PyTorch深度学习实践(一)
首先定义前馈线性模型forward,然后定义了损失函数loss,接着用for循环穷举参数w,最后根据所得的数据绘制图像,可以观察到当w等于2时loss最小。前面的线性模型只有一个参数w,可以在合适的区间使用穷举的方法搜索参数w,但当模型有很多参数时,这种方法就不合适了。和线性回归相比多了sigmoid函数,损失函数也变成了BCE(交叉熵损失函数)。于是便引入了一个更好的方法——梯度下降算法来找到最
·
笔记来源:《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
一、线性模型
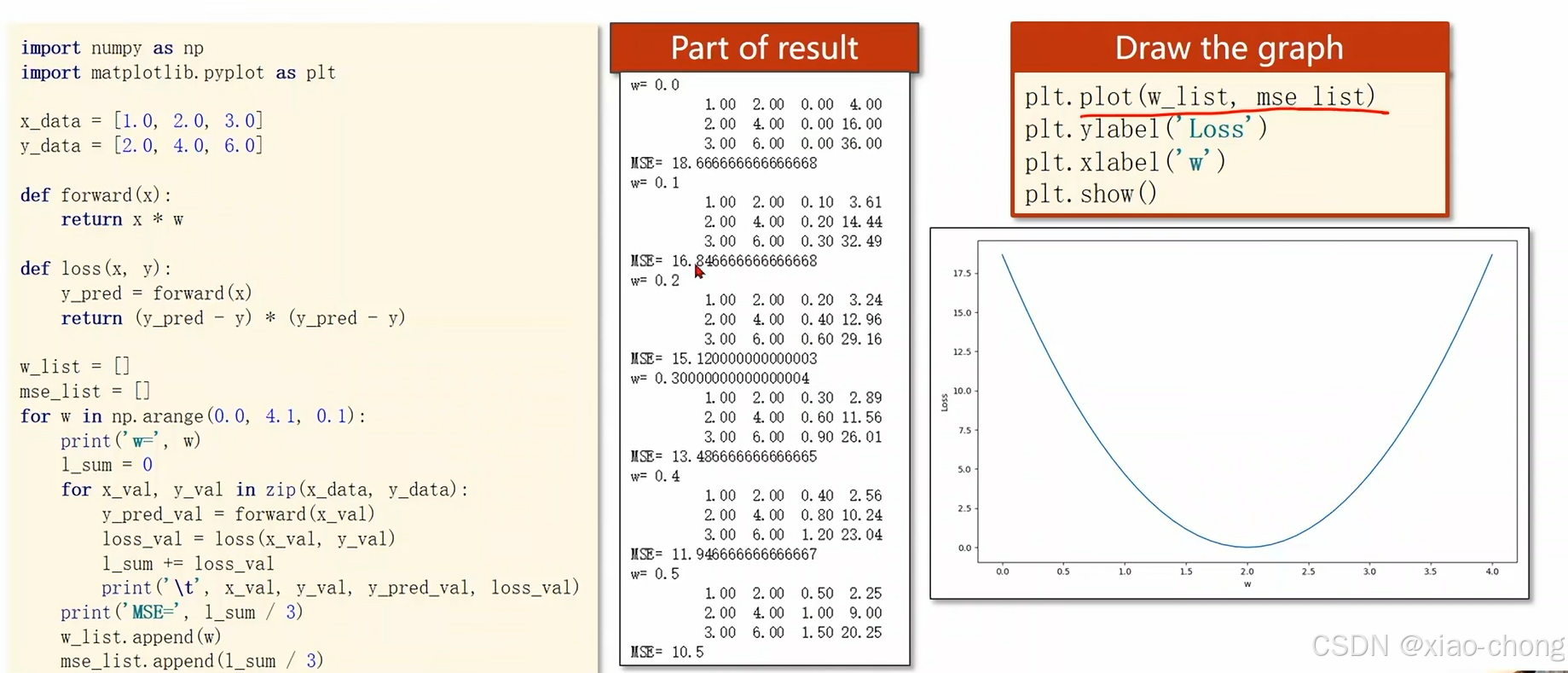
首先定义前馈线性模型forward,然后定义了损失函数loss,接着用for循环穷举参数w,最后根据所得的数据绘制图像,可以观察到当w等于2时loss最小。
二、梯度下降算法
前面的线性模型只有一个参数w,可以在合适的区间使用穷举的方法搜索参数w,但当模型有很多参数时,这种方法就不合适了
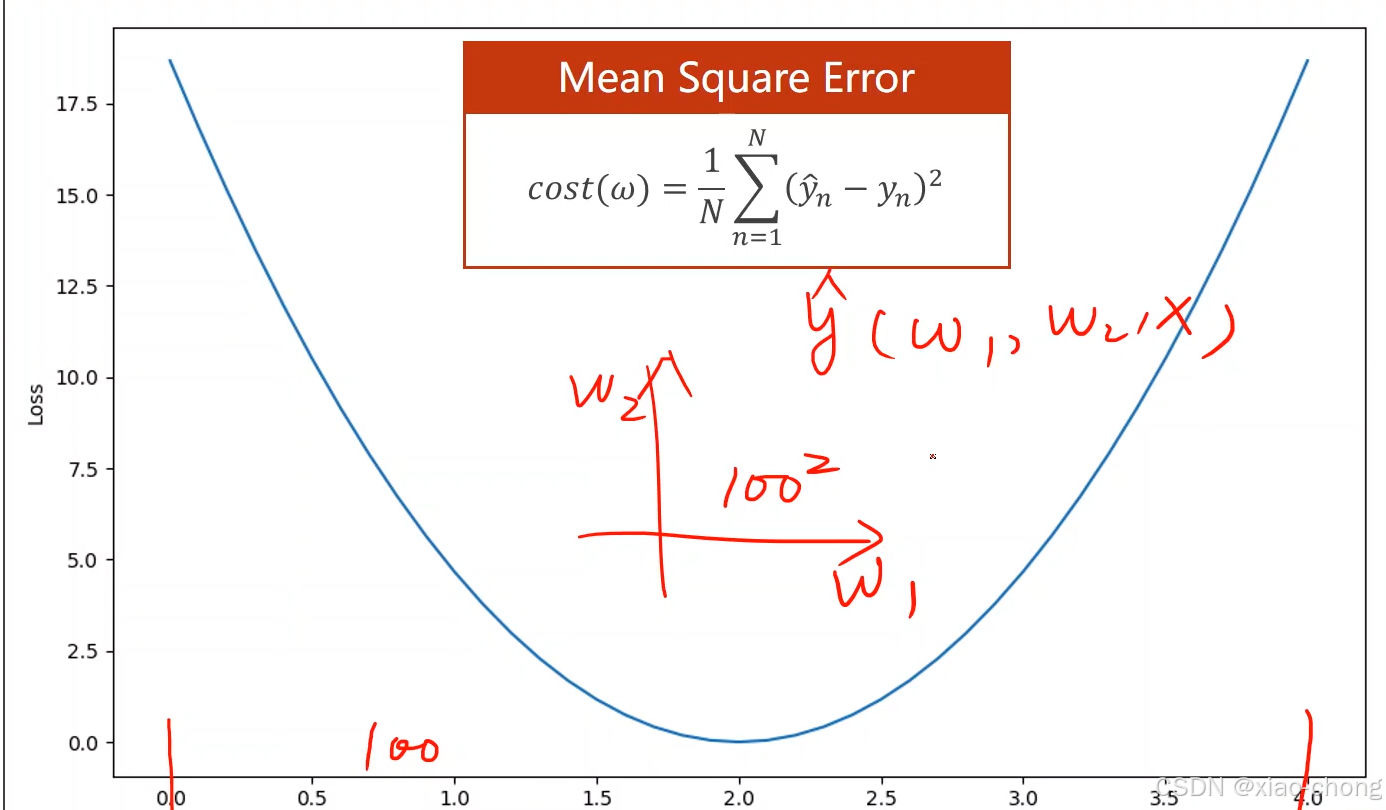
于是便引入了一个更好的方法——梯度下降算法来找到最优的参数w。
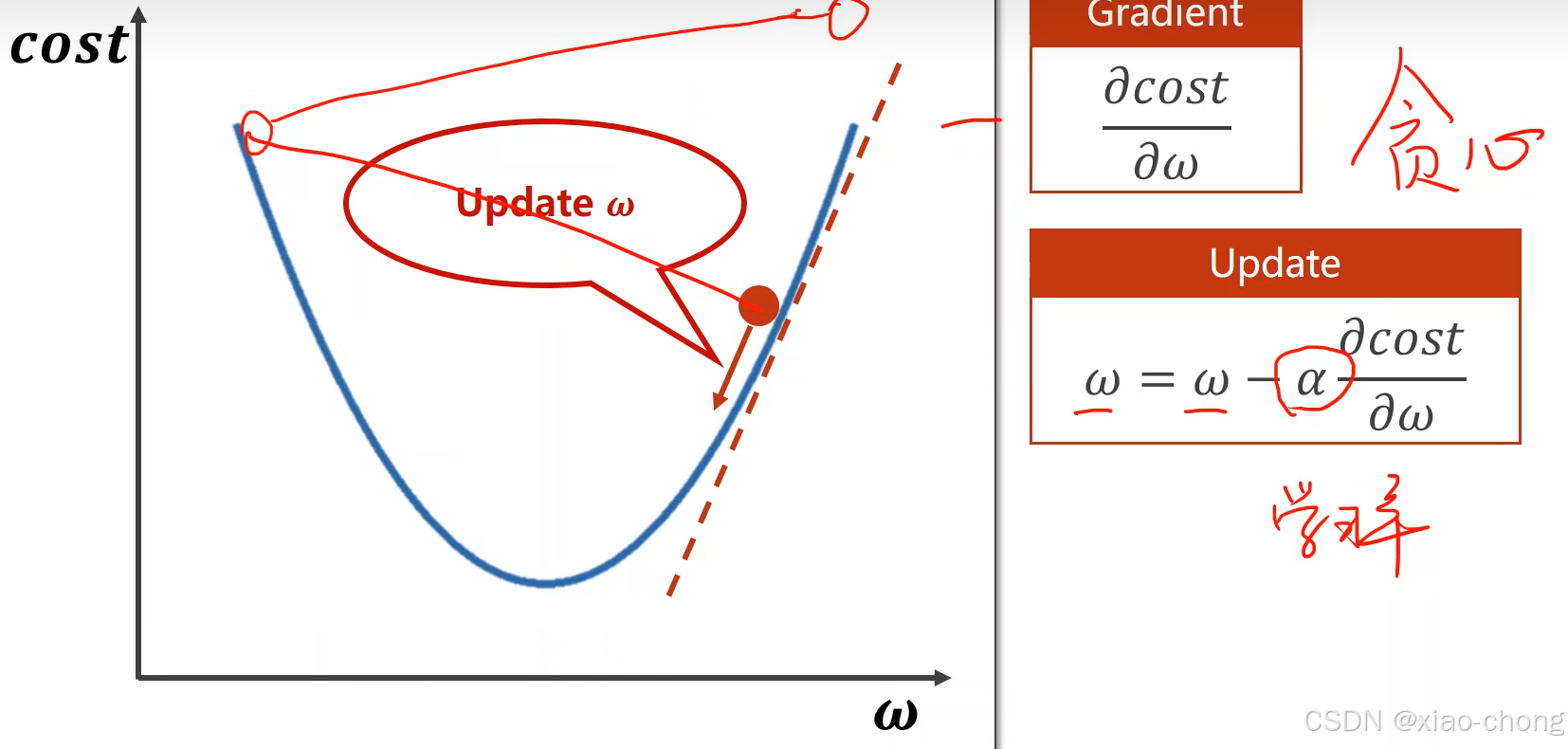
