基于深度学习的屠宰厂生猪无序识别计数算法开发与应用
收藏关注不迷路!!
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
前言
随着经济现代化的不断发展,人们的物质需求不断增加,对猪肉的需求一直在增长,以家庭为主的小型生猪屠宰场将逐渐满足不了市场快速增长的需求,在激烈的竞争中逐渐显露出劣势被市场淘汰,而大规模的集约式的生猪屠宰场将成为市场的主流。在传统的小型生猪屠宰场,因为生猪数量少、场地小,这给人工进行计数带来很多便利。在传统的小型生猪屠宰场中的工作人员需要完全依靠自己对猪场进行检查监控,他们需要不间断的进行生猪的计数,消耗工作人员大量的体力,而且工作十分枯燥无趣,可能会导致工作人员因疲劳疏忽工作而造成漏检错检。这种效率极低的计数方式不能符合大规模场的要求。在大规模的生猪屠宰场里需要使用更多的自动化方式来替代低效高昂难监管的人工方式,自动化监督、辅助管理等需求变得非常迫切。
课题研究的生猪无序识别计数算法,可以有效降低劳动力,代替人工进行高效的生猪计数、检测,并可以在后续通过数据可视化手段将数据以简单的图表展现,清晰明了地展示各类重要的数据,用更为高效的手段和更为节省的投入达到更好的经济效益。
详细视频演示
文章底部名片,联系我看更详细的演示视频
一、项目介绍
在《基于深度学习的实时母猪行为检测算法》中提到传统的方法主要是使用纯人工观察或人工查阅视频记录形式进行,需要消耗大量人力物力。机器视觉技术作为非侵入式监测的解决方案,在行为跟踪识别领域发挥着重要的作用。近年来,使用机器视觉技术对母猪行为检测进行研究成为热点。但是,当前检测方法大多以准确识别生猪个体作为前提,一般针对生猪的单一行为进行检测。当文提出了一种基于深度学习的母猪行为实时检测算法(Real-Time Sows Behaviors Detection Algorithm Based on Deep Learning,SBDA-DL),主要针对母猪的饮水行为、排尿行为和爬跨行为共三种行为进行实时检测[6]。
在《基于深度学习YOLOv4的舍养育肥猪行为识别》中提到为了增加生猪福利,实时检测猪只的健康状况,预防异常现象发生,试验进行了舍养育肥猪行为检测。该方法通过深度学习YOLO v4模型对猪只行为进行了训练,验证,测试和评估。结果表明:训练模型中猪只的躺卧,站立,进食,坐立和侵略性行为的识别精度分别为98.80%,95.05%,89.40%,79.41%,97.30%,平均精度为91.99%;利用该模型进行测试的精度分别为90.70%,90.16%,88.38%,80.75%,96.69%,平均精度则为89.34%。说明基于深度学习YOLOv4的舍养育肥猪行为识别模型有效克服了环境中不同光照强度和噪声的影响,达到了较好的识别效果,并且利用模型可以有效地检测猪只的侵略性行为[7]。
