数学建模之数据拟合与预测
我们使用逻辑斯蒂增长模型(Logistic Growth Model)来描述人口增长。模型的公式为:其中:x(t)是时间 t时的人口数量。xm是人口的承载能力(最大值)。r是增长率。x0 是初始人口数量(在 t0 时刻)。在代码中,我们定义了一个lambda函数来表示这个模型:本文展示了如何使用Python进行数据拟合与预测。我们通过逻辑斯蒂增长模型,结合curve_fit和差分法,对人口数据进
引言
在数据分析和科学计算中,模型的拟合与预测是非常重要的任务。本文将通过一个实际案例,介绍如何使用Python中的numpy、pandas和scipy.optimize库,结合数学模型对数据进行拟合与预测。我们将以人口增长模型为例,展示如何从数据中提取关键参数,并预测未来的值。
1. 数据准备
利用下表给出的近两个世纪的美国人口统计数据(以百万为单位),建立人口预测模型,最后用它预报2010年美国的人口。
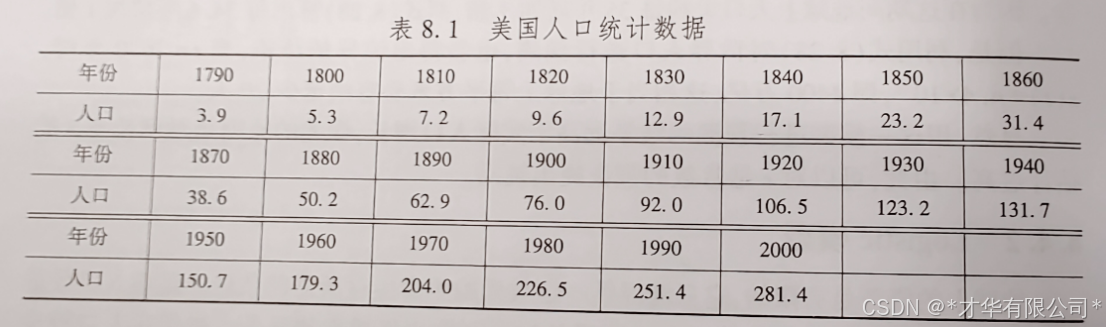
首先,我们需要加载近两年来人口数据的变化,以建立人口预测模型。读取Excel文件data8_13.xlsx的人口数据,其中包含了一些年份和对应的人口数据。
import numpy as np
import pandas as pd
from scipy.optimize import curve_fit
# 读取Excel文件
a = pd.read_excel('data\data8_13.xlsx', header=None)
b = a.values # 转换为NumPy数组
# 提取数据
xd = b[1::2, :] # 每隔一行提取数据
xd = xd[~np.isnan(xd)] # 去除NaN值
# 定义时间序列
td = np.linspace(1790, 2000, 22) # 从1790年到2000年,共22个时间点2. 定义数学模型
我们使用逻辑斯蒂增长模型(Logistic Growth Model)来描述人口增长。模型的公式为:
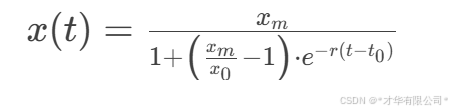
其中:
-
x(t)是时间 t时的人口数量。
-
xm是人口的承载能力(最大值)。
-
r是增长率。
-
x0 是初始人口数量(在 t0 时刻)。
在代码中,我们定义了一个lambda函数来表示这个模型:
x = lambda t, r, xm: xm / (1 + (xm / 3.9 - 1) * np.exp(-r * (t - 1790)))
3. 使用curve_fit进行参数拟合
scipy.optimize.curve_fit是一个强大的工具,用于拟合非线性模型。我们可以通过它来估计模型中的参数 r和 xm。
# 定义参数的边界
bd = [(0, 200), (0.1, 1000)]
# 使用curve_fit拟合模型
p1 = curve_fit(x, td[1:], xd[1:], bounds=bd)[0]
# 预测2010年的人口
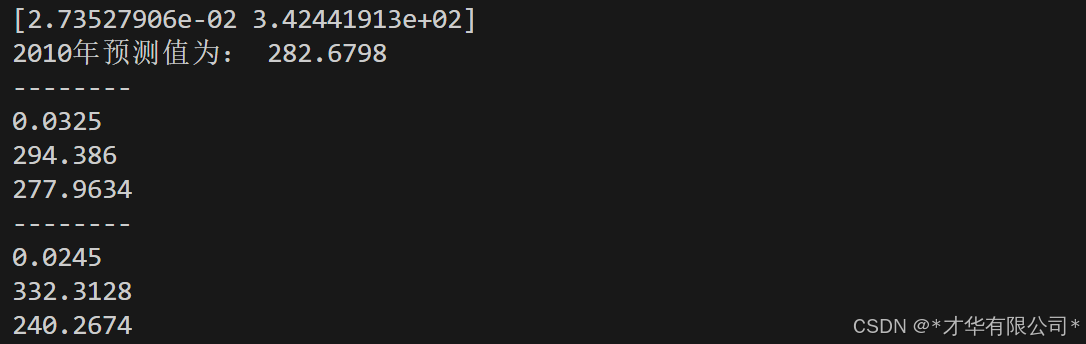
y = round(x(2010, *p1), 4)
print("2010年预测值为:", y)4. 使用差分法估计参数
除了curve_fit,我们还可以通过差分法来估计模型的参数。差分法的基本思想是利用人口增长率与人口数量的关系来推导参数。
方法1:基于前向差分
n = len(xd)
b1 = np.diff(xd) / 10 / xd[:-1] # 计算增长率
a1 = np.vstack([np.ones(n - 1), -xd[:-1]]).T # 构造矩阵
p2 = np.linalg.pinv(a1) @ b1 # 求解线性方程
r = p2[0]
