MySQL数据库------------探索高级SQL查询语句(一)
(增、删、改、查)对 MySQL 数据库的查询,除了基本的查询外,有时候需要对查询的结果集进行处理。例如只取 10 条数据、对查询结果进行排序或分组等等。
目录
①order by还可以结合where进行条件过滤,筛选地址是哪里的学生按分数降序排列
②查询学生信息先按hobbyid降序排列,相同分数的,id也按降序排列
③ 查询学生信息先按兴趣id降序排列,相同分数的,id按升序排列
6.3结合order by语句,按score的大小降序排列显示前三行
一、常用查询
(增、删、改、查)
对 MySQL 数据库的查询,除了基本的查询外,有时候需要对查询的结果集进行处理。 例如只取 10 条数据、对查询结果进行排序或分组等等
1.1按关键字排序
PS:类比于windows 任务管理器
- 使用 SELECT 语句可以将需要的数据从 MySQL 数据库中查询出来
- 如果对查询的结果进行排序,可以使用 ORDER BY 语句来对语句实现排序,并最终将排序后的结果返回给用户。这个语句的排序不光可以针对某一个字段,也可以针对多个字段
(1)语法
SELECT column1, column2, ... FROM table_name ORDER BY column1, column2, ...
ASC|DESC;
ASC 是按照升序进行排序的,是默认的排序方式,即 ASC 可以省略。
SELECT 语句中如果没有指定具体的排序方式,则默认按 ASC方式进行排序。
DESC 是按降序方式进 行排列
当然 ORDER BY 前面也可以使用 WHERE 子句对查询结果进一步过滤。
环境准备:
[root@localhost ~]#mysql -uroot -p123123
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 64
Server version: 5.7.17-log Source distribution
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| anhui |
| henan |
| mysql |
| performance_schema |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> create database beijing;
Query OK, 1 row affected (0.00 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| anhui |
| beijing |
| henan |
| mysql |
| performance_schema |
| sys |
+--------------------+
7 rows in set (0.00 sec)
mysql> use beijing;
Database changed
