ORACLE数据库备份入门:第二部分:2-数据文件与归档日志
数据库的数据有两个部分,即数据文件与日志文件,它们都需要备份,缺少任何一方就不能进行恢复。数据文件不比容易理解,它就是保存数据的文件,对应的是底层存储的数据块。我们经常用的数据表,会通过数据文件这个逻辑层,最终保存在存储中。那日志文件是什么?数据库的日志有两种,一是系统日志,例如alert.log等,记录了数据库的运行情况,不包括任何用户数据,用于排错等运维工作;另外一种是数据日志,记录的是数据内容,比如什么时间往哪个表里写了什么数据。数据日志,是备份需要关注的内容。
想要了解备份原理,前提是首先要了解数据库的日志原理,两者息息相关。Oracle的日志结构,是目前为止关系型数据库中最经典、最高效、最严谨的,其它的数据也使用了相似或者完全相同的架构。因此,了解了Oracle的日志体系后,学习其它数据库也会更快的上手。为了方便阅读,让新手更容易入门,文章中会尽量简化描述,减少知识点的涉及。
数据日志有三种,REDO、UNDO和FLASHBACK。这里,我们先介绍和备份关系最密切的REDO LOG,用中文表达,我们的习惯称呼是“重做“日志。
1. REDO日志简介
1.1 在线(online)和归档(archive)
REDO日志中记录了数据库全部的“写操作“,并且数据在REDO日志中写入后,应用就会得到成功的返回,不论数据是不是已经写入到数据文件。说两句题外话,REDO的性能是数据库写入的关键点,通常DBA会把REDO日志放到现有存储资源中最快的介质上,如SSD等。并且为了提升REDO日志的高可用性,还会将它进行镜像,即一个组中有多个文件,保存相同内容。
所有的数据都写入REDO日志,那这个文件必然会变的非常巨大,影响性能的同时也会难于管理。因此,REDO日志采用多个文件顺序写入的架构,并且引入归档机制。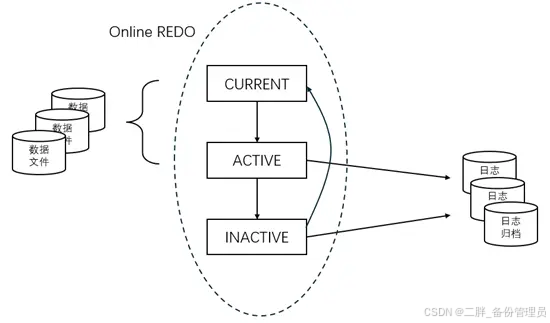
正在写入的REDO文件,状态为CURRENT,当临近写满后开始往下一个文件写入,文件状态变成ACTIVE。ACTIVE状态的REDO文件,有两个含义:一是数据还未完成写入数据文件;二是REDO日志开始了归档。当数据完成了写入数据文件后,REDO文件状态变为INACTIVE。当归档完成后,INACTIVE状态的REDO文件被标记为可以被循环利用了。因此,REDO文件至少需要配置3组,如果需要高可用,每组日志可配置多个文件(镜像)。3个REDO文件组(每组有一个文件或多个文件镜像),称为Online Redo,循环使用,并且进行归档,保证所有的历史数据被保留下来。为了提升可靠性,也可以配置更多的文件组,保证在日志被循环利用前有足够的缓冲时间进行归档。
日志的归档模式需要手动打开(在MOUNT状态开启,重启不会失效),否则REDO默认在无归档的循环使用状态,旧的数据会被覆盖。
1.2 数据写入流程
了解数据库的写入原理和流程,这对于恢复是至关重要的。当客户端有数据写入时,在执行Commit之前,数据保存在内存中。下面我们简单的了解一下过程和原理:
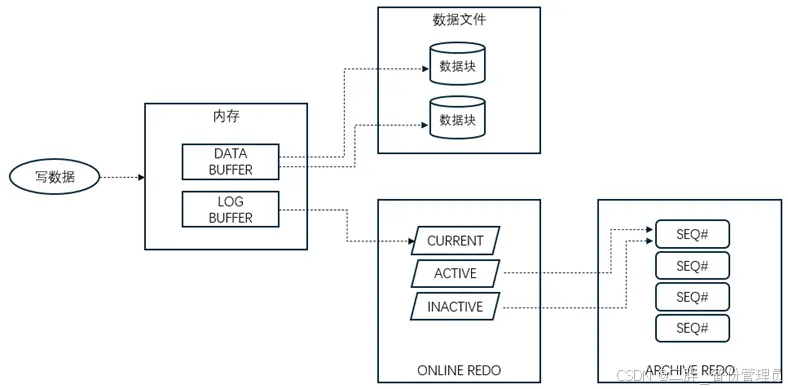
1)数据会以不同的形式分别保存在DATA BUFFER和LOG BUFFER中;
2)写数据commit会触发log buffer中的数据保存到online redo日志中,由LGWR进程执行。写操作完成后,客户端得到返回写数据成功;
