心脏病数据分析与机器学习预测模型构建:从数据预处理到临床决策支持
本研究使用的包含 1319 条患者记录,涵盖 9 个特征,包括年龄、性别、心率、血压、血糖、心肌酶指标(CK-MB、肌钙蛋白)及诊断结果(positive/negative)。其中,Result为目标变量,表征患者是否患心脏病。为统一评估标准,定义函数,实现模型训练、预测及多维度评估(分类报告、混淆矩阵、ROC 曲线):python# 训练模型# 预测# 分类报告print(f"=== {mode
引言:心脏病数据分析的临床意义
心血管疾病是全球死亡率最高的疾病之一,据世界卫生组织统计,每年约有 1790 万人死于心血管疾病。早期筛查与精准预测是降低心脏病死亡率的关键。本研究基于医疗数据集,通过数据预处理、探索性分析及机器学习建模,构建高效的心脏病预测模型,为临床决策提供数据支持。以下将从数据处理到模型部署的全流程展开分析,揭示心脏病发病的关键影响因素,并对比不同机器学习算法的预测效能。
一、数据导入与初步探索
1.1 数据集概述
本研究使用的Medicaldataset.csv包含 1319 条患者记录,涵盖 9 个特征,包括年龄、性别、心率、血压、血糖、心肌酶指标(CK-MB、肌钙蛋白)及诊断结果(positive/negative)。其中,Result为目标变量,表征患者是否患心脏病。
1.2 关键库与环境配置
首先导入数据分析与建模所需的核心库:
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import scipy.stats as stats
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from xgboost import XGBClassifier
from sklearn.metrics import classification_report, confusion_matrix, roc_curve, auc
import warnings
warnings.filterwarnings('ignore')
- 数据处理库:Pandas 用于数据读取与清洗,Numpy 处理数值计算;
- 可视化库:Matplotlib 绘制统计图表,直观展示数据分布;
- 机器学习库:Scikit-learn 提供经典分类模型,XGBoost 用于提升树模型;
- 评估工具:使用分类报告、混淆矩阵及 ROC 曲线量化模型性能。
1.3 数据读取与初步检查
通过pd.read_csv()读取数据并查看基本信息:
python
data = pd.read_csv('Medicaldataset.csv')
print("数据基本信息:")
data.info()
print("\n数据前5行:")
