【学习笔记】统计学习方法——条件随机场
摘要: 条件随机场(Conditional Random Field,CRF)是自然语言处理的基础模型,广泛应用于中文分词、命名实体识别、词性标注等标注场景。下面通过一个小问题来引入: 假设你有许多小明同学一天内不同时段的照片,从小明提裤子起床到脱裤子睡觉各个时间段都有(小明是照片控!)。现在的任务是对这些照片进行分类。比如有的照片是吃饭,那就给它打上吃饭的标签;有的照片是跑步时拍的,那就打上
摘要:
条件随机场(Conditional Random Field,CRF)是自然语言处理的基础模型,广泛应用于中文分词、命名实体识别、词性标注等标注场景。
下面通过一个小问题来引入:
假设你有许多小明同学一天内不同时段的照片,从小明提裤子起床到脱裤子睡觉各个时间段都有(小明是照片控!)。现在的任务是对这些照片进行分类。比如有的照片是吃饭,那就给它打上吃饭的标签;有的照片是跑步时拍的,那就打上跑步的标签;有的照片是开会时拍的,那就打上开会的标签。问题来了,你准备怎么干?一个简单直观的办法就是,不管这些照片之间的时间顺序,想办法训练出一个多元分类器。就是用一些打好标签的照片作为训练数据,训练出一个模型,直接根据照片的特征来分类。例如,如果照片是早上6:00拍的,且画面是黑暗的,那就给它打上睡觉的标签;如果照片上有车,那就给它打上开车的标签。
这样可行吗?
乍一看可以!但实际上,由于我们忽略了这些照片之间的时间顺序这一重要信息,我们的分类器会有缺陷的。举个例子,假如有一张小明闭着嘴的照片,怎么分类?显然难以直接判断,需要参考闭嘴之前的照片,如果之前的照片显示小明在吃饭,那这个闭嘴的照片很可能是小明在咀嚼食物准备下咽,可以给它打上吃饭的标签;如果之前的照片显示小明在唱歌,那这个闭嘴的照片很可能是小明唱歌瞬间的抓拍,可以给它打上唱歌的标签。所以,为了让我们的分类器能够有更好的表现,在为一张照片分类时,我们必须将与它相邻的照片的标签信息考虑进来。
这——就是条件随机场(CRF)大显身手的地方!
概念理解
成对马尔可夫性
设无向图G中的任意两个没有边连接的节点u,v ,其他所有节点为O,成对马尔可夫性指:给定 Y O Y_O YO的条件下, Y u Y_u Yu和 Y v Y_v Yv条件独立

P ( Y u , Y v ∣ Y O ) = P ( Y u ∣ Y O ) P ( Y v ∣ Y O ) P\left(Y_{u}, Y_{v} \mid Y_{O}\right)=P\left(Y_{u} \mid Y_{O}\right) P\left(Y_{v} \mid Y_{O}\right) P(Yu,Yv∣YO)=P(Yu∣YO)P(Yv∣YO)
局部马尔可夫性
设无向图G的任一节点v,W是与v有边相连的所有节点,O是v、W外的其他所有节点,局部马尔可夫性指:给定 Y W Y_W YW的条件下, Y v Y_v Yv和 Y O Y_O YO条件独立

P ( Y v , Y O ∣ Y W ) = P ( Y v ∣ Y W ) P ( Y O ∣ Y W ) P\left(Y_{v}, Y_{O} \mid Y_{W}\right)=P\left(Y_{v} \mid Y_{W}\right) P\left(Y_{O} \mid Y_{W}\right) P(Yv,YO∣YW)=P(Yv∣YW)P(YO∣YW)
在 P ( Y O / Y W ) > 0 P\left(Y_{O} / Y_{W}\right)>0 P(YO/YW)>0 时, 等价地,
P ( Y v ∣ Y W ) = P ( Y v ∣ Y W , Y O ) P\left(Y_{v} \mid Y_{W}\right)=P\left(Y_{v} \mid Y_{W}, Y_{O}\right) P(Yv∣YW)=P(Yv∣YW,YO)
全局马尔可夫性
设节点集合 A , B A, B A,B 是在无向图 G G G 中被节点集合C分开的任意节点集合, 全局马尔可夫性指:给定 Y C Y_{C} YC 的条件下, Y A Y_{A} YA 和 Y B Y_{B} YB 条件独立

P ( Y A , Y B ∣ Y C ) = P ( Y A ∣ Y C ) P ( Y B ∣ Y C ) P\left(Y_{A}, Y_{B} \mid Y_{C}\right)=P\left(Y_{A} \mid Y_{C}\right) P\left(Y_{B} \mid Y_{C}\right) P(YA,YB∣YC)=P(YA∣YC)P(YB∣YC)
团和最大团
无向图G中任何两个结点均有边连接的结点子集称为团。若C是无向图G的一个团,并且不能再加进任何一个G的结点使其成为更大的一个团,则称此C为最大团。

CRF
条件随机场
设X和Y是随机变量, P ( Y ∣ X ) P(Y \mid X) P(Y∣X) 是在给定 X X X 的条件下Y的条件概率分布。若随机变量 Y Y Y 构成一个有无向图 G = ( V , E ) G=(V, E) G=(V,E) 表示的马尔可夫场, 即
P ( Y v ∣ X , Y w , w ≠ v ) = P ( Y v ∣ X , Y w , w ∼ v ) P\left(Y_{v} \mid X, Y_{w}, w \neq v\right)=P\left(Y_{v} \mid X, Y_{w}, w \sim v\right) P(Yv∣X,Yw,w=v)=P(Yv∣X,Yw,w∼v)
对任意节点v都成立,则称 P ( Y ∣ X ) P(Y \mid X) P(Y∣X) 是条件随机场。式中 w ≠ v w \neq v w=v 表示 w w w 是除v以外的所有节点, w ∼ v w \sim v w∼v 表示 w w w 是与 v v v 相连接的所有节点。

线性链随机场
对于线性链条件随机场来说,图G的每条边都存在于状态序列Y的相邻两个节点, 最大团 C C C 是相邻两个节点的集合, X和Y有相同的图 结构意味着每个 X i X_{i} Xi 都与 Y i ⟶ Y_{i} \longrightarrow Yi⟶ 对应 0 _{0} 0
