【DL】深度学习优化方法:SGD、SGDM、Adagrad、RMSProp、Adam
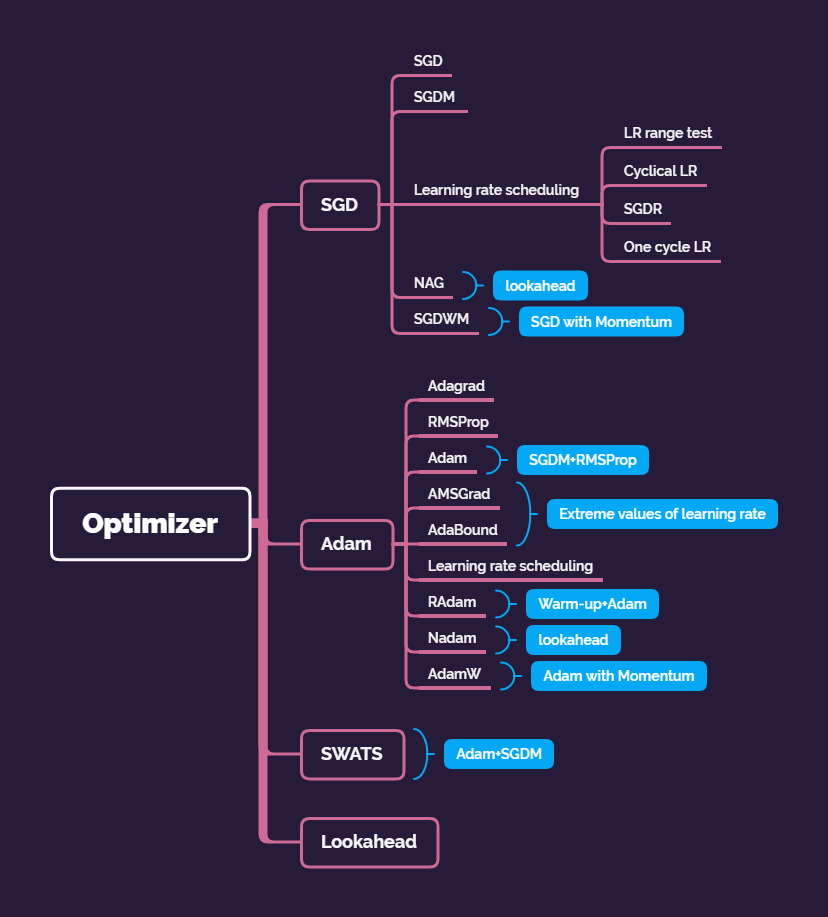
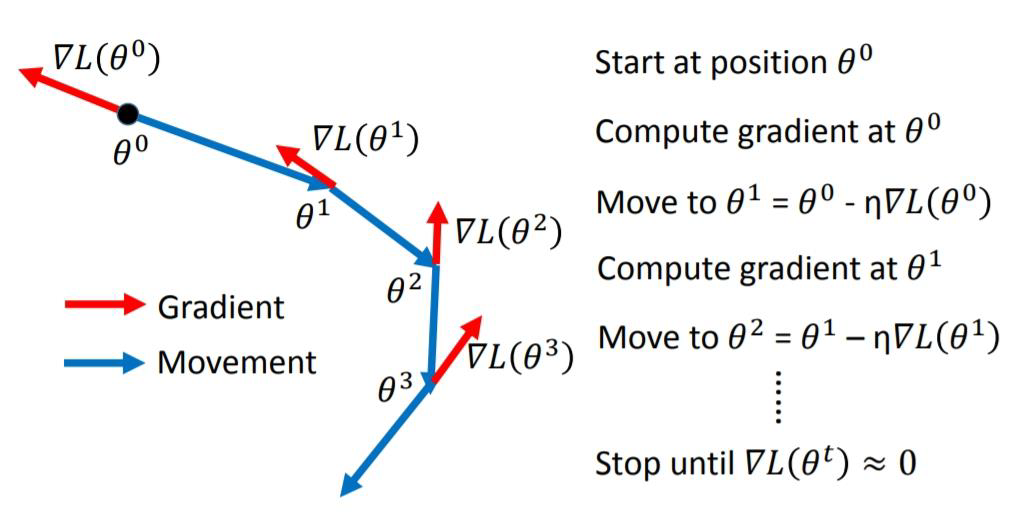
Gradient Descent1. 算法框架2. 理论原理假设参数θ\thetaθ是二维的,损失函数在(a,b)(a,b)(a,b)处的一阶泰勒展开,L(θ)=L(a,b)+∂L(a,b)∂θ1(θ1−a)+∂L(a,b)∂θ2(θ2−b)+o(θ1−a)+o(θ2−b)L(\theta)=L(a,b)+\frac{\partial L(a,b)}{\partial \theta_1}...
