二手房源信息数据分析与可视化
数据读取及描述性分析,得到房价及平米的数值型描述删除车位信息数据分析1:价格最高的5个别墅,删除别墅信息数据分析2:找出数据中的住房户型分布数据分析3:找出关注人数最多的五套房子数据分析4:户型和关注人数分布数据分析5:面积分布数据分析6:各个行政区房源单价均价数据分析7:各个行政区的房源总价对比数据分析8:按照地铁信息对各个区域每平米均价排序,柱形图绘制数据分析9:按小区均价排序综合:紧邻望京地
- 数据读取及描述性分析,得到房价及平米的数值型描述
- 删除车位信息
- 数据分析1:价格最高的5个别墅,删除别墅信息
- 数据分析2:找出数据中的住房户型分布
- 数据分析3:找出关注人数最多的五套房子
- 数据分析4:户型和关注人数分布
- 数据分析5:面积分布
- 数据分析6:各个行政区房源单价均价
- 数据分析7:各个行政区的房源总价对比
- 数据分析8:按照地铁信息对各个区域每平米均价排序,柱形图绘制
- 数据分析9:按小区均价排序
- 综合:紧邻望京地铁站,三室一厅,400万-500万,大于80平米的房子
# 导入模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 设置使中文显示完整
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#所有房源信息
house=pd.read_csv('house.csv')
house.head(20)
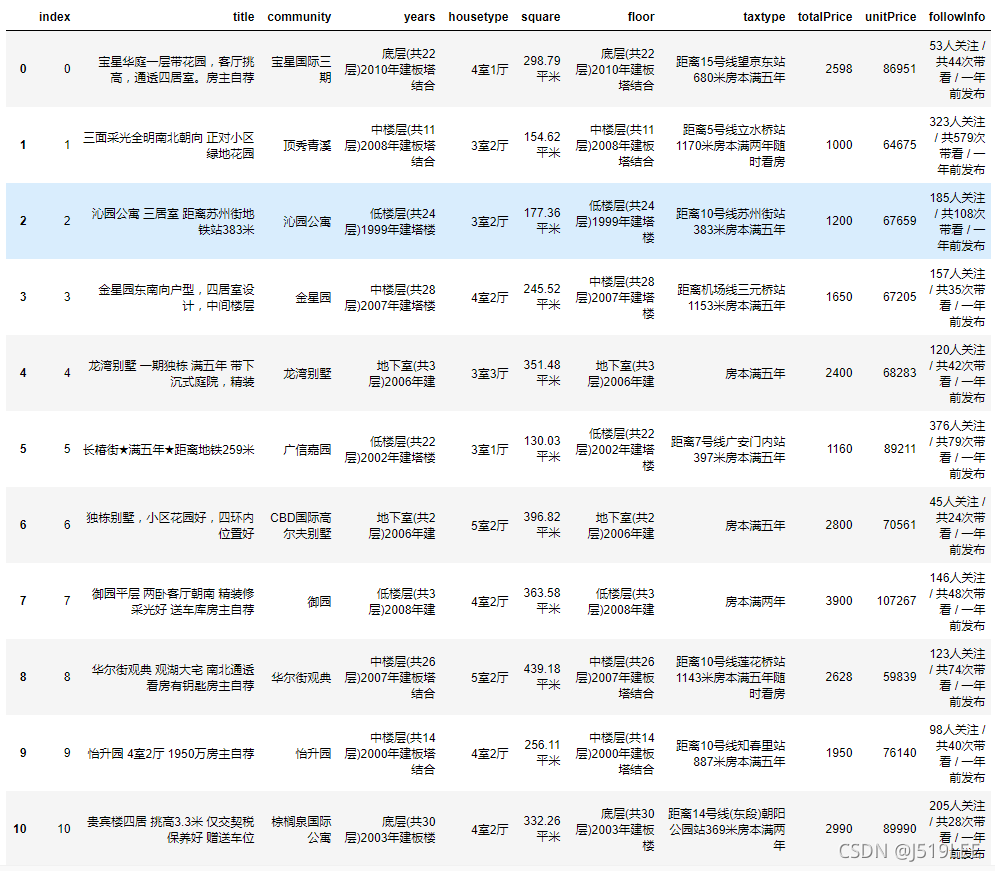
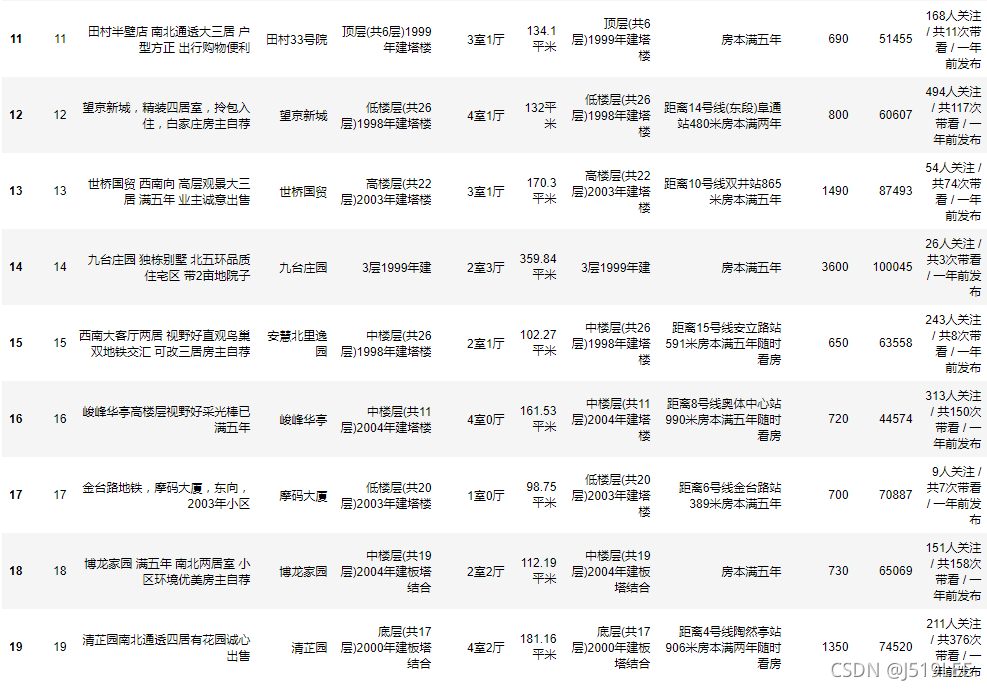
house.csv - 房源信息
‘index’ : 编号
‘title’ : 标题
‘community’ :小区
‘years’ :楼层/建筑年代
‘housetype’ :户型
‘square’:平米数
‘floor’:楼层/建筑年代
‘taxtype’ :房子标记信息
‘totalPrice’:总价
‘unitPrice’:单价
‘followInfo’:多少人关注/带看/发布时间
