吴恩达-深度学习-各个变量的求导
这是关于损失函数对各变量的求导 是单样本实例的 在这里 是假设样本有两个特征值 那么对应的有两个权重 但是偏差是一样的 所以关于z的函数则如上图所示 关于da/dz的求导 是因为 a = σ(z)=1/(1+ⅇ^(-z) ) 所以对于da/dz的求导等于a(1-a) 而L(a,y) = -(...

这是关于损失函数对各变量的求导 是单样本实例的 在这里 是假设样本有两个特征值 那么对应的有两个权重 但是偏差是一样的 所以关于z的函数则如上图所示 关于da/dz的求导 是因为 a = σ(z)= 1/(1+ⅇ^(-z) ) 所以对于da/dz的求导等于a(1-a) 而L(a,y) = -(y * logy ̂ +(1-y)*log(1-y ̂)) 所以通过求导 可以得到dl/dz = a - y,在python代码中 用dz 来表达 最终的函数对于z变量的求导 所以这里da 代表dl/dz 那么也可以求出 dw1 dw2 db 再分别对 w1 w2 b进行一次梯度下降法但是在训练中你不可能只训练一个样本 而是m个样本组成的训练集 因此下面则是对于训练集的讨论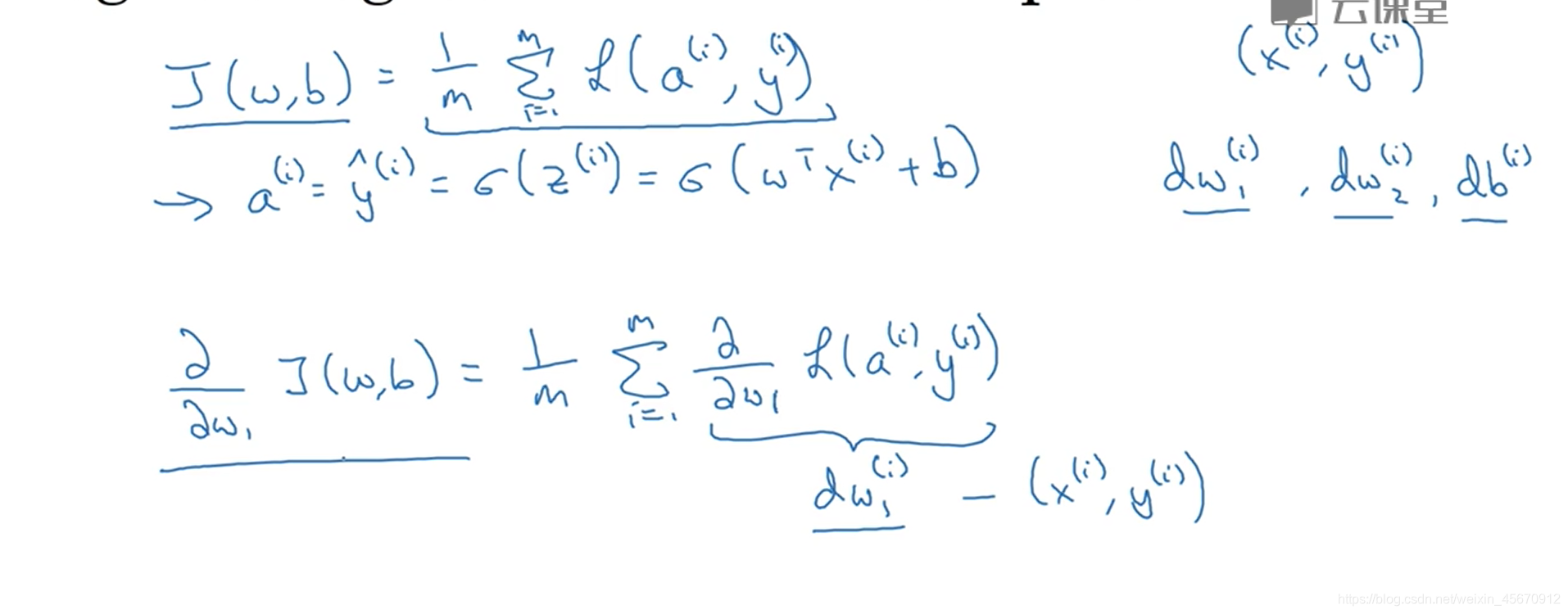 其实对于整个训练集的讨论也是一样的 因为我们可以求出的单个训练集的关于各变量的求导 那么对于m各样本的代价函数关于各变量的求导 也就是将各个样本对各变量的求导之和加起来 再取一个均值 则得到的就是一个全局的梯度值
