目标检测之DETR(DEtection TRansformer)
Lmatch−1ci≠∅pσici1ci≠∅Lboxbibσi(1)Lmatch−1ci∅pσici1ci∅Lboxbibσi11ci≠∅1ci∅是一个指示函数,当第iii个物体有有效类别时取值为 1,否则为 0;cic_ici表示第iii个物体的真实类别;σi\sigma(i)σi表示与第ii。
1. 引言
1.1 背景与发展
DETR(Detection Transformer)是由 Facebook AI Research(FAIR)团队于 2020 年提出的一种全新的目标检测方法,首次将 Transformer 架构引入到目标检测任务中,标志着目标检测进入了端到端建模的新阶段。
在 DETR 出现之前,主流的目标检测方法如 Faster R-CNN、YOLO 和 SSD 等,通常依赖于复杂的多阶段处理流程,包括候选区域生成、锚框设计、非极大值抑制(NMS)等。这些手工设计的组件虽然有效,但增加了模型的复杂性和训练难度。DETR 的提出,旨在简化这一流程。
1.2 DETR 的创新点
DETR的论文提出了一种将目标检测转化为直接集合预测(Set Prediction)问题的新方法。该方法摒弃了传统检测流程中依赖人工设计的组件,如非极大值抑制算法(non-maximum suppression)或锚框生成机制(anchor generation),通过模型自身学习目标之间的关系及全局图像信息,并行输出最终预测结果。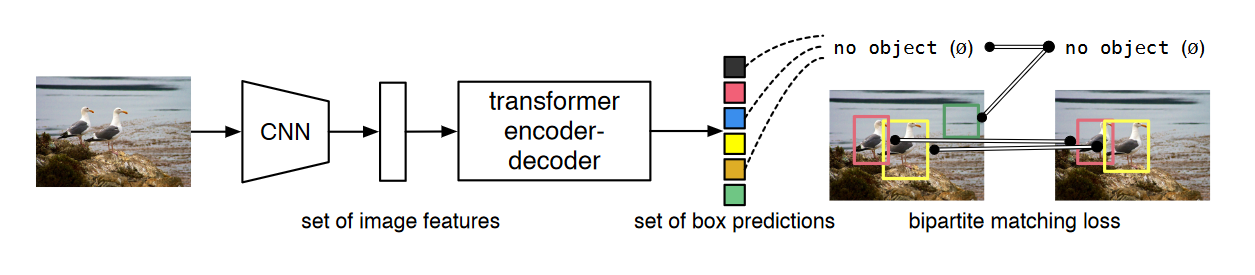
新框架名为DEtection TRansformer(DETR),其核心思想包含两部分:
- 基于集合的全局损失函数 :通过二部图匹配技术,确保模型预测的每个目标唯一且不重复。
- Transformer编码器-解码器架构 :利用Transformer的全局注意力机制,分析整张图像的上下文信息。
具体而言,DETR仅需一组预先学习的“ 对象查询(object queries)”(类似任务提示词),即可推理出图像中所有目标的位置和类别。该设计概念简洁,无需依赖复杂专用库,且在COCO数据集上的表现与经典Faster R-CNN相当,甚至运行效率更高。此外,DETR可轻松扩展至全景分割任务,性能显著优于现有方法。
2. 模型架构解析
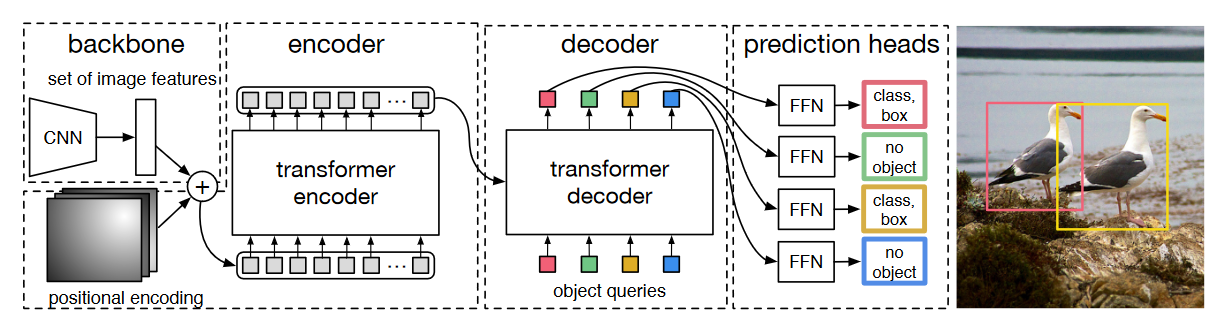
2.1 CNN 主干网络(Backbone)
DETR采用经典的卷积神经网络作为骨干网络(Backbone),其核心作用是将原始图像数据映射为高维特征表示。具体而言:
-
输入定义
输入图像表示为三维张量 x img ∈ R 3 × H 0 × W 0 x_{\text{img}} \in \mathbb{R}^{3 \times H_0 \times W_0} ximg∈R3×H0×W0,其中通道维度固定为3(RGB三通道), H 0 H_0 H0 和 W 0 W_0 W0 分别表示原始图像的高度和宽度 [[6]]。 -
输出特征图
骨干网络输出降采样32倍的特征图 f ∈ R C × H × W f \in \mathbb{R}^{C \times H \times W} f∈RC×H×W,其中:- 通道维度 C = 2048 C=2048 C=2048(典型ResNet输出特征维度)
- 空间维度 H = H 0 32 H = \frac{H_0}{32} H=32H0, W = W 0 32 W = \frac{W_0}{32} W=32W0
该特征图保留了图像的全局语义信息,同时降低了空间分辨率以提升计算效率。
-
网络选择
实验中通常选用ResNet-50或ResNet-101作为基础网络,因其在ImageNet预训练中表现出优异的特征提取能力。
2.2 Transformer 编码器
-
特征维度压缩
