运维云计算SRE-第8周
nat和tomcat
1. 总结 tomcat实现多虚拟机
#tomcat实现多虚拟机
#1、下载安装软件java-1.8.0.jdk和tomcat
#切换指定目录
cd /usr/local/src/
#oracle官网下载jdk-8u391-linux-x64.tar.gz:
https://www.oracle.com/java/technologies/downloads/?er=221886#java8
#apache官网下载tomcat
wget https://dlcdn.apache.org/tomcat/tomcat-9/v9.0.97/bin/apache-tomcat-9.0.97.tar.gz
#2、二进制安装java和tomcat,并启动tomcat
tar -xvf apache-tomcat-9.0.97.tar.gz #解压tomcat压缩包
tar -xvf jdk-8u391-linux-x64.tar.gz #解压java压缩包
ln -s jdk1.8.0_241/ jdk #添加java软连接
ln -s apache-tomcat-9.0.97/ tomcat #添加tomcat软连接
# 使用vim编辑器打开或创建/etc/profile.d/jdk.sh文件,用于配置Java环境变量
vim /etc/profile.d/jdk.sh
# 设置JAVA_HOME环境变量,指向Java安装目录的默认路径
export JAVA_HOME=/usr/java/default
# 将JAVA_HOME目录下的bin目录添加到PATH环境变量中,以便系统可以找到Java命令
export PATH=$JAVA_HOME/bin:$PATH
# 创建或覆盖tomcat.sh文件,用于配置Tomcat的环境变量
echo 'PATH=/usr/local/src/tomcat/bin:$PATH' > /etc/profile.d/tomcat.sh
# 使用点(.)命令来执行/etc/profile.d/jdk.sh脚本,使其中的环境变量设置立即生效
. /etc/profile.d/jdk.sh
# 同样使用点(.)命令来执行/etc/profile.d/tomcat.sh脚本,使其中的环境变量设置立即生效
. /etc/profile.d/tomcat.sh
# 使用useradd命令创建一个名为tomcat的系统用户,该用户没有登录shell,用于运行服务
useradd -r -s /sbin/nologin tomcat
# 创建一个目录路径/data/webapps/,用于存放Tomcat的web应用程序
mkdir -p /data/webapps/
# 使用chown命令更改/data/webapps/目录的所有者和组为tomcat用户,确保tomcat用户有权限访问该目录
chown -R tomcat.tomcat /data/webapps/
# 同样使用chown命令更改Tomcat安装目录/usr/local/src/tomcat/的所有者和组为tomcat用户
chown -R tomcat.tomcat /usr/local/src/tomcat/
# 使用vim编辑器打开Tomcat配置文件/usr/local/src/tomcat/conf/tomcat.conf
vim /usr/local/src/tomcat/conf/tomcat.conf
# 在打开的tomcat.conf文件中(或在编辑器中新建一行),设置JAVA_HOME环境变量,指向JDK的安装目录
JAVA_HOME=/usr/local/src/jdk
#3、利用systemd,管理tomcat服务
# 使用vim编辑器编辑systemd的tomcat服务单元文件
vim /lib/systemd/system/tomcat.service
# [Unit] 部分定义了服务的元数据及其依赖关系
[Unit]
# 服务的简短描述
Description=Tomcat
# 定义服务启动的先后顺序,这里指定了在syslog和网络服务启动后再启动Tomcat
# 注释掉了对remote-fs.target和nss-lookup.target的依赖,可能是因为它们不是必需的
After=syslog.target network.target
# [Service] 部分详细描述了如何启动、停止和管理服务
[Service]
# 服务类型,forking表示服务会作为子进程启动
Type=forking
# 从指定的配置文件中加载环境变量
EnvironmentFile=/usr/local/src/tomcat/conf/tomcat.conf
# 设置JAVA_HOME环境变量,指向JDK的安装目录
Environment=JAVA_HOME=/usr/local/src/jdk
# 指定启动Tomcat的命令或脚本
ExecStart=/usr/local/src/tomcat/bin/startup.sh
# 指定停止Tomcat的命令或脚本
ExecStop=/usr/local/src/tomcat/bin/shutdown.sh
# 为服务创建独立的临时文件目录,提高安全性
PrivateTmp=true
# 指定运行服务的用户和组
User=tomcat
Group=tomcat
# [Install] 部分定义了如何安装(即启用)这个服务
[Install]
# 指定服务应该在哪个目标(runlevel)下被启动,multi-user.target是常用的多用户模式
WantedBy=multi-user.target
# 重新加载systemd配置,使新的或修改过的服务单元文件生效
systemctl daemon-reload