其实对于整个训练集的讨论也是一样的 因为我们可以求出的单个训练集的关于各变量的求导 那么对于m各样本的代价函数关于各变量的求导 也就是将各个样本对各变量的求导之和加起来 再取一个均值 则得到的就是一个全局的梯度值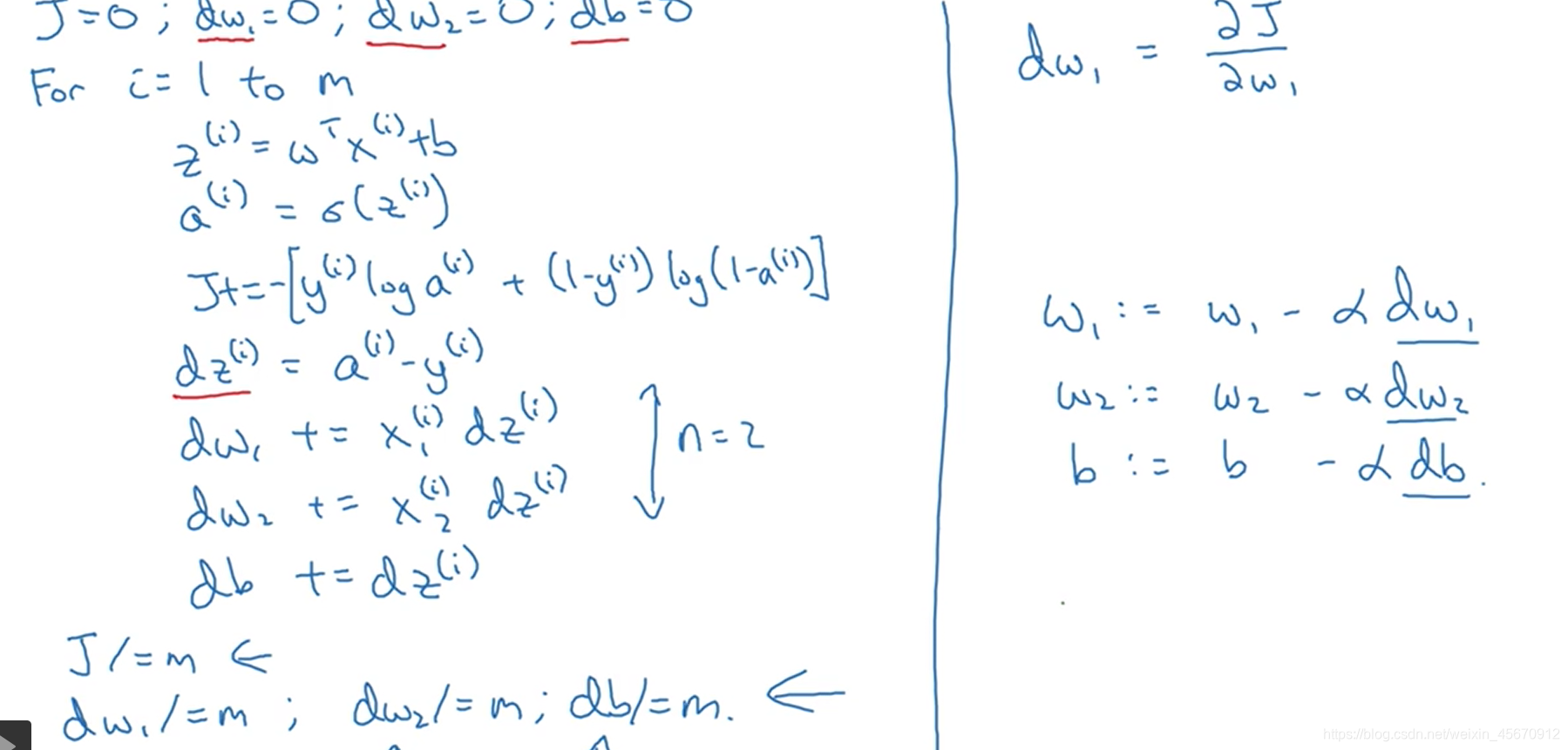 这是关于对于如何去求得到一个代价函数的最优解的一个步骤 通过不断的迭代更新 得到我们最终想要的w1 w2 b.这里我们发现用的是两个for循环 一个是对m各训练集的遍历 一个是对样本特征值的遍历 但是在代码中去跑这些程序 效率太低 因为我们最终对样本集的训练会是特别大的 所以在这里显式的for循环不是很好 需要用到向量化
这是关于对于如何去求得到一个代价函数的最优解的一个步骤 通过不断的迭代更新 得到我们最终想要的w1 w2 b.这里我们发现用的是两个for循环 一个是对m各训练集的遍历 一个是对样本特征值的遍历 但是在代码中去跑这些程序 效率太低 因为我们最终对样本集的训练会是特别大的 所以在这里显式的for循环不是很好 需要用到向量化

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)