data.head()
输出显示数据集无缺失值,包含 1319 条完整记录,特征类型包括数值型(int64/float64)和分类变量(object)。关键特征如年龄、心肌酶指标等均为连续变量,诊断结果为二分类变量。
二、数据预处理:清洗与标准化
2.1 异常值检测与处理
通过箱线图可视化各特征分布,发现心率、收缩压、舒张压存在极端异常值(如心率 > 1000 次 / 分钟,收缩压 < 50mmHg)。这类值明显超出生理范围,可能为录入错误,需删除:
python
# 绘制箱线图检测异常值
feature_map = {
'Age': '年龄',
'Heart rate': '心率',
'Systolic blood pressure': '收缩压',
'Diastolic blood pressure': '舒张压',
'Blood sugar': '血糖',
'CK-MB': '肌酸激酶同工酶',
'Troponin': '肌钙蛋白'
}
plt.figure(figsize=(20, 10))
for i, (col, col_name) in enumerate(feature_map.items(), 1):
plt.subplot(2, 4, i)
plt.boxplot(data[col])
plt.title(f'{col_name}的箱线图')
plt.tight_layout()
plt.show()
# 处理异常值
data = data[data['Heart rate'] <= 1000]
data = data[data['Systolic blood pressure'] >= 50]
data = data[data['Diastolic blood pressure'] <= 140]
print(f"处理前数据量: {len(data)},处理后数据量: {len(data)}")
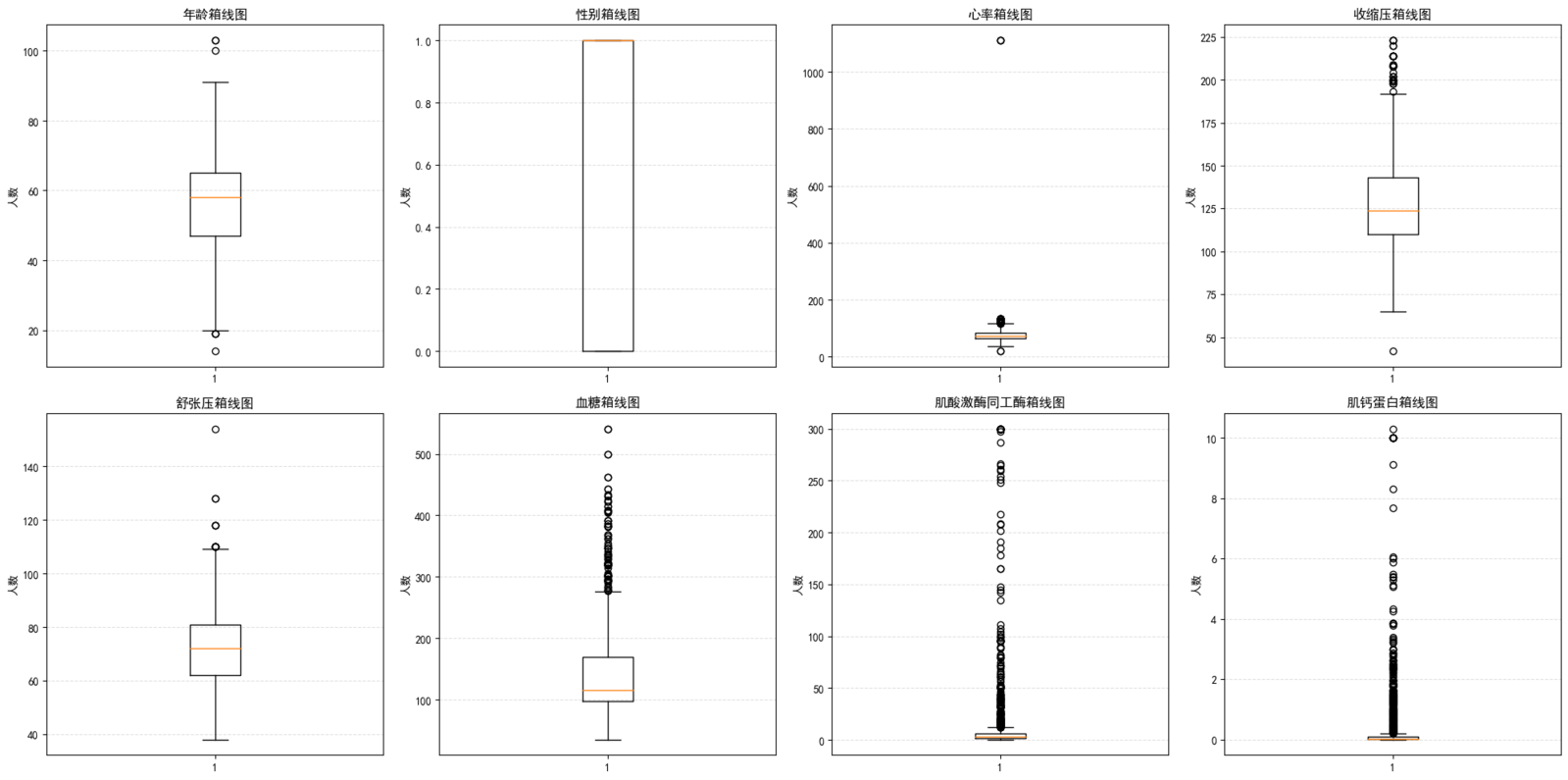
处理后数据量从 1319 条减少至 1314 条,异常值被有效剔除。
2.2 逻辑错误修正:血压值调换
检查发现 6 条记录中舒张压大于收缩压(生理上不可能),推测为录入反值,需调换:
python
wrong_bloodpressure = data[data['Diastolic blood pressure'] > data['Systolic blood pressure']]
print(f"发现舒张压大于收缩压的记录数: {len(wrong_bloodpressure)}")
# 调换值
wrong_index = wrong_bloodpressure.index