设 X = ( X 1 , … , X n ) , Y = ( Y 1 , … , Y n ) X=\left(X_{1}, \ldots, X_{n}\right), Y=\left(Y_{1}, \ldots, Y_{n}\right) X=(X1,…,Xn),Y=(Y1,…,Yn) 均为线性链表示的随机变量序列, 若在给定随机变量序列 X X X 的条件下, 随机变量序列 Y Y Y 的 条件分布 P ( Y ∣ X ) P(Y \mid X) P(Y∣X) 构成条件随机场,即满足马尔可夫性
P ( Y i ∣ X , Y 1 , ⋯ , Y i − 1 , Y i + 1 , ⋯ , Y n ) = P ( Y i ∣ X , Y i − 1 , Y i + 1 ) , i = 1 , ⋯ , n 其 中 当 i 取 1 或 n 时 只 考 虑 单 边 P\left(Y_{i} \mid X, Y_{1}, \cdots, Y_{i-1}, Y_{i+1}, \cdots, Y_{n}\right)=P\left(Y_{i} \mid X, Y_{i-1}, Y_{i+1}\right),\\ i=1,\cdots,n~~~~其中当i取1或n时只考虑单边 P(Yi∣X,Y1,⋯,Yi−1,Yi+1,⋯,Yn)=P(Yi∣X,Yi−1,Yi+1),i=1,⋯,n 其中当i取1或n时只考虑单边
则称 P ( Y ∣ X ) P(Y \mid X) P(Y∣X) 为线性链条件随机场。在标注问题中 X X X 表示输入观测序列, Y Y Y 表示对应的状态序列。
参数化形式
设 P ( Y ∣ X ) P(Y \mid X) P(Y∣X) 为线性链条件随机场,则在随机变量X取值为x的条件下,随机变量Y取值为y的条件概率具有如下形式:
P ( y ∣ x ) = 1 Z ( x ) exp [ ∑ i , k λ k t k ( y i − 1 , y i , x , i ) + ∑ i , l μ l s l ( y i , x , i ) ] P(y \mid x)=\frac{1}{Z(x)} \exp \left[\sum_{i, k} \lambda_{k} t_{k}\left(y_{i-1}, y_{i}, x, i\right)+\sum_{i, l} \mu_{l} s_{l}\left(y_{i}, x, i\right)\right] P(y∣x)=Z(x)1exp⎣⎡i,k∑λktk(yi−1,yi,x,i)+i,l∑μlsl(yi,x,i)⎦⎤
其中 s l ( y i , x , i ) , l = 1 , 2 , ⋯ , L 。 s_l \left(y_i,x,i\right),l=1,2,\cdots,L。 sl(yi,x,i),l=1,2,⋯,L。 L 是 定 义 在 该 节 点 的 节 点 特 征 函 数 的 总 个 数 , i 是 当 前 节 点 在 序 列 的 位 置 。 L是定义在该节点的节点特征函数的总个数,i是当前节点在序列的位置。 L是定义在该节点的节点特征函数的总个数,i是当前节点在序列的位置。
t k ( y i − 1 , y i , x , i ) , k = 1 , 2 , ⋯ , K 。 t_k(y_{i-1},y_i,x,i),k=1,2,\cdots,K。 tk(yi−1,yi,x,i),k=1,2,⋯,K。 K 是 定 义 在 该 节 点 的 局 部 特 征 函 数 的 总 个 数 , i 是 是 当 前 节 点 在 序 列 的 位 置 。 K是定义在该节点的局部特征函数的总个数,i是是当前节点在序列的位置。 K是定义在该节点的局部特征函数的总个数,i是是当前节点在序列的位置。
Z ( x ) = ∑ y exp [ ∑ i , k λ k t k ( y i − 1 , y i , x , i ) + ∑ i , l μ l s l ( y i , x , i ) ] Z(x)=\sum_{y} \exp \left[\sum_{i, k} \lambda_{k} t_{k}\left(y_{i-1}, y_{i}, x, i\right)+\sum_{i, l} \mu_{l} s_{l}\left(y_{i}, x, i\right)\right] Z(x)=y∑exp⎣⎡i,k∑λktk(yi−1,yi,x,i)+i,l∑μlsl(yi,x,i)⎦⎤
上式是基本形式, 表示给定输入序列 x , x, x, 对输出序列 y y y 预闪的条件概率。 t k t_{k} tk 是定义在边上的特征函数,称为转移特征, 依赖于当前和前一个 位置, s l s_{l} sl 是定义在节点上的特征函数, 称为状态特征, 依赖于当前位置。 t k t_{k} tk 和 s l s_{l} sl 都依赖于位置, 是局部特征函数。通常都是0-1函数。线性链条件随机场也是对数线性模型(逻辑回归也是)。
【例子】
这里我们给出一个linear-CRF用于词性标注的实例,为了方便,我们简化了词性的种类。假设输入 的都是三个词的句子, 即 X = ( X 1 , , X 2 , , X 3 ) , X=\left(X_{1}, \quad, X_{2}, \quad, X_{3}\right), X=(X1,,X2,,X3), 输出的词性标记为 Y = ( Y 1 , , Y 2 , Y 3 ) , Y=\left(Y_{1}, \quad, Y_{2}, \quad Y_{3}\right), Y=(Y1,,Y2,Y3), 其中 Y ∈ { 1 ( Y \in\{1( Y∈{1( 名词 ) , 2 ( 动 词 ) } ), 2(动词)\} ),2(动词)}。
这里只标记出取值为1的特征函数如下:
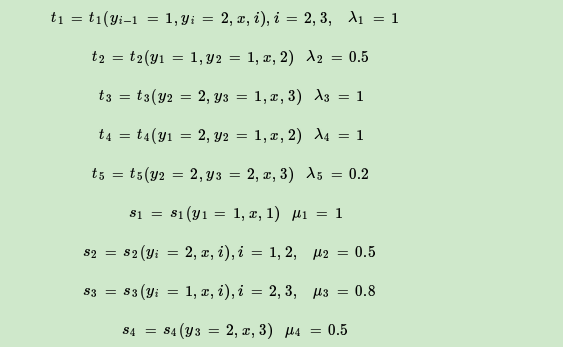
求标记(1,2,2)的非规范化概率。
利用linear-CRF的参数化公式,我们有:
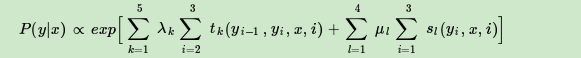
带入(1,2,2)有:
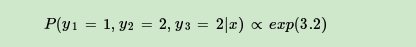
简化形式
设有 K 1 K_{1} K1 个转移特征, K 2 K_{2} K2 个状态特征, K = K 1 + K 2 , K=K_{1}+K_{2}, K=K1+K2, 记
