达梦数据库-自定义类型简介
一是通过 SQL 语句 CREATE TYPE 语句创建。二是通过 DMSQL 程序 TYPE 语句创建对象类型的创建方法和另外三者略有不同,包含创建类型和创建类型体两部分如果创建类型时声明了过程或方法,那么需要使用 CREATE TYPE BODY 定义这些过程或方法。
自定义类型包括:
记录类型
对象类型
数组类型
集合类型
自定义类型的创建方式有两种:
一是通过 SQL 语句 CREATE TYPE 语句创建。
二是通过 DMSQL 程序 TYPE 语句创建
对象类型的创建方法和另外三者略有不同,包含创建类型和创建类型体两部分
如果创建类型时声明了过程或方法,那么需要使用 CREATE TYPE BODY 定义这些过程或方法
创建类型
通过SQL语句创建
此种方式创建的自定义类型可以作为 DMSQL 程序语句块中变量、过程或函数参数的数据类型
其中对象类型、VARRAY 类型、嵌套表类型还可以直接作为表中列的数据类型
语法:
CREATE [OR REPLACE] TYPE [<模式名>.]<类型名>[WITH ENCRYPTION] [<调用权限子句>]AS|IS <自定义类型定义子句>;
[<调用权限子句>]::=
AUTHID DEFINER |
AUTHID CURRENT_USER
<自定义类型定义子句>::=
<记录类型定义子句>|
<对象类型定义子句>|
<数组类型定义子句>|
<集合类型定义子句>
<对象类型定义子句> ::= OBJECT [UNDER [<模式名>.]<父类型名>] (<对象定义>,{<对象定义>})[[NOT] FINAL] [[NOT] INSTANTIABLE]
<对象定义> ::= <变量列表定义>|<过程声明>|<函数声明>|<构造函数声明>
<过程声明> ::= [<方法继承属性>][STATIC|MEMBER] PROCEDURE <过程名> <参数列表>
<函数声明> ::= [<方法继承属性>][MAP] [STATIC|MEMBER] FUNCTION <函数名> <参数列表> RETURN <返回值数据类型>[DETERMINISTIC][PIPELINED]
<方法继承属性> ::= <重载属性> | <final属性> | <重载属性> <final属性>
<重载属性> ::= [NOT] OVERRIDING
<final属性> ::= FINAL | NOT FINAL | INSTANTIABLE | NOT INSTANTIABLE
<构造函数声明> ::= CONSTRUCTOR FUNCTION <函数名> <参数列表> RETURN SELF AS RESULT
<记录类型定义子句> ::= RECORD(变量列表定义)
<数组类型定义子句> ::= ARRAY <数据类型>' [' [<常量表达式>]{,[<常量表达式>]}']'
<集合类型定义子句> ::= <数组集合定义子句>|<嵌套表定义子句>|<索引表定义子句>
<数组集合定义子句> ::= VARRAY(<常量表达式>) OF <数据类型> [NOT NULL]
<嵌套表定义子句> ::= TABLE OF <数据类型> [NOT NULL]
<索引表定义子句> ::= TABLE OF <数据类型> [INDEX BY <数据类型>]
![![[Pasted image 20241008155200.png]]](https://i-blog.csdnimg.cn/direct/1a69939bc71049d2afd311b6251f4159.png)
(从这个图里能看到有四种子句,分别是记录、对象、数组、集合)
示例:
展示对象类型如何作为表中列的类型,过程中的参数类型和变量类型
创建对象类型 COMPLEX
CREATE TYPE COMPLEX AS OBJECT(
RPART INT,
IPART INT,
FUNCTION PLUS(X COMPLEX) RETURN COMPLEX,
FUNCTION LES(X COMPLEX) RETURN COMPLEX
);
/
CREATE TYPE BODY COMPLEX AS
FUNCTION PLUS(X COMPLEX) RETURN COMPLEX IS
BEGIN
RETURN COMPLEX(RPART+X.RPART, IPART+X.IPART);
END;
FUNCTION LES(X COMPLEX) RETURN COMPLEX IS
BEGIN