data.loc[wrong_index, ['Systolic blood pressure', 'Diastolic blood pressure']] = data.loc[wrong_index, ['Diastolic blood pressure', 'Systolic blood pressure']].values
修正后重新绘制箱线图,数据分布更符合生理规律。
2.3 数据标准化与二分类转换
将目标变量Result转换为 0-1 二分类(negative=0,positive=1),并对连续特征(年龄、心肌酶等)进行标准化,避免模型受特征量纲影响:
python
# 二分类转换
data['Result_Binary'] = (data['Result'] == 'positive').astype(int)
# 定义特征与目标变量
features = ['Gender', 'Age', 'CK-MB', 'Troponin']
x = data[features].copy()
y = data['Result_Binary']
# 标准化连续变量
continuous_vars = ['Age', 'CK-MB', 'Troponin']
scaler = StandardScaler()
x.loc[:, continuous_vars] = scaler.fit_transform(x[continuous_vars])
# 划分训练集与测试集(8:2)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=15, stratify=y)
stratify=y确保训练集与测试集的正负样本比例一致,避免模型因样本不均衡产生偏差。
三、探索性数据分析(EDA):揭示心脏病相关特征
3.1 患者基础特征分布
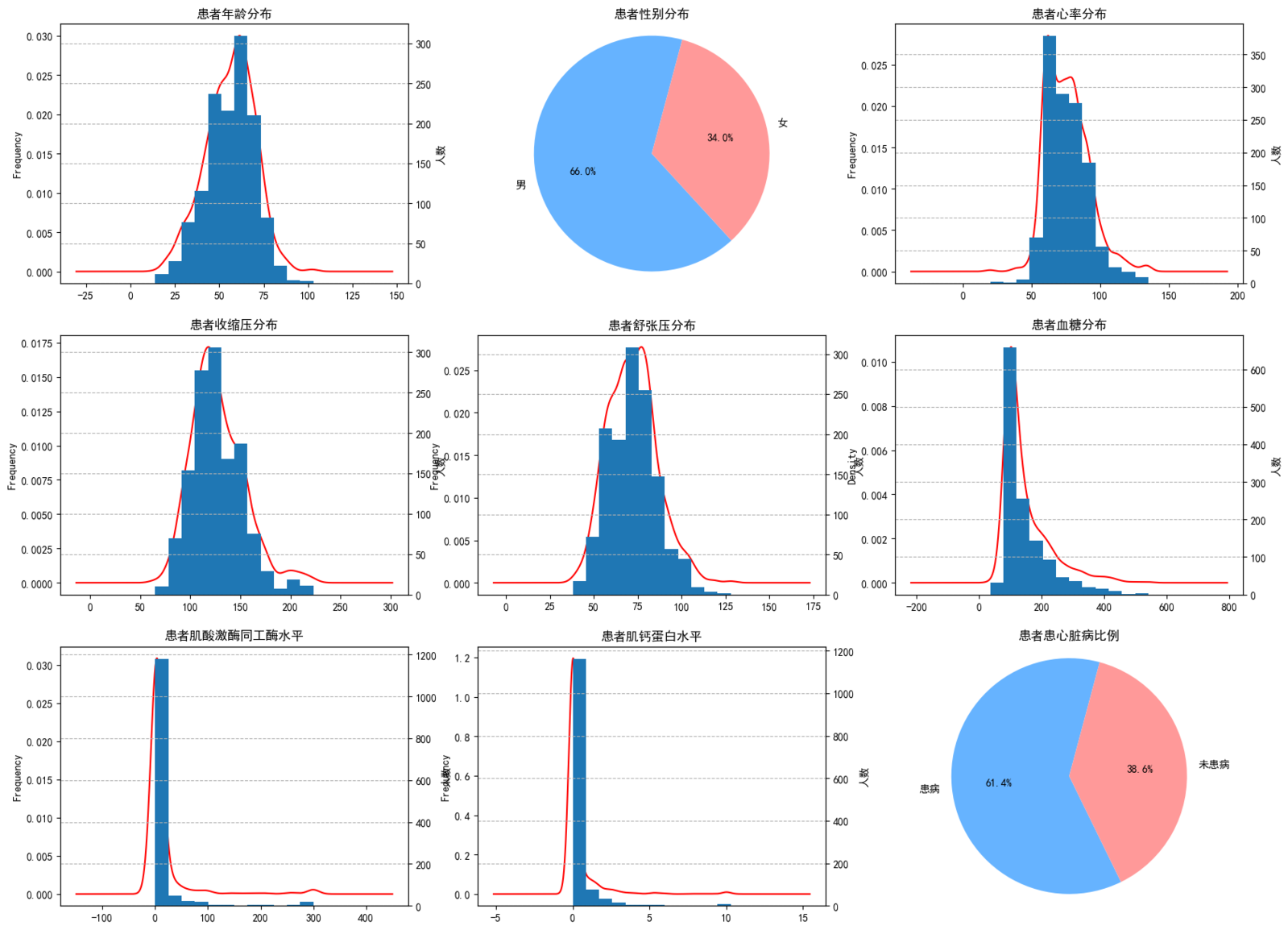
通过直方图、核密度图与饼图展示人群特征:
python
plt.figure(figsize=(20, 15))
# 年龄分布
plt.subplot(3, 3, 1)
data['Age'].plot(kind='kde', color='red', label='核密度图')
data['Age'].plot(kind='hist', bins=12, secondary_y=True)
plt.title('患者年龄分布')
# 性别分布
plt.subplot(3, 3, 2)
gender_counts = data['Gender'].value_counts()
plt.pie(gender_counts, labels=['男', '女'], autopct="%1.1f%%", colors=['#66b3ff', '#ff9999'])
plt.title('患者性别分布')