Gradient Descent
1. 算法框架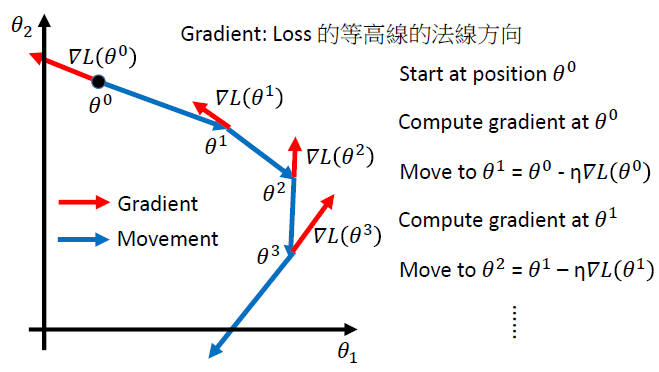
2. 理论原理
假设参数 θ \theta θ是二维的,损失函数在 ( a , b ) (a,b) (a,b)处的一阶泰勒展开,
L ( θ ) = L ( a , b ) + ∂ L ( a , b ) ∂ θ 1 ( θ 1 − a ) + ∂ L ( a , b ) ∂ θ 2 ( θ 2 − b ) + o ( θ 1 − a ) + o ( θ 2 − b ) L(\theta)=L(a,b)+\frac{\partial L(a,b)}{\partial \theta_1}(\theta_1-a)+\frac{\partial L(a,b)}{\partial \theta_2}(\theta_2-b)+o(\theta_1-a)+o(\theta_2-b) L(θ)=L(a,b)+∂θ1∂L(a,b)(θ1−a)+∂θ2∂L(a,b)(θ2−b)+o(θ1−a)+o(θ2−b)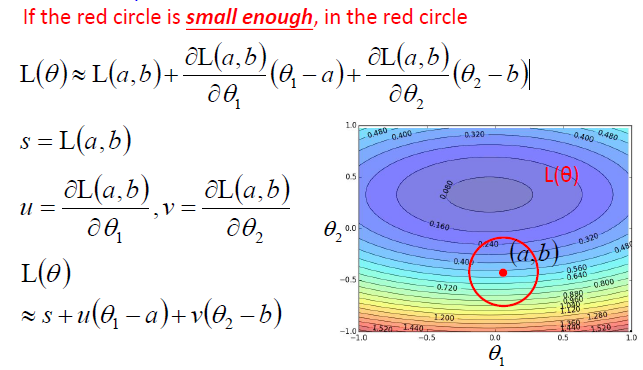

3. 优化策略
3.1 调整学习率
- 不同学习率下损失函数随迭代次数的变化:太小收敛慢,太大不收敛
- 优化策略
- 简单且合理的想法:每隔几步就把学习率降低一些,开始时离目标很远,使用较大的学习率,快要接近目标时减少学习率,比如 η t = η / t + 1 \eta^t=\eta/\sqrt{t+1} ηt=η/t+1;