二、功能介绍
1.数据采集与预处理:
数据集的采集可以自行设计并采集生猪在屠宰场的视频。在屠宰场通道的正上方架设垂直于地面的监控摄像头,对生猪经过通道进行全天候拍摄,将得到的相关数据通过计算机视觉算法进行处理。将得到的数据集划分为训练集和测试集,其中训练集用于模型训练,测试集用于模型评估。
2.深度学习模型设计与训练:
采用YOLO算法进行目标检测,以识别屠宰场中的生猪。首先根据收集好的数据集,使用YOLO算法来进行模型训练。在训练过程中,采用适当的损失函数来度量目标检测的误差,并采用优化算法来更新模型参数。及时调整模型的超参数(如学习率、批大小等),以提高模型的性能。
采用DeepSORT算法对被检测到的生猪进行无序目标跟踪和计数。对于每一帧图像或视频,使用YOLO模型检测生猪目标,并获取其位置信息以及类别信息。对于每个检测到的生猪目标,从图像中提取特征向量,可以使用深度学习模型提取特征。将上一步得到的生猪目标特征向量输入到DeepSORT算法中,进行目标匹配和轨迹初始化。在轨迹初始化阶段,DeepSORT会为每个生猪目标分配一个唯一的ID,并初始化其轨迹信息。在连续的帧中,使用已经初始化的轨迹信息对生猪目标进行跟踪。对于每一帧中检测到的生猪目标,利用目标特征向量进行目标匹配,将其关联到已有的轨迹上,并更新轨迹信息。在每一帧中,遍历所有被跟踪的生猪目标。判断每个目标的ID是否在之前出现过,以识别新生猪目标。对于新的生猪目标,进行计数操作,并将其ID保存到一个字典或列表中,以便后续判断是否为新目标。
三、核心代码
部分代码:
from ultralytics import YOLO
import cv2
import numpy as np
import tempfile
from pathlib import Path
from tqdm.auto import tqdm
import os
from moviepy.editor import VideoFileClip
import ffmpeg
import datetime
import deep_sort.deep_sort.deep_sort as ds
import gradio as gr
# 控制处理流程是否终止
should_continue = True
current_time = datetime.datetime.now()
formatted_time = current_time.strftime("%Y-%m-%d_%H-%M-%S")