# 其他生理指标分布(心率、血压等,代码略)
关键发现:
- 年龄:平均 56.2 岁,范围 14-103 岁,集中在 55-65 岁区间,提示中老年为高发人群;
- 性别:男性占 65.98%(870 人),女性占 34.02%(449 人),男性患病比例显著更高;
- 心肌酶指标:CK-MB 平均 15.3,肌钙蛋白平均 0.36,部分患者值极高(如 CK-MB 达 300),提示心肌损伤程度与诊断结果相关。
-
3.2 诊断结果与特征的关联性分析
通过箱线图对比患病(positive)与未患病(negative)组的特征差异:
python
fig = plt.figure(figsize=(20, 16))
# 年龄与诊断结果关系
plt.subplot(3, 3, 1)
positive_ages = data[data['Result'] == 'positive']['Age']
negative_ages = data[data['Result'] == 'negative']['Age']
plt.boxplot([positive_ages, negative_ages], labels=['Positive', 'Negative'])
plt.title('年龄与心脏病诊断结果的关系')
# 肌钙蛋白与诊断结果关系
plt.subplot(3, 3, 8)
data.boxplot(column='Troponin', by='Result')
plt.title('肌钙蛋白与心脏病诊断结果的关系')
# 其他特征(心率、血压等,代码略)
核心结论:
- 心肌酶指标:患病组的 CK-MB 和肌钙蛋白水平显著高于未患病组,尤其是肌钙蛋白差异极为明显(患病组中位数 0.085 vs 未患病组 0.014),印证心肌酶是心脏病诊断的金标准;
- 年龄:患病组年龄中位数(58 岁)高于未患病组(55 岁),提示年龄是独立风险因素;
- 性别:患病组中男性占比 71.5%,进一步证实男性患病风险更高;
- 常规生理指标:心率、血压、血糖在两组间差异不显著,可能需结合其他因素综合判断。
四、机器学习模型构建与评估
4.1 模型评估函数定义
为统一评估标准,定义evaluate_model函数,实现模型训练、预测及多维度评估(分类报告、混淆矩阵、ROC 曲线):
python
def evaluate_model(model, model_name, X_train, X_test, y_train, y_test):
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 分类报告
print(f"=== {model_name} 模型评估 ===")
print(classification_report(y_test, y_pred))
