python数据分析实验4:基于协同过滤的电影推荐系统从原理到代码实战
在大数据时代,推荐系统已成为解决信息过载的重要工具。其中,协同过滤(Collaborative Filtering)作为推荐系统的经典算法,通过分析用户与物品的交互行为,能够精准捕捉用户偏好,广泛应用于电商、流媒体等场景。本文将基于 Python 实现一个电影推荐系统,详细讲解用户 - 用户协同过滤(UBCF)和物品 - 物品协同过滤(IBCF)的核心逻辑,并提供完整的代码示例。
一、引言
在大数据时代,推荐系统已成为解决信息过载的重要工具。其中,协同过滤(Collaborative Filtering)作为推荐系统的经典算法,通过分析用户与物品的交互行为,能够精准捕捉用户偏好,广泛应用于电商、流媒体等场景。本文将基于 Python 实现一个电影推荐系统,详细讲解用户 - 用户协同过滤(UBCF)和物品 - 物品协同过滤(IBCF)的核心逻辑,并提供完整的代码示例。
二、技术原理:协同过滤核心概念
1. 协同过滤分类
- 用户 - 用户协同过滤(User-Based CF):通过计算用户之间的相似度,找到与目标用户兴趣相似的 “邻居用户”,基于邻居的历史行为生成推荐。
- 物品 - 物品协同过滤(Item-Based CF):计算物品之间的相似度,为用户推荐与其历史交互物品相似的其他物品。
2. 余弦相似度(Cosine Similarity)
用于衡量向量之间的相似程度,公式为:
cosine相似度=(A⋅B)/(∣∣A∣∣×∣∣B∣∣)
在推荐系统中,通过用户 - 物品评分矩阵构建向量,计算用户或物品之间的相似度。
三、代码实现:电影推荐系统构建
1. 数据准备
数据源自 MovieLens 数据集(ml-latest-small),由明尼苏达大学 GroupLens 研究组提供,包含 610 名用户对 9742 部电影的 100836 条评分和 3683 条标签,时间跨度为 1996 年 3 月 29 日至 2018 年 9 月 24 日。数据集聚焦用户对电影的 5 星评分和 自由文本标签,用户随机选取且至少评分 20 部电影,无 demographic 信息,仅以匿名 ID 标识。
字段说明
1. ratings.csv - 用户评分数据
- 字段:
userId, movieId, rating, timestamp - 说明:
userId:用户唯一标识(匿名化 ID,在ratings.csv和tags.csv中一致)。movieId:电影唯一标识(与 MovieLens 网站一致,如1对应 Toy Story)。rating:用户评分(0.5 星到 5 星,半星递增,如 3.0、4.5)。timestamp:评分时间戳(UTC 时间,从 1970 年 1 月 1 日午夜开始的秒数)。
- 数据组织:按
userId排序,同用户内按movieId排序。
2. movies.csv - 电影元数据
- 字段:
movieId, title, genres - 说明:
movieId:电影唯一标识(与其他文件一致)。title:电影标题(包含发行年份,如Toy Story (1995),可能存在人工录入或导入误差)。genres:电影类型(管道分隔列表,可选值包括 Action、Adventure、Comedy 等 19 种,无类型时标注(no genres listed))。
3. tags.csv - 用户标签数据
- 字段:
userId, movieId, tag, timestamp - 说明:
userId, movieId:同ratings.csv,标识用户和电影。tag:用户自定义标签(短文本,如 "funny"、"scifi",反映用户对电影的主观描述)。timestamp:标签添加时间戳(格式同评分时间戳)。
- 数据组织:按
userId排序,同用户内按movieId排序。
4. links.csv - 电影外部链接数据
- 字段:
movieId, imdbId, tmdbId - 说明:
movieId:电影唯一标识(与其他文件一致)。imdbId:IMDb 电影标识(如tt0114709对应 Toy Story 的 IMDb 页面)。tmdbId:The Movie Database (TMDb) 电影标识(如862对应 Toy Story 的 TMDb 页面)。
- 用途:用于关联外部电影数据库,获取更多元数据(如海报、剧情简介)。
数据格式与编码
- 所有文件为 UTF-8 编码的 CSV 格式,含单标题行,含逗号的字段用双引号转义(如电影标题
Misérables, Les (1995))。 - 数据可从 GroupLens 官网 公开下载,使用时需遵守 使用许可,引用请参考指定文献。
通过网盘分享的文件:协调算法电影数据
链接: https://pan.baidu.com/s/1ss7sm-PJdQGv1hpphFeEXw?pwd=1111 提取码: 1111
数据加载与清洗
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 加载数据
def load_data():
links = pd.read_csv('links.csv')
movies = pd.read_csv('movies.csv')
ratings = pd.read_csv('ratings.csv')
tags = pd.read_csv('tags.csv')
return links, movies, ratings, tags
# 数据准备:构建用户-电影评分矩阵
def data_preparation(ratings):
ratings = ratings.dropna() # 移除缺失值
# 转换为用户-电影矩阵,缺失值填充为0
user_movie_matrix = ratings.pivot(index='userId', columns='movieId', values='rating').fillna(0)
return user_movie_matrix2. 用户 - 用户协同过滤(UBCF)
核心逻辑:
- 计算用户之间的余弦相似度,找到相似用户;
- 从相似用户的评分中筛选目标用户未评分的电影。
# 用户-用户协同过滤
def user_based_collaborative_filtering(user_id, user_movie_matrix, top_n=5):
user_index = user_movie_matrix.index.get_loc(user_id) # 获取目标用户索引