def get_detectable_classes(model_file):
"""获取给定模型文件可以检测的类别。
参数:
- model_file: 模型文件名。
返回:
- class_names: 可检测的类别名称。
"""
model = YOLO(model_file)
class_names = list(model.names.values()) # 直接获取类别名称列表
del model # 删除模型实例释放资源
return class_names
# 用于终止视频处理
def stop_processing():
global should_continue
should_continue = False # 更改变量来停止处理
return "尝试终止处理..."
# 用于开始视频处理
# gr.Progress(track_tqdm=True)用于捕获tqdm进度条,从而在GUI上显示进度
def start_processing(input_path, progress=gr.Progress(track_tqdm=True)):
print('************', input_path)
global should_continue
should_continue = True
detect_class = int(0)
model = YOLO('runs/v8-4-pose-all2/weights/best.pt')
tracker = ds.DeepSort("deep_sort/deep_sort/deep/checkpoint/ckpt.t7")
output_video_path = detect_and_track(input_path, './output', detect_class, model, tracker)
clip = VideoFileClip("./output/output.avi")
clip.write_videofile("./output/output.mp4")
return "./output/output.mp4", "./output/output.mp4"
# return output_video_path
def putTextWithBackground(
img,
text,
origin,
font=cv2.FONT_HERSHEY_SIMPLEX,
font_scale=1,
text_color=(255, 255, 255),
bg_color=(0, 0, 0),
thickness=1,
):
"""绘制带有背景的文本。
:param img: 输入图像。
