《动手学深度学习》笔记——深度学习基础(二)
目录1 自动求导1.1 计算图1.2 自动求导的两种模式1.3 复杂度比较1.4 自动求导例子1.4.1 标量变量的反向传播1.4.2 非标量变量的反向传播1.4.3 分离计算1.4.4 Python控制流的梯度计算1.5 自动求导 Q&A2 概率2.1 基本概率论2.1.1 概率论公理2.1.2 随机变量2.2 处理多个随机变量2.2.1 联合概率(joint probability)2.2.
目录
2.2.2 条件概率(conditional probability)
2.2.3 贝叶斯定理(Bayes定理,Bayes’ theorem)
1 自动求导
深度学习框架通过自动计算导数,即自动微分(automatic differentiation)来加快求导。 实际中,根据设计好的模型,系统会构建一个计算图(computational graph), 来跟踪计算是哪些数据通过哪些操作组合起来产生输出。 自动微分使系统能够随后反向传播梯度。 这里,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。
- 含义:计算一个函数在指定值上的导数
- 自动求导有别于
- 符号求导
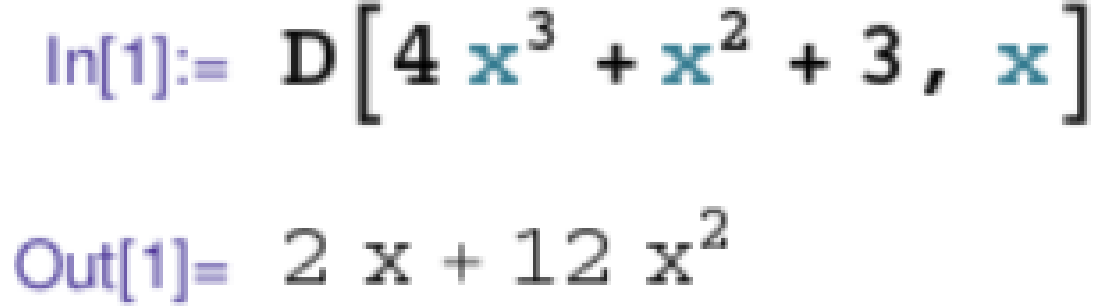
- 数值求导
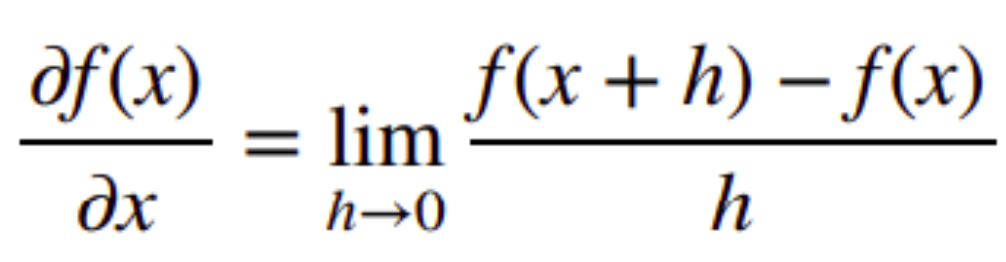
- 符号求导
为了更好地理解自动求导,下面引入计算图的概念
1.1 计算图
-
将代码分解成操作子
-
将计算表示成一个无环图
下图自底向上其实就类似于链式求导过程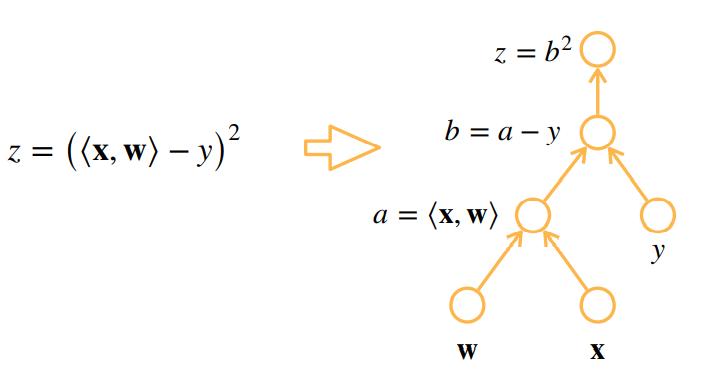
-
计算图有两种构造方式
-
显示构造:可以理解为先定义公式再代值
Tensorflow/Theano/MXNet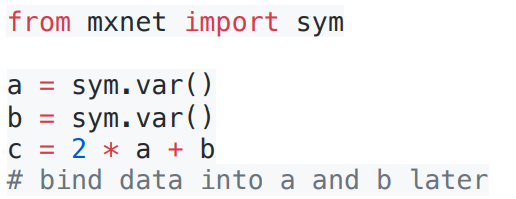
-
隐式构造:系统将所有的计算记录下来
Pytorch/MXNet
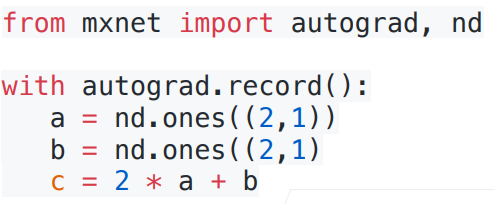
-
1.2 自动求导的两种模式

反向累积计算过程
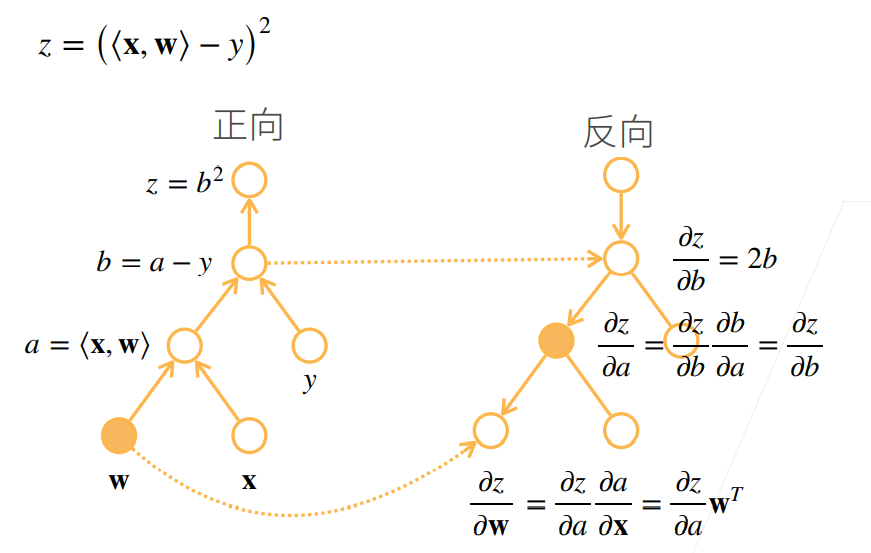
反向累积的正向过程:自底向上,需要存储中间结果
反向累积的反向过程:自顶向下,可以去除不需要的枝(图中的x应为w)
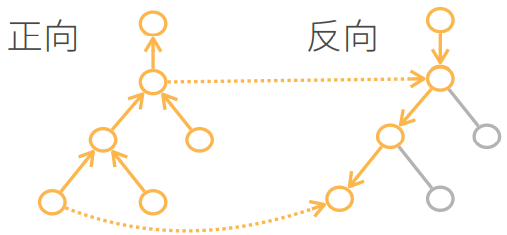
1.3 复杂度比较
-
反向累积
-
计算复杂度:O(n),n是操作子数。通常正向和反向的代价类似
-
内存复杂度:O(n):存储正向过程所有的中间结果
-
-
正向累积:
-
