李宏毅 机器学习回归、分类、聚类、异常检测视频笔记
线性回归1.ModelA set of function一组函数2.Goodness of Function评价函数损失函数 L:输入:函数,输出:衡量模型how bad is3.Bset Funcion挑选最好的函数梯度下降:可微分,找到合适的loss函数衡量error关注测试集误差过拟合隐藏因素独热编码其他隐藏因素正则化b上下平滑,不影响结论where does the error come
https://www.bilibili.com/video/BV164411b7dx?p=90
线性回归
1.Model
A set of function一组函数
2.Goodness of Function评价函数
损失函数 L:
输入:函数,输出:衡量模型how bad is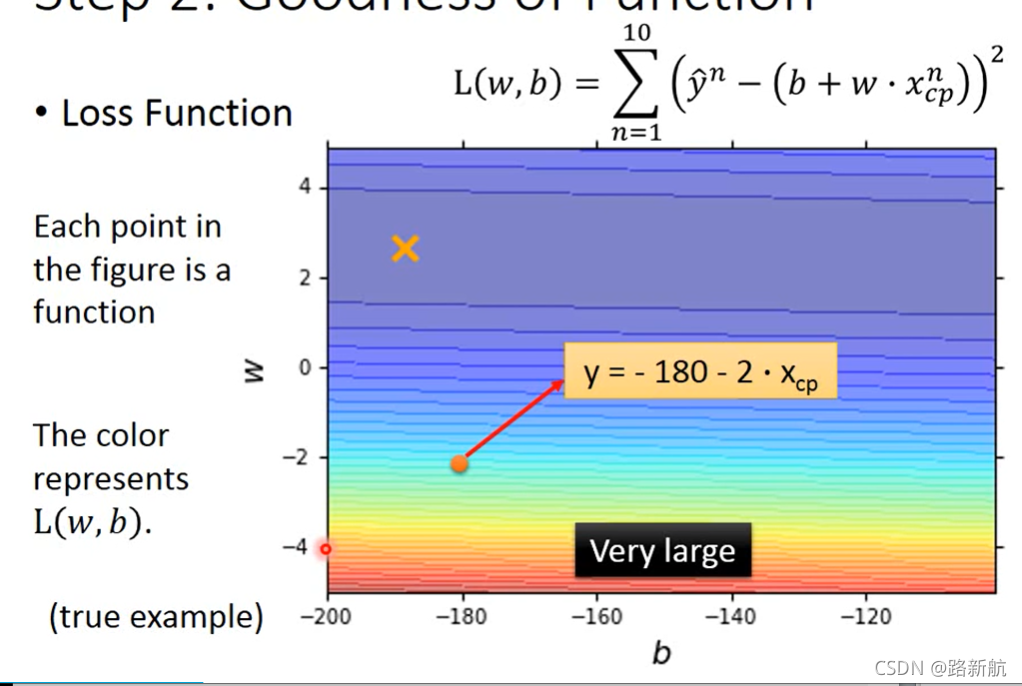
3.Bset Funcion挑选最好的函数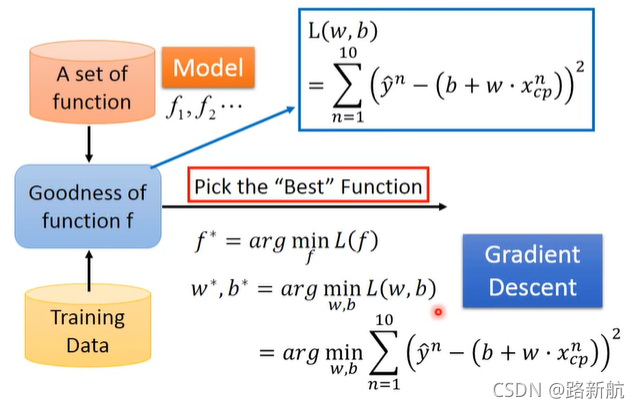
梯度下降:可微分,找到合适的loss函数