:param text: 要绘制的文本。
:param origin: 文本的左上角坐标。
:param font: 字体类型。
:param font_scale: 字体大小。
:param text_color: 文本的颜色。
:param bg_color: 背景的颜色。
:param thickness: 文本的线条厚度。
"""
# 计算文本的尺寸
(text_width, text_height), _ = cv2.getTextSize(text, font, font_scale, thickness)
# 绘制背景矩形
bottom_left = origin
top_right = (origin[0] + text_width, origin[1] - text_height - 5) # 减去5以留出一些边距
cv2.rectangle(img, bottom_left, top_right, bg_color, -1)
# 在矩形上绘制文本
text_origin = (origin[0], origin[1] - 5) # 从左上角的位置减去5来留出一些边距
cv2.putText(
img,
text,
text_origin,
font,
font_scale,
text_color,
thickness,
lineType=cv2.LINE_AA,
)
def extract_detections(results, detect_class):
"""
从模型结果中提取和处理检测信息。
- results: YoloV8模型预测结果,包含检测到的物体的位置、类别和置信度等信息。
- detect_class: 需要提取的目标类别的索引。
参考: https://docs.ultralytics.com/modes/predict/#working-with-results
"""
# 初始化一个空的二维numpy数组,用于存放检测到的目标的位置信息
# 如果视频中没有需要提取的目标类别,如果不初始化,会导致tracker报错
detections = np.empty((0, 4))
confarray = [] # 初始化一个空列表,用于存放检测到的目标的置信度。
# 遍历检测结果
# 参考:https://docs.ultralytics.com/modes/predict/#working-with-results
for r in results:
for box in r.boxes:
# 如果检测到的目标类别与指定的目标类别相匹配,提取目标的位置信息和置信度
if box.cls[0].int() == detect_class:
x1, y1, x2, y2 = box.xywh[0].int().tolist() # 提取目标的位置信息,并从tensor转换为整数列表。
conf = round(box.conf[0].item(), 2) # 提取目标的置信度,从tensor中取出浮点数结果,并四舍五入到小数点后两位。
detections = np.vstack((detections, np.array([x1, y1, x2, y2]))) # 将目标的位置信息添加到detections数组中。
confarray.append(conf) # 将目标的置信度添加到confarray列表中。
return detections, confarray # 返回提取出的位置信息和置信度。
# 视频处理
def detect_and_track(input_path: str, output_path: str, detect_class: int, model, tracker) -> Path:
"""
处理视频,检测并跟踪目标。
- input_path: 输入视频文件的路径。
- output_path: 处理后视频保存的路径。
- detect_class: 需要检测和跟踪的目标类别的索引。
- model: 用于目标检测的模型。
- tracker: 用于目标跟踪的模型。
"""
global should_continue
output_file = f'./output/{formatted_time}.mp4'
ffmpeg.input(input_path).output(output_file, vcodec='libx264').run()
cap = cv2.VideoCapture(output_file) # 使用OpenCV打开视频文件。
if not cap.isOpened(): # 检查视频文件是否成功打开。
print(f"Error opening video file {input_path}")
return None
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数
fps = cap.get(cv2.CAP_PROP_FPS) # 获取视频的帧率
size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))) # 获取视频的分辨率(宽度和高度)。
output_video_path = Path(output_path) / "output.avi" # 设置输出视频的保存路径。
