中科大、阿里、牛津 、圣三一学院等重磅开源!高效医学图像分割
本文提出了一种高效医学图像分割模型Zig-RiR,通过创新的嵌套RWKV结构和锯齿状扫描机制,实现了线性计算复杂度。该模型采用Outer和Inner RWKV块分别捕捉全局与局部特征,在保持空间连续性的同时显著提升效率。实验表明,Zig-RiR在2D/3D医学图像数据集上性能优异,处理1024×1024图像时速度提升14.4倍,内存减少89.5%,为高分辨率医学图像分割提供了高效解决方案。
论文信息
论文题目:[TMI 2025] Zig-RiR: Zigzag RWKV-in-RWKV for Efficient Medical Image Segmentation(TMI2025 | 用于高效医学图像分割的锯齿状 rwkv嵌套rwkv网络)
作者机构:Tianxiang Chen, Xudong Zhou, Zhentao Tan, Yue Wu, Ziyang Wang, Zi Ye*, Tao Gong, Qi chu, NenghaiYu, and Lu Le
University of Science and Technology of china, Alibaba Cloud, University of Oxford, The Alan Turing InstituteTrinity College Dublin, Alibaba DAMO Academy
文章链接:https://ieeexplore.ieee.org/document/10969076
项目链接:https://github.com/txchen-USTC/Zig-RiR
1. 亮点直击
本文提出了一种新颖的医疗图像分割模型 Zigzag RWKV-in-RWKV (Zig-RiR),可用于精准分割二维、三维的医疗图像,其核心亮点包括:
线性复杂度:通过引入RWKV模型的思想,实现了长距离建模的线性计算复杂度,显著提升了效率。
全局与局部特征兼顾:采用嵌套结构(Outer和Inner RWKV块)分别捕捉全局和局部特征,同时保持空间连续性。
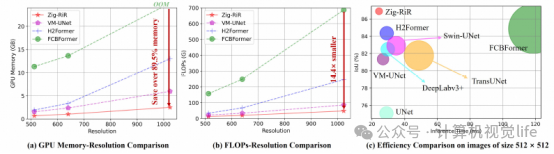
高效性与轻量化:在高分辨率(1024 × 1024)医疗图像上测试时,速度比现有最先进方法快14.4倍,GPU内存使用减少89.5%。
2. 解决的问题
当前主流的基于CNN和Transformer结构的医疗图像分割模型存在以下问题:
计算复杂度高:Transformer的自注意力机制导致二次方级别的计算复杂度,限制了模型在高分辨率图像上的应用。
局部特征探索不足:直接应用Vision-RWKV模型时,对局部特征的提取能力较弱,且空间连续性被破坏。
效率与精度权衡困难:现有方法难以在保持高精度的同时实现高效推理。
3. 提出的方法
