一文介绍列存储数据库Hbase
Hbase是分布式、面向列的开源数据库(其实准确的说是面向列族)。HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hbase提供高性能的计算能力,Zookeeper为Hbase提供稳定服务和Failover机制,因此我们说Hbase是一个通过大量廉价的机器解决海量数据的高速存储和读取的分布式数据库解决方案。HBase以表的形式存储数据。表有行和列(族)组成。列都归属于列族,一个
·
一. 介绍
- Hbase是分布式、面向列的开源数据库(其实准确的说是面向列族)。HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hbase提供高性能的计算能力,Zookeeper为Hbase提供稳定服务和Failover机制,因此我们说Hbase是一个通过大量廉价的机器解决海量数据的高速存储和读取的分布式数据库解决方案。
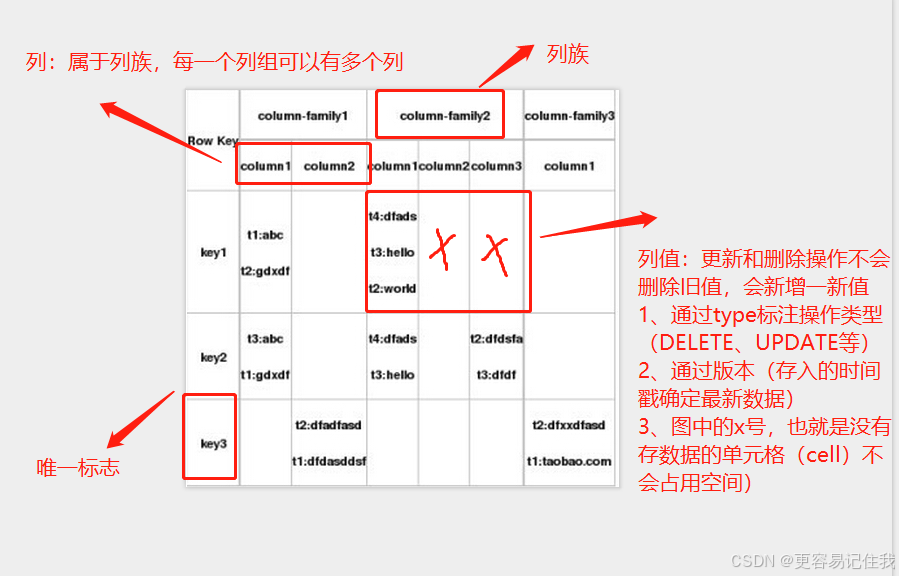
- HBase以表的形式存储数据。表有行和列(族)组成。列都归属于列族,一个列族下可以有多个列,通常情况下,列族数量应该小于等于3(如下图)
二、HBase 的特点
- 海量存储:HBase是基于HDFS分布式文件系统去构建的
- 水平扩展:增加数据处理能力的RegionServer和存储能力的HDFS
- 稀疏:每一个列族,都可以无线扩展列,空列不会占用内存空间
- 多版本:每个单元中的数据可以有多个版本,默认版本号就是插入的时间戳
- 面向列(族)设计:面向列表(簇)的存储和权限控制,列(簇)独立检索。
- 数据安全:WAL机制保证了数据写入时不会因集群异常而导致写入数据丢失
- LSM数据结构和 Rowkey 有序排列等架构上的独特设计,提高写入能力
