深度学习笔记(7)——注意力机制和transformer
注意力机制和Transformer
注意力机制和transformer
引入注意力机制的原因:RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片 t的计算依赖 t-1 时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
CNN和RNN只建模了输入信息的局部依赖关系,而注意力机制可以处理变长的向量序列
全连接层?可以处理全局信息,但是无法处理变长问题
自注意力模型: 连接权重αi,j\alpha_{i,j}αi,j由注意力机制动态生成,算两个特征之间的相似度作为权重
注意力的类型:
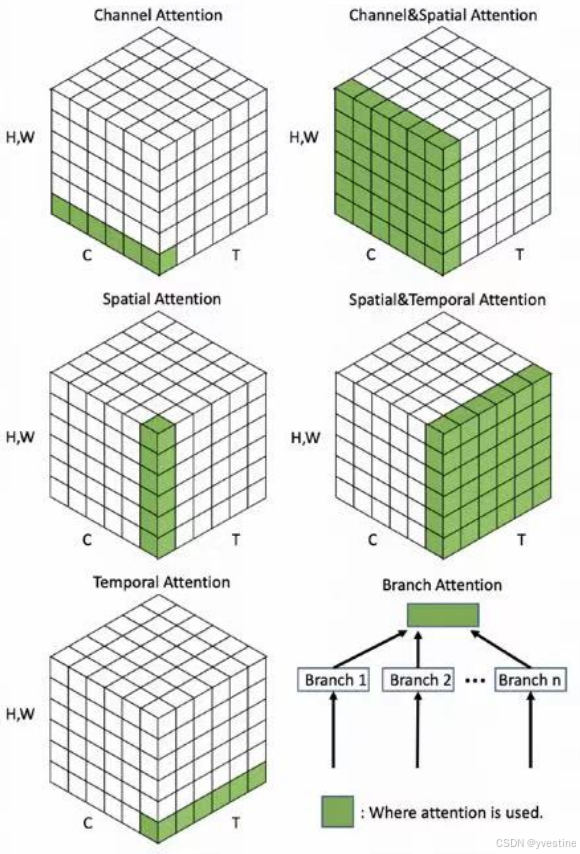
- channel attention:通道注意力机制,通过学习的方式,自适应地调整每个通道的权重,使模型更加关注对分类任务更重要的特征,从而提高模型的性能。
- spatial attention:空间注意力机制,通过学习的方式,自适应地调整每个像素点的权重,使模型更加关注对分类任务更重要的区域,从而提高模型的性能。
- temporal attention:时间注意力机制,通过学习的方式,自适应地调整每个时间步的权重,使模型更加关注对分类任务更重要的时间步,从而提高模型的性能。
- channel&spatial attention:通道和空间注意力机制,通过学习的方式,自适应地调整每个通道和每个像素点的权重,使模型更加关注对分类任务更重要的特征和区域,从而提高模型的性能。
- spatial&temporal attention:空间和时间注意力机制,通过学习的方式,自适应地调整每个像素点和每个时间步的权重,使模型更加关注对分类任务更重要的区域和时间步,从而提高模型的性能。