# 启用tomcat服务,并立即启动它
systemctl enable --now tomcat
# 启动tomcat服务
# systemctl start tomcat
#4、配置多虚拟机和网站资源
<!-- 使用vim编辑器打开Tomcat配置文件server.xml -->
vim /usr/local/src/tomcat/conf/server.xml
<!-- Tomcat服务器的根元素 -->
<Server port="8005" shutdown="SHUTDOWN">
<!-- 服务元素,可以包含多个服务 -->
<Service name="Catalina">
<!-- 连接器配置(通常位于<Service>内,但在此示例中未展示) -->
<!-- 引擎元素,处理请求的组件 -->
<Engine name="Catalina" defaultHost="localhost">
<!-- 默认主机配置,可以包含多个主机 -->
<!-- 注意:以下<Host>元素是示例,通常会有一个默认的<Host>配置 -->
<!-- 第一个主机配置 -->
<Host name="www.apache.com" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<!-- 访问日志阀,记录访问日志 -->
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="www.apache.com_access_log" suffix=".log"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
<!-- 第二个主机配置,注意appBase和日志前缀的不同 -->
<Host name="www.dengedu.com" appBase="/data/webapps"
unpackWARs="true" autoDeploy="true">
<!-- 访问日志阀,记录访问日志 -->
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="www.dengedu.com_access_log" suffix=".log"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
</Engine>
</Service>
</Server>
systemctl restart tomcat #重新启动tomcat
#安装和配置mysql数据库,用于jpress(www.dengedu.com)登录
# 使用apt包管理器(通常在Debian或Ubuntu系统上)安装mysql-server,并自动确认所有提示
apt -y install mysql-server
# 启动MySQL客户端命令行工具,用于执行SQL命令
mysql
# 创建一个名为jpress的数据库
create database jpress;
# 创建用户jpress@'localhost'
create user jpress@'localhost' identified with mysql_native_password by '123456';
# 授予jpress@'localhost'用户对jpress数据库的所有权限
grant all on jpress.* to jpress@'localhost';
# 退出MySQL客户端命令行工具
exit
#配置jpress(www.dengedu.com)
cp jpress-v5.1.0 /data/webapps/ #拷贝网站数据到指定文件夹
mv jpress-v5.1.0 ROOT #自动解包后,文件夹修改名为ROOT
#将8080端口重定向为80端口
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080
#4、测试结果
在windows系统中修改 C:\Windows\System32\drivers\etc\hosts文件,添加一行
10.0.0.100 www.dengedu.com www.apache.com
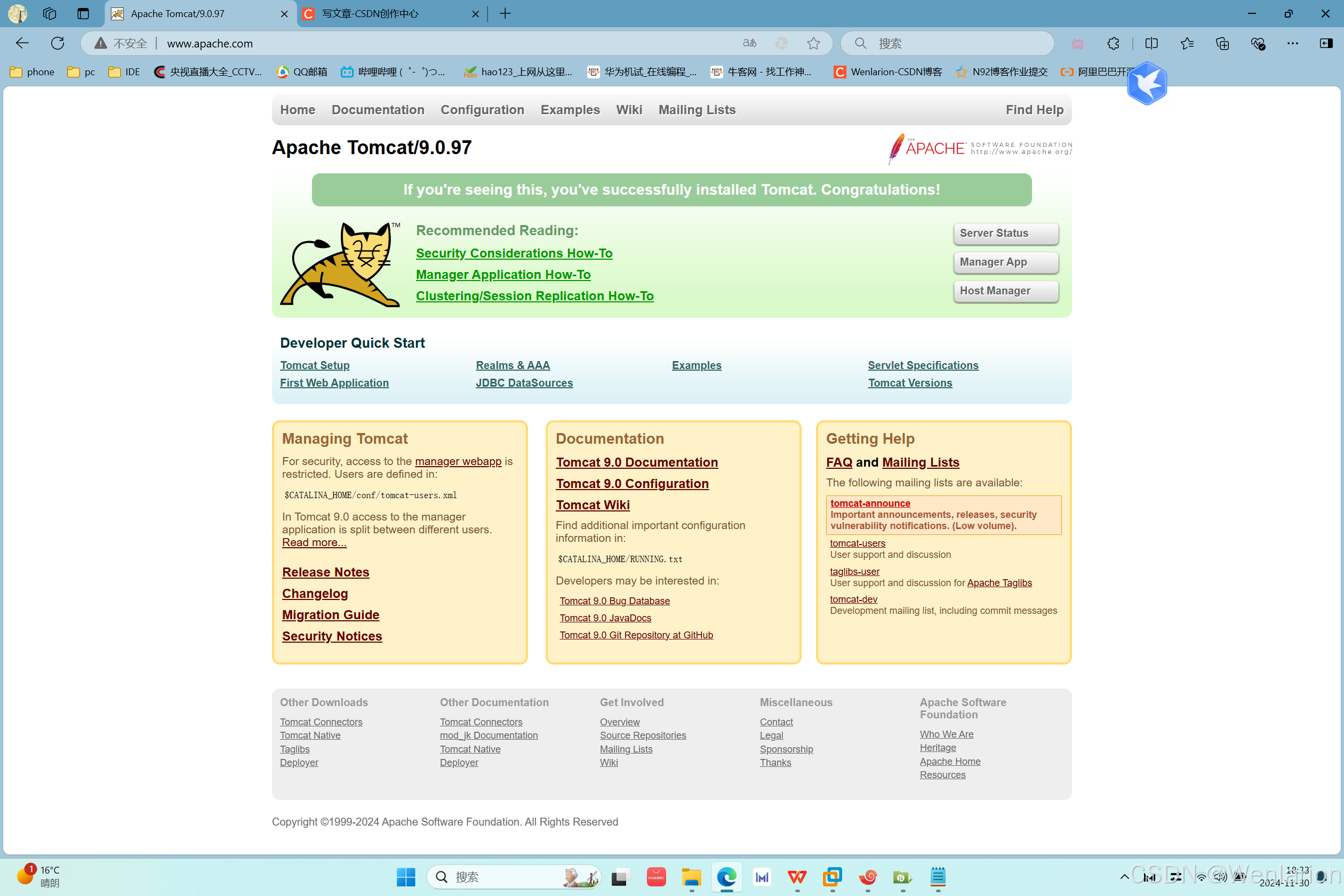
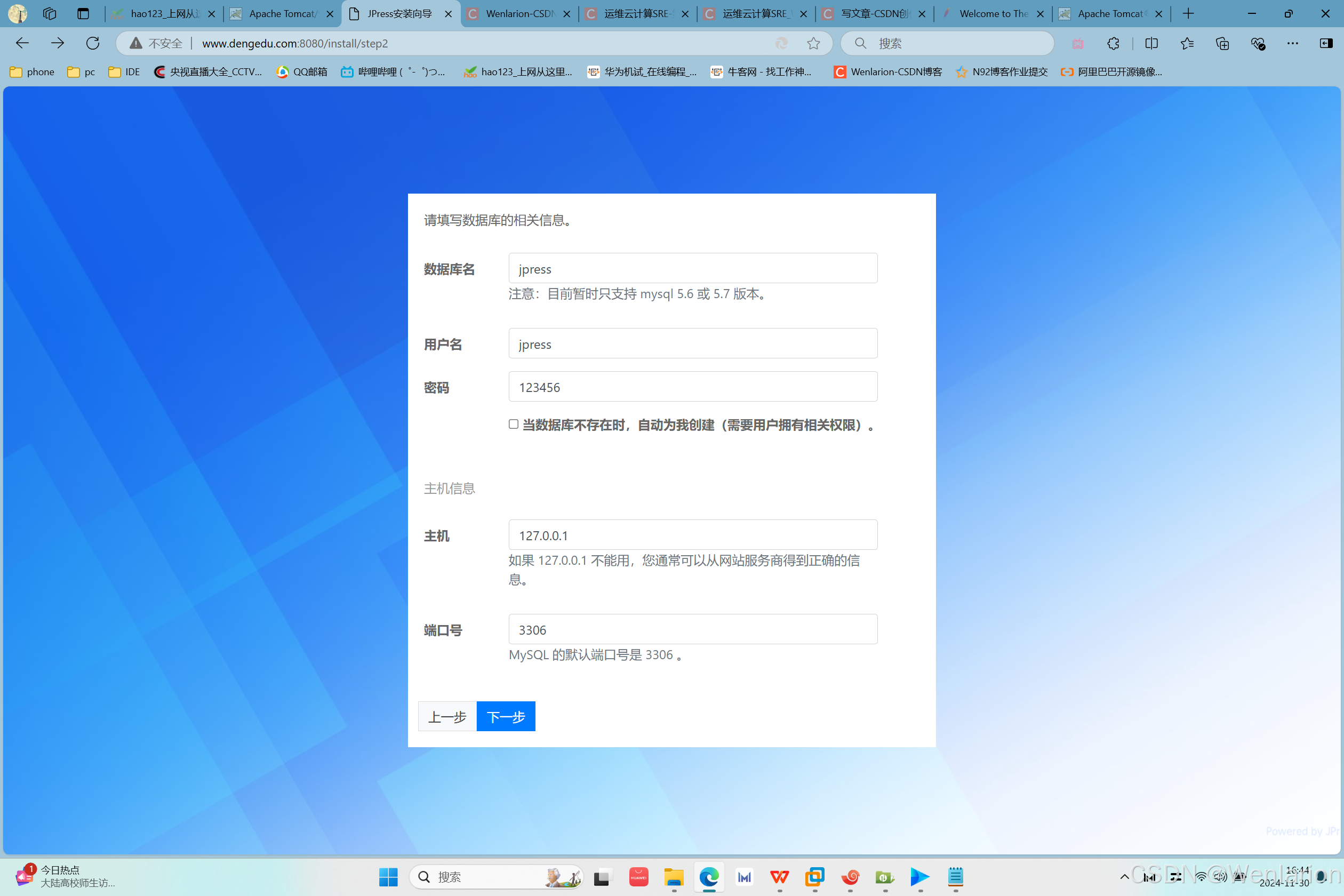
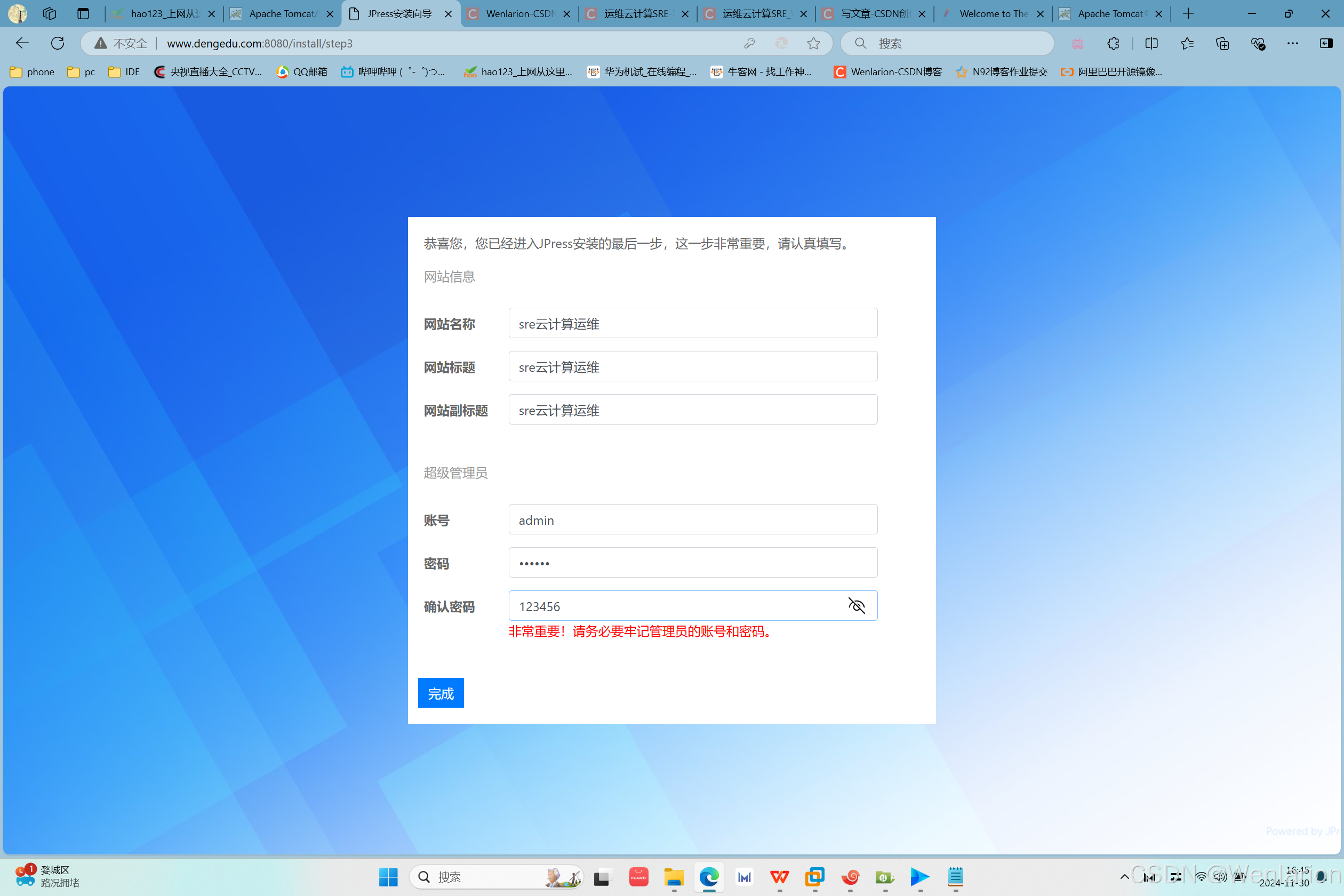
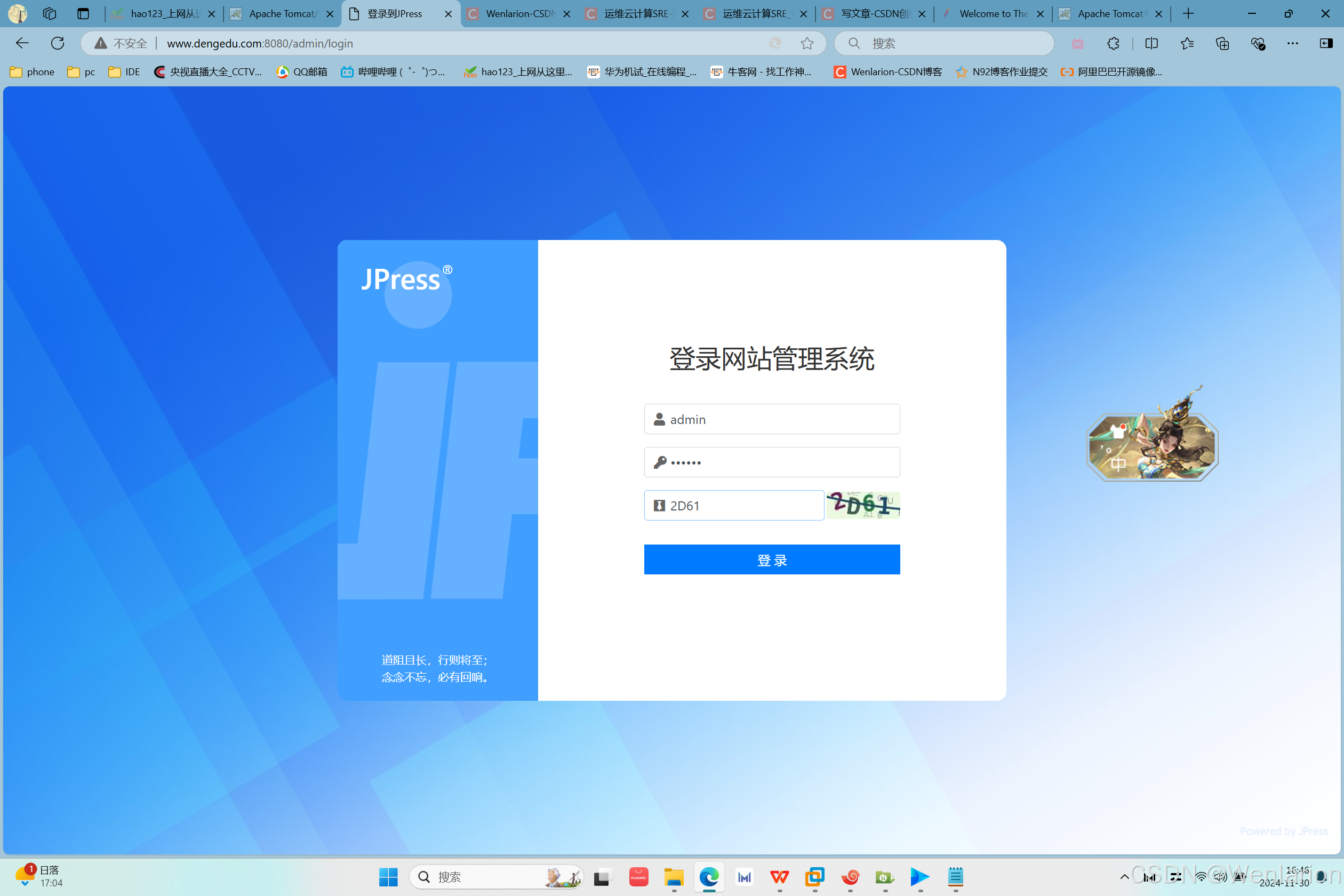
在windows系统上访问www.apache.com和www.dengedu.com测试结果:
访问www.apache.com
访问www.dengedu.com
2. 总结 tomcat定制访问日志格式和反向代理tomcat
Tomcat定制访问日志格式
Tomcat的访问日志记录了客户端对服务器的访问请求及服务器的响应情况,对于分析服务器性能和排查问题具有重要意义。Tomcat允许用户定制访问日志的格式,以满足不同的需求。
Tomcat访问日志的格式由一系列特定的占位符组成,每个占位符对应一种日志信息。例如:
%a:远程IP地址
%A:本地IP地址
%b:除了HTTP头外的字节数,如果为0则用“-”表示
%B:除了HTTP头外的字节数
%h:远程主机名(如果解释主机失败则显示IP地址)
%H:请求的协议
%l:Remote logical username from identd(总是返回“-”)
%m:请求方式(GET、POST等)
%p:接受本次请求的本地端口
%q:查询字符串(如果存在,前面会添加“?”)