计算复杂度:O(n),每次计算一个变量的梯度时都需要将所有节点扫一遍
-
内存复杂度:O(1),不存储中间结果
-
1.4 自动求导例子
1.4.1 标量变量的反向传播
假设要对 关于列向量
求导。首先创建变量
并为其分配一个初始值。
>>> import torch
>>> x = torch.arange(4.0)
>>> x
tensor([0., 1., 2., 3.])在计算 关于
的梯度之前,需要一个地方存储梯度。重要的是,我们不会在每次对一个参数求导时都分配新的内存。 因为我们经常会成千上万次地更新相同的参数,每次都分配新的内存可能很快就会将内存耗尽。
# requires_grad : 如果需要为张量计算梯度,则为True,否则为False。
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 查看x的梯度值,默认值是None
计算 。( PyTorch隐式地构造计算图,grad_fn是求梯度的函数,用来记录变量是怎么来的。)
>>> y = 2 * torch.dot(x, x)
>>> y
tensor(28., grad_fn=<MulBackward0>)
调用反向传播函数来自动计算 关于
每个分量的梯度。
>>> y.backward()
>>> x.grad
tensor([ 0., 4., 8., 12.])验证这个梯度是否计算正确
>>> x.grad == 4 * x # 函数y关于x的梯度应为4x。
tensor([True, True, True, True])现在计算 的另一个函数
# 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
>>> x.grad.zero_() # 如果没有这一步结果就会累加上之前的梯度值,变为[1,5,9,13]
>>> y = x.sum()
>>> y.backward()
>>> x.grad
tensor([1., 1., 1., 1.])1.4.2 非标量变量的反向传播
当y不是标量时,向量y关于向量x的导数的最自然解释是一个矩阵。 对于高阶和高维的y和x,求导的结果可以是一个高阶张量。深度学习中,我们的目的不是计算微分矩阵,而是单独计算批量中每个样本的偏导数之和。
# 对非标量调用backward需要传入一个gradient参数,该参数指定微分函数关于self的梯度。
# 本例只想求偏导数的和,所以传递一个1的梯度是合适的
>>> x.grad.zero_()
>>> y = x * x # 哈达玛积,对应元素相乘
# 等价于y.backward(torch.ones(len(x)))
>>> y.sum().backward()
>>> x.grad
tensor([0., 2., 4., 6.])