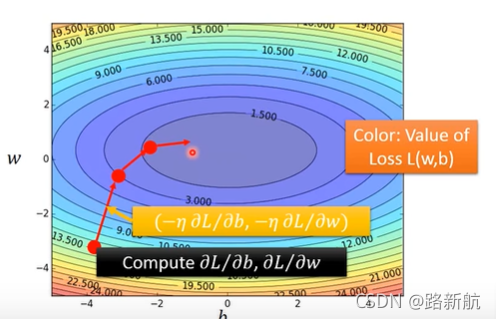
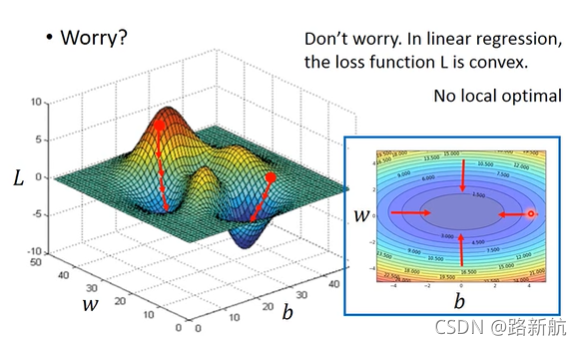

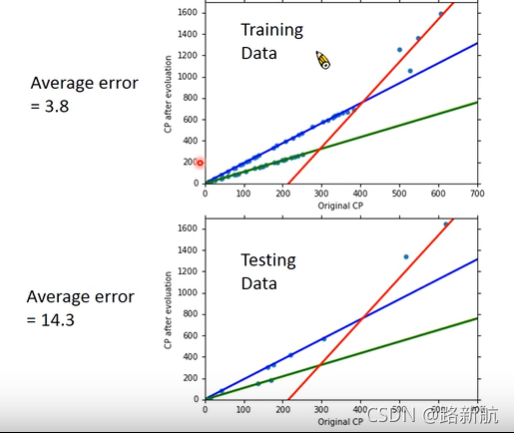
衡量error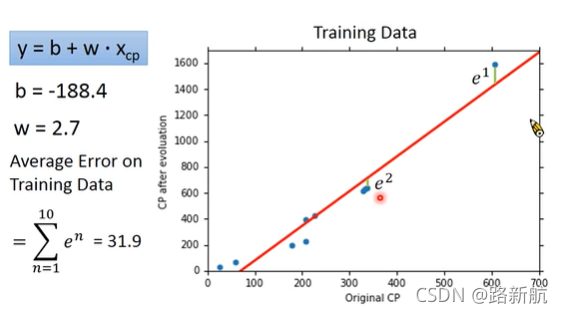
关注测试集误差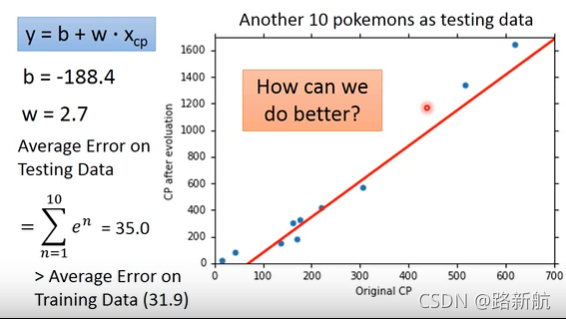
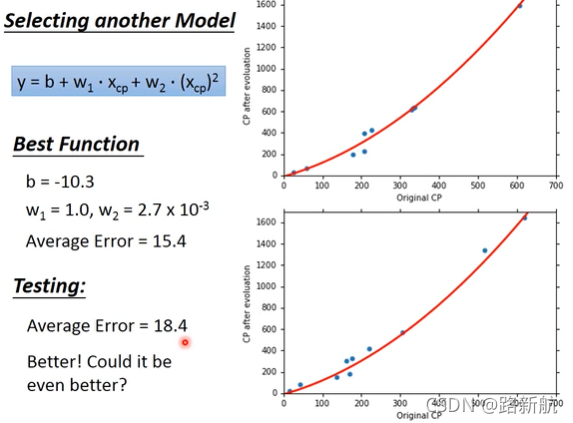
