
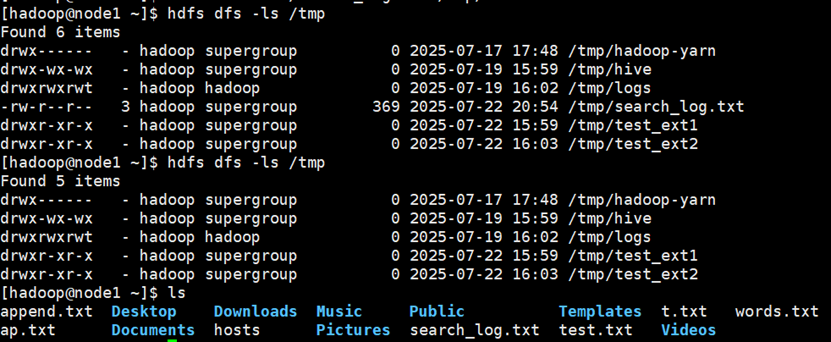
我们可以发现,在使用LOAD加载数据时,通过hdfs上传数据后,原有的数据文件不见了,但是通过本地系统上传数据,原有数据文件仍然存在。
原因在于,从hdfs上传数据,实际上是走了’hdfs dfs -mv’流程,即将你的数据从原目录移动到当前数据表所在的hdfs目录下;从linux本地上传数据,实际上是走了’hdfs dfs -put’流程,直接加载linux本地文件到数据表的hdfs目录下。
INSERT SELECT语法

此处与oracle、MySQL基本一致,故不详细介绍。但注意,请务必保证两张表的字段完全一致!
演示
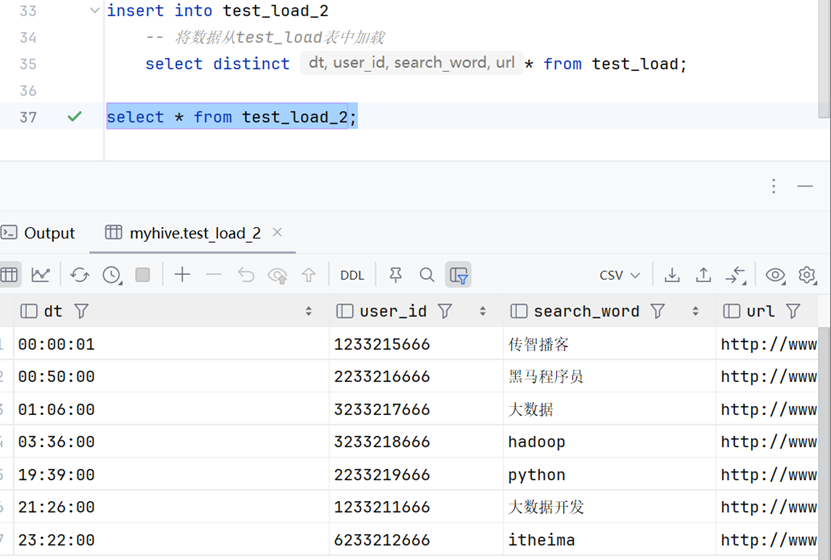
执行流程分析
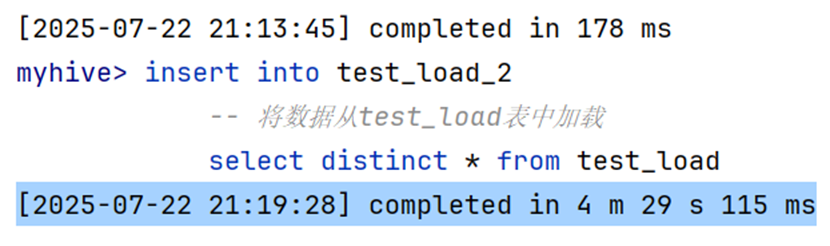
不难发现,这个过程用了四分半左右才完成,这是因为从别的数据表中加载数据会被hive分配成MapReduce任务。而我们知道,光是将SQL翻译并启动为MapReduce任务本身就已经相当耗时,所以执行花了如此长的时间并不意外。
两种数据加载的使用场景

数据在本地
推荐使用LOAD DATA LOCAL方式进行。
数据在hdfs中

当我们想保留原始文件时,若使用load方式将会执行’hdfs dfs -mv’,原始文件将会被转移,这是行不通的。但由于该数据可能在数据表中不存在,是hdfs的数据文件,所以我们需要建立外部表,将数据与其进行关联,然后通过INSERT SELECT将外部表数据加载。
建立外部表的原因是,这个外部表只是临时使用的表,并非我们需要长期管理的表。当外部表没用而删除时,数据是希望被保留的,这个特性只有外部表才具备。
数据只在数据表中
只能使用INSERT SELECT方式。
数据导出
INSERT OVERWRITE方式

导出到linux本地(有local关键字)
使用默认列分隔符
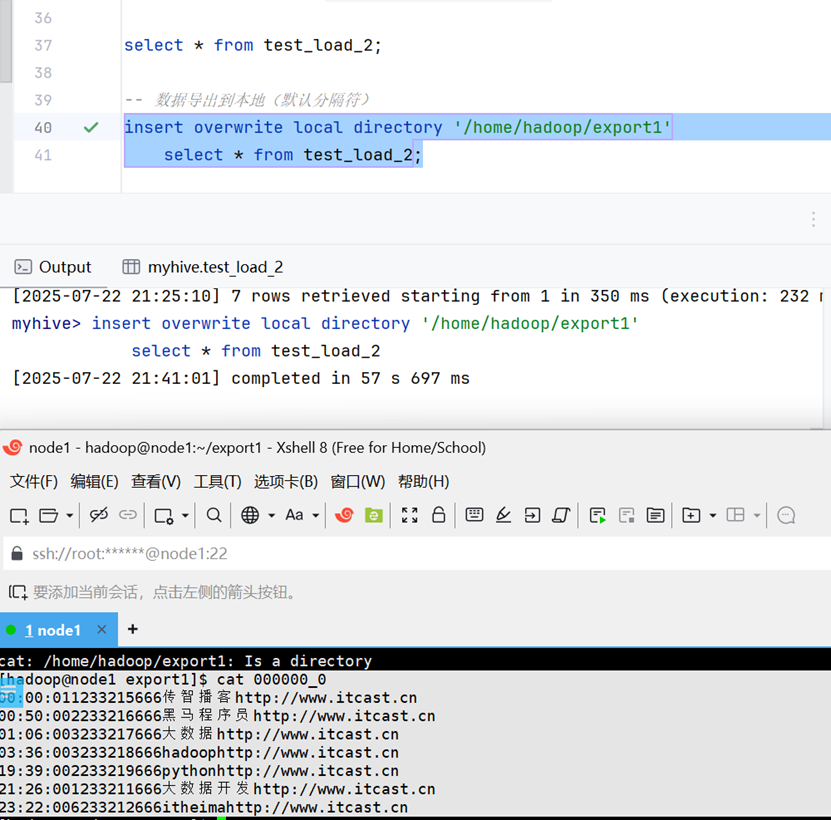
insert overwrite local directory '你的路径' select * from 你的数据表;指定列分隔符
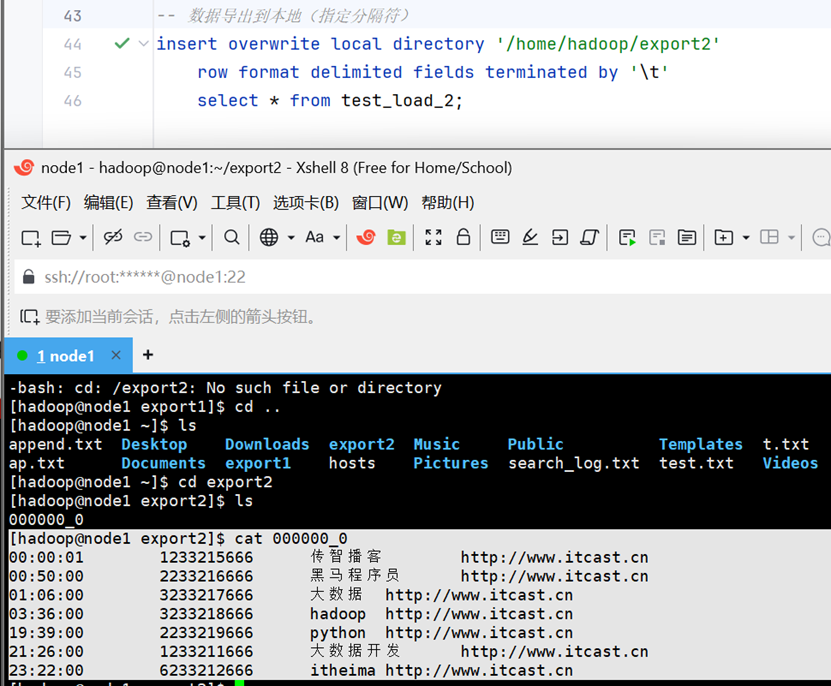
insert overwrite local directory '你的路径‘
row format delimited fields terminated by '你的分隔符'
select * from 你的数据表;导出到hdfs(无local关键字)
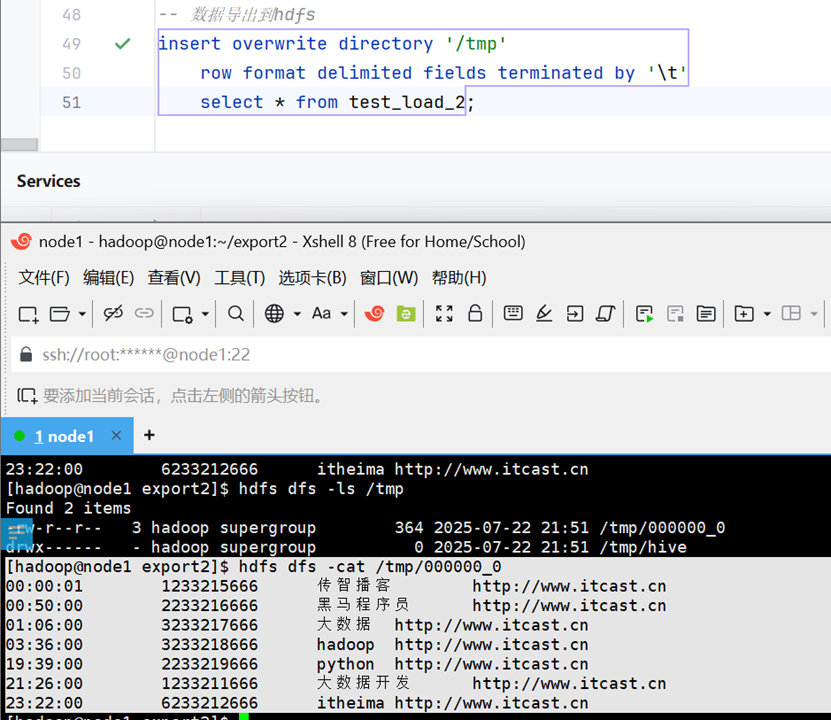
注意事项
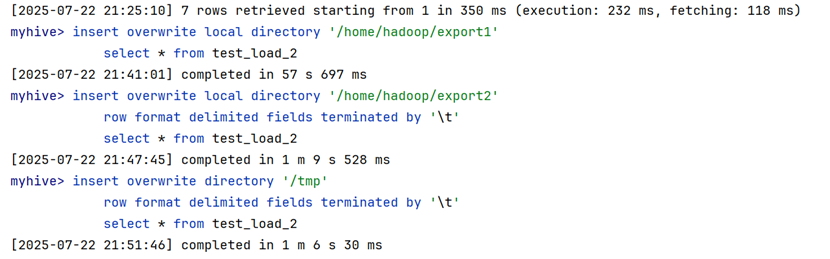
不难发现,每个insert overwrite流程花费时间都非常久,原因与数据加载的insert select相同,这两个有insert的流程都需要执行MapReduce任务。
Hive shell方式

#方法1:
bin/hive -e ‘你的SELECT语句;’ > 你的目标文件路径
#方法2:
bin/hive -f 你的SQL脚本文件 > 你的目标文件路径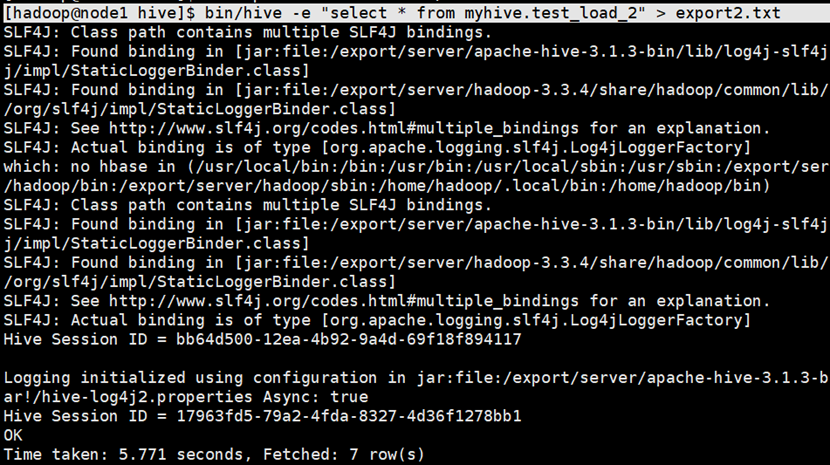
总结
数据加载总结

数据导出总结

分区表
分区表的概念

原先的数据表和其中存储的数据都位于一个文件夹内,这样对于检索等操作无疑会造成隐患(数据量增大时)。既然hdfs在存储时将大文件分散成几块小文件进行存储,那么hive也可以将数据表和数据拆成几个小文件夹。
我们可以依据我们的分区逻辑,将数据表文件夹进一步拆分,这样检索时就可以通过查看分区的标识来决定是否进入该分区查询数据。同时,由于每个分区位于不同的文件夹,这也实现了分区数据之间的物理独立性。
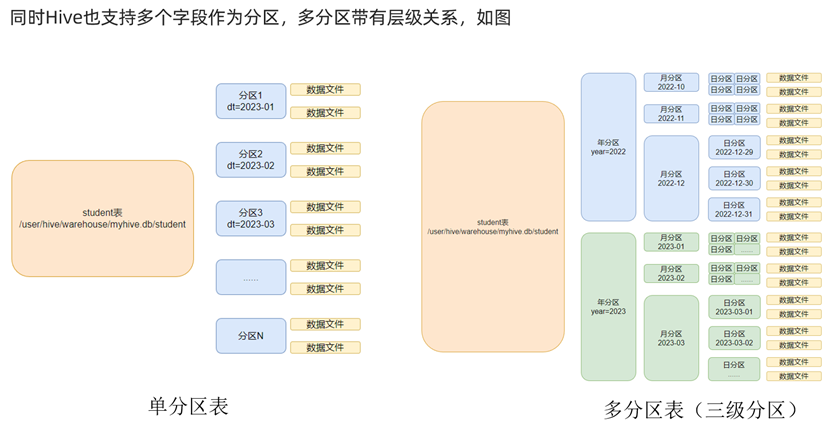
同样的,分区也可以具有层次结构,一个分区内又可以划分为更多分区。这在数据量极大的情况下,查询的效率是极高的。
分区表的使用
基础语法1——创建、添加数据到分区表

需要注意,我们定义的字段列和分区列虽然在不同地方定义,最后都会被创建为数据表的字段。
但我们需要知道二者数据来源不同:我们定义的字段列数据来自于我们的文件,而分区列的数据来自于我们加载数据指定的分区。
创建分区表语法
create table 你的数据表名(…)
-- 指定为分区表
partitioned by (你需要的分区列1, …) #若有多列,则为多分区,按先后划分层级
--指定列分隔符
row format delimited fields terminated by '你的分隔符';加载数据到分区表语法
load data [local] inpath "你的文件目录" into table 你的数据表
-- 指定分区列
partition(month = '202507'); #有几个分区层级就要指定几个层级!演示 & 分析
首先创建一个单分区表(内部表):

我们在hdfs中查看一下会发现,内部是没有子文件夹的:

这是因为内部没有数据,所以不需要分区。我们此时加载一份文件到数据库中:
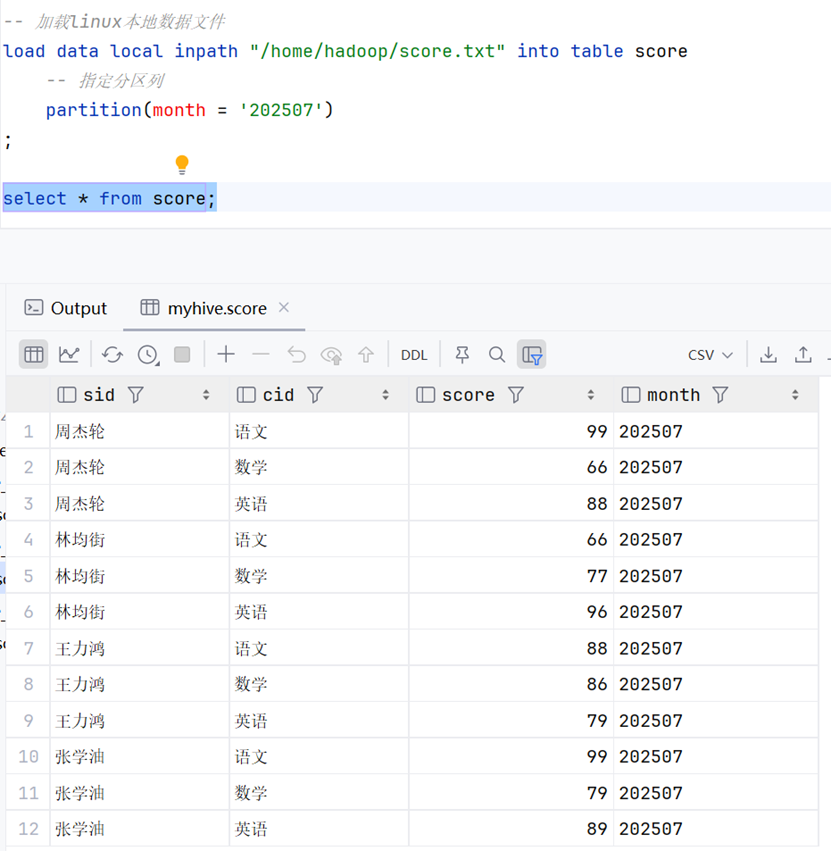
然后我们再次查看hdfs的数据表目录:
![]()
基础语法2——查看、添加、删除分区
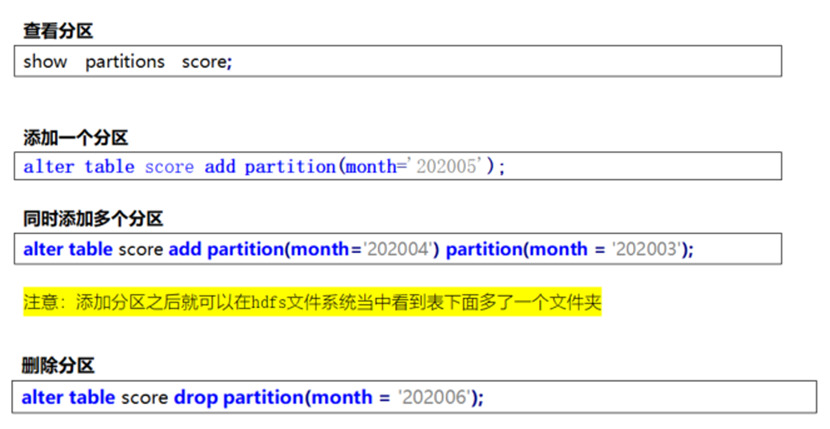
当我们添加分区后,实际上就等于在hive表下新增一个文件夹。将数据加入到该分区实际上就是把数据放入新分区文件夹下。由于这仅仅是新建了一个文件夹,因此并不会对原有数据进行改变。若我们想要将原先没有分区的数据放入分区中,则可以在hdfs中执行’hdfs dfs -mv’操作,移动数据所在的位置。
需要牢记一点:对hive表的分区,实际上就是对文件夹的操作。
-- 查看分区语法
SHOW PARTITIONS 你的数据表;
-- 添加分区语法
ALTER TABLE 你的数据表 ADD PARTITIONS(分区列1) PARTITIONS(分区列2)…;
-- 删除分区语法
ALTER TABLE 你的数据表 DROP PARTITIONS(你的分区列);总结