# 所有小区信息
community=pd.read_csv('community_describe.csv')
community.head()
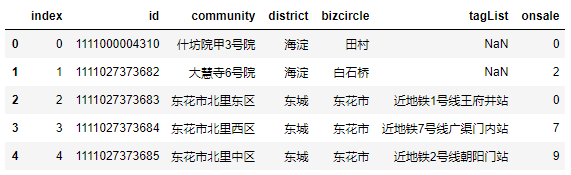
community_describe.csv - 小区信息
‘index’ :索引
‘id’ :编号
‘community’ :小区名
‘district’ :行政区域
‘bizcircle’ :商圈
‘tagList’ : 地铁站
‘onsale’ :是否在售(房源数量)
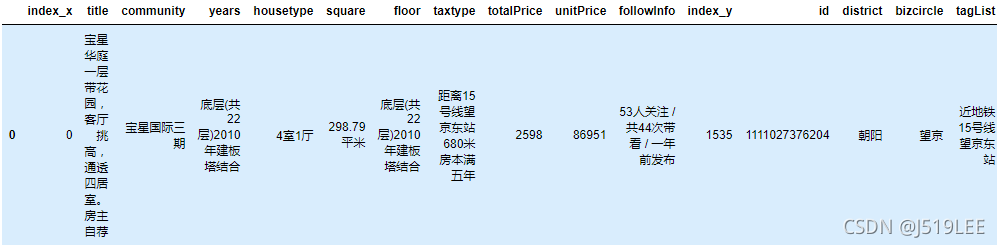
# 合并小区信息和房源信息表,可以获得房源更详细的地理位置
house_detail=pd.merge(house,community,on='community')
# 打印数据
house_detail.head(1)
# len(house_detail)
# 问题1:数据读取及描述性分析,得到房价及平米的数值型描述
# 使用表1:house
# 思考过程:房价数值型(没问题)
# 平米:(square 279.88平米)
# 数据预处理1:把square中的值(平米)两个字去掉 - apply()
# select_data参数: 128.22平米
# str参数:平米
def data_ad(select_data,str):
if str in select_data:
return float(select_data[0:select_data.find(str)])
else:
return None
# 处理房屋面积数据
house['square']=house['square'].apply(data_ad,str='平米')
# 查看数据
house.head(1)

house['square'].max()
2623.28
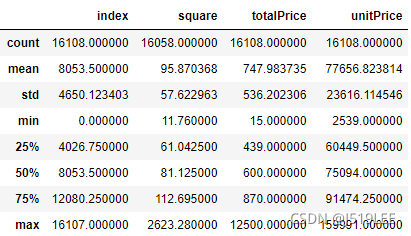
house.describe()
户型的种类