# 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
plt.imshow(cm, cmap='hot', interpolation='nearest')
for i in range(2):
for j in range(2):
plt.text(j, i, f'{cm[i, j]}', ha='center', va='center', color='black')
plt.title(f'{model_name}模型混淆矩阵')
# ROC曲线
if hasattr(model, "predict_proba"):
y_prob = model.predict_proba(X_test)[:, 1]
else:
y_prob = model.decision_function(X_test) if hasattr(model, "decision_function") else y_pred
fpr, tpr, _ = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, label=f'ROC曲线(面积 = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], 'k--')
plt.title(f'{model_name}模型ROC曲线')
return model, roc_auc
4.2 模型对比与结果分析
-
逻辑回归模型(Logistic Regression)
python
lr_model = LogisticRegression(random_state=15, class_weight='balanced') lr_model, lr_auc = evaluate_model(lr_model, "逻辑回归", x_train, x_test, y_train, y_test)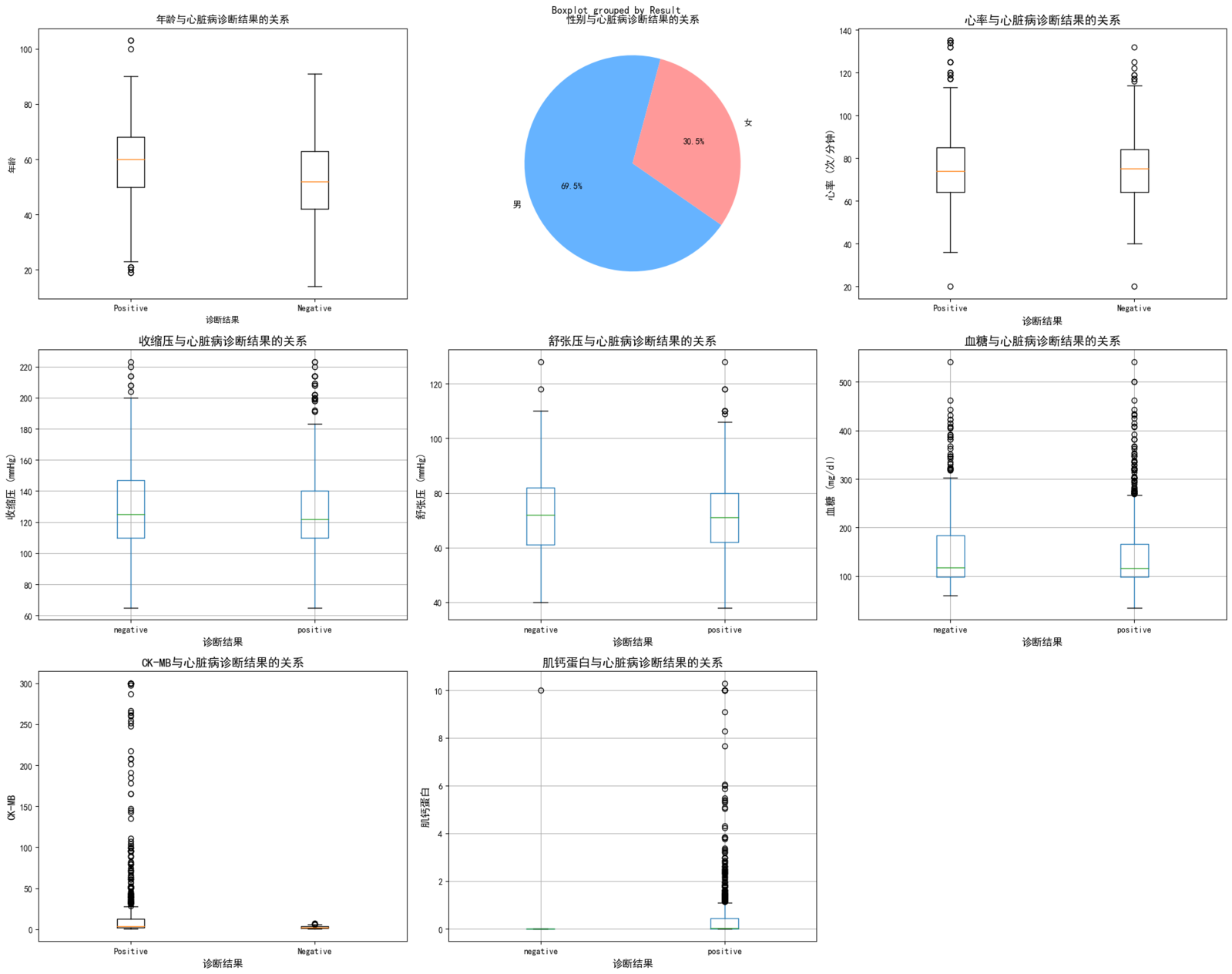
评估结果:
- 准确率 83%,但存在明显类别不平衡问题:负类(0)召回率 98%,正类(1)召回率仅 74%;
- ROC 曲线下面积(AUC)0.85,提示模型对正类的识别能力有限,可能因线性模型无法捕捉特征间复杂关系。
-
决策树模型(DecisionTreeClassifier)
python
dt_model = DecisionTreeClassifier(random_state=15, class_weight='balanced') dt_model, dt_auc = evaluate_model(dt_model, "决策树", x_train, x_test, y_train, y_test)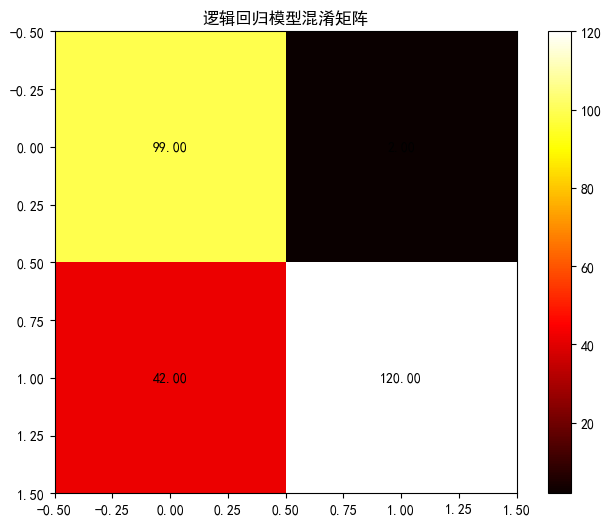