- 不存在一个one-size-fit-all的学习率,不同的参数需要选择不同的学习率。
3.1 特征缩放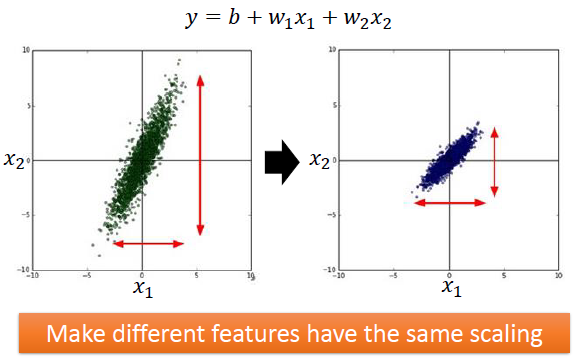
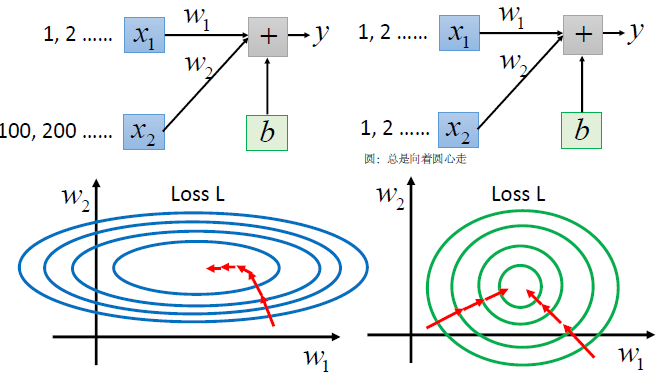
4. 优缺点
- 优点:
- 若损失函数为凸函数,能保证收敛到全局最优;若非凸,能收敛到局部最优;
- 缺点:
- 由于每轮迭代都需要在整个数据集上计算一次,所以批量梯度下降可能非常慢;
- 训练数较多时,需要较大内存;
- 批量梯度下降不允许在线更新模型,例如新增实例。
Stochastic Gradient Descent
- 每次迭代只使用一个数据
- 优点:
- 算法收敛速度快,可以在线更新;
- 有几率跳出一个比较差的局部最优而收敛到一个更好的局部最优甚至是全局最优;
- 缺点:
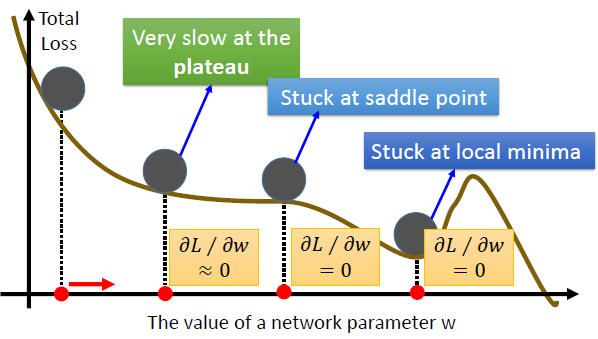
- 训练不稳定,容易收敛到局部最优,且容易被困在鞍点。
SGD with momentum
Momentum算法借用了物理中的动量概念,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。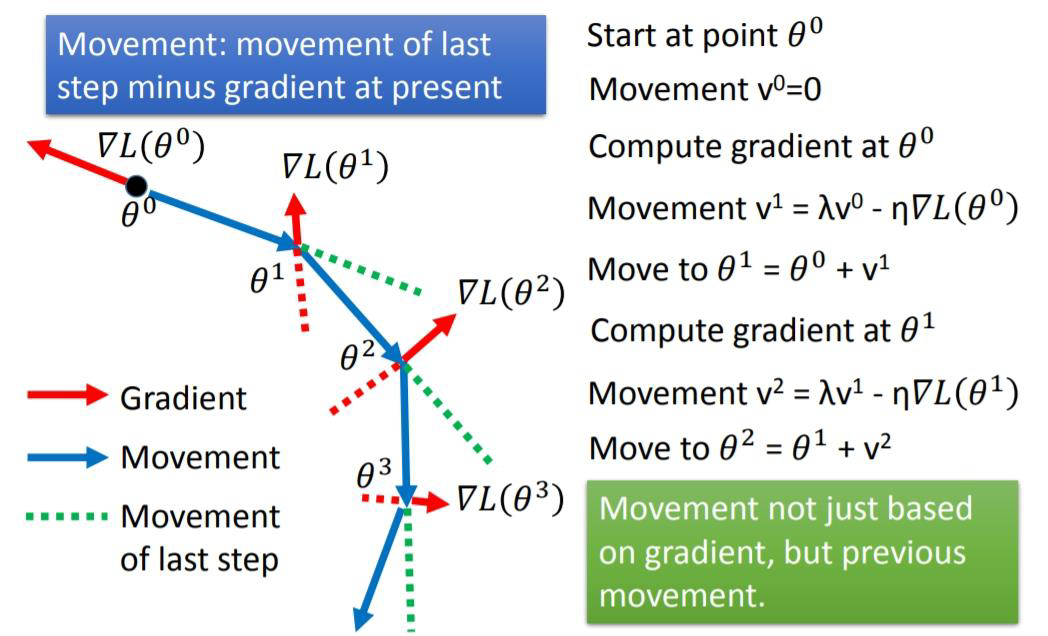

Momentum算法会观察历史更新方向 v t − 1 v_{t-1} vt−1,若当前负梯度方向与历史更新方向一致,表明当前样本不太可能是异常点,则会增强这个方向的梯度,若当前负梯度方向与历史更新方向不一致,则会一定程度的偏离负梯度方向.