# 户型的种类,以及每个户型都有多少套房源
house.housetype.value_counts()
2室1厅 6582
3室1厅 2534
1室1厅 2472
3室2厅 1424
2室2厅 1018
1室0厅 620
4室2厅 496
4室1厅 181
2房间1卫 100
5室2厅 92
1房间1卫 87
1室2厅 64
4室3厅 55
3房间1卫 44
3室0厅 35
2室0厅 34
车位 32
6室2厅 29
5室3厅 22
联排别墅 19
1房间0卫 16
5室1厅 15
6室3厅 13
独栋别墅 12
3室3厅 11
4室0厅 10
叠拼别墅 10
4房间2卫 9
双拼别墅 9
2房间2卫 6
4房间1卫 6
6室1厅 5
5室4厅 4
7室3厅 3
3房间2卫 3
5室5厅 3
6室4厅 3
2房间0卫 2
5房间3卫 2
9室4厅 2
6房间2卫 2
3房间3卫 2
6房间4卫 2
7室2厅 2
4房间3卫 2
2室3厅 2
6房间3卫 1
5室0厅 1
7室1厅 1
8室2厅 1
8室4厅 1
8房间5卫 1
5房间2卫 1
4室4厅 1
3室4厅 1
7室0厅 1
2房间3卫 1
6室0厅 1
Name: housetype, dtype: int64
数据预处理2:删除车位信息
# 删除车位信息
# 操作的表:house
# 操作的字段:housetype
car = house[house.housetype.str.contains('车位')]
car.shape[0]
# 删掉这些数据:drop()
# inplace=True参数: 直接替换原数组,没有返回值
house.drop(car.index,inplace=True)
car.shape
(32, 11)
car=house[house.housetype.str.contains('车位')]
# 记录中共有车位
car.shape[0]
0
数据分析1:价格最高的5个别墅
# 思路:1.先找到所有别墅的数据
# 2.按照总价降序排列,获取前5条(sort_values())
villa = house[house.housetype.str.contains('别墅')]