- branch attention:分支注意力机制,通过学习的方式,自适应地调整每个分支的权重,使模型更加关注对分类任务更重要的分支,从而提高模型的性能。
没有channel&temporal attention和channel&spatial&temporal attention
self-attention
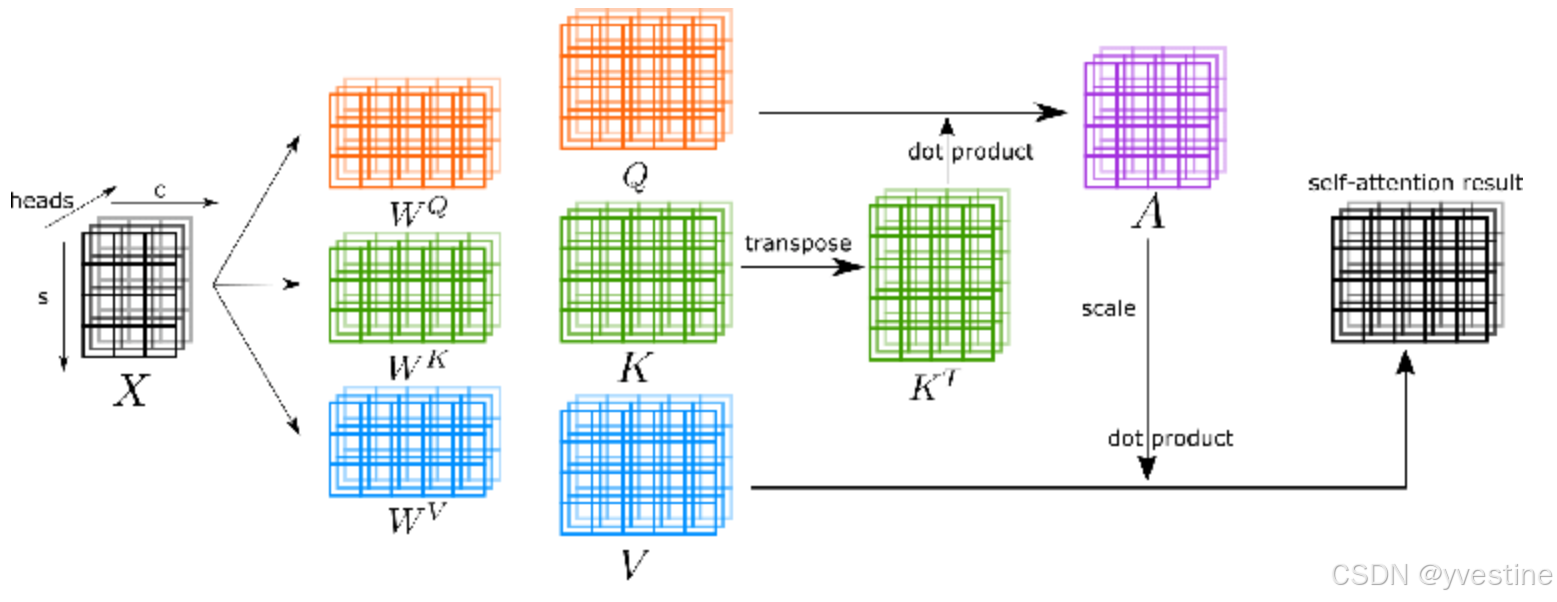
自注意力的QKV:
Q:Query,查询向量,Q=XWQQ=XW_QQ=XWQ
K:Key,键向量,K=XWKK=XW_KK=XWK
V:Value,值向量,V=XWVV=XW_VV=XWV
Q、K、V其实都是从同样的输入矩阵X线性变换而来的,self-attention中的self就是值得是Q、K、V的输入相同,都是X本身。,其中WQ,WK,WVW_Q,W_K,W_VWQ,WK,WV是三个可训练的参数矩阵,Attention不直接使用X,而是使用经过矩阵乘法生成的这三个矩阵,因为使用三个可训练的参数矩阵,可增强模型的拟合能力。\
计算Q和K里的每个事物的相似度,再做softmax
H=Vsoftmax(QKTdk)H=Vsoftmax(\frac{QK^T}{\sqrt{d_k}})H=Vsoftmax(dkQKT)
除以dk\sqrt{d_k}dk:使差额减小,让softmax出的概率不至于那么离谱
多头注意力
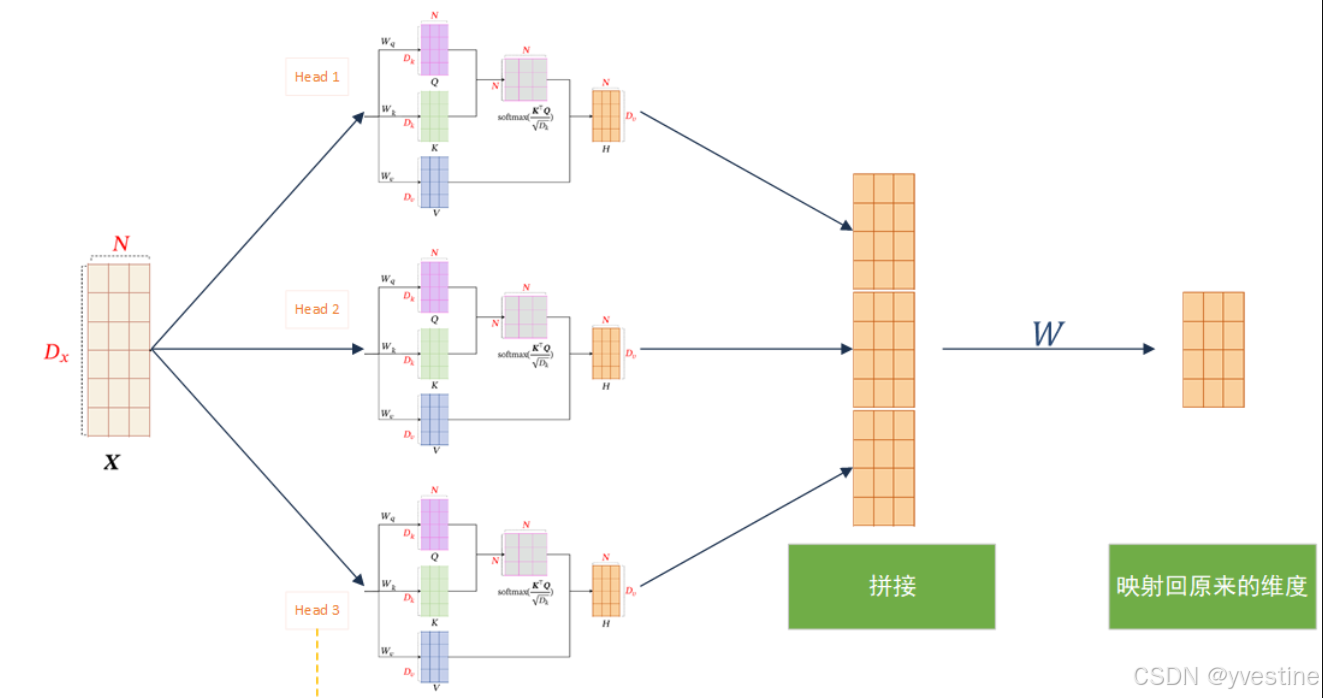
多头注意力(Multi-Head Attention)是一种在Transformer模型中被广泛采用的注意力机制扩展形式,它通过并行地运行多个独立的注意力机制来获取输入序列的不同子空间的注意力分布,从而更全面地捕获序列中潜在的多种语义关联。