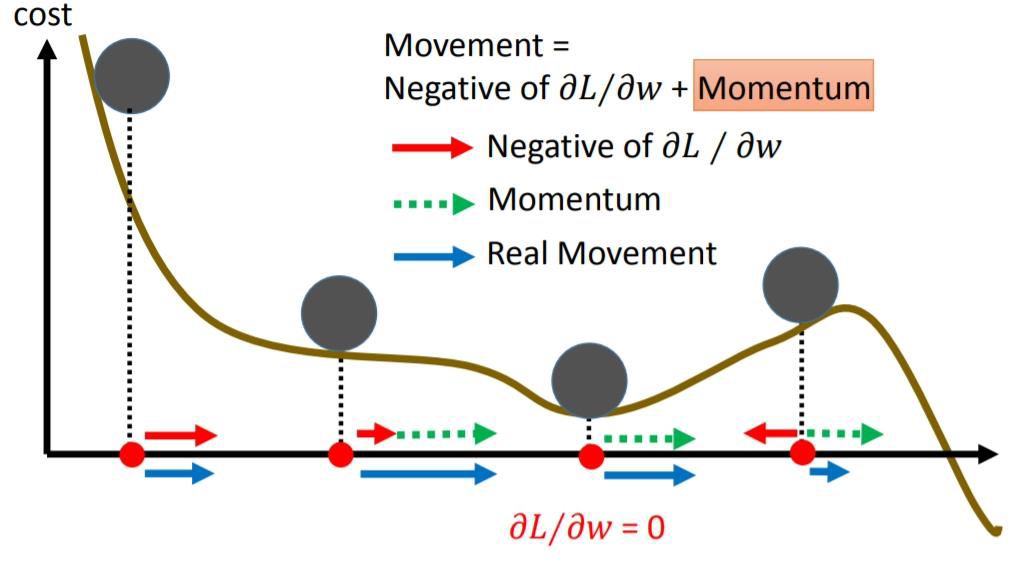
- 解决了梯度下降不稳定、容易陷入鞍点的缺点;可以加快训练速度,减小震荡。
Adagrad
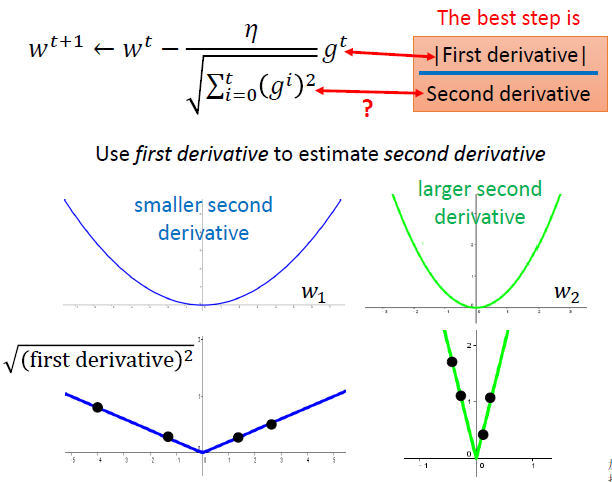
随着训练的不断进行,我们希望模型的更新趋于稳定,逐渐收敛,若是保持一个较大的学习率,会导致模型的损失函数在极值点不断震荡达不到收敛,而采用Adagrad将之前梯度的平方求和再开根号作为分母,会使得一开始学习率呈放大趋势,随着训练的进行学习率会逐渐减小。
1. 更新公式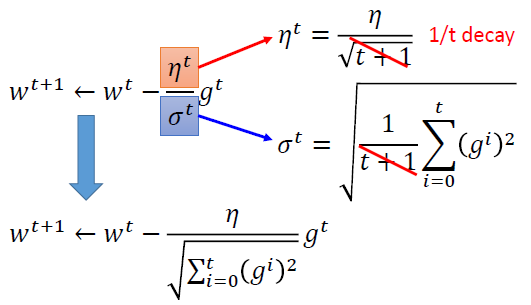
2. 学习率构造原理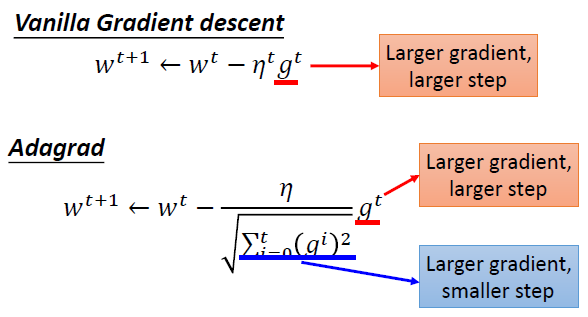
- 构造反差的效果
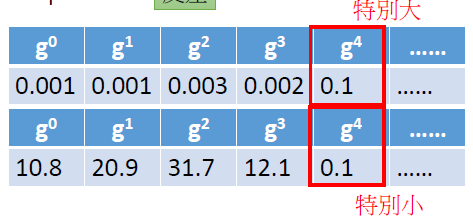
- 通过实例看出最优步长与一次微分成正比,与二次微分成反比,这里采用之前所有一次微分的均方根估计二次微分
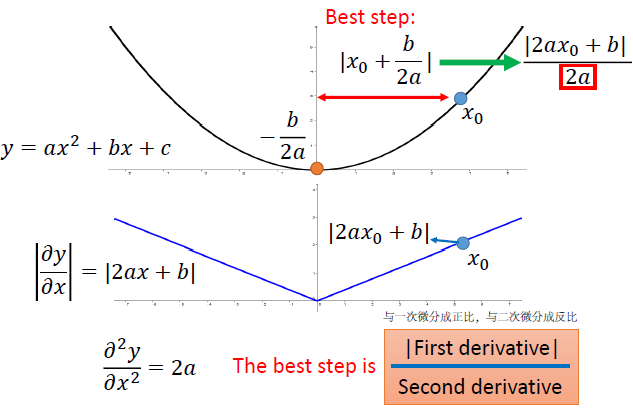
同一参数,可以通过比较其一次微分比较其距离最优值的距离;不同参数还需要考虑二次微分。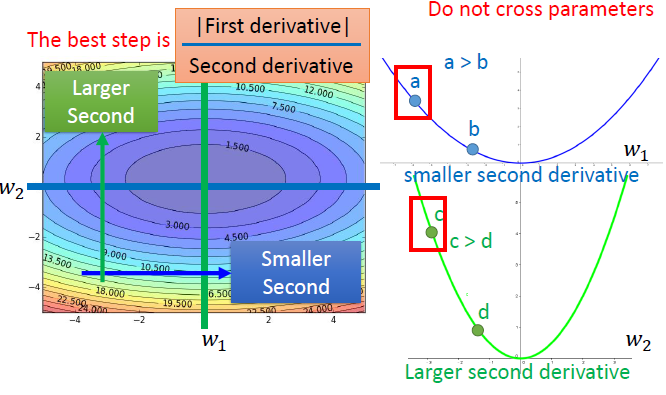
3. 优缺点
- 优点:
- Adagrad算法能够在训练中自动的对learning rate进行调整,对于出现频率较低参数采用较大的α更新;相反,对于出现频率较高的参数采用较小的α更新。因此,Adagrad非常适合处理稀疏数据。
- 缺点:
- 在训练的中后期,分母上梯度平方的累加将会越来越大,从而梯度趋近于0,使得训练提前结束。
RMSProp
Adagrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应的平均值
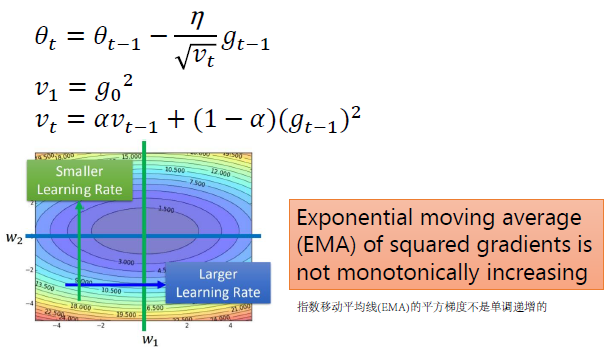
- 优:可缓解Adagrad算法学习率下降较快的问题;
- 缺:可能收敛到局部极小值
- 这一点可以不用太担心,因为对深层神经网络来说,目标函数具有局部极小值的概率很小:局部极小值意味着在每一个参数维度都是极小,假设在每一个维度极小值出现的概率为p,n个参数,出现局部极小概率为 p n p^n pn,对深层神经网络,n很大,这概率很小