3)除了数据commit之外,还有一些触发LGWR写日志文件的条件。包括:每3秒自动执行一次、日志切换、buffer消耗超过1/3、强制数据进行checkpoint操作等;
4)写日志文件操作结束后,系统将data buffer中的数据块写入数据文件中,由DBW进程执行;
5)日志先写,数据块后写,这种逻辑叫Write Ahead Log,因此两者之间可能会有差距。在有差距的时间段里,因此日志和数据块不一致,因此数据库处于不一致状态。如果此时数据库服务器意外关闭后重启,如电源故障,数据库需要instance recovery,自动将日志中的差异数据写入数据文件,保证数据文件的一致性;
6)数据库具备Checkpoint机制,将data buffer中的数据写入数据文件,前提是数据已经完成了日志文件写入。Checkpoint每3秒钟检测一次,将变化的数据从data buffer写入数据文件。除些之外,一些数据库操作也会触发Checkpoint。例如,日志切换,正常关闭数据库等;
7)日志文件是Current或Active状态,意味着它包含了还没有被写入数据文件的部分。如果日志中的全部数据已经完成了数据文件的写入,状态会变为inactive;
总结一下:首先,数据写入日志文件,客户端得到成功的返回;第二步,数据写入数据文件,数据库得到一致性。
1.3 REDO线程
每个REDO操作会有一个线程号(Thread#),在此管理下,每个日志文件分配一个序号(Sequence#)。每一次Online Redo文件被循环使用时,序号就会更新。例如:当前的Current序号是130,Active序号是129,Inactive是128。在日志切换后,Inactive的日志被循环使用,作为了Current,分配了新的序号131。以此类推,后面被循环利用的日志序号会被分配为132、133、134……,最大可增长到10^28(远远大于数据库的生命周期,不需要考虑这个问题)。那线程号呢?最多有几个?作用是什么?通常在RAC环境中才会使用多线程,即每个节点一个线程。例如:节点1的Thread#是1,节点2的Thread#是2,各自使用一套Sequence#。这样设计的意义是什么?
RAC是多个节点并发读/写数据的,每个节点有自己的Online Redo,归档保存在共享存储中。每个节点的REDO记录从该节点写入的数据。
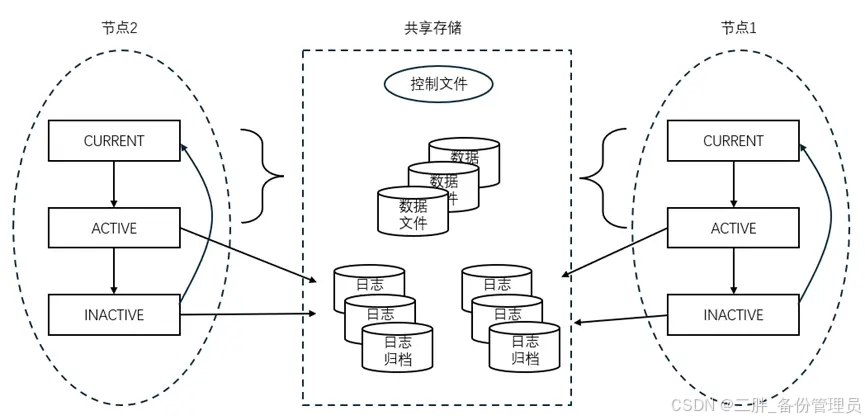 两个节点,对应了两套REDO,同时写入同一套数据文件,因此就必须保证这三者都具备一致性。控制文件中记录了这些信息,保证数据库整体的一致性。在进行恢复时,需要从两个线程的归档中应用数据,才能保证数据文件具备一致性。丢失任何一个线程的归档,数据库都无法恢复。并且,归档必须要保存在共享存储中,保证每个节点都可以访问两个线程的全部归档。
两个节点,对应了两套REDO,同时写入同一套数据文件,因此就必须保证这三者都具备一致性。控制文件中记录了这些信息,保证数据库整体的一致性。在进行恢复时,需要从两个线程的归档中应用数据,才能保证数据文件具备一致性。丢失任何一个线程的归档,数据库都无法恢复。并且,归档必须要保存在共享存储中,保证每个节点都可以访问两个线程的全部归档。
举例说明:
在RAC的一个节点进行恢复操作时(可能是丢失数据,也可能是数据文件损坏),需要将归档应用到数据文件中。控制文件计算出,如果要使数据文件达到一致点的,需要两个节点的归档。并且控制文件还提示到具体的文件,例如需要Thread 1的Sequence 251和Thread 2的Sequence 269这两个归档。这时候,无论从哪个节点操作恢复,都需要同时访问这两个归档日志文件。