为解决上述问题,本文提出了 Zigzag RWKV-in-RWKV (Zig-RiR) 模型,具体包括以下创新点:
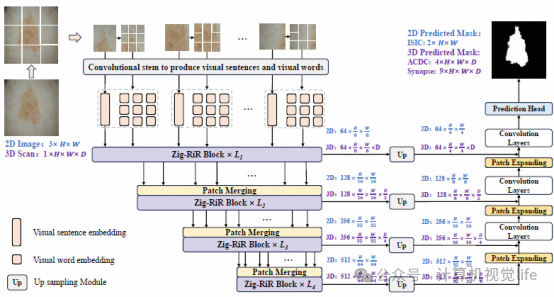
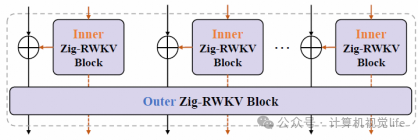
嵌套结构设计:
Outer RWKV块:将局部图像块视为“视觉句子”,用于提取全局信息。
Inner RWKV块:将每个“视觉句子”分解为更小的子块(“视觉单词”),用于进一步探索局部特征,且计算成本极低。
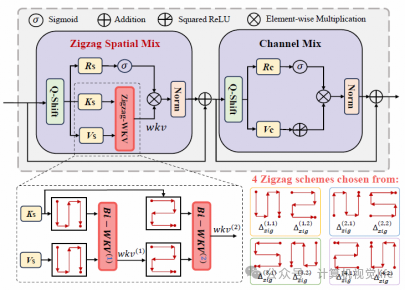
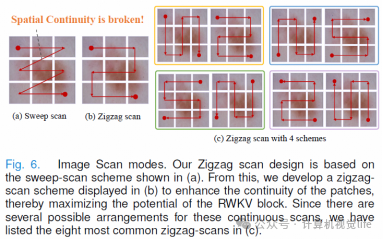
Zigzag-WKV注意力机制:
引入一种新的锯齿状扫描机制,在扫描Token时确保空间连续性不遭到破坏。
特征聚合:
通过整合“视觉单词”和“视觉句子”的特征,模型能够有效捕捉全局与局部信息,同时保持空间一致性。
4. 实验设置
数据集:实验在四个医疗图像分割数据集(ISIC 2016, ISIC 2018, ACDC, Synapse)上进行,涵盖2D和3D模态。
对比方法:与现有的最先进方法(如基于Transformer和CNN的模型)进行了性能和效率的对比。
测试条件:特别针对高分辨率(1024 × 1024)医疗图像进行了测试,以验证模型在极端场景下的表现。
5. 实验结果
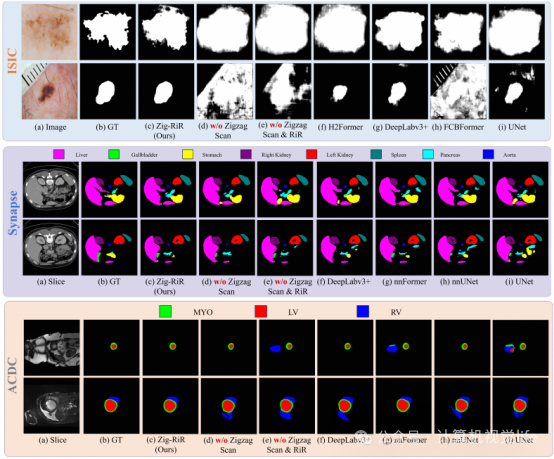
定性结果:
在二维ISIC数据集和三维ACDC, Synapse数据集上,Zig-RiR均展现出了明显的精准分割优势。
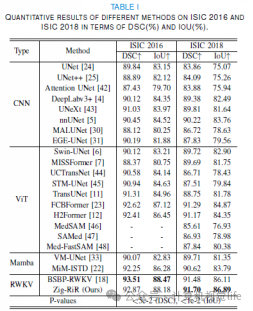
定量结果:
在二维ISIC数据集和三维ACDC, Synapse数据集上,Zig-RiR都表现出极高的分割性能,表明它在提取目标的边界和区域时非常准确。
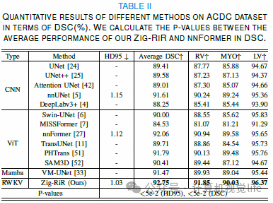
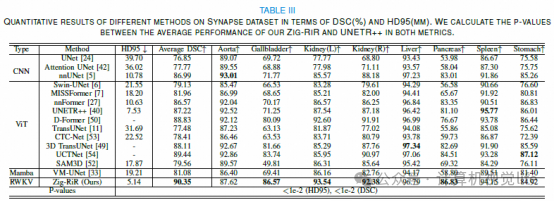
效率优势:
速度提升:相比现有最先进方法,推理速度提高了 14.4倍。 内存优化:在处理1024 × 1024高分辨率图像时,GPU内存使用减少了 89.5%。
结语:
Zig-RiR模型通过创新的嵌套结构和锯齿状扫描设计,成功实现了对二维、三维医疗图像的高效率且精准的分割,为该领域提供了先进的解决方案。
对更多实验结果和文章细节感兴趣的读者,可以阅读论文原文~
这里也给大家准备了论文复现文档和更多创新点的资料,大家可以扫码找我领取哈~

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 18
18 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)