mysql> create table qhua(id int(3) not null,name varchar(8)primary key not null,score decimal(5,2),address varchar(20),phone varchar(11),hobbyid int(6));
Query OK, 0 rows affected (0.03 sec)
mysql> show tables;
+-------------------+
| Tables_in_beijing |
+-------------------+
| qhua |
+-------------------+
1 row in set (0.01 sec)
mysql> insert into qhua values(1,'sbk',99,'tongzhou',33333,2);
Query OK, 1 row affected (0.01 sec)
mysql> mysql>
mysql> insert into qhua values(2,'lss',90,'haidian',44446,2);
Query OK, 1 row affected (0.01 sec)
mysql> mysql> insert into qhua values(3,'xzz',80,'qinghuay',6666,3);
Query OK, 1 row affected (0.01 sec)
mysql> insert into qhua values(4,'khui',79,'beijing',66322,3);
Query OK, 1 row affected (0.00 sec)
mysql> insert into qhua values(5,'zgq',66,'xian',64622,5);
Query OK, 1 row affected (0.00 sec)
mysql> insert into qhua values(6,'wql',55,'xian',64622,5);
Query OK, 1 row affected (0.00 sec)
mysql> insert into qhua values(7,'gwx',15,'shenzheng',64611,1);
Query OK, 1 row affected (0.00 sec)
mysql> insert into qhua values(8,'ym',35,'shenzheng',65653,1);
Query OK, 1 row affected (0.01 sec)
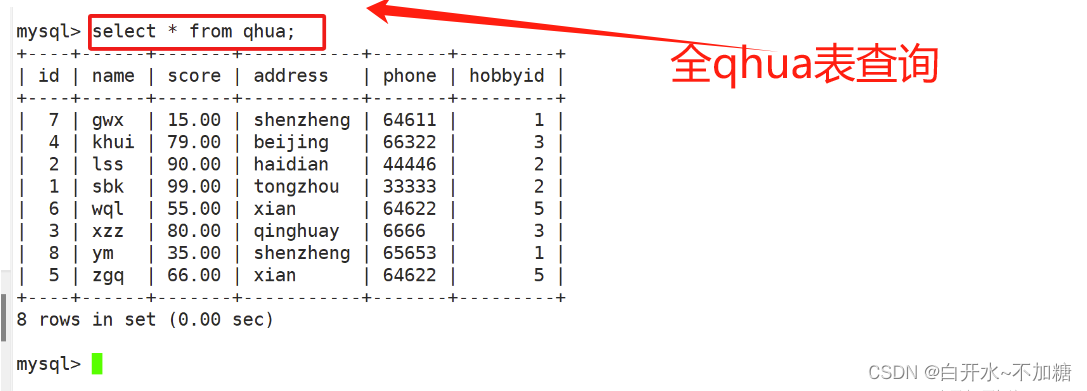
mysql> select * from qhua;
+----+------+-------+-----------+-------+---------+
| id | name | score | address | phone | hobbyid |
+----+------+-------+-----------+-------+---------+
| 7 | gwx | 15.00 | shenzheng | 64611 | 1 |