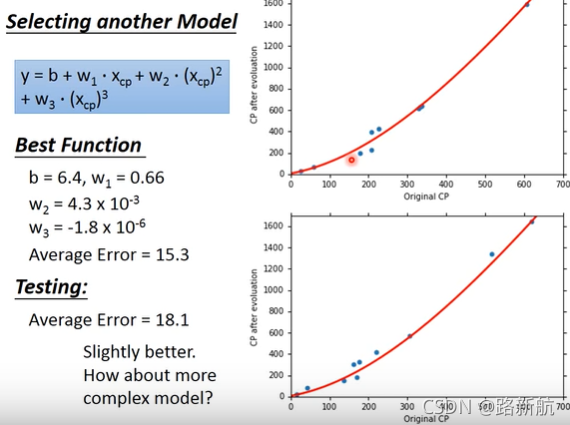
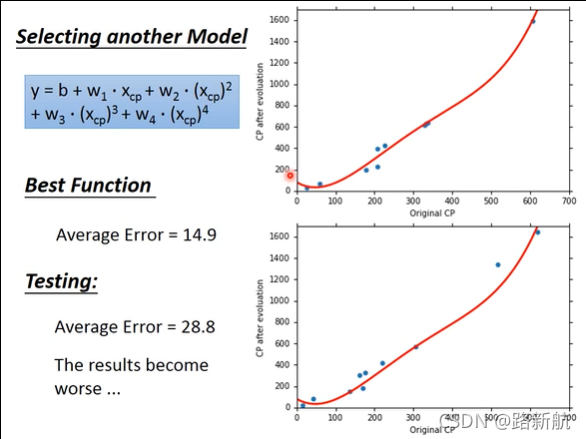
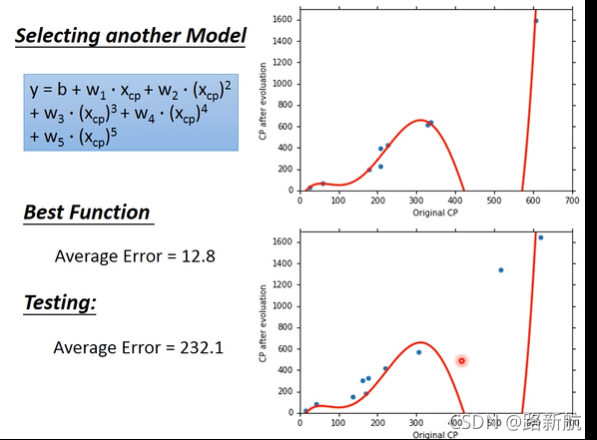
过拟合
隐藏因素

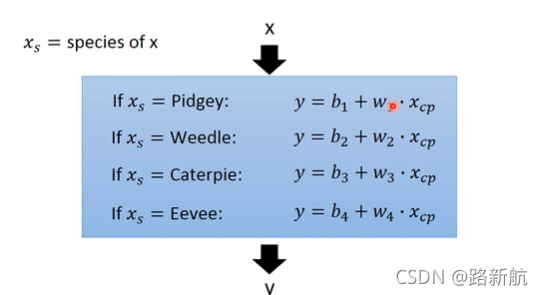
独热编码
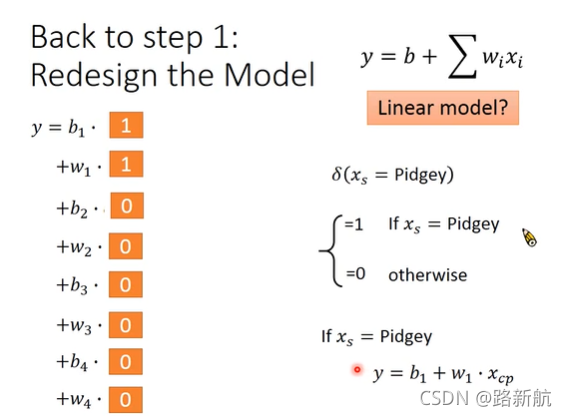
其他隐藏因素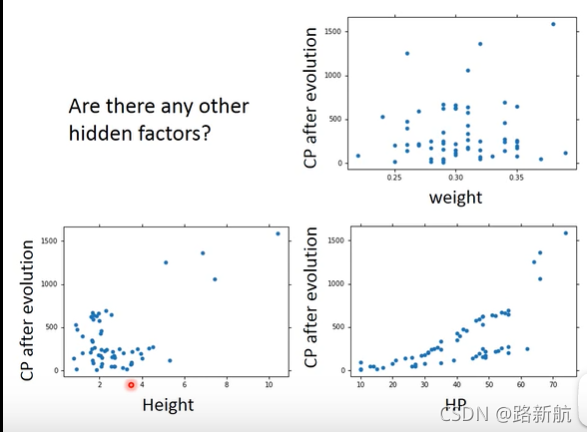