2. 一致性备份
2.1 数据文件的一致性
我们先来考虑这样一个问题:数据库有3个数据文件进行备份,不论是否同时开始,都不可能同时结束。因此,我们得到的备份数据,数据文件之间是有时间差距的,这肯定不是我们想要的结果。例如,表1记录的是交易明细,表2记录了个人余额,表3记录了汇总信息。表1 备份结束后(t2),甲给乙转了50块钱,这显然不会被记录在表1的备份中。这笔交易,会更新表2 和表3。在表2 备份结束后(t4),表1又被更新了,生产新的交易,同时触发了表2和表3 的更新。这部分内容,也不会被记录在表2的备份中,当然更不可能被记录在表1的备份中。 当我们使用这份备份来恢复后,会发现3个表的数据不一致,而且数据库系统也不允许这样的恢复。怎么解决这个问题?
当我们使用这份备份来恢复后,会发现3个表的数据不一致,而且数据库系统也不允许这样的恢复。怎么解决这个问题?
找一个时间段,没有数据写入,这样就不会有一致性问题了吧。答案是否定的。即使找到了这个理想的时间段,三个表都没有更新,也无法实现一致性的恢复,更何况这种理想很难实现。首先,数据库在系统层不判断用户数据的变化,只能判断存储层的变化。其次,即使没有用户数据变化,数据文件在系统层也会定期发生变化。例如更新Checkpoint系统等。(系统定期将缓存中的数据写入存储块,即使没有用户数据发生变化,也会更新数据文件的Head信息)。因此,不论用户数据有没有变化,系统层都不会保证在一致状态。一致性的裁决,是需要查检控制文件、数据库文件、系统文件的。所有这些文件头中的SCN都相同,数据库才允许打开。这里提到了SCN这个概念,以下简要说明。
2.2 SCN
SCN(system change number)是数据库校验一致性的唯一标准,具备全局性,它是自动生成的连续增加的正整数。控制文件会记录所有日志文件、数据文件的SCN号,它们之间都是通过它来校验一致性的。
通过以下的命令输出,可以更容易的了解SCN的概念:
首先来查看数据文件的SCN,其中7号文件是用户数据文件,当前的SCN是2196299。手工触发一次Checkpoint动作(强制数据写入磁盘)后,这个数据文件的SCN更新为2198860。其它数据文件有的发生了变化,有的没变。不是定期都会自动增长吗?我们可以仔细观察,没变的数据文件有两个部分,一是PDBSEED,它是PDB的只读库,所以不会变;二是ORCLPDB,它是一个普通PDB库,但是由于状态是MOUNT,没有打开,因此也不会变。
这时我们再查看REDO日志状态,每个日志文件都记录了开始和结束的SCN(change#)。不要在意CURRENT状态的REDO的结束SCN号有多么大,它没有意义,因此不可预知结束的SCN。 再来看看归档的REDO,每个文件也都记录了起止的SCN号。
再来看看归档的REDO,每个文件也都记录了起止的SCN号。 一致性恢复,就是通过这些SCN来判断的。如果数据文件的SCN保持相同,系统认为数据库是一致的,可以打开。
一致性恢复,就是通过这些SCN来判断的。如果数据文件的SCN保持相同,系统认为数据库是一致的,可以打开。
2.3 如何达到一致性
那如何保证备份时数据库的一致性呢?
第一种办法,将数据库停止掉,或锁定,不接受更新操作。备份结束后,再打开数据库。这种办法确实可行,但是不适用于所有场景。有些交易型数据库24小时运行,不能停机,例如银行、运营商等,如何解决?
