2.2.9 hadoop体系之离线计算-mapreduce分布式计算-流量统计之手机号码分区
目录1.需求分析2.代码方案2.1 自定义分区2.2 JobMain添加分区设置2.3 分区结果1.需求分析在需求一的基础上,继续完善,将不同的手机号分到不同的数据文件的当中去,需要自定 义分区来实现,这里我们自定义来模拟分区,将以下数字开头的手机号进行分开135 开头的数据到一个分区文件136开头的数据到一个分区文件137开头的数据到一个分区文件其他数据到一个分区文件2.代码方案2.1 自定义分
·
目录
1.需求分析
在需求一的基础上,继续完善,将不同的手机号分到不同的数据文件的当中去,需要自定 义分区来实现,这里我们自定义来模拟分区,将以下数字开头的手机号进行分开
- 135 开头的数据到一个分区文件
- 136开头的数据到一个分区文件
- 137开头的数据到一个分区文件
- 其他数据到一个分区文件
2.代码方案
2.1 自定义分区
package ucas.mapreduce_flowcount_partitioner;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class FlowPartition extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int i) {
String line = text.toString();
if (line.startsWith("135")) {
return 0;
} else if (line.startsWith("136")) {
return 1;
} else if (line.startsWith("137")) {
return 2;
} else {
return 3;
}
}
}2.2 JobMain添加分区设置
job.setPartitionerClass(FlowPartition.class);
package ucas.mapreduce_flowcount_partitioner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
//创建一个任务对象
Job job = Job.getInstance(super.getConf(), "mapreduce_flowcount");
//打包放在集群运行时,需要做一个配置
job.setJarByClass(JobMain.class);
//第一步:设置读取文件的类: K1 和V1
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://192.168.0.101:8020/input/flowcount"));
//第二步:设置Mapper类
job.setMapperClass(FlowCountMapper.class);
//设置Map阶段的输出类型: k2 和V2的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//第三,四,五,六步采用默认方式(分区,排序,规约,分组)
job.setPartitionerClass(FlowPartition.class);
//第七步 :设置文的Reducer类
job.setReducerClass(FlowCountReducer.class);
//设置Reduce阶段的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//设置Reduce的个数
//第八步:设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出的路径
TextOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.101:8020/out/flowcount_out"));
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动一个任务
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
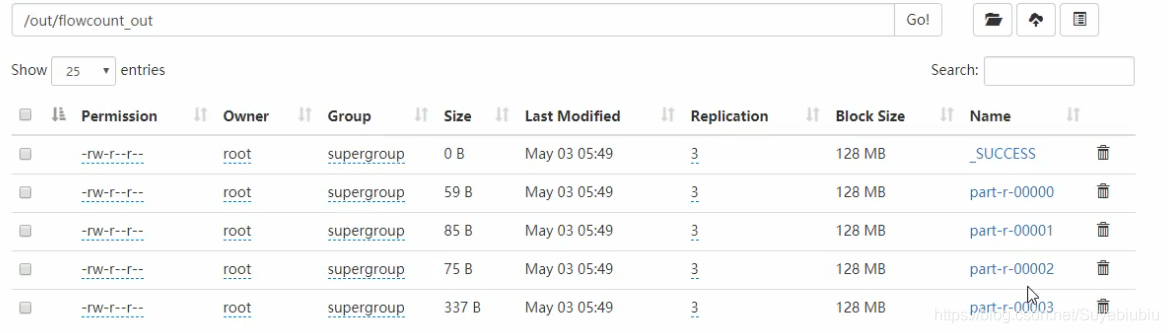
2.3 分区结果

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)