正则化

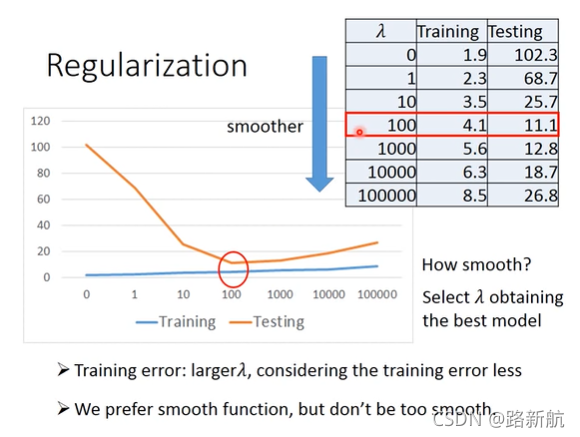
b上下平滑,不影响
结论

where does the error come from
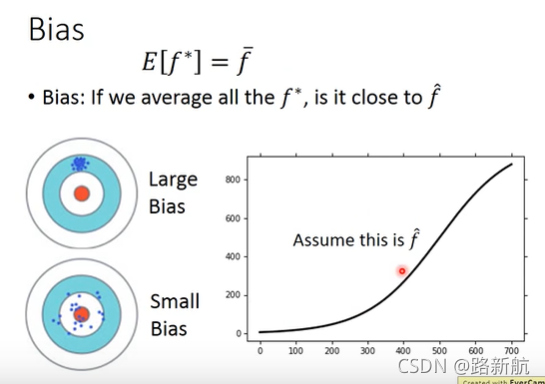
Estimator评估器



偏差和方差
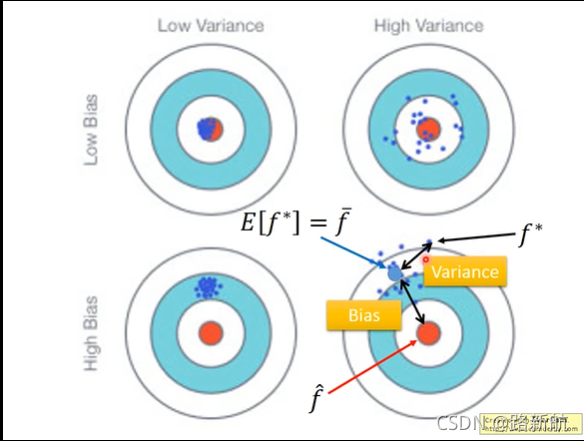
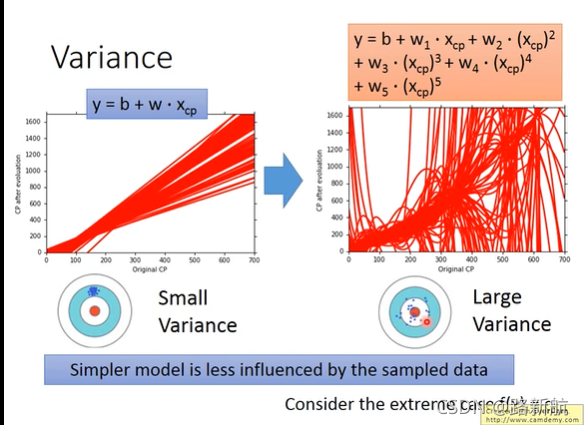
