【数学建模】评价类算法
评价类算法
层次分析法(AHP)
实例1——打分解决评价类问题

小明关心大学的四个方面及其重要性程度(权重):
- 学习氛围(0.4)
- 就业前景(0.3)
- 男女比例(0.2)
- 校园景色(0.1)
- PS:重要性程度(权重)和为1
学习氛围打分

就业前景打分

男女比例打分
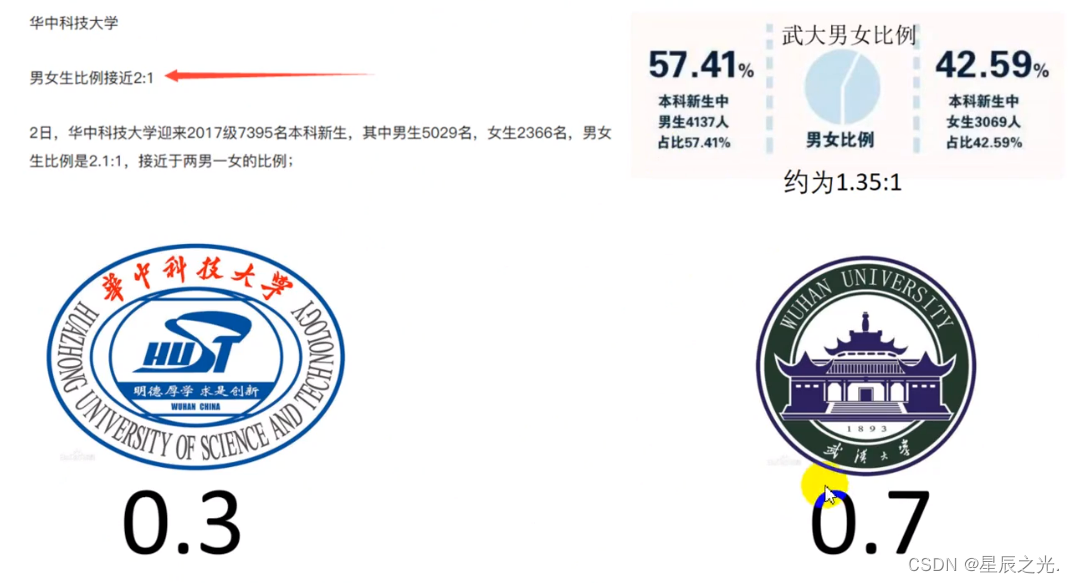
校园景色打分

整理得权重表格
| 指标权重 | 华科 | 武大 | |
|---|---|---|---|
| 学习氛围 | 0.4 | 0.7 | 0.3 |
| 就业前景 | 0.3 | 0.5 | 0.5 |
| 男女比例 | 0.2 | 0.3 | 0.7 |
| 校园景色 | 0.1 | 0.25 | 0.75 |
华科最终得分:0.515
0.7 × 0.4 + 0.5 × 0.3 + 0.3 × 0.2 + 0.25 × 0.1 0.7\times 0.4+0.5\times 0.3+0.3\times0.2+0.25\times0.1 0.7×0.4+0.5×0.3+0.3×0.2+0.25×0.1
武大最终得分:0.485
0.3 × 0.4 + 0.5 × 0.3 + 0.7 × 0.2 + 0.75 × 0.1 0.3\times 0.4+0.5\times 0.3+0.7\times0.2+0.75\times0.1 0.3×0.4+0.5×0.3+0.7×0.2+0.75×0.1
结果
华科分数大于武大,结果选择华科
总结:
打分解决评价类问题只需补充下表
| 指标权重 | 方案1 | 方案2 | ······ | |
|---|---|---|---|---|
| 指标1 | ||||
| 指标2 | ||||
| 指标3 | ||||
| ······ |
- PS:权重和为1,各指标的每一方案的和为1
解决评价类问题
填好志愿后,小明同学想出去旅游。在查阅了网上的攻略后,他初步选择了苏杭、北戴河和桂林三地之一作为目标景点。
请你确定评价指标、形成评价体系来为小明同学选择最佳的方案。
1. 想到问题
① 我们评价的目标是什么?
② 我们为了达到这个目标有哪几种可选的方案?
③ 评价的准则或者说指标是什么? (我 们根据什么东西来评价好坏)
前两个好解决,第三个问题要根据题目中的背景材料、常识以及网上搜集到的参考资料结合筛选出最合适的指标
2. 查询并确定目标和指标
优先选择知网 (cnki.net)(或者万方(wanfangdata.com.cn)、百度学术 (baidu.com)、google学术 (scqylaw.com)等平台)搜索相关文献。
找不到文献:
头脑风暴+搜索别人或者专家的看法

优选谷歌或必应搜索引擎
虫部落快搜 - 搜索快人一步 - Google (chongbuluo.com)
3. 确定指标
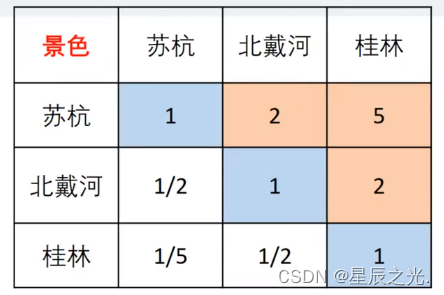
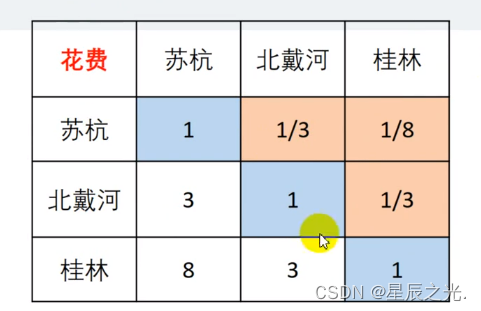
- 景点景色
- 旅游花费
- 居住环境
- 饮食情况
- 交通便利