Adam

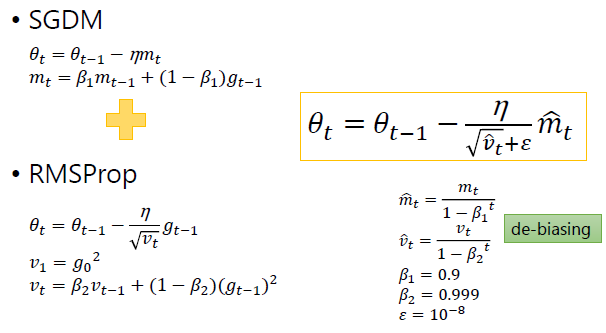
- m t , v t m_t,v_t mt,vt分别是对梯度的一阶矩估计和二阶矩估计,可以看做对期望 E [ g t ] , E [ g t 2 ] E[g_t],E[g_t^2] E[gt],E[gt2]的近似;
- m ^ t , v ^ t \hat{m}_t,\hat{v}_t m^t,v^t是对 m t , v t m_t,v_t mt,vt的校正,可以近似为对期望的无偏估计。
优点:
- 是一种自适应学习率的方法;
- 利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
- Adam 方法也会比 RMSprop方法收敛的结果要好一些。
比较Adam与SGDM
- Adam:训练快,Generalization Gap大,不稳定
- SGDM:训练慢,Generalization Gap小,收敛的稳、好
注:Adam的Generalization Gap较大,并不是说明Adam找到的是sharp minima,而SGDM找到的flat minima
Generalization Gap
Generalization Gap现象是指:使用大的batchsize训练网络会导致网络的泛化性能下降。
- 大的batchsize训练使得目标函数倾向于收敛到sharp minima(类似于local minima),sharp minima导致了网络的泛化性能下降;小的batchsize则倾向于收敛到一个flat minima
- sharp minima的存在是导致Generalization Gap出现的最重要原因
- 大的batchsize导致的Generalization Gap现象并不是过拟合造成的
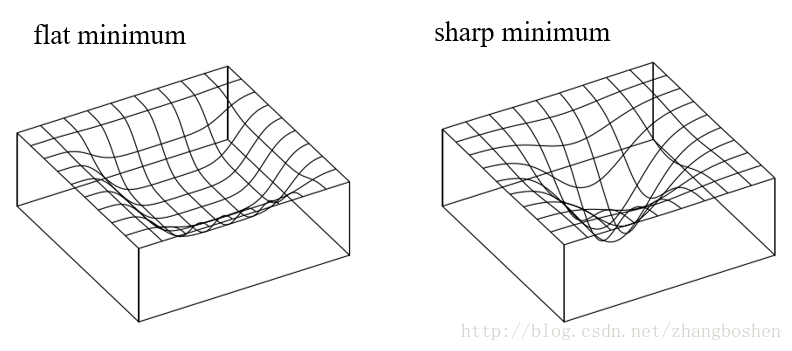
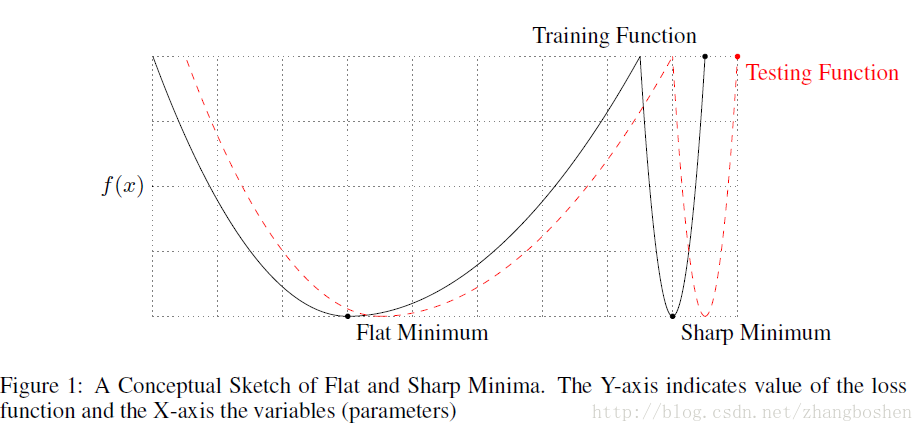
《On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima》-ICLR2017文章阅读
SWATS(2017)
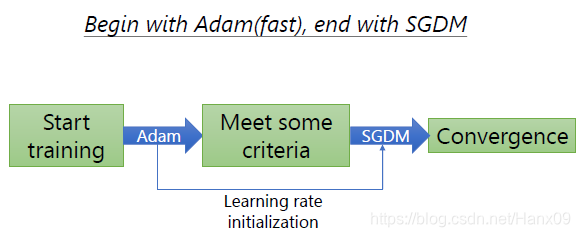