# 记录中共有别墅?
villa.shape[0]
# 排序
# by参数:指定排序的字段
# ascending: False降序
villa.sort_values(by='totalPrice',ascending=False).head(5)

数据预处理3:删除别墅信息
house.drop(villa.index,inplace=True)
# 现在还剩下?条记录
house.shape[0]
16026
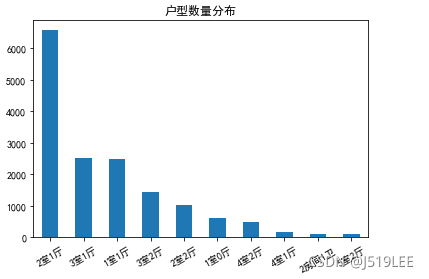
数据分析2:找出数据中的住房户型分布
# 思路: 统计出每个户型的房源数量(value_counts()),再进行可视化
house.housetype.value_counts()
2室1厅 6582
3室1厅 2534
1室1厅 2472
3室2厅 1424
2室2厅 1018
1室0厅 620
4室2厅 496
4室1厅 181
2房间1卫 100
5室2厅 92
1房间1卫 87
1室2厅 64
4室3厅 55
3房间1卫 44
3室0厅 35
2室0厅 34
6室2厅 29
5室3厅 22
1房间0卫 16
5室1厅 15
6室3厅 13
3室3厅 11
4室0厅 10
4房间2卫 9
2房间2卫 6
4房间1卫 6
6室1厅 5
5室4厅 4
5室5厅 3
6室4厅 3
3房间2卫 3
7室3厅 3
6房间2卫 2
9室4厅 2
4房间3卫 2
5房间3卫 2
7室2厅 2
2室3厅 2
3房间3卫 2
2房间0卫 2
6房间4卫 2
8房间5卫 1
5房间2卫 1
7室1厅 1
8室2厅 1
6室0厅 1
8室4厅 1
4室4厅 1
3室4厅 1
7室0厅 1
2房间3卫 1
6房间3卫 1
5室0厅 1
Name: housetype, dtype: int64
# 可视化绘制
house_type = house.housetype.value_counts()
house_type.head(10).plot(kind='bar',title='户型数量分布',rot=30)
plt.show()
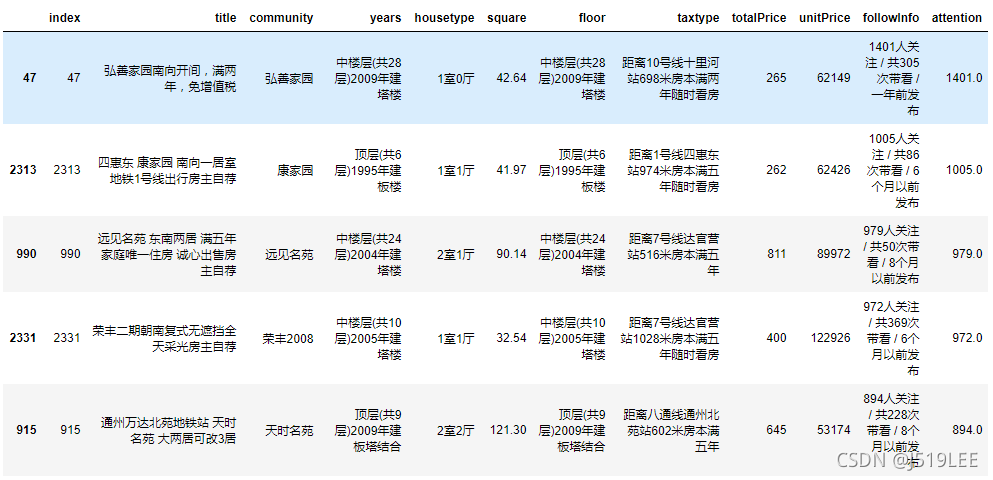
数据分析3:找出关注人数最多的五套房子