- 分而治之策略:一次性考虑五个指标关系会考虑不周;可以两个两个指标相互比较,根据两两比较的结果来推算权重
| 标度 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 重要性 | 相同 | 稍强 | 强 | 明显强 | 绝对强 |
- PS:A和B相比是B和A相比的倒数
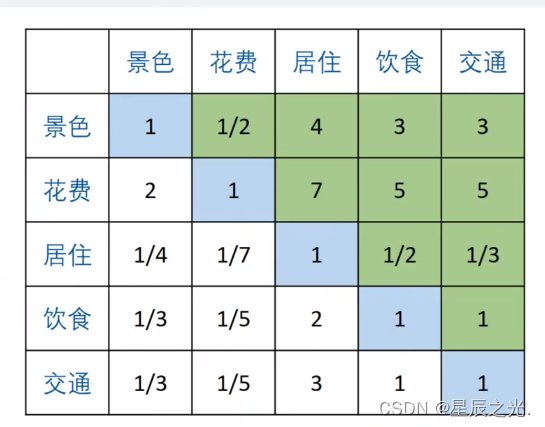
4. 列表及填表(判断矩阵)
| 景色 | 花费 | 居住 | 饮食 | 交通 | |
|---|---|---|---|---|---|
| 景色 | 1 | ||||
| 花费 | 1 | ||||
| 居住 | 1 | ||||
| 饮食 | 1 | ||||
| 交通 | 1 |
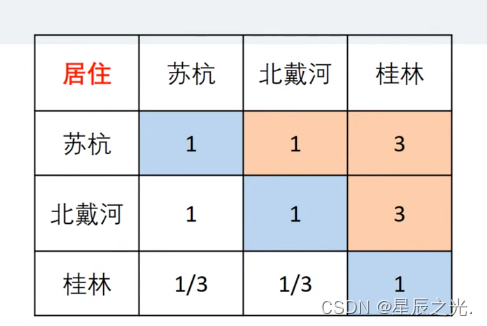
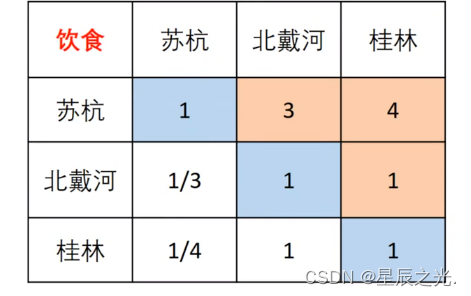
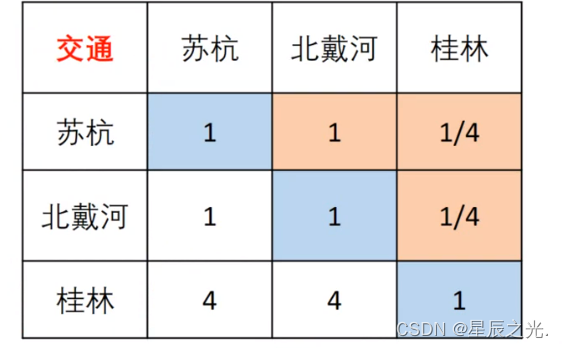
5. 一致性检验
clear all
clc
A=[1/1 1/2 4/1 3/1 3/1
2/1 1/1 7/1 5/1 5/1
1/4 1/7 1/1 1/2 1/3
1/3 1/5 2/1 1/1 1/1
1/3 1/5 3/1 1/1 1/1]; %判断矩阵
[V,D]=eig(A); %计算特征向量V和特征值D:A*V=V*D
[lambda, i]=max(diag(D)); %最大特征值lambda及其位置i
CI=(lambda-5)/(5-1); %一致性指标
CR=CI/1.12 %一致性比例=0.0161
KaTeX parse error: Unknown column alignment: * at position 23: …{\begin{array}{*̲{20}{c}} {{a_…
- 一致矩阵有一个特征值为 n n n,其余特征值均为0.
- 特征值为 n n n时,对应的特征向量刚好为KaTeX parse error: Unknown column alignment: * at position 25: …{\begin{array}{*̲{20}{c}} {\fr…
- 判断矩阵越不一致时,最大特征值与 n n n相差就越大
方法1:算术平均法求权重
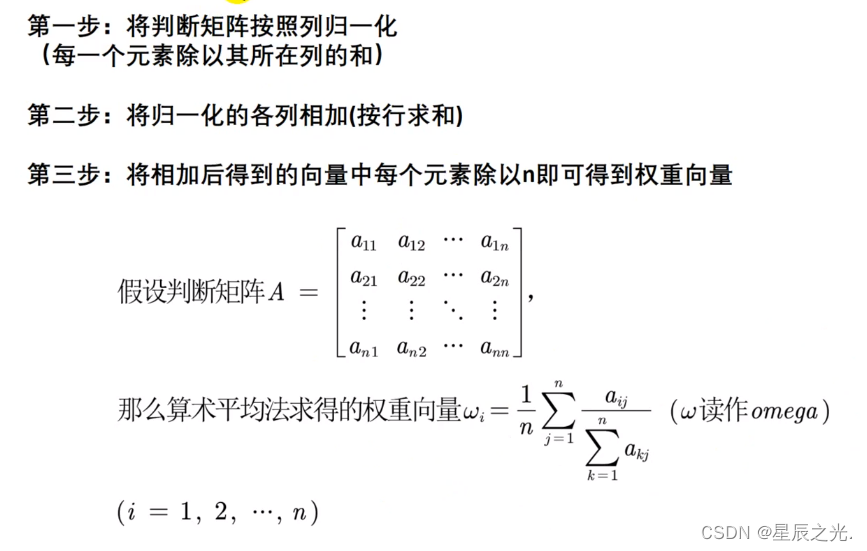
方法2:几何平均法求权重

