MongoDB、Redis、HBase、Neo4j,四种数据库的特点和应用场景
开源的NoSQL文档数据库基于硬盘运行但支持内存缓存支持分布式架构支持复杂查询和索引开源的分布式列式数据库,属于 NoSQL 数据库家族运行在 Hadoop 分布式文件系统(HDFS)之上,适合处理海量数据支持稀疏数据模型,采用列族存储结构高吞吐量,适合大规模随机读写操作提供强大的水平扩展能力,能够处理 PB 级数据开源的图数据库,专为图形数据存储和查询设计基于图形数据模型,采用节点、关系和属性的
一、Redis(键值对存储数据库)简介
1.Redis本质与特点
开源的NoSQL数据库
基于内存运行的数据库,但可以持久化到硬盘
单线程模型,保证操作的原子性
支持多种数据结构存储
支持数据备份和复制
2.Redis的数据结构
字符串(String):最基本的数据类型,可以存储文本或二进制数据
哈希(Hash):适合存储对象,类似于Java中的Map
列表(List):有序的字符串列表,支持双向操作
集合(Set):无序的唯一字符串集合
有序集合(Sorted Set):每个元素关联一个分数的有序集合
★3.主要应用场景
数据缓存:缓存热点数据,减轻数据库压力
★会话存储:存储网站会话信息(Session)
排行榜:利用有序集合实现实时排行
计数器:如文章点赞数、视频播放量
消息队列:实现简单的消息队列功能
实时统计:网站访问统计、用户行为分析
4.Redis的优势
极高的读写性能:基于内存操作
丰富的数据类型支持
原子性操作保证:单线程模型
支持数据持久化
主从复制功能
支持事务处理
支持Lua脚本扩展
5.Redis的局限性
内存限制:数据量受限于服务器内存
单线程特性:无法充分利用多核CPU
持久化成本:数据持久化会影响性能
数据一致性:主从复制为异步,可能数据不一致
成本较高:内存成本高于硬盘存储
★6.应用场景举例
a) 社交网络
用户关系存储
消息通知队列
在线用户统计
b) 电商平台
商品库存管理
★购物车信息
商品访问统计
秒杀活动支持
c) 游戏应用
玩家积分排行
在线玩家状态
游戏进度缓存
d) 内容网站
热门内容缓存
阅读量统计
用户浏览历史
7.Redis表示例
# 存储字符串
SET user:1 '{"name":"张三","age":25}'
GET user:1
# 存储数字
SET visits 2468
INCR visits
# 操作列表
LPUSH colors red
LPUSH colors blue
LPUSH colors green
LRANGE colors 0 -1
# 操作集合
SADD user:logins 20240315
SADD user:logins 20240316
SMEMBERS user:logins
Redis本身是一个键值数据库,不像传统关系数据库那样有表名的概念。每个键值对都是独立存储的。
★9.Reids特点+应用场景




10.键值对存储数据库结构示意图
二、MongoDB(文档存储数据库)简介
1.MongoDB本质与特点
开源的NoSQL文档数据库
基于硬盘运行但支持内存缓存
支持分布式架构
支持复杂查询和索引
2.MongoDB的数据结构
文档(Document): JSON、xml、BSON格式数据存储单元
集合 (Collection):类似于传统关系型数据库中的表,但无需预定义模式
3.主要应用场景
大规模数据存储:处理TB级数据
非结构化数据管理:灵活存储多种类型的非结构化或半结构化数据
物联网数据:处理高并发数据
日志系统:高效的写入性能满足实时日志采集需求
实时数据分析:支持复杂的聚合和查询操作
物联网数据:处理高并发的数据流和实时数据存储
内容管理:用于存储文章、评论和多媒体数据
4.MongoDB的优势
灵活的数据模型:无需预定义结构
强大的查询能力:支持多种查询操作
高可用性:副本集保证数据可靠
水平扩展:支持分片
二级索引支持:优化查询性能
5.MongoDB的局限性
事务支持有限:多文档事务较新
连接操作性能:关联查询效率低
内存消耗大:索引占用内存
数据一致性:最终一致性模型
磁盘空间:占用空间较大
6.应用场景举例
a) 社交网络
用户信息存储
动态和评论管理
实时消息存储
b) 电商平台
商品信息存储(例如产品描述和评论)
订单数据管理
个性化推荐系统
c) 物联网
传感器数据存储
实时数据流处理
设备状态跟踪
d) 企业应用
实时数据仓库
报告和分析存储
7.MongoDB文档示例
# 插入文档
db.users.insertOne({"name": "李四", "age": 30, "hobbies": ["篮球", "阅读"]})
# 查询文档
db.users.find({"name": "李四"})
# 更新文档
db.users.updateOne({"name": "李四"}, {"$set": {"age": 31}})
# 删除文档
db.users.deleteOne({"name": "李四"})
# 聚合查询
db.orders.aggregate([
{"$match": {"status": "completed"}},
{"$group": {"_id": "$user_id", "total_spent": {"$sum": "$amount"}}}
])
★9.MongoDB特点+应用场景





