数据分析多项目
项目简介数据分析多项目通常涉及对数据的收集、处理、分析和解释,旨在发现数据中的规律、趋势和关联性,从而为决策提供支持。具体功能如下:1、数据处理与清洗:这是数据分析的基础步骤,包括去除重复数据、处理缺失值、数据类型转换等,以确保数据的质量和准确性。2、数据可视化与探索性分析:通过图表、图形等方式直观展示数据,帮助理解数据的分布、趋势和异常值等,为进一步的分析提供直观依据。项目客户群1、大数据分析公
数据分析多项目
项目背景
2020年新冠疫情在世界各地肆虐,可以说无处不在,无孔不入。它的蔓延和由此产生的影响导致了一场前所未有的全球性危机。许多科学机构使用数据分析,机器学习等科学技术对新冠疫情的控制以及社会生产的恢复提供了非常有力的帮助。本项目就是使用数据分析手段对新冠疫情的数据进行一些分析以及将所需要的数据进行可视化展示。
项目概述
项目简介
数据分析多项目通常涉及对数据的收集、处理、分析和解释,旨在发现数据中的规律、趋势和关联性,从而为决策提供支持。
具体功能如下:
1、数据处理与清洗:这是数据分析的基础步骤,包括去除重复数据、处理缺失值、数据类型转换等,以确保数据的质量和准确性。
2、数据可视化与探索性分析:通过图表、图形等方式直观展示数据,帮助理解数据的分布、趋势和异常值等,为进一步的分析提供直观依据。
项目客户群
1、大数据分析公司:实现数据分析处理等功能;
2、网站可视化平台系统、数据研发公司:实现后端数据分析处理与可视化。
项目需求
1、分析各国最新数据占比,从数据中提取出各个国家最新时间的确诊人数占比。
2、中国11月份的新增病例分析,从数据中提取出中国11月的确诊人数走势。
3、中国疫情各年龄段数据分析,从数据中提取出中国各个年龄段的确诊人数分布。
4、中国疫情确诊、疑似、治愈、死亡等统计分析,从数据中提取出中国的确诊、疑似、治愈、死亡人数进行可视化展示。
5、中国疫情新增数据时间段统计分析,从数据中提取出中国11月份的数据,并做分差获取新增人数。
6、从数据中提取出12月1日中国各省市的疫情确诊情况,使用pyecharts生成疫情地图。
7、从数据中提取出12月1日中国天津的疫情确诊情况,使用pyecharts生成疫情地图
项目目标
通过完成本项目,您将能够:
1.掌握数据分析与可视化项目环境的搭建(Pandas、Pyecharts、Matplotlib)
2.掌握高性能科学计算库的使用和数据分析的方法,具备数据处理的能力
3.掌握可视化库的使用,具备对处理可视化图形时需要用到的数据内容的能力
4.通过本项目可以综合提升学生的能力,从任务需求、数据分析、数据处理、到数据可视化的步骤,可以让刚刚步入职场的同学胜任数据分析开发的基础岗位
项目环境
| 实验环境 | 版本信息 |
|---|---|
| 操作系统 | Ubuntu-18.04 桌面版 |
| 内存信息 | ≥8G |
| 硬盘信息 | ≥60G |
| 开发工具 | Pycharm-2021 |
| 开发语言 | Python-3.6.9 |
软件清单
| 产品 | 版本信息 | 功能描述 |
|---|---|---|
| Pandas | latest | 开源的第三方Python库的数据分析包 |
| Pyecharts | latest | 基于 Python 的强大的可视化工具,提供丰富的图表类型和灵活的配置选项 |
| Matplotlib | latest | Python中用来数据可视化展示 |
项目开发
| 任务 | 岗位 | 详细说明 | 交付标准 |
|---|---|---|---|
| 环境搭建 | python运维工程师 | python运维工程师在开发前与数据分析师对接,了解项目所需环境,进行环境配置。配置环境时要避免重新安装、版本不兼容、更换版本等问题产生,保证开发过程的顺畅。配置完成并通过测试后,对接给数据分析师 | 各组件测试可正常运行 |
| 创建项目与类文件 | 数据分析师、数据可视化技术员 | 数据分析师从公司部门主管处获取任务书,了解任务详情和开发内容要求后,首先梳理整体的项目逻辑,然后根据需求设计项目模块,并确定各个模块需具备的功能及相互之间的联系。从网络运维工程师那里获取到开发环境后,进行实际开发工作 | 项目文件格式准确;类文件结构及数量准确 |
| 下载数据 | 数据分析师、数据可视化技术员 | 数据分析师了解任务详情和项目要求后,根据项目所需,从公司内部数据站中下载所需数据。下载到数据后,进行实际开发工作 | 数据符合项目需求,满足数据分析等操作使用 |