方法3:特征值法求权重
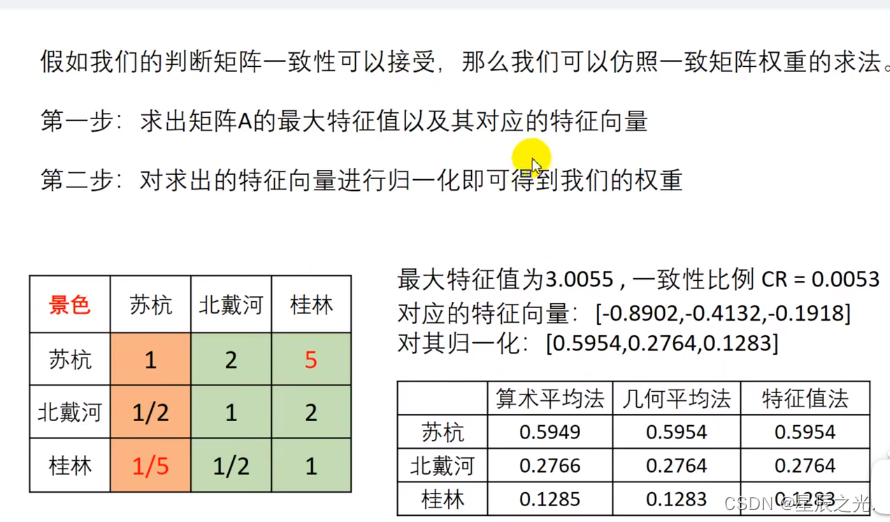
整理得
| 指标权重 | 苏杭 | 北戴河 | 桂林 | |
|---|---|---|---|---|
| 景色 | 0.2636 | 0.5954 | 0.2764 | 0.1283 |
| 花费 | 0.4758 | 0.0819 | 0.2363 | 0.6817 |
| 居住 | 0.0538 | 0.4286 | 0.4286 | 0.1429 |
| 饮食 | 0.0981 | 0.6337 | 0.1919 | 0.1744 |
| 交通 | 0.1087 | 0.1667 | 0.1667 | 0.6667 |
苏杭得分:0.299
0.5954 × 0.2636 + 0.0819 × 0.4758 + 0.4286 × 0.0538 + 0.6337 × 0.0981 + 0.1667 × 0.1087 = 0.299 0.5954\times0.2636+0.0819\times0.4758+0.4286\times0.0538+0.6337\times0.0981+0.1667\times0.1087=0.299 0.5954×0.2636+0.0819×0.4758+0.4286×0.0538+0.6337×0.0981+0.1667×0.1087=0.299
北戴河得分:0.245
桂林得分:0.455
综上解得最佳旅游景点是桂林
- 结合excel简化运算
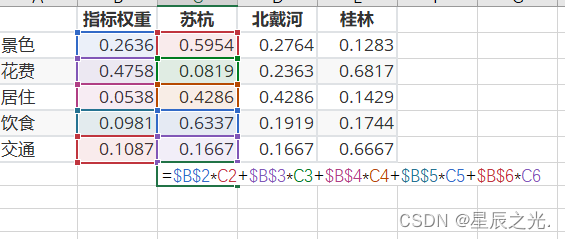
- PS:F4可锁定单元格
层次分析法步骤
- 分析系统中各因素之间的关系,建立系统的递阶层次结构
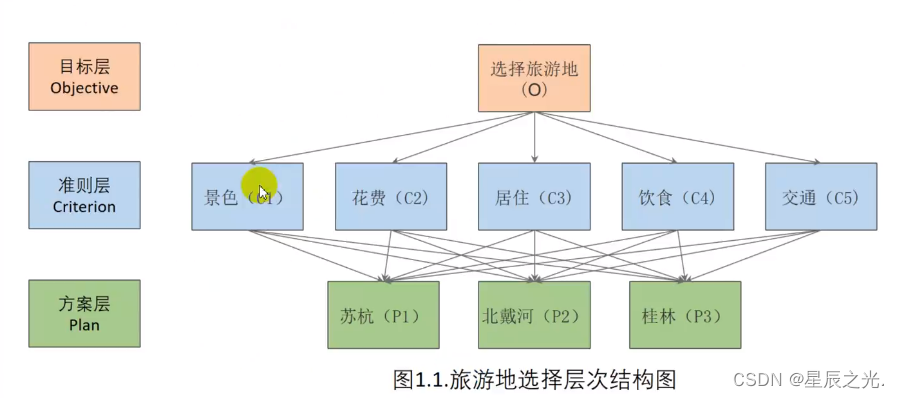
-
对于同一层次的各元素关于上一层次中某一-准则的重要性进行两两比较,构造两两比较矩阵(判断矩阵)
-
由判断矩阵计算被比较元素对于该准则的相对权重,并进行一致性检验(检验 通过权重才能用)
三种方法计算权重:
(1) 算术平均法 (2) 几何平均法 (3) 特征值法- 建议三种都用,保证结果稳健性
一致性检验步骤
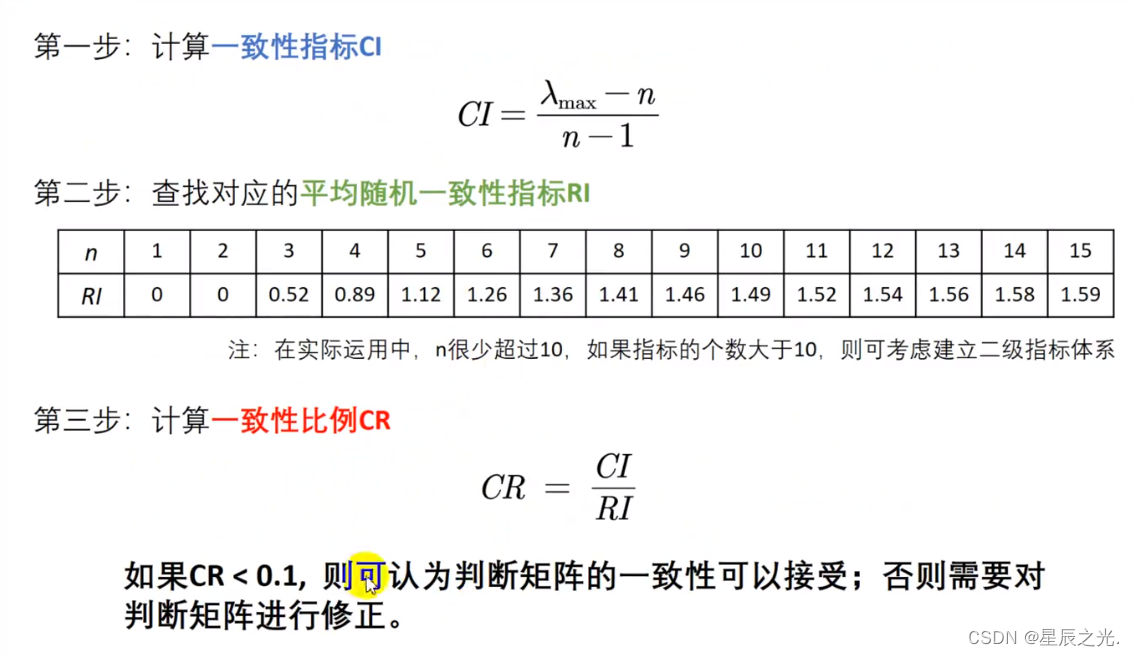
- PS: C R ≥ 0.10 CR\geq 0.10 CR≥0.10,矩阵A需要修改,往一致矩阵上调整—→一致矩阵各行成倍数关系
- 计算各层元素对系统目标的合成权重, 并进行排序。
局限性
-
评价的决策层不能太多,太多的话n会很大,判断矩阵和一致矩阵差异可能会很大。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传

- 平均随机一致性指标RI的表格中n最多是15
-
如果决策层中指标的数据是已知的,那么我们如何利用这些数据来使得评价的更加准确呢?
模糊综合评价法
模糊综合评价是一种基于模糊数学的综合评价方法,该法根据模糊数学的隶属度理论(隶属函数)把定性评价转化为定量评价。
模糊数学
模糊概念
从属于该概念到不属于该概念之间无明显分界线,外延不清楚。
带有模糊概念的词:
高、矮、胖、瘦、冷、暖、年轻人、老人… 亦此亦彼
传递精确概念的词:
男性、女性、已婚、单身…
非此即彼
模糊集合
在人们的思维中还有着许多模糊的概念,例如年轻、很大、暖和、傍晚等,这些概念所描述的对象属性不能简单地用”是”或"否”来回答,模糊集合就是指具有某个模糊概念所描述的属性的对象的全体。