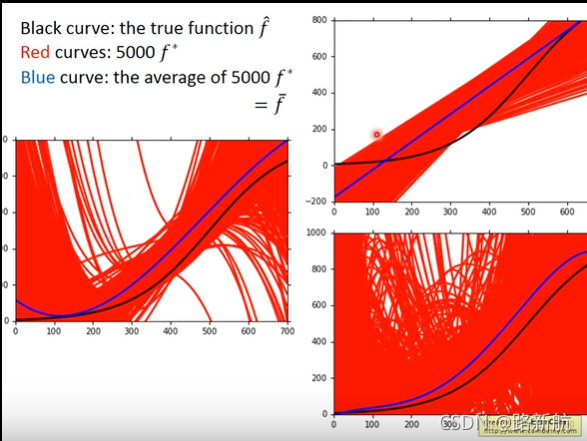
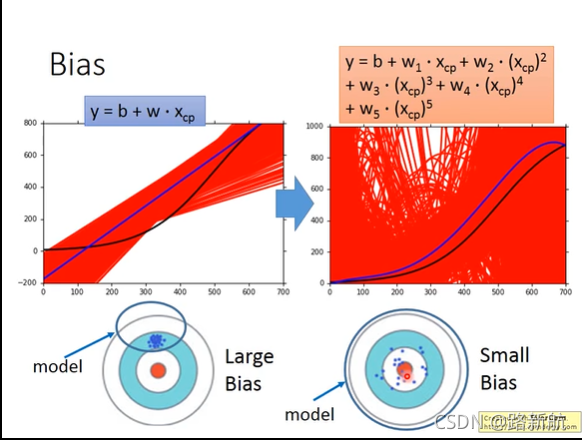
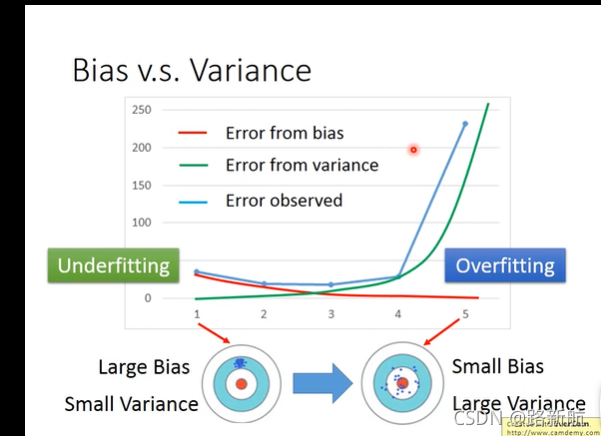
bias大欠拟合-重新设计模型,选择更复杂模型
variance大过拟合-增加数据量、正则化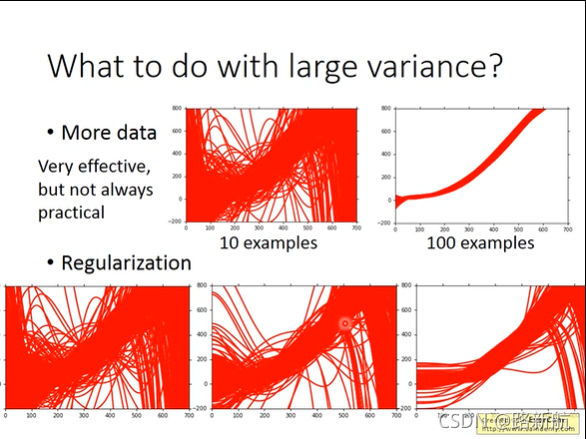
model selection