DETR在获得CNN输出的特征图后,通过1×1卷积对通道维度进行压缩。具体而言,将原始特征图 f ∈ R C × H × W f \in \mathbb{R}^{C \times H \times W} f∈RC×H×W 的通道数从 C = 2048 C=2048 C=2048降至 d = 256 d=256 d=256,得到新的特征表示 f ′ ∈ R d × H × W f' \in \mathbb{R}^{d \times H \times W} f′∈Rd×H×W。这一操作不仅减少了后续Transformer的计算量(通过1×1卷积实现参数压缩),还保留了特征的空间结构信息。 -
序列化处理
为了适配Transformer架构,DETR将压缩后的三维特征图重塑为二维序列形式:
f ′ ′ = Reshape ( f ′ ) ∈ R d × ( H ⋅ W ) f'' = \text{Reshape}(f') \in \mathbb{R}^{d \times (H \cdot W)} f′′=Reshape(f′)∈Rd×(H⋅W)
此时特征序列长度为 N = H ⋅ W N = H \cdot W N=H⋅W,每个位置的特征向量维度为 d d d。这种展平操作使得特征图的空间位置信息需要额外编码进行补偿。 -
位置编码嵌入
由于Transformer对输入序列的顺序不敏感,DETR采用位置编码(Positional Encoding)显式注入空间位置信息。最终输入编码器的表示为:
x enc = f ′ ′ + P E ∈ R d × N x_{\text{enc}} = f'' + PE \in \mathbb{R}^{d \times N} xenc=f′′+PE∈Rd×N
其中PE可以是学习得到的位置嵌入或固定的位置编码策略,确保模型能感知特征在原始图像中的空间分布。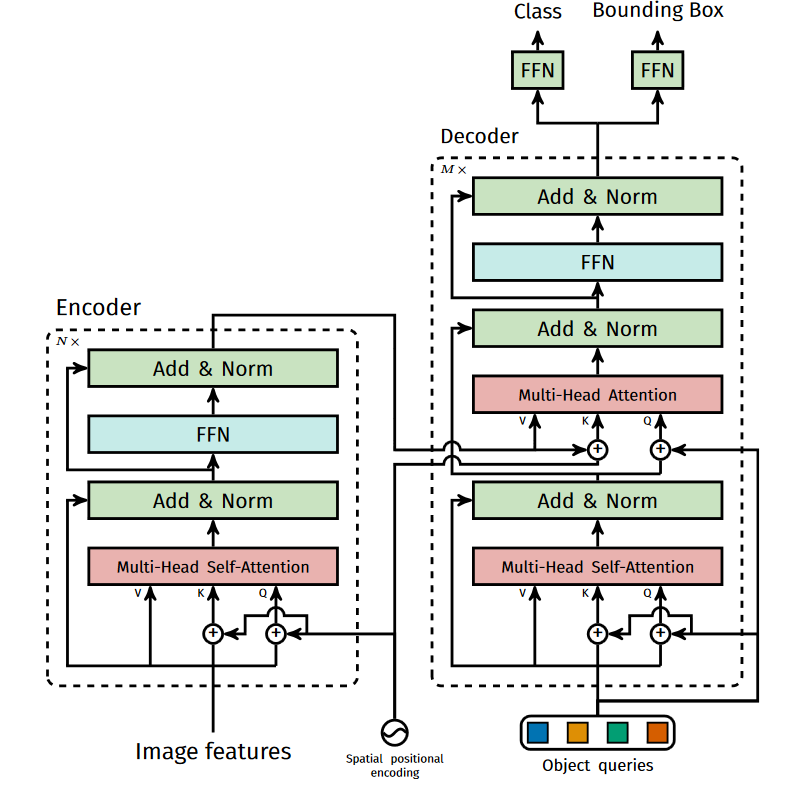
Fig 4. DETR编码器-解码器网络结构
2.3 Transformer 解码器与目标查询(Object Queries)
2.3.1 解码器架构解析
DETR的Transformer解码器采用双输入设计(如图4右侧所示):
- 编码器输出特征:来自CNN骨干网络与Transformer编码器处理后的全局特征表示
- 可学习对象查询(Object Queries):一组维度为 d d d的可训练嵌入向量
2.3.2 Object Queries核心作用
作为DETR架构的关键创新,Object Queries实现了对传统检测范式的革新:
- 功能类比:其作用类似于CNN检测算法中的anchor boxes,但通过可学习参数直接建模目标特征
- 数量配置:通常设置 N = 100 N=100 N=100个Object Queries(远大于单张图像中目标数量),确保覆盖所有潜在检测目标
- 特征交互:通过cross-attention机制,每个Object Query会从编码器特征中聚合对应目标的全局特征信息
2.3.3 预测过程详解
- 并行解码:所有Object Queries同步输入解码器,一次性生成 N N N个decoder output embedding(不同于Transformer的自回归序列生成模式)
- 结果映射:通过MLP将 d d d维嵌入向量分别解码为边界框坐标(4维)和类别概率分布
- 优化机制:
- 采用匈牙利匹配(Hungarian Matching)建立预测结果与ground truth的一一对应关系
- 通过可学习参数优化,使不同Object Queries分别收敛至特定目标实例
2.4 前馈网络(FFN)与检测头
-
预测头架构
DETR的预测头采用三层全连接网络结构,包含输入层、隐藏层和输出层:
激活函数:在隐藏层使用ReLU非线性激活函数
维度配置:输入层与Object Query维度一致(通常为256维),隐藏层节点数设为 d d d(实验中常取256),输出层对应检测任务需求。 -
多尺度预测机制
每个Object Query通过预测头生成两组输出:
边界框预测:输出4维向量表示目标位置: ( x c e n t e r , y c e n t e r , w , h ) (x_{center}, y_{center}, w, h) (xcenter,ycenter,w,h),坐标值经过sigmoid函数归一化至[0,1]区间。
类别预测:输出包含背景类别的概率分布向量, 通过softmax函数实现类别置信度归一化。 -