RETURN COMPLEX(RPART-X.RPART, IPART-X.IPART);
END;
END;
/

运行第二部分后,查看这个对象的DDL,相应地加上了
这里PLUS函数是两个COMPLEX对象相加,LES是相减
建立表 c_tab。将 complex 对象类型作为 C2 的数据类型
CREATE TABLE C_TAB(C1 INT, C2 COMPLEX);
向表 c_tab 中插入数据
INSERT INTO C_TAB VALUES(1, COMPLEX(2,3));
INSERT INTO C_TAB VALUES(2, COMPLEX(4,2).PLUS(COMPLEX(2,3)));
打印表中 C2.RPART 的内容
DECLARE
A INT;
BEGIN
FOR I IN 1..2 LOOP
SELECT C2.RPART INTO A FROM C_TAB WHERE C1=I;
PRINT A;
END LOOP;
END
/
表中数据是这样的: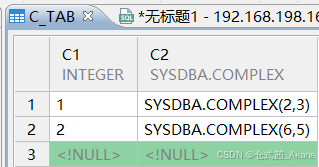
将 complex 对象类型作为过程的参数 a 的类型和变量 b 的类型。
CREATE or replace PROCEDURE proc_complex(a COMPLEX default COMPLEX(2,3)) AS
b COMPLEX;
BEGIN
a.RPART=a.RPART+100;
b=a;
PRINT b.RPART;
END;
/
调用过程 proc_complex。
call proc_complex;
通过DMSQL程序创建
通过 DMSQL 程序 TYPE 语句创建自定义类型。
此种方式创建的自定义类型可以作为 DMSQL 程序语句块中变量、过程或函数参数的数据类型
记录类型
记录类型是由单行多列的标量类型构成复合类型,类似于 C 语言中的结构
记录类型提供了处理彼此独立但又作为一个整体单元的多个相关变量的一种机制
例如:DECLAREV_ID INT; V_NAME VARCHAR(30); 这两个变量在逻辑上是相互关联的,因为它们分别对应表 T(ID INT, NAME VARCHAR(30))中的两个字段。
如果为这样的变量声明一个记录类型,那么它们之间的关系就十分明显了。
语法:
TYPE <记录类型名> IS RECORD
(<字段名><数据类型> [<default 子句>]{,<字段名><数据类型> [<default 子句>]});
<default 子句> ::= <default 子句 1>
| <default 子句 2>
<default 子句 1> ::= DEFAULT <缺省值>
<default 子句 2> ::= := <缺省值>
通过将需要操作的表结构定义成一个记录,可以方便地对表中的行数据进行操作。
在DMSQL 程序中使用记录,需要先定义一个 RECORD 类型,再用该类型声明变量,也可以使用[[数据类型#%TYPE 和 %ROWTYPE|%ROWTYPE]]来创建与表结构匹配的记录。
可以单独对记录中的字段赋值,使用点标记引用一个记录中的字段(记录名.字段名)。
下面的例子定义了一个记录类型 sale_person,声明一个该记录类型的变量 v_rec,使用点标记为 v_rec 的两个字段赋值,之后使用 v_rec 更新表的一行数据
DECLARE
TYPE sale_person IS RECORD(
ID SALES.SALESPERSON.SALESPERSONID%TYPE,
SALESTHISYEAR SALES.SALESPERSON.SALESTHISYEAR%TYPE); -- 定义记录类型
v_rec sale_person; -- 声明变量
BEGIN
v_rec.ID := 1;
v_rec.SALESTHISYEAR:= 5500; -- 变量赋值
UPDATE SALES.SALESPERSON SET SALESTHISYEAR=v_rec.SALESTHISYEAR WHERE
SALESPERSONID =v_rec.ID; -- 用这个记录类型的变量更新一行数据
END;
/
也可以将一个记录直接赋值给另外一个记录,此时两个记录中的字段类型定义必须完全一致。
如下面的例子将表中的一行数据读取到一个记录中。
然后,将记录 v_rec1 赋值给v_rec2。
DECLARE
TYPE t_rec IS RECORD( ID INT, NAME VARCHAR(50));