分桶表
分桶表的概念
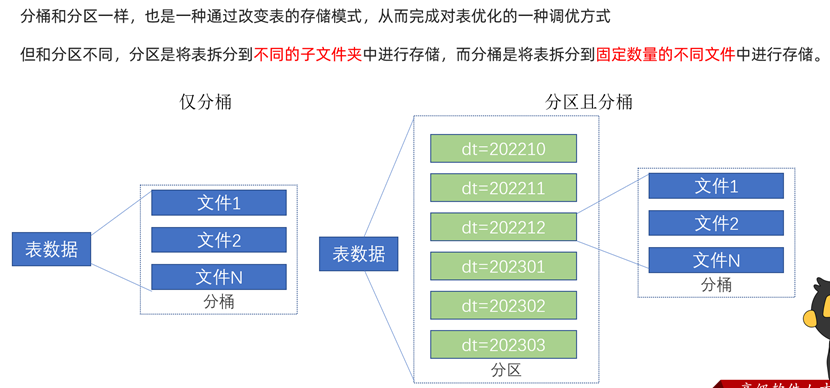
注意将分区表与分桶表进行区分,分区表是将数据文件拆分到不同文件夹存储,而分桶表则是将数据文件拆分到不同文件中进行存储。
我们需要知道,分桶表的拆分数量是在创建时就已经固定了的,不可更改。因此我们可以结合分区表的特性,将分区中的文件进行分桶存储,进一步提升表结构的性能。需要注意,分区 & 分桶结合的表中,每个分区的桶数是固定的,但我们可以通过新增分区来‘增加’桶的数量。
分桶表的创建
与分区表不同之处在于,分区表的分区列是我们新定义的一个列,而分桶表的聚簇列是使用我们已经定义好的字段。
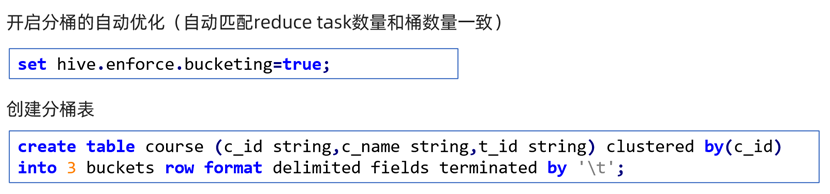
创建语法
-- 开启分桶的自动优化
set hive.enforce.bucketing=true;
-- 创建分桶表
create table course(cid string, cname string, tid string)
-- 指定分桶列
clustered by (cid)
-- 指定分桶数
into 3 buckets
-- 自定义分隔符
row format delimited fields terminated by '\t';分桶表的数据加载(通过实例演示)
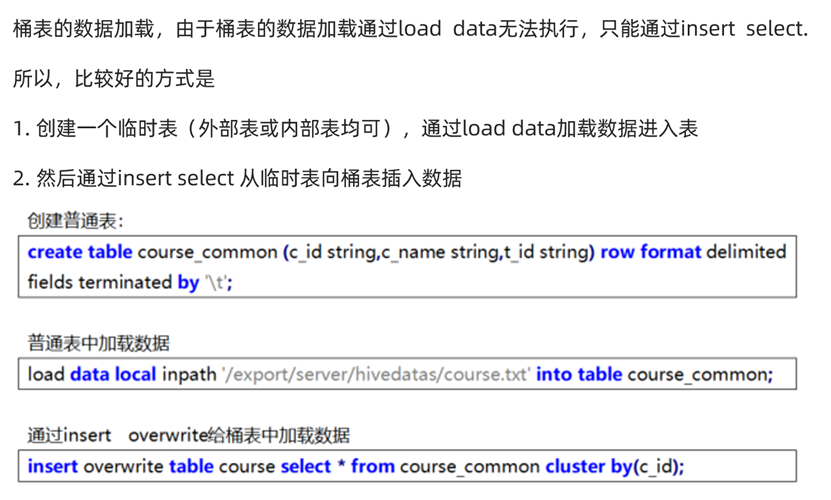
在向分桶表插入数据时,一定要加上cluster by关键字 & 定义表时的聚簇列!
创建临时表 & 加载数据到表中
-- 创建普通表进行数据加载
create table course_com
(
cid string,
cname string,
tid string
)
row format delimited fields terminated by '\t';
--加载数据
load data local inpath '/home/hadoop/course.txt' into table course_com;通过INSERT SELECT把数据导出到分桶表中
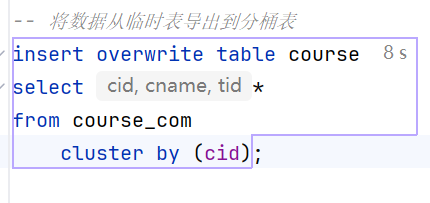
-- 将数据从临时表导出到分桶表
insert overwrite table course
select *
from course_com
cluster by (cid);数据存储查看(hdfs中)

可以发现,分桶表中直接将数据拆分到了三个文件,而不是分区表的分区文件夹。
分桶表Hash取模原理
为什么分桶表数据加载不能使用LOAD?

若不进行分桶,则文件被拆分为多少份是无所谓的。当我们没有设置分区时,就直接将数据放到hive表中;当我们设置分区时,则根据我们指定的分区放入对应文件夹。这两种操作都是将数据放入对应文件夹中,而文件夹原先有多少数据并不会影响这一过程。

但是当我们设置分桶后,数据存储逻辑就发生了改变。由于我们设置分桶,因此数据将拆分到特定的桶中进行存储,而不能像有/没有分区一样随意放入对应文件夹。
而如何保证数据能够放到对应文件夹?这就需要进行计算(Hash取模),也就是需要将数据拆分后,分别计算应当如何存放。这个计算是基于我们设置的cluster进行的,且是一个MapReduce任务。
我们回想之前讲解的数据加载,LOAD方法是无法执行MapReduce计算的,因此只能够使用INSERT SELECT方法执行数据加载。
Hash取模与分桶

Hash加密最重要的一个特征即:同样的值在进行Hash计算后,结果是一致的(这也就是为什么java重写比较方法需要重写hash,因为我们想要对对象进行比较时,不能让对象相同的属性值影响hash结果)。
我们在数据加载时,通过cluster指定了进行hash计算的字段,当数据加载时,将会根据该字段首先进行Hash加密,得出值后根据我们设置的分桶数进行取模。因此,若相同的cluster数据,将会被分到同一个桶中。假设我们插入数据中包含三个cluster为’str’的数据,那么他们三个都将会被放到0号桶(假设)。
总而言之,分桶表存储数据时,需要根据cluster字段进行hash取模,然后分配到对应桶中。

分桶表对性能的提升

我们前面有说到,由于Hash加密的特性,相同的元素具有相同的hash值,因此cluster列相同的数据一定会被放于同一份桶文件中。这就为我们查询cluster相关的数据带来了极大的性能提升,因为相同元素一定在同一个桶,基于cluster列的数据操作就可以直接锁定该桶,排除其余桶,无疑大大减少了检索的次数。
但需要注意,该性能提升仅能针对cluster列,若基于其余列进行操作,则无法实现这些性能提升,相反的,若这些列由于cluster列不同而被分到不同桶中,甚至可能增大操作的复杂度。
对于单值过滤的性能提升
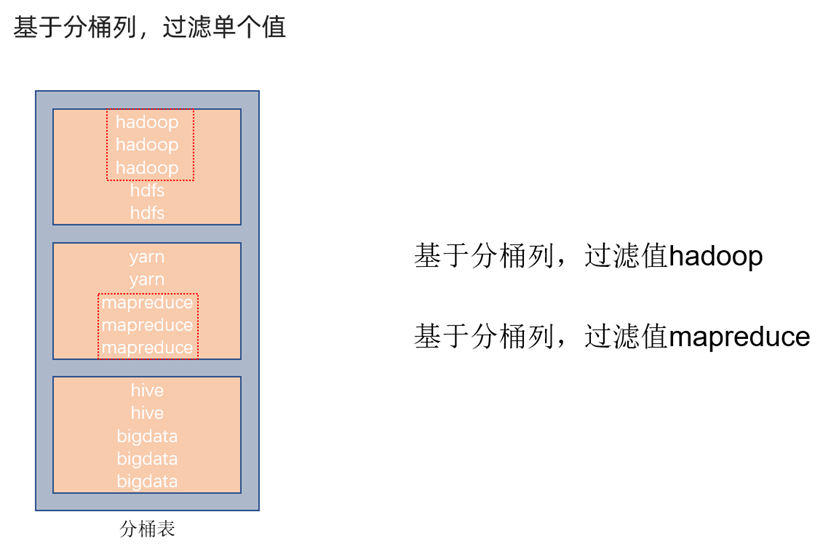
由于cluster相同在同一桶中,过滤就操作就可以直接在cluster所在的桶中进行,不用扫描全表。
对于联合查询JOIN的性能提升
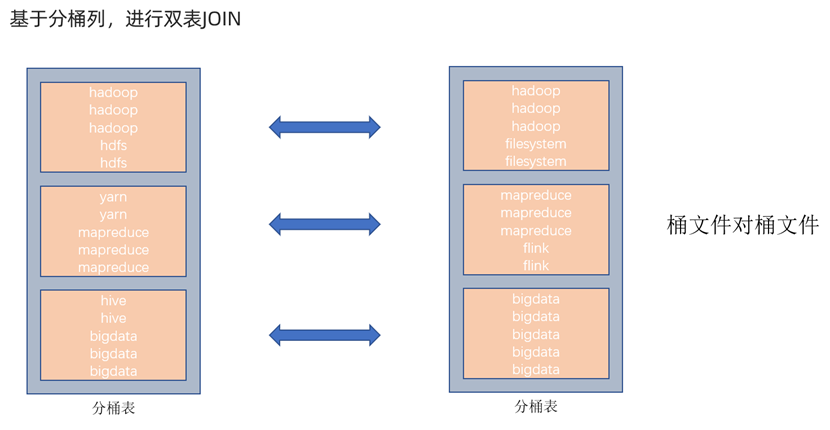
由于cluster相同的在同一桶中,JOIN ON操作就可以直接将两表cluster各自所在的桶文件互相对应,无需循环匹配数据。
对于group by分组的性能提升
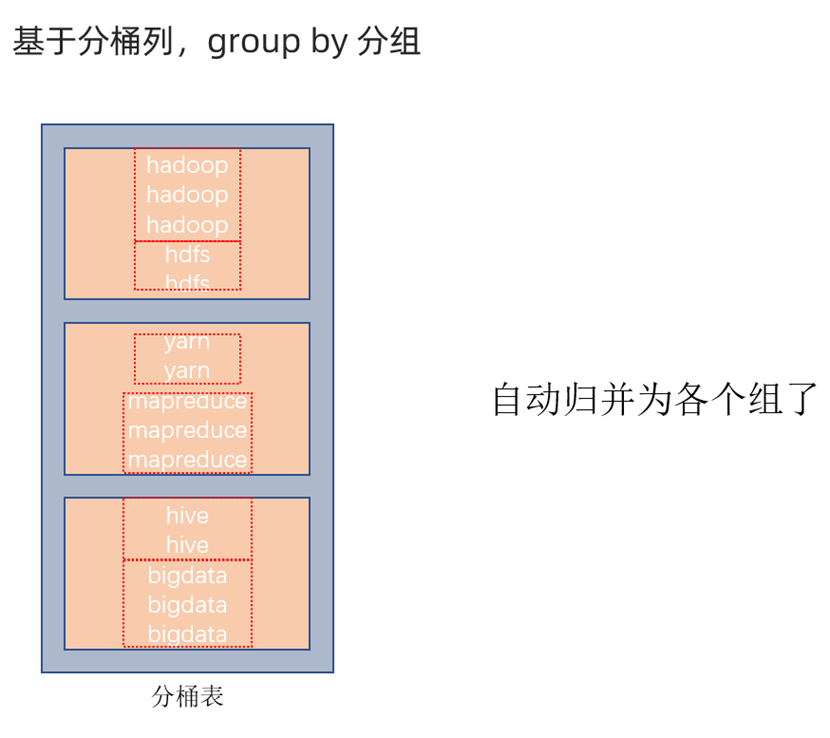
由于cluster相同的被分到同一桶中,这实际上就已经为我们进行了分组。我们只需要单独对该桶内的元素进一步分组即可,不用扫描全表查找对应元素。
总结


修改表操作
表属性修改相关

表重命名

alter table 已有表 rename to 新表名;修改表属性

alter table score set tblproperties 你要更改的表属性;分区修改相关

添加分区

alter table score add partition(month='202508');修改分区值
![]()
alter table score partition (month = '202507') rename to partition (month = '202509');注意事项

我们将month=’202507’的分区修改为month=’202509‘的分区后,hdfs中的实体文件并没有更改。这是由于我们使用的是外部表,通过alter对分区属性的修改仅是对元数据的修改,这部分数据所处的文件夹并未被修改。也就是说,修改后的数据中,month=’202509’的一系列数据仍然位于month=’202507’的文件夹下方。
因此在实际工作中,不建议修改外部表分区值,因为这很可能造成数据字段与hdfs实体文件夹不相符,从而产生混乱。
删除分区

alter table score drop partition (month = '202508');注意事项
与修改分区值相同,若使用外部表进行操作,将不会导致数据发送变化,元数据和数据相互独立。
表字段修改相关

这些操作均与MySQL相符,此处不详细介绍。
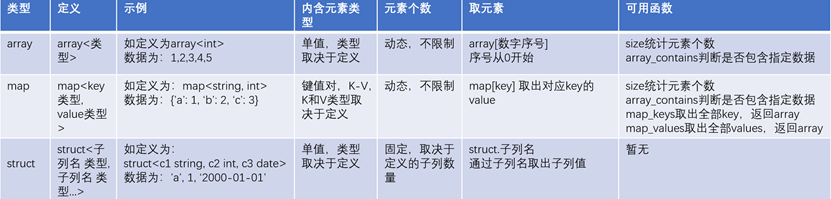
Hive的复杂数据类型操作

Array类型操作

创建包含array类型数据的表

Array数据类型必须存储相同类型的元素,因此创建时需要指定泛型。
创建时,需要指定字段间的分隔符(row format) & array数据间的分隔符(collection items)。注意分隔符需要与数据文件分隔符一致!
将数据导入包含array数据类型的表中

常用array数据类型查询方法

相关演示
创建包含Array数据类型的数据表
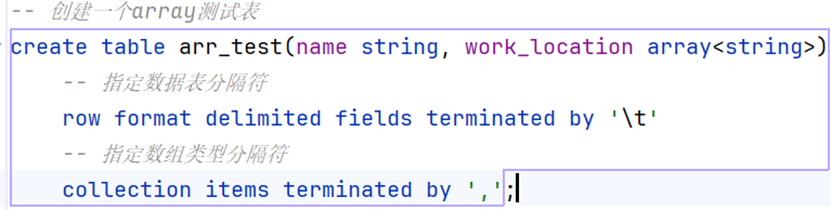
-- 创建一个array测试表
create table arr_test(name string, work_location array<string>)
-- 指定数据表分隔符
row format delimited fields terminated by '\t'
-- 指定数组类型分隔符
collection items terminated by ',';加载本地数据到表中
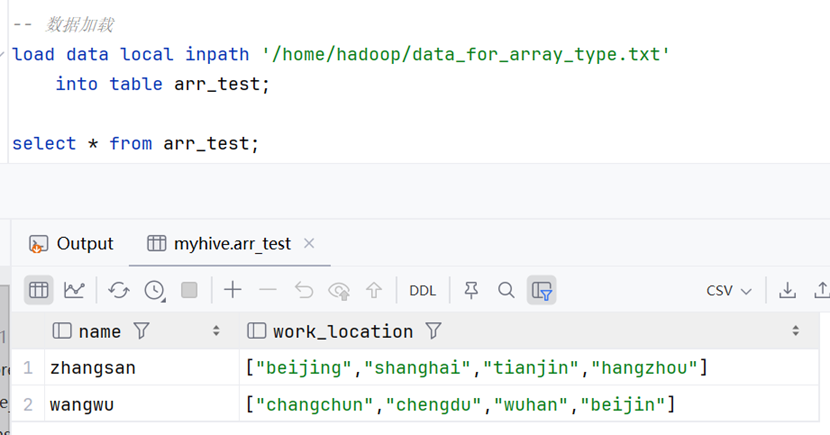
-- 数据加载
load data local inpath '/home/hadoop/data_for_array_type.txt'
into table arr_test;查询array相关数据