f k ( y i − 1 , y i , x , i ) = { t k ( y i − 1 , y i , x , i ) k = 1 , 2 , ⋯ , K 1 s l ( y i , x , l ) k = K 1 + l ; l = 1 , 2 , ⋯ , K 2 f_{k}\left(y_{i-1}, y_{i}, x, i\right)=\left\{\begin{array}{l} t_{k}\left(y_{i-1}, y_{i}, x, i\right) \quad k=1,2, \cdots, K_{1} \\ s_{l}\left(y_{i}, x, l\right) \quad k=K_{1}+l ; l=1,2, \cdots, K_{2} \end{array}\right. fk(yi−1,yi,x,i)={tk(yi−1,yi,x,i)k=1,2,⋯,K1sl(yi,x,l)k=K1+l;l=1,2,⋯,K2
然后, 对转移与状态特征在各个位置i求和, 记作
f k ( y , x ) = ∑ i = 1 n f k ( y i − 1 , y i , x , i ) , k = 1 , 2 , ⋯ , K f_{k}(y, x)=\sum_{i=1}^{n} f_{k}\left(y_{i-1}, y_{i}, x, i\right), \quad k=1,2, \cdots, K fk(y,x)=i=1∑nfk(yi−1,yi,x,i),k=1,2,⋯,K
用w k _{k} k 表示特征 f k ( y , x ) f_{k}(y, x) fk(y,x) 的权值, 即
w k = { λ k , k = 1 , 2 ⋯ , K 1 μ l , k = K 1 + l , l = 1 , 2 , ⋯ , K 2 w_{k}=\left\{\begin{array}{ll} \lambda_{k}, & k=1,2 \cdots, K_{1} \\ \mu_{l}, & k=K_{1}+l, l=1,2, \cdots, K_{2} \end{array}\right. wk={λk,μl,k=1,2⋯,K1k=K1+l,l=1,2,⋯,K2
于是, 条件随机场可以表示为
p ( y ∣ x ) = 1 Z y ( x ) exp ∑ k = 1 K w k f k ( y , x ) p(y \mid x)=\frac{1}{Z_{y}(x)} \exp \sum_{k=1}^{K} w_{k} f_{k}(y, x) p(y∣x)=Zy(x)1expk=1∑Kwkfk(y,x)
矩阵形式
引进特殊的起点和和终点状态标记 y 0 = start , y n + 1 = stop , y_{0}=\operatorname{start}, y_{n+1}=\operatorname{stop}, \quad y0=start,yn+1=stop, 这是 P w ( y ∣ x ) P_{w}(y \mid x) Pw(y∣x) (简化形式)可以通过矩阵形式表示
对观测序列 x x x 的每一个位置 i = 1 , 2 , ⋯ , n + 1 , i=1,2, \cdots, n+1, i=1,2,⋯,n+1, 定义一个m阶的矩阵(m是标记 y i y_{i} yi 取值的个数 ) ) )
M i ( x ) = [ M i ( y i − 1 , y i ∣ x ) ] M i ( y i − 1 , y i ∣ x ) = exp ( W i ( y i + 1 , y i ∣ x ) ) W i ( y i + 1 , y i ∣ x ) = ∑ k = 1 K w k f k ( y i − 1 , y i , x , i ) \begin{aligned} M_{i}(x) &=\left[M_{i}\left(y_{i-1}, y_{i} \mid x\right)\right] \\ M_{i}\left(y_{i-1}, y_{i} \mid x\right) &=\exp \left(W_{i}\left(y_{i+1, y_{i} \mid x}\right)\right) \\ W_{i}\left(y_{i+1}, y_{i} \mid x\right) &=\sum_{k=1}^{K} w_{k} f_{k}\left(y_{i-1}, y_{i}, x, i\right) \end{aligned} Mi(x)Mi(yi−1,yi∣x)Wi(yi+1,yi∣x)=[Mi(yi−1,yi∣x)]=exp(Wi(yi+1,yi∣x))=k=1∑Kwkfk(yi−1,yi,x,i)
这样,给定观测序列 x , x, x, 相应标记序列y的非规范化概率可以通过该序列 n + 1 n+1 n+1 个矩阵适当元素的乘积 ∏ i = 1 n + 1 M i ( y i − 1 , y i ∣ x ) \prod_{i=1}^{n+1} M_{i}\left(y_{i-1}, y_{i} \mid x\right) ∏i=1n+1Mi(yi−1,yi∣x) 表示, 于 是条件概率 P w ( y ∣ x ) P_{w}(y \mid x) Pw(y∣x) 是
P w ( y ∣ x ) = 1 Z w ( x ) ∏ i = 1 n + 1 M i ( y i − 1 , y i ∣ x ) P_{w}(y \mid x)=\frac{1}{Z_{w}(x)} \prod_{i=1}^{n+1} M_{i}\left(y_{i-1}, y_{i} \mid x\right) Pw(y∣x)=Zw(x)1i=1∏n+1Mi(yi−1,yi∣x)
其中, Z w ( x ) Z_{w}(x) Zw(x) 是规范化因子, 是 n + 1 n+1 n+1 个矩阵的乘积的(start, stop)元素。
Z w ( x ) = ( M 1 ( x ) M 2 ( x ) ⋯ M n + 1 ( x ) ) start , stop Z_{w}(x)=\left(M_{1}(x) M_{2}(x) \cdots M_{n+1}(x)\right)_{\text {start}, \text {stop}} Zw(x)=(M1(x)M2(x)⋯Mn+1(x))start,stop
注意, y 0 = start 5 y n + 1 = s t o p y_{0}=\operatorname{start} 5 y_{n+1}=s t o p y0=start5yn+1=stop 表示开始开始状态和终止状态, 规范化因子 Z w ( x ) Z_{w}(x) Zw(x) 是以start为起点stop为终点通过状态的所有路径 y 1 y 2 ⋯ y n y_{1} y_{2} \cdots y_{n} y1y2⋯yn 的非规范化概率 ∏ i = 1 n + 1 M i ( y i − 1 , y i ∣ x ) \prod_{i=1}^{n+1} M_{i}\left(y_{i-1}, y_{i} \mid x\right) ∏i=1n+1Mi(yi−1,yi∣x) 之和