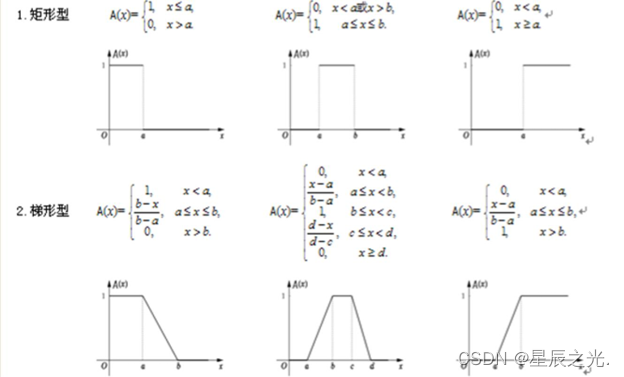
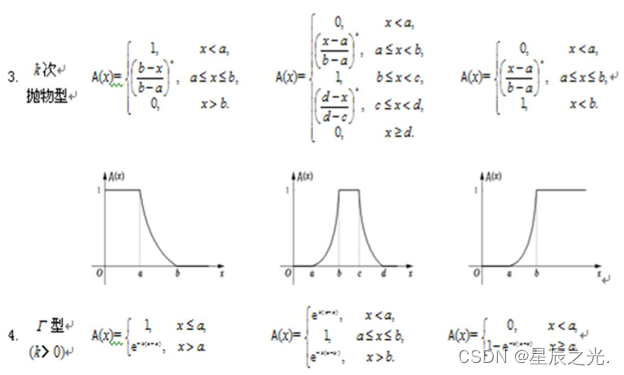
隶属函数
是用于表征模糊集合的数学工具。为了描述一个元素u对一个模糊集合的隶属关系,由于这种关系的不分明性,它将用从区间[0,1]中所取的数值代替0,1这两值来描述,表示元素属于某模糊集合的“真实程度”。
步骤概述
- 确定综合评价的因素集及权重向量
- 建立综合评价的评语集
- 获得评价矩阵
- 模糊综合判断
因素集、权重向量、评语集
- 因素集是以影响评价对象的各种因素为元素所组成的一个普通集合。
- 由于各种因素所处地位和作用的不同,考虑权重向量: A = [ a 1 , a 2 , … , a n ] A=[a_1,a_2, \ldots ,a_n] A=[a1,a2,…,an]
- 评语集是评价者对评价对象可能做出的各种结果所组成的集合。

因素集 U = { 色彩 , 做工 , 品牌 , 款式 } U=\{色彩,做工,品牌,款式\} U={色彩,做工,品牌,款式}
权重向量 A = [ 0.3 , 0.3 , 0.3 , 0.1 ] A=[0.3,0.3,0.3,0.1] A=[0.3,0.3,0.3,0.1] PS:这是小明自己认为的,主观性强,为了避免主观性可以使用熵权法
评语集 V = { 好 , 一般 , 差 } V=\{好,一般,差\} V={好,一般,差}
获得评价矩阵
评价矩阵是通过对事物的每个因素隶属于各个评语的程度进行评价(专家打分或隶属函数)得到的。
-
专家经验法确定评价矩阵:
根据专家的实际经验给出模糊信息的处理算式或相应权系数值来确定隶属函数。
-
隶属函数确定评价矩阵:
确定方法:指派法、模糊统计法、借用已有的客观尺度

模糊综合判断
模糊综合判断:
基于合适的矩阵合成方法计算总评价 B = A ∘ R B=A \circ R B=A∘R再根据不同的决策方法, 最终得到各系统的综合评价值,并给出综合评价结果。