-- 查询每个人工作的第一个城市
select name, work_location[0] from arr_test;
-- 查询每个人工作的城市个数
select name, size(arr_test.work_location) from arr_test;
-- 查询有在某个特定城市工作的人(即数组中包含该元素)
select name from arr_test where array_contains(work_location, 'beijing');总结

Map类型操作

创建包含map类型数据的表
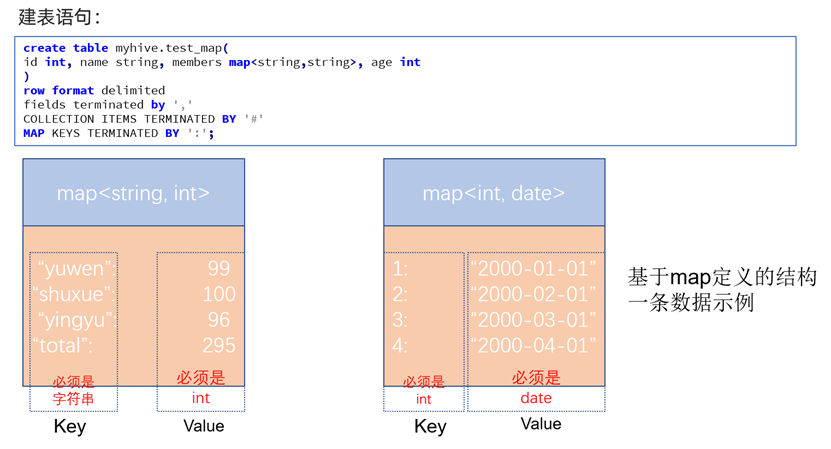
与java相同,map的key或value内的元素必须是同一类型的。我们需要用泛型指定keys的类型 & values的类型。
创建时,除了字段间的分隔符外,还需要额外指定map的两个分隔符:多对map数据间的分隔符 & 每对map数据内的分隔符。注意分隔符需要与数据文件分隔符一致!
将数据导入包含map数据类型的表中

常用map数据类型查询方法

通过map_keys() & map_values()方法返回的数据均为array类型,我们可以通过这两个函数拿到对应的keys 或 values,然后通过array_contains()函数筛选包含对应元素的数据。
相关演示
创建一个包含map类型的数据表

-- 创建一个包含map类型的数据表
create table map_test(
id int,
name string,
members map<string, string>,
age int
)
-- 指定字段分隔符
row format delimited fields terminated by ','
-- 指定多对map数据间的分隔符
collection items terminated by '#'
-- 指定每对map数据内的分隔符
map keys terminated by ':';数据加载

-- 数据加载
load data local inpath '/home/hadoop/data_for_map_type.txt'
into table map_test;查询map相关数据
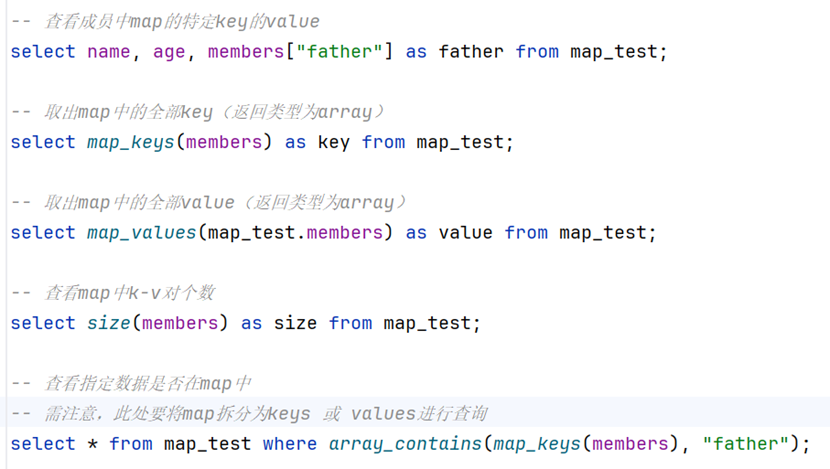
-- 查看成员中map的特定key的value
select name, age, members["father"] as father from map_test;
-- 取出map中的全部key(返回类型为array)
select map_keys(members) as key from map_test;
-- 取出map中的全部value(返回类型为array)
select map_values(map_test.members) as value from map_test;
-- 查看map中k-v对个数
select size(members) as size from map_test;
-- 查看指定数据是否在map中
-- 需注意,此处要将map拆分为keys 或 values进行查询
select * from map_test where array_contains(map_keys(members), "father");总结

Struct类型操作

创建包含struct类型数据的表
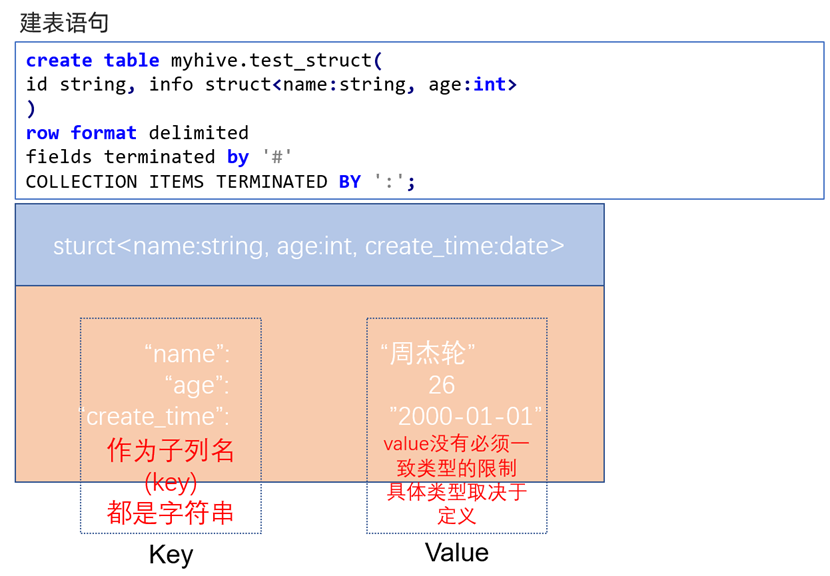
当我们想要存储包含不同数据类型的多列数据到一个字段中时(可以理解为将一个对象存储到这个列中),由于这个对象有不同属性的元素,因此不能使用array进行存储;又由于这个对象的不同属性间是平级关系,且多于2个属性,因此使用map存储也行不通。
此时我们就可以通过struct类型进行存储。可以理解为,我们在创建数据表时创建了一个对象字段,这个对象字段中有几个属性(对象的成员变量),我们后续可以将数据文件中的对应对象数据存到这个字段中。需要注意的是,成员变量的数据类型一旦确定,就必须严格遵守,否则会报错。
同样的,我们不仅需要指定列分隔符,还需要指定对象的属性间的分隔符(可以类比map元素内的分隔符)。由于每条数据的struct字段只会存在一个struct对象,因此我们不需要像map一样,指定每对map元素间的分隔符,只需要指定当前对象的属性间分隔符即可。
注意分隔符需要与数据文件分隔符一致!
将数据导入包含struct数据类型的表

常用struct数据类型查询方法
由于struct的属性在建表时已经确定,因此无需通过size()函数查询struct内部元素个数。同时,由于struct类型属于复合格式,因此也无法通过array、map的函数筛选对应数据。
相关演示
创建一个包含struct数据类型的表
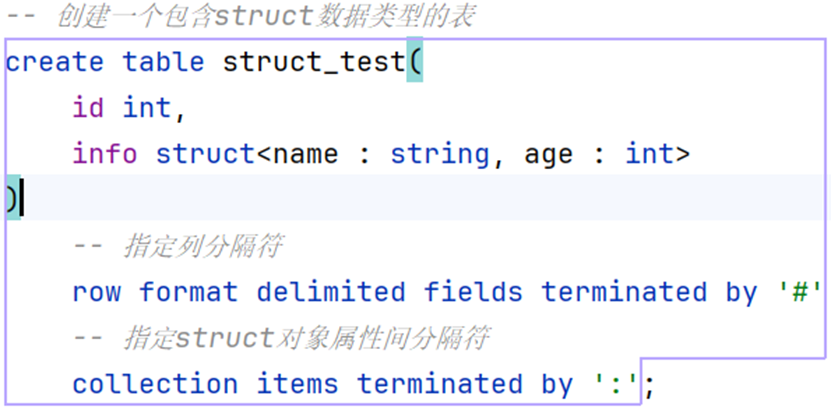
-- 创建一个包含struct数据类型的表
create table struct_test(
id int,
info struct<name : string, age : int>
)
-- 指定列分隔符
row format delimited fields terminated by '#'
-- 指定struct对象属性间分隔符
collection items terminated by ':';数据加载

-- 数据加载
load data local inpath '/home/hadoop/data_for_struct_type.txt'
into table struct_test;查询struct相关数据

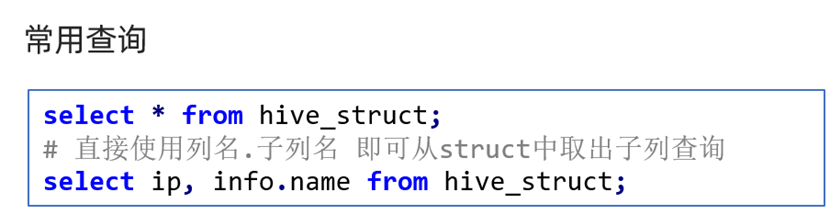
-- 查询特定对象属性的内容
select id, info.name from struct_test;总结

总结
数据查询
基础查询

RLIKE正则匹配
正则表达式(regex)
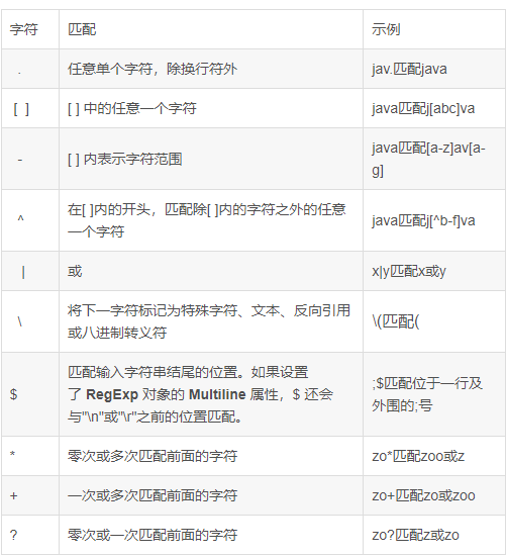
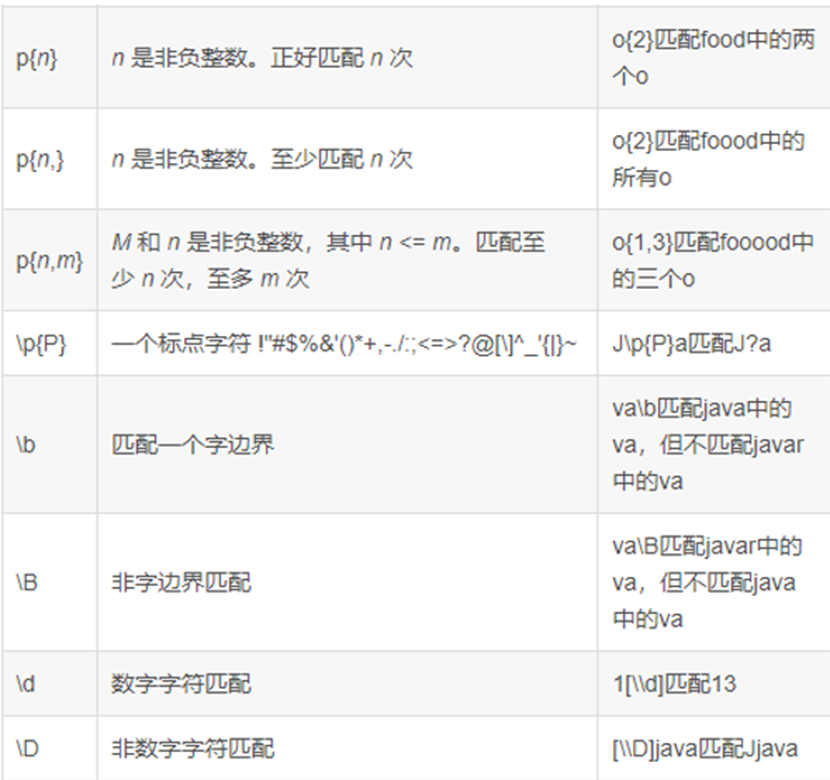
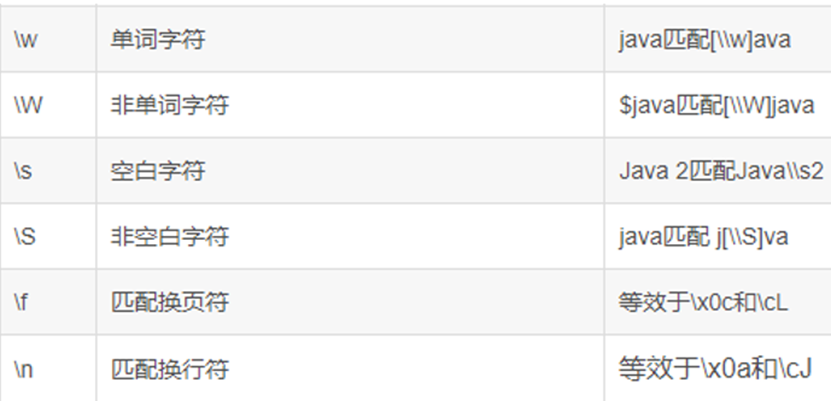
在使用LIKE时,我们可以通过‘%’来表示任意数量字符。而使用RLIKE时,我们则需要使用正则表达式,通过’.*’来匹配任意字符。其中,’.’表示匹配一个任意字符,’*’则表示匹配前面任意数量的字符。
RLIKE语法使用

一些案例演示
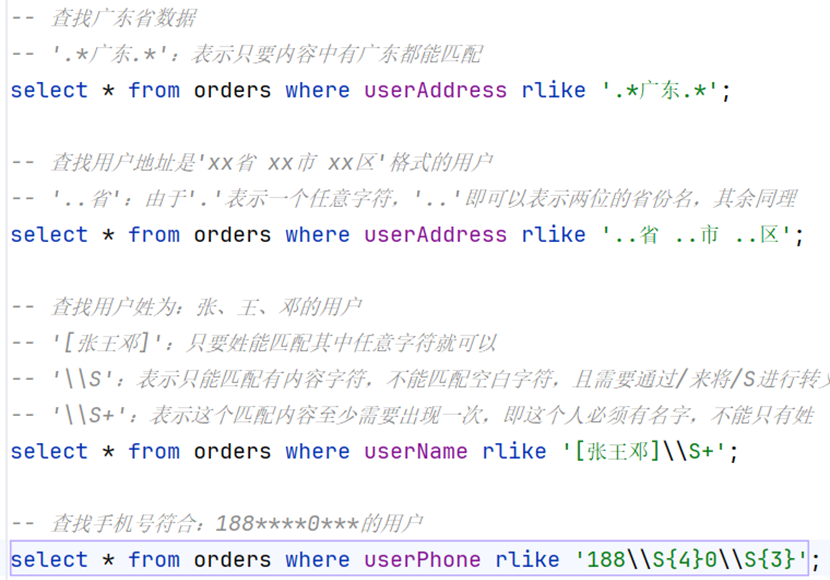
-- 查找广东省数据
-- '.*广东.*':表示只要内容中有广东都能匹配
select * from orders where userAddress rlike '.*广东.*';
-- 查找用户地址是'xx省 xx市 xx区'格式的用户
-- '..省':由于'.'表示一个任意字符,'..'即可以表示两位的省份名,其余同理
select * from orders where userAddress rlike '..省 ..市 ..区';
-- 查找用户姓为:张、王、邓的用户
-- '[张王邓]':只要姓能匹配其中任意字符就可以
-- '\\S':表示只能匹配有内容字符,不能匹配空白字符,且需要通过/来将/S进行转义
-- '\\S+':表示这个匹配内容至少需要出现一次,即这个人必须有名字,不能只有姓
select * from orders where userName rlike '[张王邓]\\S+';
-- 查找手机号符合:188****0***的用户
select * from orders where userPhone rlike '188\\S{4}0\\S{3}';UNION联合
基础语法

select * from course where cid like '3'
union
select * from course where cid like '7';UNION的去重

UNION在子查询中的应用


Sampling采样
抽样数据的重要性

由于大数据体系下,对于数据的处理常常会执行MapReduce流程,那么即使是查看少量数据,也会因此而变得非常慢,这显然不合理。因此我们需要一些方法,能够抽取表中部分数据让用户查看。
Hive的TABLESAMPLE抽样函数
语法1,基于随机分桶抽样

若基于column,由于同一个列值相同,因此hash取模后结果也相同,所以分桶并不改变,结果也不会改变。若基于整行随机,那么每一次结果都将会不同。
一般来说,基于rand()抽样运行速度会更快,这是因为其不用像基于column那样需要计算该列hash值。但如果这个数据表是一张分桶表,且我们又需要根据分桶列进行抽样,那么显然,由于该列已经进行分桶,此时使用column抽样将会更有效率。
语法2,基于数据块抽样