%r:请求的第一行(方式和请求URI)
%s:响应的HTTP状态码
%S:用户SessionID
%t:日期和时间,使用公用日志格式
%u:经过身份验证的远程用户(如果有),否则为“-”
%U:被请求的URL路径
%v:本地服务器名
用户可以在Tomcat的配置文件server.xml中,通过修改<Valve>元素的pattern属性来定制访问日志的格式。例如:
<Valve className="org.apache.catalina.valves.AccessLogValve"
directory="logs"
prefix="localhost_access_log"
suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />反向代理与Tomcat部署模式
Standalone模式(Tomcat单独运行)
在Standalone模式下,Tomcat直接接受用户的请求,这种配置方式虽然简单,但并不推荐用于生产环境。原因如下:
安全性:Tomcat直接暴露在互联网上,容易受到各种攻击,如DDoS攻击、SQL注入等。
性能:Tomcat在处理静态资源(如图片、CSS、JavaScript等)时效率不高,这些资源本应由专门的静态文件服务器来处理。
可维护性:当Tomcat需要升级或维护时,可能会影响到用户的访问。
反向代理模式
反向代理模式通过在前置一台Nginx(或其他反向代理服务器,如Apache Httpd)来优化Tomcat的部署。这种配置方式具有以下优点:
安全性:Nginx作为反向代理,可以隐藏Tomcat的真实IP地址和端口,减少被直接攻击的风险。同时,Nginx还可以配置SSL/TLS证书,实现HTTPS加密通信。
性能:Nginx擅长处理静态资源,可以将静态资源的请求直接响应给用户,而无需转发给Tomcat。对于动态资源(如JSP页面),Nginx会将其代理给Tomcat进行处理。这种分工合作的方式可以显著提高系统的整体性能。
可维护性:当Tomcat需要升级或维护时,可以通过Nginx的负载均衡功能将请求转发到其他正常的Tomcat实例上,从而避免影响到用户的访问。
LNMT与LAMT架构
LNMT:Linux + Nginx + MySQL + Tomcat。这是一种常见的Web应用架构,其中Nginx作为反向代理和静态文件服务器,MySQL作为数据库服务器,Tomcat作为应用服务器处理动态页面。
LAMT:Linux + Apache(Httpd) + MySQL + Tomcat。与LNMT类似,但使用Apache Httpd作为反向代理和静态文件服务器。Apache Httpd也是一款功能强大的Web服务器,但在处理高并发和静态资源方面可能稍逊于Nginx。
多级代理与LNNMT架构
多级代理:在某些复杂场景下,可能需要配置多级代理来优化网络流量和提高系统的可扩展性。例如,可以在前端配置一个全局负载均衡器(如HAProxy、F5等),将请求分发到多个Nginx实例上;然后每个Nginx实例再将请求代理到后端的Tomcat实例上。
LNNMT:Linux + Nginx + Nginx(多级代理)+ MySQL + Tomcat。这是一种包含多级代理的Web应用架构,其中第一个Nginx实例作为全局负载均衡器和静态文件服务器,第二个Nginx实例作为反向代理将请求转发给Tomcat实例。这种架构可以提供更高的可用性和可扩展性。
综上所述,反向代理模式通过引入Nginx等反向代理服务器来优化Tomcat的部署,提高了系统的安全性、性能和可维护性。在实际应用中,可以根据具体需求选择合适的架构和配置方式。
3. 总结iptable 5表5链, 基本使用,扩展模块。
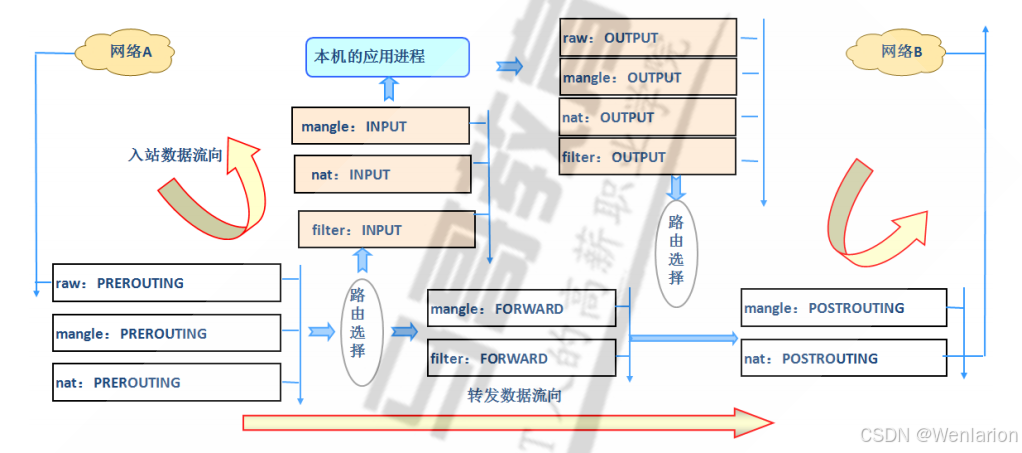
iptables 的 5 表 5 链
5 个表
filter 表:主要用于过滤数据包,是最常用的表。它可以根据规则决定是否允许数据包通过(ACCEPT)、丢弃数据包(DROP)或者拒绝数据包(REJECT)。例如,在一个服务器上,可以用 filter 表来设置规则,只允许来自特定 IP 地址范围的 SSH 连接请求通过,而拒绝其他 IP 地址的请求。
nat 表:主要用于网络地址转换(NAT)。它有三种操作类型:源地址转换(SNAT)、目的地址转换(DNAT)和端口重定向(REDIRECT)。比如,在一个使用私有 IP 地址的局域网中,通过路由器的 NAT 功能,将内部私有 IP 地址的数据包在转发到互联网时,把源 IP 地址转换为路由器的公网 IP 地址,这就是 SNAT 的应用。
mangle 表:主要用于修改数据包的内容,如修改数据包的 TTL(生存时间)、TOS(服务类型)等。例如,可以通过 mangle 表降低某些非关键业务数据包的优先级,从而优化网络带宽的使用。
raw 表:主要用于处理在连接跟踪机制之前的数据包,它可以绕过一些内核模块的处理,比如在一些对性能要求较高的场景下,使用 raw 表来关闭某些连接的跟踪,以提高数据包处理速度。
security 表:主要用于实现强制访问控制(MAC)策略,如 SELinux 等,不过在实际应用中相对较少使用。
5 个链
INPUT 链:用于处理进入本机的数据包。例如,当外部客户端尝试连接本机的服务(如 HTTP 服务)时,数据包会先经过 INPUT 链,根据 INPUT 链中的规则来决定是否允许该数据包进入本机进一步处理。
OUTPUT 链:用于处理本机向外发送的数据包。比如,当本机上的一个程序向外部服务器发送数据请求(如发送邮件)时,数据包会经过 OUTPUT 链,这里的规则可以控制本机的对外访问。
FORWARD 链:用于处理经过本机转发的数据包。在一个充当路由器的 Linux 系统中,当数据包从一个网络接口进入,需要转发到另一个网络接口时,会经过 FORWARD 链,通过设置 FORWARD 链的规则可以实现数据包的转发控制。
PREROUTING 链:位于 nat 表中,用于在数据包进入路由决策之前进行处理。在进行目的地址转换(DNAT)时,会在这个链中进行操作,例如,将外部访问内部服务器的某个公网 IP 和端口的数据包,在这个链中转换为内部服务器的私有 IP 和端口。
POSTROUTING 链:位于 nat 表中,用于在数据包离开本机的最后一刻进行处理。在进行源地址转换(SNAT)时,通常会在这个链中操作,比如将内部私有 IP 地址的数据包在离开路由器时,将源 IP 地址转换为路由器的公网 IP 地址。
iptables 基本使用
查看规则
可以使用iptables -L命令来查看当前的 iptables 规则。例如,iptables -L -n(-n选项表示以数字形式显示 IP 地址和端口号,而不是进行反向解析)可以查看 filter 表的规则。如果要查看特定表的规则,如 nat 表,可以使用iptables -t nat -L。
添加规则
基本语法是iptables -A [链名] [规则选项]。例如,要在 INPUT 链中添加一条规则,允许来自特定 IP 地址(如 192.168.1.100)的 SSH(端口 22)连接,可以使用iptables -A INPUT -p tcp -s 192.168.1.100 --dport 22 -j ACCEPT。其中-p tcp表示协议为 TCP,-s表示源 IP 地址,--dport表示目的端口,-j表示执行的动作(这里是 ACCEPT 允许通过)。
删除规则
可以使用iptables -D [链名] [规则编号]来删除规则。首先要通过iptables -L -n -v命令查看规则编号,然后根据编号删除规则。例如,如果要删除刚才添加的允许 192.168.1.100 的 SSH 连接的规则(假设编号为 1),可以使用iptables -D INPUT 1。
修改规则
可以先删除旧规则,再添加新规则来修改规则。或者使用iptables -R [链名] [规则编号] [新规则选项]来替换指定编号的规则。
保存规则
直接使用iptables命令添加的规则在系统重启后会丢失。在 Ubuntu 等基于 Debian 的系统中,可以使用iptables -save > /etc/iptables/rules.v4来保存规则;在 CentOS 等基于 Red Hat 的系统中,可以使用service iptables save(旧版本)或firewalld -cmd --runtime -to -permanent(如果使用 firewalld 作为前端管理工具)来保存规则。
iptables -t filter -A INPUT -s 10.0.0.7 -j REJECT #添加规则1
iptables -t filter -R INPUT 1 -p tcp -s 10.0.0.7 -j REJECT#替换规则1
iptables -t filter -I INPUT 2 -d 192.168.10.8 -j DROP#插入规则2
iptables -t filter -I INPUT 3 ! -s 192.168.10.0/24 -j ACCEPT #插入规则3
iptables -vnL --line-number #查看规则
iptables -t filter -D INPUT 2 #删除规则2
iptables -t filter -F INPUT #清空所有规则
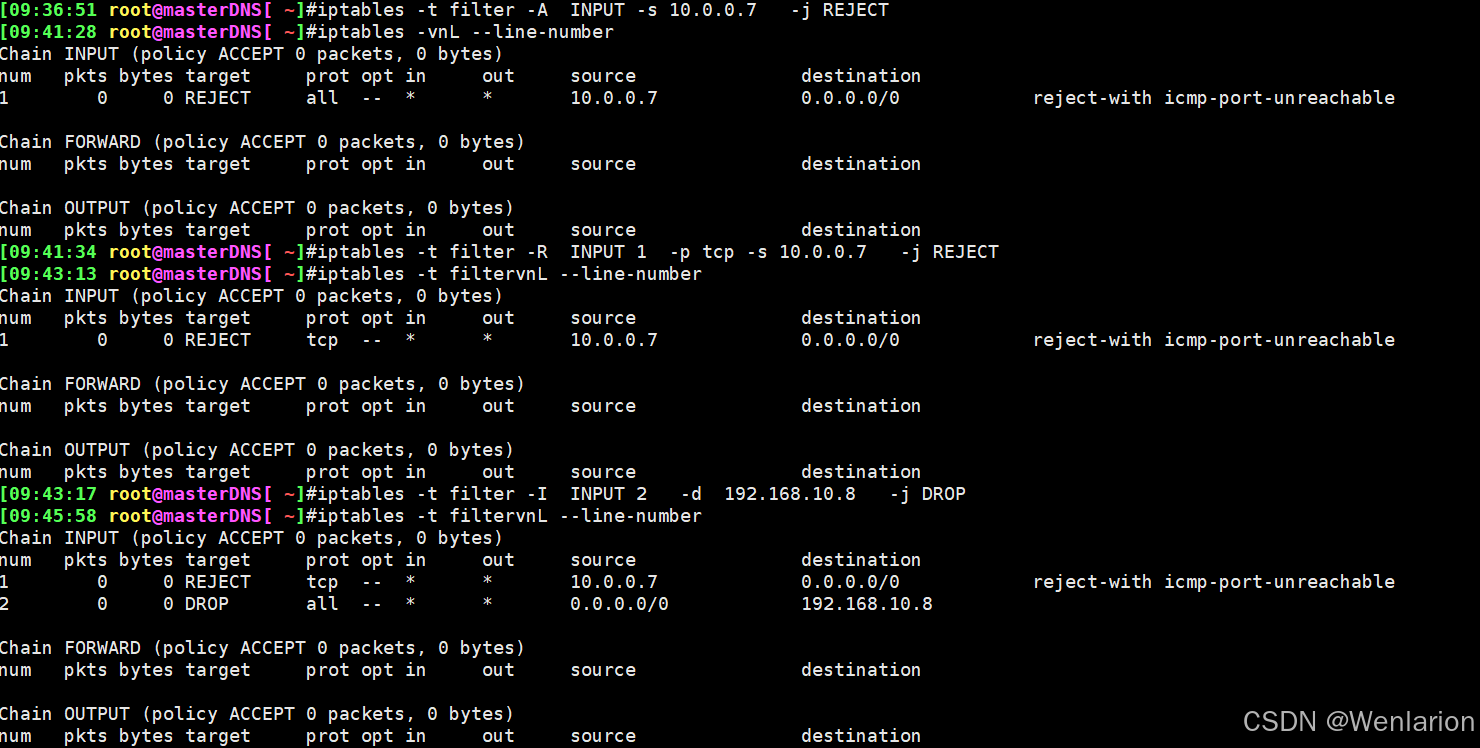
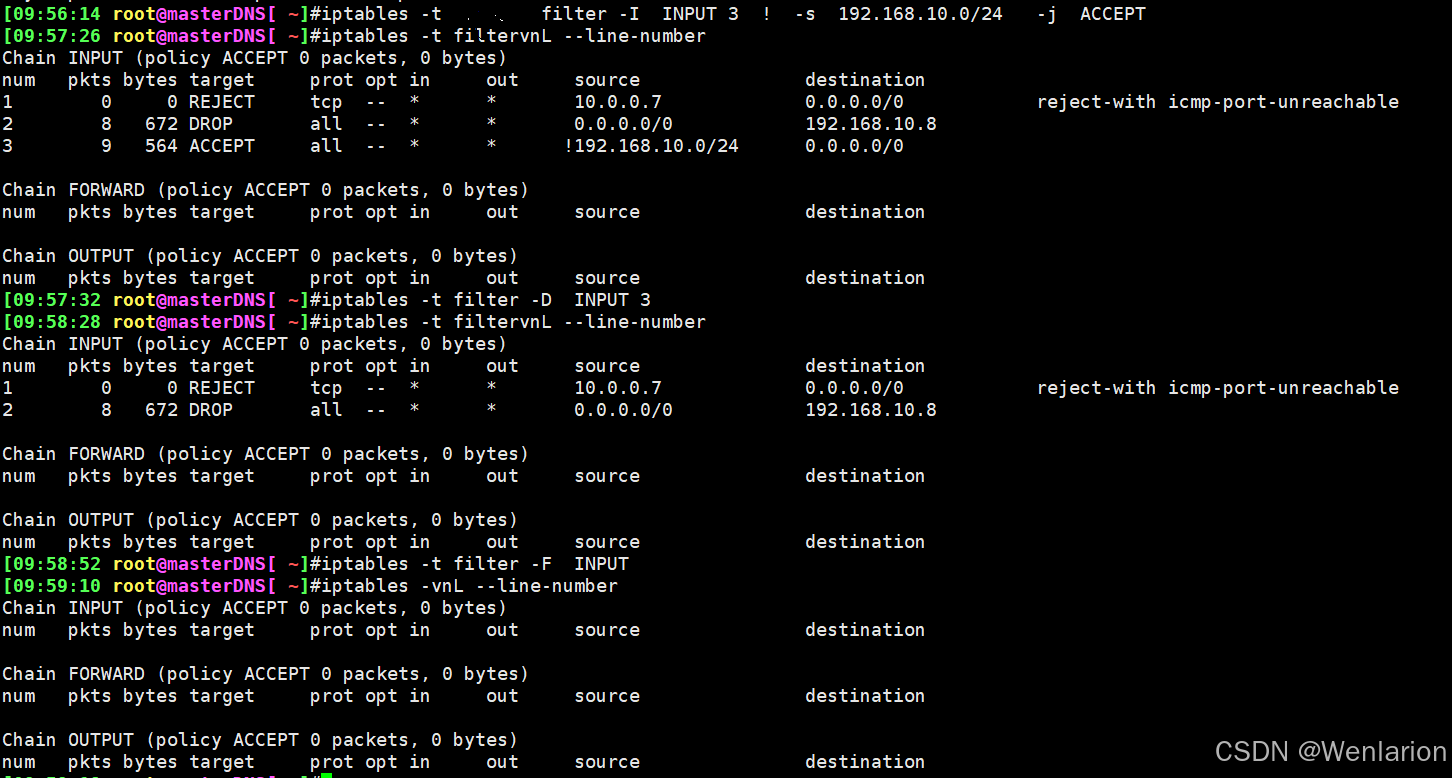
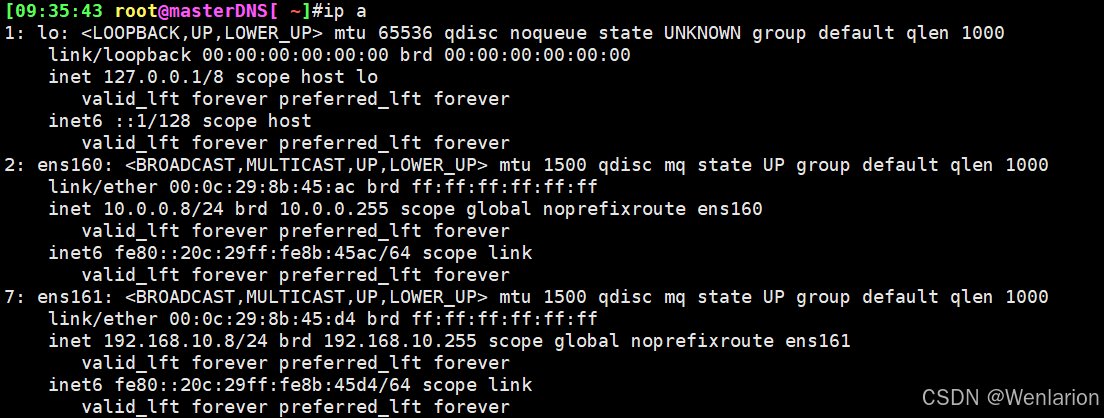