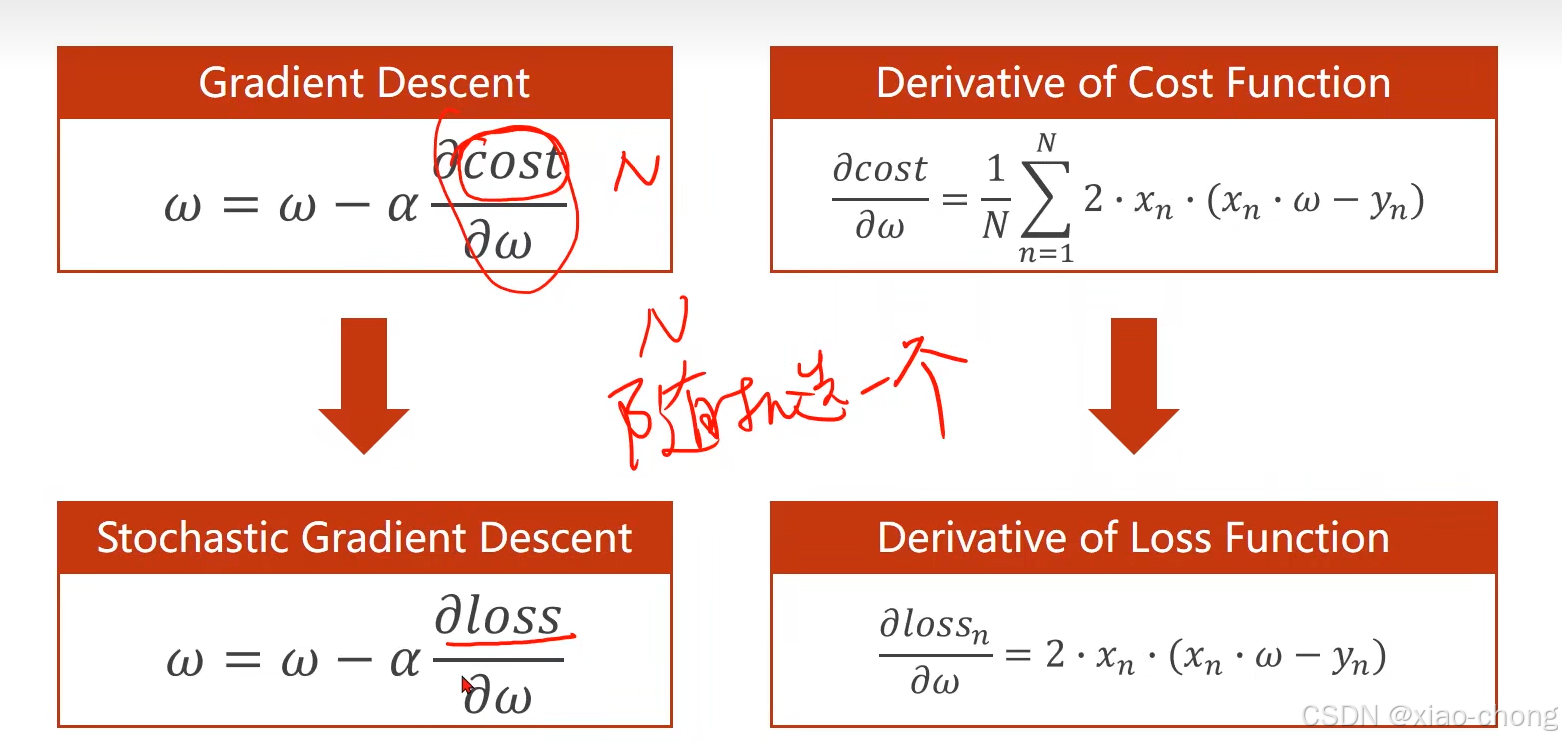
上图公式是梯度下降算法的核心公式
下面还是继续使用线性模型的那个例子计算:

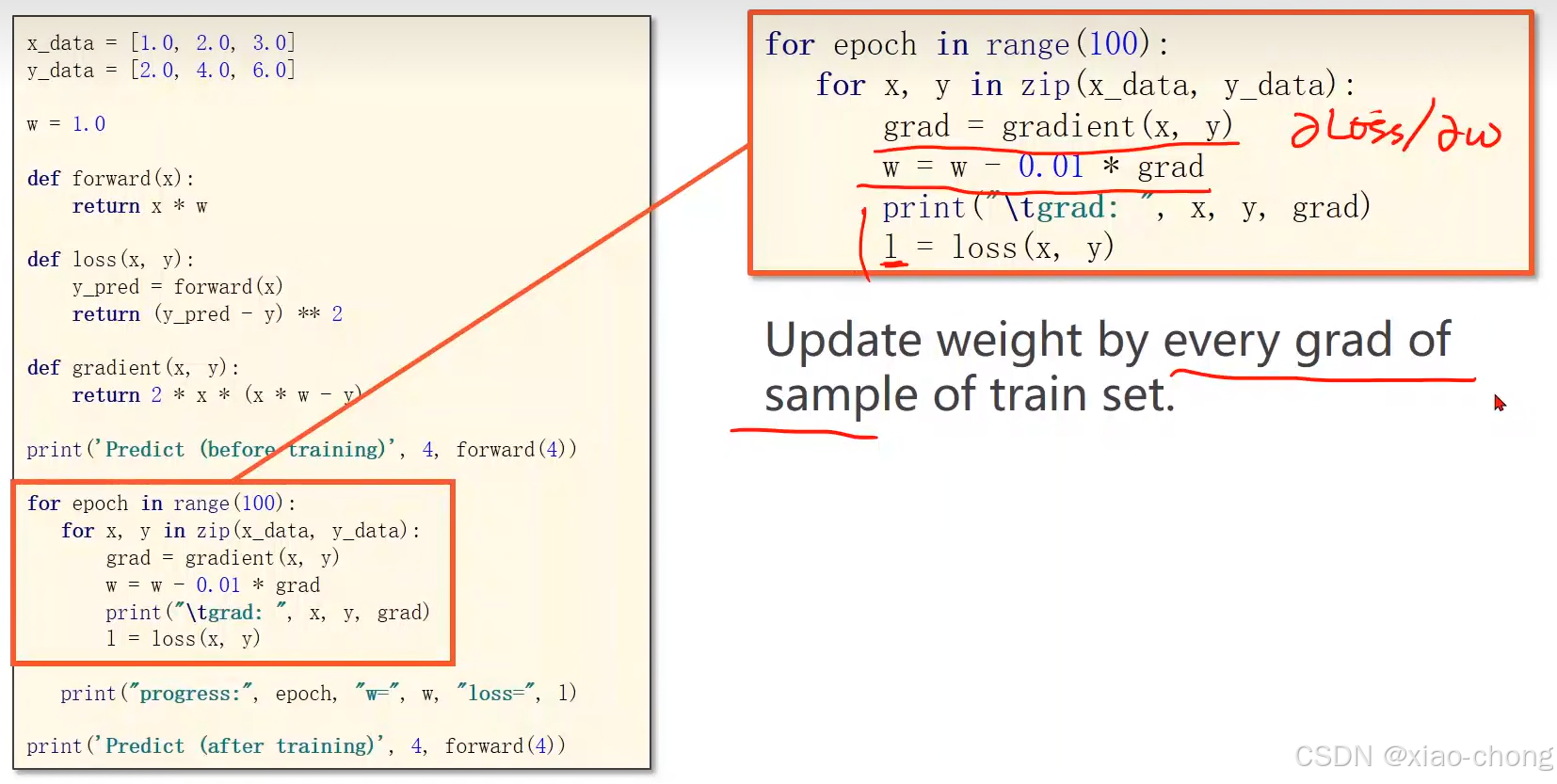
代码实现过程:
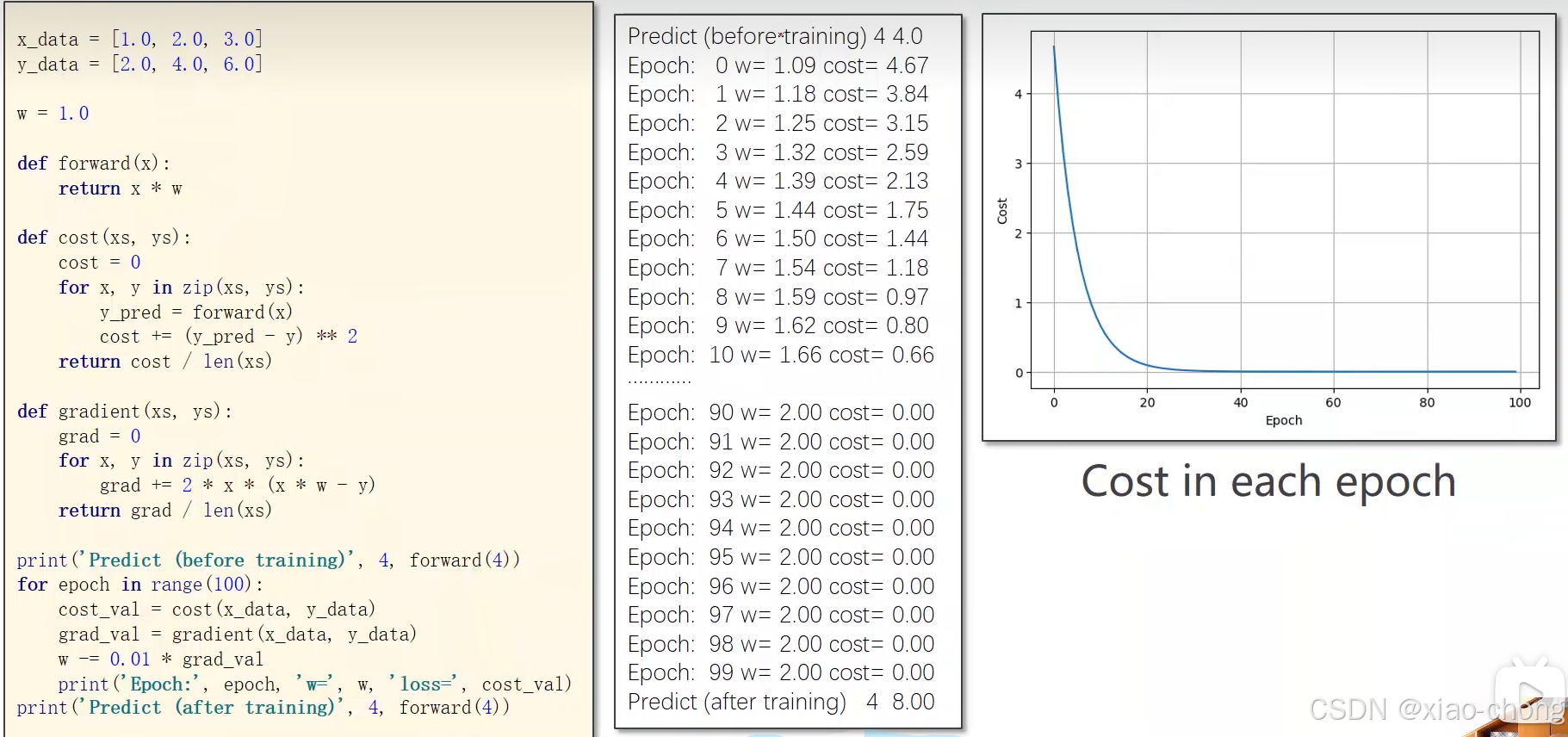
这里的for循环是循环的训练次数。
在深度学习中常用的是 随机梯度下降
 三、反向传播
三、反向传播
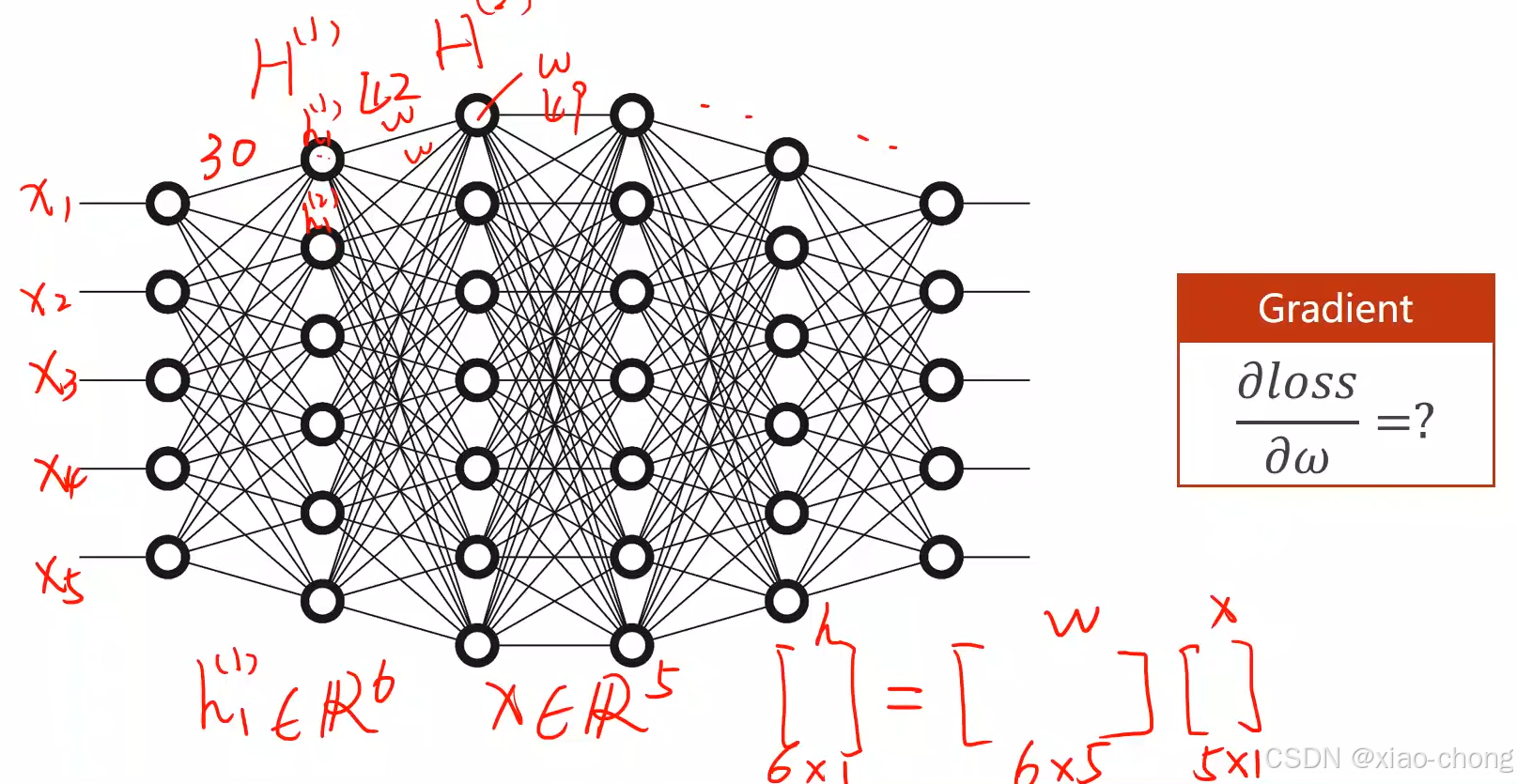
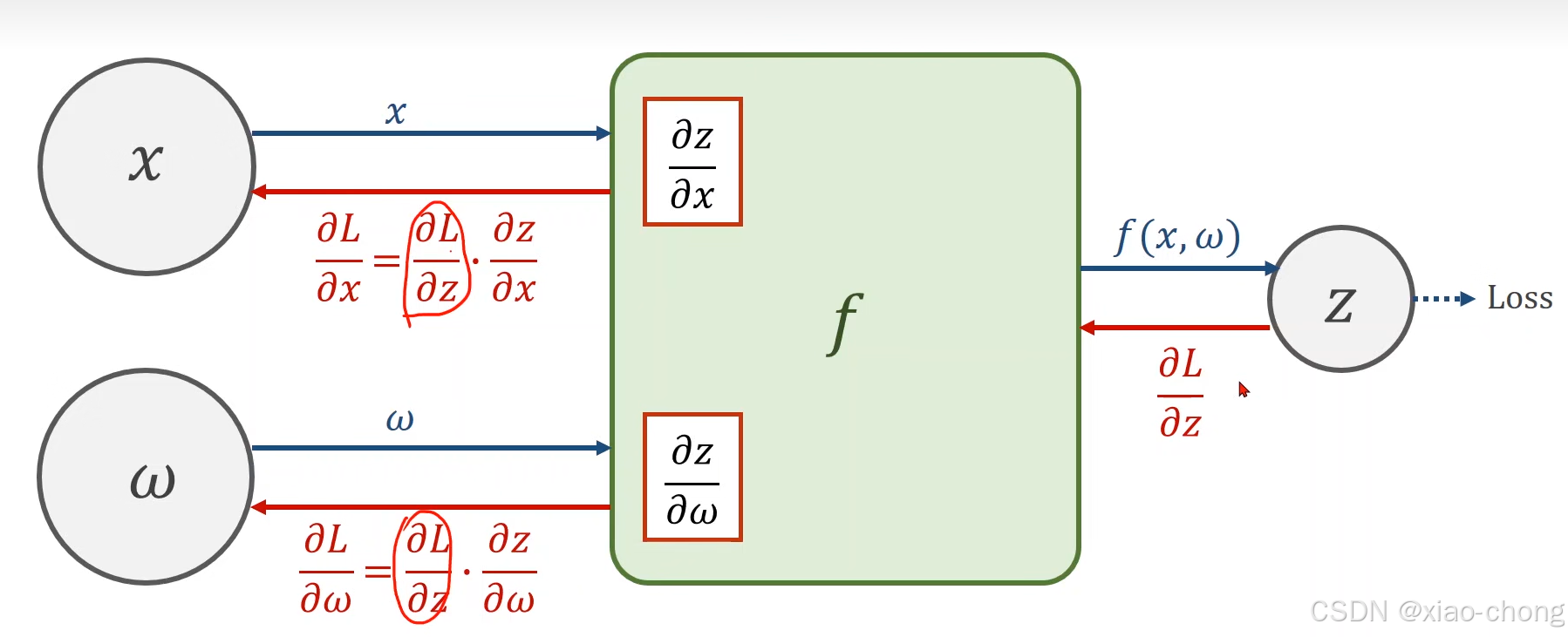