TYPE t_rec_NEW IS RECORD( ID INT, NAME VARCHAR(50));
v_rec1 T_REC;
v_rec2 T_REC_NEW;
BEGIN
SELECT PRODUCTID,NAME INTO v_rec1 FROM PRODUCTION.PRODUCT WHERE AUTHOR LIKE '鲁迅'; -- 将数据读取到v_rec1中
v_rec2 := v_rec1; -- 记录赋值
PRINT v_rec2.ID;
PRINT v_rec2.NAME;
END;
/
定义记录类型时,字段的数据类型除了可以是常规数据类型,还可以是常规数据类型
后跟着“[n]”或“[n1,n2…]”表示一维或多维数组,如:
DECLARE
TYPE T_REC IS RECORD( ID INT[3], NAME VARCHAR(30)[3]);
DMSQL 程序还支持定义包含数组、集合和其他 RECORD 的 RECORD。例如下面是一个在 RECORD 定义中包含其他 RECORD 的例子,关于数组和集合的介绍请看后续小节。
DECLARE
TYPE TimeType IS RECORD (hours INT, minutes INT ); -- 定义记录 TimeType
TYPE MeetingType IS RECORD (
day DATE,
time_of TimeType -- 嵌套记录 TimeType
);
BEGIN
NULL;
END;
/
对象类型
不支持通过 DMSQL 程序 TYPE 语句创建对象类型。对象类型的创建请使用 SQL 语句 CREATE TYPE 语句创建
数组类型
DMSQL 程序支持数组数据类型,包括静态数组类型和动态数组类型
静态数组类型
静态数组是在声明时已经确定了数组大小的数组,其长度是预先定义好的,在整个程序中,一旦给定大小后就无法改变
语法:
TYPE <数组名> IS ARRAY <数据类型> [<数组长度>{,<数组长度>}]);
<数据类型>除了支持常规数据类型(INT,VARCHAR 等),还支持复杂数据类型(数组、记录类型和集合类型)。
本节中的示例以常规类型为主,复杂类型的示例请参考2.3.2.3.3 复杂类型数组。
<数组长度>指定数组中元素的个数,正整数。例如:[5]。此处的[]是定义数组长度的必选符号。定义多维数组需指定多个<数组长度>。
定义了静态数组类型后需要用这个类型申明一个数组变量然后进行操作。
理论上 DM 支持静态数组的每一个维度的最大长度为 65534,但是静态数组最大长度同时受系统内部堆栈空间大小的限制,如果超出堆栈的空间限制,系统会报错。
例 使用静态数组:
DECLARE
TYPE Arr IS ARRAY VARCHAR[3]; --TYPE 定义一维数组类型
a Arr; --声明一维数组
TYPE Arr1 IS ARRAY VARCHAR[2,4]; --TYPE 定义二维数组类型
b Arr1; --声明二维数组
BEGIN
FOR I IN 1..3 LOOP
a[I] := I * 10;
PRINT a[I];
END LOOP;
PRINT '--------';
FOR I IN 1..2 LOOP
FOR J IN 1..4 LOOP
b[I][J] = 4*(I-1)+J;
PRINT b[I][J];
END LOOP;
END LOOP;
END;
/
动态数组类型
与静态数组不同,动态数组可以随程序需要而重新指定大小,其内存空间是从堆(HEAP)上分配(即动态分配)的,通过执行代码而为其分配存储空间,并由 DM 自动释放内存。
动态数组与静态数组的定义方法类似,区别只在于动态数组没有指定下标,需要动态分配空间。
语法:
TYPE <数组名> IS ARRAY <数据类型> [{,}]);
定义了动态数组类型后需要用这个类型申明一个数组变量,之后在 DMSQL 程序的执行部分需要为这个数组变量动态分配空间。动态分配空间语句如下所示:
数组变量名 := NEW <数据类型>[<常量表达式>{,<常量表达式>}];
<常量表达式>指定数组中元素的个数。例如:[5]或者[5+1]。此处的[]是定义数组长度的必选符号。定义多维数组需指定多个<常量表达式>。
或者可以使用如下语句对多维数组的某一维度进行空间分配:
数组变量名 := NEW <数据类型>[<常量表达式>][];
例 1 使用动态数组:
DECLARE
TYPE Arr IS ARRAY VARCHAR[];
a Arr;
BEGIN
a := NEW VARCHAR[4]; --动态分配空间