查看DNS服务器的IP配置
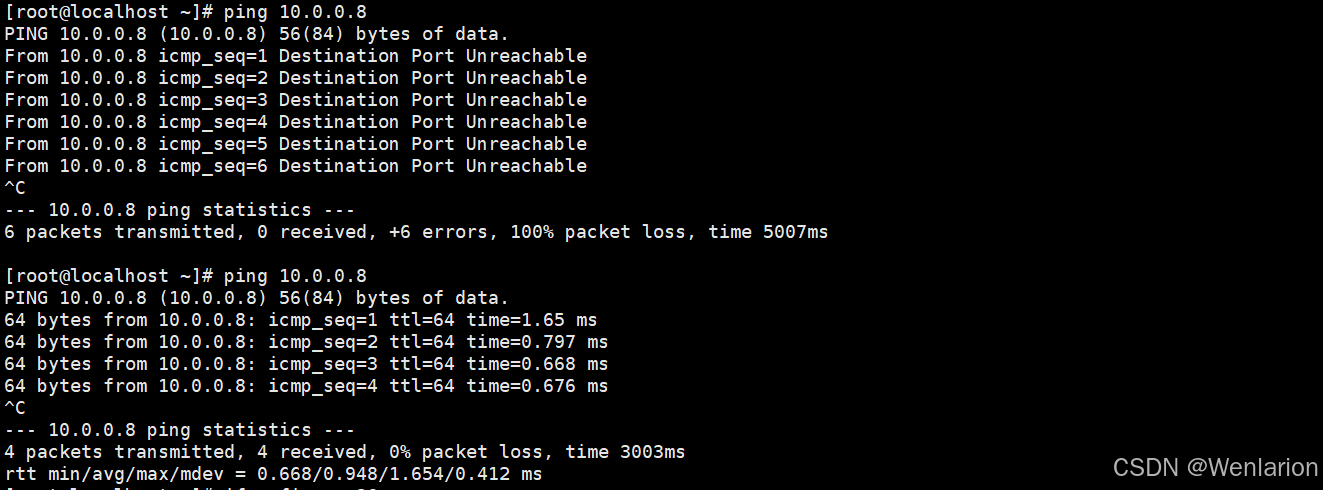
添加规则1并修改规则1,客户端由不能ping通DNS服务器变为可以ping通DNS服务器
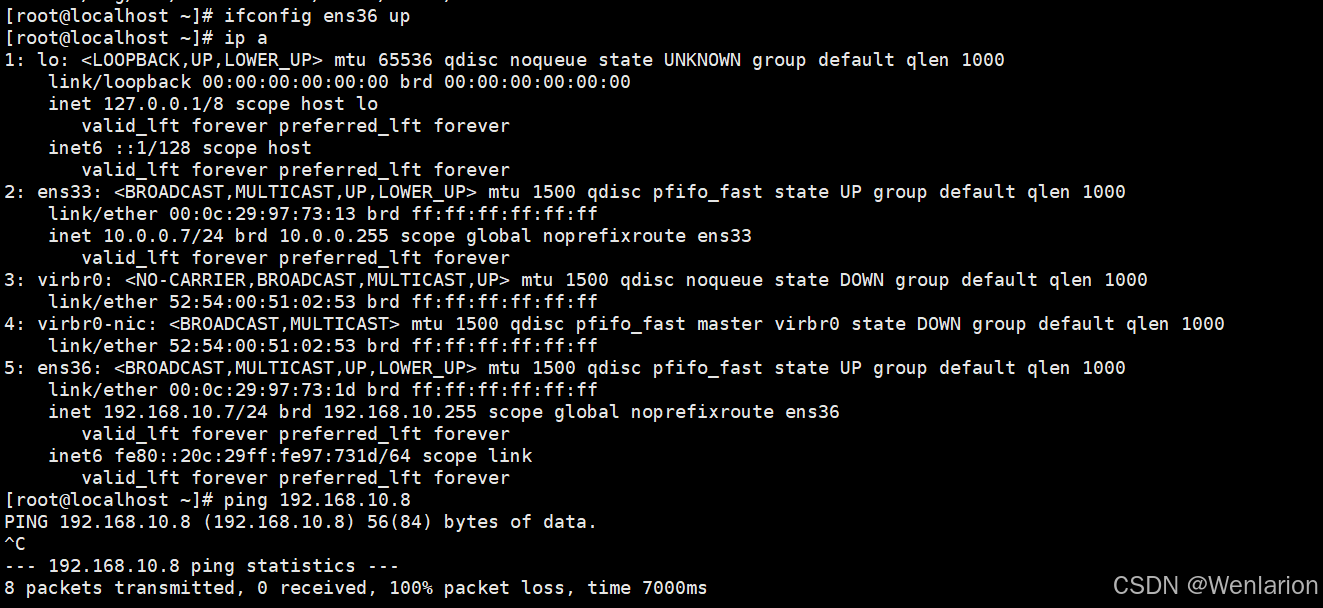
添加规则2,客户端添加网卡ens36,无法ping通DNS服务器
iptables 扩展模块
multiport 模块
功能概述
multiport模块用于指定多个端口。这在需要同时对多个端口应用相同规则时非常有用,比如在配置防火墙规则允许或拒绝来自特定源 IP 对多个服务端口(如 HTTP、HTTPS、SSH 等)的访问。
使用示例
例如,允许来自特定 IP 地址192.168.1.100访问本地服务器的22(SSH)、80(HTTP)和443(HTTPS)端口。可以使用以下iptables命令:
iptables -A INPUT -s 192.168.1.100 -p tcp -m multiport --dports 22,80,443 -j ACCEPT
这里-m multiport表示使用multiport模块,--dports参数后面跟着要允许访问的目标端口列表,用逗号分隔。
参数说明
--sports:用于指定源端口范围,可用于限制来自某些源端口的流量。例如,如果只想允许来自源端口为1024 - 65535的流量访问目标端口,可以使用--sports 1024:65535。
--dports:如上述示例中用于指定目标端口范围,在规则匹配中用于确定流量的目标端口是否在指定范围内。
iprange 模块
功能概述
iprange模块用于指定 IP 地址范围。这在需要根据连续的 IP 地址段来制定规则时很有帮助,比如限制某个子网内的一段 IP 地址访问特定资源。
使用示例
假设要拒绝来自192.168.1.10 - 192.168.1.20这个 IP 地址范围的主机访问本地的3306(MySQL)端口。可以使用以下命令:
iptables -A INPUT -p tcp --dport 3306 -m iprange --src -range 192.168.1.10 - 192.168.1.20 -j REJECT
其中-m iprange表示使用iprange模块,--src -range参数指定了源 IP 地址范围。
参数说明
--src -range:用于指定源 IP 地址范围,格式可以是起始IP地址 - 结束IP地址。
--dst -range:用于指定目标 IP 地址范围,在某些场景下(如限制本地服务器对特定 IP 段的访问)可以使用这个参数。
mac 模块
功能概述
mac模块用于根据 MAC 地址来过滤数据包。MAC 地址是网络设备的物理地址,通过基于 MAC 的规则可以对特定网络设备进行访问控制,即使它们的 IP 地址可能会改变。
使用示例
例如,要允许 MAC 地址为00:11:22:33:44:55的设备访问本地网络,可以使用以下命令:
iptables -A INPUT -m mac --mac -source 00:11:22:33:44:55 -j ACCEPT这里-m mac表示使用mac模块,--mac -source参数指定了源 MAC 地址。
参数说明
--mac -source:用于指定源 MAC 地址,用于匹配数据包的发送方 MAC 地址。
--mac -destination:用于指定目标 MAC 地址,不过在实际应用中,基于目标 MAC 地址过滤相对较少用,因为数据包在到达目标主机之前,目标 MAC 地址通常是由网络设备(如路由器)动态解析的。
string 模块
功能概述
string模块用于在数据包的应用层数据中查找特定的字符串。这在内容过滤方面很有用,比如可以阻止包含特定关键词的网页访问请求或者过滤包含恶意内容的数据包。
使用示例
假设要阻止包含malware这个关键词的 HTTP 请求。可以使用以下命令(假设已经设置好连接跟踪和 HTTP 协议相关模块):
iptables -A INPUT -p tcp --dport 80 -m string --algo kmp --string "malware" -j REJECT其中-m string表示使用string模块,--algo kmp指定了匹配算法,--string参数指定要查找的字符串。
参数说明
--algo:用于指定匹配算法,除了 Boyer - Moore 算法外,还可以使用其他算法(如kmp - Knuth - Morris - Pratt 算法),不过 Boyer - Moore 算法在大多数情况下效率较高。
--string:指定要在数据包内容中查找的字符串内容。
--from和--to:可以用于指定从数据包的哪个字节位置开始查找和结束查找,用于更精细的内容控制。
time 模块
功能概述
time模块用于根据时间来控制iptables规则。可以设置规则在特定的日期、时间或者时间段内生效,这对于在非工作时间加强安全限制或者在特定时间允许特定访问等场景很有用。
使用示例
例如,只允许在工作日(周一到周五)的上午 9 点到下午 5 点访问本地的FTP服务(端口21)。可以使用以下命令:
iptables -A INPUT -p tcp --dport 21 -m time --weekdays Mon,Tue,Wed,Thu,Fri --timestart 09:00:00 --time - stop 17:00:00 -j ACCEPT
这里-m time表示使用time模块,--weekdays参数指定了允许访问的工作日,--timestart和--time - stop分别指定了允许访问的开始时间和结束时间。
参数说明
--weekdays:用于指定允许或禁止访问的工作日,可以是Sun、Mon等缩写形式,多个工作日用逗号分隔。
--monthdays:用于指定允许或禁止访问的月份中的日期,范围是 1 - 31。
--timestart和--time - stop:分别指定规则生效的开始时间和结束时间,时间格式为HH:MM:SS。
conlimit 模块
功能概述
conlimit模块用于限制并发连接数。可以防止某个源 IP 地址或者某个用户建立过多的连接,从而避免服务器被大量连接耗尽资源,主要用于服务器的连接数限制和防止 DDoS 攻击等场景。
使用示例
例如,限制每个源 IP 地址最多同时建立 10 个到本地服务器的HTTP(端口80)连接。可以使用以下命令:
iptables -A INPUT -p tcp --dport 80 -m conlimit --connlimit - above 10 -j REJECT这里-m conlimit表示使用conlimit模块,--connlimit - above参数指定了超过多少个并发连接就拒绝访问。
参数说明
--connlimit - above:用于指定超过多少个并发连接就触发规则,如上述示例中,当源 IP 地址建立的并发连接数超过 10 个时,就会拒绝该 IP 地址的连接请求。
--connlimit - mask:用于指定 IP 地址的子网掩码,在基于子网进行连接数限制时使用。例如,使用--connlimit - mask 24可以基于/24子网进行连接数限制。
limit 模块
功能概述
limit模块用于限制数据包的传输速率。可以防止某个源 IP 地址或者某种类型的流量占用过多的带宽,实现流量整形和防止网络拥塞等功能。
使用示例
例如,限制来自某个 IP 地址的ICMP(ping)请求每秒最多通过 5 个包。可以使用以下命令:
iptables -A INPUT -p icmp -m limit --limit 5/sec -j ACCEPT这里-m limit表示使用limit模块,--limit参数指定了数据包的限制速率,格式为数量/时间单位,这里5/sec表示每秒 5 个包。
参数说明
--limit:用于指定数据包的限制速率,时间单位可以是sec(秒)、minute(分钟)、hour(小时)等,例如10/minute表示每分钟允许通过 10 个数据包。
--limit - burst:用于指定在规则开始生效时允许通过的最大突发数据包数量。例如,--limit - burst 10表示在规则开始生效时,最多允许 10 个数据包立即通过,之后再按照--limit规定的速率限制。
state 模块
功能概述
state模块用于根据连接状态来过滤数据包。iptables可以跟踪连接的状态,如NEW(新连接)、ESTABLISHED(已建立连接)、RELATED(相关连接,如 FTP 数据连接与控制连接相关)等,通过基于状态的过滤可以更灵活地控制网络访问。
使用示例
例如,允许已经建立的TCP连接的数据包通过,但拒绝新的连接请求。可以使用以下命令:
iptables -A INPUT -p tcp -m state --state ESTABLISHED -j ACCEPT
iptables -A INPUT -p tcp -m state --state NEW -j REJECT这里-m state表示使用state模块,--state参数指定了要匹配的连接状态。
参数说明
--state:用于指定要匹配的连接状态,常见的状态有NEW(新连接)、ESTABLISHED(已建立连接)、RELATED(相关连接)、INVALID(无效连接,如数据包没有对应的连接状态)。通过指定这些状态,可以对不同阶段的连接进行不同的处理。
#在rocky系统添加的规则
#使用multiport模块添加规则1,限制访问端口