| 4 | khui | 79.00 | beijing | 66322 | 3 |
| 2 | lss | 90.00 | haidian | 44446 | 2 |
| 1 | sbk | 99.00 | tongzhou | 33333 | 2 |
| 6 | wql | 55.00 | xian | 64622 | 5 |
| 3 | xzz | 80.00 | qinghuay | 6666 | 3 |
| 8 | ym | 35.00 | shenzheng | 65653 | 1 |
| 5 | zgq | 66.00 | xian | 64622 | 5 |
+----+------+-------+-----------+-------+---------+
8 rows in set (0.00 sec)
mysql>create database beijing; #创建数据库
use beijing; #切换库
create table qhua(id int(3) not null,name varchar(8)primary key not null,score decimal(5,2),address varchar(20),phone varchar(11),hobbyid int(6)); #创建qhua表
insert into qhua values(1,'sbk',99,'tongzhou',33333,2); #插入数据
1.2简单的select条件查询(where)
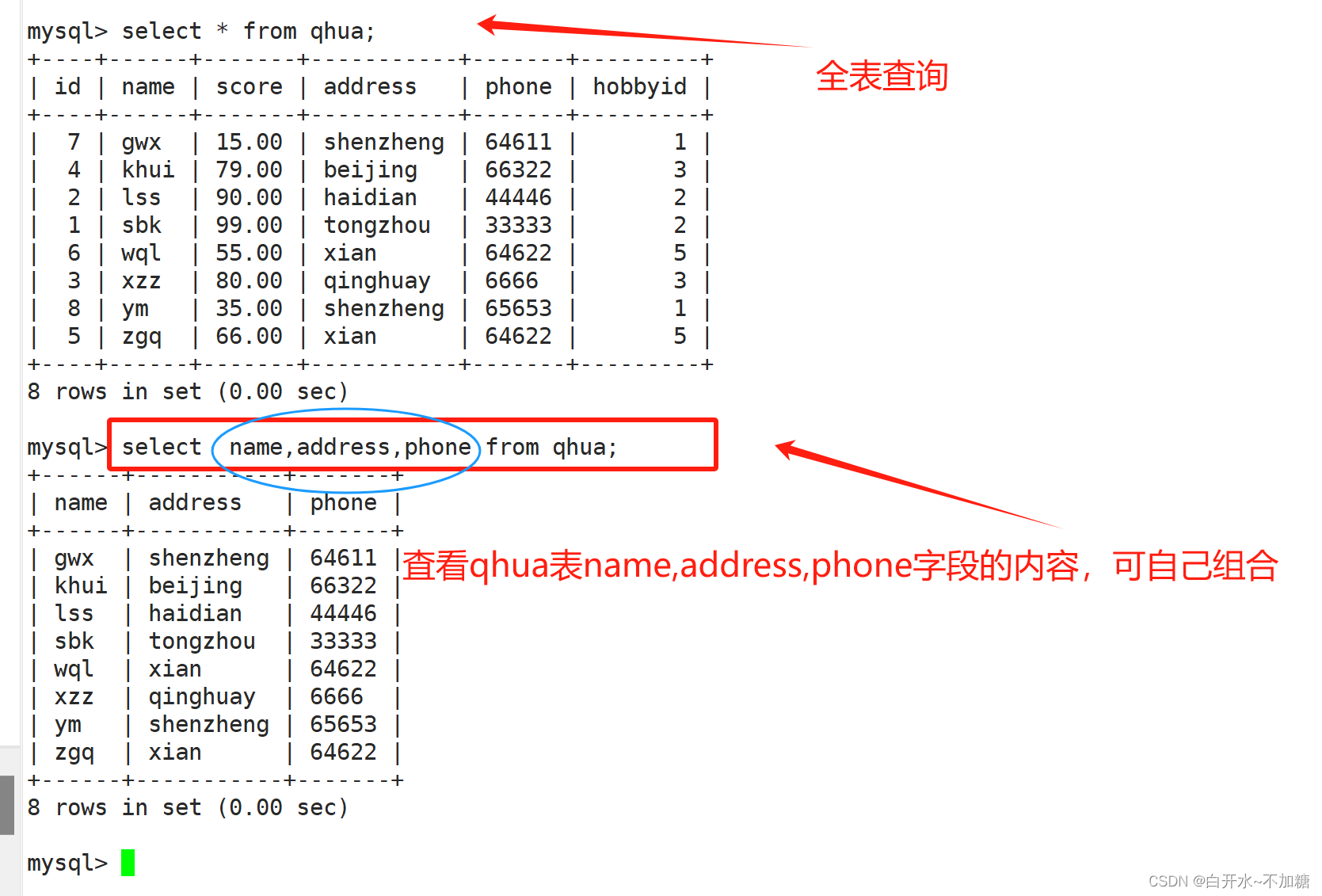
二、排序
select 字段列表 from 表名 order by 字段 asc或desc
asc 升序,默认为asc(Ascending)
desc 降序(Descending)2.1升序排列
ASC 是按照升序进行排序的,是默认的排序方式,即 ASC 可以省略
ORDER BY 语句来对语句实现排序
按分数排序,默认不指定是升序排列
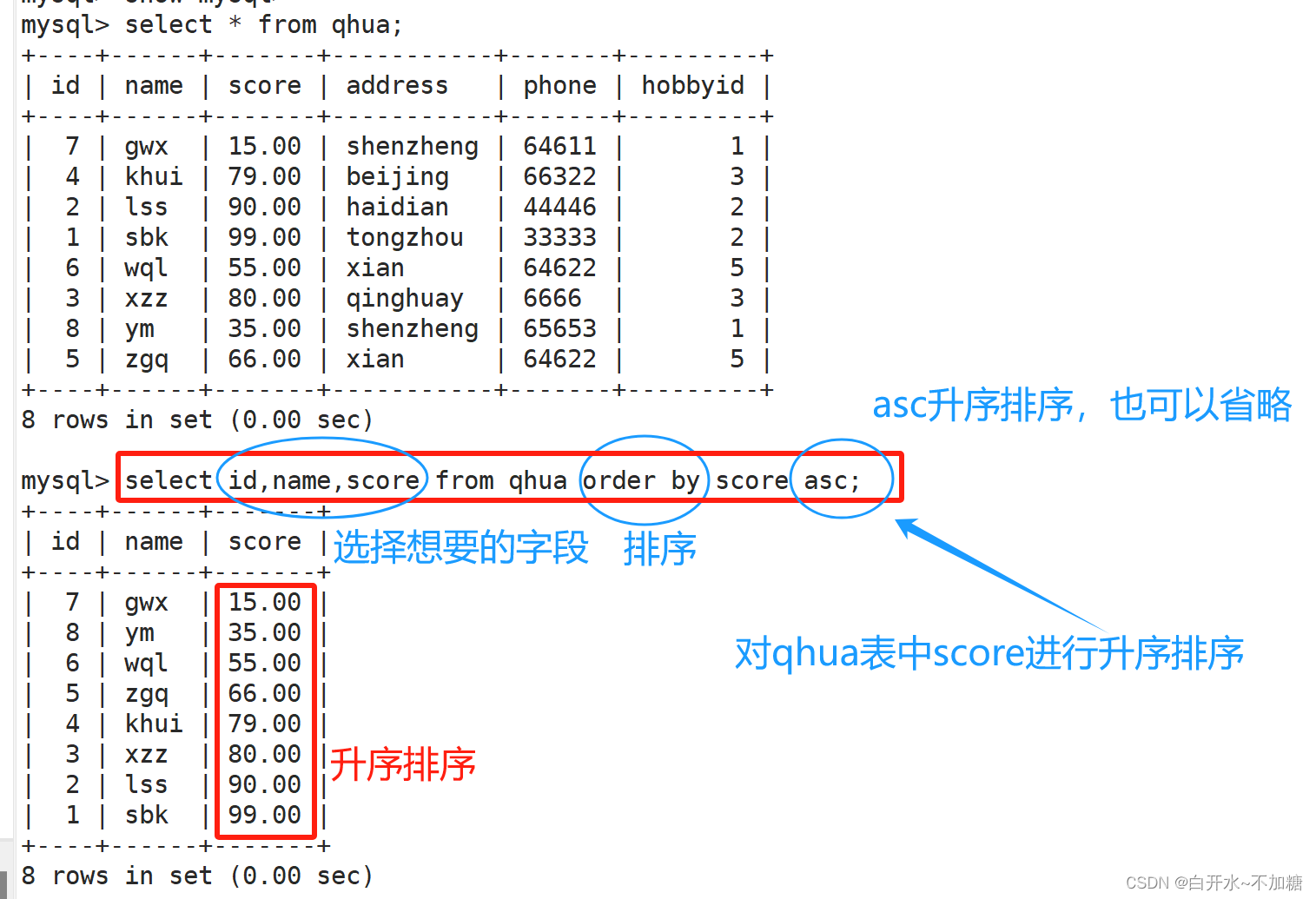
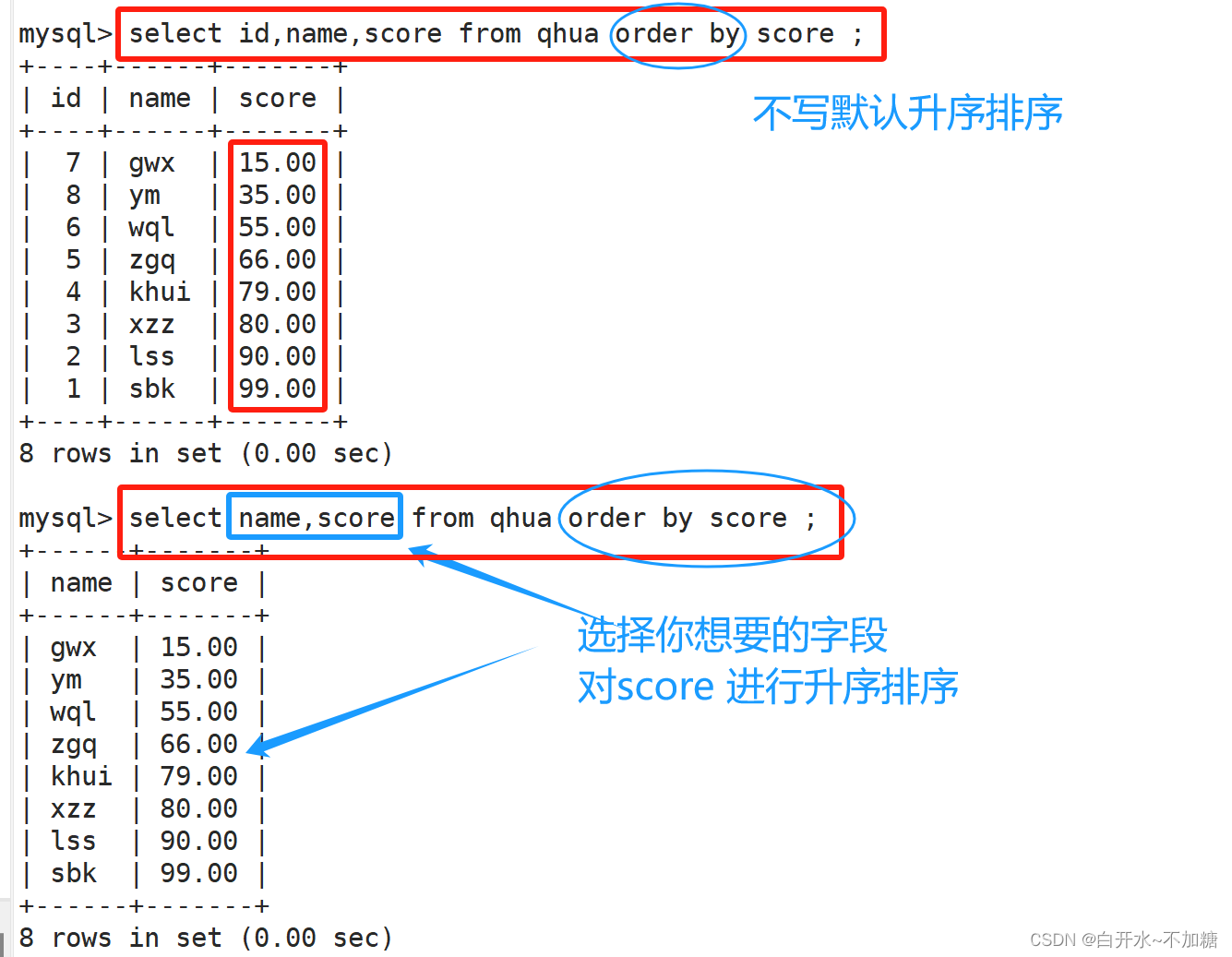
2.2降序排序
ORDER BY #按关键字排序
语法:SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC, DESC];
#ASC 是按照升序进行排序的,是默认的排序方式。
#DESC 是按降序方式进行排序。DESC 是按降序方式进 行排列
分数按降序排列
select name,score from qhua order by score desc;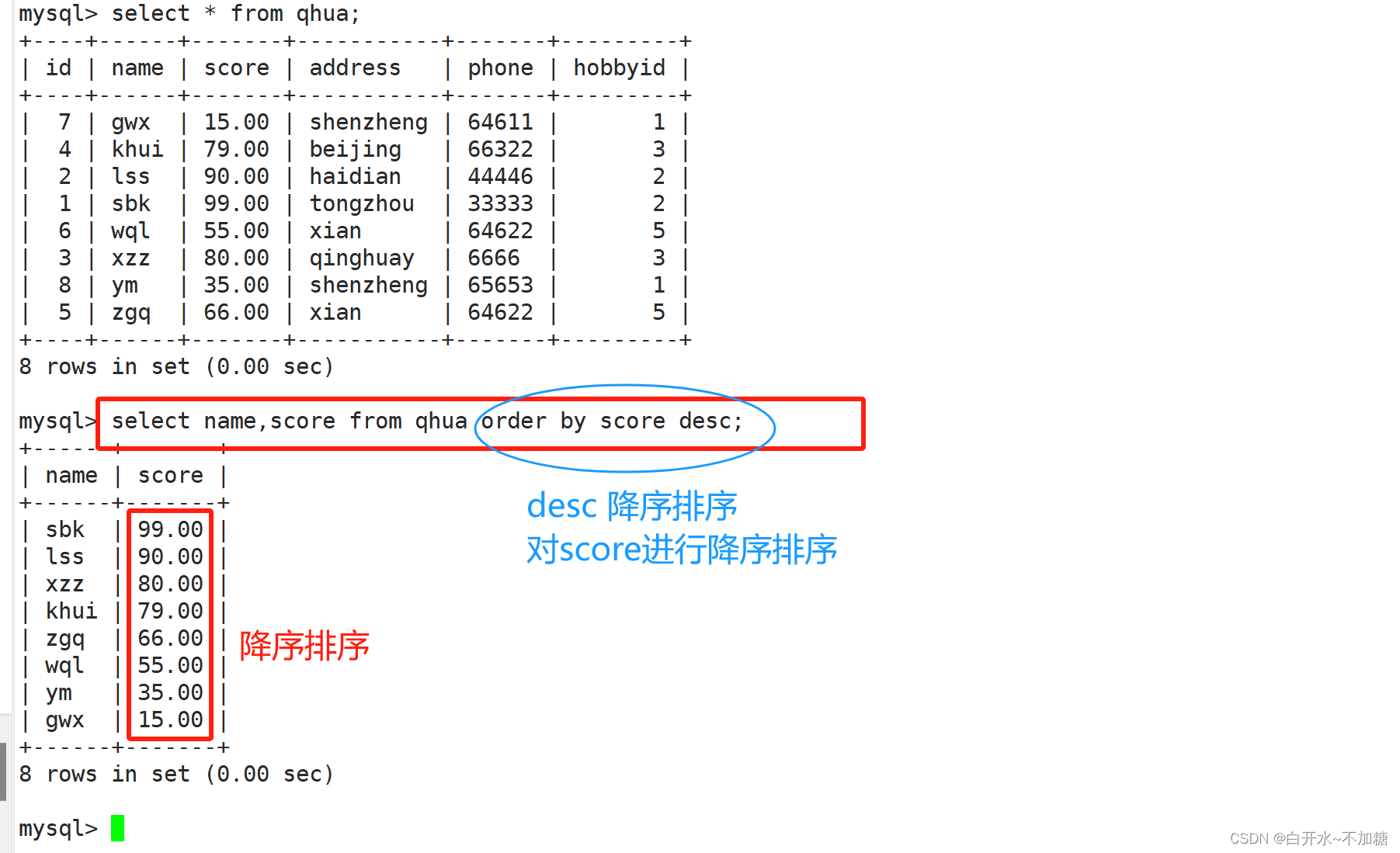
三、order by 查询结果排序
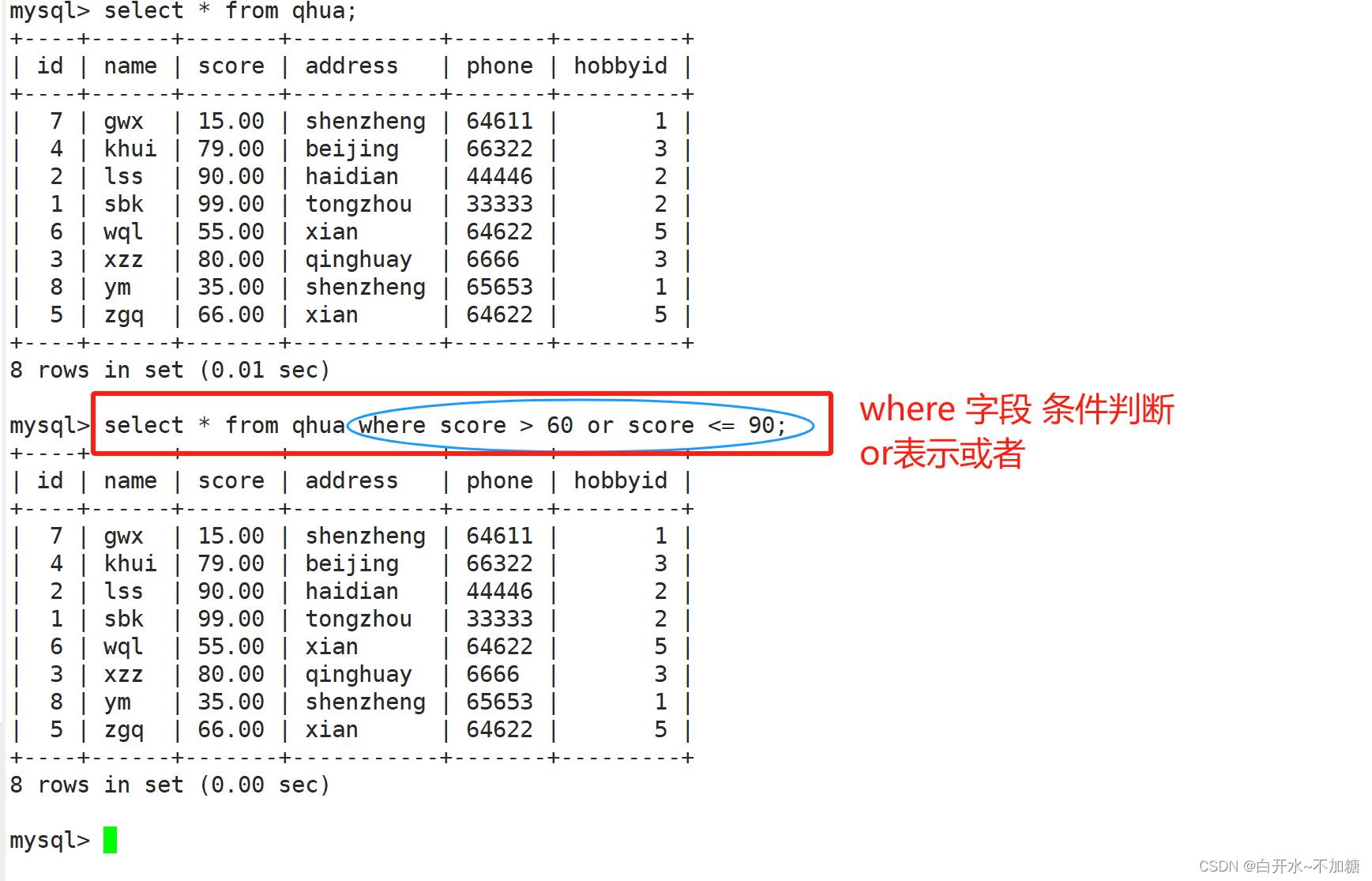
①order by还可以结合where进行条件过滤,筛选地址是哪里的学生按分数降序排列