矩阵合成
主因素决定型 M ( ∧ , ∨ ) M(\wedge,\vee) M(∧,∨)
先取小后取大
n n n
b j = ∨ ( a i ∧ r i j ) b_j=\vee(a_i\wedge r_{ij}) bj=∨(ai∧rij)
i = 1 i=1 i=1
KaTeX parse error: Unknown column alignment: * at position 24: …{\begin{array}{*̲{20}{c}} {0.3…
每列与行向量对应元素相比较,取最小值,如何从向量中取最大值。
由于综合评判的结果仅由 a i a_i ai与 r i j r_{ij} rij中的某一确定,着眼点是考虑主要因素,其他因素对结果影响不大,这种运算有时候出现决策结果不易分辨的情况。
KaTeX parse error: Unknown column alignment: * at position 60: …{\begin{array}{*̲{20}{c}} {\be…
- ( ( 0.3 ∧ 0.8 ) ∨ ( 0.3 ∧ 0.7 ) ∨ ( 0.3 ∧ 0.6 ) ∨ ( 0.1 ∧ 0.7 ) ) ((0.3 \wedge 0.8) \vee (0.3 \wedge 0.7) \vee (0.3 \wedge 0.6) \vee (0.1 \wedge 0.7)) ((0.3∧0.8)∨(0.3∧0.7)∨(0.3∧0.6)∨(0.1∧0.7)) 结果为:0.3
- ( ( 0.3 ∧ 0.1 ) ∨ ( 0.3 ∧ 0.2 ) ∨ ( 0.3 ∧ 0.2 ) ∨ ( 0.1 ∧ 0. 1 ) ) ((0.3 \wedge 0.1) \vee (0.3 \wedge 0.2) \vee (0.3 \wedge 0.2) \vee (0.1 \wedge 0.{\text{1}})) ((0.3∧0.1)∨(0.3∧0.2)∨(0.3∧0.2)∨(0.1∧0.1)) 结果为:0.2
- ( ( 0.3 ∧ 0. 1 ) ∨ ( 0.3 ∧ 0. 1 ) ∨ ( 0.3 ∧ 0.2 ) ∨ ( 0.1 ∧ 0. 2 ) ) ((0.3 \wedge 0.{\text{1}}) \vee (0.3 \wedge 0.{\text{1}}) \vee (0.3 \wedge 0.2) \vee (0.1 \wedge 0.{\text{2}})) ((0.3∧0.1)∨(0.3∧0.1)∨(0.3∧0.2)∨(0.1∧0.2)) 结果为:0.2
主因素突出型 M ( . , ∨ ) M(.,\vee) M(.,∨)
先相乘再取大
n n n
b j = ∨ ( a i ⋅ r i j ) b_j=\vee(a_i \cdot r_{ij}) bj=∨(ai⋅rij)
i = 1 i=1 i=1
KaTeX parse error: Unknown column alignment: * at position 24: …{\begin{array}{*̲{20}{c}} {0.3…
主因素在综合评价中起主导作用时,建议采用方法一,当方法一失效时再采用方法二。
加权平均型 M ( . , ⊕ ) M(.,\oplus) M(.,⊕)
先相乘后相加
b j = ∑ i = 1 n a i r i j , j = 1 , … , m {b_j} = \sum\limits_{i = 1}^n {{a_i}{r_{ij}}} ,j = 1, \ldots ,m bj=i=1∑nairij,j=1,…,m
KaTeX parse error: Unknown column alignment: * at position 24: …{\begin{array}{*̲{20}{c}} {0.3…
加权平均型 M ( ∧ , ⊕ ) M(\wedge,\oplus) M(∧,⊕)
先相乘后相加
b j = min { 1 , ∑ i = 1 n ( a i ∧ r i j ) } , j = 1 , … , m {b_j} = \min \left\{ {1,\sum\limits_{i = 1}^n {({a_i} \wedge {r_{ij}})} } \right\},j = 1, \ldots ,m bj=min{1,i=1∑n(ai∧rij)},j=1,…,m