这其实不算是随机,而是基于数据顺序选取。因此当抽样条件不变时,结果也不会改变。由于这只需要按顺序选取,无需筛选,因此执行速度也相当快。
抽样演示
基于桶抽样
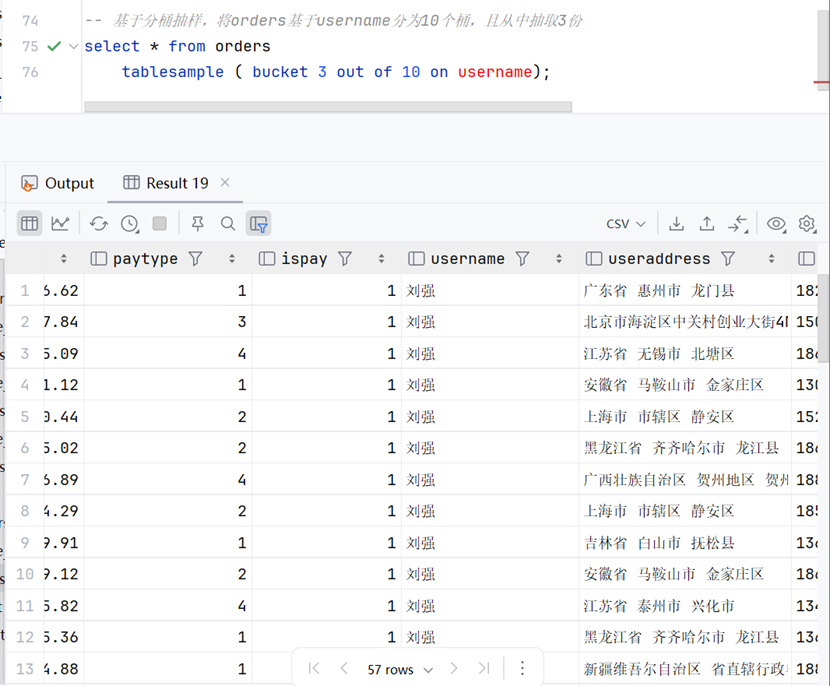
-- 将orders基于username分为10个桶,且从中抽取3份
select * from orders
tablesample ( bucket 3 out of 10 on username);基于数据库抽样
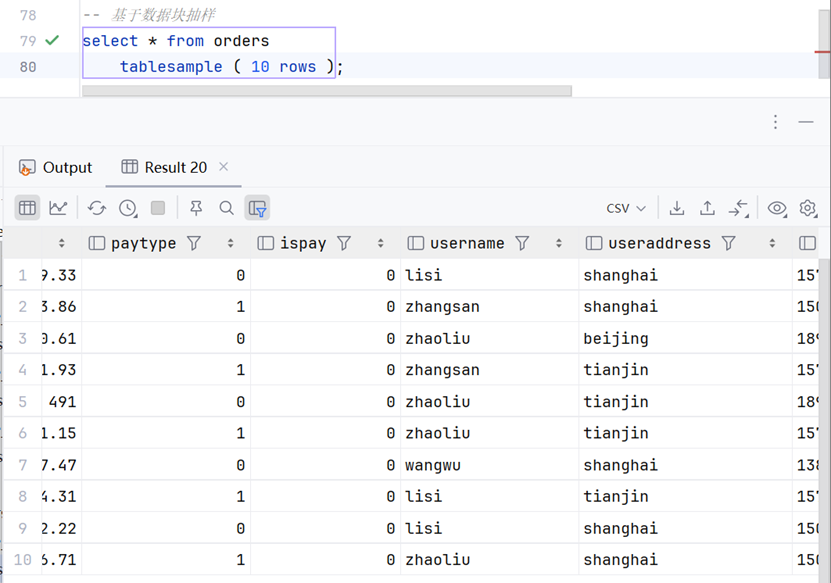
-- 基于数据块抽样
select * from orders
tablesample ( 10 rows );总结

若需要随机抽样,则使用基于桶抽样;若需要快速抽样,则使用基于数据块抽样。
Virtual Column虚拟列
虚拟列概念 & 作用
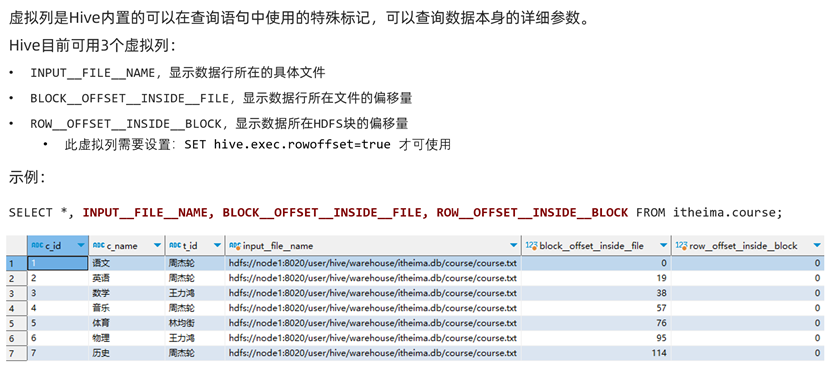

虚拟列是Hive为我们提供的通过SQL查询数据本身参数的标记,我们可以查看这些数据的所在文件、偏移量等等。我们甚至可以通过聚合函数,统计这张表占据了多少数据文件,或者这个分桶表总共有几个桶文件,每个桶文件中有多少条数据等等。
虚拟列查询示例
基础查询
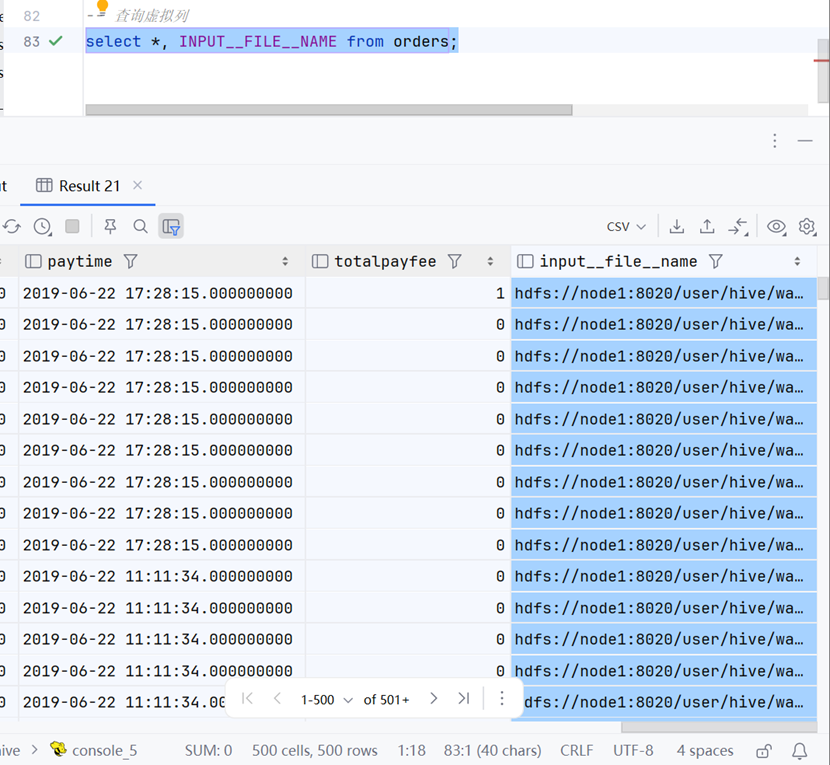
-- 查询虚拟列
select *, INPUT__FILE__NAME from orders;聚合函数中的虚拟列查询
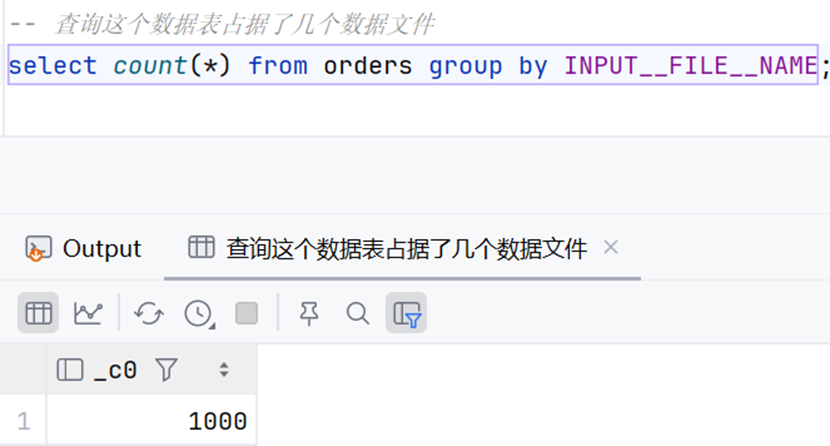
-- 查询这个数据表占据了几个数据文件
select count(*) from orders group by INPUT__FILE__NAME;总结

函数
Hive函数总览

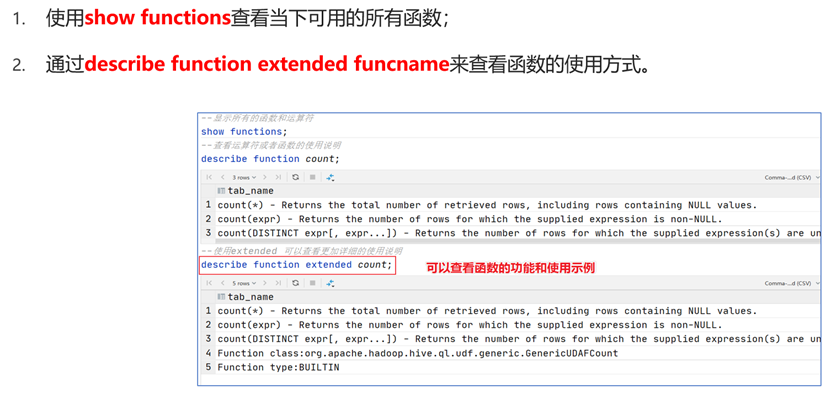
具体可见官方文档LanguageManual UDF - Apache Hive - Apache Software Foundation
查看Hive的函数列表 & 使用方法
数值函数(部分)

示例

取整 & 精度控制
-- 取整函数 & 精度控制
select round(3.14);
select round(3.14, 1);
取随机数
-- 取随机数
select rand(); -- 每次完全随机
select rand(3); -- 设置种子后,每次结果是一致的
取绝对值
-- 取绝对值
select abs(-10);
求pi
-- 求pi
select pi();集合函数(全部)
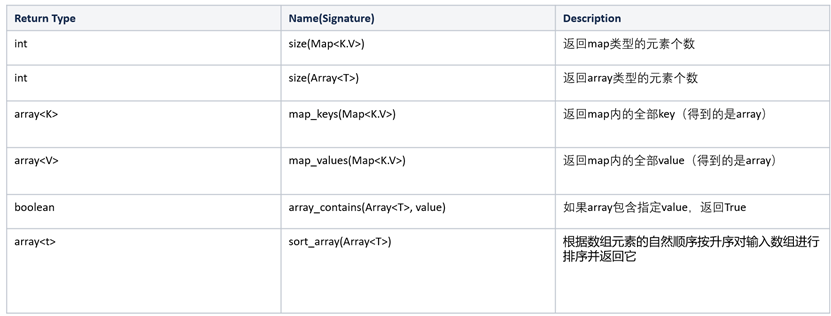
示例
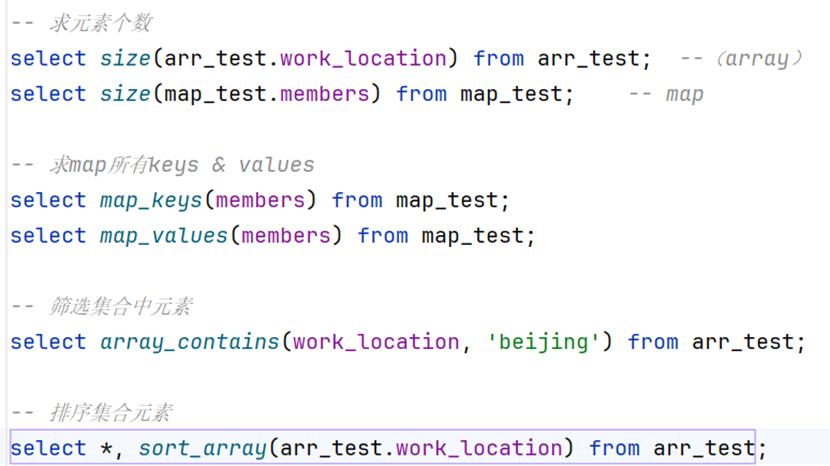
求元素个数
-- 求元素个数
select size(arr_test.work_location) from arr_test; --(array)
select size(map_test.members) from map_test; -- map求map的所有keys & values
-- 求map所有keys & values
select map_keys(members) from map_test;
select map_values(members) from map_test;筛选集合中元素
-- 筛选集合中元素
select array_contains(work_location, 'beijing') from arr_test;排序集合元素
-- 排序集合元素(按元素内容升序)
select *, sort_array(arr_test.work_location) from arr_test;类型转换函数(全部)

示例

转换为二进制
-- 转换为二进制
select 'hadoop', binary('hadoop');任意类型转换
-- 任意类型转换(将字符串'1'转换为数字类型)
select cast('1' as bigint);日期函数(部分)
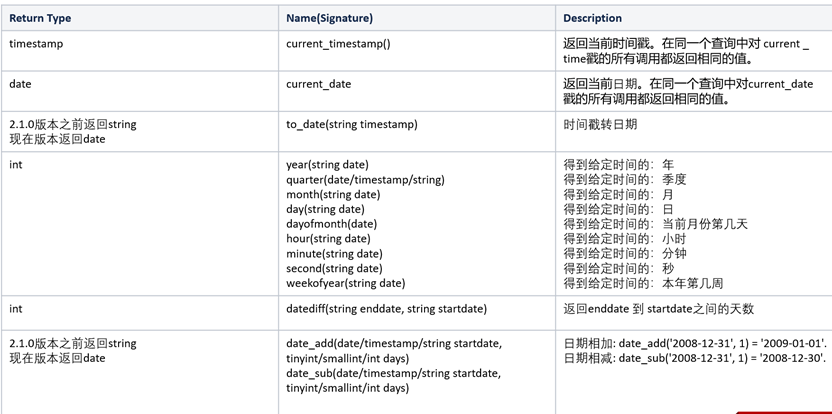
示例
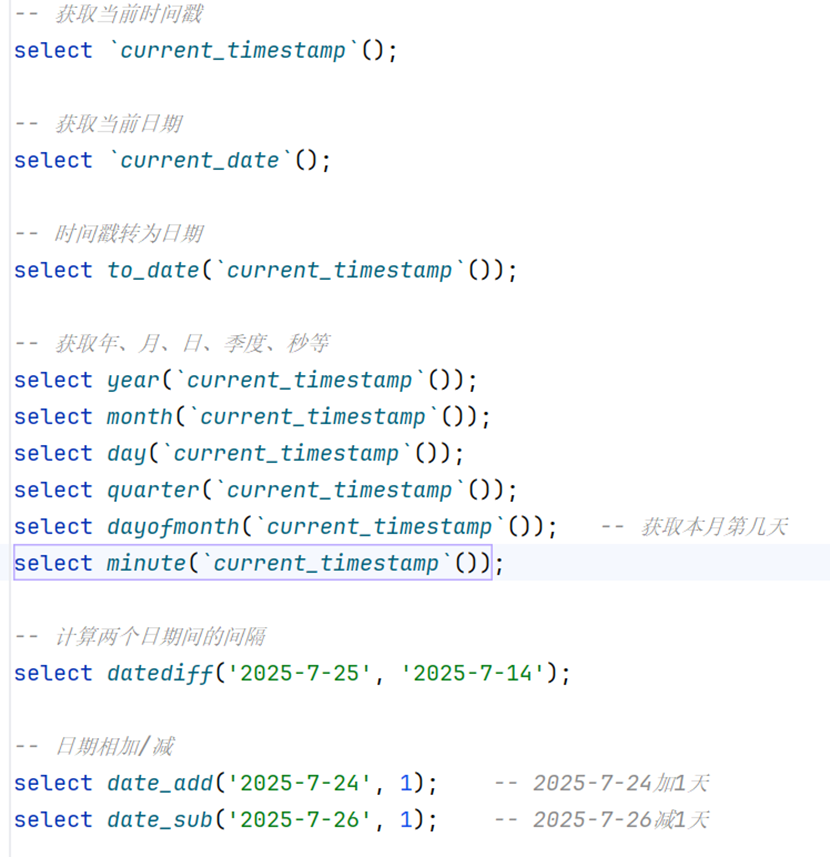
获取当前时间戳
-- 获取当前时间戳
select `current_timestamp`();获取当前日期
-- 获取当前日期
select `current_date`();时间戳转为日期
-- 时间戳转为日期
select to_date(`current_timestamp`());获取日期参数的年、月、日等
-- 获取年、月、日、季度、秒等
select year(`current_timestamp`());
select month(`current_timestamp`());
select day(`current_timestamp`());
select quarter(`current_timestamp`());
select dayofmonth(`current_timestamp`()); -- 获取本月第几天
select minute(`current_timestamp`());计算两个日期间的间隔
-- 计算两个日期间的间隔
select datediff('2025-7-25', '2025-7-14');日期相加/减
-- 日期相加/减
select date_add('2025-7-24', 1); -- 2025-7-24加1天
select date_sub('2025-7-26', 1); -- 2025-7-26减1天条件函数(全部)