ORDER BY 语句也可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,ORDER BY 后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定
但order by 之后的第一个参数只有在出现相同值时,第二个字段才有意义
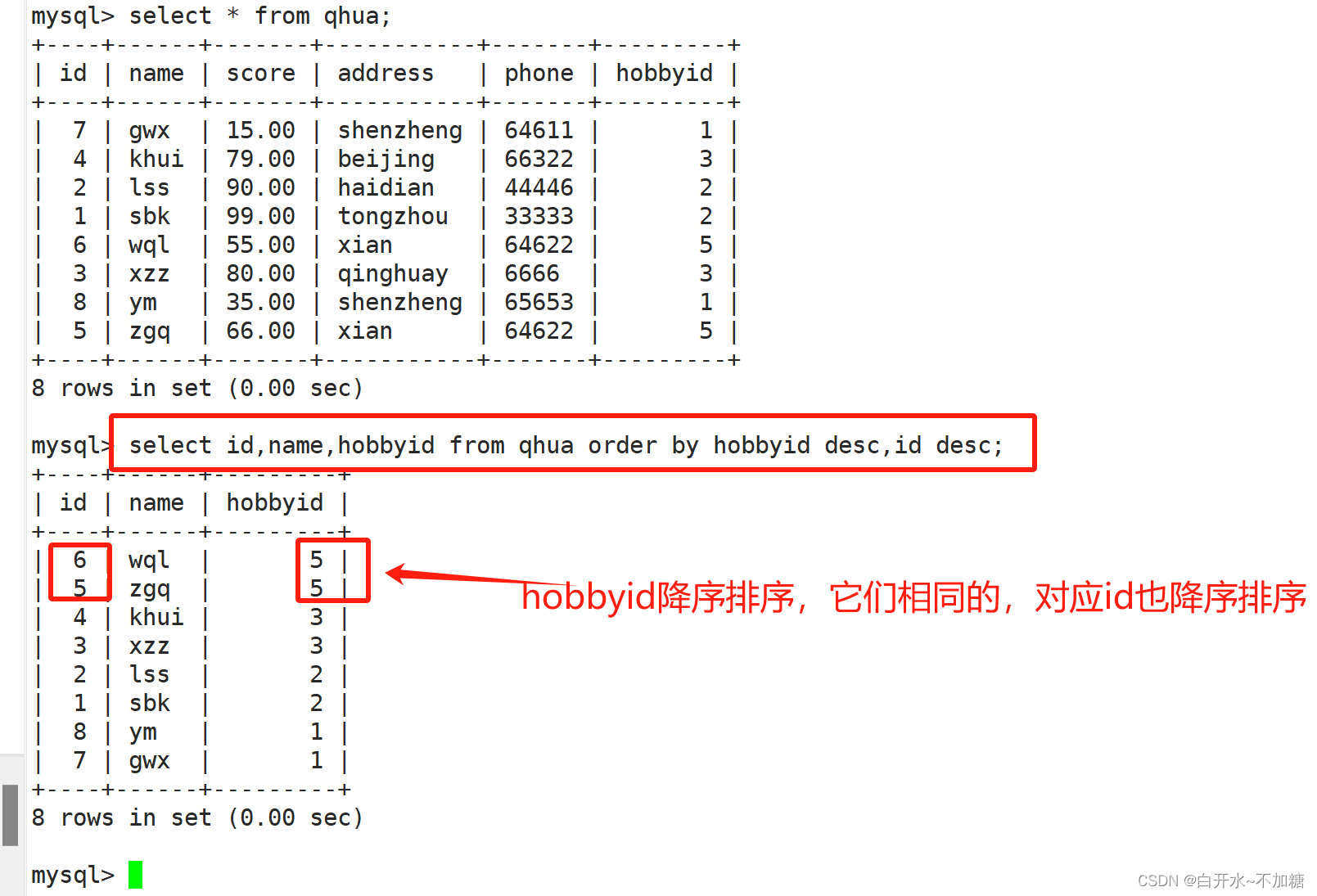
②查询学生信息先按hobbyid降序排列,相同分数的,id也按降序排列
③ 查询学生信息先按兴趣id降序排列,相同分数的,id按升序排列
select id,name,hobbyid from qhua order by hobbyid desc,id asc;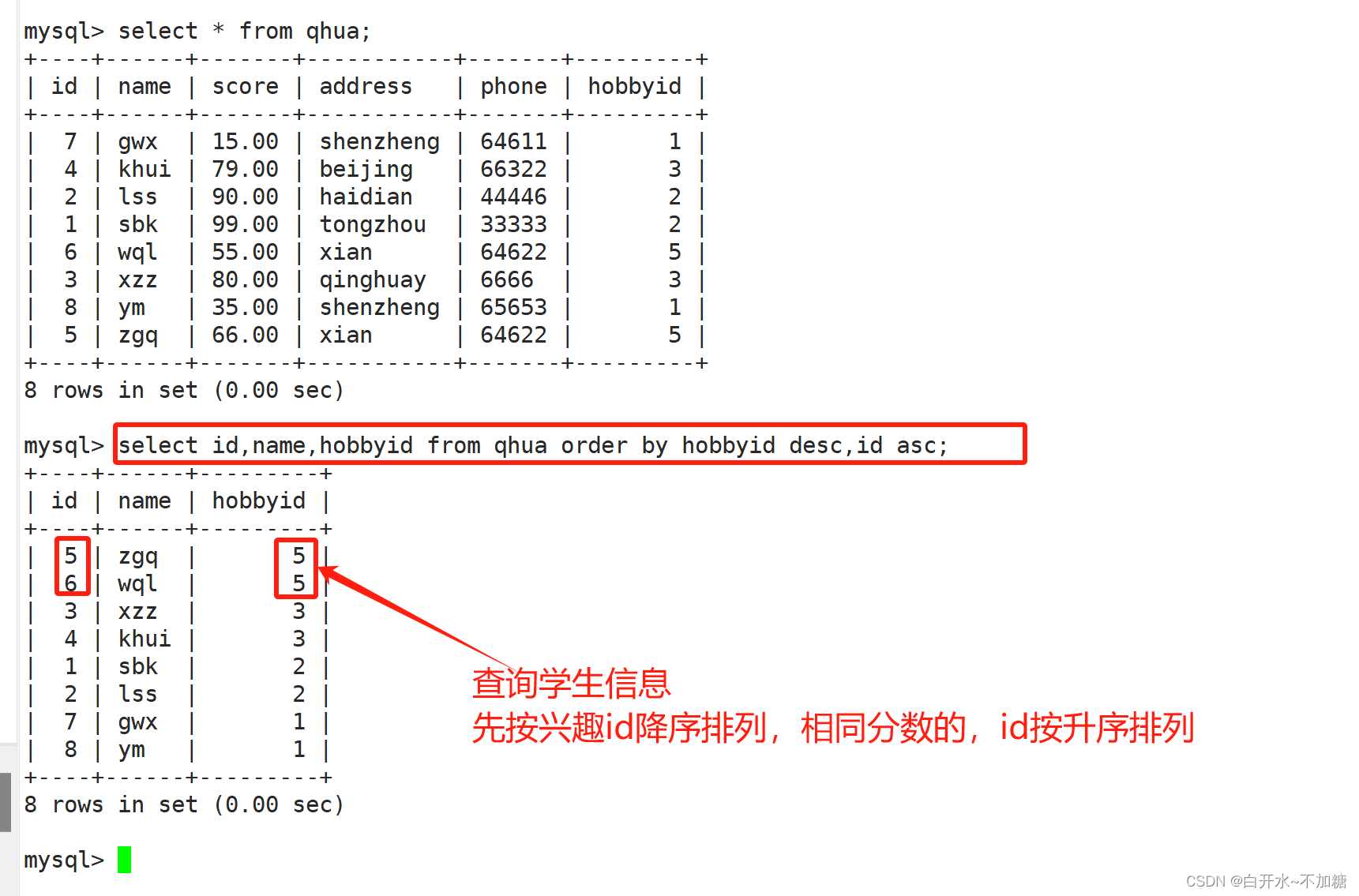
四、区间判断及查询不重复记录
4.1AND/OR ——且/或
and 且
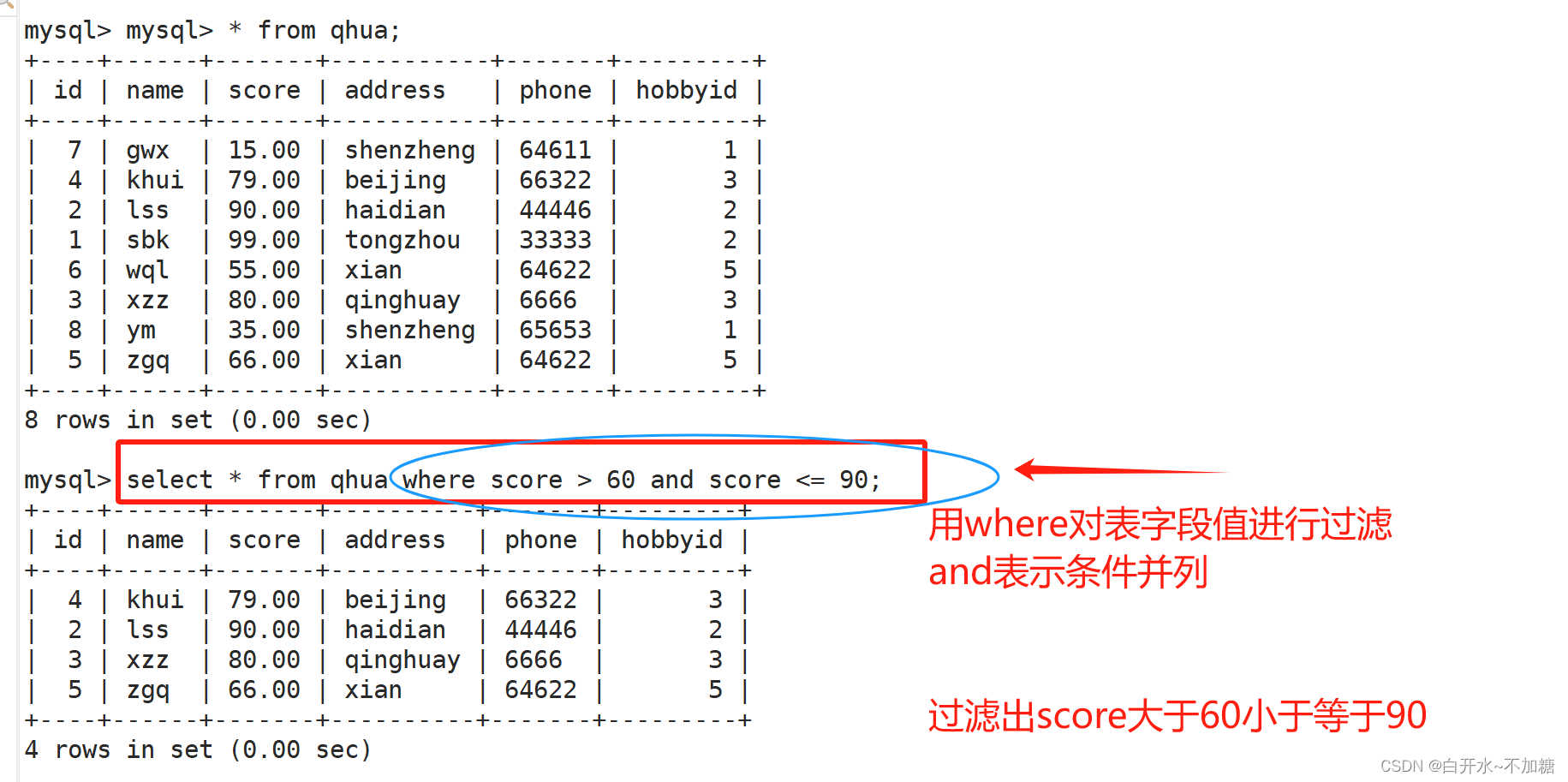
or 或
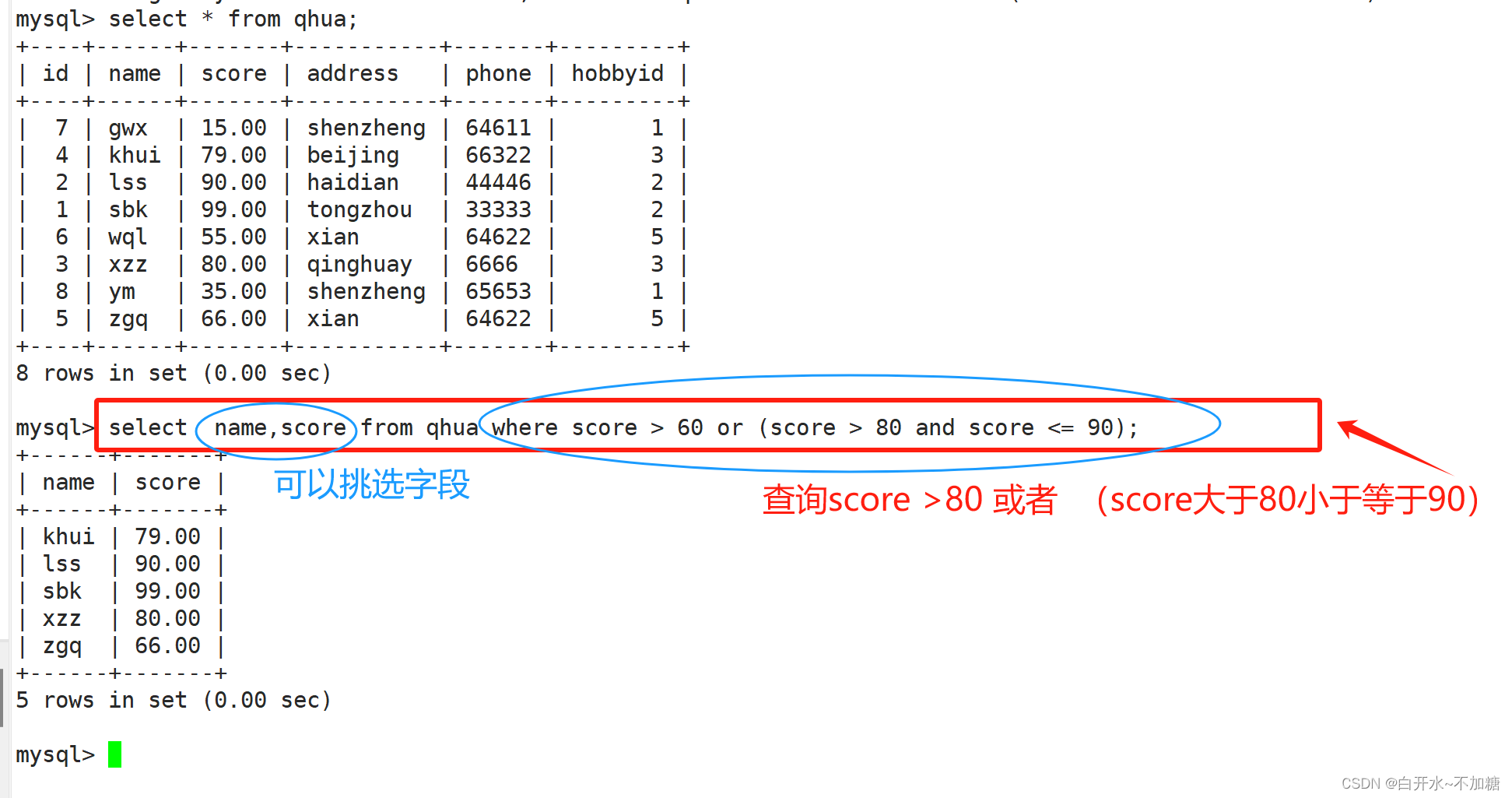
4.2嵌套/多条件
4.3distinct 查询不重复记录
语法:SELECT DISTINCT "字段" FROM "表名";
select distinct address FROM qhua;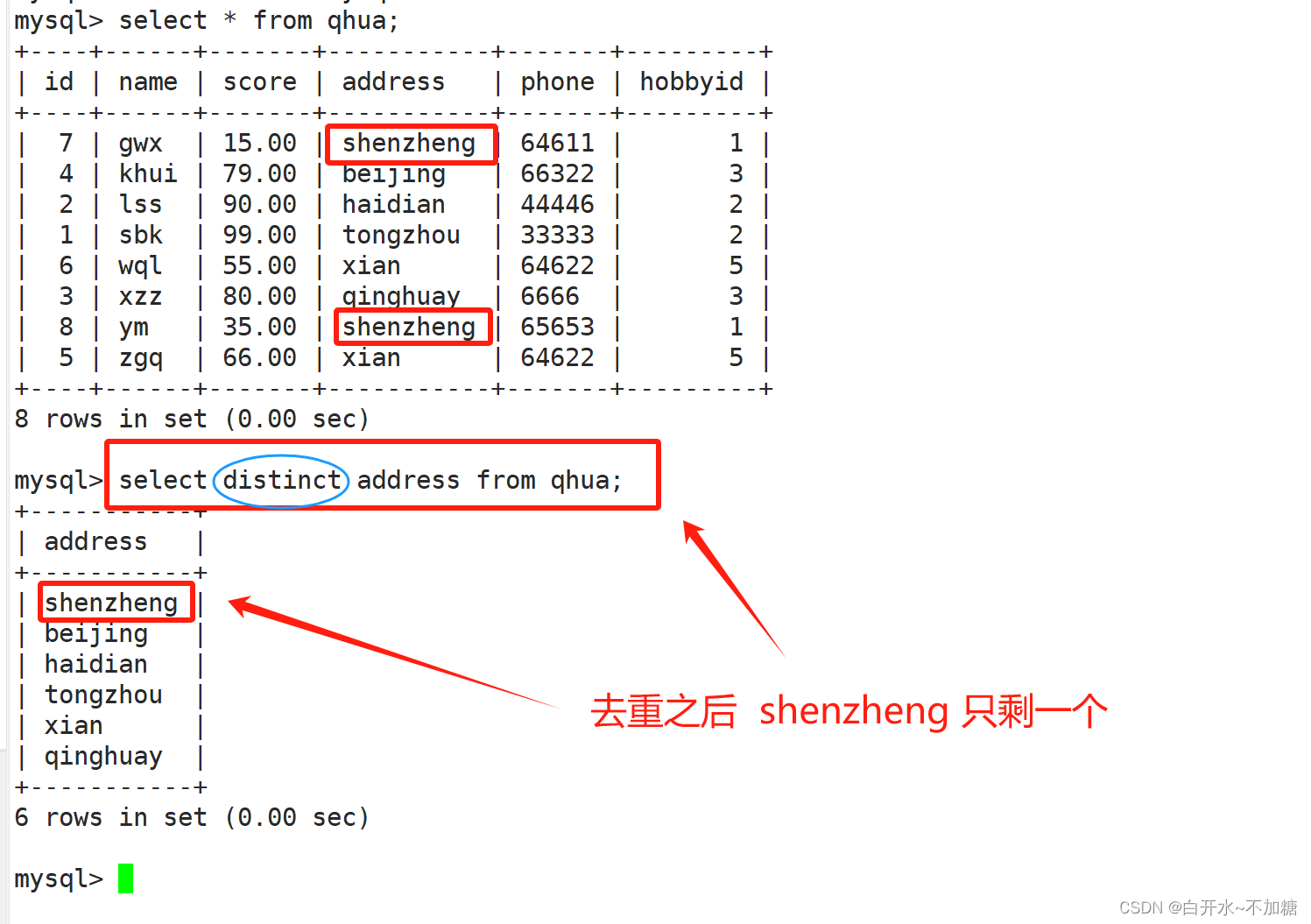
五、group by 与 聚合函数
5.1对结果进行分组 group by
通过 SQL 查询出来的结果,还可以对其进行分组,使用 GROUP BY 语句来实现 ,GROUP BY 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN),GROUP BY 分组的时候可以按一个或多个字段对结果进行分组处理
语法:SELECT "字段1", SUM("字段2") FROM "表名" GROUP BY "字段1";
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name ORDER BY sales desc;语法
SELECT column_name, aggregate_function(column_name)FROM table_name WHERE column_name operator value GROUP BY column_name;
GROUP BY
对GROUP BY后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
GROUP BY 有一个原则,凡是在GROUP BY后面出现的字段,必须在 SELECT 后面出现;
凡是在 SELECT 后面出现的、且未在聚合函数中出现的字段,必须出现在 GROUP BY 后面
按address相同的分组,计算相同分数的学生个数(基于name个数进行计数)
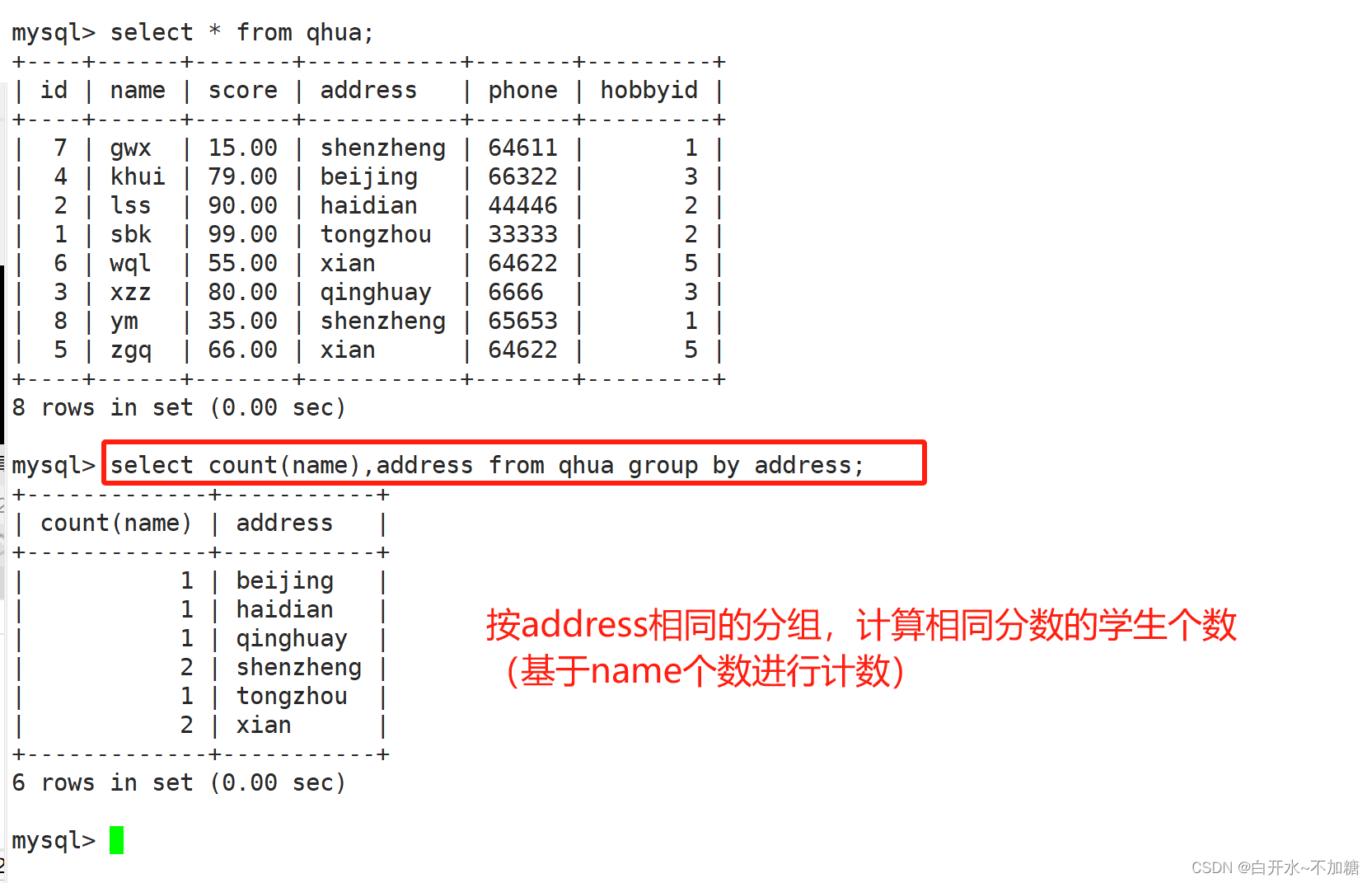
结合where语句,筛选分数大于等于80的分组,计算学生个数(基于name个数进行计数)