CRF的概率计算问题
前向-后向算法
对每个指标 i = 0 , 1 , ⋯ , n + 1 i=0,1,\cdots,n+1 i=0,1,⋯,n+1,定义前向向量 α i ( x ) \alpha_i(x) αi(x)
α 0 ( y ∣ x ) = { 1 , y = s t a r t 0 , 否 则 \alpha_0(y|x)= \begin{cases} 1, y=start \\ 0, 否则 \end{cases} α0(y∣x)={1,y=start0,否则
α i T ( x ) = α i − 1 T ( x ) M i ( x ) \alpha_i^T(x)=\alpha_{i-1}^T(x)M_i(x) αiT(x)=αi−1T(x)Mi(x)
α i ( y i ∣ x ) \alpha_{i}\left(y_{i} \mid x\right) αi(yi∣x) 表示在位置 i i i 的标记是 y i y_{i} yi 并且从 1 到 i i i 的前 部分标记序列的非规范化概 率, y i y_{i} yi 可取的值有 m m m 个, 所以 α i ( x ) \alpha_{i}(x) αi(x) 是 m m m 维列向量。 同样,对每个指标 i = 0 , 1 , ⋯ , n + 1 , i=0,1, \cdots, n+1, i=0,1,⋯,n+1, 定义后向向量 β i ( x ) \beta_{i}(x) βi(x) :
β n + 1 ( y n + 1 ∣ x ) = { 1 , y n + 1 = stop 0 , 否则 β i ( y i ∣ x ) = [ M i + 1 ( y i , y i + 1 ∣ x ) ] β i + 1 ( y i + 1 ∣ x ) \begin{aligned} \beta_{n+1}\left(y_{n+1} \mid x\right) &=\left\{\begin{array}{ll} 1, & y_{n+1}=\text { stop } \\ 0, & \text { 否则 } \end{array}\right.\\ \beta_{i}\left(y_{i} \mid x\right) &=\left[M_{i+1}\left(y_{i}, y_{i+1} \mid x\right)\right] \beta_{i+1}\left(y_{i+1} \mid x\right) \end{aligned} βn+1(yn+1∣x)βi(yi∣x)={1,0,yn+1= stop 否则 =[Mi+1(yi,yi+1∣x)]βi+1(yi+1∣x)
又可表示为
β i ( x ) = M i + 1 ( x ) β i + 1 ( x ) \beta_{i}(x)=M_{i+1}(x) \beta_{i+1}(x) βi(x)=Mi+1(x)βi+1(x)
β i ( y i ∣ x ) \beta_{i}\left(y_{i} \mid x\right) βi(yi∣x) 表示在位置 i i i 的标记为 y i y_{i} yi 并且从 i + 1 i+1 i+1 到 n n n 的后部分标记序列的非规范化概率。
概率计算
按照前向-后向向量的定义,很容易计算标记序列在位置 i 是标记 y i y_{i} yi 的条件概率 和在位置 i − 1 i-1 i−1 与 i i i 是标记 y i − 1 y_{i-1} yi−1 和 y i y_{i} yi 的条件概率:
P ( Y i = y i ∣ x ) = α i T ( y i ∣ x ) β i ( y i ∣ x ) Z ( x ) P\left(Y_{i}=y_{i} \mid x\right)=\frac{\alpha_{i}^{\mathrm{T}}\left(y_{i} \mid x\right) \beta_{i}\left(y_{i} \mid x\right)}{Z(x)} P(Yi=yi∣x)=Z(x)αiT(yi∣x)βi(yi∣x)
P ( Y i − 1 = y i − 1 , Y i = y i ∣ x ) = α i − 1 T ( y i − 1 ∣ x ) M i ( y i − 1 , y i ∣ x ) β i ( y i ∣ x ) Z ( x ) P\left(Y_{i-1}=y_{i-1}, Y_{i}=y_{i} \mid x\right)=\frac{\alpha_{i-1}^{\mathrm{T}}\left(y_{i-1} \mid x\right) M_{i}\left(y_{i-1}, y_{i} \mid x\right) \beta_{i}\left(y_{i} \mid x\right)}{Z(x)} P(Yi−1=yi−1,Yi=yi∣x)=Z(x)αi−1T(yi−1∣x)Mi(yi−1,yi∣x)βi(yi∣x)
其中,
Z ( x ) = α n T ( x ) 1 = 1 β 1 ( x ) Z(x)=\alpha_{n}^{\mathrm{T}}(x) 1=1 \beta_{1}(x) Z(x)=αnT(x)1=1β1(x)
1 是元素均为 1 的 m 维列向量。
期望值的计算
P ( Y ∣ X ) P(Y \mid X) P(Y∣X) 的数学期望。
特佐聚数 f k f_{k} fk 美于条件分布 P ( Y ∣ X ) P(Y \mid X) P(Y∣X) 的数学期望是