# 设置视频编码格式为XVID格式的avi文件
# 如果需要使用h264编码或者需要保存为其他格式,可能需要下载openh264-1.8.0
# 下载地址:https://github.com/cisco/openh264/releases/tag/v1.8.0
# 下载完成后将dll文件放在当前文件夹内
fourcc = cv2.VideoWriter_fourcc(*"XVID")
output_video = cv2.VideoWriter(output_video_path.as_posix(), fourcc, fps, size, isColor=True) # 创建一个VideoWriter对象用于写视频。
# 对每一帧图片进行读取和处理
# 使用tqdm显示处理进度。
for _ in tqdm(range(total_frames)):
# 如果全局变量should_continue为False(通常由于GUI上按下Stop按钮),则终止目标检测和跟踪,返回已处理的视频部分
if not should_continue:
print('stopping process')
break
success, frame = cap.read() # 逐帧读取视频。
# 如果读取失败(或者视频已处理完毕),则跳出循环。
if not (success):
break
# 使用YoloV8模型对当前帧进行目标检测。
results = model(frame, stream=True)
# 从预测结果中提取检测信息。
detections, confarray = extract_detections(results, detect_class)
# 使用deepsort模型对检测到的目标进行跟踪。
resultsTracker = tracker.update(detections, confarray, frame)
for x1, y1, x2, y2, Id in resultsTracker:
x1, y1, x2, y2 = map(int, [x1, y1, x2, y2]) # 将位置信息转换为整数。
# 绘制bounding box和文本
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 255), 3)
putTextWithBackground(frame, str(int(Id)) + ' pig', (max(-10, x1), max(40, y1)), font_scale=1.5, text_color=(255, 255, 255), bg_color=(255, 0, 255))