Transformer
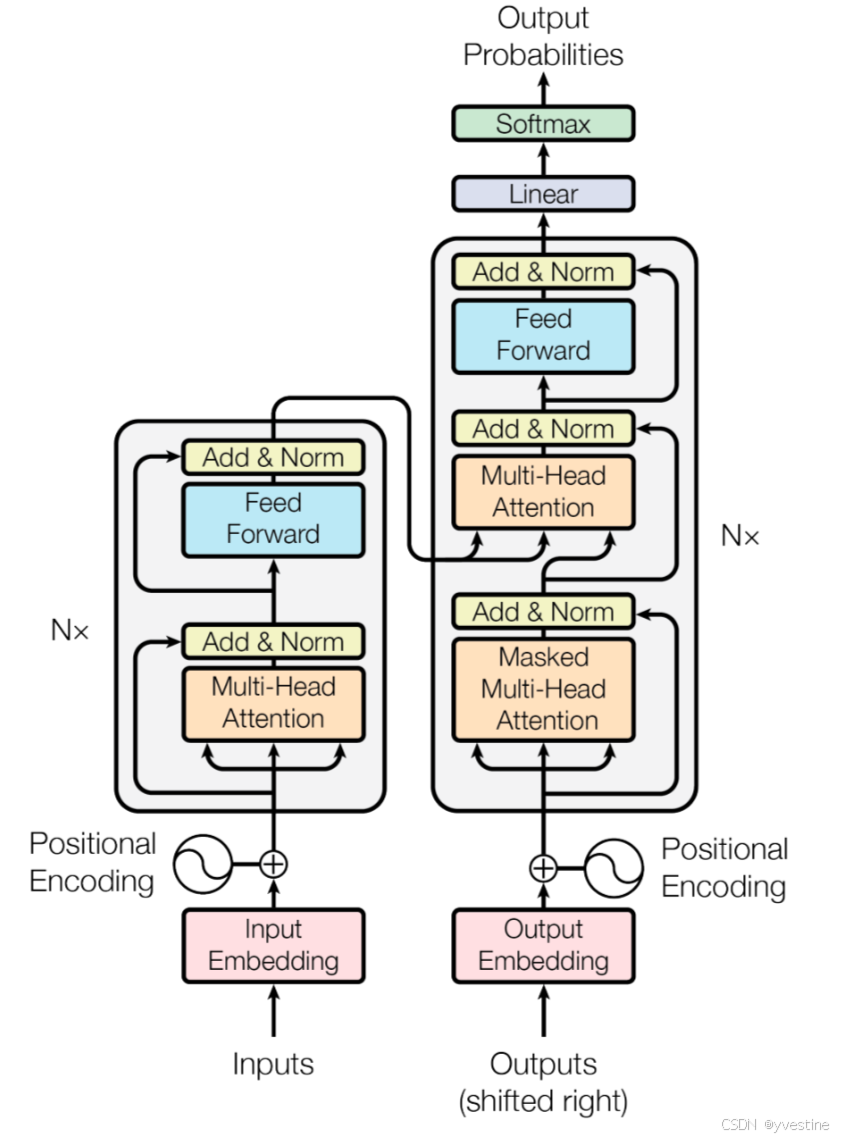
- 使用Embedding嵌入算法将每个输入单词转换为向量。列表的大小是我们可以设置的超参数——基本上它是我们训练数据集中最长句子的长度。
- 在输入序列中嵌入单词之后,它们中的每一个都流过编码器的两层中的每一层(分别是self-attention层和Feed Forward层)。每个位置的单词在Encoders编码器中流过自己的路径。在multi-head attention中,这些路径之间存在依赖关系,需要再加一个position encoding。然而,Feed Forward前馈层没有这些依赖关系,因此各种路径可以在流过前馈层的同时并行执行。
Encoder:全局语义建模self-attention。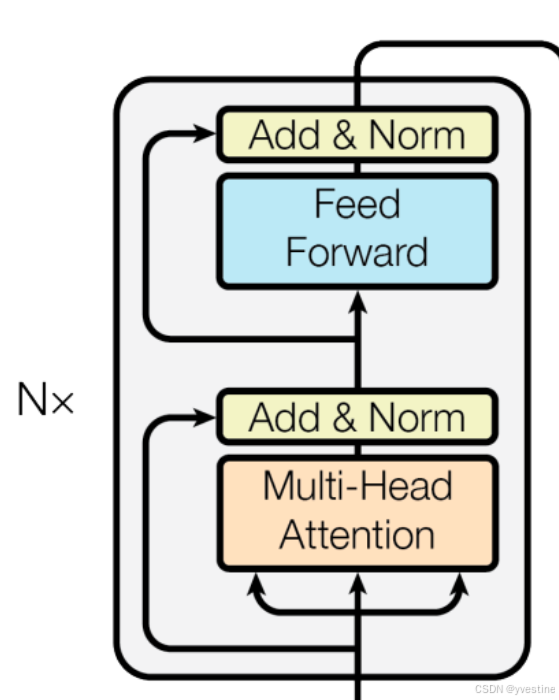
- Self-Attention:允许查看其他位置以寻找有助于更好地编码该单词的线索。
- Add & Norm:normalization可以稳定训练,并正则化,防止过拟合。addition是残差连接,防止梯度消失,可以训练更深的网络。
- 多头注意力:扩展了模型关注不同位置的能力,使用多头注意力,我们不仅有一个,而且还有多组查询/键/值权重矩阵(Transformer 使用八个注意力头,所以我们最终每个编码器/解码器都有八个集合),这些集合中的每一个都是随机初始化的。然后,在训练之后,每个集合用于将输入嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
- 使用位置编码表示序列的顺序,转换器为每个输入嵌入添加了一个向量。这些向量遵循模型学习的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离
- 每个编码器中的每个子层(self-attention)在其周围都有一个残差连接,然后是一个层归一化步骤。(即add&normalization)
- (masked multi-head attention)操作方式与编码器中的方式略有不同:在解码器中,自注意力层只允许关注输出序列中较早的位置(即逐个单词查看,看不到后面的)。这是通过在 self-attention 计算中的 softmax 步骤之前masking屏蔽未来位置来完成的。

训练和测试阶段:t时刻只能看到t-1时刻及之前的信息 - Decoder里面也有一个multi-head attention,它的Q,K来自于左边的encoder,V来自于下边的masked multi-head attention.
- 最终的线性和 Softmax 层:softmax 层将这些分数转化为概率(全部为正,全部加起来为 1)。选择概率最高的单元格,并生成与其关联的单词作为该时间步的输出。
重点:
transformer的encoder一侧模型可以看到所有时间步,为Representation,输入为input tokens,输出是hidden state
decoder一侧模型只能看到之前的时间步,右侧时间步被mask掉,为Generation,输入为output tokens and hidden states,输出为 output tokens

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)