- 什么时候切换为SGDM
- 如何初始化SGDM的学习率
优化Adam
AMSGrad(2018)
Adam存在的问题
Adam的 m t m_t mt和SGDM的 m t m_t mt相同,这里关注自适应学习率 η v ^ t + ϵ \frac{\eta}{\sqrt{\hat{v}_t}+\epsilon} v^t+ϵη,取 β 1 = 0 \beta_1=0 β1=0, β 2 = 0.999 \beta_2=0.999 β2=0.999
{ θ t = θ t − 1 − η v ^ t + ϵ m ^ t m t = β 1 m t − 1 + ( 1 − β 1 ) g t − 1 , β 1 = 0 v t = β 2 v t − 1 + ( 1 − β 2 ) g t − 1 2 , β 2 = 0.999 \begin{cases}\theta_t=\theta_{t-1}-\frac{\eta}{\sqrt{\hat{v}_t}+\epsilon}\hat{m}_t\\ m_t=\beta_1m_{t-1}+(1-\beta_1)g_{t-1},\beta_1=0\\ v_t=\beta_2v_{t-1}+(1-\beta_2)g_{t-1}^2,\beta_2=0.999\end{cases} ⎩⎪⎨⎪⎧θt=θt−1−v^t+ϵηm^tmt=β1mt−1+(1−β1)gt−1,β1=0vt=β2vt−1+(1−β2)gt−12,β2=0.999 ⟹ \Longrightarrow ⟹ { θ t = θ t − 1 − η v ^ t + ϵ g t − 1 m ^ t = m t = g t − 1 v ^ t = 1 1 − β 2 v t = β 2 1 − β 2 v t − 1 + g t − 1 2 \begin{cases}\theta_t=\theta_{t-1}-\frac{\eta}{\sqrt{\hat{v}_t}+\epsilon}g_{t-1}\\ \hat{m}_t=m_t=g_{t-1}\\ \hat{v}_t=\frac{1}{1-\beta_2}v_t=\frac{\beta_2}{1-\beta_2}v_{t-1}+g_{t-1}^2\end{cases} ⎩⎪⎨⎪⎧θt=θt−1−v^t+ϵηgt−1m^t=mt=gt−1v^t=1−β21vt=1−β2β2vt−1+gt−12