E P ( Y ∣ X ) [ f k ] = ∑ y P ( y ∣ x ) f k ( y , x ) = ∑ i = 1 n + 1 ∑ y i − 1 y i f k ( y i − 1 , y i , x , i ) α i − 1 T ( y i − 1 ∣ x ) M i ( y i − 1 , y i ∣ x ) β i ( y i ∣ x ) Z ( x ) k = 1 , 2 , ⋯ , K \begin{aligned} E_{P(Y \mid X)}\left[f_{k}\right]=& \sum_{y} P(y \mid x) f_{k}(y, x) \\ =& \sum_{i=1}^{n+1} \sum_{y_{i-1} y_{i}} f_{k}\left(y_{i-1}, y_{i}, x, i\right) \frac{\alpha_{i-1}^{\mathrm{T}}\left(y_{i-1} \mid x\right) M_{i}\left(y_{i-1}, y_{i} \mid x\right) \beta_{i}\left(y_{i} \mid x\right)}{Z(x)} \\ & \quad \quad k=1,2, \cdots, K \end{aligned} EP(Y∣X)[fk]==y∑P(y∣x)fk(y,x)i=1∑n+1yi−1yi∑fk(yi−1,yi,x,i)Z(x)αi−1T(yi−1∣x)Mi(yi−1,yi∣x)βi(yi∣x)k=1,2,⋯,K
其中 ,
Z ( x ) = α n T ( x ) 1 Z(x)=\alpha_{n}^{\mathrm{T}}(x) 1 Z(x)=αnT(x)1
E P ( X , Y ) [ f k ] = ∑ x , y P ( x , y ) ∑ i = 1 n + 1 f k ( y i − 1 , y i , x , i ) = ∑ x P ~ ( x ) ∑ y P ( y ∣ x ) ∑ i = 1 n + 1 f k ( y i − 1 , y i , x , i ) = ∑ x P ~ ( x ) ∑ i = 1 n + 1 ∑ y i − 1 y i f k ( y i − 1 , y i , x , i ) α i − 1 T ( y i − 1 ∣ x ) M i ( y i − 1 , y i ∣ x ) β i ( y i ∣ x ) Z ( x ) k = 1 , 2 , ⋯ , K \begin{aligned} E_{P(X, Y)}\left[f_{k}\right] &=\sum_{x, y} P(x, y) \sum_{i=1}^{n+1} f_{k}\left(y_{i-1}, y_{i}, x, i\right) \\ &=\sum_{x} \tilde{P}(x) \sum_{y} P(y \mid x) \sum_{i=1}^{n+1} f_{k}\left(y_{i-1}, y_{i}, x, i\right) \\ &=\sum_{x} \tilde{P}(x) \sum_{i=1}^{n+1} \sum_{y_{i}-1 y_{i}} f_{k}\left(y_{i-1}, y_{i}, x, i\right) \frac{\alpha_{i-1}^{T}\left(y_{i-1} \mid x\right) M_{i}\left(y_{i-1}, y_{i} \mid x\right) \beta_{i}\left(y_{i} \mid x\right)}{Z(x)} \\ & & k=1,2, \cdots, K \end{aligned} EP(X,Y)[fk]=x,y∑P(x,y)i=1∑n+1fk(yi−1,yi,x,i)=x∑P~(x)y∑P(y∣x)i=1∑n+1fk(yi−1,yi,x,i)=x∑P~(x)i=1∑n+1yi−1yi∑fk(yi−1,yi,x,i)Z(x)αi−1T(yi−1∣x)Mi(yi−1,yi∣x)βi(yi∣x)k=1,2,⋯,K
其中,
Z ( x ) = α n T ( x ) 1 Z(x)=\alpha_{n}^{\mathrm{T}}(x) 1 Z(x)=αnT(x)1
假设经聚分布为 P ~ ( X ) , \tilde{P}(X), P~(X), 特征函数 f k f_{k} fk 关于联合分布 P ( X , Y ) P(X, Y) P(X,Y) 的数学期望是
E P ( X , Y ) [ f k ] = ∑ x , y P ( x , y ) ∑ i = 1 n + 1 f k ( y i − 1 , y i , x , i ) = ∑ x P ~ ( x ) ∑ y P ( y ∣ x ) ∑ i = 1 n + 1 f k ( y i − 1 , y i , x , i ) = ∑ x P ~ ( x ) ∑ i = 1 n + 1 ∑ y i − 1 y i f k ( y i − 1 , y i , x , i ) α i − 1 T ( y i − 1 ∣ x ) M i ( y i − 1 , y i ∣ x ) β i ( y i ∣ x ) Z ( x ) k = 1 , 2 , ⋯ , K \begin{aligned} E_{P(X, Y)}\left[f_{k}\right] &=\sum_{x, y} P(x, y) \sum_{i=1}^{n+1} f_{k}\left(y_{i-1}, y_{i}, x, i\right) \\ &=\sum_{x} \tilde{P}(x) \sum_{y} P(y \mid x) \sum_{i=1}^{n+1} f_{k}\left(y_{i-1}, y_{i}, x, i\right) \\ &=\sum_{x} \tilde{P}(x) \sum_{i=1}^{n+1} \sum_{y_{i}-1 y_{i}} f_{k}\left(y_{i-1}, y_{i}, x, i\right) \frac{\alpha_{i-1}^{T}\left(y_{i-1} \mid x\right) M_{i}\left(y_{i-1}, y_{i} \mid x\right) \beta_{i}\left(y_{i} \mid x\right)}{Z(x)} \\ & & k=1,2, \cdots, K \end{aligned} EP(X,Y)[fk]=x,y∑P(x,y)i=1∑n+1fk(yi−1,yi,x,i)=x∑P~(x)y∑P(y∣x)i=1∑n+1fk(yi−1,yi,x,i)=x∑P~(x)i=1∑n+1yi−1yi∑fk(yi−1,yi,x,i)Z(x)αi−1T(yi−1∣x)Mi(yi−1,yi∣x)βi(yi∣x)k=1,2,⋯,K
其中,
Z ( x ) = α n T ( x ) 1 Z(x)=\alpha_{n}^{\mathrm{T}}(x) 1 Z(x)=αnT(x)1