还可以结合order by把计算出的学生个数按升序排列 count(name)基于名字统计人员个数
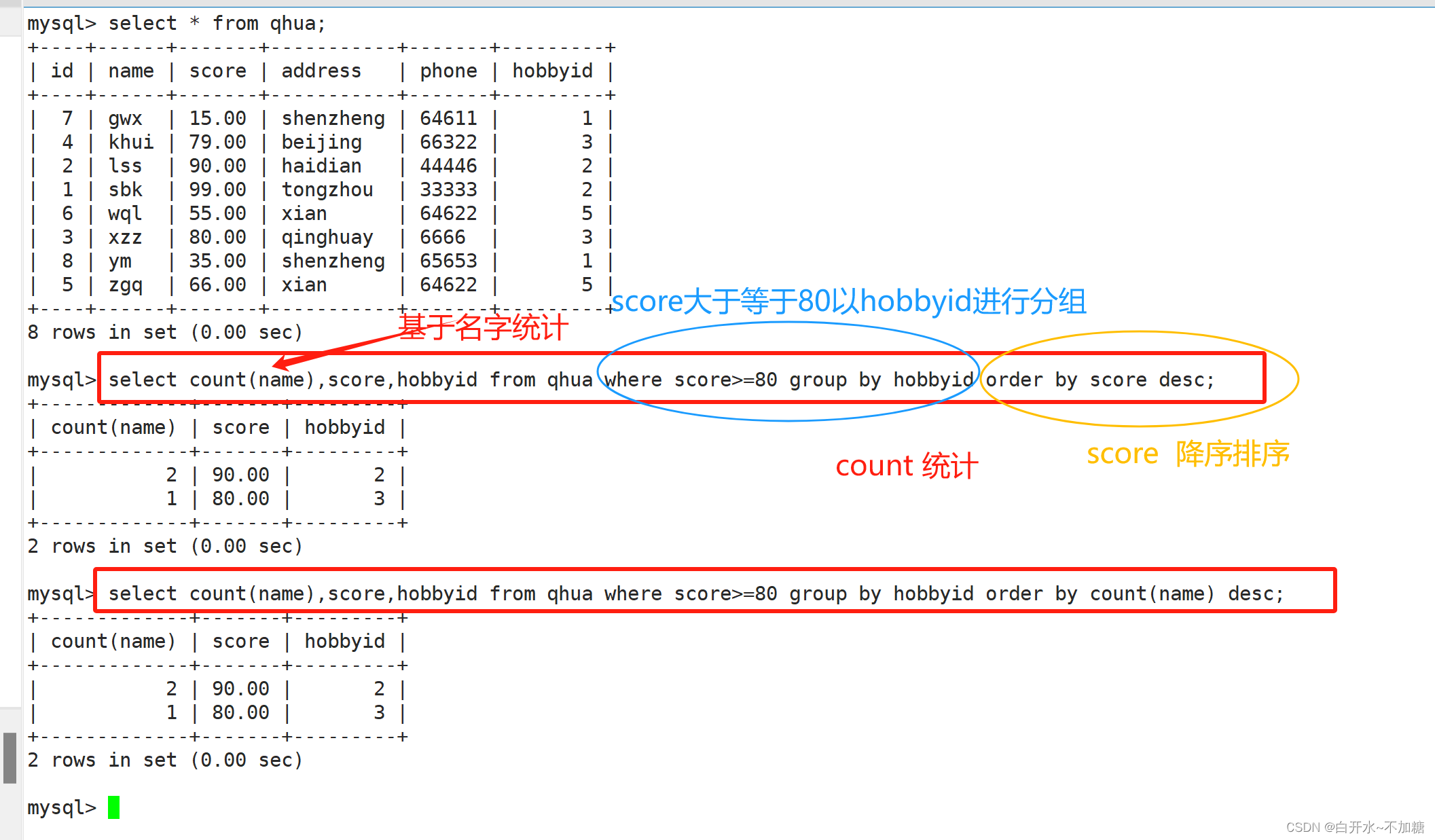
查询表总共有多少条数据
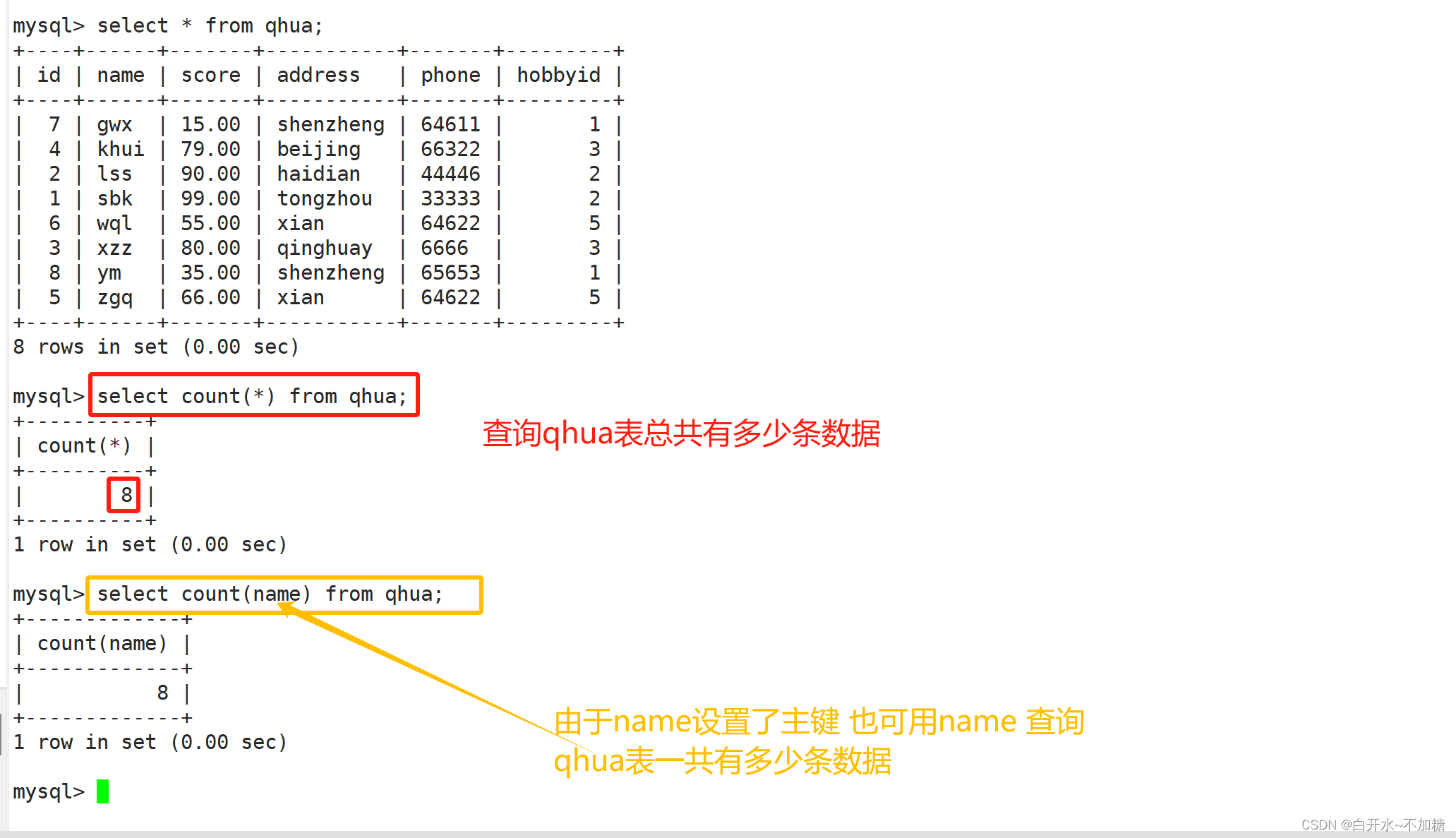
5.2聚合函数
常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN)
| 函数 | 含义 |
|---|---|
| avg() | 返回指定列的平均值 |
| count() | 返回指定列中非 NULL 值的个数 |
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum(x) | 返回指定列的所有值之和 |
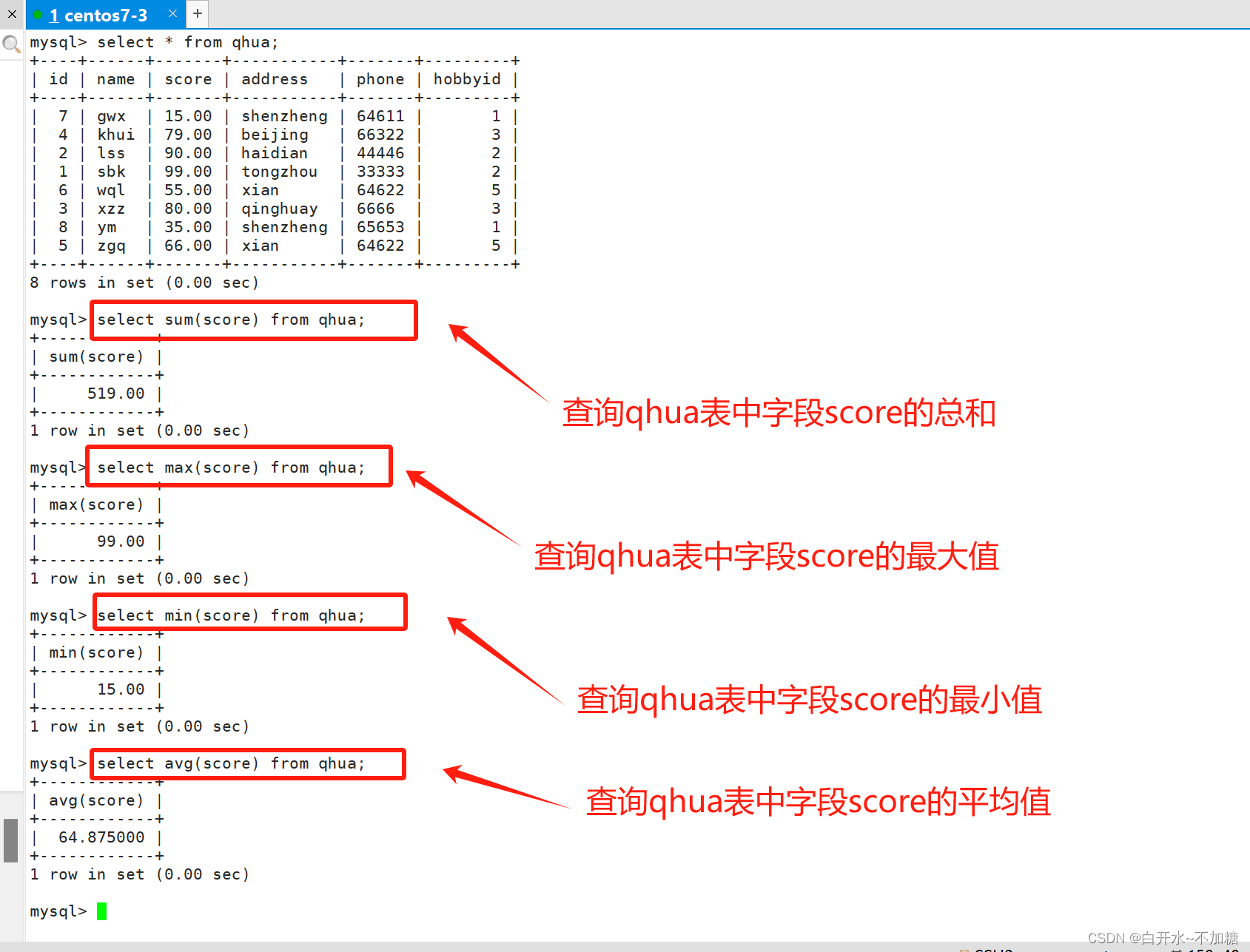
SELECT avg(score) FROM 表名; #查看score字段的平均值
SELECT max(score) FROM 表名; #查看score字段的最小值
SELECT min(score) FROM 表名; #查看score字段的最大值
SELECT sum(score) FROM 表名; #查看score字段的总和
SELECT count(Store_Name) FROM 表名; #查看store_name字段的非null个数
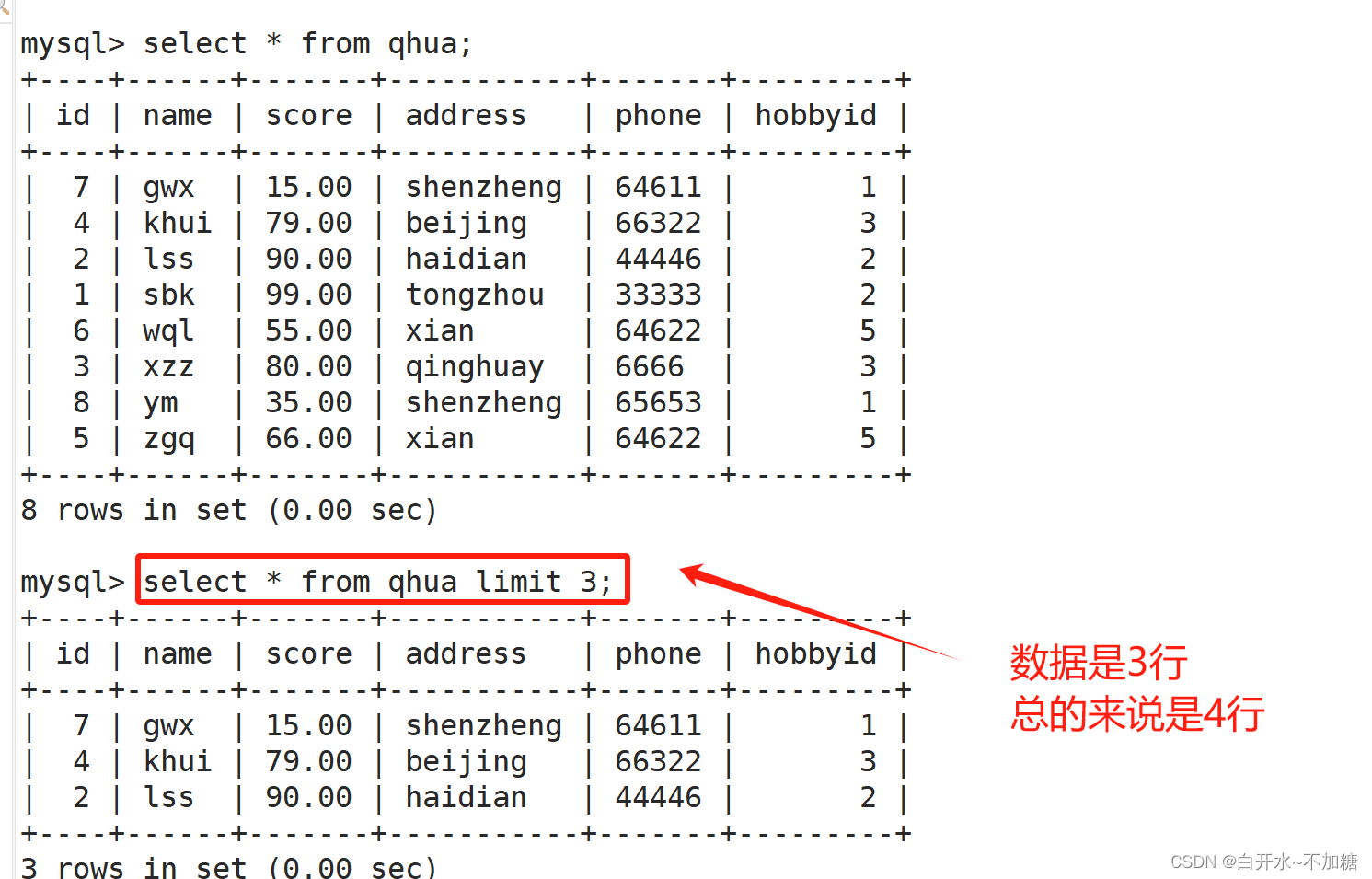
SELECT count(DISTINCT Store_Name) FROM 表名; #查看store_name字段去重后的非null个数六、限制结果条目(limit⭐⭐⭐)
limit 限制输出的结果记录
在使用 MySQL SELECT 语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅 需要返回第一行或者前几行,这时候就需要用到 LIMIT 子句
(1)语法
SELECT column1, column2, ... FROM table_name LIMIT [offset,] numberLIMIT 的第一个参数是位置偏移量(可选参数),是设置 MySQL 从哪一行开始显示。 如果不设定第一个参数,将会从表中的第一条记录开始显示。需要注意的是,第一条记录的 位置偏移量是 0,第二条是 1,以此类推。第二个参数是设置返回记录行的最大数目。
6.1查询所有信息显示前4行记录
6.2从第4行开始,往后显示3行内容
mysql> select * from qhua limit 4,3;
+----+------+-------+-----------+-------+---------+
| id | name | score | address | phone | hobbyid |
+----+------+-------+-----------+-------+---------+
| 6 | wql | 55.00 | xian | 64622 | 5 |