| 项目功能实现 | 数据分析师、数据可视化技术员 | 数据分析师明确任务目的后,对下载到的数据进行数据处理与分析操作,并根据任务要求进行可视化分析 | 项目文件格式准确;数据分析内容准确,可视化图形内容清楚明了,代码梳理清楚 |
任务一 环境搭建
任务场景
python运维工程师在开发前与数据分析师对接,了解项目所需环境,进行环境配置。配置环境时要避免重新安装、版本不兼容、更换版本等问题产生,保证开发过程的顺畅。配置完成并通过测试后,对接给数据分析师。
1.1 安装pandas库
在桌面右键点击【在此打开终端】,进入终端命令行界面:
在terminal终端中,使用pip命令安装pandas库:
pip install pandas
# 注:可使用指定的pandas版本进行下载
# 例如:pip install pandas==1.1.5
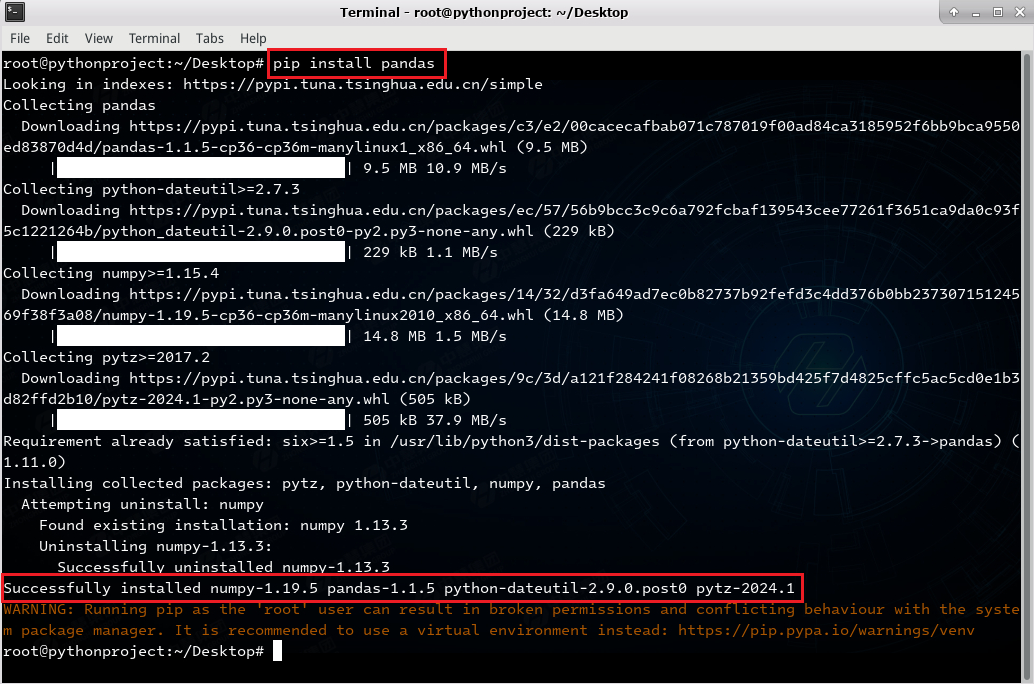
当下载pandas时,会自动帮我们下载好所需的其他库,如:numpy等等,所以后续就不必再下载numpy
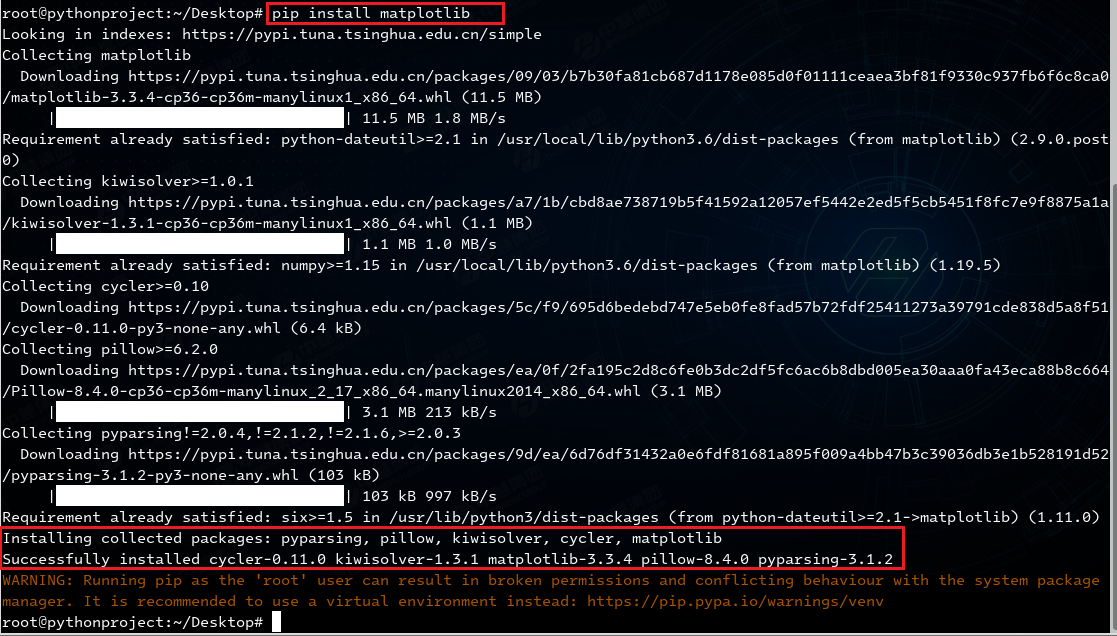
1.2 安装Matplotlib
Matplotlib是Python中用来数据可视化的第三方库,在本实验中主要用来可视化展示。
pip install matplotlib
# 注:可使用指定的matplotlib版本进行下载
# 例如:pip install matplotlib==3.3.4
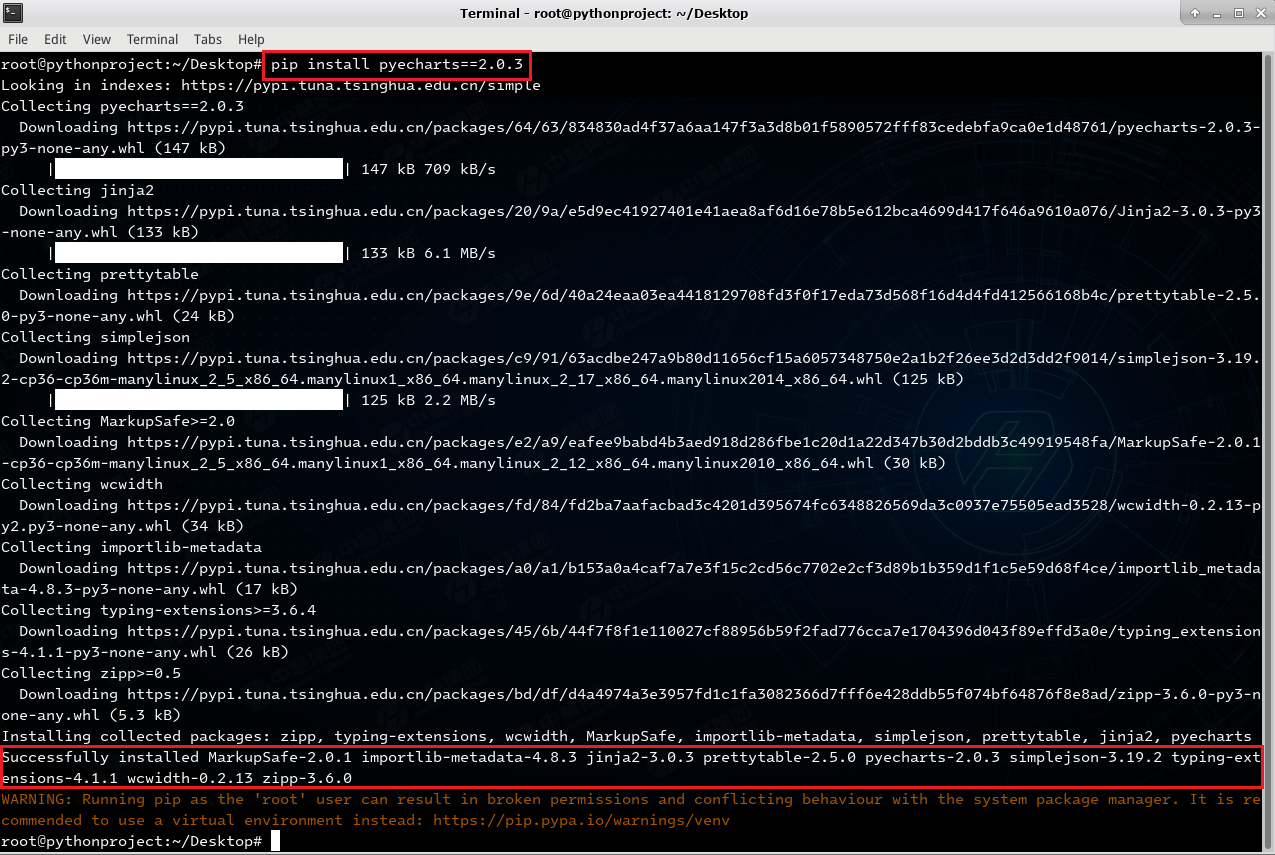
1.3 安装Pyecharts
Pyecharts 是一个基于 Python 的强大的可视化工具,它提供了丰富的图表类型和灵活的配置选项,可以帮助我们轻松地创建各种类型的图表。
# pyecharts需要指定版本进行下载(以便后续在版本不同的情况下出现不同的问题)
pip install pyecharts==2.0.3
任务二 创建项目与类文件
2.1 创建项目文件python_project
双击桌面的【Pycharm】开发者工具,勾选【同意协议】选款,点击【continue】继续:
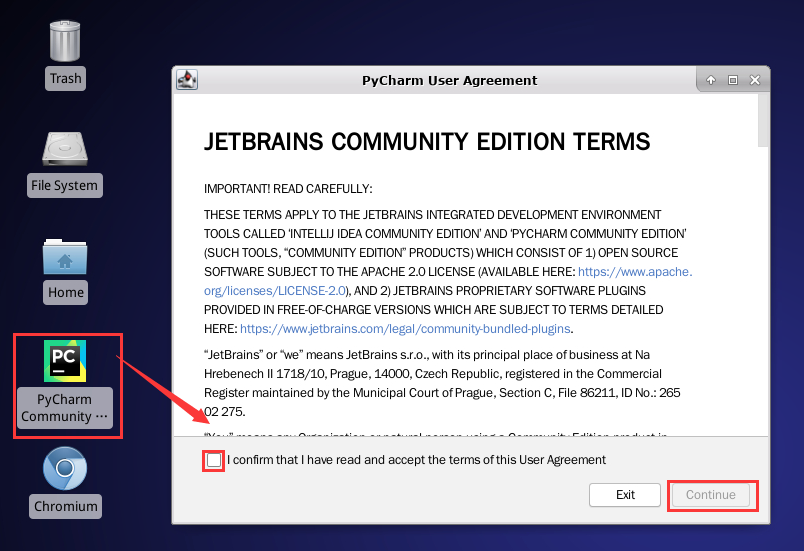
在欢迎界面,点击【New Project】创建新的项目:
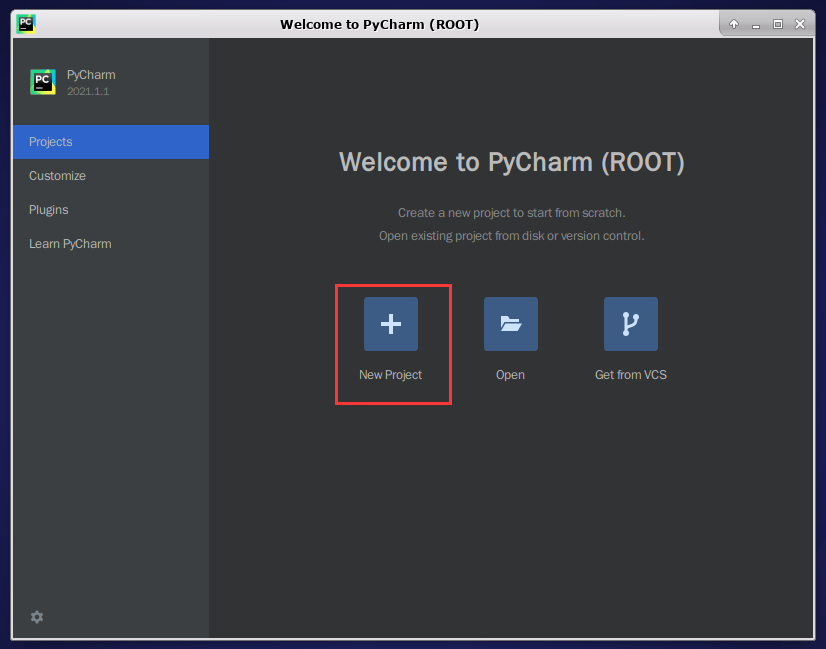
为项目命名为python_project(名称可自定义),选择python解释器版本完成创建:
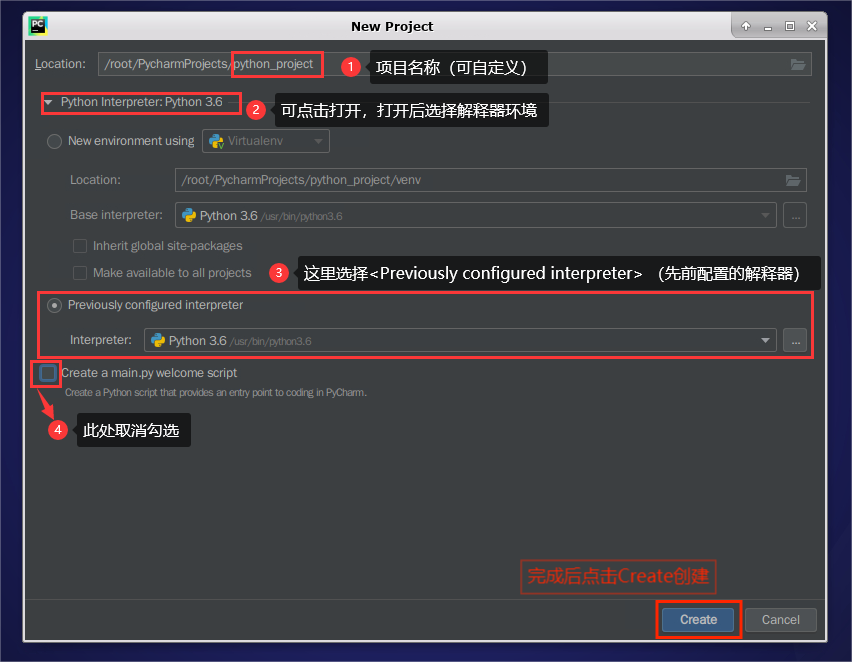
将弹出的每日更新【Tip of the day】点击【Close】关闭即可。
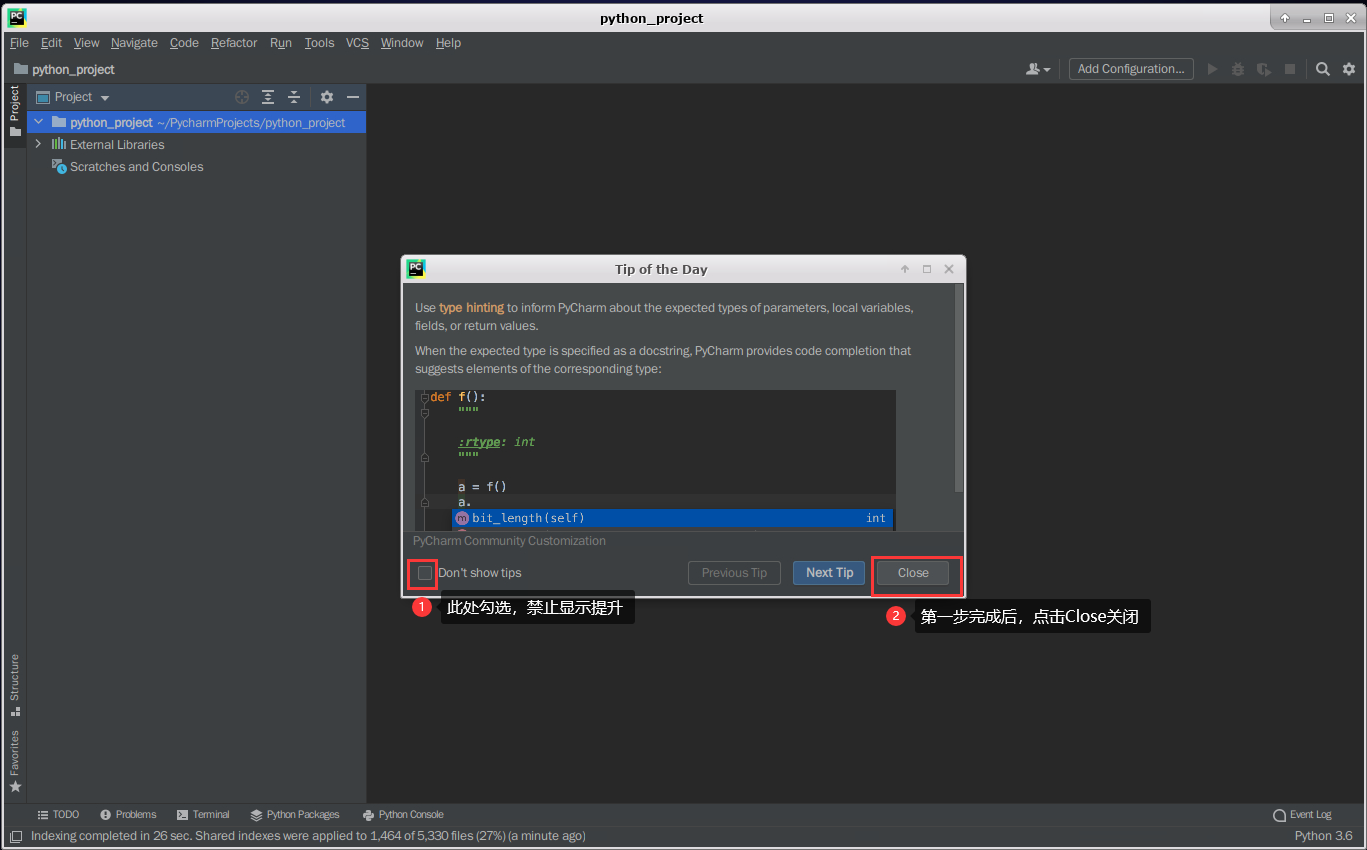
2.2 创建用于测试是否成功的代码文件test.py
在项目名称上进行右击鼠标,依次选择【New】,【Python file】:
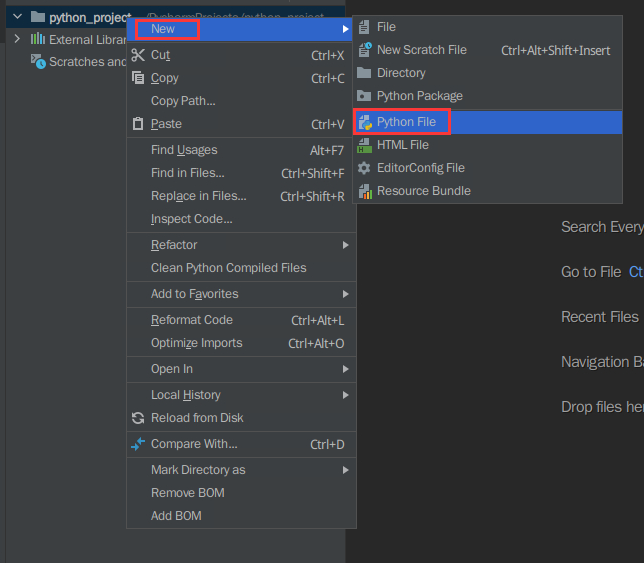
输入代码文件名称test(名称可自定义),点击回车完成创建。
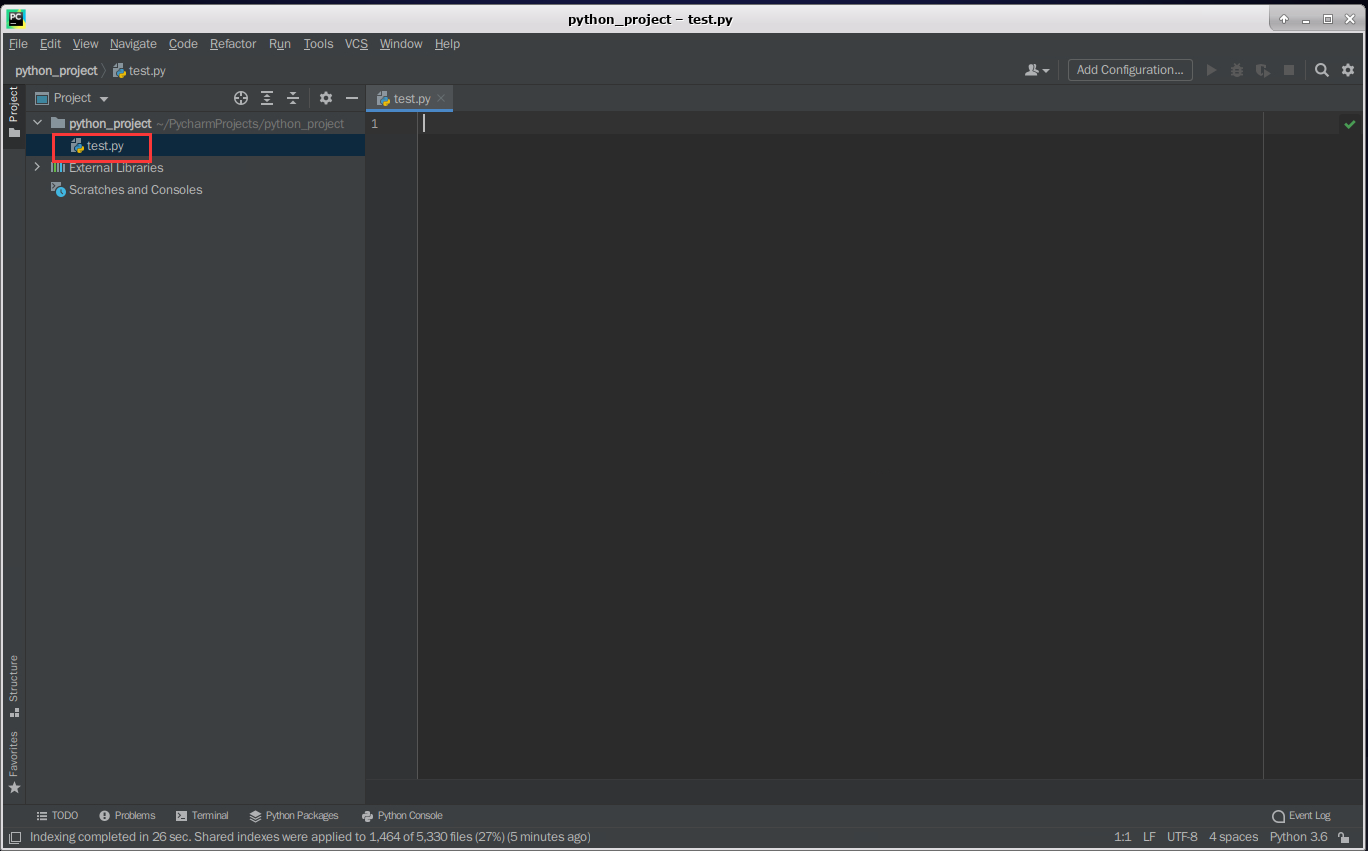
此时,测试文件test.py已成功创建
任务三 下载数据
3.1 先创建数据存放地址data
在项目python_project上进行右击鼠标,依次选择【New】,【Directory】创建一个文件夹
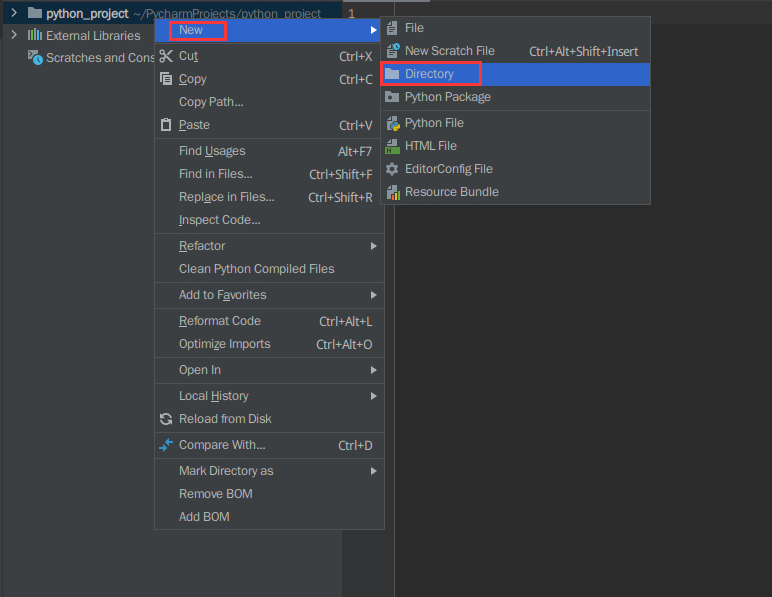
为文件夹命名为data,按回车完成创建(可自定义名称,但在使用时需要和路径名称保持一致)。
3.2 回到terminal终端,切换到data路径下载数据
cd /root/PycharmProjects/python_project/data
3.3 下载使用到的数据
① 下载epidemic_data.csv
wget res.zhonghui.vip/python-2/data_analysis_project/data/epidemic_data.csv
② 下载DXYArea1201.csv
wget res.zhonghui.vip/python-2/data_analysis_project/data/DXYArea1201.csv
任务四 项目功能实现
先创建存放执行结果的文件:
右击点击python_project文件夹,选择new,选择Directory并点击
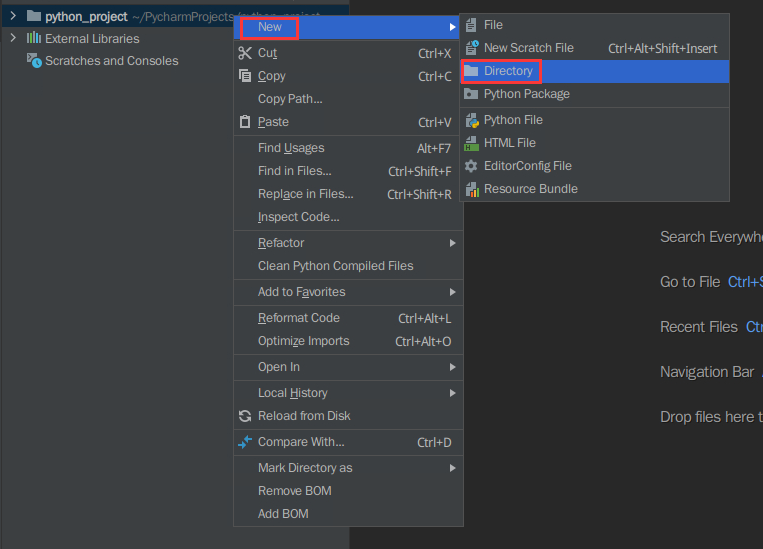
输入result并回车