当神经网络层数比较多,参数比较多的时候,我们就不能像之前一样能直接写出梯度的解析式,这时需要使用反向传播来计算:

四、用PyTorch实现线性回归
代码:
import torch
x_data=torch.tensor([[1.0],[2.0],[3.0]])
y_data=torch.tensor([[2.0],[4.0],[6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel,self).__init__()
self.linear=torch.nn.Linear(1,1)
def forward(self,x):
y_pred=self.linear(x)
return y_pred
model=LinearModel()
#损失函数
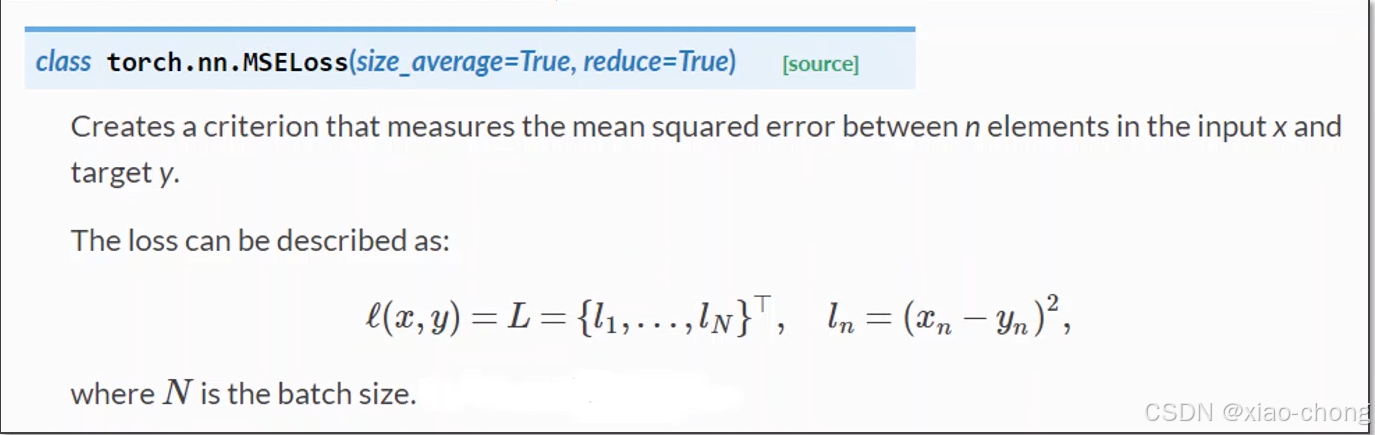
criterion=torch.nn.MSELoss(size_average=False)
#优化器
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(100):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
print(epoch,loss)
optimizer.zero_grad() #所有梯度归零