示例
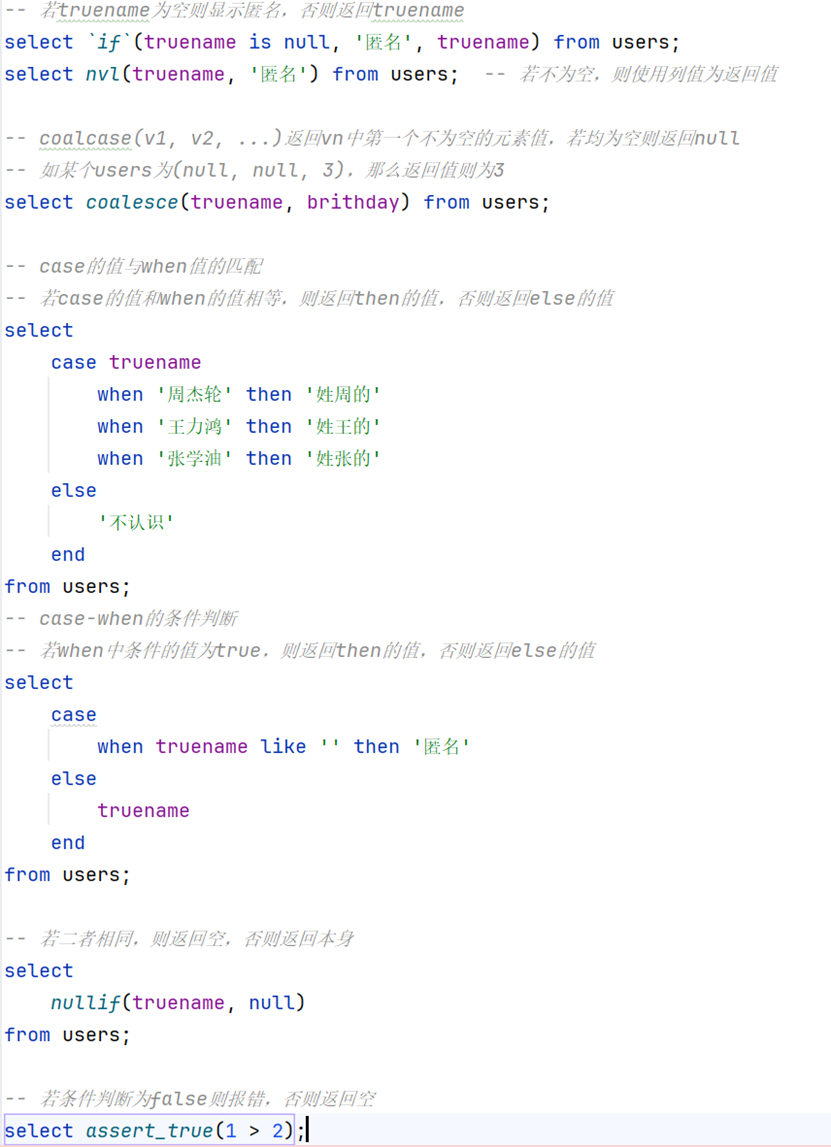
通过if & nvl函数判断truename是否为空
-- 若truename为空则显示匿名,否则返回truename
select `if`(truename is null, '匿名', truename) from users;
select nvl(truename, '匿名') from users; -- 若不为空,则使用列值为返回值coalcase返回当前行数据中第一个非空值
-- coalcase(v1, v2, ...)返回vn中第一个不为空的元素值,若均为空则返回null
-- 如某个users为(null, null, 3),那么返回值则为3
select coalesce(truename, brithday) from users;case-when
case的值与when的值进行匹配
-- case的值与when值的匹配
-- 若case的值和when的值相等,则返回then的值,否则返回else的值
select
case truename
when '周杰轮' then '姓周的'
when '王力鸿' then '姓王的'
when '张学油' then '姓张的'
else
'不认识'
end
from users;case-when的条件判断
-- case-when的条件判断
-- 若when中条件的值为true,则返回then的值,否则返回else的值
select
case
when truename like '' then '匿名'
else
truename
end
from users;nullif
-- 若二者相同,则返回空,否则返回本身
select
nullif(truename, null)
from users;assert_true
-- 若条件判断为false则报错,否则返回空
select assert_true(1 > 2);字符串函数(部分)

示例
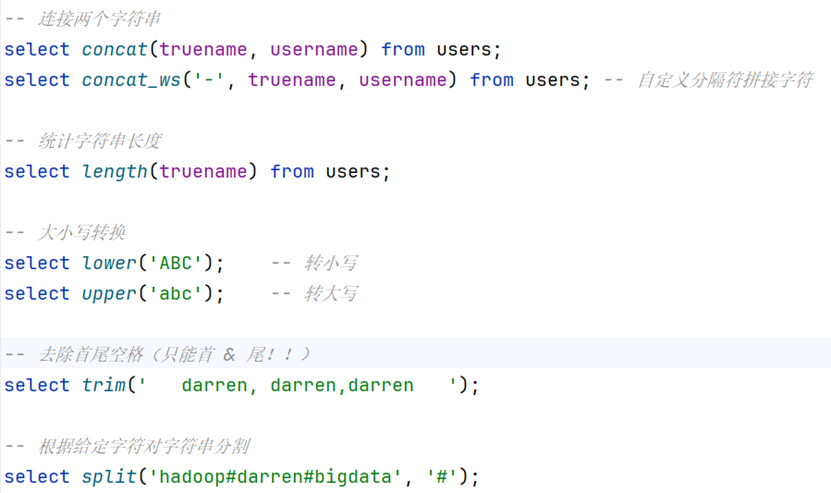
连接字符串
-- 连接两个字符串
select concat(truename, username) from users;
select concat_ws('-', truename, username) from users; -- 自定义分隔符拼接字符统计字符串长度
-- 统计字符串长度
select length(truename) from users;转换大小写
-- 大小写转换
select lower('ABC'); -- 转小写
select upper('abc'); -- 转大写去除首尾空格
-- 去除首尾空格(只能首 & 尾!!)
select trim(' darren, darren,darren ');按字符分割字符串
-- 根据给定字符对字符串分割
select split('hadoop#darren#bigdata', '#');数据脱敏函数(部分)

示例
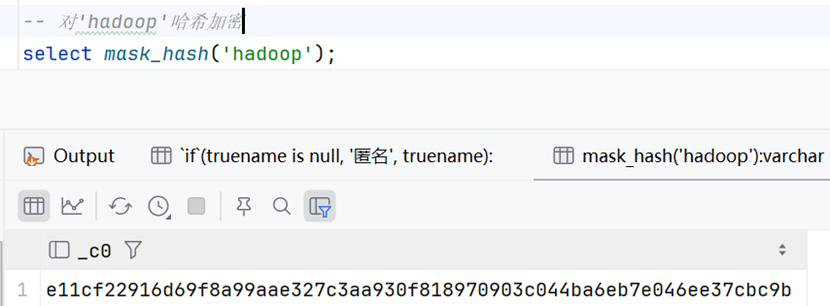
-- 对'hadoop'哈希加密
select mask_hash('hadoop');其他函数(部分)

示例
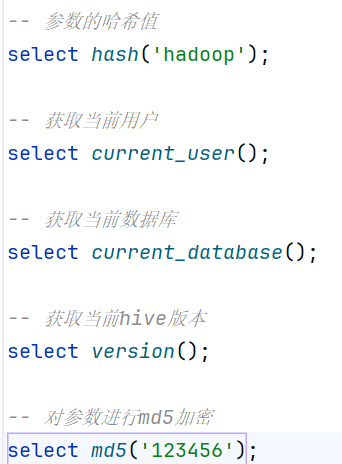
-- 参数的哈希值
select hash('hadoop');
-- 获取当前用户
select current_user();
-- 获取当前数据库
select current_database();
-- 获取当前hive版本
select version();
-- 对参数进行md5加密
select md5('123456');案例实现
需求分析
案例背景
案例目标
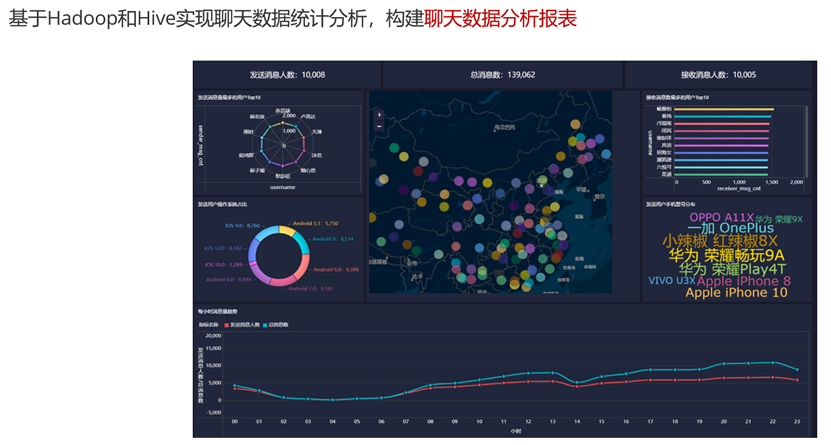
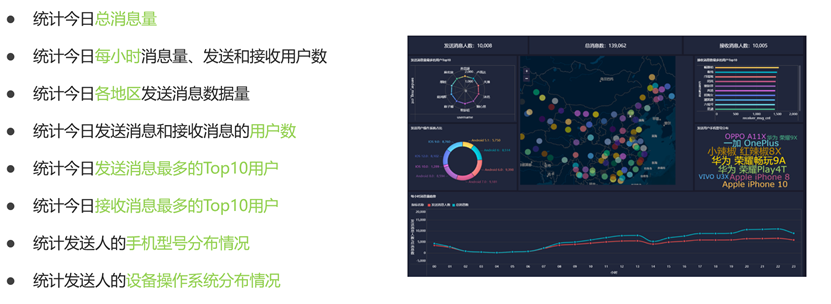
统计指标
数据准备
数据内容(数据文件结构)
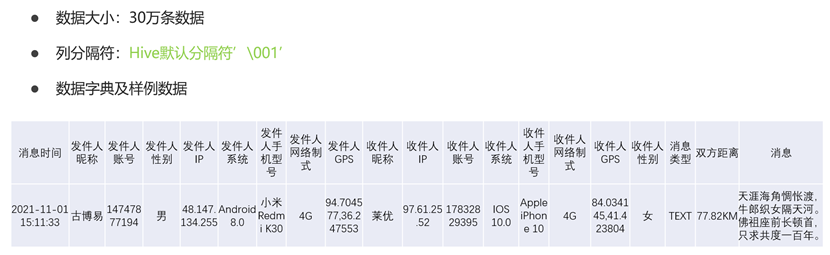
数据文件分隔符采用Hive默认分隔符,因此后续建表时无需自定义分隔符。
建库建表
建库
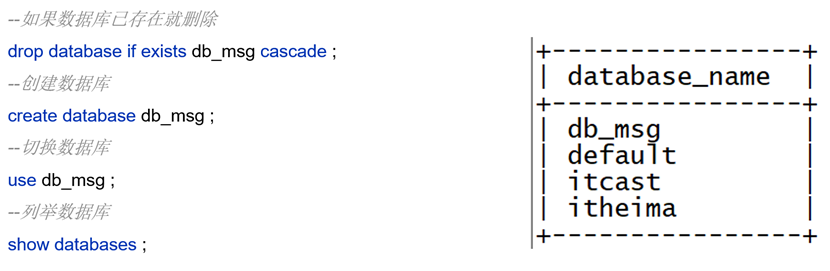
-- 1. 如果数据库已存在则删除(级联删除所有表)
DROP DATABASE IF EXISTS db_msg CASCADE;
-- 2. 创建新数据库(使用COMMENT添加描述)
CREATE DATABASE db_msg
COMMENT '消息业务数据库';
-- 3. 切换到目标数据库
USE db_msg;
-- 4. 验证数据库列表(确认创建成功)
SHOW DATABASES;建表

-- 创建消息源表(带完整注释和存储格式)
CREATE TABLE tb_msg_source (
msg_time STRING COMMENT '消息发送时间,格式:yyyy-MM-dd HH:mm:ss',
sender_name STRING COMMENT '发送人昵称',
sender_account STRING COMMENT '发送人账号',
sender_sex STRING COMMENT '发送人性别:M(男)/F(女)/U(未知)',
sender_ip STRING COMMENT '发送人IP地址',
sender_os STRING COMMENT '发送人操作系统:iOS/Android/Windows/Other',
sender_phonetype STRING COMMENT '发送人手机型号',
sender_network STRING COMMENT '发送人网络类型:4G/5G/WiFi/Other',
sender_gps STRING COMMENT '发送人GPS定位,格式:经度,纬度',
receiver_name STRING COMMENT '接收人昵称',
receiver_ip STRING COMMENT '接收人IP地址',
receiver_account STRING COMMENT '接收人账号',
receiver_os STRING COMMENT '接收人操作系统:iOS/Android/Windows/Other',
receiver_phonetype STRING COMMENT '接收人手机型号',
receiver_network STRING COMMENT '接收人网络类型:4G/5G/WiFi/Other',
receiver_gps STRING COMMENT '接收人GPS定位,格式:经度,纬度',
receiver_sex STRING COMMENT '接收人性别:M(男)/F(女)/U(未知)',
msg_type STRING COMMENT '消息类型:text/image/video/audio/location',
distance STRING COMMENT '双方距离(单位:米)',
message STRING COMMENT '消息内容(文本或媒体URL)'
);数据加载


-- 加载数据
load data local inpath '/home/hadoop/chat_data-30W.csv' into table tb_msg_source;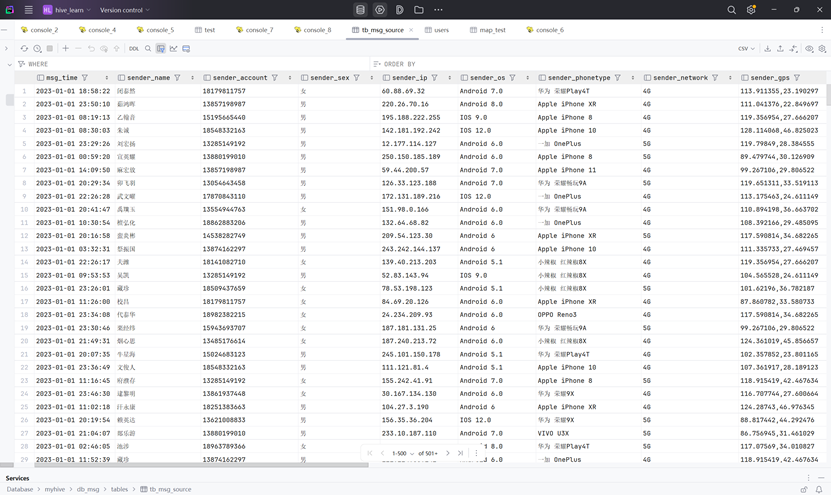
ETL数据清洗
为什么要进行数据清洗
我们的原始数据文件具有一些问题,由于我们直接将其导入了数据库中,所以我们需要针对这部分数据进行去除或者更新,以使得这些数据能符合我们统计规范。
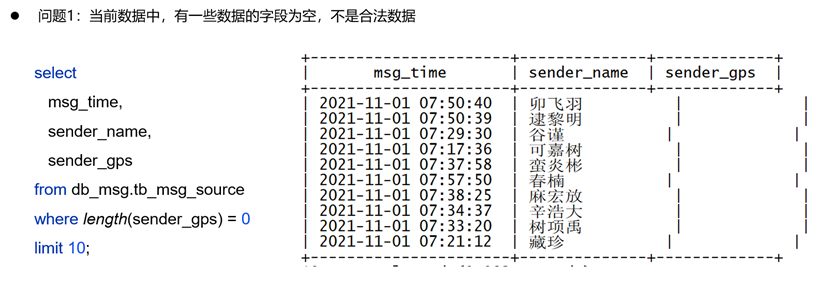
后续我们需要根据某些字段(如sender_gps)进行统计,但有些数据这些字段为空,这表示这些数据是不合法的,我们需要对其进行去除。
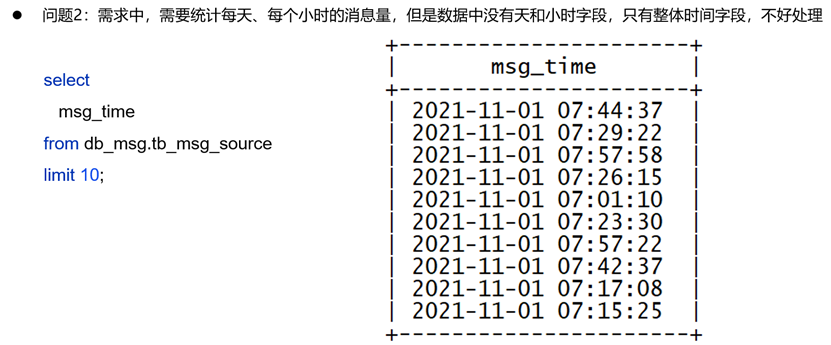
我们需要统计每天、每小时的信息量,而msg_time中存储的日期是时间戳格式,我们显然无法直接通过时间戳统计这些数据。因此我们需要将这些字段基于日期函数,获取其中的日期、小时等内容。

对于sender_gps不为空的字段,由于其经纬度是混合的,所以我们需要拆分以分别处理。
ETL需求

ETL实现
数据过滤

select *,
-- 获取日期具体参数
day(msg_time) msg_day, hour(msg_time) msg_hour,
-- 获取经纬度具体参数
split(sender_gps, ',')[0] sender_lng, split(sender_gps, ',')[1] sender_lat
from tb_msg_source
-- 去除sender_gps为空的数据
where sender_gps is not null;结果表创建

-- 创建ETL处理后的消息表(带完整注释和优化配置)
CREATE TABLE db_msg.tb_msg_etl (
-- 原始消息字段
msg_time STRING COMMENT '消息发送时间,格式:yyyy-MM-dd HH:mm:ss',
sender_name STRING COMMENT '发送人昵称',
sender_account STRING COMMENT '发送人账号',
sender_sex STRING COMMENT '发送人性别:M(男)/F(女)/U(未知)',
sender_ip STRING COMMENT '发送人IP地址',
sender_os STRING COMMENT '发送人操作系统:iOS/Android/Windows/Other',
sender_phonetype STRING COMMENT '发送人手机型号',
sender_network STRING COMMENT '发送人网络类型:4G/5G/WiFi/Other',
sender_gps STRING COMMENT '发送人GPS定位原始数据',
-- 接收方信息
receiver_name STRING COMMENT '接收人昵称',
receiver_ip STRING COMMENT '接收人IP地址',
receiver_account STRING COMMENT '接收人账号',
receiver_os STRING COMMENT '接收人操作系统',
receiver_phonetype STRING COMMENT '接收人手机型号',
receiver_network STRING COMMENT '接收人网络类型',
receiver_gps STRING COMMENT '接收人GPS定位原始数据',
receiver_sex STRING COMMENT '接收人性别',
-- 消息内容
msg_type STRING COMMENT '消息类型:text/image/video/audio/location',
distance STRING COMMENT '双方距离(单位:米)',
message STRING COMMENT '消息内容(文本或媒体URL)',
-- ETL新增字段
msg_day STRING COMMENT '消息日期(yyyy-MM-dd)',
msg_hour STRING COMMENT '消息小时(0-23)',
sender_lng DOUBLE COMMENT '发送人经度(WGS84坐标系)',
sender_lat DOUBLE COMMENT '发送人纬度(WGS84坐标系)'
)
COMMENT '消息数据ETL处理结果表';数据加载到新表
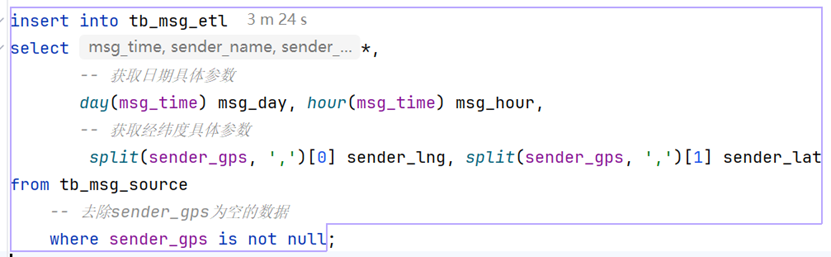
insert into tb_msg_etl
select *,
-- 获取日期具体参数
day(msg_time) msg_day, hour(msg_time) msg_hour,
-- 获取经纬度具体参数
split(sender_gps, ',')[0] sender_lng, split(sender_gps, ',')[1] sender_lat
from tb_msg_source
-- 去除sender_gps为空的数据
where sender_gps is not null;ETL介绍