1.4.3 分离计算
将某些计算移动到记录的计算图之外
>>> x.grad.zero_() # 清零梯度
>>> y = x * x
>>> u = y.detach() # 把y当作常数,而不再是关于x的函数,并赋值给u
>>> z = u * x # 对于u而言,他只是一个值为x*x的常数
>>> z.sum().backward()
>>> x.grad == u
tensor([True, True, True, True])
>>> x.grad.zero_()
>>> y.sum().backward() # y实际上还是关于x的函数
>>> x.grad == 2*x
tensor([True, True, True, True])1.4.4 Python控制流的梯度计算
使用自动微分的一个好处是: 即使构建函数的计算图需要通过Python控制流(例如,条件、循环或任意函数调用),我们仍然可以计算得到的变量的梯度。这也是隐式构造的优势,因为它会存储梯度计算的计算图,再次计算时执行反向过程就可以。
在下面的代码中,while循环的迭代次数和if语句的结果都取决于输入a的值。
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
>>> a = torch.randn(size=(), requires_grad=True) # size=0表示a是标量
>>> d = f(a)
>>> d.backward()
>>> a.grad == d / a
tensor(True)1.5 自动求导 Q&A
Q1:ppt上隐式构造和显式构造看起来为啥差不多?
显式和隐式的差别其实就是数学上求梯度和python求梯度计算上的差别,不用深究
显式构造就是我们数学上正常求导数的求法,先把所有求导的表达式选出来再代值
Q2:需要正向和反向都算一遍吗?
需要正向先算一遍,自动求导时只进行反向就可以,因为正向的结果已经存储
Q3:为什么PyTorch会默认累积梯度
便于计算大批量;方便进一步设计
Q4:为什么深度学习中一般对标量求导而不是对矩阵或向量求导
loss一般都是标量
Q5:为什么获取.grad前需要backward
backward相当于告诉程序需要计算梯度,因为计算梯度的代价很大,默认不计算
Q6:pytorch或mxnet框架设计上可以实现矢量的求导吗
可以
2 概率
简单地说,机器学习就是做出预测。为此,我们需要使用概率学。概率是一种灵活的语言,用于说明我们的确定程度,并且它可以有效地应用于广泛的领域中。
2.1 基本概率论
以掷骰子为例,如果骰子是公平的,那么所有六个结果都有相同的可能发生,所以每个数字发生的概率为
。现实生活中要检查骰子是否有瑕疵, 唯一方法是多次投掷并记录结果。 对于每个值,一种自然的方法是将它出现的次数除以投掷的总次数, 即此事件(event)概率的估计值。 大数定律(law of large numbers)指示: 随着投掷次数的增加,这个估计值会越来越接近真实的潜在概率。 接下来用代码进行演示。
导入软件包
%matplotlib inline # IPython内置魔法函数(Magic Functions),可通过命令行语法形式来访问。
import torch
from torch.distributions import multinomial
from d2l import torch as d2l在统计学中,把从概率分布中抽取样本的过程称为抽样(sampling)。 笼统来说,可以把分布(distribution)看作对事件的概率分配。 将概率分配给一些离散选择的分布称为多项分布(multinomial distribution)。
为了抽取一个样本,即掷骰子,我们只需传入一个概率向量。 输出是另一个相同长度的向量:它在索引 处的值是采样结果中出现
的次数。
>>> fair_probs = torch.ones([6]) / 6 # tensor([0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.1667])
>>> multinomial.Multinomial(1, fair_probs).sample()
tensor([1., 0., 0., 0., 0., 0.])