# 思路
# 1.将关注人数提取出来,增加新的一列 attention (不能草率删除,因为里面还有其他数据)
# 2.按照attention降序排列
house['attention'] = house['followInfo'].apply(data_ad,str='人关注')
house.head(5)
data1=house.sort_values(by='attention',ascending=False).head()
data1
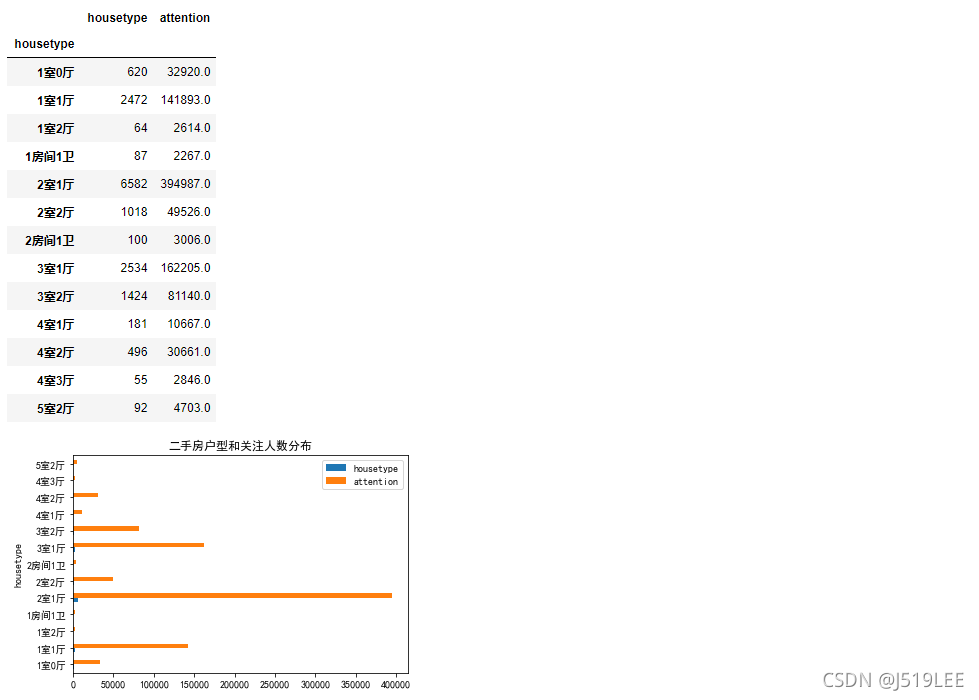
数据分析4:户型和关注人数分布
# 思路:每个户型共有多少关注人数
# 1.根据户型(housetype)进行分组,再根据关注人数(attention)进行聚合
# 2.可视化
type_interest_group = house.groupby(house['housetype']).agg({'housetype':'count','attention':'sum'})
type_interest_group
interest_sort = type_interest_group[type_interest_group['housetype']>50]
interest_sort.plot(kind='barh',title='二手房户型和关注人数分布')
interest_sort
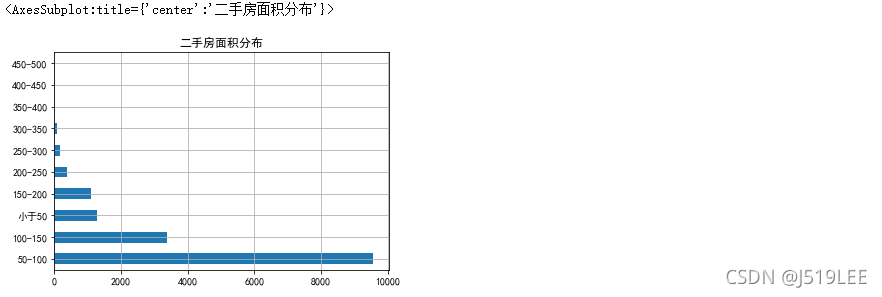
数据分析5:面积分布
# 面积分布
# 思考:指定区间范围内的房源数量分布,比如目标:50-100平米有多少套房子,100-150平米的有多少
# 套房子
# 如何拿到多个区间的数据呢? 对数据进行分箱操作 - pd.cut()
# bins参数:指定区间范围
area_level=[0,50,100,150,200,250,300,350,400,450,500]
label_level=['小于50','50-100','100-150','150-200','200-250','250-300','300-350','350-400','400-450','450-500']