output_video.write(frame) # 将处理后的帧写入到输出视频文件中。
output_video.release() # 释放VideoWriter对象。
cap.release() # 释放视频文件。
print(f'output dir is: {output_video_path}')
return output_video_path
if __name__ == "__main__":
# YoloV8、V9官方模型列表,从左往右由小到大,第一次使用会自动下载
model = 'runs/v8-4-pose-all2/weights/best.pt'
# 获取YoloV8模型可以检测的所有类别,默认调用model_list中第一个模型
detect_classes = get_detectable_classes(model)
output_dir = './output'
# 使用Gradio的Blocks创建一个GUI界面
# Gradio参考文档:https://www.gradio.app/guides/blocks-and-event-listeners
with gr.Blocks() as demo:
with gr.Tab("目标追踪"):
# 使用Markdown显示文本信息,介绍界面的功能
gr.Markdown(
"""
# 目标检测与跟踪
"""
)
# 行容器,水平排列元素
with gr.Row():
# 列容器,垂直排列元素
with gr.Column():
input_path = gr.Video(label="Input video") # 视频输入控件,用于上传视频文件
with gr.Row():
# 创建两个按钮控件,分别用于开始处理和停止处理
start_button = gr.Button("Process")
stop_button = gr.Button("Stop")
with gr.Column():
output = gr.Video() # 视频显示控件,展示处理后的输出视频
output_path = gr.Textbox(label="Output path") # 文本框控件,用于显示输出视频的文件路径
# 将按钮与处理函数绑定
start_button.click(start_processing, inputs=[input_path], outputs=[output, output_path])
stop_button.click(stop_processing)
demo.launch()
四、效果图
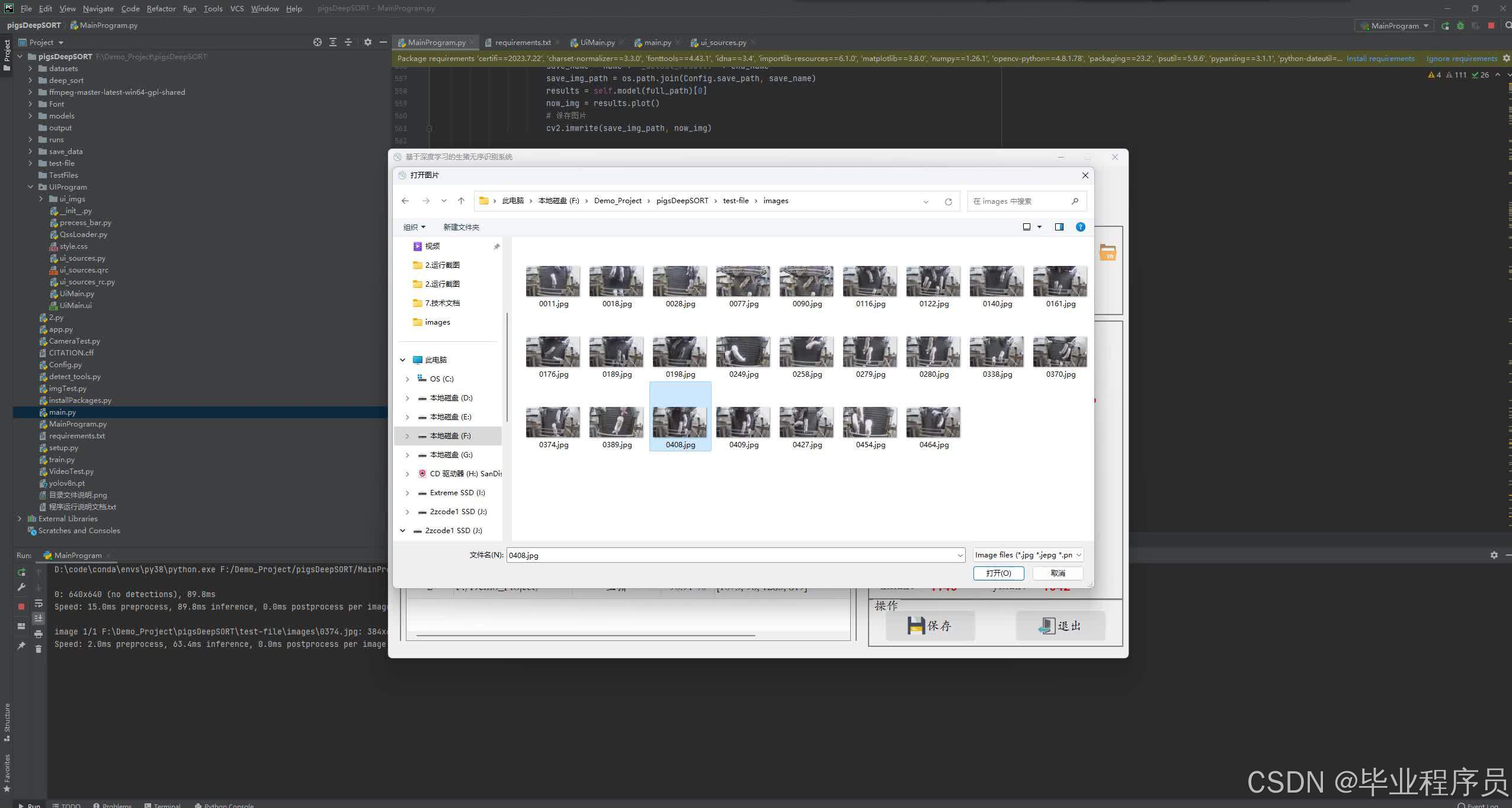