当训练到最后,大部分的梯度都很小,不提供方向信息,只有小部分的梯度很大,提供方向信息
通过计算来看:假设开始时梯度比较小,均是1,999步后,梯度突然变大,为100000,之后又变为1。第二列为梯度对步长的影响。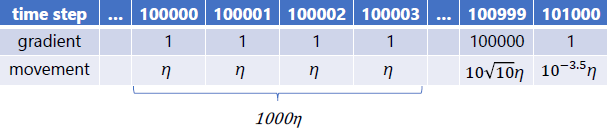
前面梯度较小,没有提供什么方向信息,但累加起来为 1000 η 1000\eta 1000η,相比于较大的梯度提供的信息 10 10 η 10\sqrt{10}\eta 1010η很大,但较大的梯度本提供了更多的方向信息,Adam却不能体现。
提出AMSGrad
{ θ t = θ t − 1 − η v ^ t + ϵ m t v ^ t = m a x ( v ^ t − 1 , v t ) \begin{cases} \theta_t=\theta_{t-1}-\frac{\eta}{\sqrt{\hat{v}_t}+\epsilon}m_t\\ \hat{v}_t=max(\hat{v}_{t-1},v_t) \end{cases} {θt=θt−1−v^t+ϵηmtv^t=max(v^t−1,vt)
- 减少了不含信息的梯度的影响(non-informative gradients)
- max记录最大的梯度,保证不会在经历很多很小的梯度后忘记之前较大的梯度
- 缺:学习率单调递减,类似Adagrad,使得训练提前结束
AdaBound(2019)
Adam/AMSGrad存在的问题
学习率会出现太大和太小两种极端情形。
AMSGrad只解决了学习率太大的情况。
提出AdaBound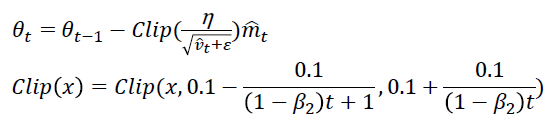
缺点:不是自适应的学习率。
RAdam

优化SGDM——寻找最优学习率
收敛慢:学习率是固定的。
##后续补充
LR range test
Cyclical LR
SGDR
One cycle LR
Lookahead
- k步向前,1步向后


Nesterov accelerated gradient (NAG)
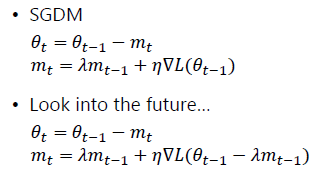
NAdam

提升优化性能的技巧
1. Shuffling