式 (11.34) 和式 (11.35) 是特征函数数学期望的一般计算公式。对于转移特征 t k ( y i − 1 , y i , x , i ) , k = 1 , 2 , ⋯ , K 1 , t_{k}\left(y_{i-1}, y_{i}, x, i\right), k=1,2, \cdots, K_{1}, tk(yi−1,yi,x,i),k=1,2,⋯,K1, 可以将式中的 f k f_{k} fk 换成 t k : t_{k}: tk: 对于状态特征,可以将 式中的 f k f_{k} fk 换成 s i , s_{i}, si, 表示为 $s_{l}\left(y_{i}, x, i\right), k=K_{1}+l, l=1,2, \cdots, K_{2} $ 。
有了式 (11.32) ∼ \sim ∼ 式 ( 11.35 ) , (11.35), (11.35), 对于给定的观测序列 x x x 与标记序列 y , y, y, 可以通过一次 前向扫描计甘 α i \alpha_{i} αi 及 Z ( x ) , Z(x), Z(x), 通过一次后向扫描计算 β i , \beta_{i}, βi, 从而计算所有的概率和特征的 期望。
CRF的学习预测算法
迭代尺度法
输入: 特征函数 t 1 , t 2 , ⋯ , t K 1 , s 1 , s 2 , ⋯ , s K 2 ; t_{1}, t_{2}, \cdots, t_{K_{1}}, s_{1}, s_{2}, \cdots, s_{K_{2}} ; t1,t2,⋯,tK1,s1,s2,⋯,sK2; 经验分布 P ~ ( x , y ) \tilde{P}(x, y) P~(x,y)
输出: 参数估计值 w ^ \hat{w} w^; 模型 P w ^ P_{\hat{w}} Pw^
(1) 对所有 k ∈ { 1 , 2 , ⋯ , K } , k \in\{1,2, \cdots, K\}, k∈{1,2,⋯,K}, 取初值 w k = 0 w_{k}=0 wk=0
(2) 对每一 k ∈ { 1 , 2 , ⋯ , K } k \in\{1,2, \cdots, K\} k∈{1,2,⋯,K} :
(a) 当 k = 1 , 2 , ⋯ , K 1 k=1,2, \cdots, K_{1} k=1,2,⋯,K1 时, 令 δ k \delta_{k} δk 是方程
∑ x , y P ~ ( x ) P ( y ∣ x ) ∑ i = 1 n + 1 t k ( y i − 1 , y i , x , i ) exp ( δ k T ( x , y ) ) = E P ~ [ t k ] \sum_{x, y} \tilde{P}(x) P(y \mid x) \sum_{i=1}^{n+1} t_{k}\left(y_{i-1}, y_{i}, x, i\right) \exp \left(\delta_{k} T(x, y)\right)=E_{\tilde{P}}\left[t_{k}\right] x,y∑P~(x)P(y∣x)i=1∑n+1tk(yi−1,yi,x,i)exp(δkT(x,y))=EP~[tk]
的解;
当 k = K 1 + l , l = 1 , 2 , ⋯ , K 2 k=K_{1}+l, l=1,2, \cdots, K_{2} k=K1+l,l=1,2,⋯,K2 时, , ℑ ^ δ K 1 + l , \hat{\Im} \delta_{K_{1}+l} ,ℑ^δK1+l 是方程
∑ x , y P ~ ( x ) P ( y ∣ x ) ∑ i = 1 n s l ( y i , x , i ) exp ( δ K 1 + l T ( x , y ) ) = E P ~ [ s l ] \sum_{x, y} \tilde{P}(x) P(y \mid x) \sum_{i=1}^{n} s_{l}\left(y_{i}, x, i\right) \exp \left(\delta_{K_{1}+l} T(x, y)\right)=E_{\tilde{P}}\left[s_{l}\right] x,y∑P~(x)P(y∣x)i=1∑nsl(yi,x,i)exp(δK1+lT(x,y))=EP~[sl]
的值,式中 T ( x , y ) T(x, y) T(x,y) 由式 (11.38) 给出。
(b) 更新 w k w_{k} wk 值: w k ← w k + δ k w_{k} \leftarrow w_{k}+\delta_{k} wk←wk+δk
据 ( x , y ) (x, y) (x,y) 取值可能不同。为了处理这个问題,定义松己特征
s ( x , y ) = S − ∑ i = 1 n + 1 ∑ k = 1 K f k ( y i − 1 , y i , x , i ) (11.39) s(x, y)=S-\sum_{i=1}^{n+1} \sum_{k=1}^{K} f_{k}\left(y_{i-1}, y_{i}, x, i\right) \tag{11.39} s(x,y)=S−i=1∑n+1k=1∑Kfk(yi−1,yi,x,i)(11.39)
式中 S 是一个常 数。选择足解大的常数 S 使得对训练数据集的所有数据 ( x , y ) (x, y) (x,y), s ( x , y ) ⩾ 0 s(x, y) \geqslant 0 s(x,y)⩾0 成立。这时特征.总数可取 S o S_{\text {o }} So
由式 (11.36),对于特移特征 t k , δ k t_{k}, \delta_{k} tk,δk 的更新方程是
∑ P ~ ( x ) P ( y ∣ x ) ∑ i = 1 n + 1 t k ( y i − 1 , y i , x , i ) exp ( δ k S ) = E P ^ [ t k ] (11.40) \begin{array}{c} \sum \tilde{P}(x) P(y \mid x) \sum_{i=1}^{n+1} t_{k}\left(y_{i-1}, y_{i}, x, i\right) \exp \left(\delta_{k} S\right)=E_{\hat{P}}\left[t_{k}\right]\tag{11.40} \end{array} ∑P~(x)P(y∣x)∑i=1n+1tk(yi−1,yi,x,i)exp(δkS)=EP^[tk](11.40)
