深度学习-基于RNN的语言模型
输入一个词,RNN输出截止到目前为止,下一个最可能的词我 昨天 上学 迟到 了其中,s表示序列的开始,e表示序列的结束向量化:one hot 高维稀疏概率语言模型语言模型要求的输出是下一个最可能的词,我们可以让RNN计算词典中每个词是下一个词的概率,这样,概率最大的词就是下一个最可能的词。因此,神经网络的输出向量也是一个N维向量,向量中的每个元素对应着词典中相应的词是下一个词的概率。Softmax
·
输入一个词,RNN输出截止到目前为止,下一个最可能的词
我 昨天 上学 迟到 了
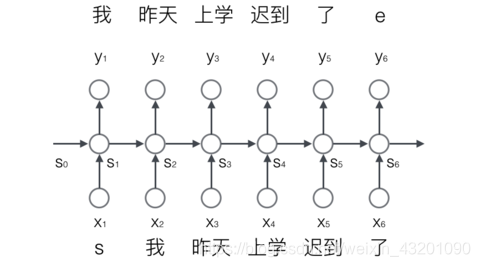 其中,s表示序列的开始,e表示序列的结束
其中,s表示序列的开始,e表示序列的结束
向量化:
-
one hot 高维稀疏
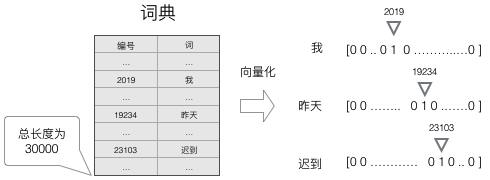
-
概率语言模型
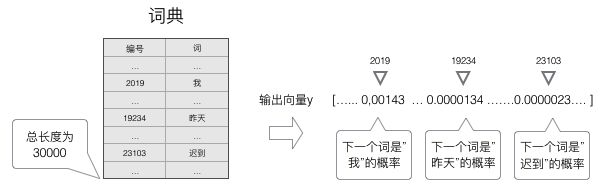
语言模型要求的输出是下一个最可能的词,我们可以让RNN计算词典中每个词是下一个词的概率,这样,概率最大的词就是下一个最可能的词。因此,神经网络的输出向量也是一个N维向量,向量中的每个元素对应着词典中相应的词是下一个词的概率。
Softmax层
Softmax函数
语言模型是对下一个词出现的概率进行建模
让神经网络输出概率:用softmax层作为神经网络的输出层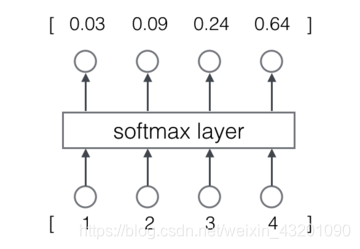
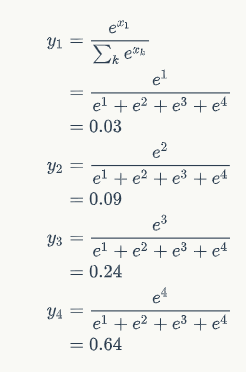
输出向量y = [y1,y2,y3,y4]
- 每一项为取值为0-1之间的正数
- 所有项的总和是1
语言模型的训练
获得 输入-标签 对:
| 输入x | 标签 y |
|---|---|
| s | 我 |
| 我 | 昨天 |
| 昨天 | 上学 |
| 上学 | 迟到 |
| 迟到 | 了 |
| 了 | e |
输入x向量化:one hot 表示字典
标签y向量化:one hot 下一个词是标签y的概率
交叉熵误差函数——模型优化

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)