在估计一个骰子的公平性时,我们希望从同一分布中生成多个样本。 如果用Python的for循环来完成这个任务,速度会慢得惊人。 因此我们使用深度学习框架的函数同时抽取多个样本,得到我们想要的任意形状的独立样本数组。
>>> multinomial.Multinomial(10, fair_probs).sample()
tensor([2., 3., 0., 2., 1., 2.])
知道如何对骰子采样后,我们模拟1000次投掷,然后统计每个数字被投中了多少次。 具体来说,我们计算相对频率,以作为真实概率的估计。
# 将结果存储为32位浮点数以进行除法
>>> counts = multinomial.Multinomial(1000, fair_probs).sample()
>>> counts / 1000 # 相对频率作为估计值
tensor([0.1600, 0.1680, 0.1710, 0.1670, 0.1670, 0.1670])我们也可以看到这些概率如何随着时间的推移收敛到真实概率。 让我们进行500组实验,每组抽取10个样本。
counts = multinomial.Multinomial(10, fair_probs).sample((500,))
cum_counts = counts.cumsum(dim=0)
estimates = cum_counts / cum_counts.sum(dim=1, keepdims=True)
d2l.set_figsize((6, 4.5))
for i in range(6):
d2l.plt.plot(estimates[:, i].numpy(),
label=("P(die=" + str(i + 1) + ")"))
d2l.plt.axhline(y=0.167, color='black', linestyle='dashed')
d2l.plt.gca().set_xlabel('Groups of experiments')
d2l.plt.gca().set_ylabel('Estimated probability')
d2l.plt.legend();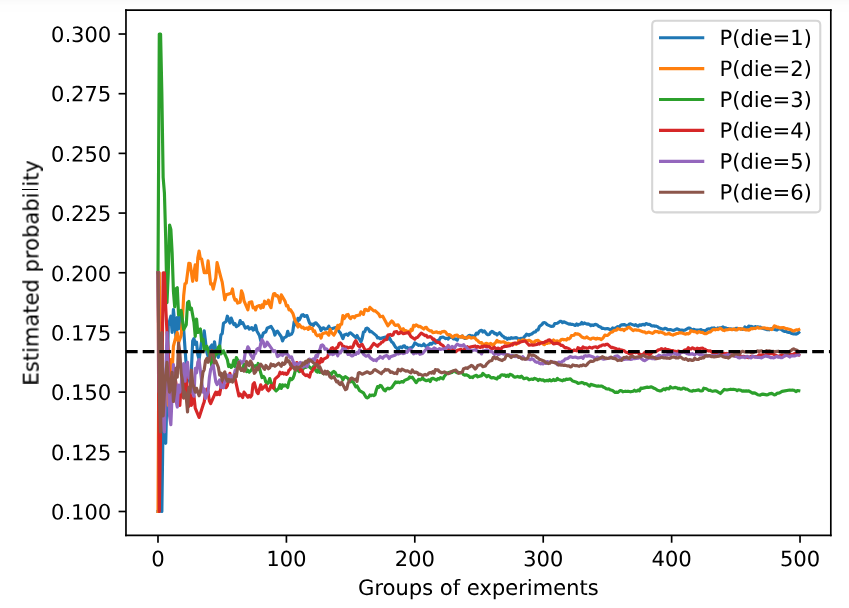
每条实线对应于骰子的6个值中的一个,并给出骰子在每组实验后出现值的估计概率。 当我们通过更多的实验获得更多的数据时,这条实体曲线向真实概率收敛。
2.1.1 概率论公理
在上面的案例中,将集合 S={1,···,6} 称为样本空间(sample space)或结果空间(outcome space),其中每个元素都是结果。事件(event)是一组给定样本空间的随机结果。例如,“看到5”({5})和“看到奇数”({1,3,5})都是掷出骰子的有效事件。注意,如果一个随机实验的结果在A中,则事件A已经发生,即如果掷出3点,则事件“看到奇数”发生了。
概率(probability)可以被认为是将集合映射到真实值的函数。在给定的样本空间S中,事件A的概率, 表示为P(A),满足以下属性:
- 对于任意事件A,其概率从不会是负数,即P(A) ≥ 0;
- 整个样本空间的概率为1,即P(S)=1;
- 互斥(mutually exclusive)事件指对于所有
都有
。若由互斥事件组成的可数序列为
,则该序列发生的概率等于其中任意一个事件各自发生的概率之和,即
。
2.1.2 随机变量