优化策略
冗余预测设计:设置 N = 100 N=100 N=100个Object Query(远大于典型图像中的目标数量),确保覆盖所有潜在目标
负样本处理:未匹配到真实目标的预测结果自动归类为背景类,通过匈牙利损失函数实现动态优化
并行解码:所有预测结果同步生成,突破传统自回归模型的序列依赖限制
3. 损失函数
在 DETR 模型中,给定一张图像,模型会输出 N N N 个 bounding box。为了评估这些 bounding box 的预测效果,DETR 采用了一种基于最优匹配的损失计算方法。
具体来说,DETR 会对这 N N N 个预测的 bounding box 和 N N N 个 ground truth 进行匹配,找到它们之间的最优二部图匹配关系,并基于该匹配结果计算损失函数,用于模型训练。
然而,在实际场景中,一张图片中包含的目标数量往往少于 N N N。为了解决这一不匹配问题,DETR 引入了一个特殊的背景类 ϕ \phi ϕ,表示不存在目标的位置。通过引入这个类别,可以将 ground truth 的数量扩展到 N N N,从而使得预测和真实标签的集合具有相同的容量。
在得到预测框集合和 ground truth 框集合后,我们可以通过定义匹配代价函数(通常结合分类损失和位置损失),构建代价矩阵,并使用匈牙利算法求解最优的一一匹配方案,从而实现预测与真实目标之间的高质量对齐。
Bounding box 与 ground truth 的匹配代价定义如下(公式 1):
L match = − 1 { c i ≠ ∅ } p ^ σ ( i ) ( c i ) + 1 { c i ≠ ∅ } L box ( b i , b ^ σ ( i ) ) (1) \begin{aligned} \mathcal{L}_{\text{match}} = -1_{\{c_i \neq \varnothing\}} \hat{p}_{\sigma(i)}(c_i) + 1_{\{c_i \neq \varnothing\}} \mathcal{L}_{\text{box}} \left(b_i, \hat{b}_{\sigma(i)}\right) \tag{1} \end{aligned} Lmatch=−1{ci=∅}p^σ(i)(ci)+1{ci=∅}Lbox(bi,b^σ(i))(1)
其中:
- 1 { c i ≠ ∅ } 1_{\{c_i \neq \varnothing\}} 1{ci=∅} 是一个指示函数,当第 i i i 个物体有有效类别时取值为 1,否则为 0;
- c i c_i ci 表示第 i i i 个物体的真实类别;
- σ ( i ) \sigma(i) σ(i) 表示与第 i i i 个 ground truth 匹配的 bounding box 的索引;
- p ^ σ ( i ) ( c i ) \hat{p}_{\sigma(i)}(c_i) p^σ(i)(ci) 表示 DETR 预测的第 σ ( i ) \sigma(i) σ(i) 个 bounding box 属于类别 c i c_i ci 的概率;
- b i b_i bi 和 b ^ i \hat{b}_i b^i 分别是第 i i i 个目标的真实坐标和预测坐标的表示(通常包括中心点坐标、宽和高);
- L box \mathcal{L}_{\text{box}} Lbox 表示 bounding box 坐标之间的误差度量,下文将进一步介绍。
L box \mathcal{L}_{\text{box}} Lbox 由两部分组成:IoU 损失和 L1 损失。这两部分通过加权方式组合,权重分别为 λ iou \lambda_{\text{iou}} λiou 和 λ L1 \lambda_{\text{L1}} λL1,其定义如下(公式 2):