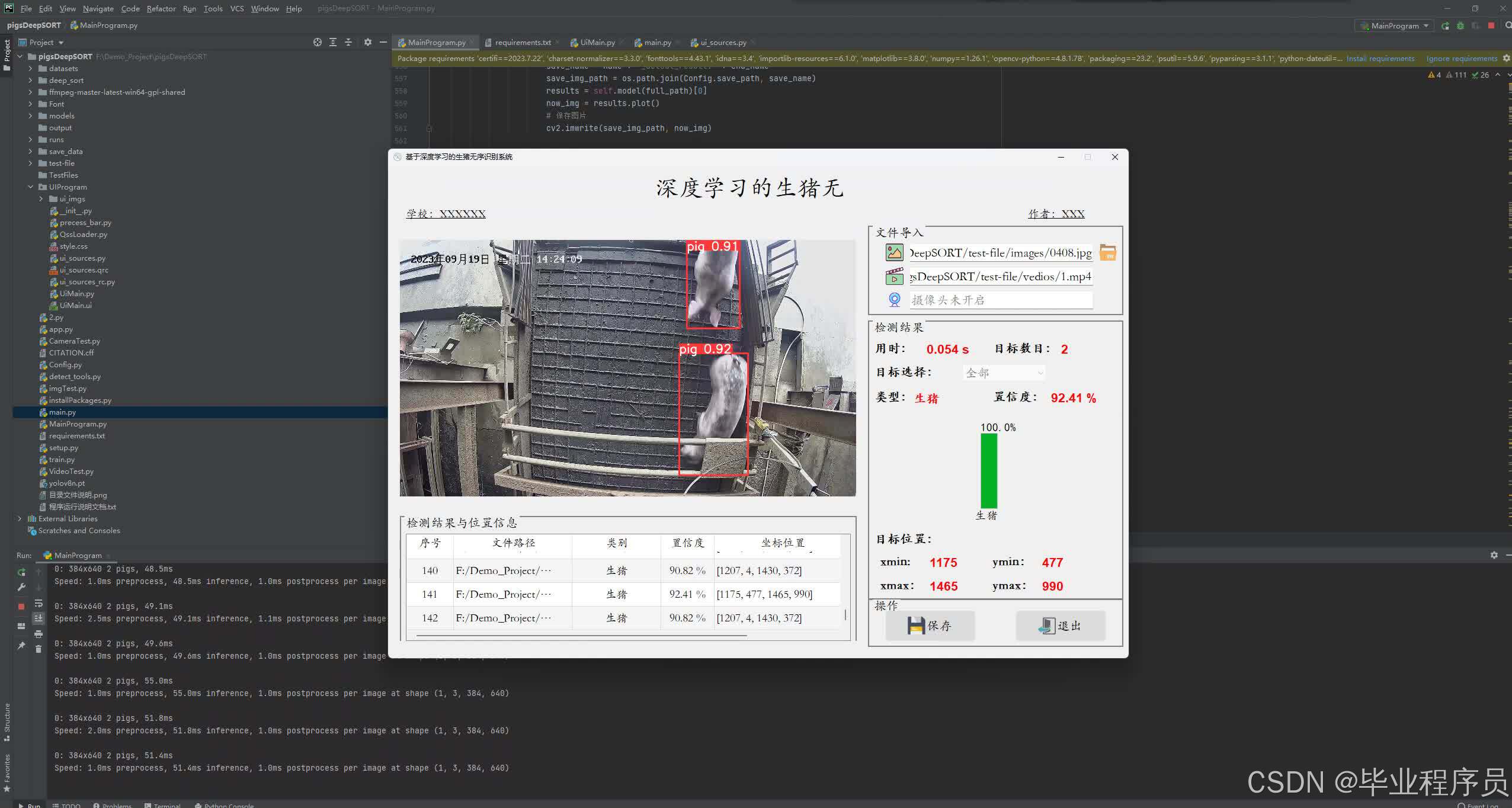
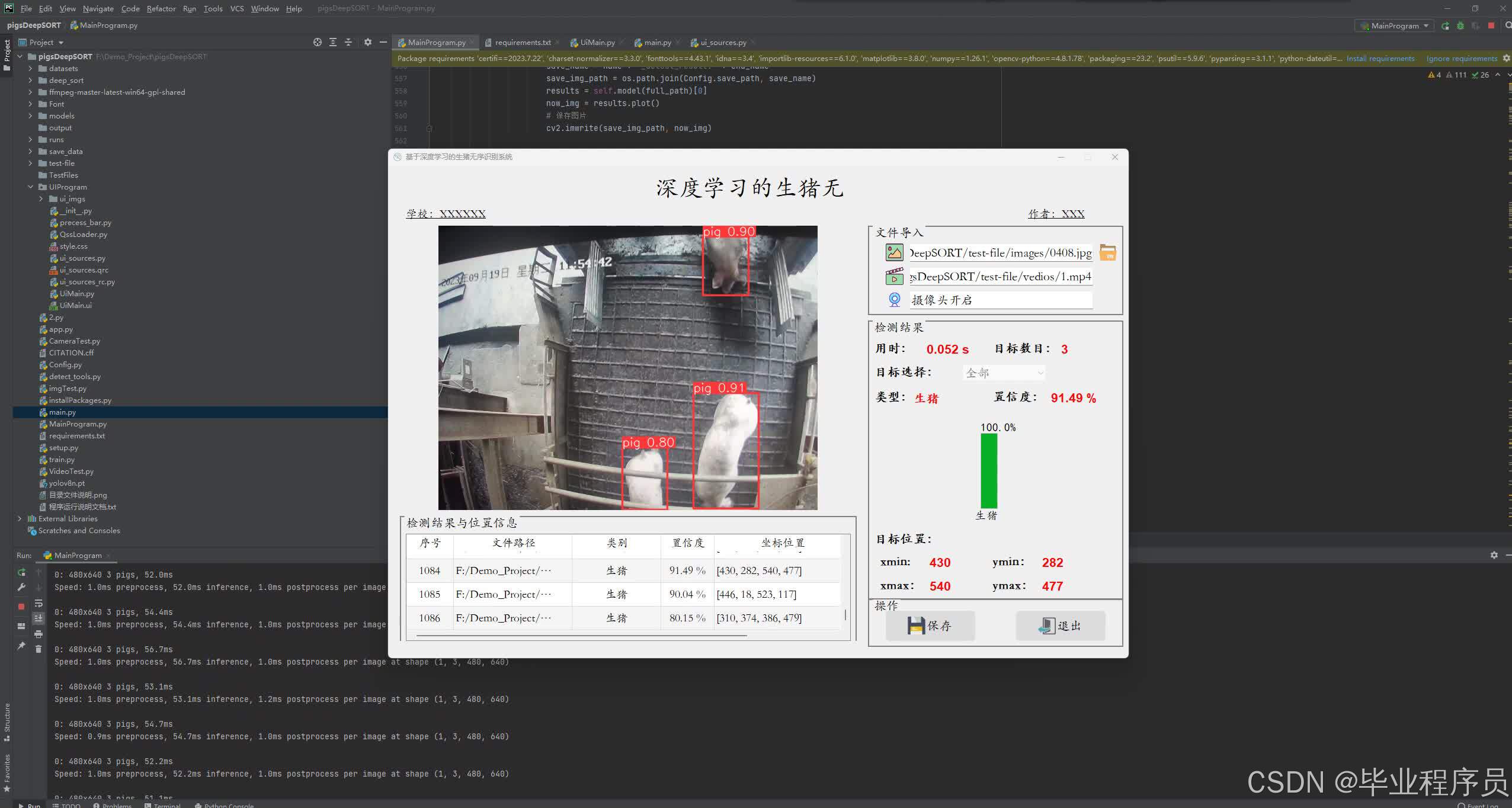
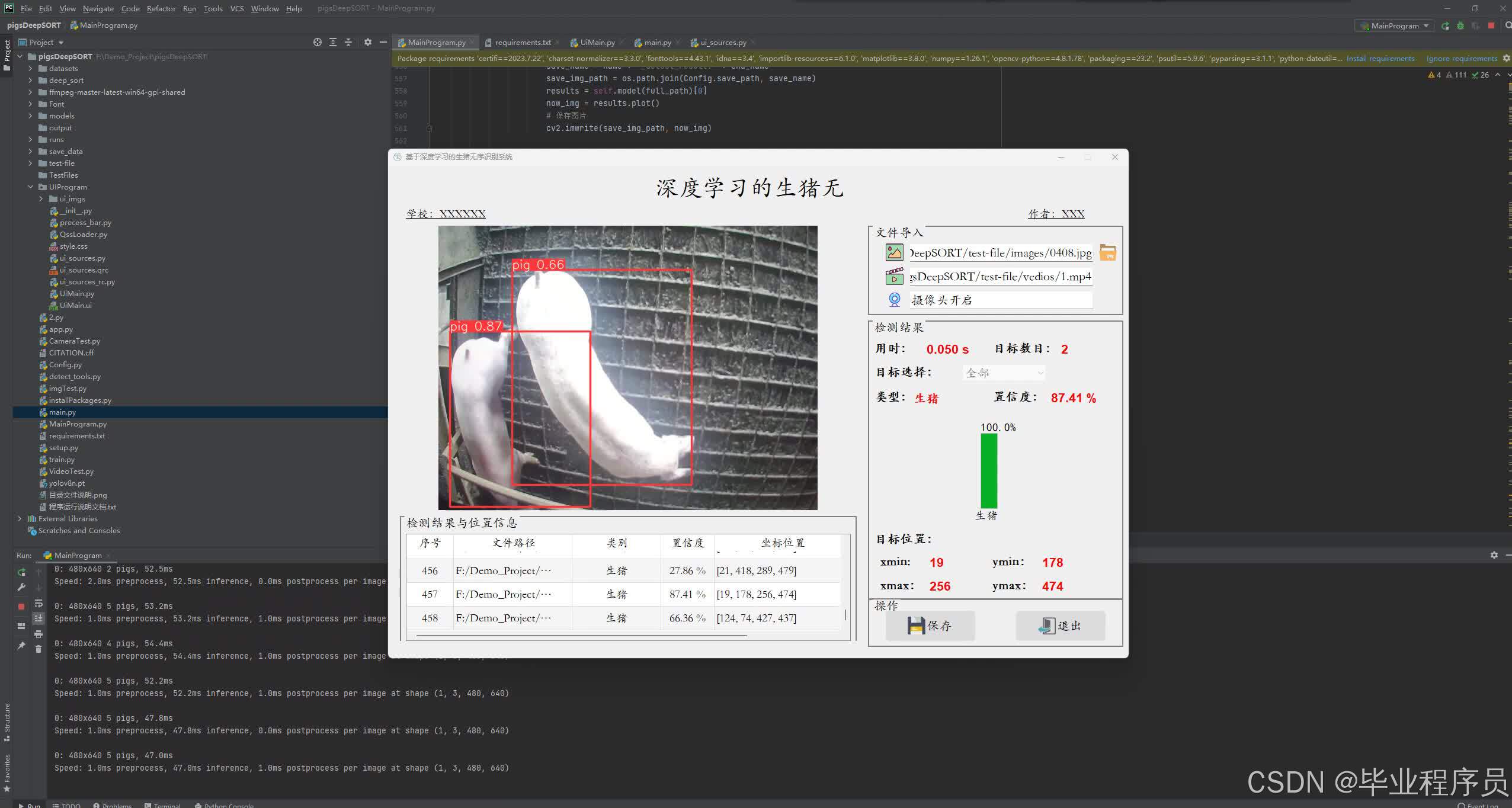
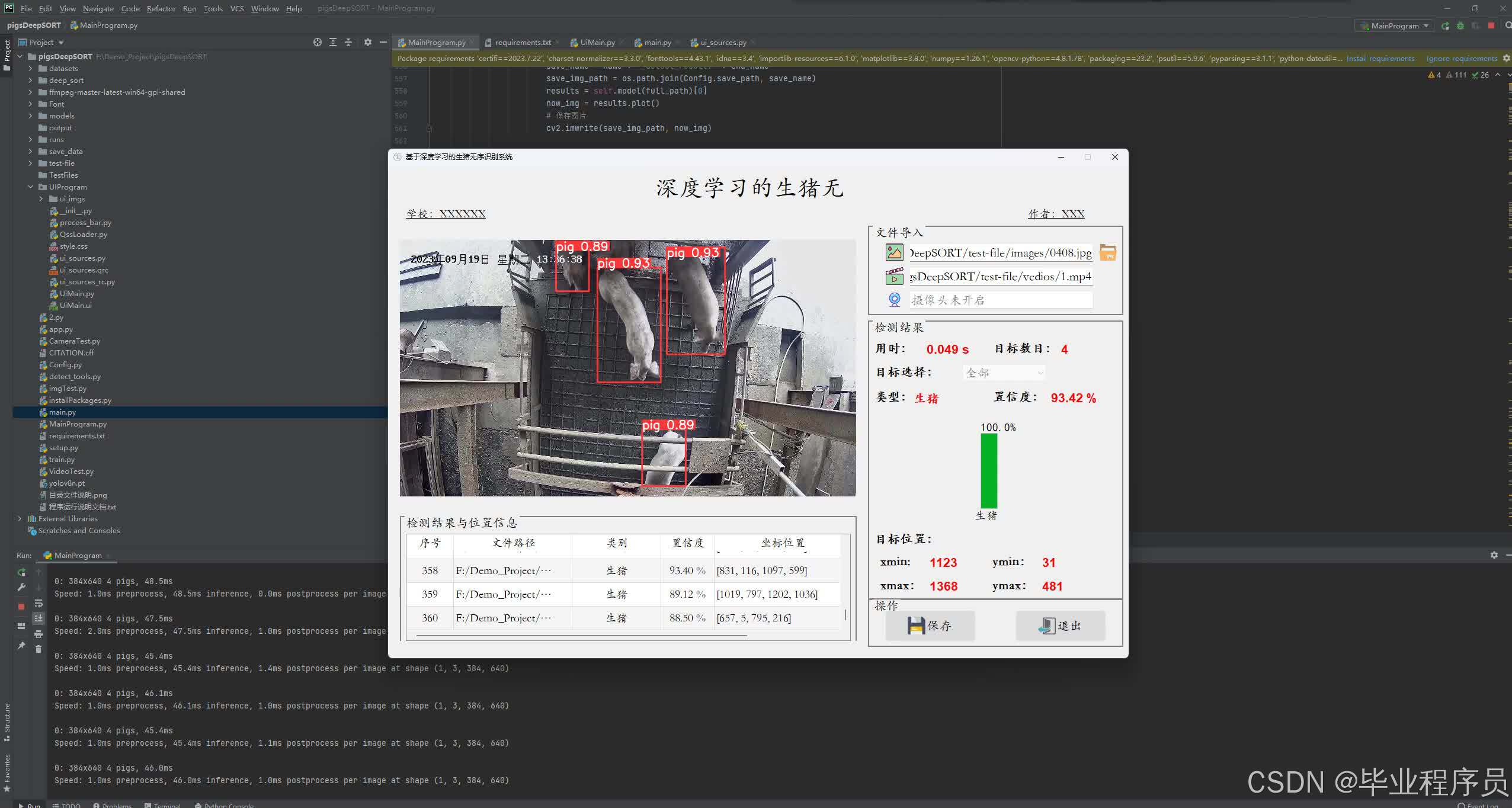
五、参考文献
[1]Huang Y, Liu J, et al. An Improved Pig Counting Algorithm Based on YOLOv5 and DeepSORT Model[J]. Sensors, 2023, 23(14): 6309.
[2]Wang Y, Yang D, Chen H, et al. Pig Counting Algorithm Based on Improved YOLOv5n Model with Multiscene and Fewer Number of Parameters[J]. Animals, 2023, 13(21): 3411.
[3]Liu C, Su J, Wang L, et al. LA-DeepLab V3+: a Novel Counting network for pigs[J]. Agriculture, 2022, 12(2): 284.
[4]Yunhao Du, Yang Song, Bo Yang, Yanyun Zhao. StrongSORT: Make DeepSORT Great Again. arXiv 2022.
[5]伍群旺,常满馨,马长华.基于卷积神经网络的生猪个体身份识别系统设计[J].电脑知识与技术:学术版, 2022, 18(31):14-16.
[6]嵇杨培,杨颖,刘刚.基于可见光光谱和YOLOv2的生猪饮食行为识别[J].光谱学与光谱分析, 2020, 40(5):7.DOI:10.3964/j.issn.1000-0593(2020)05-1588-07.
[7]季照潼,李东明,王娟,等.基于深度学习YOLOv4的舍养育肥猪行为识别[J].黑龙江畜牧兽医, 2021(000-014).
[8]嵇杨培,杨颖,刘刚.基于可见光光谱和YOLOv2的生猪饮食行为识别[J].光谱学与光谱分析, 2020, 40(5):7.DOI:10.3964/j.issn.1000-0593(2020)05-1588-07.
六 、源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 27
27 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)