| 3 | xzz | 80.00 | qinghuay | 6666 | 3 |
| 8 | ym | 35.00 | shenzheng | 65653 | 1 |
+----+------+-------+-----------+-------+---------+
3 rows in set (0.00 sec)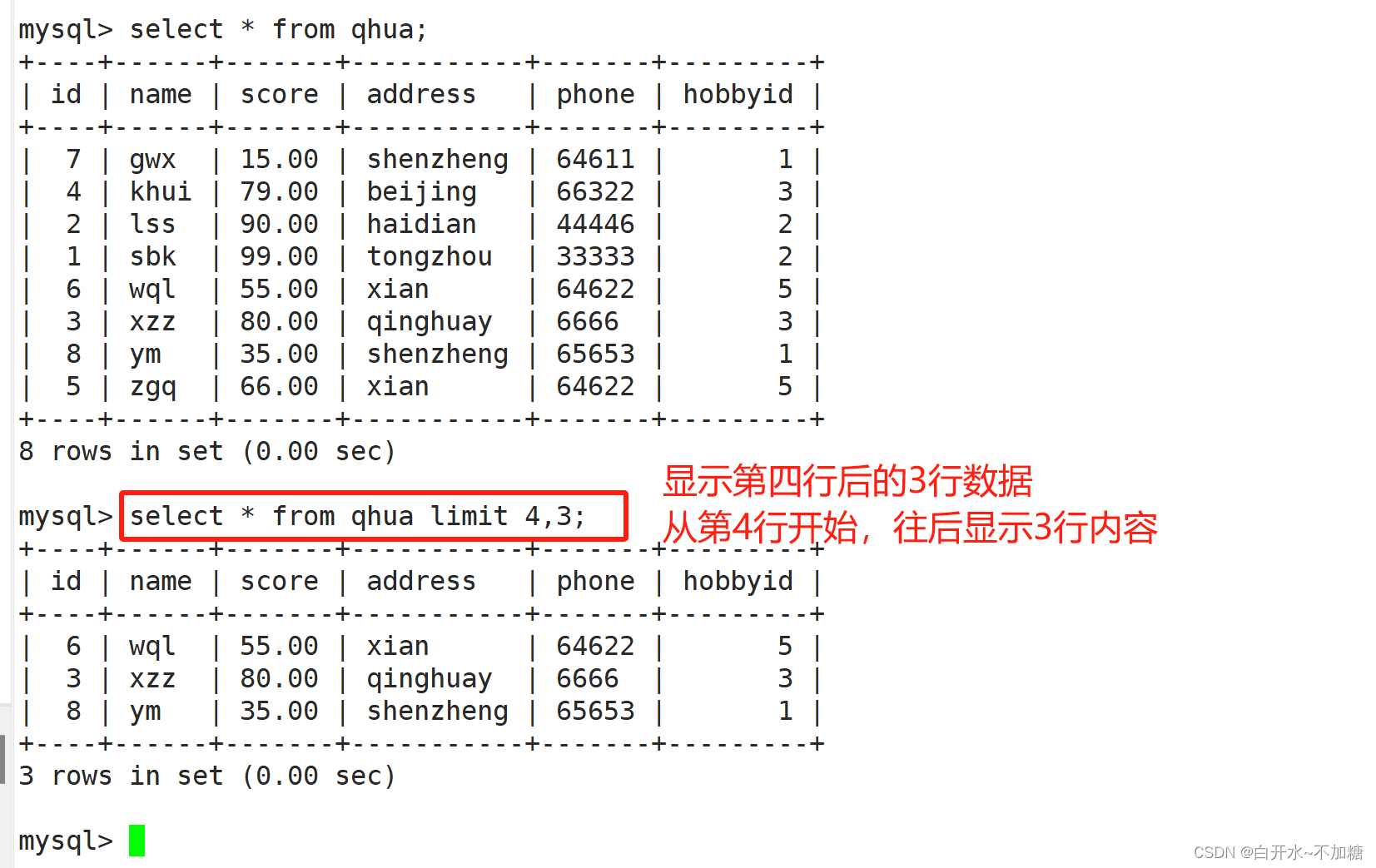
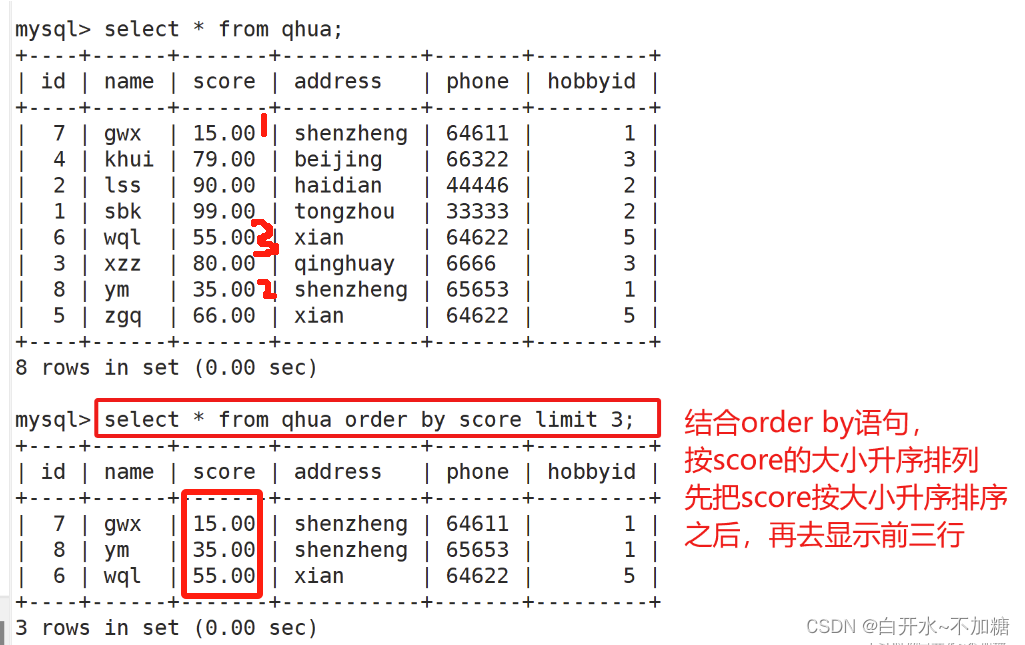
6.3结合order by语句,按score的大小降序排列显示前三行
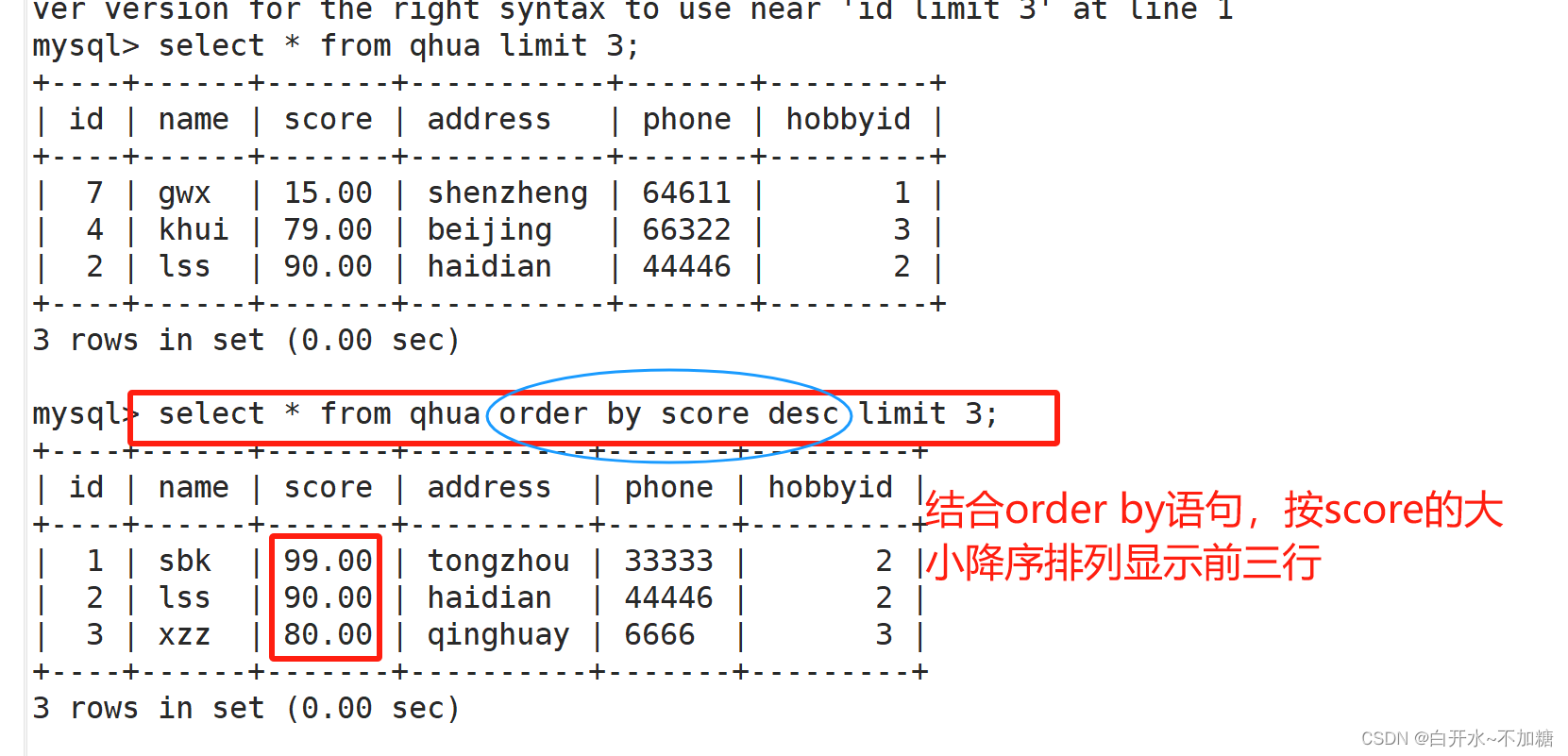
结合order by语句,按score的大小升序排列显示前三行
6.4 假设你要删除数据,你可以先查询数据,确定之后再删除

七、设置别名(alias 简写 as)
在 MySQL 查询时,当表的名字比较长或者表内某些字段比较长时,为了方便书写或者 多次使用相同的表,可以给字段列或表设置别名。使用的时候直接使用别名,简洁明了,增强可读性
(1)语法
对于列的别名:SELECT column_name AS alias_name FROM table_name;
对于表的别名:SELECT column_name(s) FROM table_name AS alias_name;
语法:SELECT "表格別名"."字段1" [AS] "字段別名" FROM "表格名" [AS] "表格別名";
SELECT Store_Name, SUM(Sales) FROM store_info A GROUP BY Store_Name;
SELECT A.Store_Name Store, SUM(A.Sales) "Total Sales" FROM store_info A GROUP BY A.Store_Name;在使用 AS 后,可以用 alias_name 代替 table_name,其中 AS 语句是可选的。AS 之后的别名,主要是为表内的列或者表提供临时的名称,在查询过程中使用,库内实际的表名 或字段名是不会被改变的
如果表的长度比较长,可以使用 AS 给表设置别名,在查询的过程中直接使用别名
临时设置info的别名为i
select i.name as 姓名,i.score as 成绩 from info as i;
列别名设置示例:
select name as 姓名,score as 成绩 from info;
7.1表中 字段列 设置别名
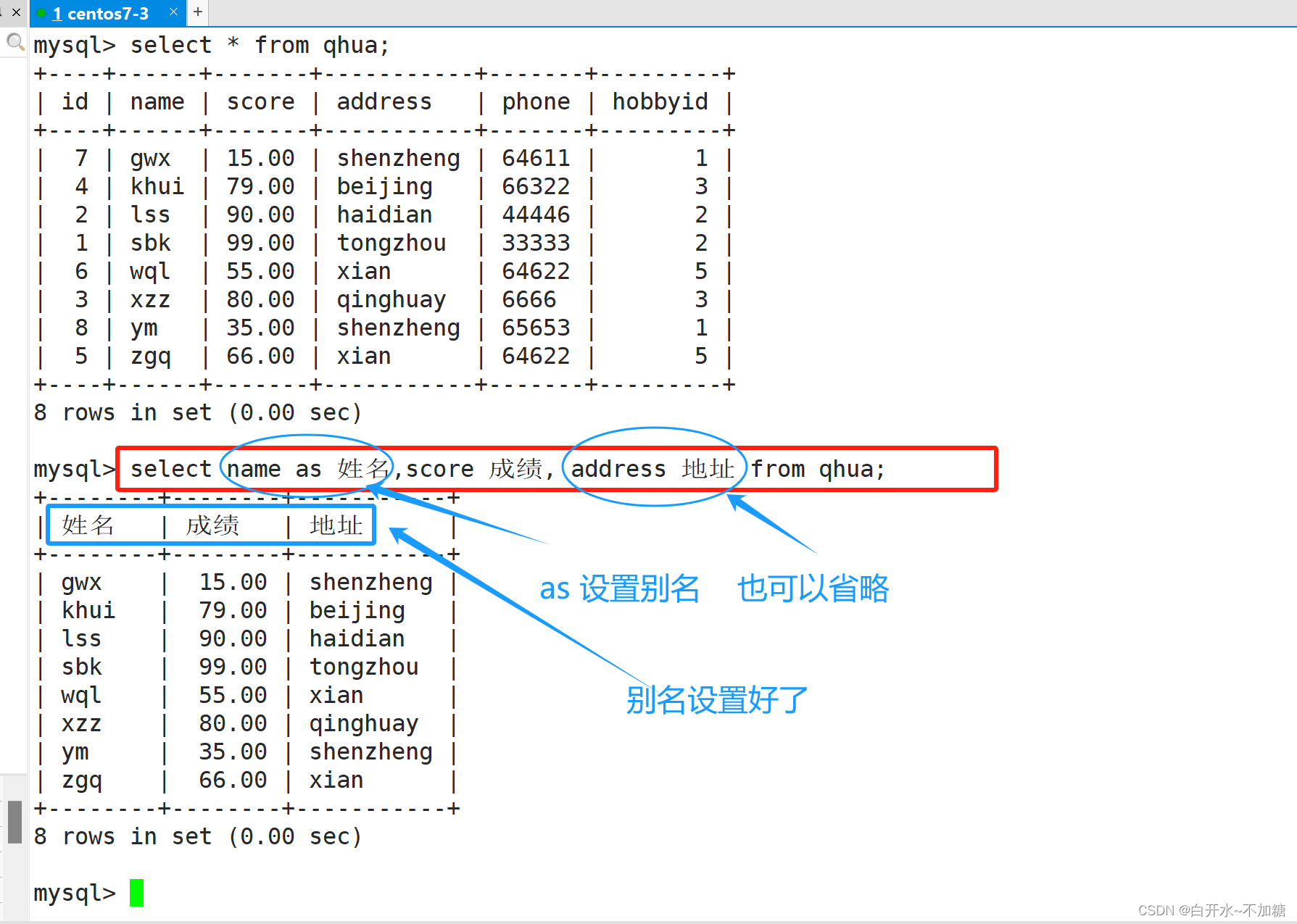
表中数据不变,也不是改表结构,只是设置了别名
使用别名查看总分数
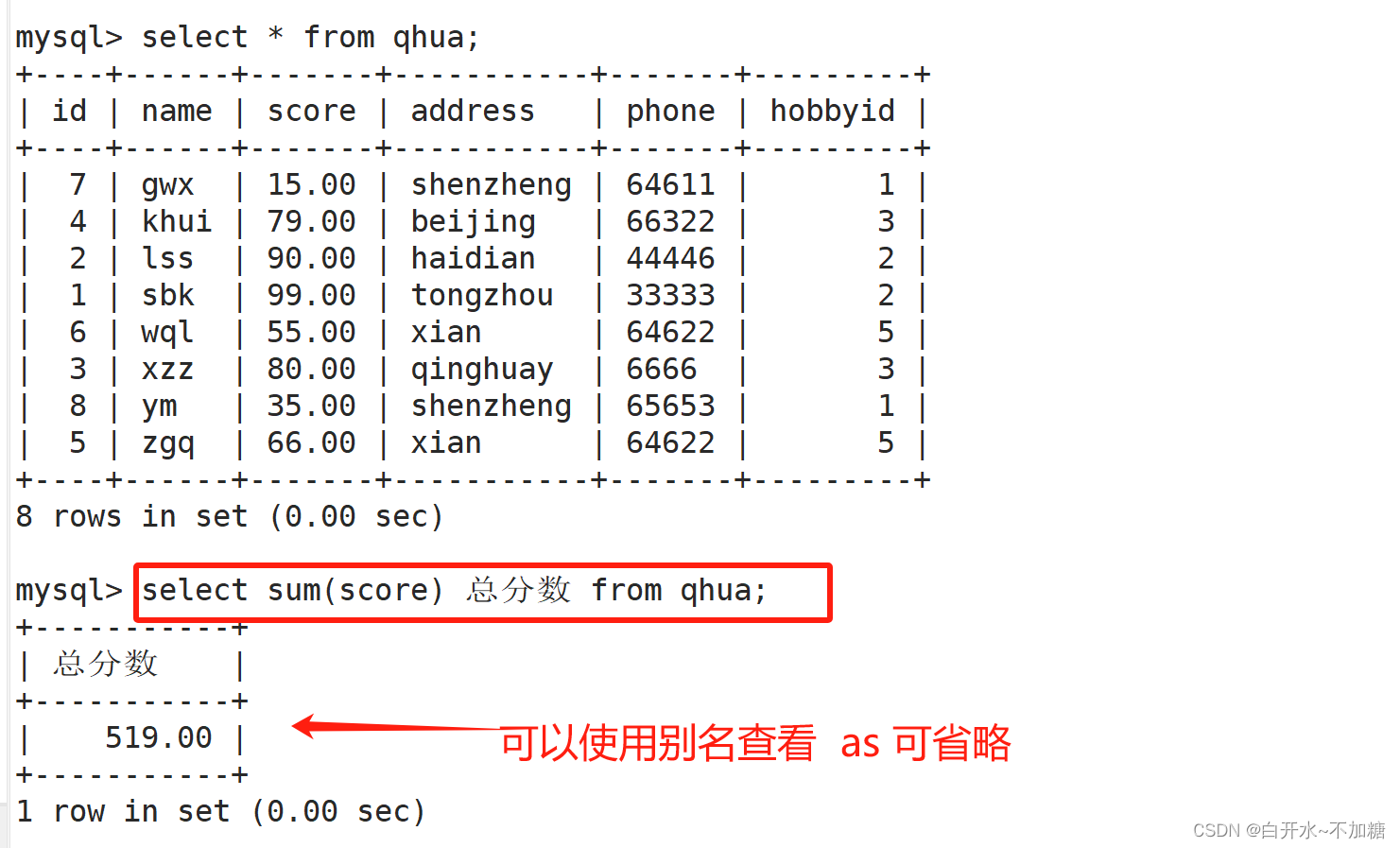
7.2表设置別名
mysql> select q.name as 姓名,q.score 成绩, q.address 地址 from qhua as q;
7.3 as (别名) 使用场景
1、对复杂的表进行查询的时候,别名可以缩短查询语句的长度