在掷骰子的随机实验中,可以引入随机变量(random variable)的概念。设掷骰子的样本空间S中有随机变量X。 事件“看到5”可表示为{X=5}或X=5,其概率表示为P({X=5})或P(X=5)。 P(X=a)可以区分随机变量X和X可以采取的值(如a)。为了简化符号,一方面可以将P(X)表示为随机变量X上的分布(distribution): 分布指示X获得某一值的概率。 另一方面可以简单用P(a)表示随机变量取值a的概率。 由于概率论中的事件是来自样本空间的一组结果,因此可以为随机变量指定值的可取范围。 例如,P(1≤X≤3)表示事件{1≤X≤3},即{X=1,2,or,3}的概率。
2.2 处理多个随机变量
很多时候会考虑多个随机变量,需要估计这些概率以及概率之间的关系,以便实现更好地推断。例如,在许多情况下,图像会附带一个标识图像中对象的标签,可以将标签视为一个随机变量,甚至可以将所有图像元数据视为随机变量,例如位置、时间、光圈、焦距、ISO等,所有这些都是联合发生的随机变量。
2.2.1 联合概率(joint probability)
联合概率可以回答A=a和B=b同时满足的概率是多少?对于任何a和b的取值,是确定的,因为要同时发生A=a和B=b,A=a就必须发生。因此,A=a和B=b同时发生的可能性不大于A=a或B=b单独发生的可能性。
2.2.2 条件概率(conditional probability)
通过联合概率的不等式可以得到,这被称为条件概率,并用
表示,即它是在A=a已发生的前提下,B=b的概率。
2.2.3 贝叶斯定理(Bayes定理,Bayes’ theorem)
使用条件概率的定义,可以得出统计学中最有用的方程之一: Bayes定理。 根据乘法法则(multiplication rule )可得到。 根据对称性,可得到
。 假设P(B)>0,求解其中一个条件变量,可得:
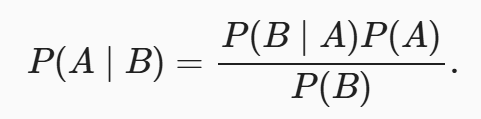
其中,P(A,B)是一个联合分布,P(A∣B)是一个条件分布。
2.2.4 边际化(marginalization)
为了能进行事件概率求和,需要求和法则, 即B的概率相当于计算A的所有可能选择,并将所有选择的联合概率聚合在一起,这也称为边际化。
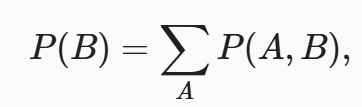
边际化结果的概率或分布称为边际概率(marginal probability)或边际分布(marginal distribution)。
2.2.5 独立性
依赖(dependence)与独立(independence)。 如果两个事件A和B是独立的,则A的发生跟B的发生无关,统计学家常将这一点表述为A⊥B。根据贝叶斯定理,可得P(A∣B)=P(A)。 在所有其他情况下,称A和B依赖。
由于等价于
,因此两个随机变量是独立的,当且仅当两个随机变量的联合分布是其各自分布的乘积。 同样地,给定另一个随机变量C时,两个随机变量A和B是条件独立的(conditionally independent), 当且仅当
。 这个情况表示为
。
2.3 期望和方差
为了概括概率分布的关键特征,我们需要一些测量方法。 一个随机变量 X 的期望(expectation,或平均值(average))表示为
![]()
当函数 f(x) 的输入是从分布P中抽取的随机变量时,f(x) 的期望值为
![]()
为了衡量随机变量 X 与其期望值的偏置,使用方差来量化
![]()
方差的平方根被称为标准差。 随机变量函数的方差衡量的是:当从该随机变量分布中采样不同值时, 函数值偏离该函数期望的程度。
![]()
总结:
-
可以从概率分布中采样。
-
可以使用联合分布、条件分布、Bayes定理、边缘化和独立性假设来分析多个随机变量。
-
期望和方差为概率分布的关键特征的概括提供了实用的度量形式。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)