FOR I IN 1..4 LOOP
a[I] := I * 4;
PRINT a[I];
END LOOP;
END;
/
对于多维动态数组,可以单独为每个维度动态分配空间,如下面的例子所示:
例 2 为多维动态数组的每个维度动态分配空间。
DECLARE
TYPE Arr1 IS ARRAY VARCHAR[,];
b Arr1;
BEGIN
b := NEW VARCHAR[2][]; --动态分配第一维空间
FOR I IN 1..2 LOOP
b[I] := NEW VARCHAR[4]; --动态分配第二维空间
FOR J IN 1..4 LOOP
b[I][J] = I*10+J;
PRINT b[I][J];
END LOOP;
END LOOP;
END;
/
也可以一次性为多维动态数组分配空间,则上面的例子可以写为:
DECLARE
TYPE Arr1 IS ARRAY VARCHAR[,];
b ARR1;
BEGIN
b := NEW VARCHAR[2,4];
FOR I IN 1..2 LOOP
FOR J IN 1..4 LOOP
b[I][J]= I*10+J;
PRINT b[I][J];
END LOOP;
END LOOP;
END;
/
复杂类型数组
静态数据和动态数组中的<数据类型>除了支持普通数据类型,还支持复杂数据类型(数组、记录类型和集合类型)。本节以具体的示例展示复杂类型数组的用法。
例 1 定义一个自定义类型(OBJECT 类型)的静态数组,存放图书的序号和名称。
CREATE OR REPLACE TYPE SYSDBA.COMPLEX AS OBJECT(
RPART INT,
IPART VARCHAR(100)
);
/
DECLARE
TYPE ARR_COMPLEX IS ARRAY SYSDBA.COMPLEX[3];
arr ARR_COMPLEX;
BEGIN
FOR I IN 1..3 LOOP
SELECT SYSDBA.COMPLEX(PRODUCTID, NAME) INTO arr[I] FROM PRODUCTION.PRODUCT
WHERE PRODUCTID=I;
PRINT arr[I].RPART || arr[I].IPART;
END LOOP;
END;
/
也可以将上例中的对象类型改为记录类型,则 DMSQL 程序可写为:
DECLARE
TYPE REC IS RECORD(ID INT, NAME VARCHAR(128));
TYPE REC_ARR IS ARRAY REC[3];
arr REC_ARR;
BEGIN
FOR I IN 1..3 LOOP
SELECT PRODUCTID, NAME INTO arr[I] FROM PRODUCTION.PRODUCT WHERE PRODUCTID=I;
PRINT arr[I].ID || arr[I].NAME;
END LOOP;
END;
/
例 2 定义一个集合类型(以 VARRAY 为例)的数组,将员工的姓名、性别和职位信息存放到数组变量中。
DECLARE
TYPE VARY IS VARRAY(3) OF varchar(100);
TYPE ARR_VARY IS ARRAY VARY[8];
arr ARR_VARY;
v1,v2,v3 varchar(50);
BEGIN
FOR I IN 1..8 LOOP
SELECT NAME,PERSON.SEX,TITLE INTO v1,v2,v3 FROM PERSON.PERSON,RESOURCES.EMPLOYEE
WHERE PERSON.PERSONID=EMPLOYEE.PERSONID AND PERSON.PERSONID=I;
arr[I] := VARY(v1,v2,v3);
PRINT '*****工号'||I||'*****';
FOR J IN 1..3 LOOP
PRINT arr[I][J];
END LOOP;
END LOOP;
END;
/
集合类型
DMSQL 程序支持三种集合类型:VARRAY 类型、索引表类型和嵌套表类型
VARRAY
VARRAY 是一种具有可伸缩性的数组,数组中的每个元素具有相同的数据类型。
VARRAY 在定义时通过<数组长度>由用户指定一个最大容量,其元素索引是从 1 开始的有序数字。
语法:
TYPE<数组名> IS VARRAY( < 数组长度 > ) OF <数据类型> [NOT NULL];
参数说明:
<数组长度>即数组中元素的最大个数,正整数。