xm = r / p2[1]
xh2 = x(2010, r, xm)
print('--------')
print(round(r, 4))
print(round(xm, 4))
print(round(xh2, 4))
方法2:基于后向差分
b2 = np.diff(xd) / 10 / xd[1:] # 计算增长率
a2 = np.vstack([np.ones(n - 1), -xd[:-1]]).T # 构造矩阵
p3 = np.linalg.pinv(a2) @ b2 # 求解线性方程
r = p3[0]
xm = r / p3[1]
xh3 = x(2010, r, xm)
print('--------')
print(round(r, 4))
print(round(xm, 4))
print(round(xh3, 4))完整代码如下:
import numpy as np
import pandas as pd
from scipy.optimize import curve_fit
a=pd.read_excel('data\data8_13.xlsx',header=None)
b=a.values
xd=b[1::2,:]
xd=xd[~np.isnan(xd)]
td=np.linspace(1790,2000,22)
x=lambda t,r,xm:xm/(1+(xm/3.9-1)*np.exp(-r*(t-1790)))
bd=[(0,200),(0.1,1000)]
p1=curve_fit(x,td[1:],xd[1:],bounds=bd)[0]
y=round(x(2010,*p1),4)
print(p1)
print("2010年预测值为:",y)
n=len(xd)
b1=np.diff(xd)/10/xd[:-1]
a1=np.vstack([np.ones(n-1),-xd[:-1]]).T
p2=np.linalg.pinv(a1) @ b1
r=p2[0]
xm=r/p2[1]
xh2=x(2010,r,xm)
print('--------')
print(round(r,4))
print(round(xm,4))
print(round(xh2,4))
b2=np.diff(xd)/10/xd[1:]
a2=np.vstack([np.ones(n-1),-xd[:-1]]).T
p3=np.linalg.pinv(a2)@b2
r=p3[0]
xm=r/p3[1]
xh3=x(2010,r,xm)
print('--------')
print(round(r,4))
print(round(xm,4))
print(round(xh3,4))
5. 结果分析
通过上述方法,我们得到了不同的参数估计值和预测结果。以下是一些关键结果:
-
curve_fit方法:-
参数 r和 xm的估计值。
-
2010年人口预测值。
-
-
差分法(前向差分):
-
参数 r 和 xm 的估计值。
-
2010年人口预测值。
-
-
差分法(后向差分):
-
参数 r 和 xm的估计值。
-
2010年人口预测值为282.6798百万人。
-
6. 总结
本文展示了如何使用Python进行数据拟合与预测。我们通过逻辑斯蒂增长模型,结合curve_fit和差分法,对人口数据进行了分析,并预测了未来的值。这种方法不仅适用于人口增长模型,还可以推广到其他领域的数据分析中。
扩展阅读
-
逻辑斯蒂增长模型:详细了解逻辑斯蒂增长模型的数学原理。
-
scipy.optimize.curve_fit:深入学习如何使用curve_fit进行非线性拟合。 -
差分法:探索差分法在数值分析中的应用。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)