2、多表相连查询的时候(通俗易懂、减短sql语句)
7.4创建表设置别名
此外,AS 还可以作为连接语句的操作符。
创建t1表,将info表的查询记录全部插入t1表
#此处AS起到的作用:
1、创建了一个新表t1 并定义表结构,插入表数据(与info表相同)
2、但是”约束“没有被完全”复制“过来 #但是如果原表设置了主键,那么附表的:default字段会默认设置一个0
相似:
克隆、复制表数据
create table t1 (select * from info);
#也可以加入where 语句判断
create table test1 as select * from info where score >=60;
在为表设置别名时,要保证别名不能与数据库中的其他表的名称冲突。
列的别名是在结果中有显示的,而表的别名在结果中没有显示,只在执行查询时使用。
方法一:创建表时设置别名
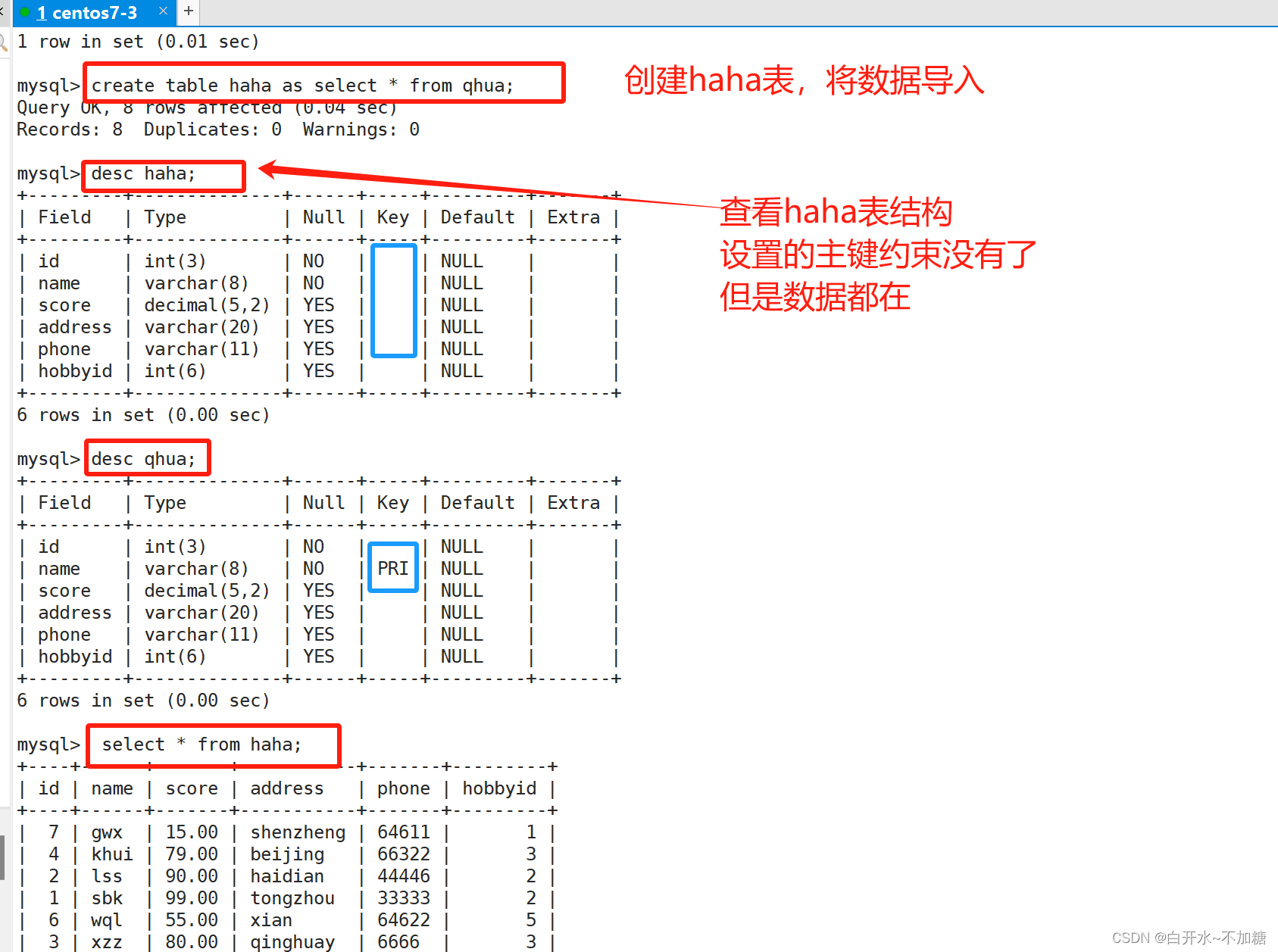
as在此处命令中起到创建了一个新表haha并定义表结构,插入表数据(与qhua表相同),”约束“没有被完全”复制“过来,但是如果原来的表设置了主键,那么附表的default字段会默认设置一个0。
方法二:克隆、复制表数据 as 可省略
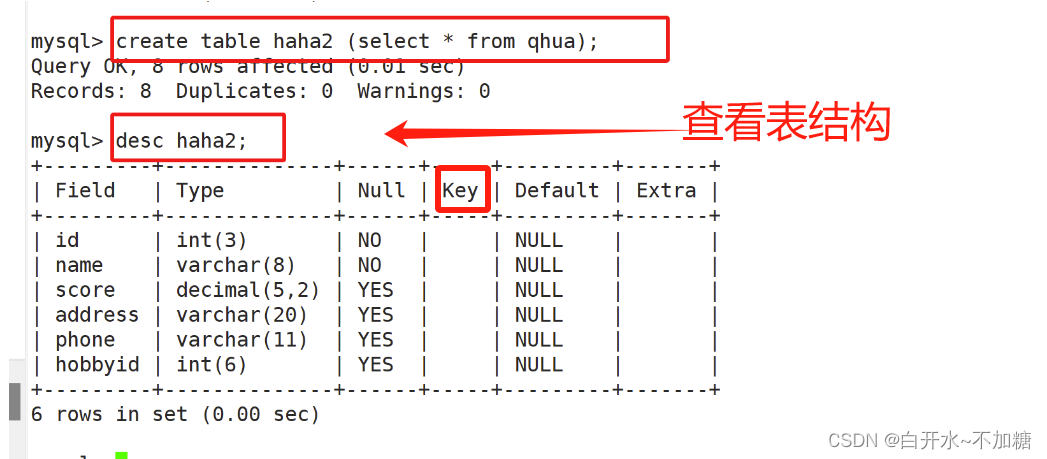

相当于只是备份了表数据,表结构没有
方法三: as 设置别名时 也可以加入where 语句判断
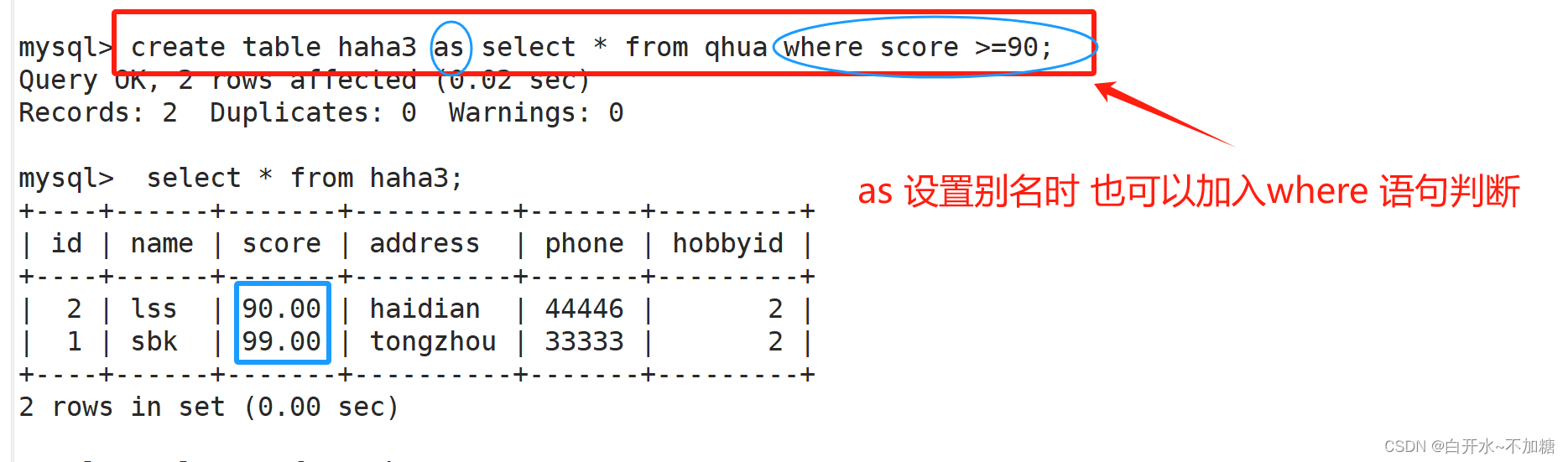
只导入了符合条件的数据
八、通配符
- 通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来。
- 通常通配符都是跟 LIKE 一起使用的,并协同 WHERE 子句共同来完成查询任务。常用的通配符有两个,分别是:
%:百分号表示零个、一个或多个字符
_:下划线表示单个字符
8.1查询名字是z开头的记录
select name,score from qhua where name like 'z%';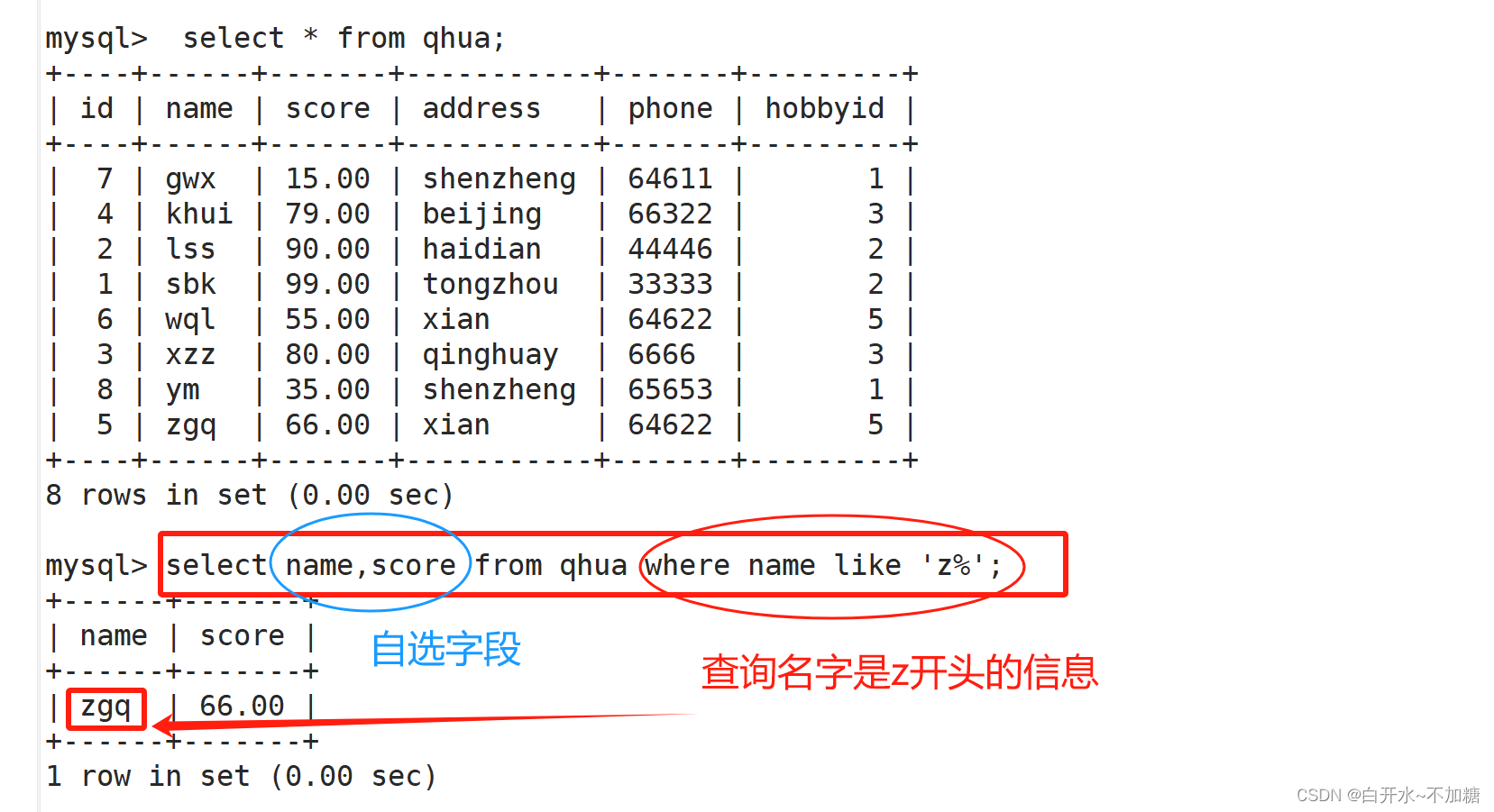
8.2查询名字是z结尾的记录
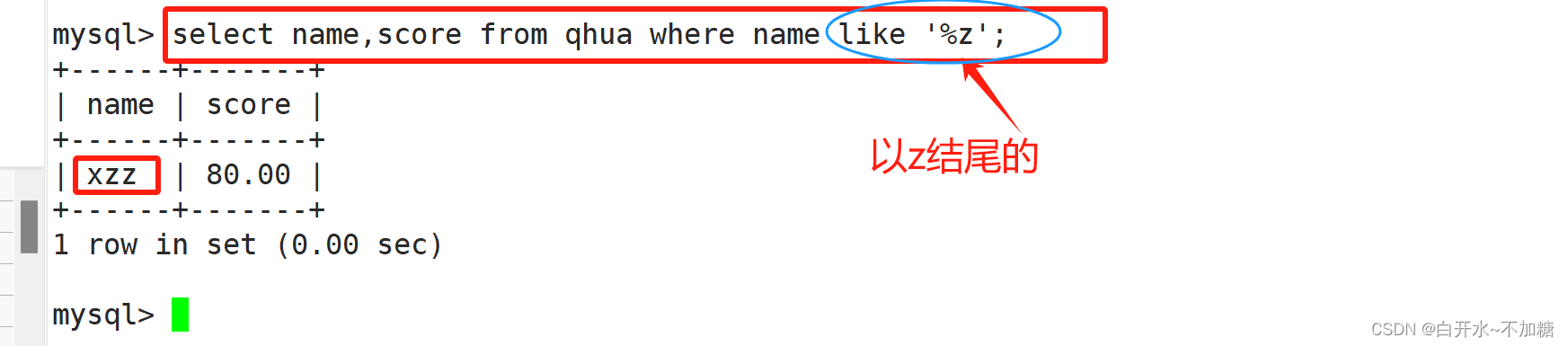
8.3查询address里是x和a中间有一个字符的记录
select name,address from qhua where address like 'x_a_';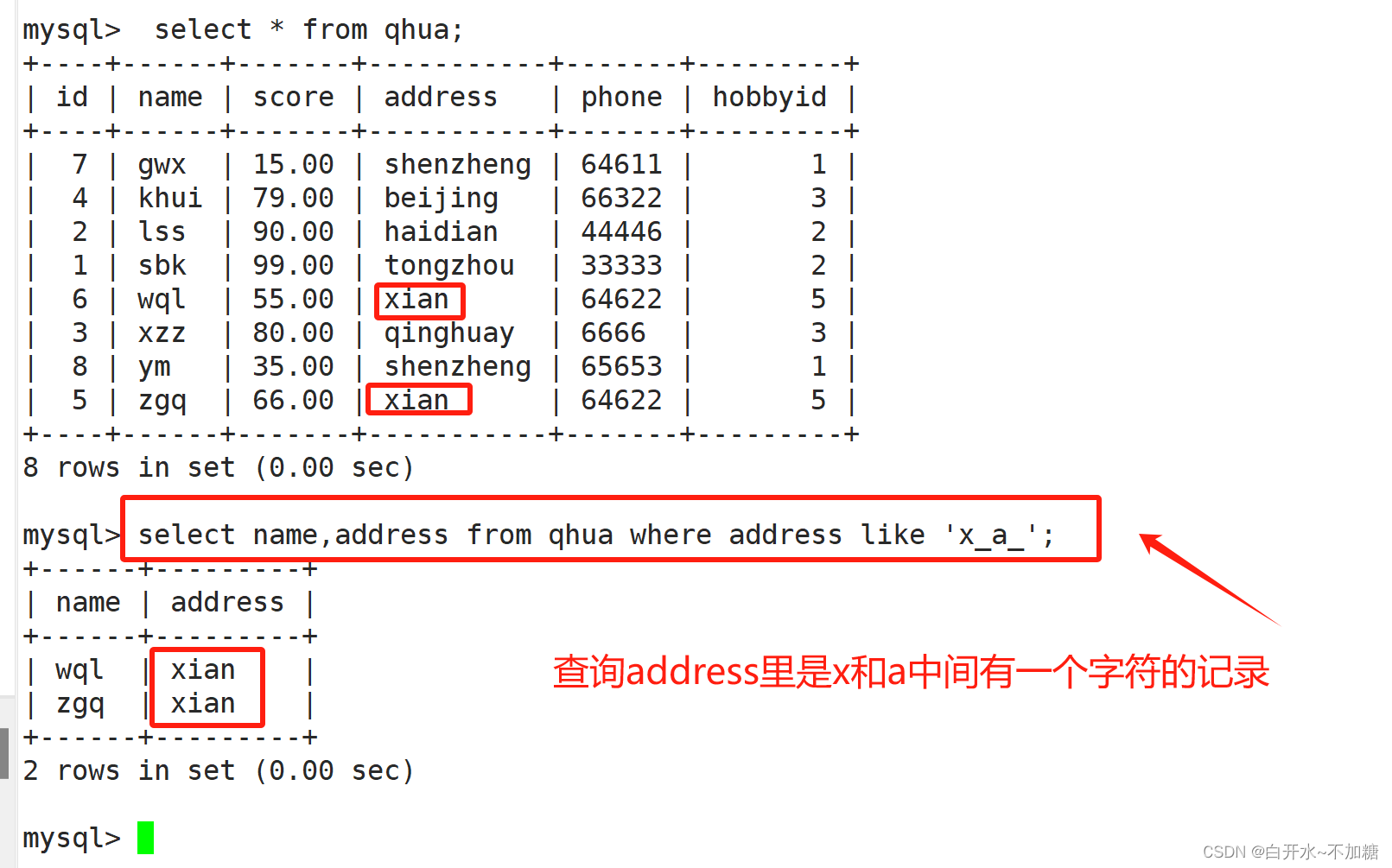
8.4查询shenz后面4个字符的地址记录
select name,address from qhua where address like 'shenz____';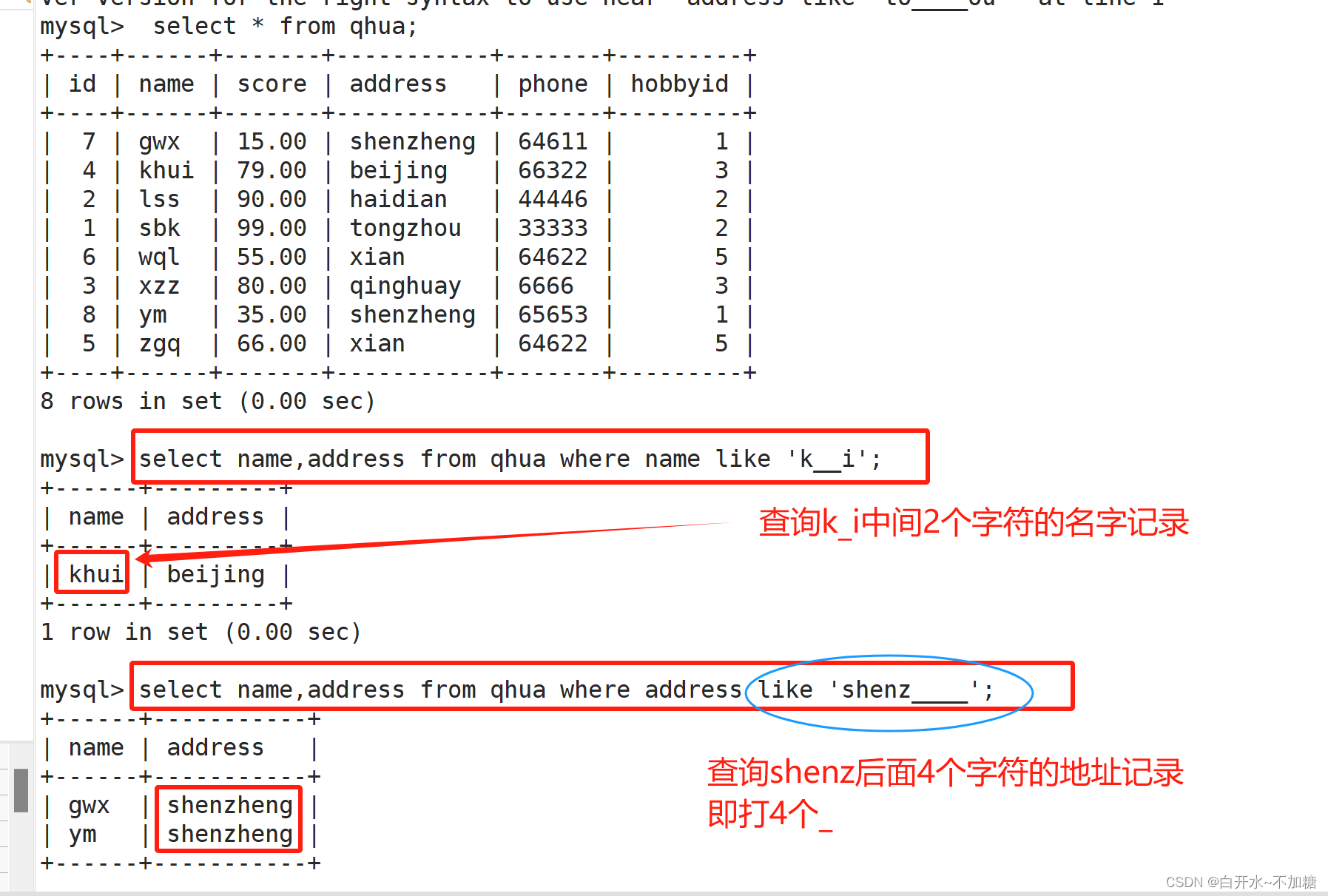
8.5查询地址中间有g的记录
select name,address from qhua where address like '%h%';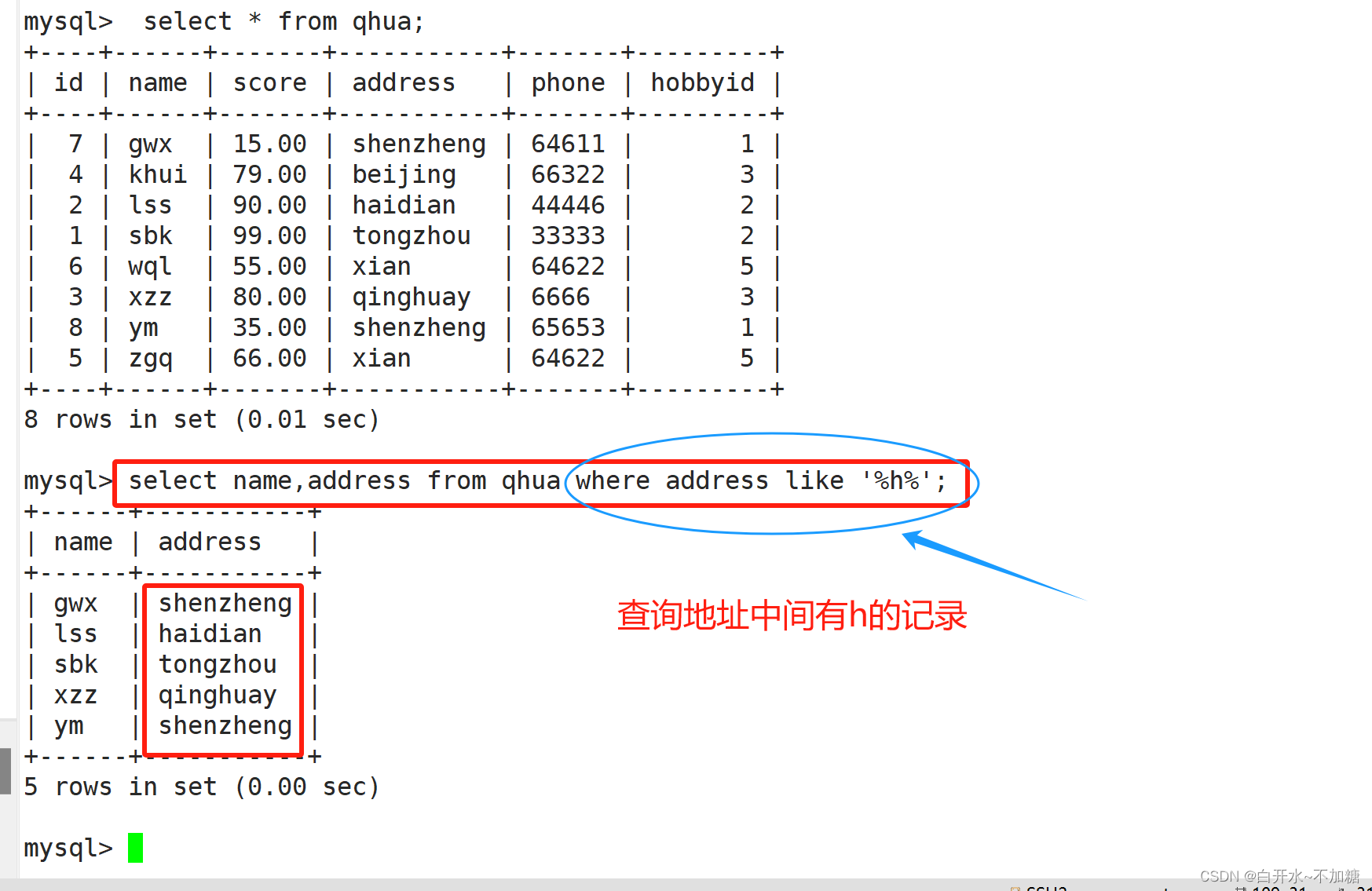