10.文档数据库的结构示意图
三、HBase(列式存储数据库)简介
1.HBase本质与特点
开源的分布式列式数据库,属于 NoSQL 数据库家族
运行在 Hadoop 分布式文件系统(HDFS)之上,适合处理海量数据
支持稀疏数据模型,采用列族存储结构
高吞吐量,适合大规模随机读写操作
提供强大的水平扩展能力,能够处理 PB 级数据
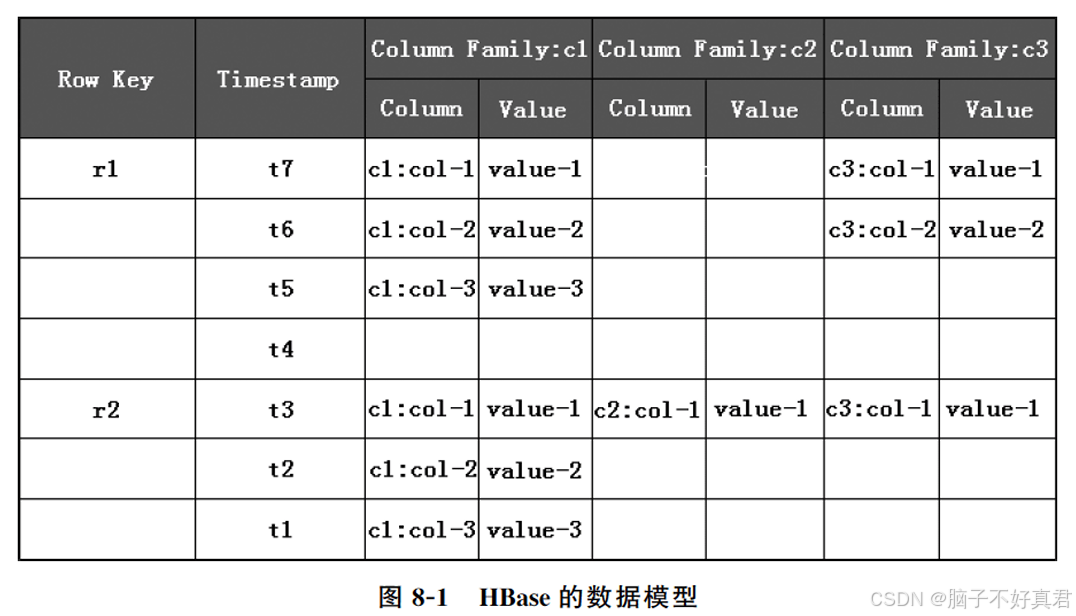
2.HBase的数据结构
表 (Table):类似于关系型数据库中的表,但具有动态列的特点
行键 (Row Key):每一行的唯一标识,用于快速定位数据
列族 (Column Family):数据按列族组织存储,每个列族包含多个列
单元格 (Cell):存储具体的数据单元,每个单元格有时间戳,支持版本管理
3.主要应用场景
海量数据存储:适合存储 PB 级别的大规模数据,如互联网日志、点击流数据等
实时查询:支持对单行数据的快速随机读写操作
时间序列数据:能够高效存储和查询按时间排序的数据,如传感器读数或金融交易数据
物联网数据:处理设备的状态信息和实时数据流
搜索引擎:索引存储及高效检索
4.HBase的优势
水平扩展性:通过添加节点,轻松扩展存储容量和计算能力
高吞吐量:适合高频随机写入和批量数据处理
稀疏数据支持:按需存储,减少空白数据的存储成本
时间版本管理:支持为每个单元格存储多个版本的数据
Hadoop生态集成:与 MapReduce、Spark 等框架无缝结合
5.HBase的局限性
查询能力有限:不支持复杂查询和事务,需依赖应用层处理
延迟较高:与内存数据库(如 Redis)相比,查询延迟较大
维护复杂:分布式系统的运维和调优难度较高
内存需求大:对集群节点的内存和磁盘性能要求较高
无原生索引:需开发者自行设计索引或结合其他工具实现
6.应用场景举例
a) 社交网络
用户行为日志存储
动态发布和查询
大规模用户关系存储
b) 电商平台
商品点击流日志记录
用户搜索记录存储
实时库存管理
c) 物联网
设备传感器数据收集
时间序列数据存储和分析
设备状态监控
d) 企业应用
数据归档和备份
日志系统的大规模存储和分析
大型数据集的离线分析
7.HBase表示例
# 创建表
create 'users', 'info', 'activity'
# 插入数据
put 'users', 'row1', 'info:name', '张三'
put 'users', 'row1', 'info:age', '25'
put 'users', 'row1', 'activity:last_login', '2024-03-15'