area_cut = pd.cut(house['square'],bins=area_level, labels=label_level)
area_cut
area_cut.value_counts().plot(kind='barh',rot=0,grid=True,title='二手房面积分布')
house_detail.head(2)

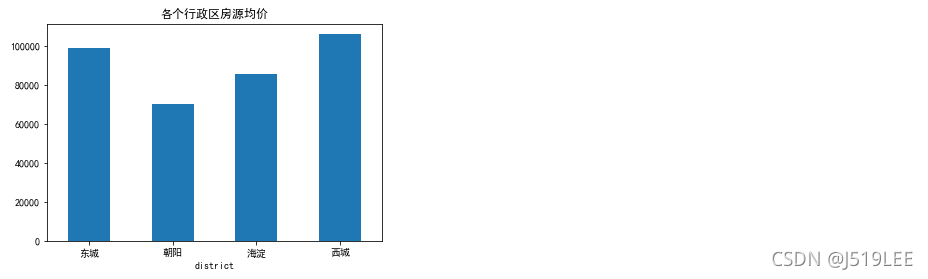
数据分析6:各个行政区房源单价均价
# 确定使用的表: house_detail
# 思路:根据行政区域进行分组,根据单价求出平均值
house_unitPrice = house_detail.groupby('district')['unitPrice'].mean()
house_unitPrice
house_unitPrice.plot(kind='bar',rot=0,title='各个行政区房源均价')
plt.show()
各个行政区房源价钱箱线图绘制
import seaborn as sns
price = house_detail[['district','unitPrice']]
# price
sns.boxplot(x='district',y='unitPrice',data=price)
plt.show()
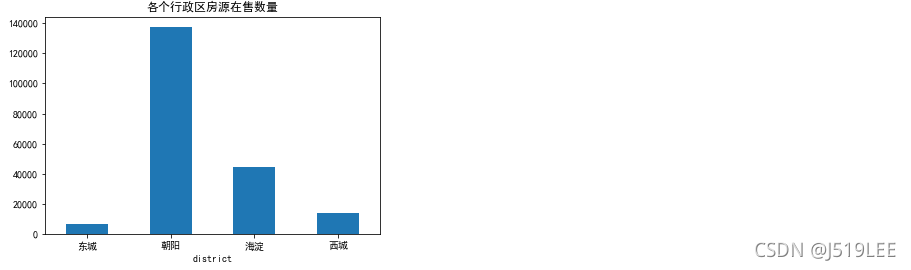
各个行政区房源在售数量
# 思路:根据行政区域进行分组,根据在售数量(onsale)进行求和聚合
house_onsale = house_detail.groupby('district')['onsale'].sum()
house_onsale.plot(kind='bar',rot=0,title='各个行政区房源在售数量')
plt.show()
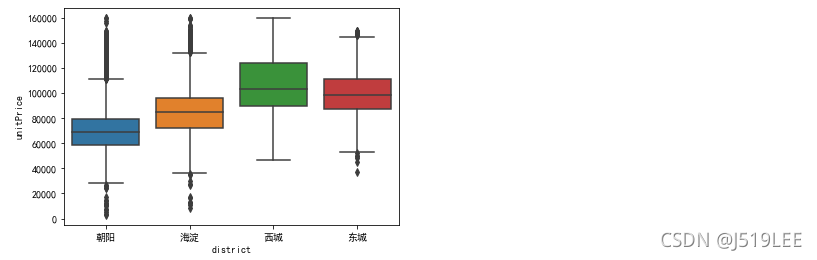
数据分析7:各个行政区的房源总价对比
# 思路:根据行政区域分组,根据总价平均值
# 直接取出数据,画箱线图
price = house_detail[['district','totalPrice']]
sns.boxplot(x='district',y='totalPrice',data=price)
