深度学习入门(4):resnet50
ResNet架构极具通用性,之后的众多网络架构(如 ResNeXt、DenseNet、HRNet 等)都基于或借鉴了其残差结构。ResNet的提出解决了深层神经网络训练中的退化问题,使构建和优化超深网络成为可能,标志着深度学习进入更高层次发展的关键转折点。的网络(用于ImageNet竞赛),并在2015年ImageNet竞赛中取得冠军。:即网络越深,准确率反而变差。传统网络在超过20层时,训练效果
引言
ResNet的提出解决了深层神经网络训练中的退化问题,使构建和优化超深网络成为可能,标志着深度学习进入更高层次发展的关键转折点。本文依旧是借鉴pytorch实战8:手把手教你基于pytorch实现ResNet(长文)_resnet代码pytorch-CSDN博客,此处只是总结复习。
正文
ResNet创新点:

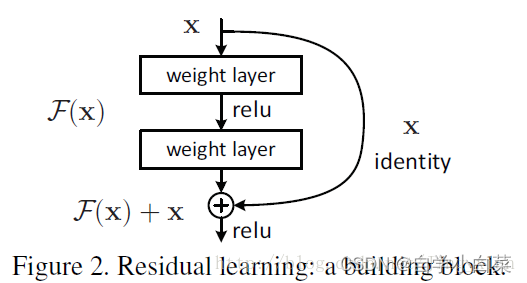
1. 残差学习(Residual Learning)
传统的深层神经网络在增加层数时会出现退化问题(Degradation Problem):即网络越深,准确率反而变差。ResNet 通过引入残差连接,让网络学习的是“残差”而非直接映射:
H(x)→F(x)+x
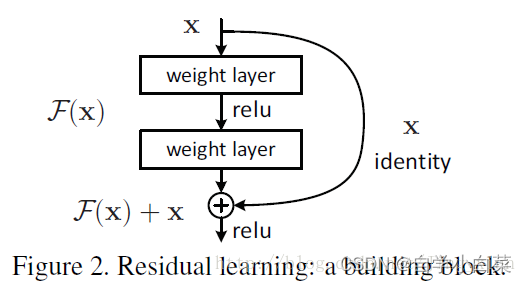
其中:
-
H(x):理想映射
-
F(x):需要学习的残差(即 H(x)−x)
-
x:输入
这种设计让网络更容易学习恒等映射(identity mapping),避免梯度消失或爆炸问题。
2. Shortcut Connection(跳跃连接)
ResNet 中每两个或三个卷积层后加入一个“快捷路径”,直接将输入加到输出上。这些不增加额外参数或计算量的连接使得信息能够直接在网络中传播,有助于深层网络的训练。
3. 极深网络的可训练性
传统网络在超过20层时,训练效果不理想,而ResNet成功地训练了高达152层的网络(用于ImageNet竞赛),并在2015年ImageNet竞赛中取得冠军。这表明残差结构显著提高了深层网络的可训练性和性能。
4. 通用性和可扩展性
ResNet架构极具通用性,之后的众多网络架构(如 ResNeXt、DenseNet、HRNet 等)都基于或借鉴了其残差结构。它也能很好地应用在图像分类、目标检测、语义分割等多个任务中。
ResNet实现:
1.网络模型
class My_Res_Block(nn.Module):
def __init__(self, in_planes, out_planes, stride=1, downsample=None):
'''
:param in_planes: 输入通道数
:param out_planes: 输出通道数
:param stride: 步长,默认为1
:param downsample: 是否下采样,主要是为了res+x中两者大小一样,可以正常相加
'''
super(My_Res_Block, self).__init__()
self.model = nn.Sequential(
# 第一层是1*1卷积层:只改变通道数,不改变大小
nn.Conv2d(in_planes, out_planes, kernel_size=1),
nn.BatchNorm2d(out_planes),
nn.ReLU(),
# 第二层为3*3卷积层,根据上图的介绍,可以看出输入和输出通道数是相同的
nn.Conv2d(out_planes, out_planes, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(out_planes),
nn.ReLU(),
# 第三层1*1卷积层,输出通道数扩大四倍(上图中由64->256)
nn.Conv2d(out_planes, out_planes * 4, kernel_size=1),
nn.BatchNorm2d(out_planes * 4),
# nn.ReLU(),
)
self.relu = nn.ReLU()
self.downsample = downsample
def forward(self, x):
res = x
result = self.model(x)
# 是否需要下采样来保证res与result可以正常相加
if self.downsample is not None:
res = self.downsample(x)
# 残差相加
result += res
# 最后还有一步relu
result = self.relu(result)
return result其输入图像变化如下:
输入图像
-
输入尺寸:(3, 224, 224)
conv1(7x7卷积,stride=2, padding=3)
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
-
通道变化:3 → 64
-
空间尺寸变化:
⌊224+2×3−72+1⌋=112⌊2224+2×3−7+1⌋=112 -
输出尺寸:(64, 112, 112)
使用大卷积核快速压缩空间尺寸。
maxPool(3x3最大池化,stride=2, padding=1)
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
-
通道不变:64
-
空间尺寸变化:
⌊112+2×1−32+1⌋=56⌊2112+2×1−3+1⌋=56 -
输出尺寸:(64, 56, 56)
进一步缩小尺寸,提取局部最大值。
block1(3个残差块,每个block输出通道256,空间尺寸不变)
self._make_layer(layers=3, stride=1, planes=64)
-
第一个残差块中,
in_planes=64 → planes=64 → out=64×4=256 -
因为 stride=1,空间尺寸不变。
-
通道变化:64 → 256
-
空间尺寸保持:(256, 56, 56)
第一个Block只是通道数扩展,尺寸不变。
block2(4个残差块,每个block输出通道512,尺寸减半)
self._make_layer(layers=4, stride=2, planes=128)
-
第一个残差块中,stride=2 进行下采样,尺寸变为一半
-
通道变化:256 → 512
-
空间尺寸变化:56 → 28
-
输出尺寸:(512, 28, 28)
block3(6个残差块,每个block输出通道1024,尺寸减半)
self._make_layer(layers=6, stride=2, planes=256)
-
通道变化:512 → 1024
-
空间尺寸变化:28 → 14
-
输出尺寸:(1024, 14, 14)
block4(3个残差块,每个block输出通道2048,尺寸减半)
self._make_layer(layers=3, stride=2, planes=512)
-
通道变化:1024 → 2048
-
空间尺寸变化:14 → 7
-
输出尺寸:(2048, 7, 7)
平均池化(7x7,全局池化)
nn.AvgPool2d(kernel_size=7, stride=1)
-
将整个 7x7 平均成一个值
-
空间尺寸变为:(2048, 1, 1)
全局平均池化:每个通道压缩成一个值
全连接层(Linear)
nn.Linear(2048, num_classes)
-
通道展平:2048
-
输出维度:(num_classes=5)
2.加载数据集
# 模型输入:224*224*3
class My_Dataset(Dataset):
def __init__(self,filename,transform=None):
self.filename = filename # 文件路径
self.transform = transform # 是否对图片进行变化
self.image_name,self.label_image = self.operate_file()
def __len__(self):
return len(self.image_name)
def __getitem__(self,idx):
# 由路径打开图片
image = Image.open(self.image_name[idx])
# 下采样: 因为图片大小不同,需要下采样为224*224
trans = transforms.RandomResizedCrop(224)
image = trans(image)
# 获取标签值
label = self.label_image[idx]
# 是否需要处理
if self.transform:
image = self.transform(image)
# image = image.reshape(1,image.size(0),image.size(1),image.size(2))
# print('变换前',image.size())
# image = interpolate(image, size=(227, 227))
# image = image.reshape(image.size(1),image.size(2),image.size(3))
# print('变换后', image.size())
# 转为tensor对象
label = torch.from_numpy(np.array(label))
return image,label
def operate_file(self):
# 获取所有的文件夹路径 '../data/net_train_images'的文件夹
dir_list = os.listdir(self.filename)
# 拼凑出图片完整路径 '../data/net_train_images' + '/' + 'xxx.jpg'
full_path = [self.filename+'/'+name for name in dir_list]
# 获取里面的图片名字
name_list = []
for i,v in enumerate(full_path):
temp = os.listdir(v)
temp_list = [v+'/'+j for j in temp]
name_list.extend(temp_list)
# 由于一个文件夹的所有标签都是同一个值,而字符值必须转为数字值,因此我们使用数字0-4代替标签值
label_list = []
temp_list = np.array([0,1,2,3,4],dtype=np.int64) # 用数字代表不同类别
# 将标签每个复制200个
for j in range(5):
for i in range(200):
label_list.append(temp_list[j])