<数据类型>是 VARRAY 中元素的数据类型。类型可以是:1.常规数据类型;2.自定义类型。
在定义了一个 VARRAY 数组类型后,再声明一个该数组类型的变量,就可以对这个数组变量进行操作了。如下面的代码片段所示:
TYPE my_array_type IS VARRAY(10) OF INTEGER;
v MY_ARRAY_TYPE;
使用 v.COUNT()方法可以得到数组 v 当前的实际大小,v.LIMIT()则可获得数组 v 的最大容量。
需要注意的是,VARRAY 的元素索引总是连续的。
例 1 下面使用常规类型 VARCHAR 进行举例。查询人员姓名并将其存入一个 VARRAY 变量中。VARRAY 最初的实际大小为 0,使用 EXCTEND()方法可扩展 VARRAY 元素个数
DECLARE
TYPE MY_ARRAY_TYPE IS VARRAY(10) OF VARCHAR(100);
v MY_ARRAY_TYPE; --声明变量的类型
BEGIN
v:=MY_ARRAY_TYPE(); -- 用构造函数初始化变量
PRINT 'v.COUNT()=' || v.COUNT();
FOR I IN 1..8 LOOP
v.EXTEND();
SELECT NAME INTO v(I) FROM PERSON.PERSON WHERE PERSON.PERSONID=I;
END LOOP;
PRINT 'v.COUNT()=' || v.COUNT();
FOR I IN 1..v.COUNT() LOOP
PRINT 'v(' || i || ')=' ||v(i);
END LOOP;
END;
/
例 2 下面使用自定义类型 RECORD 进行举例
CREATE TYPE REC IS RECORD(ID INT, NAME VARCHAR(1280));
/
DECLARE
TYPE REC_ARR IS varray(30) of rec;
arr REC_ARR;
BEGIN
arr:=REC_ARR();
FOR I IN 1..10 LOOP
arr.EXTEND();
SELECT PRODUCTID, NAME INTO arr[I] FROM PRODUCTION.PRODUCT WHERE PRODUCTID=I;
PRINT arr[I].ID || arr[I].NAME;
END LOOP;
END;
/
索引表
索引表提供了一种快速、方便地管理一组相关数据的方法。索引表是一组数据的集合,它将数据按照一定规则组织起来,形成一个可操作的整体,是对大量数据进行有效组织和管理的手段之一,通过函数可以对大量性质相同的数据进行存储、排序、插入及删除等操作,从而可以有效地提高程序开发效率及改善程序的编写方式。
索引表不需要用户指定大小,其大小根据用户的操作自动增长。
语法:
TYPE <索引表名> IS TABLE OF<数据类型> INDEX BY <索引数据类型>;
<数据类型>指索引表存放的数据的类型。类型可以是:1.常规数据类型;2.自定义类型(但不能是动态数组)。
<索引数据类型>则是索引表中元素索引的数据类型,DM 目前仅支持 INTEGER/INT 和VARCHAR 两种类型,分别代表整数索引和字符串索引。对于 VARCHAR 类型,长度不能超过 1024。
用户可使用“索引-数据”对向索引表插入数据,之后可通过“索引”修改和查询这个数据,而不需要知道数据在索引表中实际的位置。
一个非常简单的索引表的使用示例
DECLARE
TYPE Arr IS TABLE OF VARCHAR(100) INDEX BY INT; --定义索引表
x Arr; -- 声明
BEGIN
x(1) := 'TEST1';
x(2) := 'TEST2';
x(3) := x(1) || x(2);
PRINT x(3);
END;
/
索引表还可以用来管理记录,下面的例子索引表中存放的数据类型为 RECORD,展示了如何存入和遍历输出索引表的记录类型数据。
DECLARE
TYPE Rd IS RECORD(ID INT, NAME VARCHAR(128));
TYPE Arr IS TABLE OF Rd INDEX BY INT;
x Arr;
i INT;
CURSOR C1;
BEGIN
i := 1;
OPEN C1 FOR SELECT PERSONID, NAME FROM PERSON.PERSON;
//遍历结果集,把每行的值都存放入索引表中
LOOP