plt.ylim((0,6000))
plt.show()
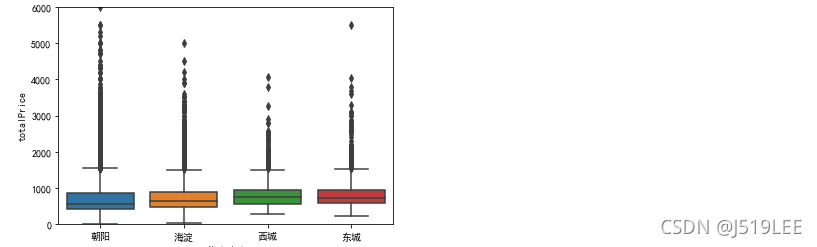
通过箱型图看到,各大区域房屋总价中位数都都在1000万以下,且房屋总价离散值较高
数据分析8:按照地铁信息对各个区域每平米均价排序,柱形图绘制
# 思路:目标找到每个地铁站附近房源的均价,比如:双井站 均价是xxx元 前门站 均价 xxx 元
# 根据地铁相关字段进行分组,然后再求单价的平均值,再排序
bizcircle_unitPrice = house_detail.groupby('bizcircle')['unitPrice'].mean().sort_values(ascending=False)
bizcircle_unitPrice
# # bizcircle_unitPrice.to_csv('bizcircle_unitPrice.csv')
bizcircle_unitPrice.head(15).plot(kind='barh',title='各个区域均价分布',rot=0)
plt.legend(['均价'])
plt.show()
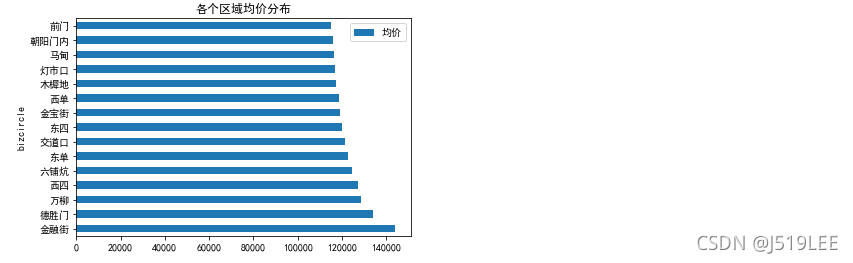
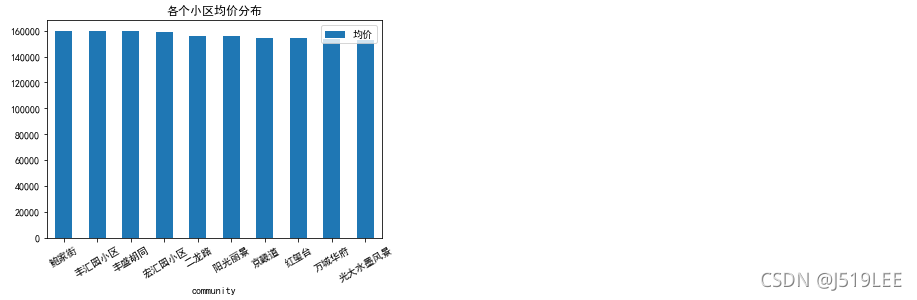
数据分析9:按小区均价排序
# 思考:按照小区进行分组(groupby()),再按照单价求平均值(mean()), 再排序(sort_values())
community_unitPrice = house_detail.groupby('community')['unitPrice'].mean().sort_values(ascending=False)
community_unitPrice.head(10).plot(kind='bar',title='各个小区均价分布',rot=30)
plt.legend(['均价'])
plt.show()
综合:紧邻望京地铁站,三室一厅,400万-500万,大于80平米的房子
第一步:找出望京附近的房屋信息
# 先找出 商圈(bizcircle)列的数据中包含 "望京" 这个字符串的数据
myhouse = house_detail[house_detail.bizcircle.str.contains('望京')]