iptables -I INPUT -p tcp -m multiport --dports 22,80 -j ACCEPT
#使用iprange模块添加规则2,限制访问网络范围
iptables -I INPUT 2 -p tcp -m iprange --src-range 10.0.0.6-10.0.0.10 -j ACCEPT
#使用mac模块添加规则3,限制客户端IP和mac地址
iptables -I INPUT -s 10.0.0.100 -m mac --mac-source 00:0c:29:60:51:0e -j ACCEPT
#使用string模块添加规则4,限制带有特定字符串的数据包
iptables -A OUTPUT -p tcp --sport 80 -m string --algo kmp --from 62 --string "google" -j REJECT
#使用string模块添加规则5,限制访问数
iptables -A INPUT -p tcp --dport 80 -m connlimit --connlimit-above 2 -j REJECT
#添加规则6和规则7,使用limit模块实现流量限制
iptables -I INPUT -p icmp --icmp-type 8 limit --limit 20/minute --limit-burst 10 -j ACCEPT
iptables -I INPUT 2 -p icmp -j REJECT
#使用state模块添加规则8和规则9,根据客户端状态限制访问
iptables -A INPUT -m state --state ESTABLISHED -j ACCEPT
iptables -A INPUT -m state --state NEW -j REJECT
#在ubuntu系统添加的规则
#使用time模块添加规则,限制访问时间
iptables -A INPUT -m time --timestart 01:00 --timestop 07:35 -j REJECTRocky系统在添加规则4之后无法访问网页。

Rocky系统在添加规则6-9之后,已建立连接的客户端在部分时间能访问,而未连接的客户端无法访问。
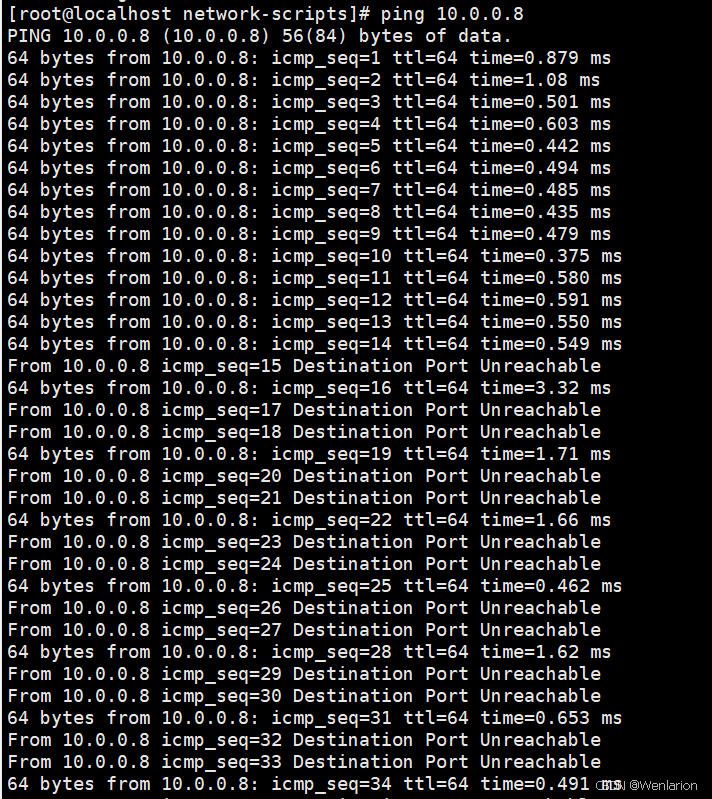
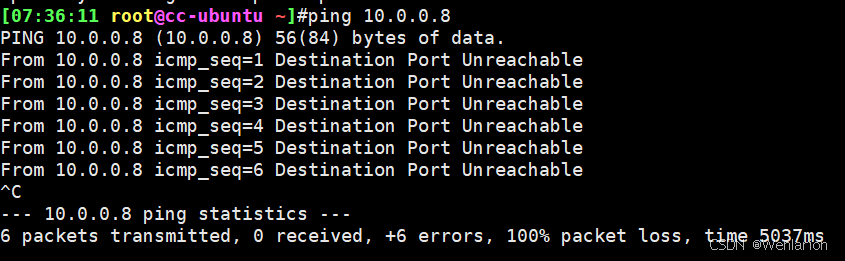
Ubuntu系统在限制访问的时间内无法访问服务器,超过后可以访问网页。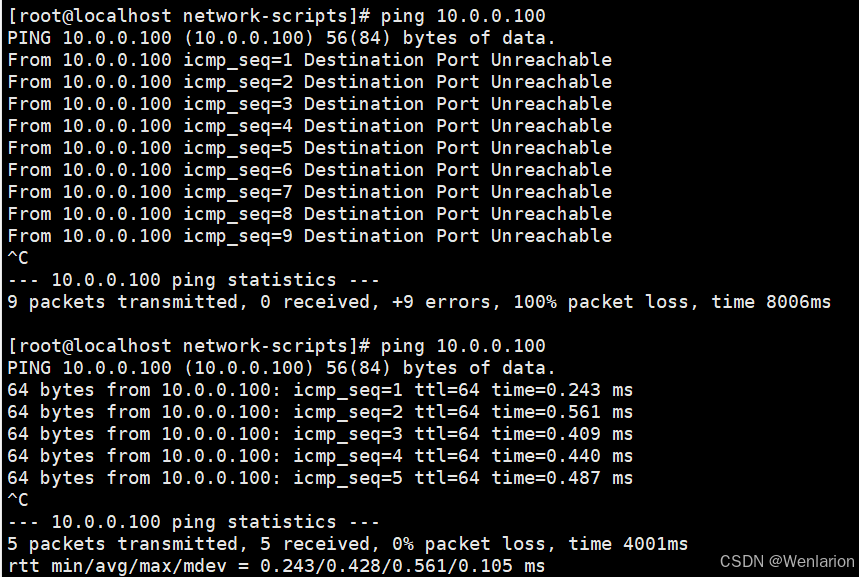
4. 总结iptables规则优化实践,规则保存和恢复。
iptables 规则优化实践、规则保存和恢复的总结如下:
一、iptables 规则优化实践
精确匹配条件:
在编写规则时,应尽可能使用精确的匹配条件,如准确的源 IP 地址范围(iprange 模块)、端口号(multiport 模块)、协议类型等。避免使用过于宽泛的匹配,例如,如果只需要允许特定子网内的几台服务器访问某个服务,就不要使用整个子网掩码为 0 的大范围匹配,这样可以减少不必要的规则匹配开销,提高防火墙性能。
例如,使用 iptables -A INPUT -s 192.168.1.10 - 192.168.1.20 -p tcp --dport 80 -j ACCEPT 精确指定了源 IP 范围和目标端口,而不是使用更宽泛的 iptables -A INPUT -s 192.168.1.0/24 -p tcp -j ACCEPT(如果仅针对少数几台主机)。
合理使用连接状态跟踪(state 模块):
充分利用 state 模块来区分连接状态,如允许已建立(ESTABLISHED)和相关(RELATED)连接通过,而对新连接(NEW)进行更严格的审查。这样可以减少对已正常通信连接的重复检查,提高效率。
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A INPUT -p tcp -m state --state NEW -j LOG
iptables -A INPUT -p tcp -m state --state NEW -j DROP上述规则先允许已建立和相关连接,然后对新连接进行日志记录并丢弃,这样既保证了正常通信,又能监控新的连接尝试。
限制并发连接数(conlimit 模块)和流量速率(limit 模块):
使用 conlimit 模块限制单个源 IP 或子网的并发连接数,防止某个源过度占用资源或发起 DDoS 攻击。例如,限制每个源 IP 对特定服务的并发连接数为 50:
iptables -A INPUT -p tcp --dport 80 -m conlimit --connlimit - above 50 -j REJECT利用 limit 模块限制数据包的传输速率,避免某个源产生过大流量。如限制某个源的 ICMP 流量为每秒 10 个包:
iptables -A INPUT -p icmp -m limit --limit 10/sec -j ACCEPT基于时间的规则(time 模块):
根据业务需求设置基于时间的规则,在非业务高峰期加强安全限制或在特定时间允许特定访问。例如,只在工作时间(周一至周五 9:00 - 18:00)允许访问内部文件共享服务器:
iptables -A INPUT -p tcp --dport 445 -m time --weekdays Mon,Tue,Wed,Thu,Fri --timestart 09:00:00 --time - stop 18:00:00 -j ACCEPT
规则顺序优化:
将常用的、匹配概率高的规则放在前面,以减少不必要的规则遍历。例如,先允许本地回环接口(lo)的流量,因为本地应用间通信频繁:
iptables -A INPUT -i lo -j ACCEPT然后是已建立和相关连接的允许规则,接着是其他特定服务的允许规则,最后是默认的拒绝规则,如:
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
iptables -A INPUT -p tcp --dport 80 -j ACCEPT
iptables -A INPUT -j DROP二、iptables 规则保存
使用 iptables -save 命令:
iptables -save 命令可以将当前的 iptables 规则以文本格式输出到标准输出。通常可以将其重定向到一个文件中以便保存。例如:
iptables -save > /etc/iptables/rules.v4这会将当前的 IPv4 iptables 规则保存到 /etc/iptables/rules.v4 文件中。对于 IPv6 规则,可以使用 ip6tables -save > /etc/iptables/rules.v6。
结合系统初始化脚本:
在一些 Linux 发行版中,可以将 iptables -save 命令添加到系统初始化脚本(如 /etc/rc.local 或特定的网络初始化脚本)中,以便在系统启动时自动保存当前规则。例如,在 /etc/rc.local 中添加:
/sbin/iptables -save > /etc/iptables/rules.v4
exit 0这样在系统每次正常关闭或重启时都会保存当前的 iptables 规则状态。
三、iptables 规则恢复
使用 iptables -restore 命令:
iptables -restore 命令可以从保存的规则文件中恢复 iptables 规则。例如,如果之前保存的规则文件是 /etc/iptables/rules.v4,可以使用:
iptables-restore < /etc/iptables/rules.v44这会将文件中的规则重新加载到 iptables 中,恢复之前保存的防火墙配置。同样,对于 IPv6 规则,可以使用 ip6tables -restore < /etc/iptables/rules.v6。
在系统启动时自动恢复:
可以在系统启动脚本(如 /etc/rc.local 或特定的网络启动脚本)中添加 iptables -restore 命令,以便在系统启动时自动恢复规则。例如:
/sbin/iptables -restore < /etc/iptables/rules.v4这样系统每次启动都会加载之前保存的 iptables 规则,保证防火墙配置的一致性。
通过合理的规则优化、保存和恢复操作,可以提高 iptables 防火墙的性能、安全性和可管理性,确保网络环境的稳定和安全。
#安装iptables-services,保存规则,开机自动加载
yum -y install iptables-services
iptables-save > /etc/sysconfig/iptables
systemctl enable iptables.service
systemctl mask firewalld.service nftables.service5. 总结NAT转换原理, DNAT/SDNAT原理,并自行设计架构实现DNAT/SNAT。
以下是NAT转换原理以及DNAT和SNAT原理的总结:
NAT转换原理
NAT(Network Address Translation,网络地址转换)是一种在IP数据包通过路由器或防火墙时修改其源或目标IP地址的技术。NAT技术的出现主要是为了解决IPv4地址短缺的问题,并增加网络的安全性。通过NAT,私有网络中的设备可以使用私有IP地址,而在与公共网络通信时,这些私有地址会被转换为公共IP地址。NAT的主要工作原理包括:
数据包从内网发往外网时,NAT会将数据包的源IP由私网地址转换成公网地址。
当响应的数据包要从公网返回到内网时,NAT会将数据包的目的IP由公网地址转换成私网地址。
DNAT原理
DNAT(Destination Network Address Translation,目的地址转换)是一种将数据包目标IP地址替换为另一个IP地址的技术。这种转换发生在数据包从外部网络发送到内部网络时,主要用于内部网络的主机对外提供服务时,将外部网络的请求重定向到内部网络的特定主机。例如,当外部主机尝试连接到内部网络的服务时,其目标IP地址会被替换为内部服务的私有IP地址,这样外部主机的连接请求就会被正确地路由到内部网络的服务上。
DNAT的主要应用场景包括:
发布内网的Web服务,将外部访问请求重定向到内部的Web服务器。
修改目标端口,以便外部主机通过特定端口访问内部网络的服务。
SNAT原理
SNAT(Source Network Address Translation,源网络地址转换)是一种将数据包源IP地址替换为另一个IP地址的技术。这种转换发生在数据包从内部网络发送到外部网络时,主要用于内部网络的主机访问外部网络时,通过共享同一个公网IP地址来访问外网资源。例如,当内部网络的主机想要访问互联网时,它们的源IP地址会被替换为路由器的公网IP地址,这样互联网上的主机就会认为所有来自内部网络的数据包都来自同一个公网IP地址。
SNAT的主要应用场景包括:
家庭和小型企业网络中,多个设备通过共享一个公网IP地址访问互联网。
保护内部网络的隐私和安全,通过SNAT隐藏内部网络的真实IP地址。
NAT转换的实现方式
NAT技术根据实现方式的不同,可以分为静态NAT、动态NAT和NAPT(Network Address and Port Translation,网络地址端口转换)三种类型:
静态NAT:内网IP与公网IP是一对一的永久映射关系。
动态NAT:内网IP从公网IP池中动态选择一个进行映射。
NAPT:把内网IP映射到公网IP的不同端口上,让多个内网IP可以共享同一个公网IP地址。
综上所述,NAT转换原理及其两种主要模式DNAT和SNAT在网络通信中发挥着重要作用,它们不仅解决了IP地址短缺的问题,还提高了网络的安全性和可扩展性。
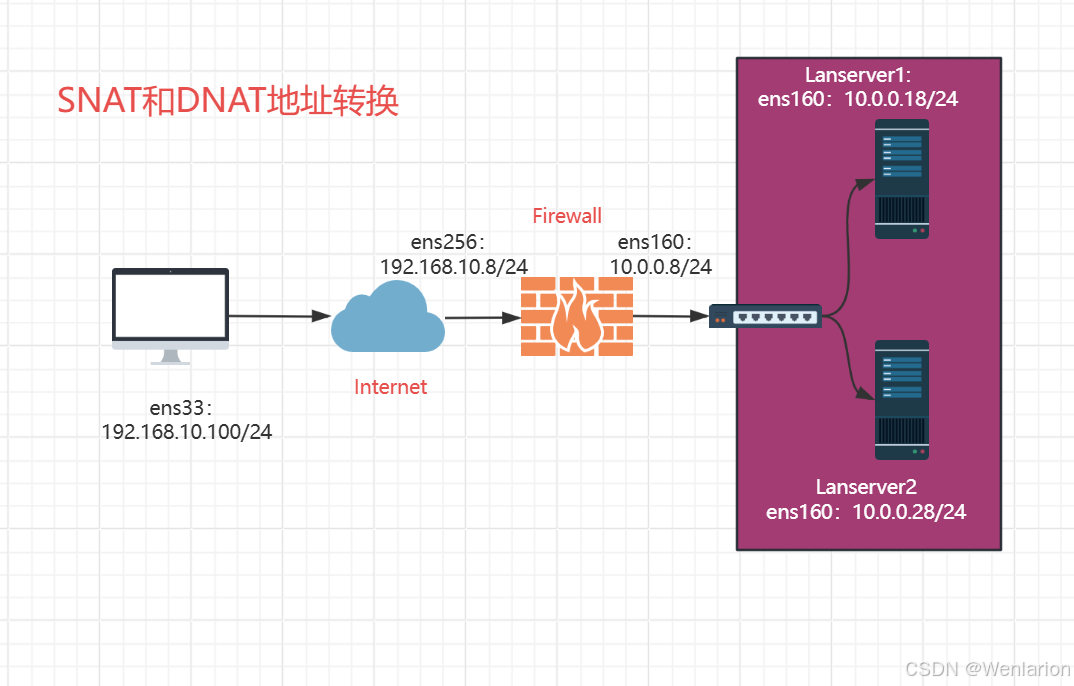
1、将在192.168.10.0/24网段的网卡设置为仅主机,在10.0.0.0/24网段的网卡设置为NAT,并按照上图所示配置网卡静态IP
2、在互联网上的Client 安装nginx服务,内部服务器Lanserver1、Lanserver2,安装apache服务
#安装nginx,并设置开机启动
apt -y install nginx
systemctl enable --now nginx
#安装apache,并设置开机启动
yum -y install httpd
systemctl enable --now httpd
3、在防火墙上进行SNAT和DNAT配置
#开启ip_forward,并生效
vim tc/sysctl.conf #配置文件sysctl.conf,添加选项
net.ipv4.ip_forward = 1
sysctl -p #使配置文件sysctl.conf生效
内部网络访问外部网络,配置SNAT,进行源地址替换
iptables -t nat -I POSTROUTING 1 -s 10.0.0.0/24 ! -d 10.0.0.0/24 -j SNAT --to-source 192.168.197.8
外部网络访问内部网络,配置DNAT,进行目标地址和端口替换
iptables -t nat -I PREROUTING 1 -d 192.168.10.8 -p tcp --dport 80 -j DNAT --to-destination 10.0.0.18:80
iptables -t nat -R PREROUTING 2 -d 192.168.10.8 -p tcp --dport 81 -j DNAT --to-destination 10.0.0.28:80
4、SNAT和DNAT配置进行验证
内部地址访问外部地址
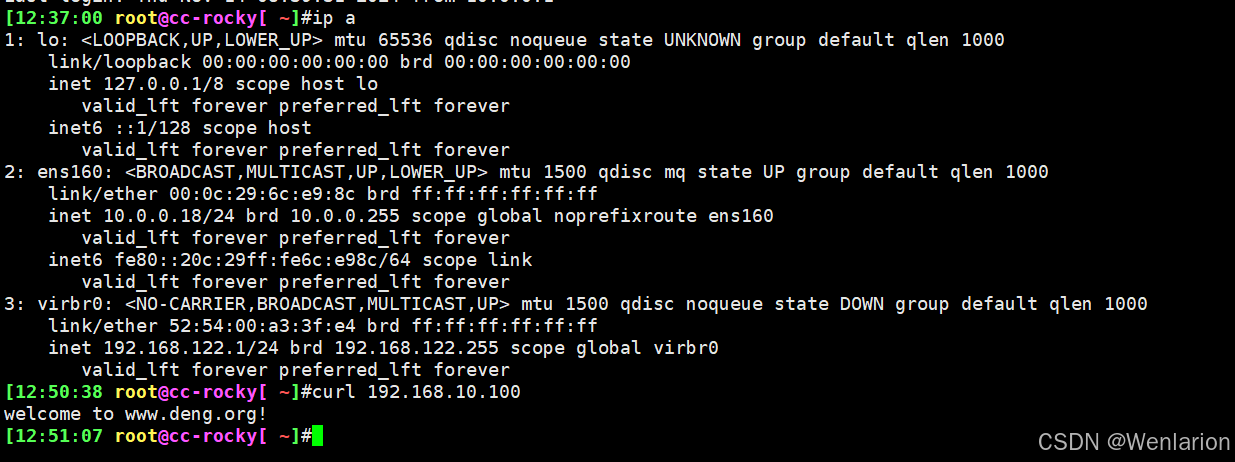
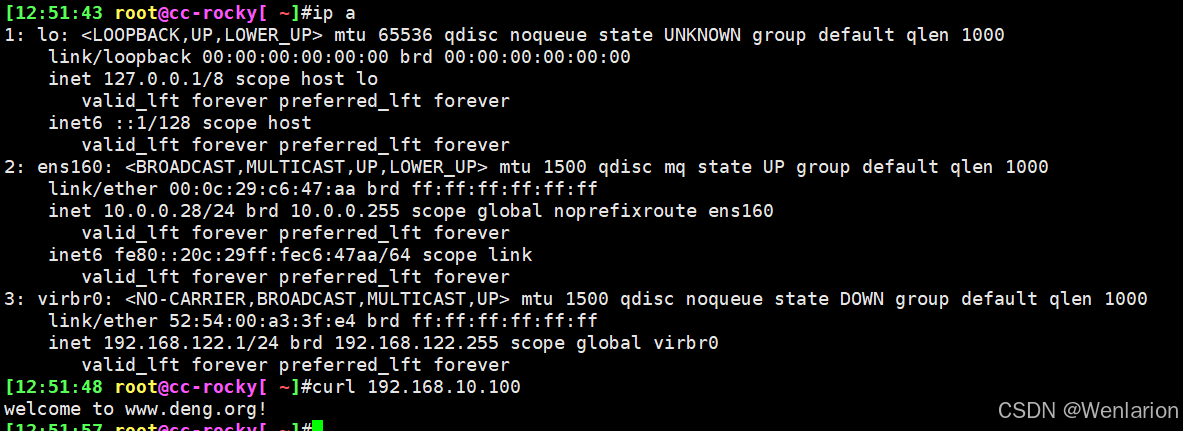
外部地址访问内部地址
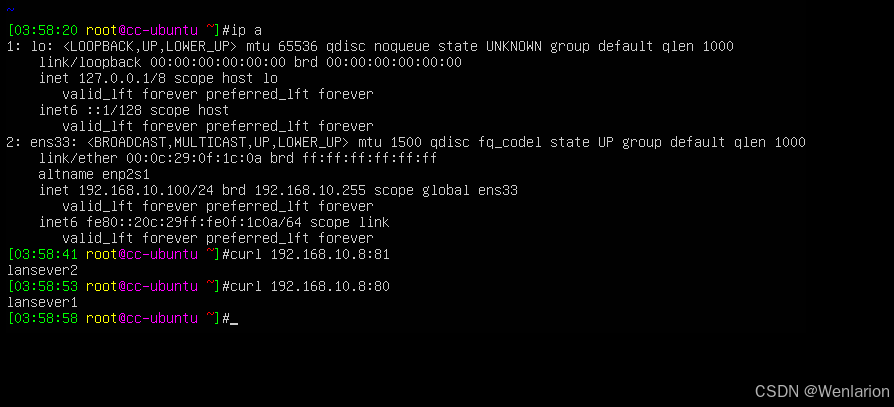
6. 使用REDIRECT将90端口重定向80,并可以访问到80端口的服务
#在上题的网络拓扑中,更改lanserver1的apache监听端口为90
vim /etc/httpd/conf/httpd.conf #配置文件httpd.conf,更改选项
Listen 90
systemctl restart httpd#重启服务,使配置文件生效
#用REDIRECT将90端口重定向80,并可以访问到80端口的服务
iptables -t nat -A PREROUTING -d 10.0.0.18 -p tcp --dport 80 -j REDIRECT --to-ports 90测试结果:更改为90端口后,拒绝连接,重定向之后,可以开启服务

7. firewalld常见区域总结。
firewalld是一个动态防火墙管理器,作为Systemd管理的防火墙前端工具,为Linux操作系统提供了一种方便且灵活的方式来管理网络访问控制。firewalld使用基于“区域”(Zone)的概念来管理防火墙策略,每个区域都对应一组特定的规则,用于定义该区域内允许和禁止的网络访问。firewalld默认提供了九个zone配置文件,以下是这些常见区域的总结:
1. trusted(信任区域)
功能及作用:可接收所有的网络连接。
2. public(公共区域)
功能及作用:除非与传出流量相关,或与ssh或dhcpv6-client预定义服务匹配,否则拒绝流量传入。在公共区域内,不能相信网络内的其他计算机不会对计算机造成危害,只能接收经过选择的连接。并且,该区域是新添加网络接口的默认区域。
3. work(工作区域)
功能及作用:除非与传出流量相关,或与ssh、ipp-client、dhcpv6-client预定义服务匹配,否则拒绝流量传入,用于工作区。相信网络内的其他计算机不会危害计算机,仅接收经过选择的连接。
4. home(家庭区域)
功能及作用:除非与传出流量相关,或与ssh、ipp-client、mdns、samba-client、dhcpv6-client预定义服务匹配,否则拒绝流量传入,用于家庭网络。信任网络内的其他计算机不会危害计算机,仅接收经过选择的连接。
5. internal(内部区域)
功能及作用:除非与传出流量相关,或与ssh、ipp-client、mdns、samba-client、dhcpv6-client预定义服务匹配,否则拒绝流量传入,用于内部网络。信任网络内的其他计算机不会危害计算机,仅接收经过选择的连接。
6. external(外部区域)
功能及作用:拒绝流量进入,除非与流出有关,与ssh相关,则允许。
7. dmz(隔离区域也称为非军事区域)
功能及作用:拒绝流量进入,除非与流出有关。对于隔离区域,只有选择接受传入的网络连接。
8. block(限制区域)
功能及作用:阻止任何传入的网络数据包,除非与流出的流量相关。
9. drop(丢弃区域)
功能及作用:任何传入的网络连接都被拒绝,并且不产生包含ICMP(Internet Control Message Protocol,互联网控制报文协议)的错误响应。
这些区域为网络管理员提供了灵活的方式来定义不同网络环境下的防火墙策略,从而确保系统的安全性。管理员可以根据实际需要选择合适的区域,并配置相应的规则来允许或拒绝特定的网络流量。
8. 通过ntftable来实现暴露本机80/443/ssh服务端口给指定网络访问
nft add table inet test
nft add chain inet test_chain
nft add rule inet test test_chain tcp dport 80 accept
nft add rule inet test test_chain tcp dport 443 accept
nft add rule inet test test_chain tcp dport ssh accept
9. 完成 nginx 反向代理 tomcat实现基于redis会话复制的集群构建
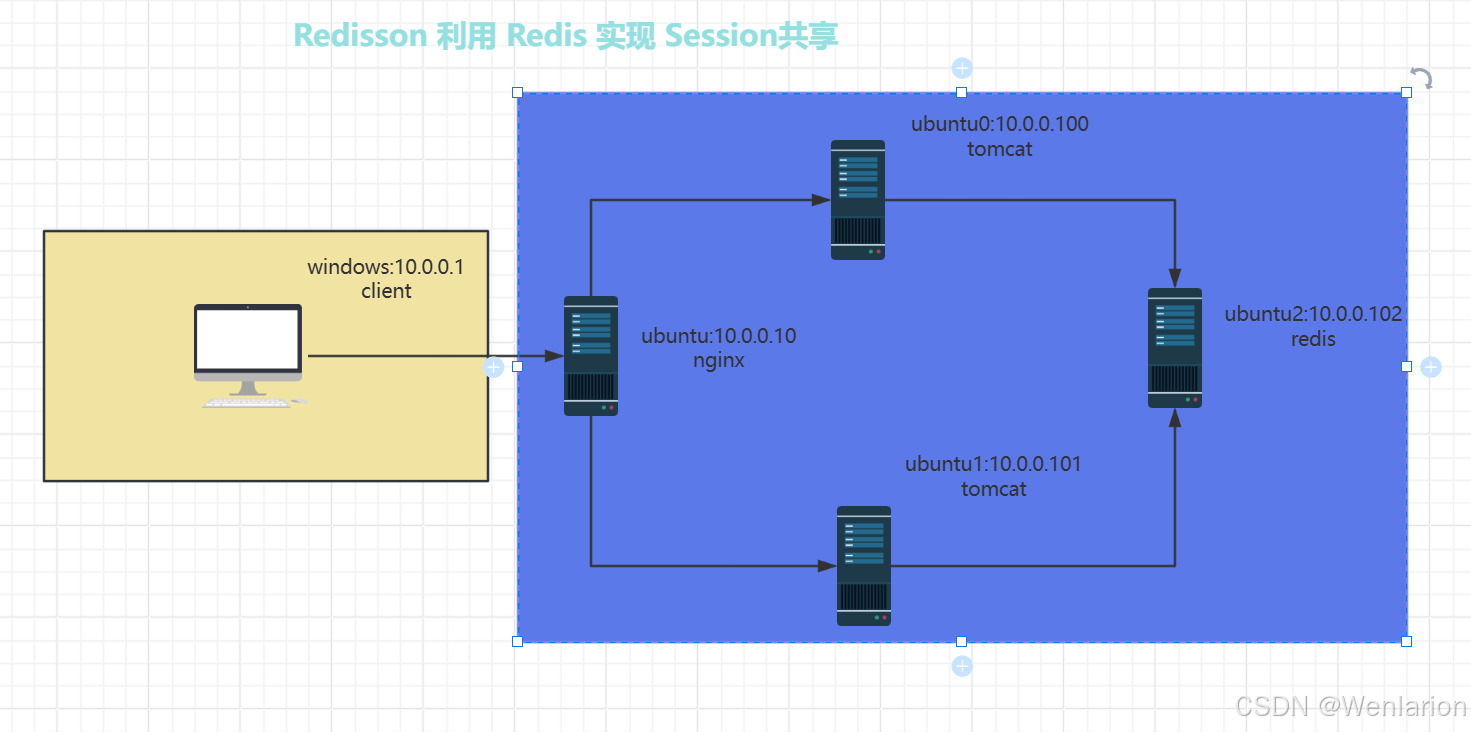
使用 Nginx 作为反向代理,利用Resisson模块,来构建一个基于 Redis 会话复制的 Tomcat 集群,可以确保用户的会话信息在所有 Tomcat 实例之间共享,从而提高高可用性和负载均衡。以下是详细的步骤:
1、在ubuntu(10.0.0.10)安装nginx,设置nginx反向代理
# 使用apt包管理器安装nginx
apt -y install nginx
# 编辑nginx的主配置文件
vim /etc/nginx/nginx.conf
# 在http块中,包含/etc/nginx/conf.d/目录下的所有.conf文件,以便管理多个站点配置
http{
...
include /etc/nginx/conf.d/*.conf;
}
# 创建并编辑特定站点的配置文件
vim /apps/nginx/conf/conf.d/www.magedu.com.conf