similarity_matrix = cosine_similarity(user_movie_matrix) # 计算用户相似度矩阵
user_similarities = similarity_matrix[user_index] # 目标用户与所有用户的相似度
# 找到相似度最高的top_n用户(排除自身)
similar_users_indices = user_similarities.argsort()[-top_n - 1:-1][::-1]
similar_users = user_movie_matrix.index[similar_users_indices]
recommended_movies = []
for similar_user in similar_users:
# 提取相似用户评分>0且目标用户未评分的电影
similar_user_ratings = user_movie_matrix.loc[similar_user]
unrated_movies = similar_user_ratings[
(similar_user_ratings > 0) & (user_movie_matrix.loc[user_id] == 0)
]
recommended_movies.extend(unrated_movies.index)
return list(set(recommended_movies)) # 去重3. 物品 - 物品协同过滤(IBCF)
核心逻辑:
- 将用户 - 电影矩阵转置为电影 - 用户矩阵,计算电影之间的相似度;
- 推荐与用户历史评分电影相似的未评分电影。
# 物品-物品协同过滤
def item_based_collaborative_filtering(user_id, user_movie_matrix, top_n=5):
movie_user_matrix = user_movie_matrix.T # 转置为电影-用户矩阵
user_ratings = user_movie_matrix.loc[user_id] # 目标用户的评分
for movie_id in user_ratings[user_ratings > 0].index: # 遍历用户评分>0的电影
movie_index = movie_user_matrix.columns.get_loc(movie_id) # 获取电影索引
similarity_matrix = cosine_similarity(movie_user_matrix) # 计算电影相似度矩阵
movie_similarities = similarity_matrix[movie_index] # 目标电影与所有电影的相似度
# 找到相似度最高的top_n电影(排除自身)
similar_movies_indices = movie_similarities.argsort()[-top_n - 1:-1][::-1]
similar_movies = movie_user_matrix.index[similar_movies_indices]
# 筛选用户未评分的电影
for similar_movie in similar_movies:
if user_ratings[similar_movie] == 0:
recommended_movies.append(similar_movie)
return list(set(recommended_movies)) # 去重4. 推荐函数与结果展示
# 推荐主函数
def recommend_movies(user_id, user_movie_matrix, method='UBCF', top_n=5):
if method == 'UBCF':
return user_based_collaborative_filtering(user_id, user_movie_matrix, top_n)
elif method == 'IBCF':
return item_based_collaborative_filtering(user_id, user_movie_matrix, top_n)
else:
raise ValueError("无效的推荐方法,请选择'UBCF'或'IBCF'")
# 主程序
if __name__ == "__main__":
links, movies, ratings, tags = load_data()
user_movie_matrix = data_preparation(ratings)
target_user_id = 47 # 目标用户ID
recommendation_method = 'IBCF' # 可选'UBCF'或'IBCF'
recommended_movie_ids = recommend_movies(target_user_id, user_movie_matrix, method=recommendation_method)
recommended_movies = movies[movies['movieId'].isin(recommended_movie_ids)]
print(f"为用户 {target_user_id} 使用 {recommendation_method} 推荐的电影:")
print(recommended_movies[['movieId', 'title', 'genres']])四、结果展示
运行代码后,输出类似以下结果(以用户 ID=47,IBCF 方法为例):
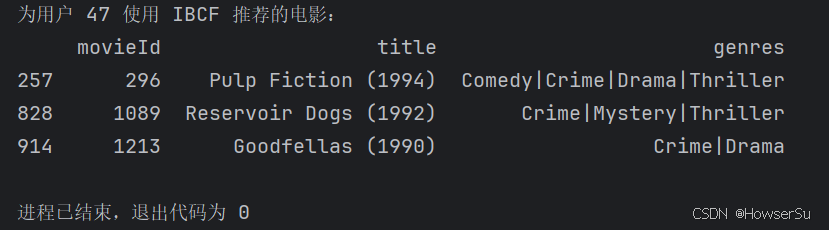
五、总结与改进方向
1. 优点
- 原理简单:无需物品或用户的额外特征,仅依赖交互数据即可实现。
- 可解释性:推荐结果基于用户或物品的相似性,逻辑清晰。
2. 局限性
- 冷启动问题:新用户或新物品缺乏交互数据时,推荐效果差。
- 稀疏性问题:评分矩阵稀疏时,相似度计算不准确。
3. 改进方向
- 混合推荐:结合内容过滤(如电影类型、导演等特征)提升推荐效果。
- 矩阵分解:使用 SVD 等方法处理稀疏矩阵,降低维度。
- 深度学习:引入神经网络(如 Neural Collaborative Filtering)挖掘非线性关系。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)