len(myhouse)
# myhouse.head(2)
896
查看分布情况
house_type=myhouse['housetype'].value_counts()
house_type.head(10).plot(kind='bar',title='户型数量分布',rot=30)
house_type.head(10)
2室1厅 230
3室2厅 155
2室2厅 134
1室1厅 117
3室1厅 108
4室2厅 55
4室1厅 25
1室0厅 25
2房间1卫 13
5室2厅 8
Name: housetype, dtype: int64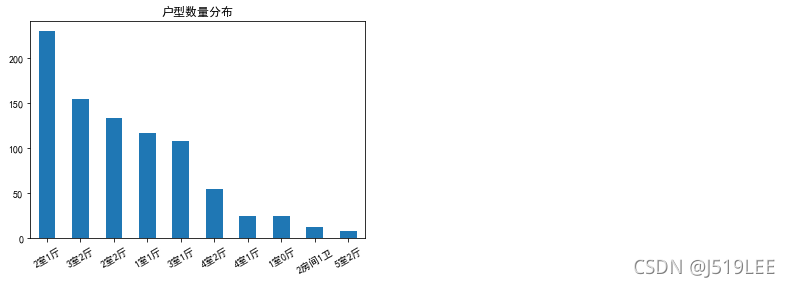
第三步:找到三室一厅的房源信息以及400万-500万,大于80平米的房源信息
# 1 找到三室一厅的房源信息
# 思路:从myhouse中筛选 housetype列中字符串包含 '3室1厅' 的数据
myhouse = myhouse[myhouse.housetype.str.contains('3室1厅')]
len(myhouse)
108
# 2 房屋总价400万-500万之间
# 思路: totalPrice > 400 & totalPrice < 500
myhouse = myhouse[(myhouse['totalPrice']>400)&(myhouse['totalPrice']<500)]
# myhouse.head()
len(myhouse)
7
myhouse
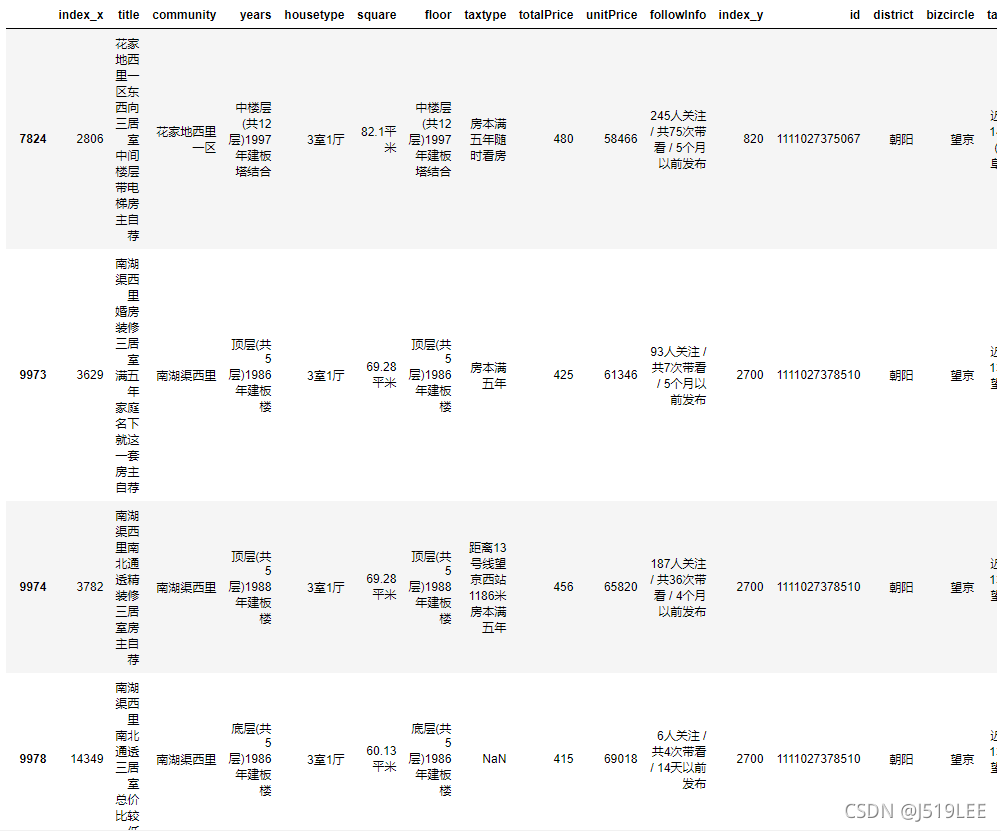
# 处理房屋面积数据
myhouse['square']=myhouse['square'].apply(data_ad,str='平米')
# 3 房屋面积大于80平米
myhouse = myhouse[myhouse.square>80]
len(myhouse)
# myhouse.head(1)
2
myhouse.head()


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)