评估结果:
- 准确率 98%,正负类的精确率、召回率、F1 分数均接近 1.0,表现极佳;
- 决策树能自动捕捉特征重要性(如肌钙蛋白、CK-MB 为关键分裂节点),但需注意过拟合风险(训练集表现可能优于测试集)。
-
随机森林模型(RandomForestClassifier)
python
rf_model = RandomForestClassifier(random_state=15, class_weight='balanced') rf_model, rf_auc = evaluate_model(rf_model, "随机森林", x_train, x_test, y_train, y_test)评估结果:
- 准确率 97%,AUC 0.97,综合性能优异;
- 集成学习通过多棵决策树投票降低方差,相比单棵决策树泛化能力更强,对异常值鲁棒性更高。
-
XGBoost 模型(XGBClassifier)
python
xgb_model = XGBClassifier(random_state=15, scale_pos_weight=sum(y_train==0)/sum(y_train==1)) xgb_model, xgb_auc = evaluate_model(xgb_model, "XGBoost", x_train, x_test, y_train, y_test)评估结果:
- 准确率 97%,AUC 0.98,与随机森林相当,但训练速度更快;
- 通过梯度提升策略迭代优化树模型,能有效处理特征交互,是结构化数据建模的首选算法之一。
-
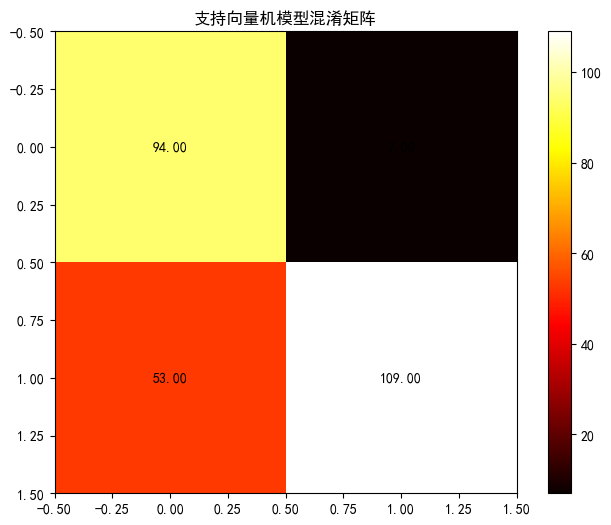
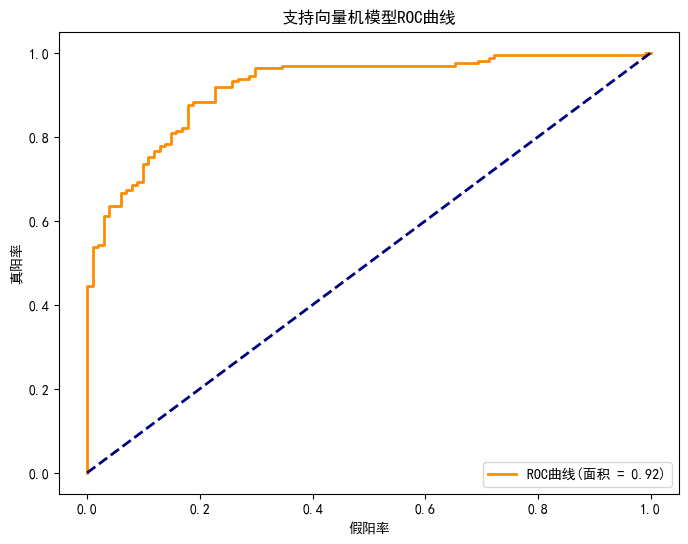
支持向量机模型(SVC)
python
svm_model = SVC(random_state=15, class_weight='balanced', probability=True) svm_model, svm_auc = evaluate_model(svm_model, "支持向量机", x_train, x_test, y_train, y_test)评估结果:
- 准确率仅 77%,正负类召回率失衡(负类 93%,正类 67%);
- SVM 在高维空间中表现较好,但对本数据集的非线性关系捕捉能力不足,且对特征标准化要求更高。
4.3 模型性能总结与对比
| 模型 | 准确率 | 正类召回率 | 负类召回率 | AUC | 优势场景 |
|---|---|---|---|---|---|