此时result文件已创建成功
4.1 分析各国最新数据占比
1)创建covid1.py为项目1的代码文件
右击点击python_project文件夹,选择new,选择Python File并点击
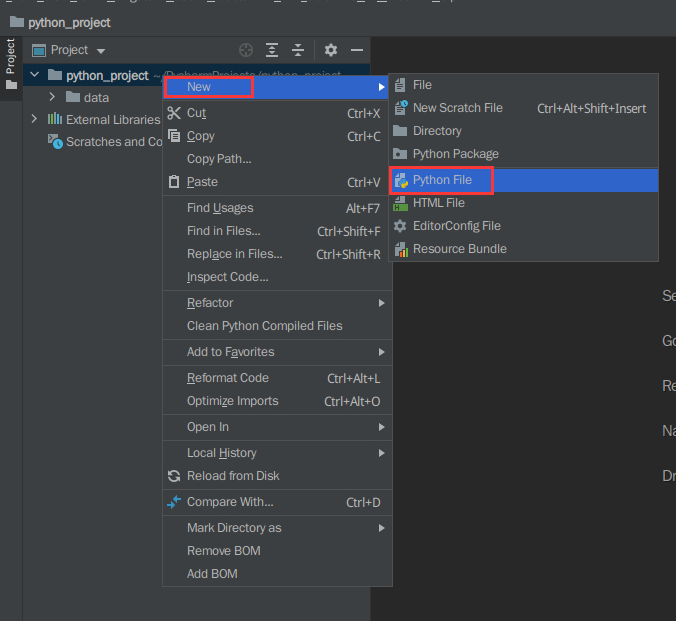
输入python文件名:covid1,回车即可创建完成
创建完成后,得到文件covid1.py:
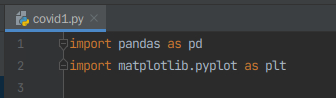
2)在covid1.py文件导入所需要的包
# 引入pandas包,并起别名为pd
import pandas as pd
# 引入matplotlib下的pyplot包,并起别名为plt
import matplotlib.pyplot as plt
3)读取DXYArea1201.csv文件,并对字段updateTime列转换成datetime数据类型,并提取数据形式为年-月-日
df = pd.read_csv('./data/DXYArea1201.csv')
# 将updateTime列转换成年-月-日的数据形式
df['updateTime'] = pd.to_datetime(df['updateTime']).dt.strftime('%Y-%m-%d')

