《生物信息学:导论与方法》----导论与历史----听课笔记(一)
北京大学----生物信息学:导论与方法(2013?)第一章 导论与历史1.1 什么是生物信息学基因组就是ATCG这四个字母的简单的重复人的基因组一共有31亿个碱基对,里面只有2.9%是编码蛋白的基因区间。高等生物有大量的可变剪切,一个基因可以有多个剪切体,翻译成多个蛋白。整个世界上除了RNA病毒之外的其他的所有物种的基因组都是由ATCG这样简单的重复组成的。核酸序列的增...
·
北京大学----生物信息学:导论与方法(2013?)
第一章 导论与历史
1.1 什么是生物信息学
- 基因组就是ATCG这四个字母的简单的重复
- 人的基因组一共有31亿个碱基对,里面只有2.9%是编码蛋白的基因区间。
- 高等生物有大量的可变剪切,一个基因可以有多个剪切体,翻译成多个蛋白。
- 整个世界上除了RNA病毒之外的其他的所有物种的基因组都是由ATCG这样简单的重复组成的。
- 核酸序列的增长的趋势一直呈现指数增长的趋势 。
- Genbank的数据每20个月就会翻一番,最近的增长趋势更加陡峭,主要是新一代测序被开发出来。
- 现在一台测序仪用一天时间就可以测出好几个人的基因组,每一个人大概300美元左右。
- 高通量技术相对于传统低通量技术错误率更高。
- 比如新一代测序技术单个碱基、单次测序的错误率是传统Sanger测序错误率的100倍高。
- 在技术挑战的时候,就是一个技术创新的机遇。
- 生命科学和计算机科学的交叉是一个必然的历史趋势。
- 生物信息学是一个前沿交叉学科,它主要通过开发并且应用计算和计算机技术来研究生物医学问题。
- 生物信息也是一个管理、检索和分析海量生物医学数据的信息技术和计算技术。
- 生物信息学还是一种和传统生物学非常互补的一种研究方法。它是一种自上而下,从全基因组出发,从系统水平出发,基于数据的一种产生新假说、发现新规律、发现新功能元件的研究方法。
- 生物信息学主要的研究问题是生物和医学里的问题,主要的研究手段和开发的主要技术涉及计算机、数学、统计和物理学里的技术。
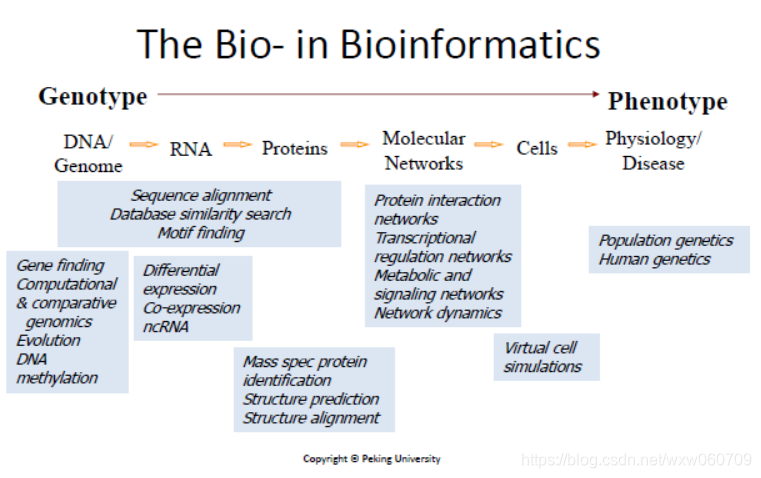
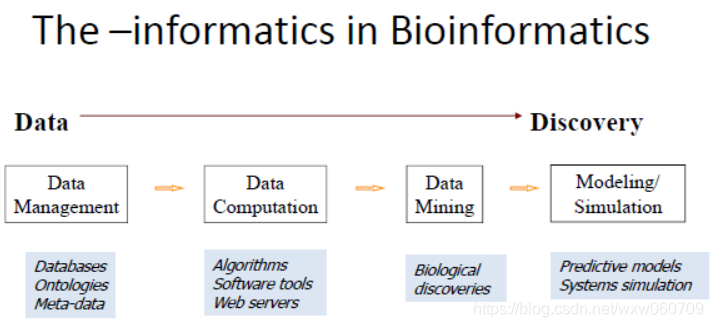
1.2 中国大陆的生物信息学
- 中国生物信息学发展的驱动力主要有四点:第一,是计算机技术和互联网的发展;第二,国内外基因组学的发展;第三,政府科研经费投入越来越多;第四,越来越多地投身于这个领域的本土和海外引进的人才以及本土培养的学生。
1.3 生物信息学历史
- 1953年,Waston and Crick在Nature上发表了只有一页纸长的一篇文章,发现了DNA的双螺旋结构,奠定了DNA作为遗传物质技术的这样的一个地位。
- 上世纪50年代,第一个蛋白的序列和第一个蛋白的结构都被解析出来。
- 然后以Pauling为代表的一些学者开始意识到可以在分子水平研究研究演化。
- 1965年,Evolutionary Divergence and Convergence in Proteins, 提出了分子钟的概念。
- 最早是以蛋白测序为主。
- 1988年,The Human Genome Project
- 1991年,Paradigm Shift
- 2001年,人的基因组的草图被发表。
- 2004年,人的基因组的完成图发表。
- 1970年,出现了bioinformatics这个词
- 1982年,Genbank建立。
- 1970年,动态规划进行序列配对,A General Method Applicaple to the Search for Similarities in the Amino Acid Sequence of Two Proteins
- 1992年,BLOSUM matrix
- 70年代,发现基因是有intro,intro突变率很高,所以对比时无所谓。
- Waterman(局部比对算法的提出者)对Needleman-Wunsch算法里做了两个非常小的改动,巧妙的解决了intro的问题。
- 1990年和1997年,BLAST方法,两篇文章引用了将近5万次,在整个科学领域里都是排在前10名的。
- 2002年,blat算法。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)