return name_list,label_list
class My_Dataset_test(My_Dataset):
def operate_file(self):
# 获取所有的文件夹路径
dir_list = os.listdir(self.filename)
full_path = [self.filename+'/'+name for name in dir_list]
# 获取里面的图片名字
name_list = []
for i,v in enumerate(full_path):
temp = os.listdir(v)
temp_list = [v+'/'+j for j in temp]
name_list.extend(temp_list)
# 将标签每个复制一百个
label_list = []
temp_list = np.array([0,1,2,3,4],dtype=np.int64) # 用数字代表不同类别
for j in range(5):
for i in range(100): # 只修改了这里
label_list.append(temp_list[j])
return name_list,label_list3.训练模型(包含加载预训练模型和保存模型)
# 训练过程
def train():
batch_size = 10 # 批量训练大小
# model = My_ResNet() # 创建模型
# 预训练模型
model = resnet50()
model.load_state_dict(torch.load('model/resnet50-0676ba61.pth'))
# 提取fc层中固定的参数
fc_features = model.fc.in_features
# 修改类别为5
model.fc = nn.Linear(fc_features, 5)
# model = torch.load('ResNet.pkl')
# 将模型放入GPU中
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
# 定义损失函数
loss_func = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(params=model.parameters(),lr=0.002)
# 加载数据
train_set = My_Dataset('data/net_train_images',transform=transforms.ToTensor())
train_loader = DataLoader(train_set, batch_size, shuffle=True,drop_last=True)
# 训练20次
for i in range(20):
model.train()
loss_temp = 0 # 临时变量
for j,(batch_data,batch_label) in enumerate(train_loader):
# 数据放入GPU中
batch_data,batch_label = batch_data.cuda(),batch_label.cuda()
# 梯度清零
optimizer.zero_grad()
# 模型训练
prediction = model(batch_data)
# 损失值
loss = loss_func(prediction,batch_label)
loss_temp += loss.item()
# 反向传播
loss.backward()
# 梯度更新
optimizer.step()
# 训练完一次打印平均损失值
print('[%d] loss: %.3f' % (i+1,loss_temp/len(train_loader)))
# 保存模型
torch.save(model,'ResNet1.pth')
test(model) # 这样可以不用加载模型,直接传给测试代码4.测试模型
def test(model):
batch_size = 10
correct = 0
test_set = My_Dataset_test('data/net_test_images', transform=transforms.ToTensor())
test_loader = DataLoader(test_set, batch_size, shuffle=False)
model.eval() # ✅ 测试模式
with torch.no_grad(): # 禁用梯度,提高效率
for batch_data, batch_label in test_loader:
batch_data, batch_label = batch_data.cuda(), batch_label.cuda()
prediction = model(batch_data)
predicted = torch.max(prediction.data, 1)[1]
correct += (predicted == batch_label).sum().item()
print('准确率: %.2f %%' % (100 * correct / 500))5.测试准确率

20轮结果,效果确实好

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)