# 定义后端服务器组magedu,包含两个服务器实例
upstream magedu {
server 10.0.0.100:8080;
server 10.0.0.101:8080;
}
# 配置一个server块,用于处理对www.magedu.org的请求
server {
listen 80; # 监听80端口(HTTP)
server_name www.magedu.org; # 指定服务器名称
listen 443 ssl; # 同时监听443端口(HTTPS)
# 指定SSL证书和密钥文件路径
ssl_certificate /apps/nginx/conf/ssl/www.magedu.com.pem;
ssl_certificate_key /apps/nginx/conf/ssl/www.magedu.com.key;
# 如果请求是通过HTTP发送的,则重定向到HTTPS
if ( $scheme = http ){
return 301 https://$server_name$request_uri;
}
# 配置location块,用于处理所有请求
location / {
proxy_pass http://magedu; # 将请求转发到后端服务器组magedu
proxy_set_header Host $http_host; # 设置请求头,将原始请求的Host字段传递给后端服务器
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # 设置请求头,将客户端IP地址传递给后端服务器
}
}
# 重新加载nginx配置,使更改生效
nginx -s reload2、在cc-ubuntu2(10.0.0.102)安装redis,用于rediss会话共享
# 使用apt包管理器安装redis
apt -y install redis # 安装redis文件
# 编辑redis配置文件
vim /etc/redis/redis.conf # 修改redis配置文件
# 将bind配置项修改为0.0.0.0,允许所有IP地址连接redis
bind 0.0.0.03、cc-ubuntu0(10.0.0.100)和cc-ubuntu2(10.0.0.101)依次安装jdk和tomcat
# 编写tomcat安装脚本
vim tomcat_install.sh
#!/bin/bash
# 定义Tomcat和JDK的版本号
TOMCAT_VERSION=9.0.97
JDK_VERSION=8u391
# 定义Tomcat和JDK的安装包名称
TOMCAT_FILE="apache-tomcat-${TOMCAT_VERSION}.tar.gz"
JDK_FILE="jdk-${JDK_VERSION}-linux-x64.tar.gz"
# 定义JDK和Tomcat的安装目录
JDK_DIR="/usr/local/src"
TOMCAT_DIR="/usr/local/src"
# 获取当前目录路径
DIR=`pwd`
# 定义一个颜色输出函数,用于显示安装状态
color () {
RES_COL=60
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
SETCOLOR_SUCCESS="echo -en \\033[1;32m"
SETCOLOR_FAILURE="echo -en \\033[1;31m"
SETCOLOR_WARNING="echo -en \\033[1;33m"
SETCOLOR_NORMAL="echo -en \E[0m"
echo -n "$2" && $MOVE_TO_COL
echo -n "["
if [ $1 = "success" -o $1 = "0" ] ;then
${SETCOLOR_SUCCESS}
echo -n $" OK "
elif [ $1 = "failure" -o $1 = "1" ] ;then
${SETCOLOR_FAILURE}
echo -n $"FAILED"
else
${SETCOLOR_WARNING}
echo -n $"WARNING"
fi
${SETCOLOR_NORMAL}
echo -n "]"
echo
}
# 定义安装JDK的函数
install_jdk(){
if [ ! -f "$DIR/$JDK_FILE" ];then
color 1 "$JDK_FILE 文件不存在"
exit;
elif [ -d $JDK_DIR/jdk ];then
color 1 "JDK 已经安装"
exit
else
[ -d "$JDK_DIR" ] || mkdir -pv $JDK_DIR
fi
tar xvf $DIR/$JDK_FILE -C $JDK_DIR
cd $JDK_DIR
pwd
ln -s jdk1* jdk
cat > /etc/profile.d/jdk.sh <<EOF
export JAVA_HOME=$JDK_DIR/jdk
export PATH=\$PATH:\$JAVA_HOME/bin
#export JRE_HOME=\$JAVA_HOME/jre
#export CLASSPATH=.:\$JAVA_HOME/lib/:\$JRE_HOME/lib/
EOF
. /etc/profile.d/jdk.sh
java -version && color 0 "JDK 安装完成" || { color 1 "JDK 安装失败" ; exit; }
}
# 定义安装Tomcat的函数
install_tomcat(){
if [ ! -f "$DIR/$TOMCAT_FILE" ];then
color 1 "$TOMCAT_FILE 文件不存在"
exit;
elif [ -d $TOMCAT_DIR/tomcat ];then
color 1 "TOMCAT 已经安装"
exit
else
[ -d "$TOMCAT_DIR" ] || mkdir -pv $TOMCAT_DIR
fi
tar xf $DIR/$TOMCAT_FILE -C $TOMCAT_DIR
cd $TOMCAT_DIR && ln -s apache-tomcat-*97/ tomcat
echo "PATH=$TOMCAT_DIR/tomcat/bin:"'$PATH' > /etc/profile.d/tomcat.sh
id tomcat &> /dev/null || useradd -r -s /sbin/nologin tomcat
cat > $TOMCAT_DIR/tomcat/conf/tomcat.conf <<EOF
JAVA_HOME=$JDK_DIR/jdk
EOF
chown -R tomcat.tomcat $TOMCAT_DIR/tomcat/
cat > /lib/systemd/system/tomcat.service <<EOF
[Unit]
Description=Tomcat
#After=syslog.target network.target remote-fs.target nss-lookup.target
After=syslog.target network.target
[Service]
Type=forking
EnvironmentFile=$TOMCAT_DIR/tomcat/conf/tomcat.conf
ExecStart=$TOMCAT_DIR/tomcat/bin/startup.sh
ExecStop=$TOMCAT_DIR/tomcat/bin/shutdown.sh
RestartSec=3
PrivateTmp=true
User=tomcat
Group=tomcat
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable --now tomcat.service &> /dev/null
systemctl is-active tomcat.service &> /dev/null && color 0 "TOMCAT 安装完成" || { color 1 "TOMCAT 安装失败" ; exit; }
}
# 调用安装JDK和Tomcat的函数
install_jdk
install_tomcat
# 运行安装脚本,安装tomcat
bash tomcat_install.sh
4、编辑虚拟机、redisson模块配置文件和网站资源文件,重新启动tomcat。
# 编辑Tomcat的server.xml配置文件,配置新的虚拟主机
vim /usr/local/src/tomcat/conf/server.xml
# 在<Host>标签内配置应用基础目录、自动部署等参数
<Server>
<Service>
<Engine>
...
<Host name="www.magedu.org" appBase="/data/test/webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
</Engine>
</Service>
</Server>
# 编辑Tomcat的context.xml配置文件,配置Redis会话管理器
vim /usr/local/src/tomcat/conf/context.xml
# 在<Context>标签内添加RedissonSessionManager配置,用于管理Redis会话
<Context>
...