KaTeX parse error: Unknown column alignment: * at position 24: …{\begin{array}{*̲{20}{c}} {0.3…
模型三和模型四对所有因素以权重大小均衡兼顾,适用于考虑各种因素起作用的情况。
评判
利用总评价向量B做出模糊评判
最大隶属度原则:
B = ( 0.24 , 0.06 , 0.06 ) B=(0.24,0.06,0.06) B=(0.24,0.06,0.06)
V = { ′ 好 ′ , ′ 一 般 ′ , ′ 差 ′ } V=\{'好','一般','差'\} V={′好′,′一般′,′差′}
加权平均原则:
A = ∑ i = 1 n b i v i ∑ i = 1 n b i A = \frac{{\sum\limits_{i = 1}^n {{b_i}{v_i}} }}{{\sum\limits_{i = 1}^n {{b_i}} }} A=i=1∑nbii=1∑nbivi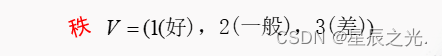
B = ( 0.24 , 0.06 , 0.06 ) B{ = }(0.24,0.06,0.06) B=(0.24,0.06,0.06) 0.24*1 + 0.06*2 + 0.06*3 0.24 + 0.06 + 0.06 = 1.5 \frac{{{\text{0}}{\text{.24*1 + 0}}{\text{.06*2 + 0}}{\text{.06*3}}}}{{{\text{0}}{\text{.24 + 0}}{\text{.06 + 0}}{\text{.06}}}}{\text{ = 1}}{\text{.5}} 0.24 + 0.06 + 0.060.24*1 + 0.06*2 + 0.06*3 = 1.5
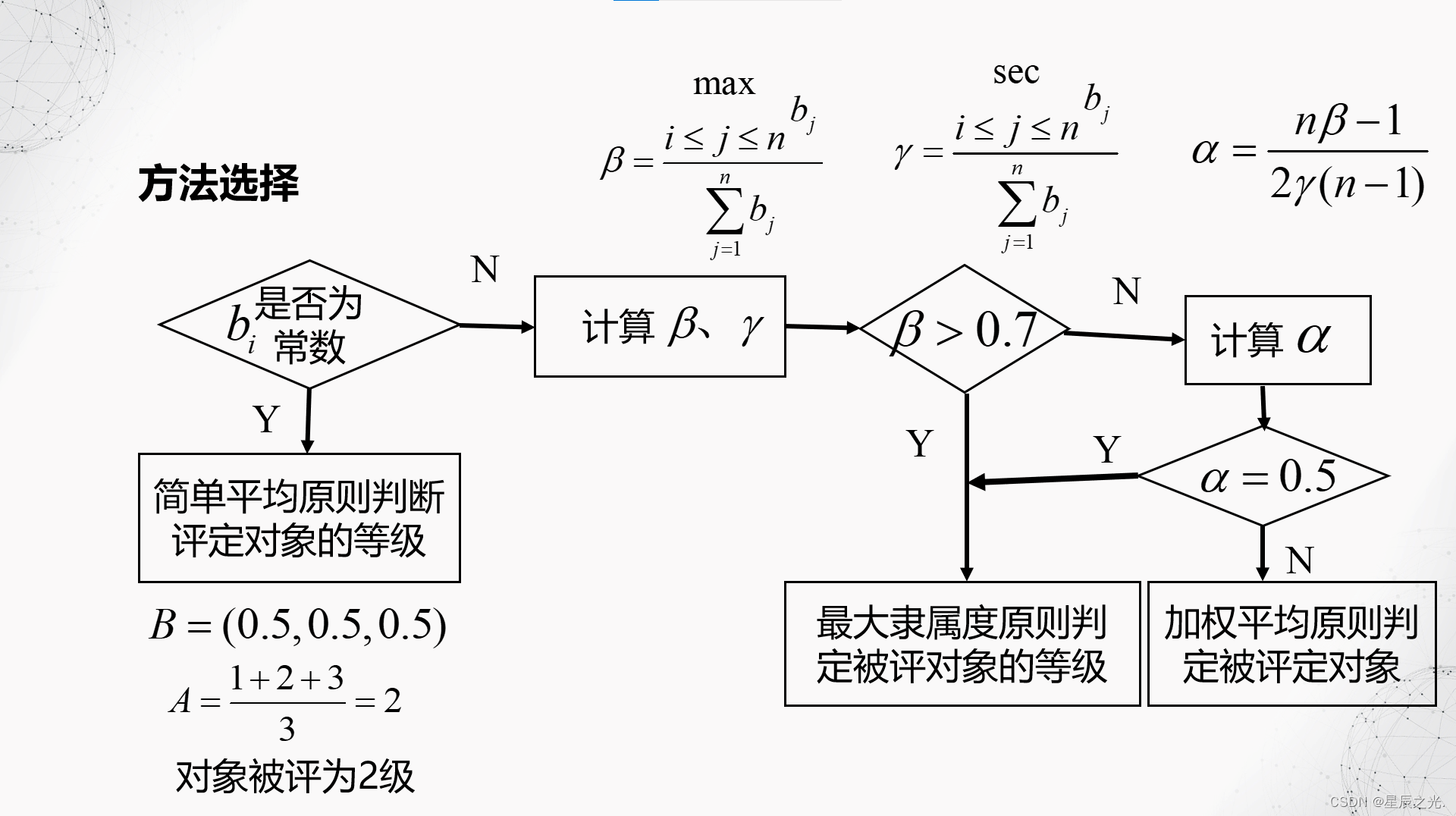
B = ( 0.8 , 0.75 , 0.03 , 0.01 , 0.01 ) B = (0.8,0.75,0.03,0.01,0.01) B=(0.8,0.75,0.03,0.01,0.01)
β = 0.8 0.8 + 0.75 + 0.03 + 0.01 + 0.01 = 0.5 γ = 0.75 1.6 = 0.46875 α = 5 β − 1 2 γ ( 5 − 1 ) = 0.4 < 0.5 → 加权平均原则判定为评价对象 \begin{gathered}\beta = \frac{{0.8}}{{0.8 + 0.75 + 0.03 + 0.01 + 0.01}} = 0.5\\\gamma = \frac{{0.75}}{{1.6}} = 0.46875~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\\\alpha = \frac{{5\beta - 1}}{{2\gamma (5 - 1)}} = 0.4 < 0.5~~~~~~~~~~~~~~~~~~~~~~~~~~~\end{gathered}\xrightarrow{{加权平均原则判定为评价对象}} β=0.8+0.75+0.03+0.01+0.010.8=0.5γ=1.60.75=0.46875 α=2γ(5−1)5β−1=0.4<0.5 加权平均原则判定为评价对象
A = 0.8 ∗ 1 + 0.75 ∗ 2 + 0.03 ∗ 3 + 0.01 ∗ 4 + 0.01 ∗ 5 1.6 = 1.55 A = \frac{{0.8*1 + 0.75*2 + 0.03*3 + 0.01*4 + 0.01*5}}{{1.6}} = 1.55 A=1.60.8∗1+0.75∗2+0.03∗3+0.01∗4+0.01∗5=1.55
一级例题
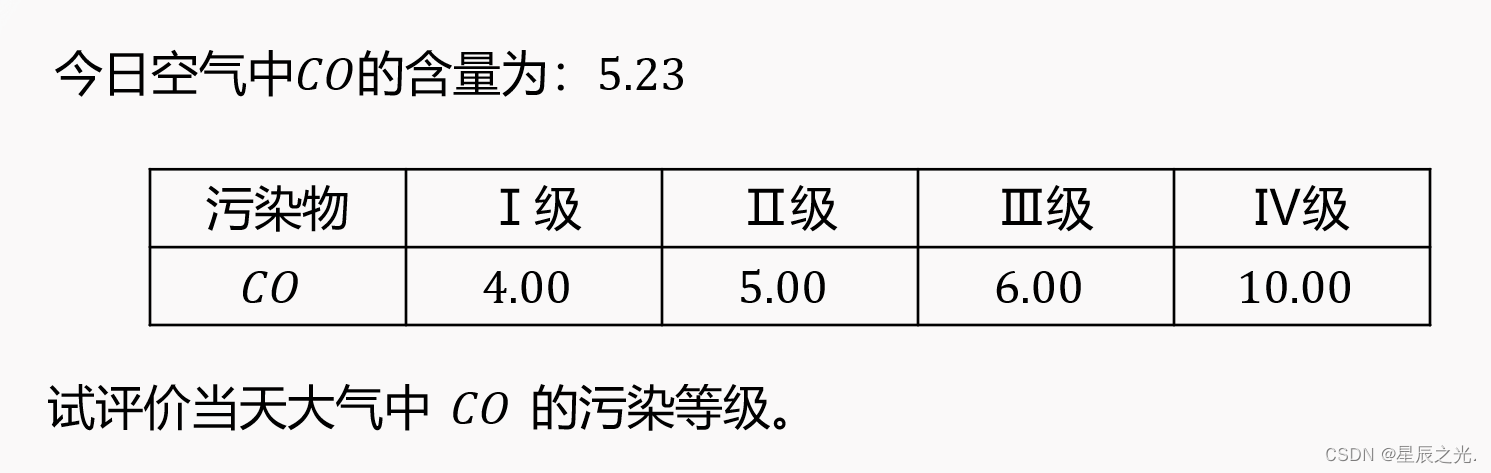
-
因素集:
$U = { CO} $ U = ( 5.23 ) U = (5.23) U=(5.23)
-
评语集
S = ( I 级 , I 级 , I 级 , I 级 ) S=(I级,I级,I级,I级) S=(I级,I级,I级,I级)
- 选择合适的隶属函数建立综合评价矩阵
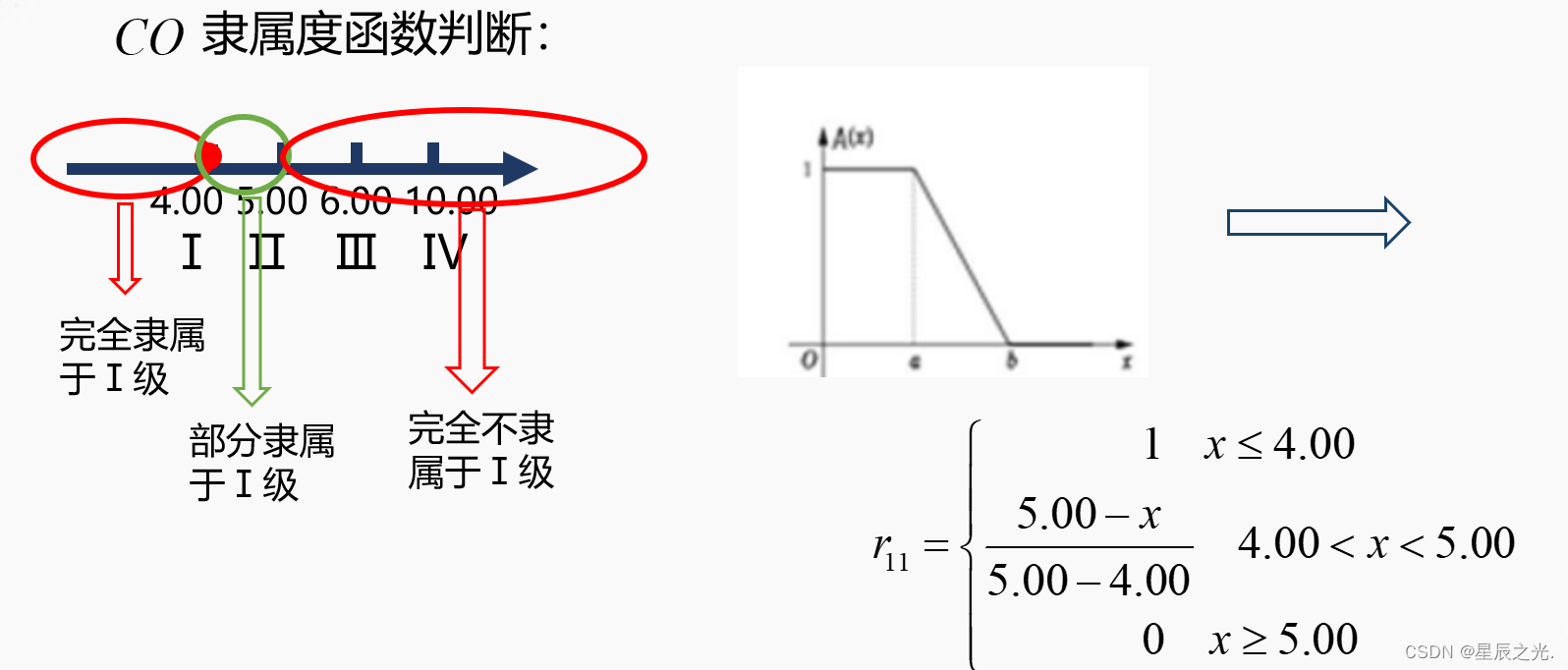
- 确定其他级别隶属函数