抽取(E):对应我们从原始表中获取全部数据。
转换(T):对应我们对数据进行过滤、拆分等。
加载(L):对应我们将新数据加载到新表中。
指标计算
统计需求总览

具体实现
今日消息总量统计
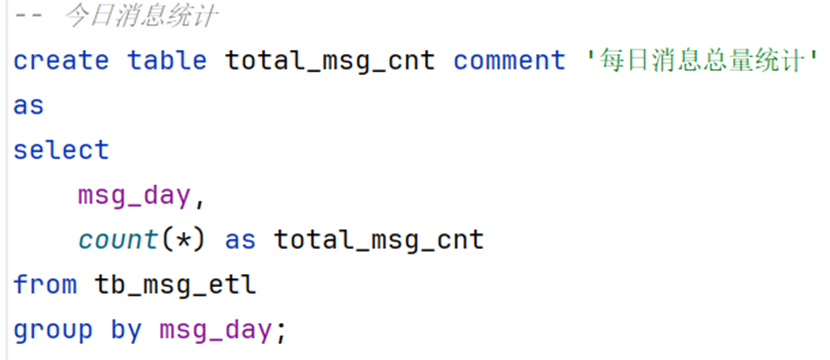
-- 今日消息统计
create table total_msg_cnt comment '每日消息总量统计'
as
select
msg_day,
count(*) as total_msg_cnt
from tb_msg_etl
group by msg_day;每小时消息量、发送 & 接收用户数
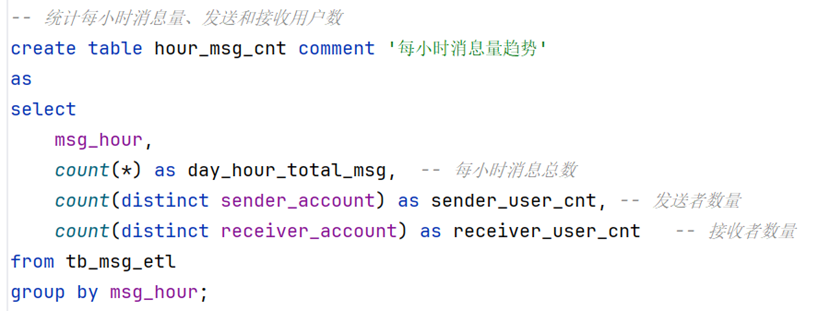
-- 统计每小时消息量、发送和接收用户数
create table hour_msg_cnt comment '每小时消息量趋势'
as
select
msg_hour,
count(*) as day_hour_total_msg, -- 每小时消息总数
count(distinct sender_account) as sender_user_cnt, -- 发送者数量
count(distinct receiver_account) as receiver_user_cnt -- 接收者数量
from tb_msg_etl
group by msg_hour;统计今日各地区发送消息量
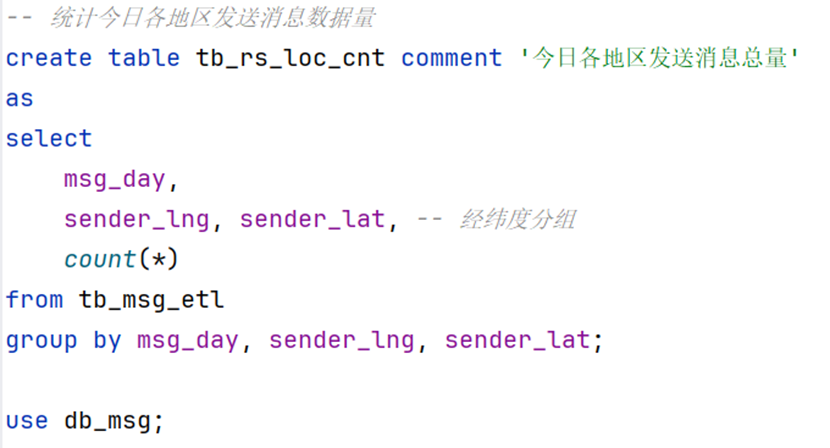
-- 统计今日各地区发送消息数据量
create table tb_rs_loc_cnt comment '今日各地区发送消息总量'
as
select
msg_day,
sender_lng, sender_lat, -- 经纬度分组
count(*)
from tb_msg_etl
group by msg_day, sender_lng, sender_lat;
use db_msg;统计今日发送消息和接收消息的用户数
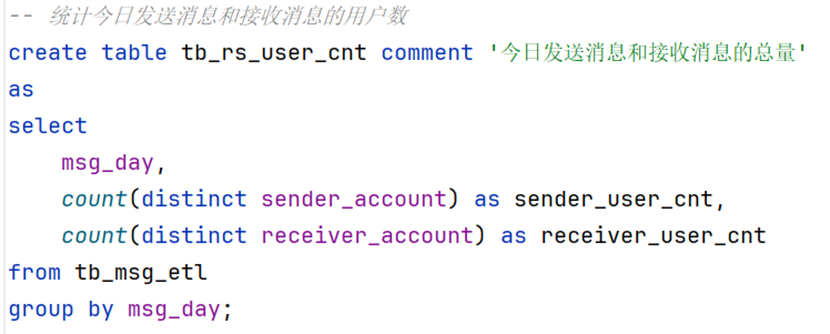
-- 统计今日发送消息和接收消息的用户数
create table tb_rs_user_cnt comment '今日发送消息和接收消息的总量'
as
select
msg_day,
count(distinct sender_account) as sender_user_cnt,
count(distinct receiver_account) as receiver_user_cnt
from tb_msg_etl
group by msg_day;发送消息最多的Top10
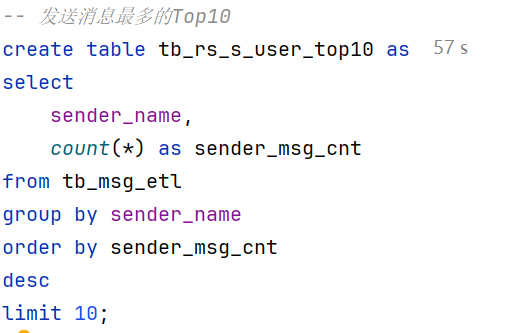
-- 发送消息最多的Top10
create table tb_rs_s_user_top10 as
select
sender_name,
count(*) as sender_msg_cnt
from tb_msg_etl
group by sender_name
order by sender_msg_cnt
desc
limit 10;接收消息最多的Top10

-- 接收消息最多的Top10
create table tb_rs_r_user_top10 as
select
receiver_name,
count(*) as receiver_msg_cnt
from tb_msg_etl
group by receiver_name
order by receiver_msg_cnt
desc
limit 10;发送人手机型号分布统计
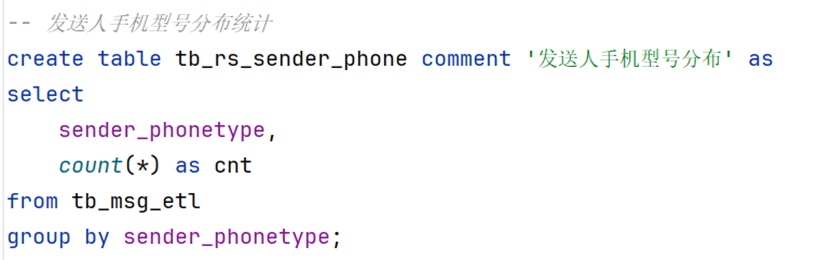
-- 发送人手机型号分布统计
create table tb_rs_sender_phone comment '发送人手机型号分布' as
select
sender_phonetype,
count(*) as cnt
from tb_msg_etl
group by sender_phonetype;发送人设备操作系统分布情况
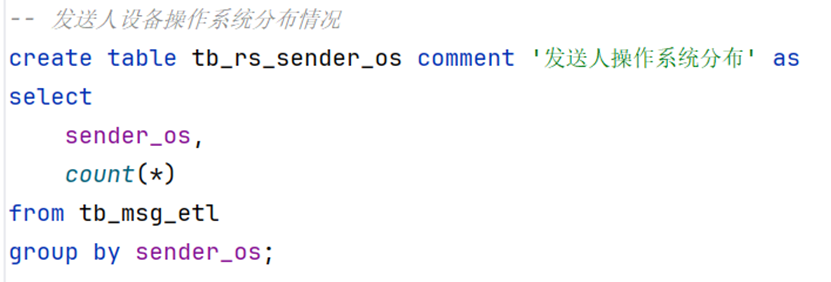
-- 发送人设备操作系统分布情况
create table tb_rs_sender_os comment '发送人操作系统分布' as
select
sender_os,
count(*)
from tb_msg_etl
group by sender_os;可视化展现
BI概述
BI介绍

说白了就是许多应用聚合体,可以完成数据挖掘、数据分析、数据展示等功能,以为商业公司提供商业价值。
FineBI
FineBI介绍 & 安装
介绍
特点

FineBI的界面展示
登录界面
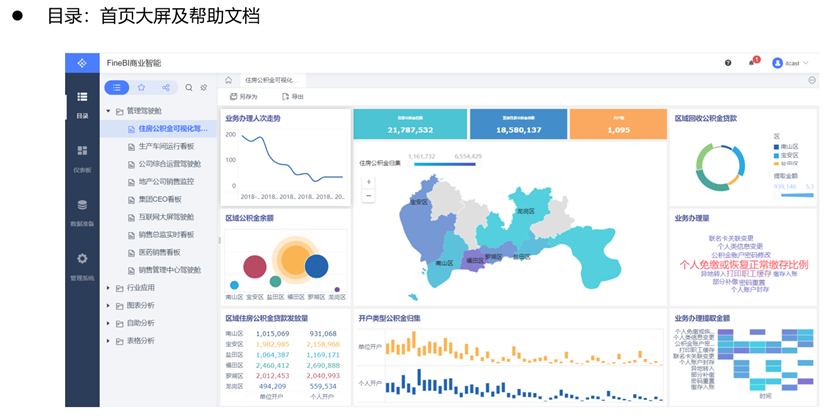
目录界面
仪表盘界面
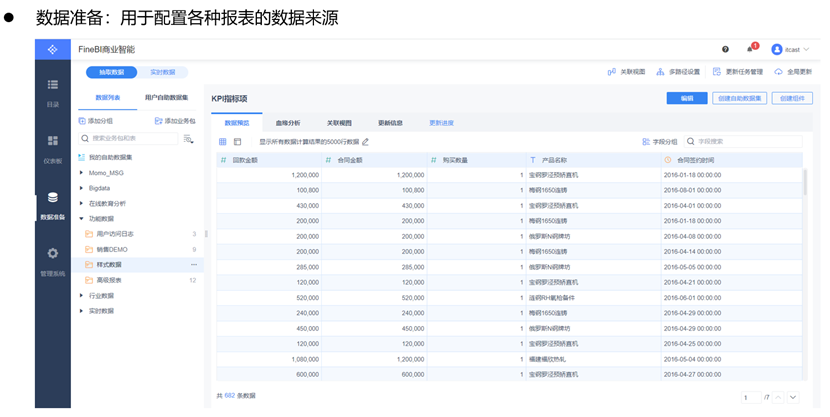
数据准备界面
管理系统界面

数据源配置 & 数据准备
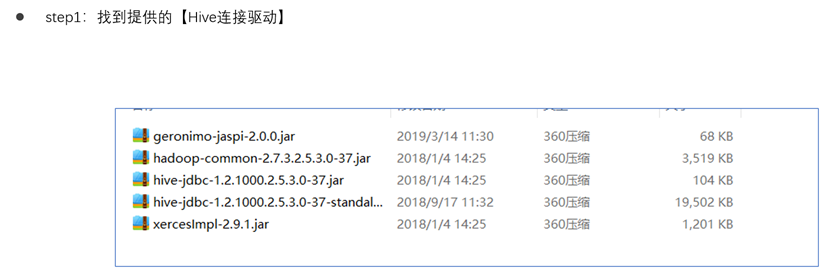
驱动配置

STEP1
STEP2
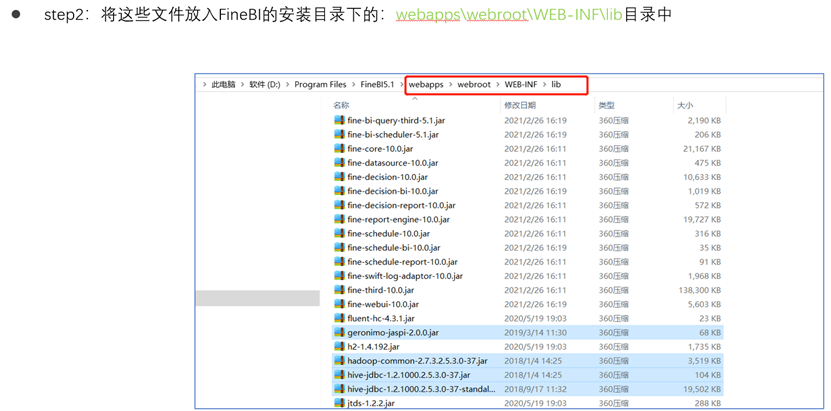
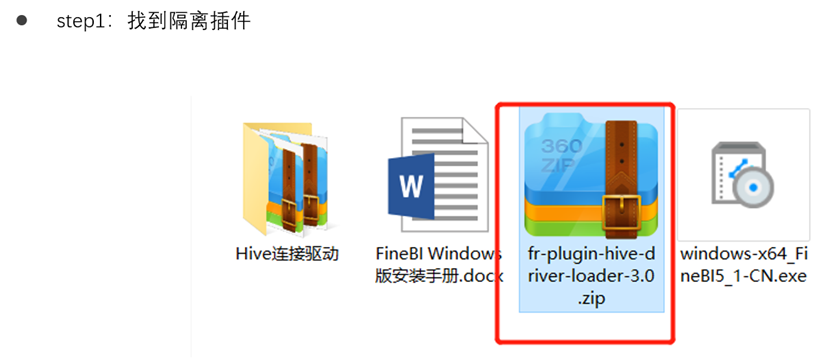
连接插件安装

STEP1
STEP2
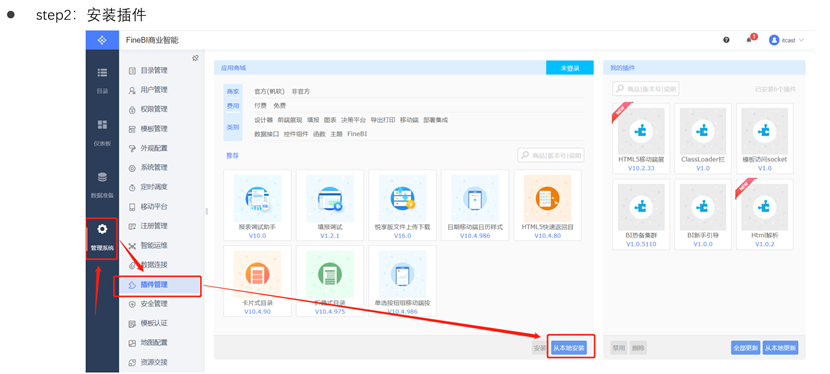
STEP3
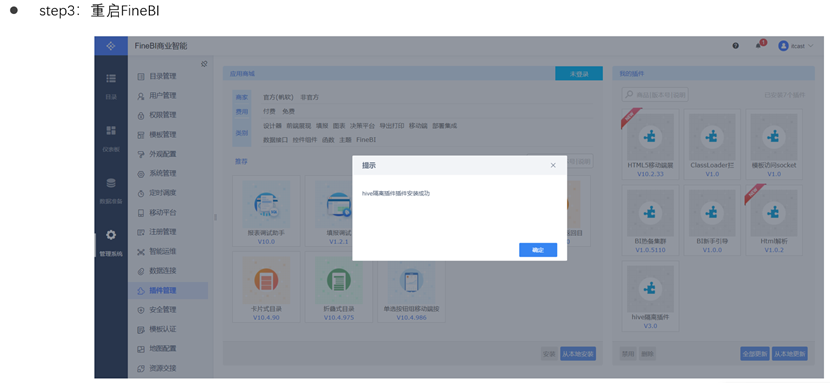
构建连接
新建连接
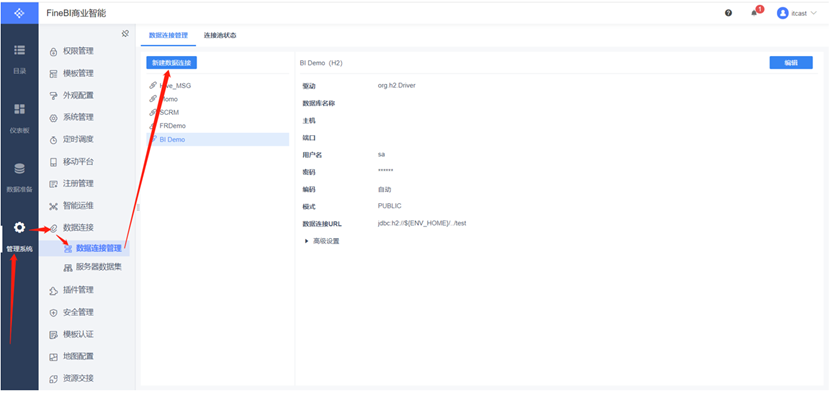