4)获取最新的时间数据
# 根据updateTime找出最新时间
new_time_str = df["updateTime"].value_counts().sort_index(ascending=False).keys()[0]
# 根据获取到的最新时间,从而提取到最新数据
new_time_data = df[df["updateTime"] == new_time_str]

5)根据最新数据,分组统计出各个国家最新数据
# 根据最新数据,分组统计出各个国家最新数据
data_by_country = new_time_data.groupby('countryName')['region_confirmedCount'].sum().reset_index()
# 将data_by_country按列名region_confirmedCount以降序排序,并设置index为countryName,提取出排名前8的国家
sort_data_by_country = data_by_country.sort_values(by='region_confirmedCount', ascending=False).set_index("countryName").head(8)

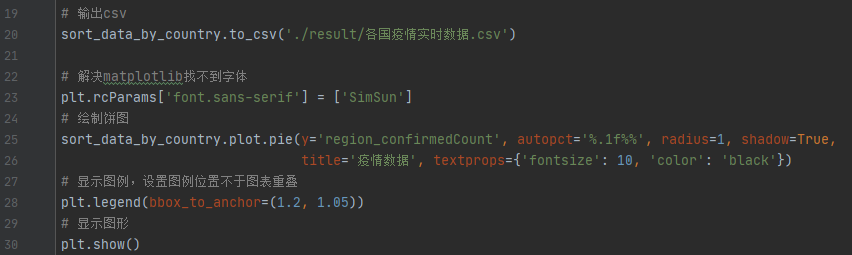
6)转存为csv文件并使用matplotlib展示可视化结果
# 输出csv
sort_data_by_country.to_csv('./result/各国疫情实时数据.csv')
# 解决matplotlib找不到字体
plt.rcParams['font.sans-serif'] = ['SimSun']
# 绘制饼图
sort_data_by_country.plot.pie(y='region_confirmedCount', autopct='%.1f%%', radius=1,shadow=True,
title='疫情数据', textprops={'fontsize': 10, 'color': 'black'})
# 显示图例,设置图例位置不于图表重叠
plt.legend(bbox_to_anchor=(1.2, 1.05))
# 显示图形
plt.show()
7)完成后右键点击并执行该文件
8)执行完成后即会出现一个figure画布,并在result文件中生成各国疫情实时数据.csv文件
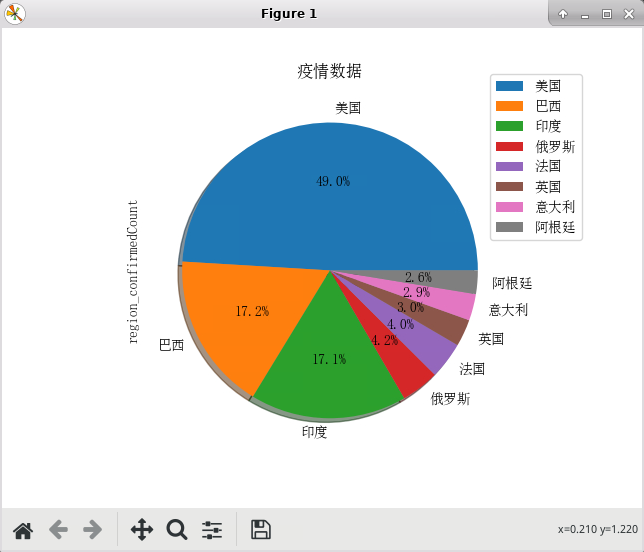
9)各国疫情实时数据.csv:

4.2 中国11月份的新增病例分析
1)同理,创建covid2.py为项目2的代码文件
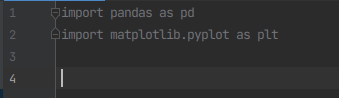
2)在covid2.py文件导入所需要的包
import pandas as pd
import matplotlib.pyplot as plt
3)读取DXYArea1201.csv文件,并将updateTime字段转换为datetime数据类型
# 读取数据
df = pd.read_csv('./data/DXYArea1201.csv')
# 将updateTime字段转换为datetime数据类型
df['updateTime'] = pd.to_datetime(df['updateTime'])

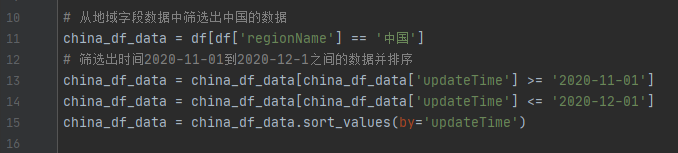
4)从地域字段数据中筛选出中国的数据,并根据updateTime字段筛选出2020-11-01到2020-12-1之间的数据,按updateTime字段进行排序
# 从地域字段数据中筛选出中国的数据
china_df_data = df[df['regionName'] == '中国']
# 筛选出时间2020-11-01到2020-12-1之间的数据并排序
china_df_data = china_df_data[china_df_data['updateTime'] >= '2020-11-01']
china_df_data = china_df_data[china_df_data['updateTime'] <= '2020-12-01']
china_df_data = china_df_data.sort_values(by='updateTime')
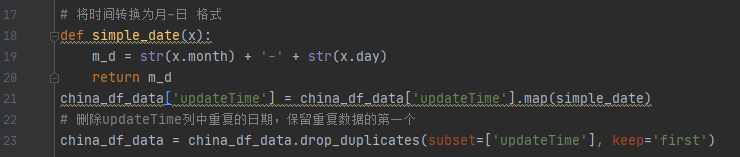
5)使用map方法将时间转换为月-日 格式,删除updateTime列中重复的日期,保留重复数据的第一个
# 将时间转换为月-日 格式
def simple_date(x):
m_d = str(x.month) + '-' + str(x.day)
return m_d
china_df_data['updateTime'] = china_df_data['updateTime'].map(simple_date)
# 删除updateTime列中重复的日期,保留重复数据的第一个
china_df_data = china_df_data.drop_duplicates(subset=['updateTime'], keep='first')
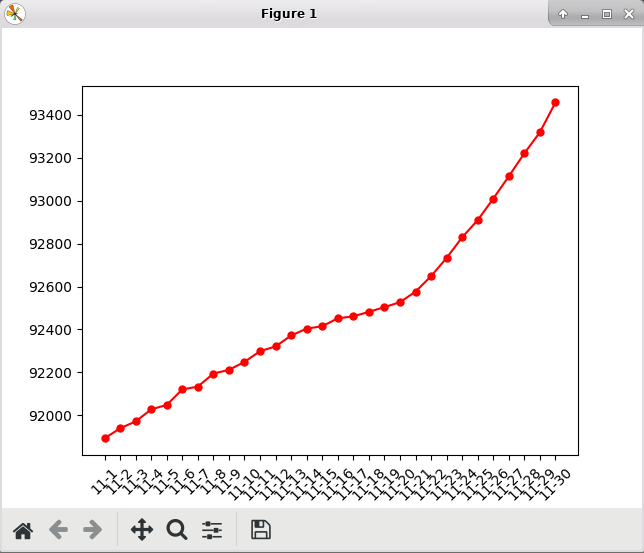
6)保存成csv数据,并使用matplotlib可视化展示
# 保存成csv数据
china_df_data.to_csv('./result/中国疫情时间段确诊的统计数据.csv', encoding='utf_8_sig')
# 数据可视化
plt.plot(china_df_data['updateTime'], china_df_data['region_confirmedCount'], color='r', marker='o', markersize=5)
plt.xticks(china_df_data['updateTime'], rotation=45)
plt.show()

7)同理,完成后右键点击并执行该文件
8)执行完成后将生成一个figure画布,并在result文件中生成中国疫情时间段统计数据.csv文件
10)中国疫情时间段统计数据.csv:
4.3 中国疫情各年龄段数据分析
1)同理,创建covid3.py为项目3的代码文件
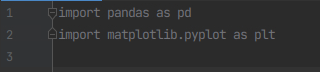
2)在covid3.py文件导入所需要的包
import pandas as pd
import matplotlib.pyplot as plt
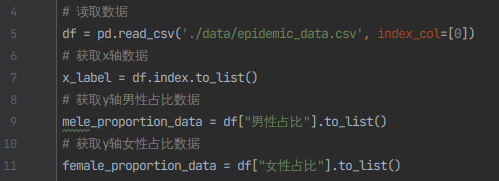
3)读取epidemic_data.csv数据,并提取出男性在各年龄段的占比数量,以及女性在各年龄段的占比数量
# 读取数据
df = pd.read_csv('./data/epidemic_data.csv', index_col=[0])
# 获取x轴数据
x_label = df.index.to_list()
# 获取y轴男性占比数据
mele_proportion_data = df["男性占比"].to_list()
# 获取y轴女性占比数据
female_proportion_data = df["女性占比"].to_list()
4)使用matplotlib绘制图形,并设置画布子图的排列方式为2行一列。
# 绘制各年龄段占比柱状图
plt.rcParams['font.sans-serif'] = ['SimSun'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 设置画布为2行1列
fig, ax = plt.subplots(2, 1, figsize=(10, 8))

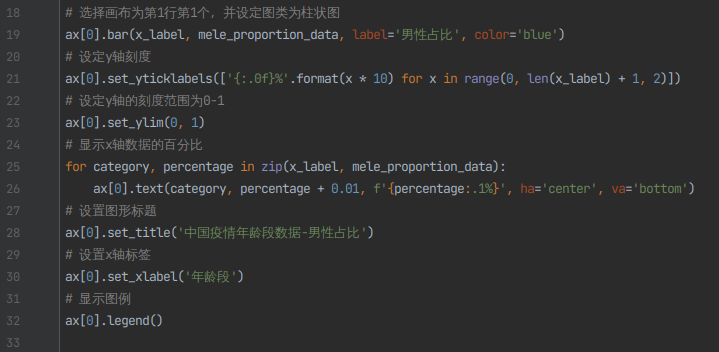
5)对画布子图的第一行第一个进行绘制各年龄段的男性占比率。
# 选择画布为第1行第1个,并设定图类为柱状图
ax[0].bar(x_label, mele_proportion_data, label='男性占比', color='blue')
# 设定y轴刻度
ax[0].set_yticklabels(['{:.0f}%'.format(x * 10) for x in range(0, len(x_label) + 1, 2)])
# 设定y轴的刻度范围为0-1
ax[0].set_ylim(0, 1)
# 显示x轴数据的百分比
for category, percentage in zip(x_label, mele_proportion_data):
ax[0].text(category, percentage + 0.01, f'{percentage:.1%}', ha='center', va='bottom')
# 设置图形标题
ax[0].set_title('中国疫情年龄段数据-男性占比')
# 设置x轴标签
ax[0].set_xlabel('年龄段')
# 显示图例
ax[0].legend()
6)对画布子图的第2行第一个进行绘制各年龄段的女性占比率。
# 选择画布为第2行第1个,并设定图类为柱状图
ax[1].bar(x_label, female_proportion_data, label='女性占比', color='red')
# 设定y轴刻度
ax[1].set_yticklabels(['{:.0f}%'.format(x * 10) for x in range(0, len(x_label) + 1, 2)])
# 设定y轴的刻度范围为0-1
ax[1].set_ylim(0, 1)
# 显示x轴数据的百分比
for category, percentage in zip(x_label, female_proportion_data):
ax[1].text(category, percentage + 0.01, f'{percentage:.1%}', ha='center', va='bottom')
# 设置图形标题
ax[1].set_title('中国疫情年龄段数据-女性占比')
# 设置x轴标签
ax[1].set_xlabel('年龄段')
# 显示图例
ax[1].legend()
7)设置画布中子图之间的间隔,并显示图形。
# 设置画布之间的间隔
plt.subplots_adjust(hspace=0.3)
# 显示图形
plt.show()
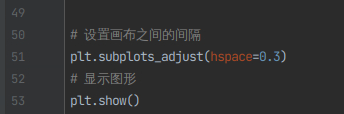
8)同理,右键点击并执行该文件,执行完成后将生成一个figure画布
4.4 中国疫情确诊、疑似、治愈、死亡的数量统计分析
1)同理,创建covid4.py为项目4的代码文件
2)在covid4.py文件导入所需要的包
import pandas as pd
import matplotlib.pyplot as plt
import csv
3)读取DXYArea1201.csv文件数据,并从地域字段数据中筛选出中国的数据
# 读取数据
df = pd.read_csv('./data/DXYArea1201.csv')
# 从地域字段数据中筛选出中国的数据
china_df_data = df[df['regionName'] == '中国']
4)分别统计中国疫情确诊、疑似、治愈、死亡人数的总数量。
# 统计中国疫情确诊、疑似、治愈、死亡人数的总数量
index_list = ['确诊人数','疑似人数','治愈人数','死亡人数']
value_list = [china_df_data['region_confirmedCount'].sum(),china_df_data['region_suspectedCount'].sum(),china_df_data['region_curedCount'].sum(),china_df_data['region_deadCount'].sum()]
result = list(zip(index_list,value_list))