L box ( b σ ( i ) , b ^ i ) = λ iou L iou ( b σ ( i ) , b ^ i ) + λ L1 ∥ b σ ( i ) − b ^ i ∥ 1 (2) \begin{aligned} \mathcal{L}_{\text{box}} \left(b_{\sigma(i)}, \hat{b}_i\right) = \lambda_{\text{iou}} \mathcal{L}_{\text{iou}} \left(b_{\sigma(i)}, \hat{b}_i\right) + \lambda_{\text{L1}} \left\| b_{\sigma(i)} - \hat{b}_i \right\|_1 \tag{2} \end{aligned} Lbox(bσ(i),b^i)=λiouLiou(bσ(i),b^i)+λL1
bσ(i)−b^i
1(2)
其中, L iou \mathcal{L}_{\text{iou}} Liou 使用的是 GIoU 损失,其形式如下(公式 3):
L iou ( b σ ( i ) , b ^ i ) = 1 − ( ∣ b σ ( i ) ∩ b ^ i ∣ ∣ b σ ( i ) ∪ b ^ i ∣ − ∣ B ( b σ ( i ) , b ^ i ) ∖ ( b σ ( i ) ∪ b ^ i ) ∣ ∣ B ( b σ ( i ) , b ^ i ) ∣ ) (3) \begin{aligned} \mathcal{L}_{\text{iou}} \left(b_{\sigma(i)}, \hat{b}_i\right) = 1 - \left( \frac{\left| b_{\sigma(i)} \cap \hat{b}_i \right|}{\left| b_{\sigma(i)} \cup \hat{b}_i \right|} - \frac{\left| B\left(b_{\sigma(i)}, \hat{b}_i\right) \setminus \left( b_{\sigma(i)} \cup \hat{b}_i \right) \right|}{\left| B\left(b_{\sigma(i)}, \hat{b}_i\right) \right|} \right) \tag{3} \end{aligned} Liou(bσ(i),b^i)=1−
bσ(i)∪b^i
bσ(i)∩b^i
−
B(bσ(i),b^i)
B(bσ(i),b^i)∖(bσ(i)∪b^i)
(3)
一旦完成最优匹配,就可以基于匹配结果构建完整的损失函数。DETR 中使用的最终损失函数 L Hungarian \mathcal{L}_{\text{Hungarian}} LHungarian 形式如下(公式 4):
L Hungarian ( y , y ^ ) = ∑ i = 1 N [ − log p ^ σ ^ ( i ) ( c i ) + 1 { c i ≠ ∅ } L box ( b i , b ^ σ ^ ( i ) ) ] (4) \begin{aligned} \mathcal{L}_{\text{Hungarian}} \left(y, \hat{y}\right) = \sum_{i=1}^N \left[ -\log \hat{p}_{\hat{\sigma}(i)}(c_i) + 1_{\{c_i \neq \varnothing\}} \mathcal{L}_{\text{box}} \left(b_i, \hat{b}_{\hat{\sigma}(i)}\right) \right] \tag{4} \end{aligned} LHungarian(y,y^)=i=1∑N[−logp^σ^(i)(ci)+1{ci=∅}Lbox(bi,b^σ^(i))](4)
与匹配代价相比,这个损失函数的主要区别在于它不仅考虑了前景目标的分类误差,还包含了背景类(即 ϕ \phi ϕ 类)的分类损失。
换句话说,在 L match \mathcal{L}_{\text{match}} Lmatch 中,只有非空类别的样本参与匹配代价的计算;而在 L Hungarian \mathcal{L}_{\text{Hungarian}} LHungarian 中,背景类也会被纳入损失计算范围,从而实现对整个预测集合的全面监督。
4. 参考文献

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)