LightGBM、XGBoost 与深度学习模型到底该选谁?一文讲透!
在选择机器学习模型时,LightGBM、XGBoost和深度学习各有其适用场景。LightGBM和XGBoost都是基于梯度提升树的集成学习算法,适用于结构化数据,具有训练速度快、可解释性强的特点,尤其在小样本场景下表现优异。LightGBM在训练速度和内存使用上优于XGBoost,适合大规模数据。深度学习模型则擅长处理非结构化数据(如图像、文本、声音),支持多模态融合,但训练速度较慢且可解释性差
·
📘LightGBM、XGBoost 与深度学习模型到底该选谁?一文讲透!
🧠 前言
在做机器学习任务时,你是不是经常遇到这样的困惑:
- 我该用 XGBoost 还是深度学习?
- LightGBM 和 XGBoost 有啥区别?
- 什么场景下深度学习是“无可替代”的?
- 我该怎么选模型?
别急,这篇文章就带你从原理、应用场景、优劣势到代码实战,一次性搞明白!
首先,让我们看一下整体脉络结构图: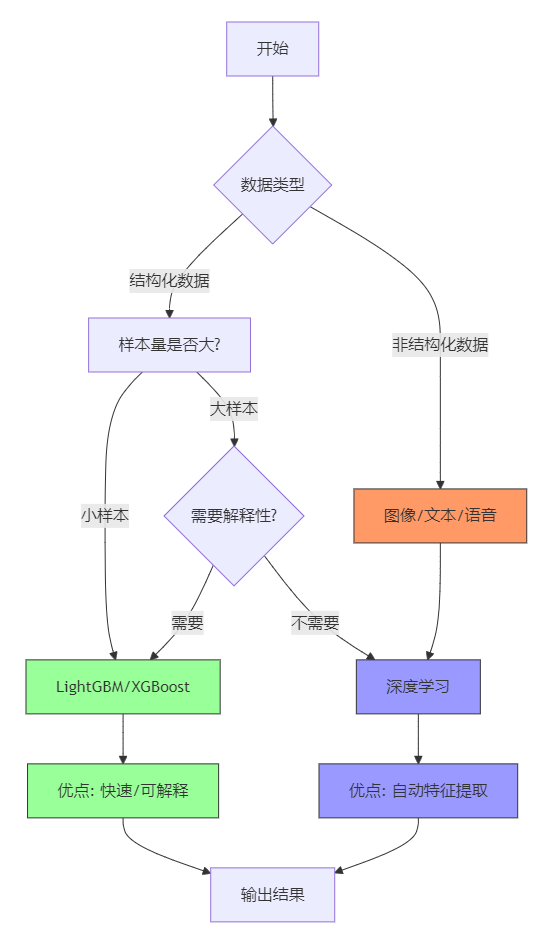
🌱 一、LightGBM 和 XGBoost 是什么?
它们都是 集成学习算法中的梯度提升树模型(GBDT)。
🚀 XGBoost(eXtreme Gradient Boosting)
- 更早提出,效率优于传统 GBDT
- 支持正则化,防止过拟合
- 使用预排序算法,适合小数据
⚡ LightGBM(Light Gradient Boosting Machine)
- 微软推出,优化了 XGBoost 的训练速度
- 支持 Leaf-wise 分裂策略,速度更快
- 对大规模、高维稀疏数据表现更优
🧩 二、和深度学习模型的核心区别是什么?
| 项目 | LightGBM / XGBoost(树模型) | 深度学习模型(神经网络) |
|---|---|---|
| 输入类型 | 表格型数据(结构化) | 图像、语音、文本、时序(非结构化) |
| 特征工程 | 需要手工构造 | 可自动提取特征 |
| 训练速度 | 快 | 慢(模型深、数据多) |
| 可解释性 | 好(特征重要性) | 差(黑箱) |
| 小数据表现 | 很好 | 容易过拟合 |
| 多模态能力 | 弱 | 强(图文结合等) |
| 归一化要求 | ❌ 不需要 | ✅ 必须 |
🛠️ 三、各自适用的典型场景
| 应用领域 | 建议模型 | 原因 |
|---|---|---|
| 信用评分 | XGBoost / LightGBM | 数据是结构化表格,数量不大 |
| 设备故障预测(基于传感器) | LightGBM | 结构化 + 快速部署 |
| 图像缺陷检测 | CNN(深度学习) | 图像是非结构化,CNN擅长 |
| 报警日志分类 | LSTM/BERT | 文本型数据,深度学习是唯一选择 |
| 多源融合(图像 + 文本 + 传感器) | 深度融合模型 | 神经网络具有多模态优势 |
📚 四、案例对比:设备故障预测
🎯 场景设定:
某公司用传感器监控设备运行(如温度、振动、压力等),目标是提前预测未来是否会出现故障。
你有一份 CSV 数据如下:
| temperature | vibration | pressure | oil_level | fault_label |
|---|---|---|---|---|
| 75.2 | 1.23 | 2.1 | 0.91 | 0 |
| 90.3 | 3.45 | 1.8 | 0.83 | 1 |
| … | … | … | … | … |
✅ 使用 LightGBM 进行预测(不需要归一化)
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 读取数据
df = pd.read_csv("sensor_data.csv")
# 特征与标签
features = ['temperature', 'vibration', 'pressure', 'oil_level']
X = df[features]
y = df['fault_label']
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 模型训练
model = lgb.LGBMClassifier()
model.fit(X_train, y_train)
# 模型评估
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
✅ 优点:
- 不需要归一化
- 快速高效
- 可解释性强(特征重要性)
🤖 使用深度学习模型(Keras)
💡 注意:需要对输入数据进行标准化
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 读取数据
df = pd.read_csv("sensor_data.csv")
features = ['temperature', 'vibration', 'pressure', 'oil_level']
X = df[features]
y = df['fault_label']
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=0)
# 构建神经网络
model = Sequential([
Dense(64, activation='relu', input_shape=(X.shape[1],)),
Dense(32, activation='relu'),
Dense(1, activation='sigmoid')
])
# 编译并训练
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=20, batch_size=16, verbose=1)
# 评估
y_pred = (model.predict(X_test) > 0.5).astype("int32")
print(classification_report(y_test, y_pred))
✅ 优点:
- 可处理非结构化数据(可升级融合图像/文本)
- 支持端到端学习
- 未来可拓展性强
❌ 缺点:
- 训练较慢
- 对数据依赖更强
- 不解释模型逻辑
🎯 结论:你该怎么选?
| 如果你是…… | 推荐模型 | 理由 |
|---|---|---|
| 需要快速上线 | LightGBM | 训练快、效果好 |
| 数据是表格型 | XGBoost / LightGBM | 传统机器学习模型更稳健 |
| 需要融合图像+传感器+文本 | 深度学习(CNN+LSTM) | 多模态不可替代 |
| 小样本场景 | LightGBM | 不容易过拟合 |
| 想要模型可解释性 | LightGBM/XGBoost | 可输出特征重要性图 |
🧠 最后总结一句话:
如果你做的是 结构化数据预测任务 —— 选 LightGBM;
如果你做的是 图像、文本、声音等复杂数据处理 —— 非深度学习莫属!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)