5)将提取的数据存入为csv文件
# 写入csv文件
fileName="./result/中国疫情确诊、疑似、治愈、死亡比例.csv"
with open(fileName,"w",encoding='utf-8') as csv_file:
writer=csv.writer(csv_file)
for row in result:
# 一条一条写入
writer.writerow(row)
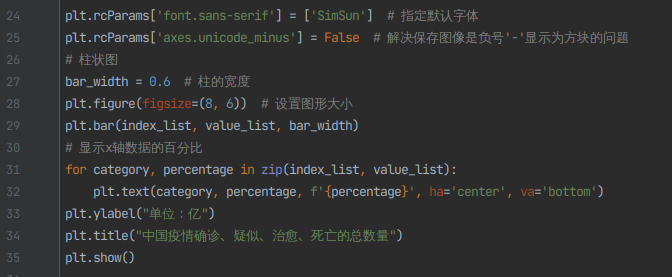
6)使用matplotlib可视化展示。
plt.rcParams['font.sans-serif'] = ['SimSun'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#柱状图
bar_width = 0.6 #柱的宽度
plt.figure(figsize=(8,6)) # 设置图形大小
plt.bar(index_list,value_list,bar_width)
# 显示x轴数据的百分比
for category, percentage in zip(index_list, value_list):
plt.text(category, percentage, f'{percentage}', ha='center', va='bottom')
plt.ylabel("单位:亿")
plt.title("中国疫情确诊、疑似、治愈、死亡的总数量")
plt.show()
7)同理,右键点击并执行该文件,执行完成后将生成一个figure画布,并在result文件中生成中国疫情确诊、疑似、治愈、死亡比例.csv文件
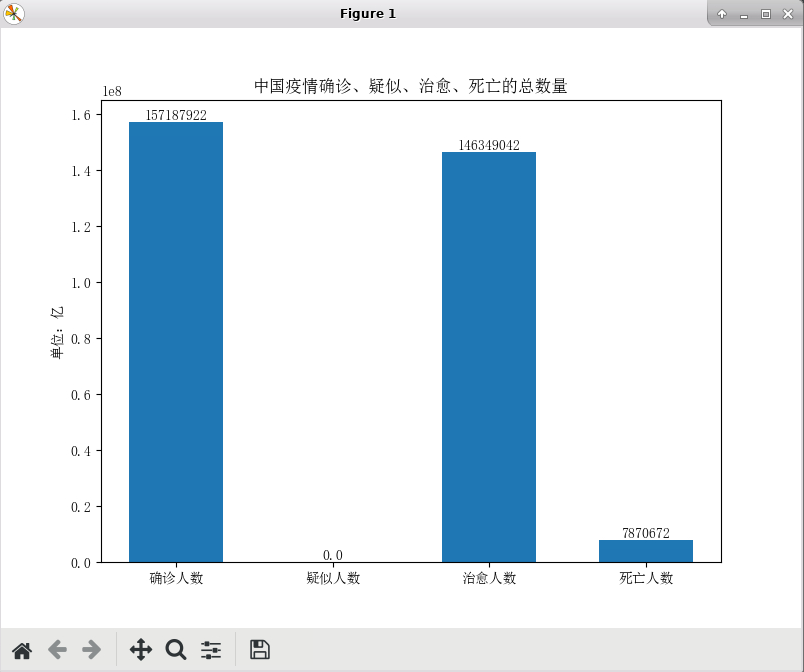
中国疫情确诊、疑似、治愈、死亡比例.csv:
4.5 中国疫情11月每日新增数据时间段统计分析
1)同理,创建covid5.py为项目5的代码文件
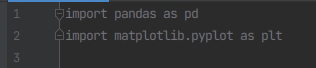
2)在covid5.py文件导入所需要的包
import pandas as pd
import matplotlib.pyplot as plt
3)读取DXYArea1201.csv文件数据,并从地域字段数据中筛选出中国的数据后,将updateTime字段转换为datetime数据类型
df = pd.read_csv('./data/DXYArea1201.csv')
china_df_data = df[df["regionName"]=="中国"]
# 将updateTime字段转换为datetime数据类型
china_df_data['updateTime'] = pd.to_datetime(china_df_data['updateTime']).dt.strftime('%Y-%m-%d')

4)根据updateTime字段提取出11月的数据后,并根据此字段进行升序排序。
# 根据updateTime找出11月的数据
china_df_data = china_df_data[china_df_data['updateTime'] >= '2020-10-31']
china_df_data = china_df_data[china_df_data['updateTime'] <= '2020-11-30']
china_df_data = china_df_data.sort_values(by='updateTime')

5)并将updateTime字段转换为月-日 格式,根据地域的确诊数量进行差分操作从而得到数量差,再根据updateTime字段进行分组,统计出同一时间的确诊数量的数量差,进而得到11月每天新增数据。
china_df_data['updateTime'] = pd.to_datetime(china_df_data['updateTime']).dt.strftime('%m-%d')
# 差分获取新增数据
china_df_data[['region_confirmedCount']] = china_df_data[['region_confirmedCount']].diff()
new_china_df_data = china_df_data.groupby('updateTime')["region_confirmedCount"].sum().reset_index()

6)处理掉10月31日的数据,只保留11月的数据,然后提取出相应的字段数据用于后续的操作。
new_china_df_data = new_china_df_data[new_china_df_data["updateTime"] != "10-31"]
# 获得地域确诊数据以及时间
new_data_added = new_china_df_data[
['region_confirmedCount','updateTime']]

7)保存为csv文件数据,并使用matplotlib可视化展示
# 保存成csv数据
new_data_added.to_csv('./result/中国疫情新增数据时间段统计数据.csv', encoding='utf_8_sig')
plt.figure(figsize=(15, 6))
plt.plot(new_data_added['updateTime'], new_data_added['region_confirmedCount'], color='#DA70D6', marker='*', markersize=5)
for category, percentage in zip(new_data_added['updateTime'], new_data_added['region_confirmedCount']):
plt.text(category, percentage, f'{int(percentage)}', ha='center', va='bottom')
plt.gca().set_ylim(-300,600)
plt.xticks(new_data_added['updateTime'], rotation=45)
plt.show()
8)同理,右键点击并执行该文件,执行完成后将生成一个figure画布,并在result文件中生成中国疫情新增数据时间段统计数据.csv文件
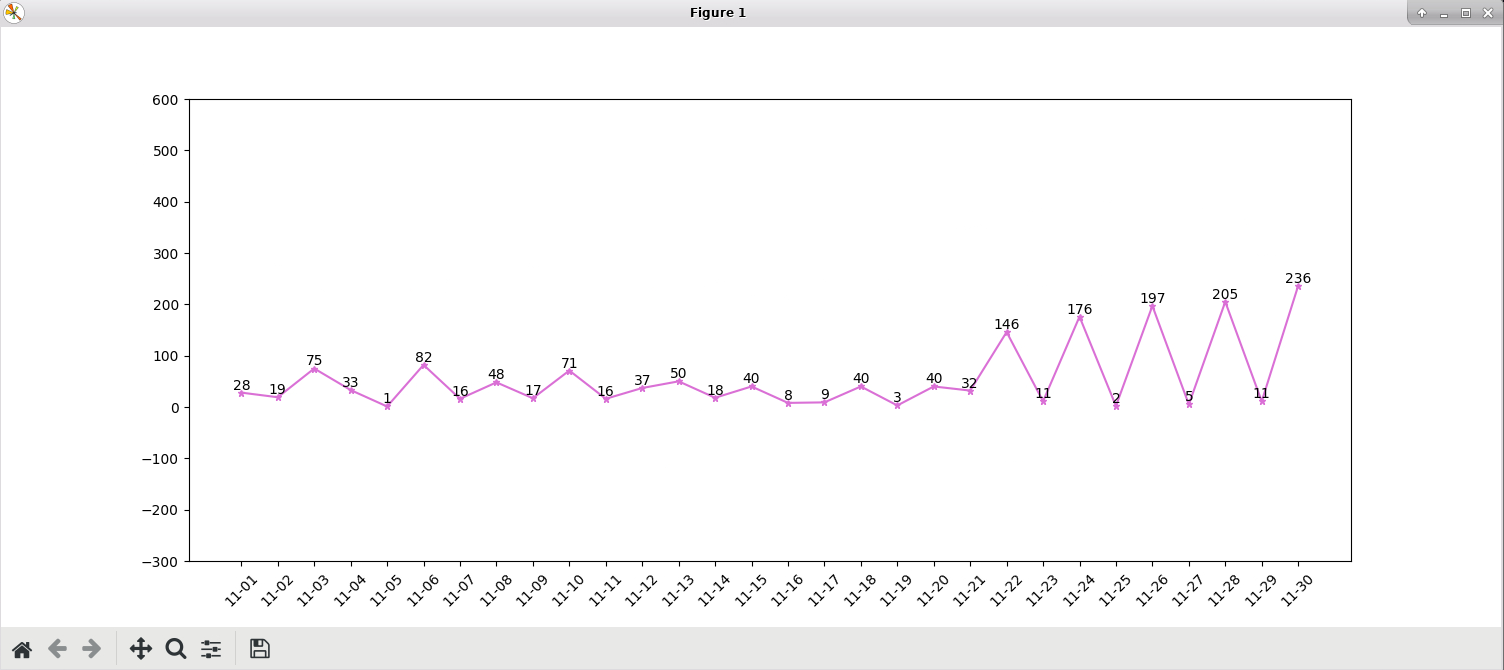
中国疫情新增数据时间段统计数据.csv:
4.6 12月1日中国各省市疫情地图
1)同理,创建covid6.py为项目6的代码文件
2)在covid6.py文件导入所需要的包
from pyecharts import options as opts
from pyecharts.charts import Map
import pandas as pd
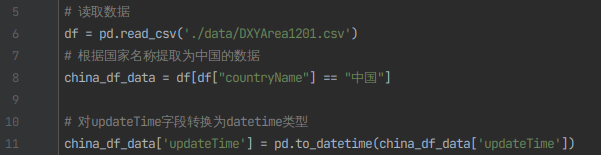
3)读取DXYArea1201.csv文件数据,从数据中筛选出中国的数据,将updateTime字段转换为datetime数据类型。
# 读取数据
df = pd.read_csv('./data/DXYArea1201.csv')
# 根据国家名称提取为中国的数据
china_df_data = df[df["countryName"] == "中国"]
# 对updateTime字段转换为datetime类型
china_df_data['updateTime'] = pd.to_datetime(china_df_data['updateTime'])
4)取出时间2020-12-1的数据。
# 提取出12月1日的数据
china_df_data = china_df_data[
(china_df_data['updateTime'] >= '2020-12-01') & (china_df_data['updateTime'] < '2020-12-02')]