配置连接
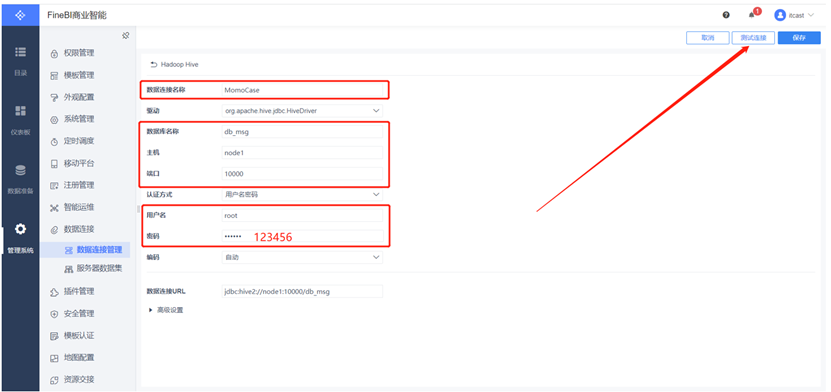

测试连接
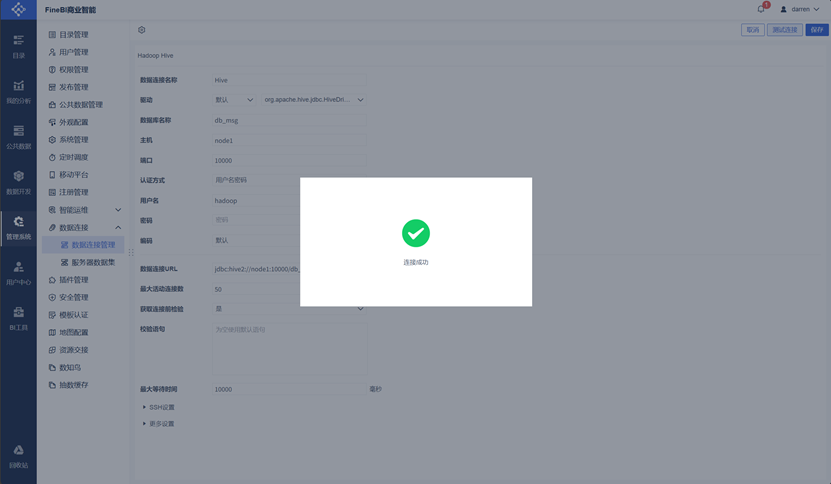
保存连接
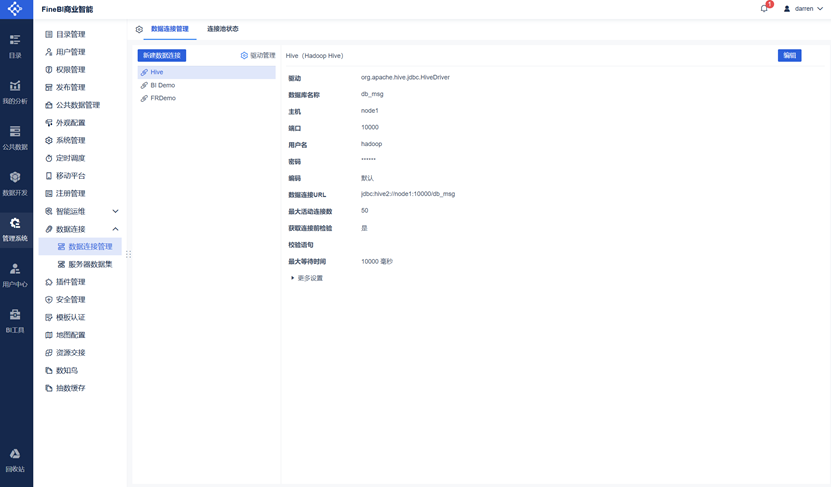
FineBI可视化实操
基于接收消息人数的示例
创建FineBI的数据集
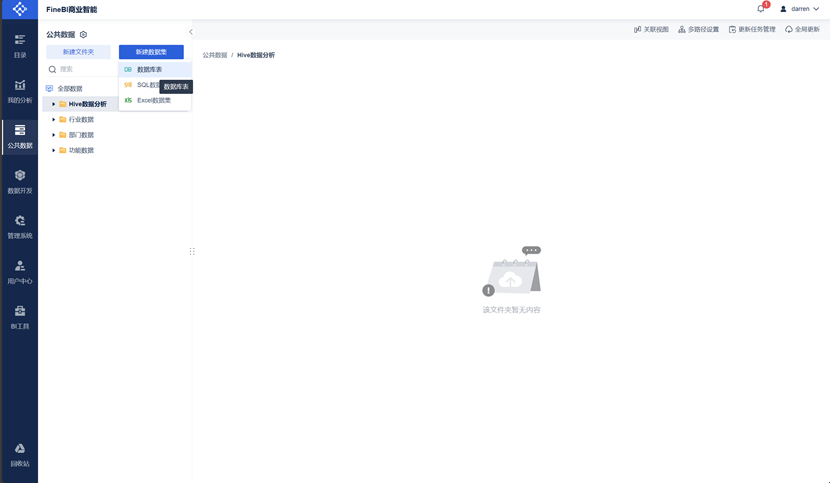
在公共数据界面,新建Hive数据分析文件夹,用于存放此次分析所用的数据集。然后选中该文件夹,点击左上角的新建数据集——数据库表。
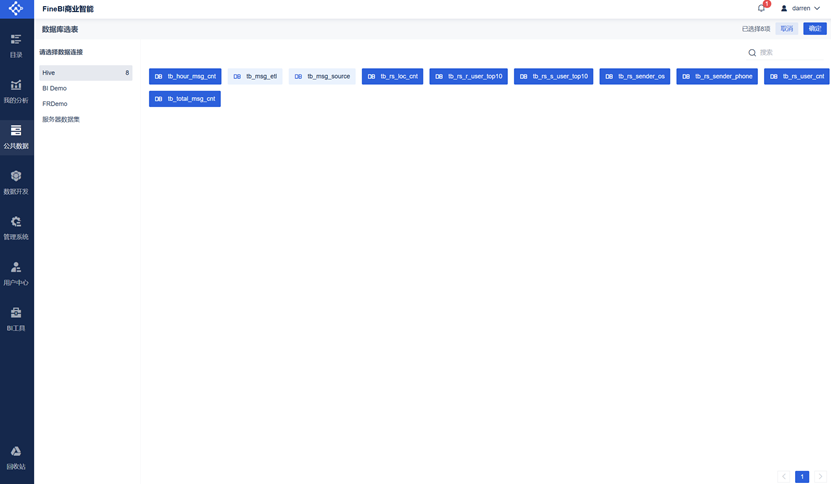
选中我们之前通过指标计算创建的统计表,点击确定。
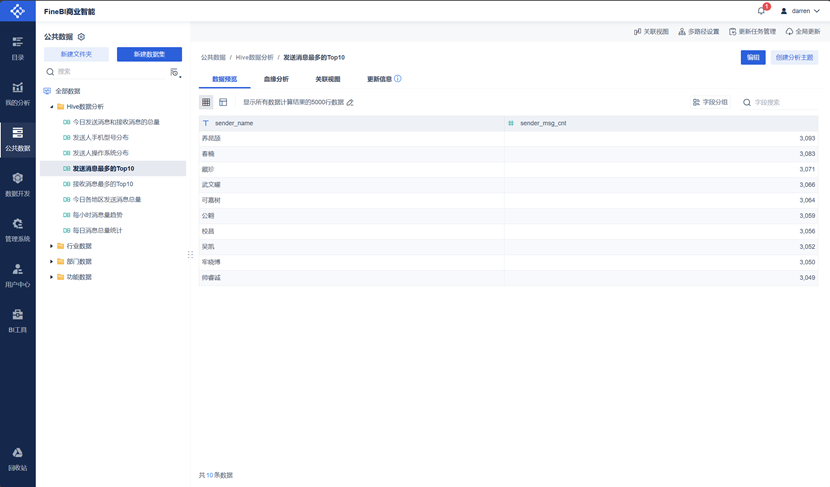
数据集连接完成,对每张表都点击数据更新,完成后我们可以在其中查看数据集内容,字段 & 属性值。
创建FineBI的数据分析主题
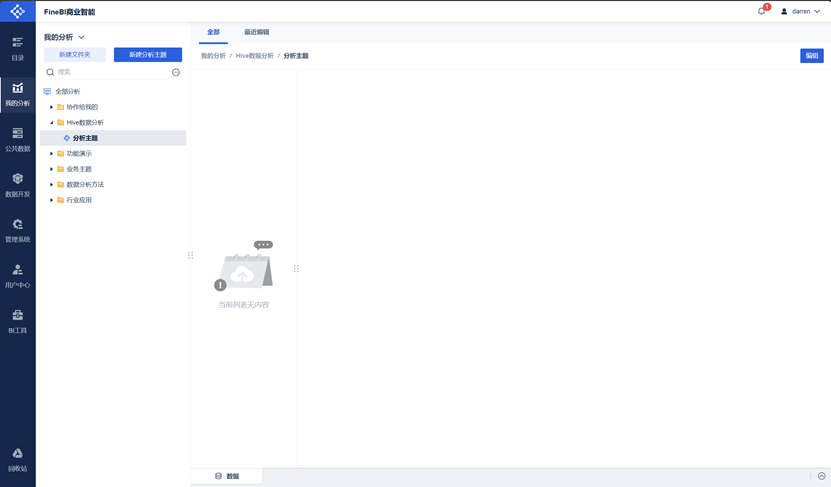
点击我的分析,创建Hive数据分析文件夹,然后添加分析主题。
创建接收消息人数的数据分析组件
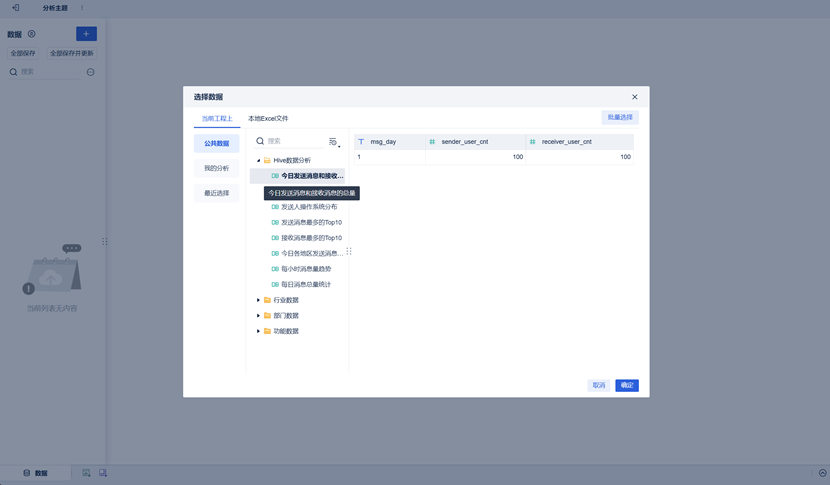
选中上一步创建的分析主题,点击编辑,选中我们数据集中的一张表,点击确定。
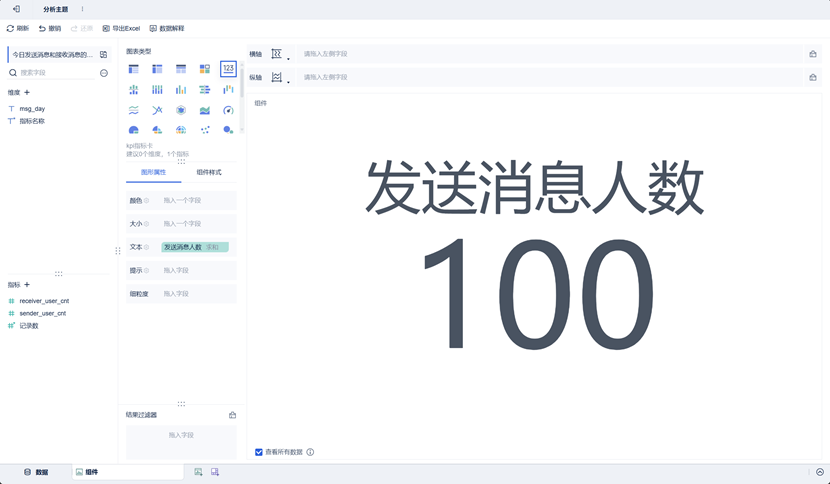
然后点击左下角组件,就可以对当前数据进行可视化分析。如图,我们选中图表类型中的123,然后将左下指标内容拖入其中,通过图形属性进行编辑,即可实现图中样式。
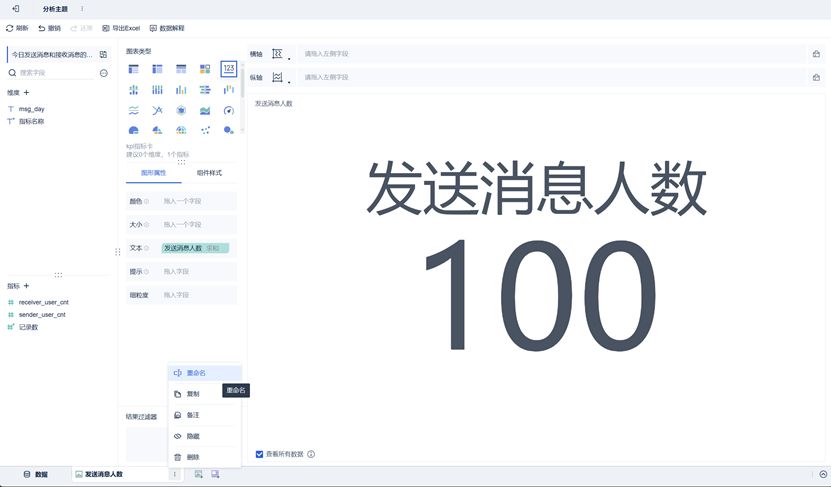
创建完成后,为该组件重命名,即可保存组件,让我们可以在仪表板中使用。
创建仪表板,添加组件
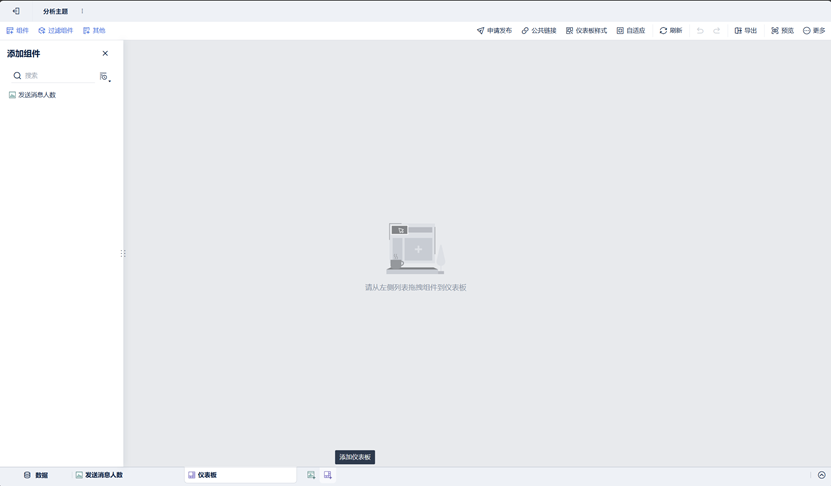
点击下方按钮,可以添加仪表板。
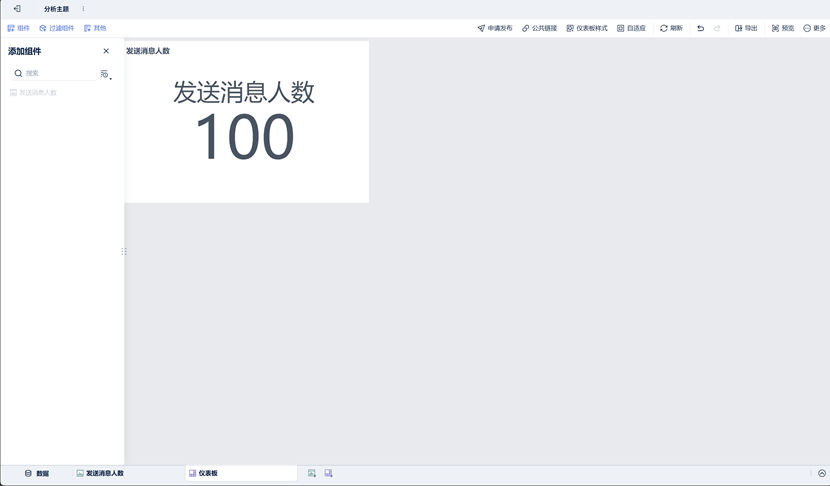
将组件拖入其中,就可以编辑其大小、样式。
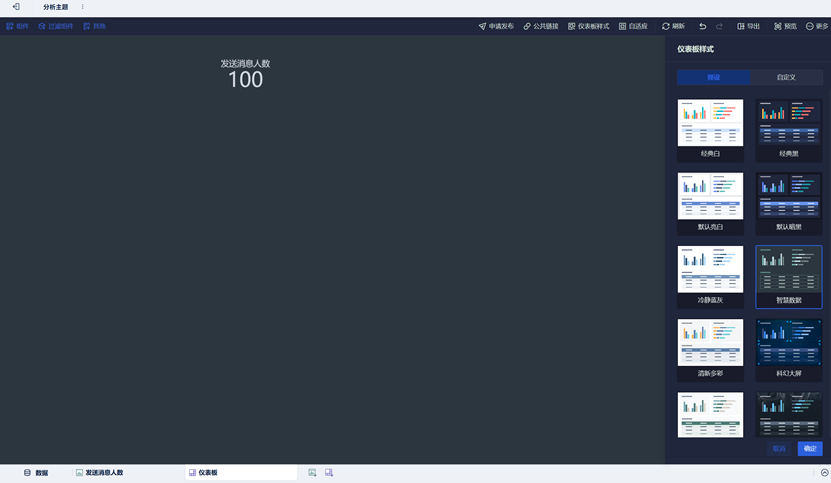
然后我们点击右上角仪表板样式,就可以编辑仪表板背景颜色等内容。
数据分析组件的总览(基于指标计算统计数据表)
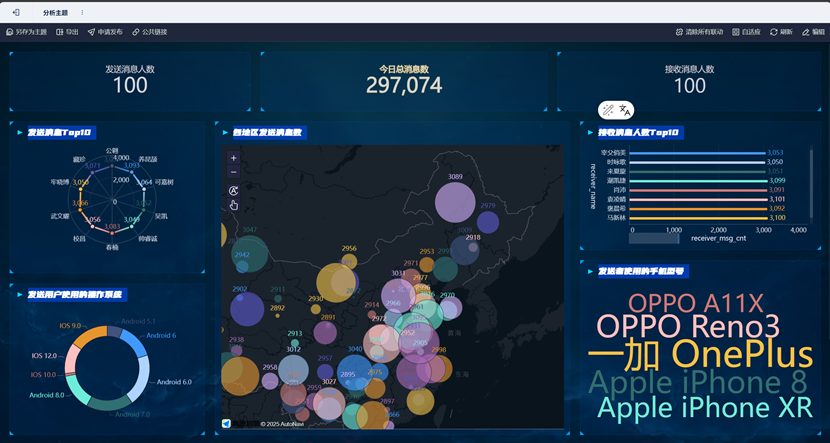
发送消息人数、接收消息人数、今日总消息数组件
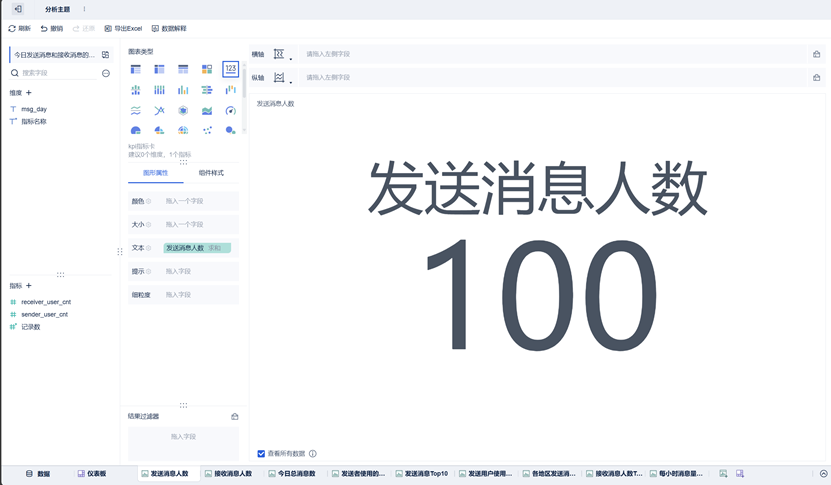
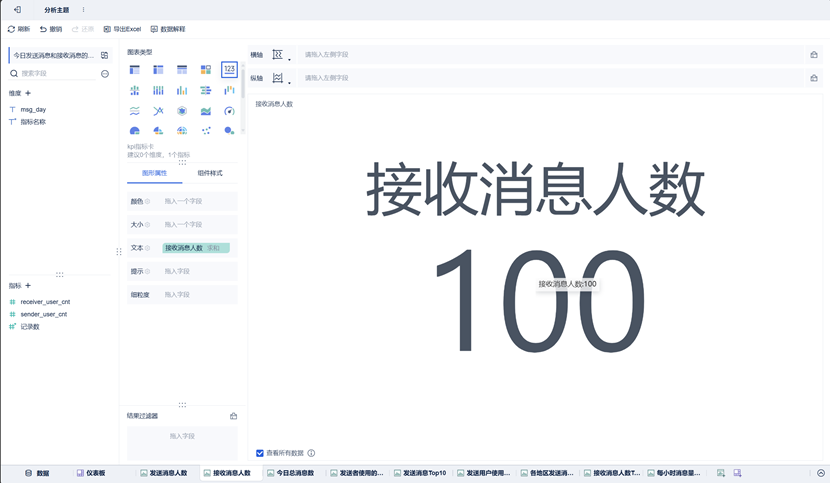
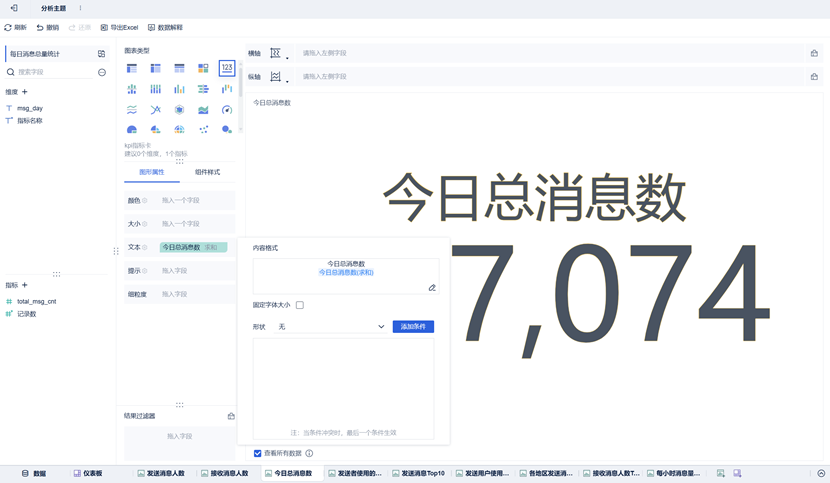