8.6 “%”和“_”结合使用
通配符“%”和“_”不仅可以单独使用,也可以组合使用
查询名字以l开头的记录
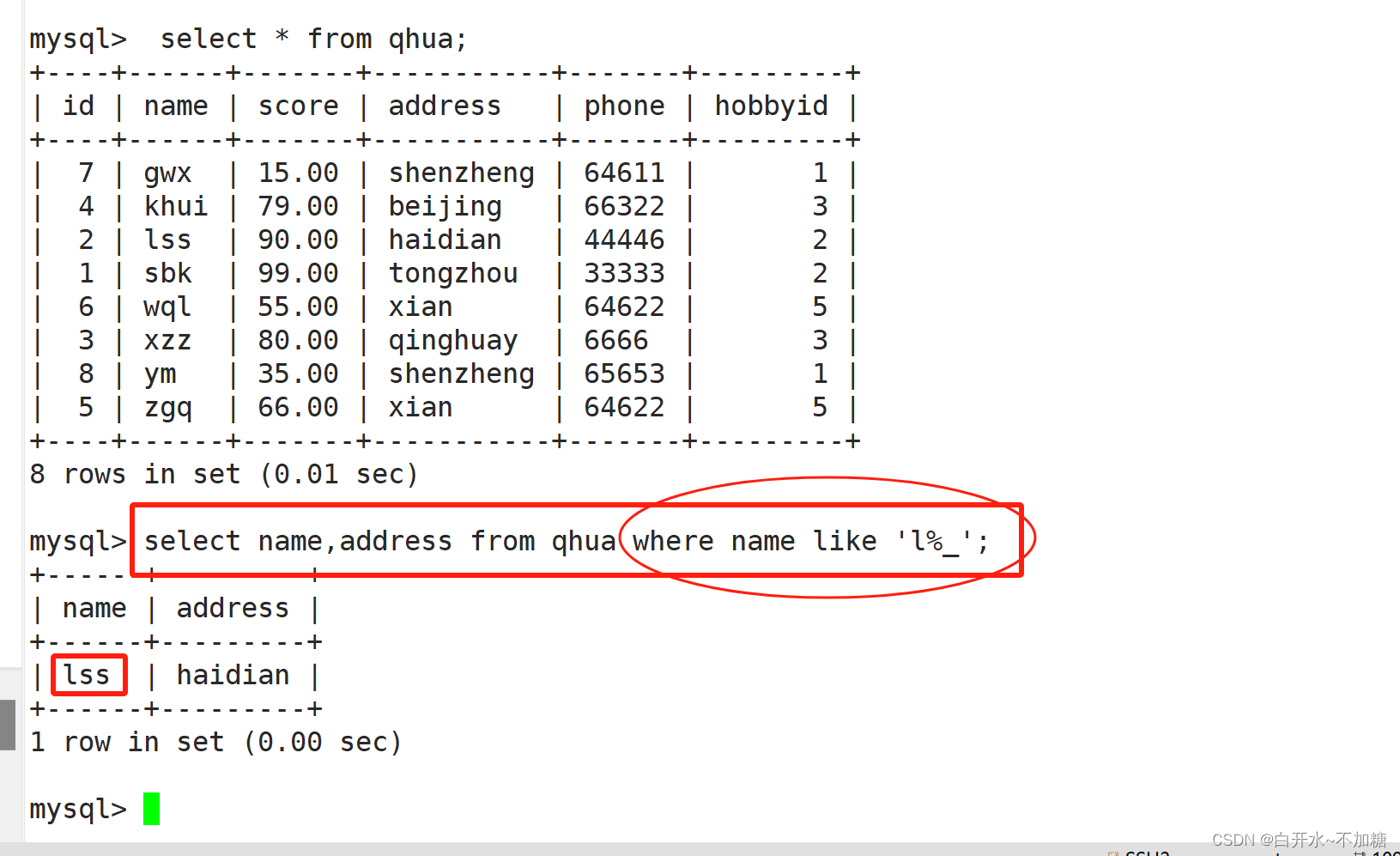
总结
1、as (别名) 使用场景
- 对复杂的表进行查询的时候,别名可以缩短查询语句的长度
- 多表相连查询的时候(通俗易懂、减短sql语句)
使用as设置表的别名,对表进行区分,这对数据的查询非常重要,根据不同的环境,使用不同的方法进行数据的查询、分析
2、聚合函数
常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN)
3、ASC 是按照升序进行排序的,是默认的排序方式,即 ASC 可以省略,结合ORDER BY 语句来对语句实现排序
order by 排序
指定字段默认排序
select 字段1,字段2,... from 表名 order by 排序字段;
指定字段降序
select 字段1,字段2,... from 表名 order by 排序字段 desc;
结合where子句进行条件过滤
select 字段1,字段2,... from 表名 where 字段='过滤值' order by 排序字段 desc;
多字段排序
select 字段1,字段2,... from 表名 order by 排序字段1,排序字段2;结合where条件
select 字段1,字段2... from 表名 where 字段名='字段值' order by 字段1,字段2... asc | desc ;and或or
select * from kysw where score >值 and score <=值;去重
select distinct 字段 from 表名;限制
select 字段 from 表名 where 字段 limit 数字1,数字2;设置别名alias
别名的设置是临时的,只有临时的显示效果,并不会修改表的结构
列的别名
select 列名1,列名2 as 别名,... from 表名;
表的别名
select 别名.列名1,别名.列名2,... from 表名 as 别名;
as 将查询的数据导入新表
create table 新表名 as select * from 表名;列的别名 select 字段 as 字段别名 表名
表的别名 select 别名.字段 from 表名 as 别名通配符
% 和 _ 与like和where子句共同完成查询任务;对大小写不敏感
select * from 表名 where 字段 like '通配符';
##like模糊查询
%:百分号表示零个、一个或多个字符 *
_:下划线表示单个字符 .查询以xxx开头的记录
select * from 表名 where name like 'l%';
查询 xxx 隔xxx个字符后为 xxx 的记录
select * from 表名 where name like '%i_l%';

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)