2. Dropout
3. Gradient noise
{ g t , i = g t , i + N ( 0 , σ t 2 ) σ t = c ( 1 + t ) γ \begin{cases} g_{t,i}=g_{t,i}+N(0,\sigma_t^2)\\ \sigma_t=\frac{c}{(1+t)^\gamma} \end{cases} {gt,i=gt,i+N(0,σt2)σt=(1+t)γc
4. Warm-up
5. Curriculum learning
6. Fine-tuning
7. Normalization
8. Regularization
优化器选择建议
SGDM
- 计算机视觉Computer vision
- 图像分类image classification
- segmentation
- 目标检测object detection
Adam
- 自然语言处理NLP
- 问答系统QA
- 机器翻译machine translation
- summary
- 语音合成Speech synthesis
- GAN
- 强化学习
On-line vs Off-line
- On-line:每一步能获取一对数据 ( x t , y ^ t ) (x_t,\hat{y}_t) (xt,y^t) / one pair of ( x t , y ^ t ) (x_t,\hat{y}_t) (xt,y^t) at a time step;
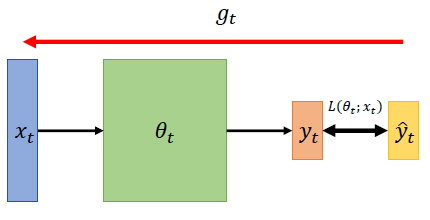
- Off-line:每一步能获取所有的数据 / pour all ( x t , y ^ t ) (x_t,\hat{y}_t) (xt,y^t) into the model at every time step。
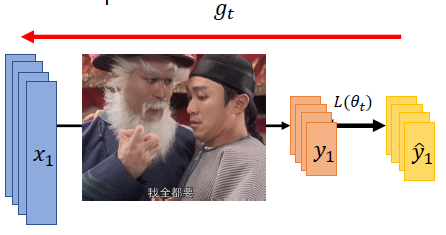
李宏毅2020深度学习
优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
An overview of gradient descent optimization algorithms

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)