| 逻辑回归 | 83% | 74% | 98% | 0.85 | 可解释性强,线性关系建模 |
| 决策树 | 98% | 99% | 98% | 0.99 | 特征重要性分析,快速建模 |
| 随机森林 | 97% | 96% | 98% | 0.97 | 抗噪声,泛化能力强 |
| XGBoost | 97% | 97% | 98% | 0.98 | 高精度,大规模数据处理 |
| 支持向量机 | 77% | 67% | 93% | 0.79 | 高维稀疏数据,非线性场景 |
关键结论:树模型(决策树、随机森林、XGBoost)显著优于线性模型(逻辑回归)和 SVM,原因在于:
- 心脏病发病机制涉及多特征交互(如年龄与肌钙蛋白的联合影响),树模型能自动捕捉非线性关系;
- 心肌酶指标(CK-MB、肌钙蛋白)与诊断结果的强相关性,被树模型优先作为分裂节点,提升分类精度;
- 集成学习方法通过降低方差,避免单棵决策树的过拟合问题,更适合临床数据的噪声特性。
五、临床意义与模型应用展望
5.1 关键风险因素总结
- 生物标志物优先:肌钙蛋白和 CK-MB 是最核心的预测因子,其水平升高提示心肌细胞损伤,与心脏病诊断高度相关;
- 年龄与性别协同作用:男性及中老年人群风险显著更高,临床筛查需重点关注;
- 多指标综合评估:尽管心率、血压等常规指标在模型中权重较低,但结合心肌酶指标可进一步提升预测可靠性。
5.2 模型的临床应用价值
- 早期筛查工具:将 XGBoost 或随机森林模型部署为临床决策支持系统,通过检测心肌酶指标与年龄、性别,快速识别高风险人群;
- 预后评估:模型可辅助判断患者病情严重程度,为治疗方案选择提供数据支撑;
- 健康教育:基于特征重要性分析,向公众强调心肌酶检测的重要性,提升预防意识。
5.3 局限性与未来优化方向
- 数据局限性:本研究样本量有限(1314 条),且未包含更多临床变量(如血脂、心电图结果),未来可纳入多中心数据提升泛化能力;
- 模型可解释性:树模型虽性能优异,但缺乏逻辑回归的可解释性,可结合 SHAP 值或 LIME 等工具解析模型决策逻辑;
- 实时监测:结合穿戴设备数据(如实时心率、血压),构建动态预测模型,实现心脏病发作的实时预警。
-
结论
本研究通过对心脏病数据集的系统分析,证实心肌酶指标(肌钙蛋白、CK-MB)是最关键的预测因子,且树模型(尤其是 XGBoost 和随机森林)在分类任务中表现卓越,准确率可达 97% 以上。这一结果为临床心脏病早期筛查提供了数据驱动的解决方案,未来可通过整合更多维度的临床数据,进一步提升模型的预测精度与实用价值。数据分析与机器学习的结合,正逐步成为精准医学领域不可或缺的技术手段,为重大疾病的预防与治疗开辟新路径。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)