IF C1%NOTFOUND THEN
EXIT;
END IF;
FETCH C1 INTO x(i).ID, x(i).NAME;
i := i + 1;
END LOOP;
//遍历输出索引表中的记录
i = x."FIRST"();
LOOP
IF i IS NULL THEN
EXIT;
END IF;
PRINT 'ID:' || CAST(x(i).ID AS VARCHAR(10)) || ', NAME:' || x(i).NAME;
i = x."NEXT"(i);
END LOOP;
END;
/
下面的例子定义了一个二维索引表 x,展示了如何存入和遍历输出二维索引表的数据
DECLARE
TYPE Arr IS TABLE OF VARCHAR(100) INDEX BY BINARY_INTEGER;
TYPE Arr2 IS TABLE OF Arr INDEX BY VARCHAR(100);
x Arr2;
ind_i INT;
ind_j VARCHAR(10);
BEGIN
//存入数据
FOR I IN 1 .. 6 LOOP
FOR J IN 1 .. 3 LOOP
x(I)(J) := CAST(I AS VARCHAR(100)) || '+'||CAST(J AS VARCHAR(10));
END LOOP;
END LOOP;
//遍历多维数组
ind_i := x."FIRST"();
LOOP
IF ind_i IS NULL THEN
EXIT;
END IF;
ind_j := x(ind_i)."FIRST"();
LOOP
IF ind_j IS NULL THEN
EXIT;
END IF;
PRINT x(ind_i)(ind_j);
ind_j := x(ind_i)."NEXT"(ind_j);
END LOOP;
ind_i := x."NEXT"(ind_i);
END LOOP;
END;
/
嵌套表
嵌套表类似于一维数组,但与数组不同的是,嵌套表不需要指定元素的个数,其大小
可自动扩展。嵌套表元素的下标从 1 开始。
语法:
TYPE <嵌套表名> IS TABLE OF <元素数据类型> [NOT NULL];
<元素数据类型>用来指明嵌套表元素的数据类型,当元素数据类型为一个定义了某个表记录的对象类型时,嵌套表就是某些行的集合,实现了表的嵌套功能。
下面的例子定义了一个嵌套表,其结构与 SALES.SALESPERSON 表相同,用来存放今年销售额大于 1000 万的销售代表的信息。
DECLARE
TYPE Info_t IS TABLE OF SALES.SALESPERSON%ROWTYPE;
info Info_t;
BEGIN
SELECT SALESPERSONID,EMPLOYEEID,SALESTHISYEAR,SALESLASTYEAR BULK COLLECT INTO info
FROM SALES.SALESPERSON WHERE SALESTHISYEAR>1000;
END;
/
指定元素数据类型的时候也可用使用对象类型
--创建对象,执行如下SQL命令
CREATE OR REPLACE TYPE TYP_FUT_ZDY_QTB
as object
(
AAZ257 NUMBER(18),
bic230 VARCHAR2(5),
constructor function TYP_FUT_ZDY_QTB return self as result
)
not final;
CREATE OR REPLACE TYPE BODY TYP_FUT_ZDY_QTB
is
constructor function TYP_FUT_ZDY_QTB return self as result is
begin
return;
end;
end;
--创建嵌套表,执行如下SQL命令
CREATE OR REPLACE TYPE TYP_OBJ_FUT_ZDY_QTB as table OF TYP_FUT_ZDY_QTB;
集合类型支持的方法
DM 为 VARRAY、索引表和嵌套表提供了一些方法,用户可以使用这些方法访问和修改
集合与集合元素
COUNT
语法:
<集合变量名>.COUNT
返回集合中元素的个数
LIMIT
语法:
<VARRAY 变量名>.LIMIT
返回 VARRAY 集合的最大的元素个数,对索引表和嵌套表不适用
FIRST
语法:
<集合变量名>.FIRST
返回集合中的第一个元素的下标号,对于 VARRAY 集合始终返回 1(为什么)