# 查询数据
# 查询一行数据
get 'users', 'row1'
# 查询列族中的数据
scan 'users', {COLUMNS => ['info']}
# 删除数据
# 删除某个单元格
delete 'users', 'row1', 'info:age'
# 删除一行数据
deleteall 'users', 'row1'
★9.HBase特点+应用场景


10.列式存储数据库的结构示意图
四、Neo4j(图形存储数据库)简介
1.Neo4j本质与特点
开源的图数据库,专为图形数据存储和查询设计
基于图形数据模型,采用节点、关系和属性的结构
支持ACID事务,确保数据一致性和可靠性
强大的图形查询能力,支持图遍历、模式匹配等复杂操作
2.Neo4j的数据结构
节点(Node):图中的实体,表示事物或对象(如用户、商品等)
关系(Relationship):连接节点的边,表示节点之间的关联或互动
属性(Property):节点或关系的附加信息,可以是键值对
标签(Label):用于对节点进行分类,类似于关系型数据库中的表
图(Graph):由节点和关系构成的结构,表示整个图的集合
3.主要应用场景
社交网络:用户关系、好友推荐、社交动态分析
推荐系统:基于用户行为和物品之间的关系进行个性化推荐
知识图谱:用于组织和查询大量关联数据,构建实体之间的关系
金融反欺诈:通过关系图分析交易行为,识别潜在的欺诈行为
供应链管理:分析产品、供应商、客户之间的复杂关系
4.Neo4j的优势
高效的图形查询能力:支持图遍历、模式匹配等复杂查询
ACID事务支持:确保数据一致性和事务的可靠性
灵活的模式:图数据模型自然表达多样的关系,不需要预定义固定模式
性能优越:图查询和遍历操作在处理大量复杂关系时表现优秀
强大的可扩展性:支持水平扩展,通过分片实现大规模数据存储
5.Neo4j的局限性
学习曲线:图数据库的查询语言(Cypher)与传统SQL差异较大,学习上可能需要一定的适应
关系查询性能:在处理关系复杂且密集的查询时,可能会受到性能瓶颈影响
事务性能:虽然支持ACID事务,但在高并发场景下,事务性能相对较弱
硬件需求:图数据库对硬件资源的要求较高,尤其是内存和存储性能
6.应用场景举例
a)社交网络
用户关系和好友推荐
动态内容推荐
社交分析和社区发现
b)推荐系统
基于物品和用户之间的关系进行产品推荐
个性化内容推送
c)知识图谱用
于表示和查询学科间的关系
在搜索引擎中提升查询的智能化和精准度
d)金融反欺诈
分析交易数据和行为,识别不正常的交易模式
监控银行转账、投资行为等的关联模式
7.Neo4j图示例
# 插入节点
CREATE (n:Person {name: "李四", age: 30, hobbies: ["篮球", "阅读"]})# 查询节点
MATCH (n:Person {name: "李四"}) RETURN n# 更新节点
MATCH (n:Person {name: "李四"}) SET n.age = 31# 删除节点
MATCH (n:Person {name: "李四"}) DELETE n# 创建关系
MATCH (a:Person {name: "李四"}), (b:Person {name: "张三"})
CREATE (a)-[:FRIEND]->(b)# 聚合查询
MATCH (o:Order)-[:PLACED_BY]->(u:User)
WHERE o.status = "completed"
RETURN u.name, SUM(o.amount) AS total_spent★9.Neo4j特点+应用场景



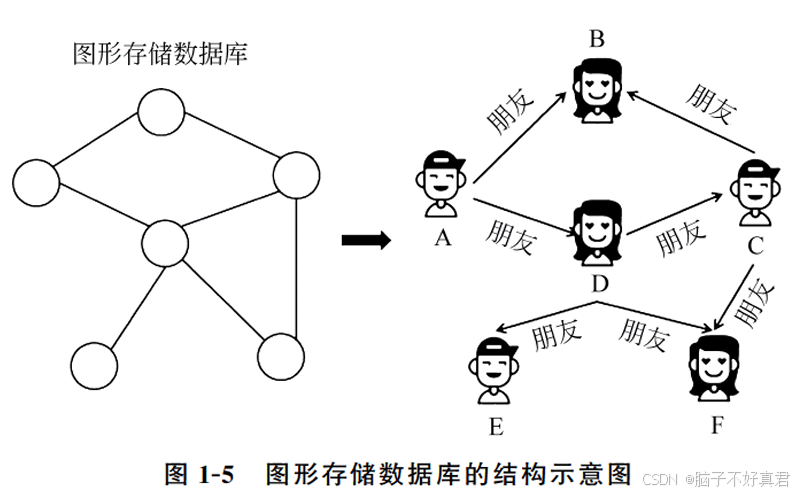
10.图形数据库的结构示意图

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)