-
例: C O CO CO浓度:5.23
→ 代入II级、III级的隶属函数 \xrightarrow{{{\text{代入II级、III级的隶属函数}}}} 代入II级、III级的隶属函数 r = ( 0 , 0.77 , 0.23 , 0 ) r=(0,0.77,0.23,0) r=(0,0.77,0.23,0)隶属于各评语集的矩阵
- 得综合评判矩阵:

优缺点
优点:
- 模糊评价通过精确的数字手段处理模糊的评价对象,能对蕴藏信息呈现模糊性的资料作出比较科学、合理、贴近实际的量化评价;
- 评价结果是一个向量,而不是一个点值,包含的信息比较丰富,既可以比较准确的刻画被评价对象,又可以进一步加工,得到参考信息。
缺点:
- 计算复杂,对指标权重向量的确定主观性较强;(可用熵权法或者主成分分析法)
- 当因素集U较大,即因素集个数较大时,在权向量和为1的条件约束下,相对隶属度权重系数往往偏小,权重向量与模糊矩阵R不匹配,结果会出现分辨率很差,无法区分谁的隶属度更高,甚至造成评判失败,此时可用分层模糊评估法加以改进。
TOPSIS 法(优劣解距离法)
实例1
小明同宿舍共有四名同学,他们第-学期的高数成绩如下表所示:
| 姓名 | 成绩 |
|---|---|
| 小明 | 89 |
| 小王 | 60 |
| 小张 | 74 |
| 小华 | 99 |
请你为这四名同学进行评分,该评分能合理的描述其高数成绩的高低。
| 姓名 | 成绩 | 排名 | 修正后的排名 | 评分 |
|---|---|---|---|---|
| 小明 | 89 | 2 | 3 | 3 / 10 = 0.3 3/10=0.3 3/10=0.3 |
| 小王 | 60 | 4 | 1 | 1 / 10 = 0.1 1/10=0.1 1/10=0.1 |
| 小张 | 74 | 3 | 2 | 2 / 10 = 0.2 2/10=0.2 2/10=0.2 |
| 小华 | 99 | 1 | 4 | 4 / 10 = 0.4 4/10=0.4 4/10=0.4 |
- PS:但是会出现随便修改成绩,只要排名不变,评分就不会改变!(相关性不强)
| 姓名 | 成绩 | 排名 | 修正后的排名 | 评分 |
|---|---|---|---|---|
| 小明 | 89 | 2 | 3 | 3 / 10 = 0.3 3/10=0.3 3/10=0.3 |
| 小王 | 4 | 1 | 1 / 10 = 0.1 1/10=0.1 1/10=0.1 | |
| 小张 | 74 | 3 | 2 | 2 / 10 = 0.2 2/10=0.2 2/10=0.2 |
| 小华 | 1 | 4 | 4 / 10 = 0.4 4/10=0.4 4/10=0.4 |
比较好的想法
最高成绩 m a x max max:99 最低成绩 m i n min min:60 构造计算评分的公式: x − m i n m a x − m i n \frac{{x - min }}{{max - min }} max−minx−min
| 姓名 | 成绩 | 未归一化的评分 | 归一化评分 |
|---|---|---|---|
| 小明 | 89 | ( 89 − 60 ) / ( 99 − 60 ) = 0.74 (89-60)/(99-60)=0.74 (89−60)/(99−60)=0.74 | 0.74 / 2.1 = 0.35 0.74/2.1=0.35 0.74/2.1=0.35 |
| 小王 | 60 | ( 60 − 60 ) / ( 99 − 60 ) = 0 (60-60)/(99-60)=0 (60−60)/(99−60)=0 | 0 / 2.1 = 0 0/2.1=0 0/2.1=0 |
| 小张 | 74 | ( 74 − 60 ) / ( 99 − 60 ) = 0.36 (74-60)/(99-60)=0.36 (74−60)/(99−60)=0.36 | 0.36 / 2.1 = 0.17 0.36/2.1=0.17 0.36/2.1=0.17 |
| 小华 | 99 | ( 99 − 60 ) / ( 99 − 60 ) = 1 (99-60)/(99-60)=1 (99−60)/(99−60)=1 | 1 / 2.1 = 0.48 1/2.1=0.48 1/2.1=0.48 |
卷面最高成绩 m a x max max:100 卷面最低成绩 m i n min min:0 构造计算评分的公式: x − 0 100 − 0 \frac{{x - 0 }}{{100 - 0 }} 100−0x−0(舍弃不用)
原因

构造计算评分的公式: x − m i n m a x − m i n 构造计算评分的公式:\frac{{x - min }}{{max - min }} 构造计算评分的公式:max−minx−min
拓展问题:增加指标个数
新增加了一个指标,现在要综合评价四位同学,并为他们进行评分。
| 姓名 | 成绩 | 与别人争吵次数 |
|---|---|---|
| 小明 | 89 | 2 |
| 小王 | 60 | 0 |
| 小张 | 74 | 1 |
| 小华 | 99 | 3 |
成绩是越高(大)越好,这样的指标称为极大型指标(效益型指标)。
与他人争吵的次数越少(越小)越好,这样的指标称为极小型指标(成本型指标)。
统一指标类型
将所有的指标转化为极大型称为指标正向化(最常用)
| 姓名 | 成绩 | 与别人争吵次数 | 正向化后的争吵次数 |
|---|---|---|---|
| 小明 | 89 | 2 | 1 |
| 小王 | 60 | 0 | 3 |
| 小张 | 74 | 1 | 2 |
| 小华 | 99 | 3 | 0 |
| 指标类型 | 极大型 | 极小型 | 极大型 |
极小型指标转换为极大型指标的公式 : m a x − x 极小型指标转换为极大型指标的公式:max- x 极小型指标转换为极大型指标的公式:max−x
标准化处理
为了消去不同指标量纲的影响,需要对已经正向化的矩阵进行标准化处理。
标准化处理的计算公式