δ k = 1 S log E P ~ [ t k ] E P [ t k ] (11.41) \delta_{k}=\frac{1}{S} \log \frac{E_{\tilde{P}}\left[t_{k}\right]}{E_{P}\left[t_{k}\right]}\tag{11.41} δk=S1logEP[tk]EP~[tk](11.41)
其中。
E P ( t k ) = ∑ x P ~ ( x ) ∑ i = 1 n + 1 ∑ y i − 1 , y i t k ( y i − 1 , y i , x , i ) α i − 1 T ( y i − 1 ∣ x ) M i ( y i − 1 , y i ∣ x ) β i ( y i ∣ x ) Z ( x ) (11.42) E_{P}\left(t_{k}\right)=\sum_{x} \tilde{P}(x) \sum_{i=1}^{n+1} \sum_{y_{i-1}, y_{i}} t_{k}\left(y_{i-1}, y_{i}, x, i\right) \frac{\alpha_{i-1}^{\mathrm{T}}\left(y_{i-1} \mid x\right) M_{i}\left(y_{i-1}, y_{i} \mid x\right) \beta_{i}\left(y_{i} \mid x\right)}{Z(x)}\tag{11.42} EP(tk)=x∑P~(x)i=1∑n+1yi−1,yi∑tk(yi−1,yi,x,i)Z(x)αi−1T(yi−1∣x)Mi(yi−1,yi∣x)βi(yi∣x)(11.42)
同样由式 (11.37),对于状态特征 s l , δ k s_{l}, \delta_{k} sl,δk 的更新方程是
∑ P ~ ( x ) P ( y ∣ x ) ∑ i = 1 n s l ( y i , x , i ) exp ( δ K 1 + l S ) = E P ˉ [ s i ] (11.43) \begin{array}{c} \sum \tilde{P}(x) P(y \mid x) \sum_{i=1}^{n} s_{l}\left(y_{i}, x, i\right) \exp \left(\delta_{K_{1}+l} S\right)=E_{\bar{P}}\left[s_{i}\right]\tag{11.43} \\ \end{array} ∑P~(x)P(y∣x)∑i=1nsl(yi,x,i)exp(δK1+lS)=EPˉ[si](11.43)
δ K 1 + l = 1 S log E P ~ [ s l ] E P [ s l ] (11.44) \delta_{K_{1}+l}=\frac{1}{S} \log \frac{E_{\tilde{P}}\left[s_{l}\right]}{E_{P}\left[s_{l}\right]}\tag{11.44} δK1+l=S1logEP[sl]EP~[sl](11.44)
其中,
E P ( s l ) = ∑ x P ~ ( x ) ∑ i = 1 n ∑ y i s l ( y i , x , i ) α i T ( y i ∣ x ) β i ( y i ∣ x ) Z ( x ) (11.45) E_{P}\left(s_{l}\right)=\sum_{x} \tilde{P}(x) \sum_{i=1}^{n} \sum_{y_{i}} s_{l}\left(y_{i}, x, i\right) \frac{\alpha_{i}^{T}\left(y_{i} \mid x\right) \beta_{i}\left(y_{i} \mid x\right)}{Z(x)}\tag{11.45} EP(sl)=x∑P~(x)i=1∑nyi∑sl(yi,x,i)Z(x)αiT(yi∣x)βi(yi∣x)(11.45)
以上算法称为算法 S。在算法 S 中需要使常数 S 取足够大,这样一来,每步迭代
的增量向量会变大,算法收签会变慢。算法 T 试图解决这个问题。算法 T 对每个观测
字列 x 计算其特休总数最大值 T ( x ) T(x) T(x) :
拟牛顿法
输入:特征函数 f 1 , f 2 , ⋯ , f n ; f_{1}, f_{2}, \cdots, f_{n} ; f1,f2,⋯,fn; 经验分布 P ~ ( X , Y ) \tilde{P}(X, Y) P~(X,Y)
输出: 最优参数值 w ^ \hat{w} w^; 最优模型 P w ^ ( y ∣ x ) P_{\hat{w}}(y \mid x) Pw^(y∣x) 。
(1)选定初始点 w ( 0 ) , w^{(0)}, w(0), 取 B 0 B_{0} B0 为正定对称矩阵, 置 k = 0 k=0 k=0 o
(2) 计算 g k = g ( w ( k ) ) g_{k}=g\left(w^{(k)}\right) gk=g(w(k)) 。若 g k = 0 , g_{k}=0, gk=0, 则停止计算; 否则转 (3)
(3) 由 B k p k = − g k B_{k} p_{k}=-g_{k} Bkpk=−gk 求出 p k p_{k} pk
(4)一维搜索: 求 λ k \lambda_{k} λk 使得
f ( w ( k ) + λ k p k ) = min λ ⩾ 0 f ( w ( k ) + λ p k ) f\left(w^{(k)}+\lambda_{k} p_{k}\right)=\min _{\lambda \geqslant 0} f\left(w^{(k)}+\lambda p_{k}\right) f(w(k)+λkpk)=λ⩾0minf(w(k)+λpk)
(5) 置 w ( k + 1 ) = w ( k ) + λ k p k w^{(k+1)}=w^{(k)}+\lambda_{k} p_{k} w(k+1)=w(k)+λkpk
(6) 计算 g k + 1 = g ( w ( k + 1 ) ) , g_{k+1}=g\left(w^{(k+1)}\right), gk+1=g(w(k+1)), 若 g k + 1 = 0 , g_{k+1}=0, gk+1=0, 则停止计算; 否则, 按下式求出 B k + 1 : B_{k+1:} Bk+1:
B k + 1 = B k + y k y k T y k T δ k − B k δ k δ k T B k δ k T B k δ k B_{k+1}=B_{k}+\frac{y_{k} y_{k}^{\mathrm{T}}}{y_{k}^{\mathrm{T}} \delta_{k}}-\frac{B_{k} \delta_{k} \delta_{k}^{\mathrm{T}} B_{k}}{\delta_{k}^{\mathrm{T}} B_{k} \delta_{k}} Bk+1=Bk+ykTδkykykT−δkTBkδkBkδkδkTBk
其中
y k = g k + 1 − g k , δ k = w ( k + 1 ) − w ( k ) y_{k}=g_{k+1}-g_{k}, \quad \delta_{k}=w^{(k+1)}-w^{(k)} yk=gk+1−gk,δk=w(k+1)−w(k)
(7)置 k = k + 1 k=k+1 k=k+1,转(3)。
维特比算法
输入:模型特征向量 F ( y , x ) F(y, x) F(y,x) 和权值向量 w , w, w, 观测序列 x = ( x 1 , x 2 , ⋯ , x n ) x=\left(x_{1}, x_{2}, \cdots, x_{n}\right) x=(x1,x2,⋯,xn)
输出:最优路径 y ∗ = ( y 1 ∗ , y 2 ∗ , ⋯ , y n ∗ ) y^{*}=\left(y_{1}^{*}, y_{2}^{*}, \cdots, y_{n}^{*}\right) y∗=(y1∗,y2∗,⋯,yn∗)
(1)初始化
δ 1 ( j ) = w ⋅ F 1 ( y 0 = start , y 1 = j , x ) , j = 1 , 2 , ⋯ , m \delta_{1}(j)=w \cdot F_{1}\left(y_{0}=\text { start }, y_{1}=j, x\right), \quad j=1,2, \cdots, m δ1(j)=w⋅F1(y0= start ,y1=j,x),j=1,2,⋯,m
(2) 递推。对 i = 2 , 3 , ⋯ , n i=2,3, \cdots, n i=2,3,⋯,n
δ i ( l ) = max 1 ⩽ j ⩽ m { δ i − 1 ( j ) + w ⋅ F i ( y i − 1 = j , y i = l , x ) } , l = 1 , 2 , ⋯ , m Ψ i ( l ) = arg max 1 ⩽ j ⩽ m { δ i − 1 ( j ) + w ⋅ F i ( y i − 1 = j , y i = l , x ) } , l = 1 , 2 , ⋯ , m \begin{array}{c} \delta_{i}(l)=\max _{1 \leqslant j \leqslant m}\left\{\delta_{i-1}(j)+w \cdot F_{i}\left(y_{i-1}=j, y_{i}=l, x\right)\right\}, \quad l=1,2, \cdots, m \\ \Psi_{i}(l)=\arg \max _{1 \leqslant j \leqslant m}\left\{\delta_{i-1}(j)+w \cdot F_{i}\left(y_{i-1}=j, y_{i}=l, x\right)\right\}, \quad l=1,2, \cdots, m \end{array} δi(l)=max1⩽j⩽m{δi−1(j)+w⋅Fi(yi−1=j,yi=l,x)},l=1,2,⋯,mΨi(l)=argmax1⩽j⩽m{δi−1(j)+w⋅Fi(yi−1=j,yi=l,x)},l=1,2,⋯,m
(3) 终止
max y ( w ⋅ F ( y , x ) ) = max 1 ⩽ j ⩽ m δ n ( j ) \max _{y}(w \cdot F(y, x))=\max _{1 \leqslant j \leqslant m} \delta_{n}(j) ymax(w⋅F(y,x))=1⩽j⩽mmaxδn(j)
y n ∗ = arg max 1 ⩽ j ⩽ m δ n ( j ) y_{n}^{*}=\arg \max _{1 \leqslant j \leqslant m} \delta_{n}(j) yn∗=arg1⩽j⩽mmaxδn(j)
(4)返回路径
y i ∗ = Ψ i + 1 ( y i + 1 ∗ ) , i = n − 1 , n − 2 , ⋯ , 1 y_{i}^{*}=\Psi_{i+1}\left(y_{i+1}^{*}\right), \quad i=n-1, n-2, \cdots, 1 yi∗=Ψi+1(yi+1∗),i=n−1,n−2,⋯,1
求得最优路径 y ∗ = ( y 1 ∗ , y 2 ∗ , ⋯ , y n ∗ ) y^{*}=\left(y_{1}^{*}, y_{2}^{*}, \cdots, y_{n}^{*}\right) y∗=(y1∗,y2∗,⋯,yn∗)
代码实现
from numpy import *
#这里定义T为转移矩阵列代表前一个y(ij)代表由状态i转到状态j的概率,Tx矩阵x对应于时间序列
#这里将书上的转移特征转换为如下以时间轴为区别的三个多维列表,维度为输出的维度
T1 = [[0.6, 1], [1, 0]]
T2 = [[0, 1], [1, 0.2]]
#将书上的状态特征同样转换成列表,第一个是为y1的未规划概率,第二个为y2的未规划概率
S0 = [1, 0.5]
S1 = [0.8, 0.5]
S2 = [0.8, 0.5]
Y = [1, 2, 2] #即书上例一需要计算的非规划条件概率的标记序列
Y = array(Y) - 1 #这里为了将数与索引相对应即从零开始
P = exp(S0[Y[0]])
for i in range(1, len(Y)):
P *= exp((eval('S%d' % i)[Y[i]]) + eval('T%d' % i)[Y[i - 1]][Y[i]])
print(P)
print(exp(3.2))
Reference:

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)