该组件使用图表类型为文本。可以在文本处将固定字体大小去除,这样在仪表板中显示可以大一些。
发送消息Top10组件
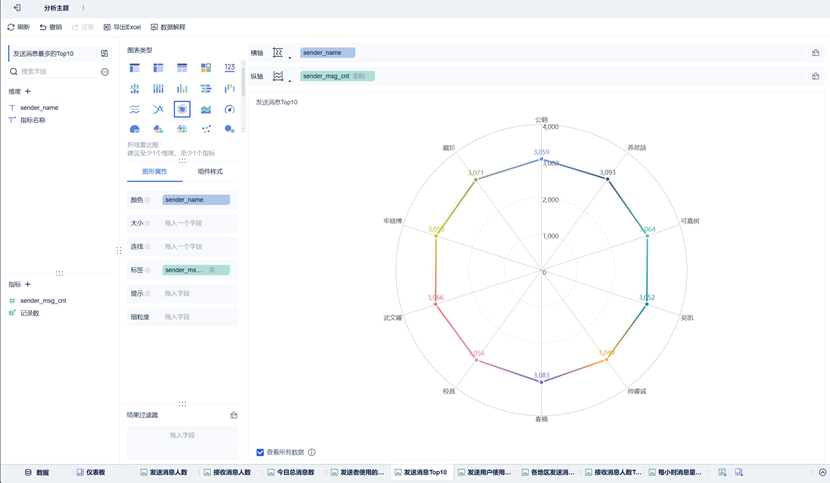
该组件使用图表类型为雷达图。可以在组件样式——图例中,将显示全部图例去除,这样图表显示更为简洁(如图)。由于他们发送消息数量差不多,我们使用sender_name作为颜色区分标准。
发送者使用操作系统组件
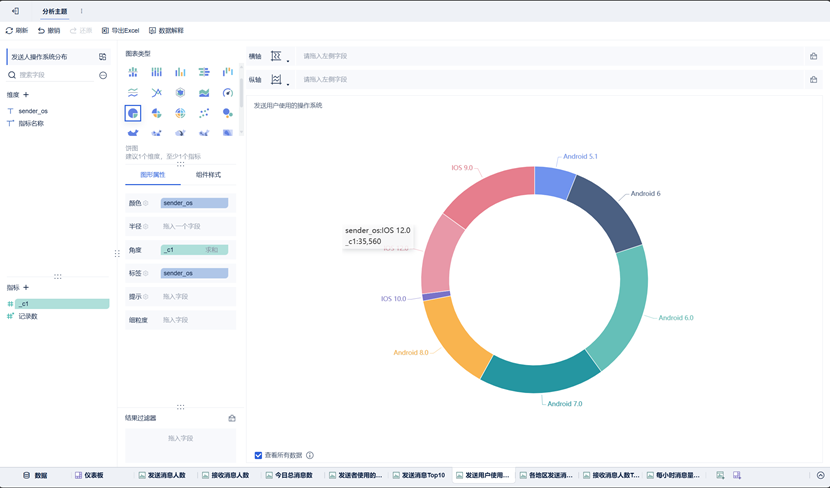
该组件图表类型为饼图。使用各OS使用数量作为角度划分,使用OS名称作为颜色划分 & 标签显示。同理,可以在组件样式——图例中,将显示全部图例去除,以实现图中效果。
各地区数据量地图显示组件
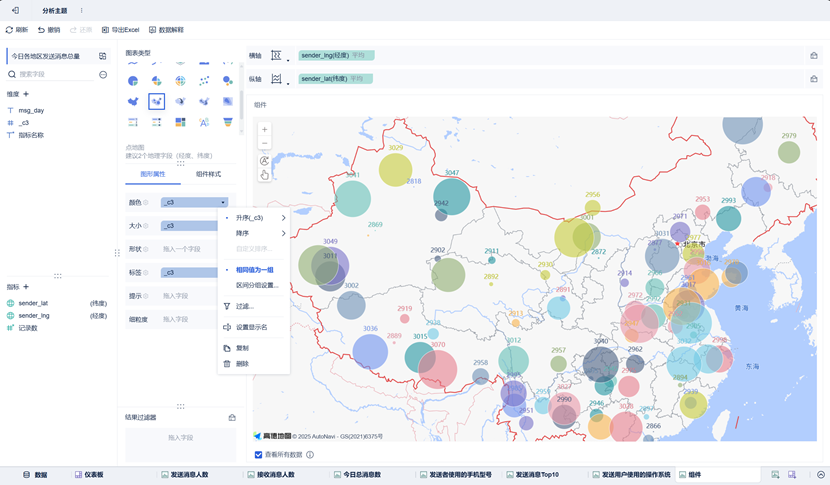
该组件使用图表类型为点地图,创建时注意事项如下:
- 收到将指标中的sender_lat & sender_lng地理角色设置为经纬度。
- 将各地区总记录数(图中为_c3)转化为指标。
- 将经纬度分别拖入横纵轴。
- 将各地区总记录数作为颜色和点地图中元素大小的依据,且将分组设置为相同值为一组。
接收消息人数Top10组件
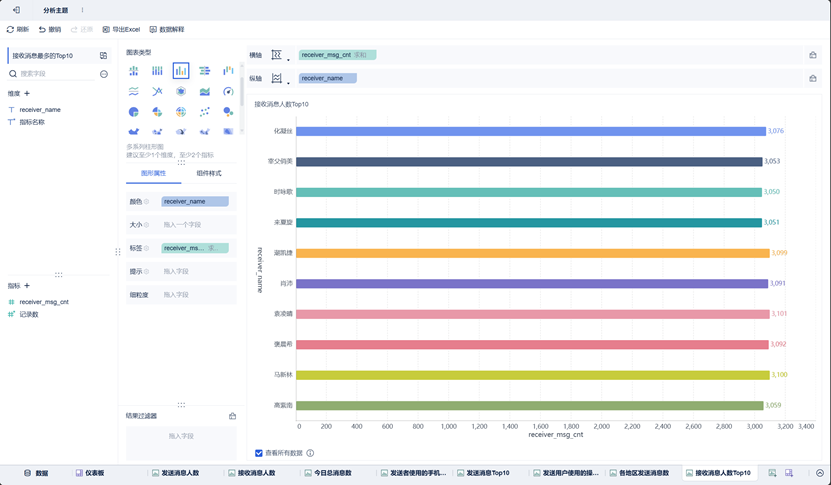
该组件使用图表类型为柱状图,在确认横纵轴后可以通过调换来实现横向柱状图。颜色区分中,由于这几位接收消息总量差别不大,因此使用其名字来区分。
发送者手机型号组件
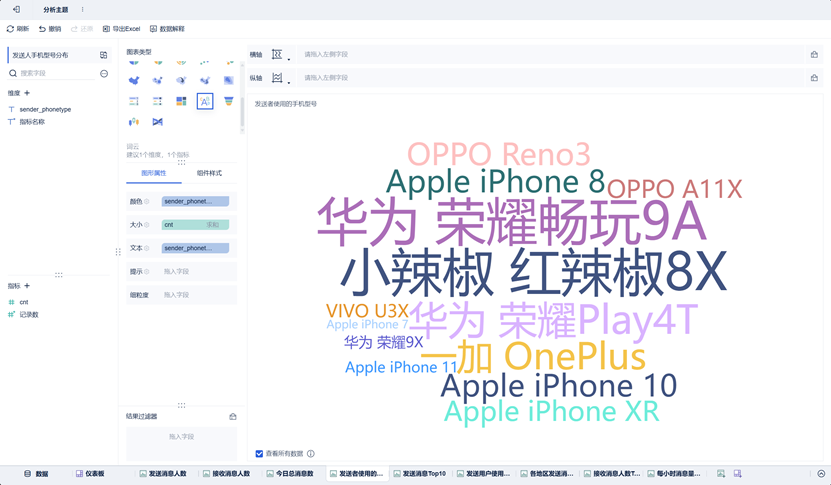
该组件使用图表类型为词云,我们使用每个型号使用者数量作为大小区分标准,将手机型号名称作为词云文本显示 & 颜色区分标准。
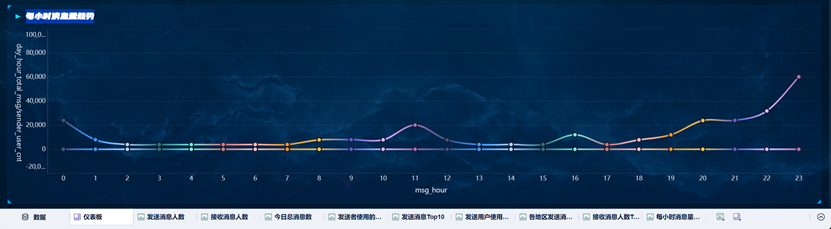
每小时消息量趋势
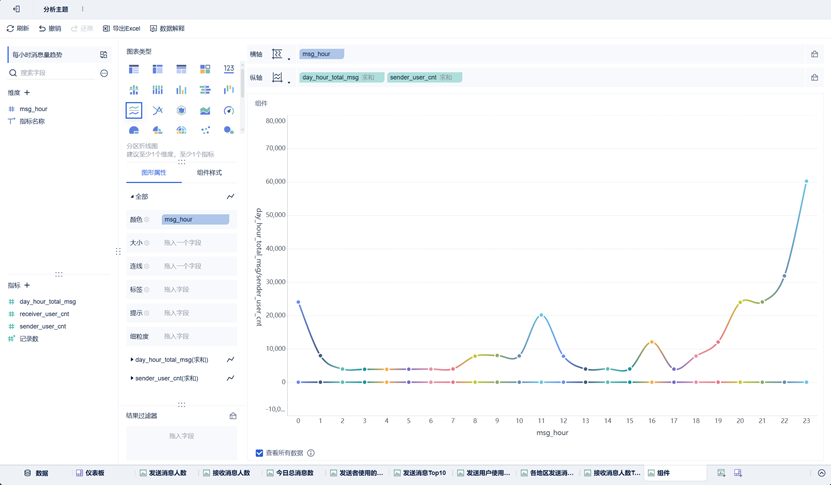
该组件使用分区折线图。在创建该组件时,需要将纵轴指标进行聚合,且颜色设置为相同值为一组。同时,由于我们在Hive创建统计数据表时,msg_hour是字符串类型,在FineBI中我们需要设置为数值类型,以便横轴自动排序。
将msg_hour设置为数值类型步骤如下:
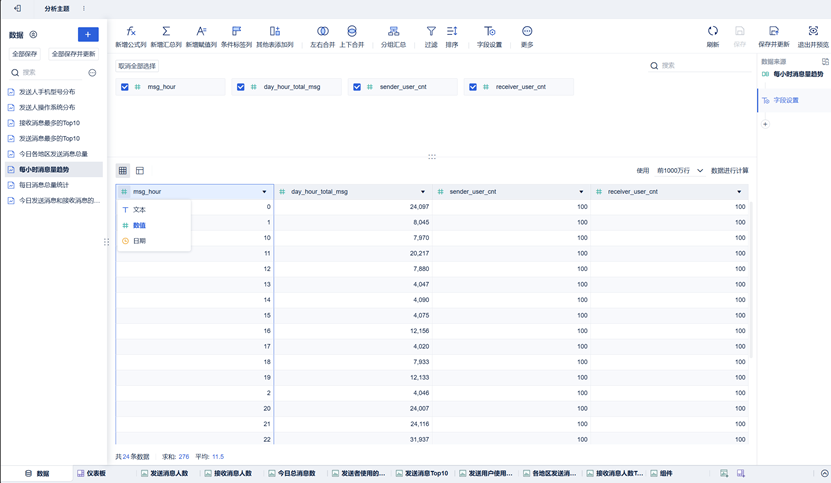
在数据出选择该表,将msg_hour字段类型更改为数值即可。
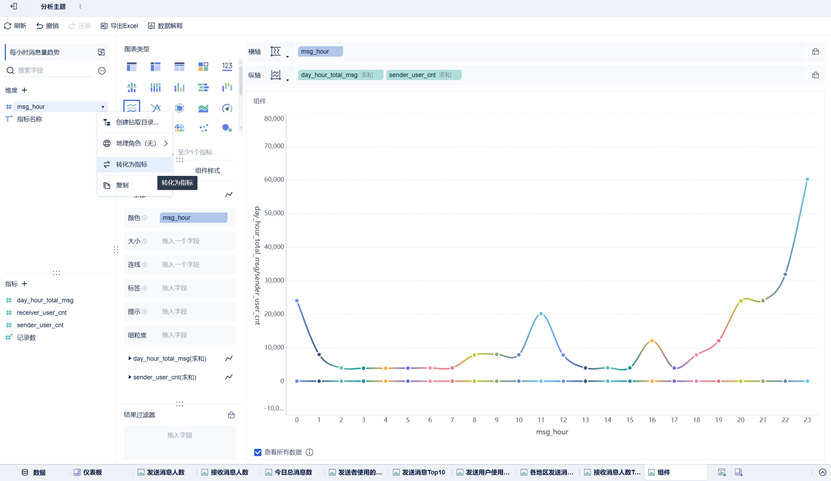
同时由于其变为数值类型,将在组件处由维度变为指标,此时我们在此处将其转为维度即可(图中为已经转化完成)。
最终报表效果

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)