X = [89,1;60,3;74,2;99,0]
[n,m]=size(X)
X./repmat(sum(X.*X).^0.5,n,1)
计算得分
| 姓名 | 成绩 | 正向化后的争吵次数 |
|---|---|---|
| 小明 | 0.5437 | 0.2673 |
| 小王 | 0.3665 | 0.8018 |
| 小张 | 0.4520 | 0.5345 |
| 小华 | 0.6048 | 0 |
| 指标类型 | 极大型 | 极大型 |
只有一个指标时候: 构造计算评分的公式: x − m i n m a x − m i n 变形 = x − m i n m a x − m i n = x − m i n ( m a x − x ) + ( x − m i n ) 可看做 : x 与最小值的距离 x 与最大值的距离 + x 与最小值的距离 只有一个指标时候:\\ 构造计算评分的公式:\frac{{x - min }}{{max - min }}\\ 变形=\frac{{x - min }}{{max - min }}=\frac{{x - min }}{{(max-x) + (x-min) }}\\ 可看做:\frac{{x与最小值的距离 }}{{x与最大值的距离+x与最小值的距离}} 只有一个指标时候:构造计算评分的公式:max−minx−min变形=max−minx−min=(max−x)+(x−min)x−min可看做:x与最大值的距离+x与最小值的距离x与最小值的距离

Z = [ 0.5437 0.2673 0.3665 0.8018 0.4520 0.5345 0.6048 0 ] Z=\begin{bmatrix} {0.5437}&{0.2673} \\ {0.3665}&{0.8018} \\ {0.4520}&{0.5345} \\ {0.6048}&0 \end{bmatrix} Z=⎣ ⎡0.54370.36650.45200.60480.26730.80180.53450⎦ ⎤最小值: [ 0.3665 , 0 ] [0.3665,0] [0.3665,0] 未归一化的得分: S i = D i − D i + + D i − {S_i} = \frac{{D_i^ - }}{{D_i^ + + D_i^ - }} Si=Di++Di−Di−

X = [89,1;60,3;74,2;99,0]
[n,m]=size(X);
Z=X./repmat(sum(X.*X).^0.5,n,1);
D_P=sum([(Z-repmat(max(Z),n,1)).^2]).^0.5 %D+向量
D_N=sum([(Z-repmat(min(Z),n,1)).^2]).^0.5 %D-向量
| 姓名 | D + D^+ D+ | D − D^- D− | 未归一化的得分 | 归一化后的得分 | 排名 |
|---|---|---|---|---|---|
| 小明 | 0.5380 | 0.3206 | 0.3734 | 0.1857 | 3 |
| 小王 | 0.2382 | 0.8018 | 0.7709 | 0.3534 | 1 |
| 小张 | 0.3078 | 0.5413 | 0.6375 | 0.3170 | 2 |
| 小华 | 0.8018 | 0.2382 | 0.2291 | 0.1139 | 4 |
步骤
1. 将原始矩阵正向化
最常见的四种指标
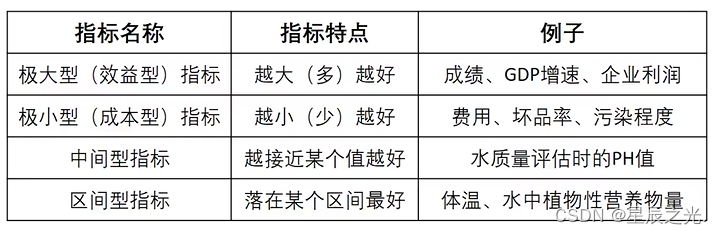
将原式矩阵正向化,就是要将所有的指标类型统一转化为极大型指标。(PS:转换的函数形式可以不唯一)
极小型指标 → \to →极大型指标
极小型指标转换为极大型指标的公式 : m a x − x 如果所有的元素均为正数,那么也可以使用 1 x 极小型指标转换为极大型指标的公式:\\ max-x\\ 如果所有的元素均为正数,那么也可以使用\frac{1}{x} 极小型指标转换为极大型指标的公式:max−x如果所有的元素均为正数,那么也可以使用x1
中间型指标 → \to →极大型指标
中间型指标:指标值既不要太大也不要太小,取某特定值最好(如水质量评估PH值)
{ x i } 是一组中间型指标序列,且最佳的数值为 x b e s t , 那么正向化的公式如下 : M = max { ∣ x i − x b e s t ∣ } , x ~ i = 1 − ∣ x i − x b e s t ∣ M \{x_i\}是一组中间型指标序列,且最佳的数值为x_{best},那么正向化的公式如下:\\ M=\max\{|x_i-x_{best}|\},{\tilde x_i}=1-\frac{{{{|x_i - x_{best} |}}}}{M} {xi}是一组中间型指标序列,且最佳的数值为xbest,那么正向化的公式如下:M=max{∣xi−xbest∣},x~i=1−M∣xi−xbest∣
| PH值(转换前) | PH值(转化后) |
|---|---|
| 6 | $1 - \frac{{\left |
| 7 | $1 - \frac{{\left |
| 8 | $1 - \frac{{\left |
| 9 | $1 - \frac{{\left |
x b e s t = 7 x_{best}=7 xbest=7 M = max { ∣ 6 − 7 ∣ , ∣ 7 − 7 ∣ , ∣ 8 − 7 ∣ , ∣ 9 − 7 ∣ } M=\max\{|6-7|,|7-7|,|8-7|,|9-7|\} M=max{∣6−7∣,∣7−7∣,∣8−7∣,∣9−7∣}
区间型指标 → \to →极大型指标
区间型指标:指标值落在某个区间内最好,例如人的体温在36℃ ~ 37℃这个区间比较好。
{ x i } 是一组中间型指标序列,且最佳的区间为 [ a , b ] , 那么正向化的公式如下 : M = max { a − max { x i } , max { x i } − b } , x ~ i = { 1 − a − x M , x < a 1 , a ≤ x ≤ b 1 − x − b M , x > b \{x_i\}是一组中间型指标序列,且最佳的区间为[a,b],那么正向化的公式如下:\\ M=\max\{a-\max\{x_i\},\max\{x_i\}-b\},{\tilde x_i}=\left\{ \begin{matrix} 1-\frac{{{{a - x}}}}{M},x<a\\ 1,a \leq x \leq b\\ 1-\frac{{{{x - b}}}}{M},x>b \end{matrix} \right. {xi}是一组中间型指标序列,且最佳的区间为[a,b],那么正向化的公式如下:M=max{a−max{xi},max{xi}−b},x~i=⎩
⎨
⎧1−Ma−x,x<a1,a≤x≤b1−Mx−b,x>b
| 体温(转换前) | 体温(转化后) |
|---|---|
| 35.2 | 0.4286 |
| 35.8 | 0.8571 |
| 36.6 | 1 |
| 37.1 | 0.9286 |
| 37.8 | 0.4286 |
| 38.4 | 0 |
a = 36 , b = 37 a=36,b=37 a=36,b=37 M = max { 36 − 35.2 , 38.4 − 37 } = 1.4 M=\max\{36-35.2,38.4-37\}=1.4 M=max{36−35.2,38.4−37}=1.4
2. 正向化矩阵标准化

3. 计算得分并归一化

带权重的TOPSIS

- PS:计算时注意权重问题


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)