LAST
语法:
<集合变量名>.LAST
返回集合中最后一个元素的下标号,对于 VARRAY 返回值始终等于 COUNT
NEXT
语法:
<集合变量名>.NEXT(<下标>)
参数:指定的元素下标。
返回在指定元素 i 之后紧挨着它的元素的下标号,如果指定元素是最后一个元素,则返回 NULL
PRIOR
语法:
<集合变量名>.PRIOR(<下标>)
参数:指定的元素下标。
返回在指定元素 i 之前紧挨着它的元素的下标号,如果指定元素是第一个元素,则返回NULL
EXISTS
语法:
<集合变量名>.EXISTS(<下标>)
如果指定下标对应的元素已经初始化,则返回 TRUE,否则返回 FALSE
DELETE
语法:
<集合变量名>.DELETE([<下标>])
参数:待删除元素的下标。
下标参数省略时删除集合中所有元素,否则删除指定下标对应的元素,如果指定下标为 NULL,则集合保持不变。VARRAY 类型不支持指定索引下标的 DELETE 方法。
DELETE
语法:
<集合变量名>.DELETE(<下标 1>, <下标 2>)
参数:
下标 1:要删除的第一个元素的下标;
下标 2:要删除的最后一个元素的下标。
删除集合中下标从下标 1 到下标 2 的所有元素。VARRAY 类型不支持指定索引下标的DELETE 方法
TRIM
语法:
<集合变量名>.TRIM([<n>])
参数:删除元素的个数。
n 参数省略时从集合末尾删除一个元素,否则从集合末尾开始删除 n 个元素。本方法不适用于索引表。
EXTEND
语法:
<集合变量名>.EXTEND([<n>])
参数:扩展元素的个数。
n 参数省略时在集合末尾扩展一个空元素,否则在集合末尾扩展 n 个空元素。本方法不适用于索引表。
EXTEND
语法:
<集合变量名>.EXTEND(<n>,<下标>])
参数:
n:扩展元素的个数;
下标:待复制元素的下标。
功能:
在集合末尾扩展 n 个与指定下标元素相同的元素。本方法不适用于索引表。
MEMBER OF
语法:
<待判断元素> MEMBER OF <集合变量名>
参数:
待判断的元素:可以是变量,也可以是常量。
功能:
判断给定元素是否存在于集合中,若存在则返回 TRUE,否则返回 FALSE,一般用作 IF
语句中的布尔判断。本方法不适用于索引表。
NOT MEMBER OF
语法:
<待判断元素> NOT MEMBER OF <集合变量名>
判断给定元素是否不存在于集合中,若不存在则返回 TRUE,否则返回 FALSE,一般用
作 IF 语句中的布尔判断。本方法不适用于索引表。
MULTISET UNION
语法:
<集合变量名 1> MULTISET UNION [ALL | DISTINCT | UNIQUE] <集合变量名 2>
计算两个集合的并集。若指定 ALL 关键字,则不去重;若指定 DISTINCT 或 UNIQUE 关键字,则去重,即去除结果集中的重复项。缺省为不去重。
本方法仅适用于嵌套表
MULTISET INTERSECT
语法:
<集合变量名 1> MULTISET INTERSECT [ALL | DISTINCT | UNIQUE] <集合变量名 2>
计算两个集合的交集。ALL 为缺省设置,当集合 1 有 M 个重复项,集合 2 有 N 个重复项时,返回 min(M,N)个重复项;DISTINCT 和 UNIQUE 表示去除结果集中的重复项。
本方法仅适用于嵌套表
MULTISET EXCEPT
语法:
<集合变量名 1> MULTISET EXCEPT [ALL | DISTINCT | UNIQUE] <集合变量名 2>
计算集合 1 和集合 2 的差集,即集合 1 中存在但集合 2 中不存在的元素集合。ALL 为缺省设置,表示返回所有集合 1 中存在但集合 2 中不存在的元素;DISTINCT 和 UNIQUE 表示去除结果集中的重复项。
本方法仅适用于嵌套表
创建类型体
重编译类型
--编译类型,执行如下SQL命令
ALTER TYPE TYPE_FUT_ZDY_DXLX COMPILE;
删除类型
删除类型
--删除类型,执行如下SQL命令
DROP TYPE TYPE_FUT_ZDY_DXLX ;
删除类型体
--删除类型体,执行如下SQL命令
DROP TYPE BODY TYPE_FUT_ZDY_DXLX ;
参考:
https://eco.dameng.com/

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)