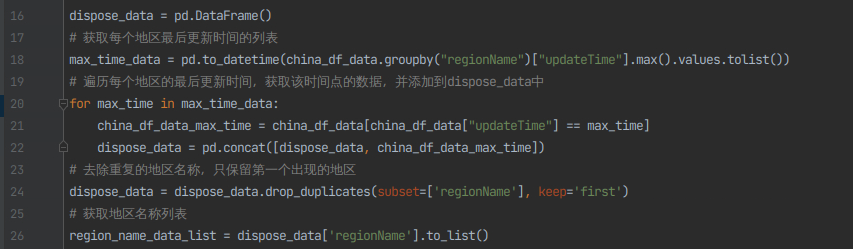
5)处理中国数据中每个地区的最新更新时间,获取该时间点的数据,并添加到dispose_data中。
dispose_data = pd.DataFrame()
# 获取每个地区最后更新时间的列表
max_time_data = pd.to_datetime(china_df_data.groupby("regionName")["updateTime"].max().values.tolist())
# 遍历每个地区的最后更新时间,获取该时间点的数据,并添加到dispose_data中
for max_time in max_time_data:
china_df_data_max_time = china_df_data[china_df_data["updateTime"] == max_time]
dispose_data = pd.concat([dispose_data, china_df_data_max_time])
# 去除重复的地区名称,只保留第一个出现的地区
dispose_data = dispose_data.drop_duplicates(subset=['regionName'], keep='first')
# 获取地区名称列表
region_name_data_list = dispose_data['regionName'].to_list()
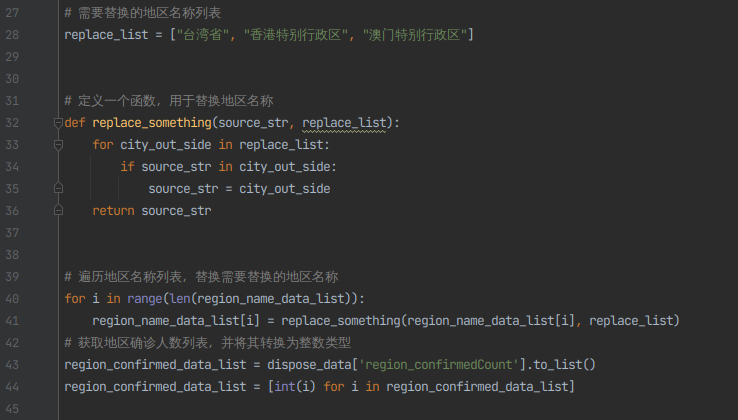
6)对特别地区进行名称替换并将地区的确诊人数数据提取出来。
# 需要替换的地区名称列表
replace_list = ["台湾省", "香港特别行政区", "澳门特别行政区"]
# 定义一个函数,用于替换地区名称
def replace_something(source_str, replace_list):
for city_out_side in replace_list:
if source_str in city_out_side:
source_str = city_out_side
return source_str
# 遍历地区名称列表,替换需要替换的地区名称
for i in range(len(region_name_data_list)):
region_name_data_list[i] = replace_something(region_name_data_list[i], replace_list)
# 获取地区确诊人数列表,并将其转换为整数类型
region_confirmed_data_list = dispose_data['region_confirmedCount'].to_list()
region_confirmed_data_list = [int(i) for i in region_confirmed_data_list]
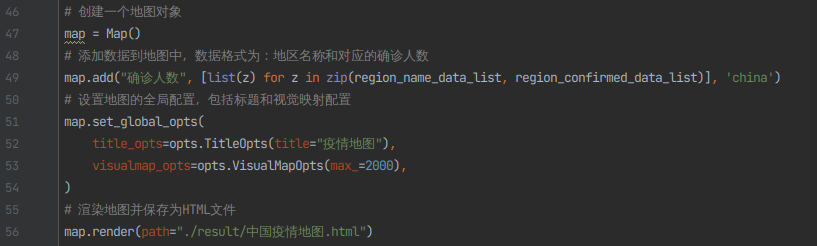
6)使用pyecharts进行中国地图的可视化展示,并将可视化页面存到result文件中
# 创建一个地图对象
map = Map()
# 添加数据到地图中,数据格式为:地区名称和对应的确诊人数
map.add("确诊人数", [list(z) for z in zip(region_name_data_list, region_confirmed_data_list)], 'china')
# 设置地图的全局配置,包括标题和视觉映射配置
map.set_global_opts(
title_opts=opts.TitleOpts(title="疫情地图"),
visualmap_opts=opts.VisualMapOpts(max_=2000),
)
# 渲染地图并保存为HTML文件
map.render(path="./result/中国疫情地图.html")
7)同理,右键点击并执行该文件,执行完成后将在result文件中生成一个中国疫情地图.html文件。
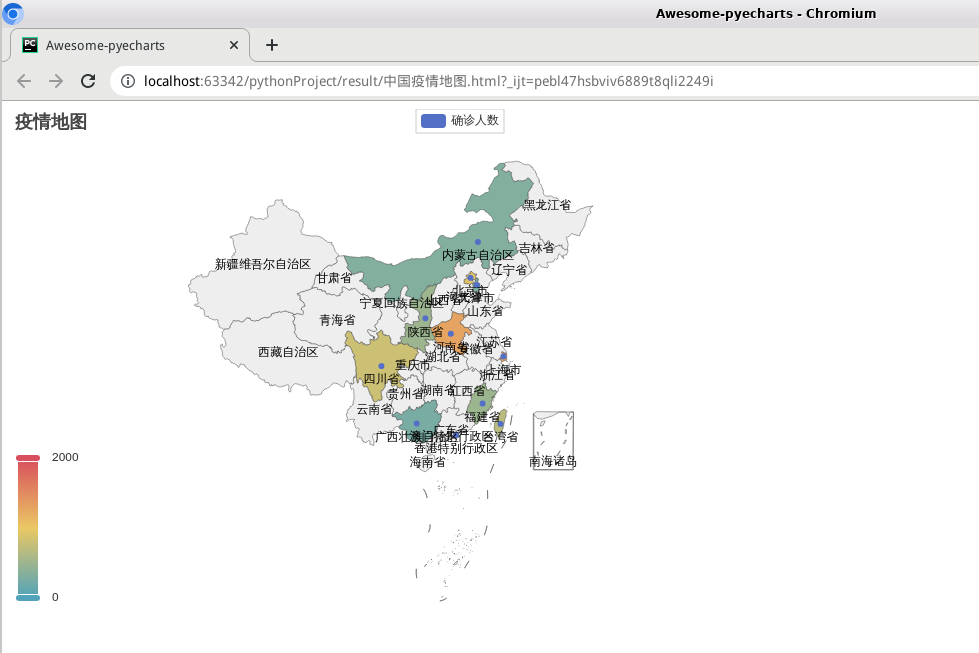
8)打开中国疫情地图.html文件,显示如下:
4.7 12月1日天津市疫情地图
1)同理,创建covid7.py为项目7的代码文件
2)在covid7.py文件导入所需要的包
from pyecharts import options as opts
from pyecharts.charts import Map
import pandas as pd
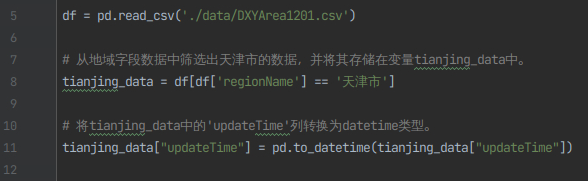
3)读取DXYArea1201.csv文件数据,从地域字段数据中筛选出天津市的数据,并将updateTime字段转换为datetime数据类型
df = pd.read_csv('./data/DXYArea1201.csv')
# 从地域字段数据中筛选出天津市的数据,并将其存储在变量tianjing_data中。
tianjing_data = df[df['regionName'] == '天津市']
# 将tianjing_data中的'updateTime'列转换为datetime类型。
tianjing_data["updateTime"] = pd.to_datetime(tianjing_data["updateTime"])
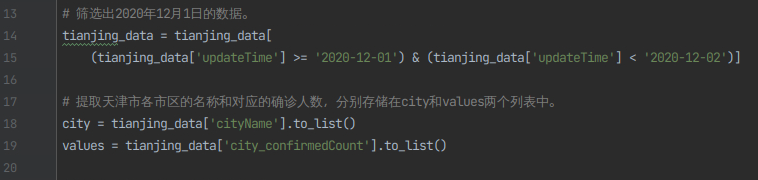
4)取出时间2020-12-1的数据,并获取可视化所需要的数据集。
# 筛选出2020年12月1日的数据。
tianjing_data = tianjing_data[
(tianjing_data['updateTime'] >= '2020-12-01') & (tianjing_data['updateTime'] < '2020-12-02')]
# 提取天津市各市区的名称和对应的确诊人数,分别存储在city和values两个列表中。
city = tianjing_data['cityName'].to_list()
values = tianjing_data['city_confirmedCount'].to_list()
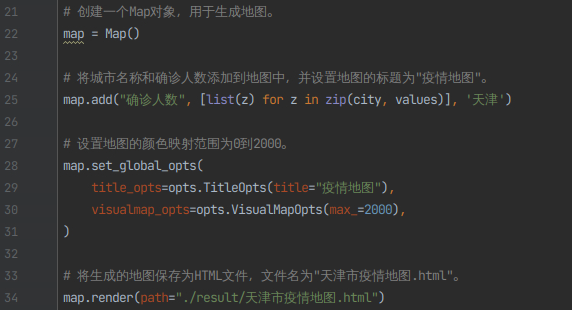
5)使用pyecharts进行天津市地图的可视化展示,并将可视化页面存到result文件中
# 创建一个Map对象,用于生成地图。
map = Map()
# 将城市名称和确诊人数添加到地图中,并设置地图的标题为"疫情地图"。
map.add("确诊人数", [list(z) for z in zip(city, values)], '天津')
# 设置地图的颜色映射范围为0到2000。
map.set_global_opts(
title_opts=opts.TitleOpts(title="疫情地图"),
visualmap_opts=opts.VisualMapOpts(max_=2000),
)
# 将生成的地图保存为HTML文件,文件名为"天津市疫情地图.html"。
map.render(path="./result/天津市疫情地图.html")
6)同理,右键点击并执行该文件,执行完成后将在result文件中生成一个天津市疫情地图.html文件。
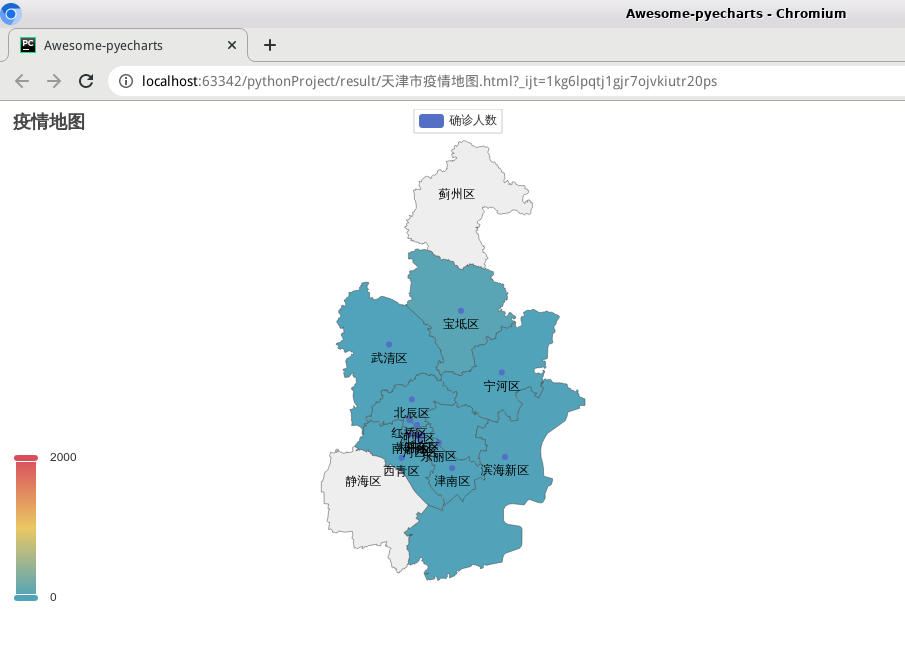
7)打开天津市疫情地图.html文件,显示如下:
辅助文档
项目完成后,可参考辅助文档
创建Demo目录用于存储下载训练代码
输入目录名称Demo,回车完成创建。