<Manager className="org.redisson.tomcat.RedissonSessionManager"
configPath="${catalina.base}/conf/redisson.conf"
readMode="REDIS" updateMode="DEFAULT" broadcastSessionEvents="false"
keyPrefix=""/>
</Context>
# 编辑Redisson的配置文件,配置Redis连接信息
vim /usr/local/src/tomcat/conf/redisson.conf
# 配置Redis服务器的地址、连接池大小等参数
---
singleServerConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
password: null
subscriptionsPerConnection: 5
clientName: null
address: "redis://10.0.0.102:6379"
subscriptionConnectionMinimumIdleSize: 1
subscriptionConnectionPoolSize: 50
connectionMinimumIdleSize: 24
connectionPoolSize: 64
database: 0
dnsMonitoringInterval: 5000
threads: 16
nettyThreads: 32
codec: !<org.redisson.codec.Kryo5Codec> {}
transportMode: "NIO"
# 更改Tomcat目录的拥有者为tomcat用户
chown -R tomcat.tomcat /usr/local/src/tomcat
# 创建Tomcat的应用基础目录,并编写一个简单的JSP页面用于测试
mkdir -p /data/test/webapps/ROOT
vim /data/test/webapps/ROOT/index.jsp
# JSP页面内容,显示服务器名称、本地地址和端口、会话ID以及当前时间
<%@ page import="java.util.*" %>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>tomcat test</title>
</head>
<body>
<h1> Tomcat Website </h1>
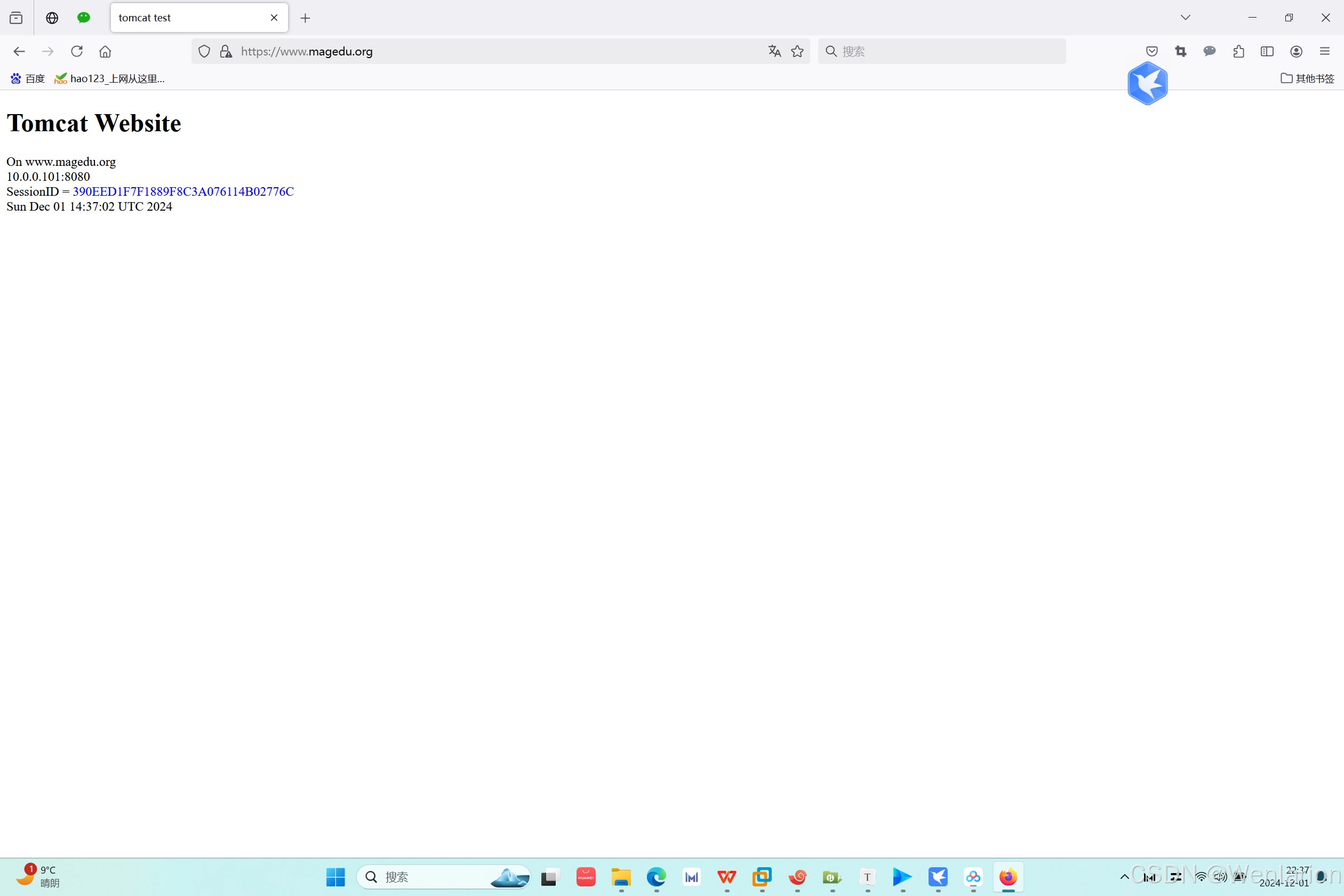
<div>On <%=request.getServerName() %></div>
<div><%=request.getLocalAddr() + ":" + request.getLocalPort() %></div>
<div>SessionID = <span style="color:blue"><%=session.getId() %></span></div>
<%=new Date()%>
</body>
</html>
#重新启动tomcat
systemctl restart tomcat5、测试结果:
在windows系统中修改 C:\Windows\System32\drivers\etc\hosts文件,添加一行
10.0.0.10 www.magedu.com
在windows系统上访问www.magedu.com,刷新浏览器页面,查看会话和访问主机IP
会话保持测试结果:
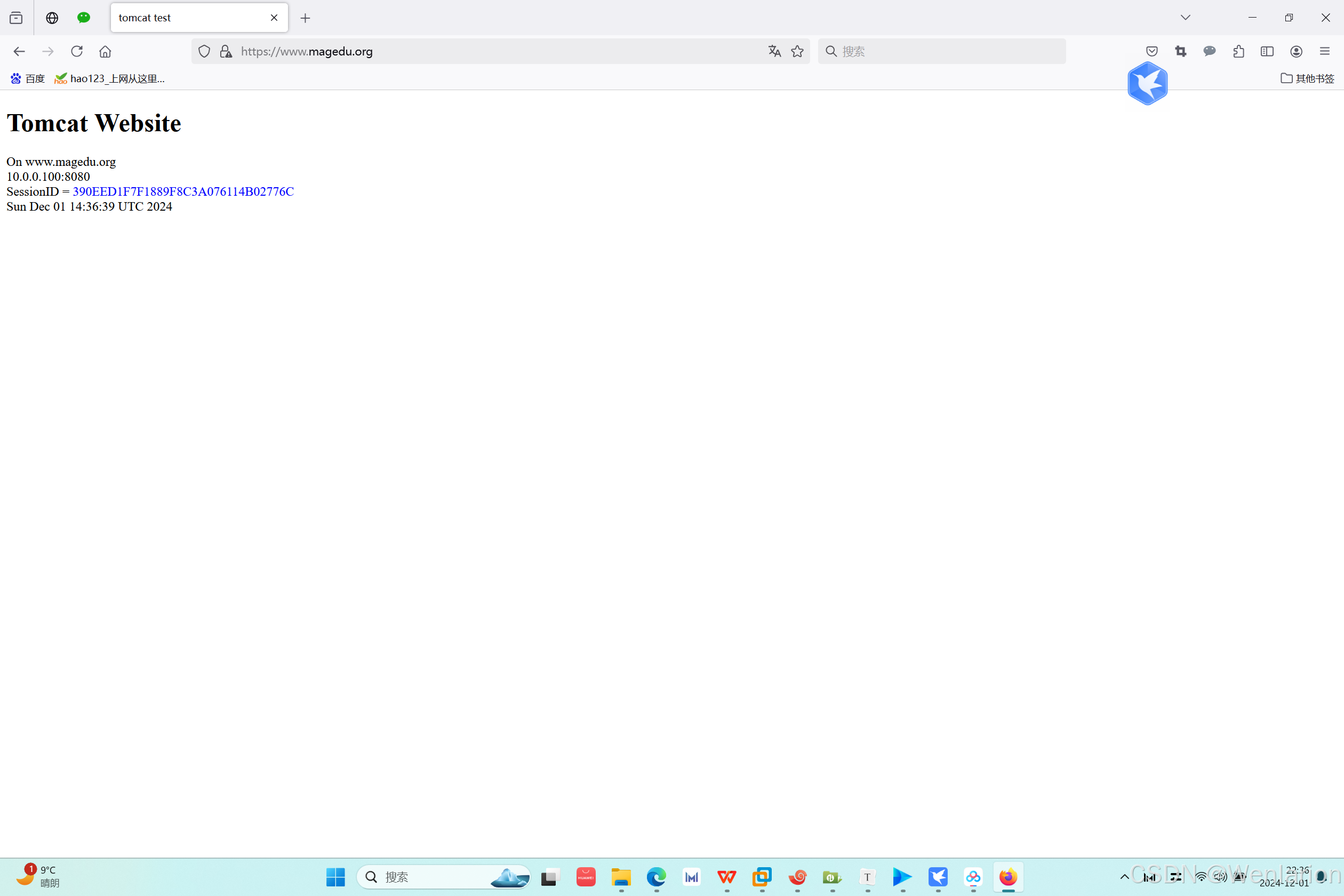
10. 总结 JVM垃圾回收算法和分代
JVM(Java虚拟机)中的垃圾回收算法和分代机制是Java内存管理的重要组成部分。以下是对JVM垃圾回收算法和分代的总结:
一、JVM垃圾回收算法
JVM中的垃圾回收算法主要包括以下几种:
标记-清除算法(Mark-Sweep):
阶段:分为标记阶段和清除阶段。在标记阶段,垃圾回收器会遍历所有对象,并标记存活的对象;在清除阶段,垃圾回收器会清除未被标记的对象,并释放其内存。
缺点:标记、清除之后会产生大量不连续的内存碎片,内存碎片会导致需要分配大对象时无法找到连续的内存而不得不触发另一次垃圾收集动作。
复制算法(Copying):
原理:将可用内存按容量划分为大小相等的两块,每次只用其中一块。当这一块内存用完时,就将还存活的对象复制到另一块上面,然后清除当前区域的所有对象。
优点:解决了内存碎片的问题。
缺点:需要两倍的内存空间,空间利用率低。如果内存中大量对象是存活的,那么会产生大量的内存复制的开销。
标记-整理算法(Mark-Compact):
原理:在标记和清除阶段之后,将存活的对象压缩到内存的一端,并直接清除边界以外的内存。
优点:避免了内存碎片的问题。
缺点:压缩过程需要额外的时间,并且存在Stop-the-World(STW)问题,即在垃圾回收算法执行过程中,JVM内存冻结,应用程序停顿。
分代收集算法(Generational):
原理:基于对象存活周期的垃圾回收算法。它将内存分为新生代和老年代两个区域,新生代通常包含大量新创建的对象,老年代包含长时间存活的对象。垃圾回收器根据不同代的特点采用不同的回收策略,如新生代采用复制算法,老年代采用标记-整理算法。
优点:能够提高垃圾回收的效率,减少不必要的内存清理。
此外,还有一些其他算法,如分区算法(Region)、引用计数算法(Reference Counting)和自适应混合回收算法(Adaptive Hybrid)等,它们各有优缺点,适用于不同的场景。
二、JVM中的分代机制
JVM中的分代机制主要是基于对象的存活周期来划分的,通常分为以下几个代:
新生代(Young Generation):
特点:主要是用来存放新生的对象。所有新生成的对象首先都是放在新生代的。新生代的目标就是尽可能快速地收集掉那些生命周期短的对象。
内部划分:新生代内部又分为伊甸园区(Eden Space)和幸存者区(Survivor Space),通常比例为8:1:1(Eden:Survivor0:Survivor1)。
垃圾回收:当新生代空间不足时,会触发Minor GC(新生代垃圾回收)。存活的对象会被复制到另一个幸存者区,并且年龄加1。当对象的年龄超过某个阈值(默认为15)时,会被晋升到老年代。
老年代(Old Generation):
特点:在新生代中经历了多次垃圾回收后仍然存活的对象,就会被放到老年代中。因此,可以认为老年代中存放的都是一些生命周期较长的对象。
垃圾回收:当老年代空间不足时,会先尝试触发Minor GC以回收部分空间。如果之后空间仍不足,那么会触发Full GC(整堆垃圾回收),此时会停止所有用户线程,直到垃圾回收结束。Full GC的停顿时间通常会比Minor GC长。
持久代/元空间(PermGen/Metaspace,Java 8及以后为元空间):
特点:用于存放静态文件,如Java类、方法等。在Java 8及以后的版本中,持久代被元空间所取代。
垃圾回收:对持久代/元空间的垃圾回收主要回收两部分内容:废弃的常量和不再使用的类型。但由于其回收效率偏低,且对GC带来不必要的复杂度,因此在实际应用中需要谨慎处理。
综上所述,JVM中的垃圾回收算法和分代机制共同构成了Java内存管理的核心。通过选择合适的垃圾回收算法和合理的分代策略,可以优化JVM的性能和稳定性,提高应用程序的运行效率。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)