- 通过科学性地设计RowKey 可让数据进行合理的 Region 切分,避免热点数据
- 主键索引和缓存机制使得Hbase 在海量数据下具备高速的随机读取性能
三、Hbase的使用场景
- Hbase是一个通过廉价PC机器集群来存储海量数据的分布式数据库解决方案。它比较适合的场景概括如下:
- 是巨量大(百T、PB级别)
- 查询简单(基于rowkey或者rowkey范围查询)
- 不涉及到复杂的关联
- 有几个典型的场景特别适合使用Hbase来存储:
- 海量订单流水数据(长久保存)
- 交易记录
- 数据库历史数据
四、HBase 的概念介绍
- Column Family的概念
- 列都属于列族,列族最多不超过三个,查询的时候,会在列族中,查找相关的列
- Rowkey的概念
- Rowkey的概念和mysql中的主键是完全一样的,Hbase使用Rowkey来唯一的区分某一行的数据。
- 由于Hbase只支持3中查询方式:
- 基于Rowkey的单行查询
- 基于Rowkey的范围扫描
- 全表扫描
- 因此,Rowkey对Hbase的性能影响非常大,Rowkey的设计就显得尤为的重要。设计的时候要兼顾基于Rowkey的单行查询也要键入Rowkey的范围扫描
- Region的概念
- Hbase将数据存储在每一个Region中,根据RowKey按照一定的范围进行划分不同的Region,当Region超过一定大小,会重新再分Region
- TimeStamp的概念
- 写入数据会带有timestamp,用于作为最新数据的依据,主要是为了历史数据的区分
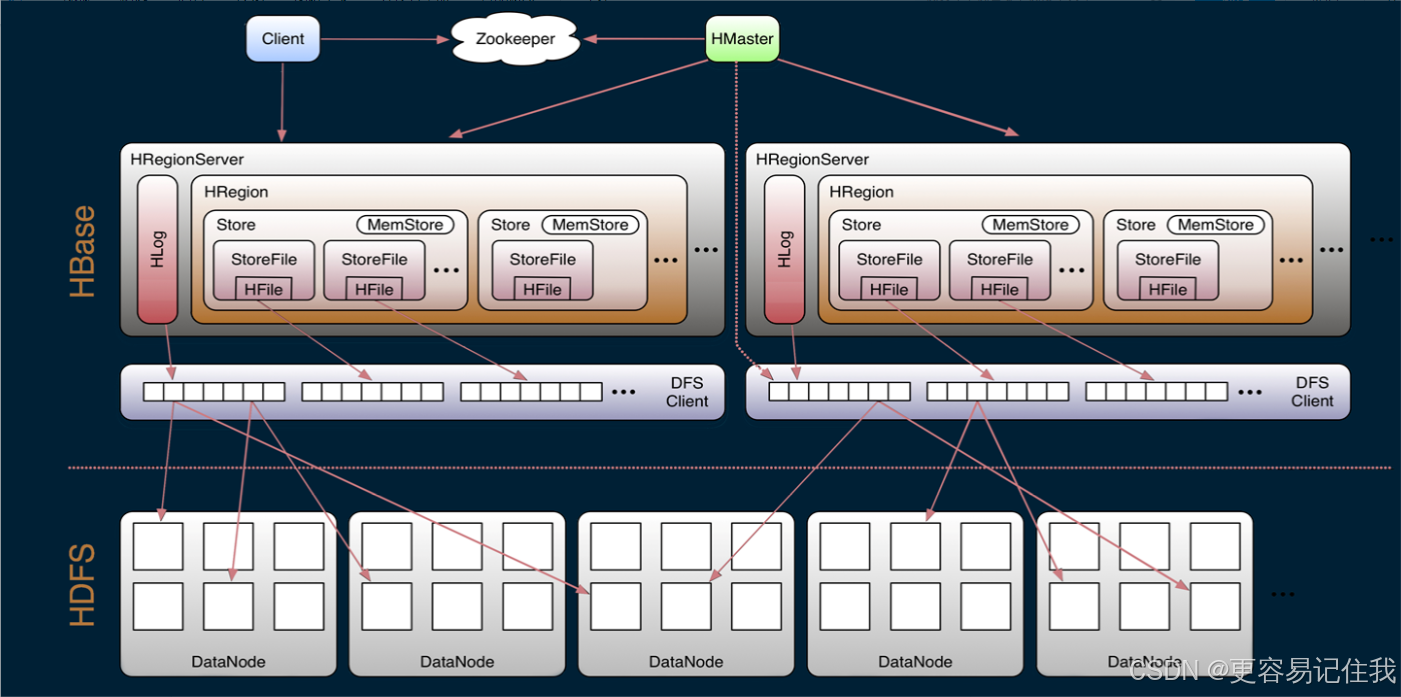
- HBase 的架构图

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)