下载covid1.py训练代码
wget res.zhonghui.vip/python-2/data_analysis_project/code/covid1.py
复制到Demo项目目录下
cp covid1.py ~/PycharmProjects/python_project/Demo/
下载covid2.py训练代码
wget res.zhonghui.vip/python-2/data_analysis_project/code/covid2.py
复制到Demo项目目录下
cp covid2.py ~/PycharmProjects/python_project/Demo/
下载covid3.py训练代码
wget res.zhonghui.vip/python-2/data_analysis_project/code/covid3.py
复制到Demo项目目录下
cp covid3.py ~/PycharmProjects/python_project/Demo/
下载covid4.py训练代码
wget res.zhonghui.vip/python-2/data_analysis_project/code/covid4.py
复制到Demo项目目录下
cp covid4.py ~/PycharmProjects/python_project/Demo/
下载covid5.py训练代码
wget res.zhonghui.vip/python-2/data_analysis_project/code/covid5.py
复制到Demo项目目录下
cp covid5.py ~/PycharmProjects/python_project/Demo/
下载covid6.py训练代码
wget res.zhonghui.vip/python-2/data_analysis_project/code/covid6.py
复制到Demo项目目录下
cp covid6.py ~/PycharmProjects/python_project/Demo/
下载covid7.py训练代码
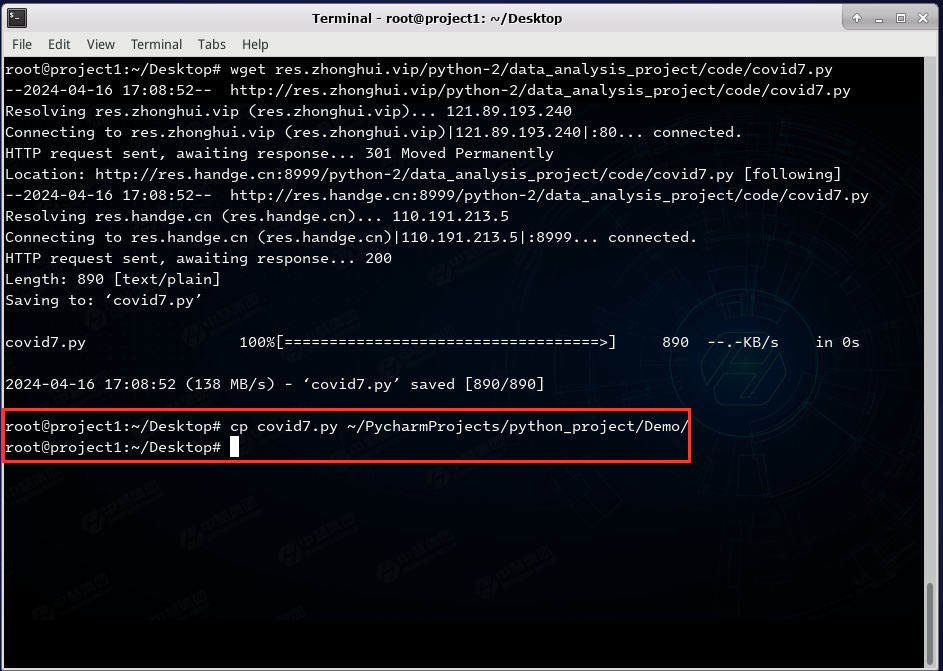
wget res.zhonghui.vip/python-2/data_analysis_project/code/covid7.py
复制到Demo项目目录下
cp covid7.py ~/PycharmProjects/python_project/Demo/
d3pH-1742112961402)]
复制到Demo项目目录下
cp covid4.py ~/PycharmProjects/python_project/Demo/
[外链图片转存中…(img-4n5V1sQt-1742112961402)]
下载covid5.py训练代码
wget res.zhonghui.vip/python-2/data_analysis_project/code/covid5.py
[外链图片转存中…(img-E2VATO4T-1742112961403)]
复制到Demo项目目录下
cp covid5.py ~/PycharmProjects/python_project/Demo/
[外链图片转存中…(img-g63zhr84-1742112961403)]
下载covid6.py训练代码
wget res.zhonghui.vip/python-2/data_analysis_project/code/covid6.py
[外链图片转存中…(img-d6dTp563-1742112961403)]
复制到Demo项目目录下
cp covid6.py ~/PycharmProjects/python_project/Demo/
[外链图片转存中…(img-q4Rk3cAd-1742112961403)]
下载covid7.py训练代码
wget res.zhonghui.vip/python-2/data_analysis_project/code/covid7.py
[外链图片转存中…(img-TmgGB2oV-1742112961403)]
复制到Demo项目目录下
cp covid7.py ~/PycharmProjects/python_project/Demo/

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)