loss.backward()
optimizer.step() #权重更新
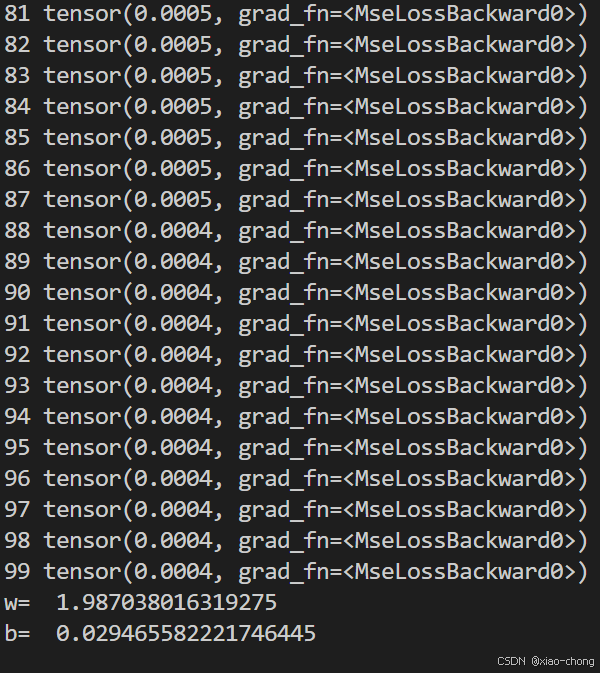
print("w= ",model.linear.weight.item())
print("b= ",model.linear.bias.item()) 结果:
代码中一些函数的调用方式:


五、逻辑斯蒂回归
这个叫回归实际上是个分类问题。
import torch
import torch.nn.functional as F
x_data=torch.tensor([[1.0],[2.0],[3.0]])
y_data=torch.tensor([[0.0],[0.0],[1.0]])
class LogisticRegressionModle(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModle,self).__init__()
self.linear=torch.nn.Linear(1,1)
def forward(self,x):
y_pred=F.sigmoid(self.linear(x))
return y_pred
modle= LogisticRegressionModle()
criterion=torch.nn.BCELoss(size_average=False)
optimizer=torch.optim.SGD(modle.parameters(),lr=0.01)
for epoch in range(1000):
y_pred=modle(x_data)
loss=criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step() 和线性回归相比多了sigmoid函数,损失函数也变成了BCE(交叉熵损失函数)。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)