第二种方法,也是最常用的方法,在大多数场景被使用。在数据文件备份的基础上,加入归档日志的备份。归档的数据内容范围包括了所有数据文件的内容。如图: 归档日志的范围包括了t0之前开始的数据写入一直到t7,实际上,只要能满足t2到t6的范围,就可以为数据文件提供一致性的补充。在恢复时,通过归档日志的应用来将数据文件之间的差异补充完整,到达t6时间点。
归档日志的范围包括了t0之前开始的数据写入一直到t7,实际上,只要能满足t2到t6的范围,就可以为数据文件提供一致性的补充。在恢复时,通过归档日志的应用来将数据文件之间的差异补充完整,到达t6时间点。
什么是归档日志的应用?前面我们介绍了,REDO日志里面记录了所有的写操作,并且进行了归档。归档日志应用,就是将日志中的写操作,在数据文件上再执行一次。例如数据文件2备份结束的时间点是t4,但是必须要恢复到t6才能满足一致性要求。我们要找到哪些归档文件中包括了t4到t6这个时间段的数据,把它执行一次,使用数据文件2 到达t6时间点。不过不用太担心这个计算方法,因为系统会自动判断应该使用哪个归档来恢复,我们只需要指定恢复的时间点或SCN号即可。
这里有一个概念被我简化掉了,目的是让读者更容易理解,这里做一个简单的说明。数据文件的备份是需要一定的时间的,用数据文件2举例,它开始的时间点是t1,结束的时间点是t4。某些数据块在t2时间点之前完成了备份,但是在t3时间点又发生了变化,到t4时间点备份完成。实际上,我们得到的数据文件备份,不是一个t4时间点的完整的副本,内部的数据块分别处于不同的时间点,本身就是不一致的。例如,A块是t2时间点,B块是t3时间点,C块是t4时间点。但是不用担心,系统记录了这些变化,只需要备份的归档包括t2和t6的范围内所有数据即可。在恢复时,不论数据块是t2还是t3,都会通过归档来补充数据到t6。
3. 归档日志备份
数据库进行写操作时,不论数据最终被保存在哪一个数据文件,它们都会在保存之前首先写入Online
REDO日志。Online REDO日志是循环使用的,为了保证数据永久保存,将它们进行了归档。备份数据库时,在多种原因的影响下,多个数据文件不可能真正意义上的完全同时结束。因此,在恢复数据库时,需要通过归档的配合来完成数据文件的一致性。因此每一次数据文件的备份,都需要附带归档的备份。另外一个重要的信息是,Online Redo日志文件只能被Oracle内容进程访问,因此它不能备份。归档是Online Redo的离线历史副本,它可以被拷贝和备份。
在SQL终端,使用命令开出所有归档文件,
数据视图v$archived_log可以显示每个归档的顺序号(sequence),开始的SCN(first_change)和结束的SCN(即next_change-1)。备份归档时,可根据这些条件进行过滤。
备份归档的语法非常简单,
RMAN> backup archivelog all; --备份全部归档
也可以备份指定的归档文件,
RMAN> backup archivelog sequence 26; --备份序号26的归档
RMAN> backup archivelog from sequence15; --从序号15开始,备份后续全部归档,包括15
RMAN> backup archivelog low sequence15 high sequence 20; --备份序号15到20的归档,包括15和20
4. 一致性恢复
以在之前的场景中进行一致性恢复为例。文件3的备份,结束的时间点为t6。文件1和文件2,恢复到t2和t4,之后再通过归档日志恢复到t6。这样三个文件都统一恢复到了t6时间点,具备了一致性,数据库可以打开。
 另外,因为归档日志备份到了时间点t7,因此也可以将所有文件统一恢复到t7。
另外,因为归档日志备份到了时间点t7,因此也可以将所有文件统一恢复到t7。 归纳一下恢复目标的时间范围,它是从最后一个数据文件备份结束的时间点(t6)到归档日志备份结束的时间点(t7)之间的任意时间点(包括t6和t7)。
归纳一下恢复目标的时间范围,它是从最后一个数据文件备份结束的时间点(t6)到归档日志备份结束的时间点(t7)之间的任意时间点(包括t6和t7)。
可以看到,归档是保证数据库一致性最关键的内容。我们再来考虑一个效率相关的问题。数据文件备份和归档日志备份的频率应该如何配合?这将在后续的增量备份章节,结合实际操作来讨论。
https://edu.csdn.net/course/detail/40454

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)