交叉验证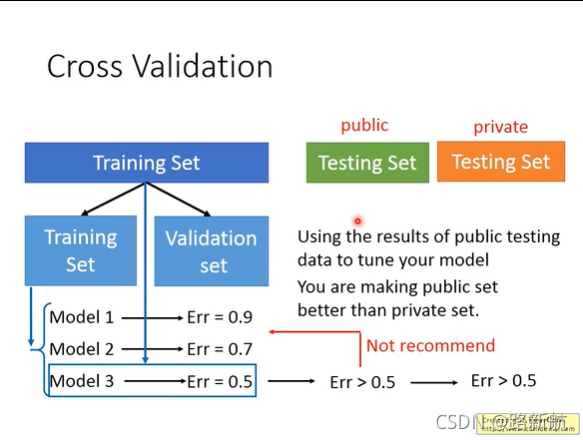
K折交叉验证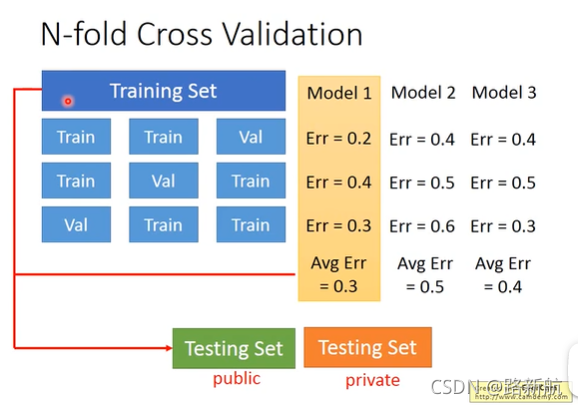
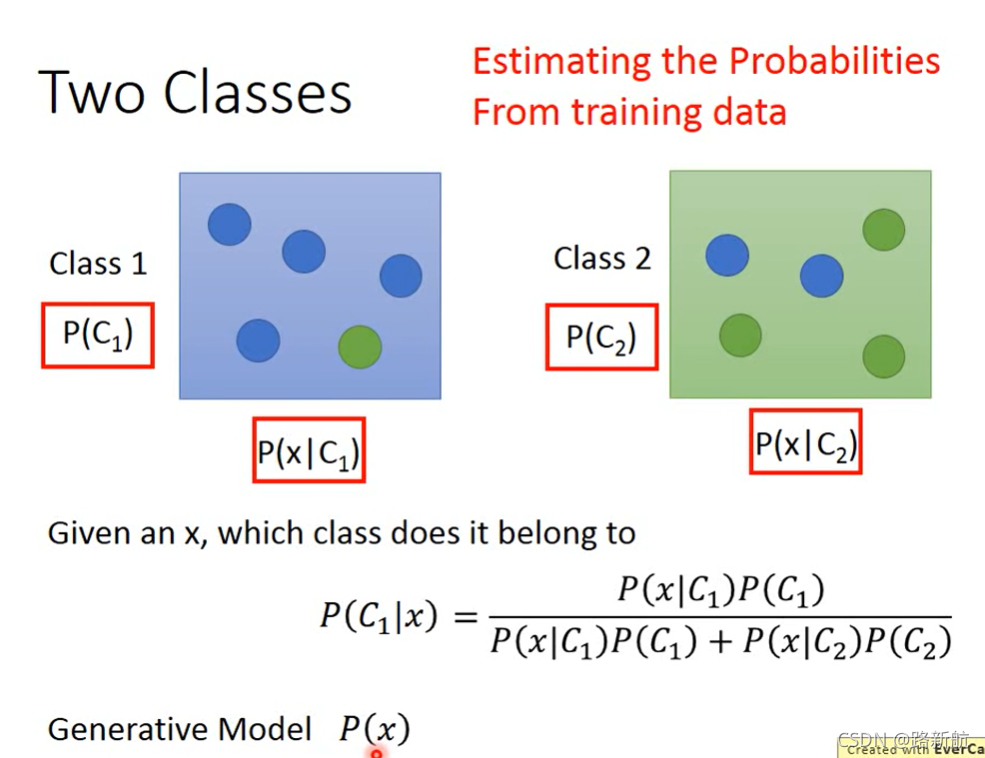
分类

 后置概率
后置概率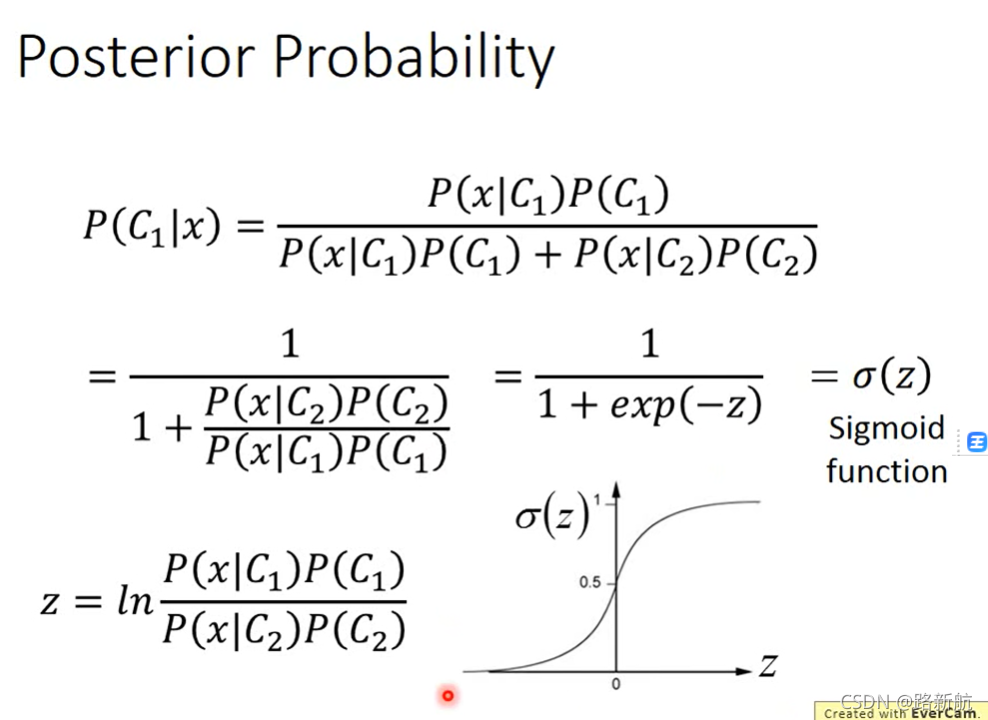

使用回归做分类
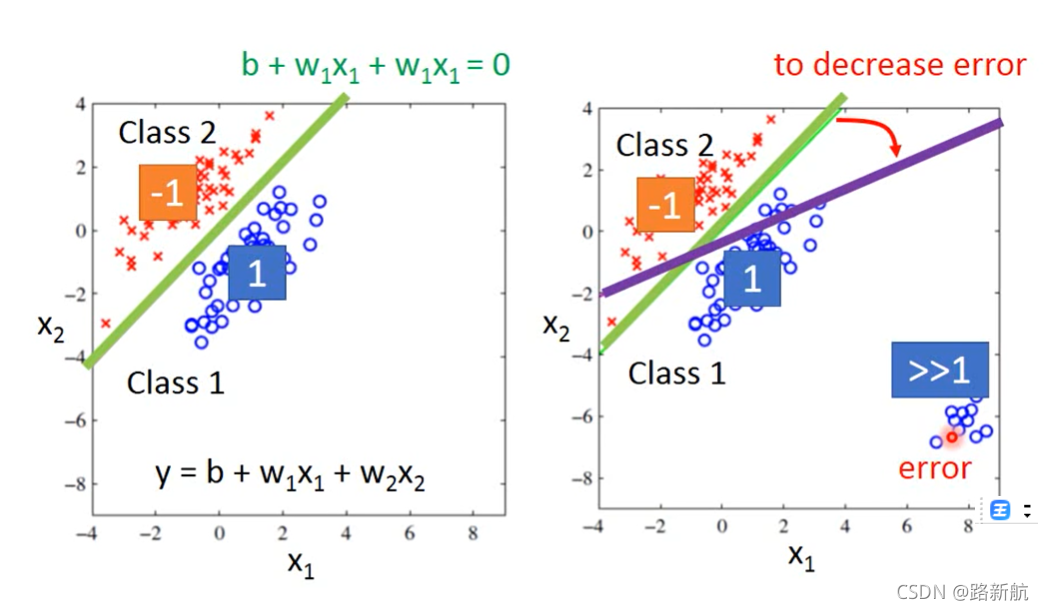

loss function:
分类错误的次数
高斯分布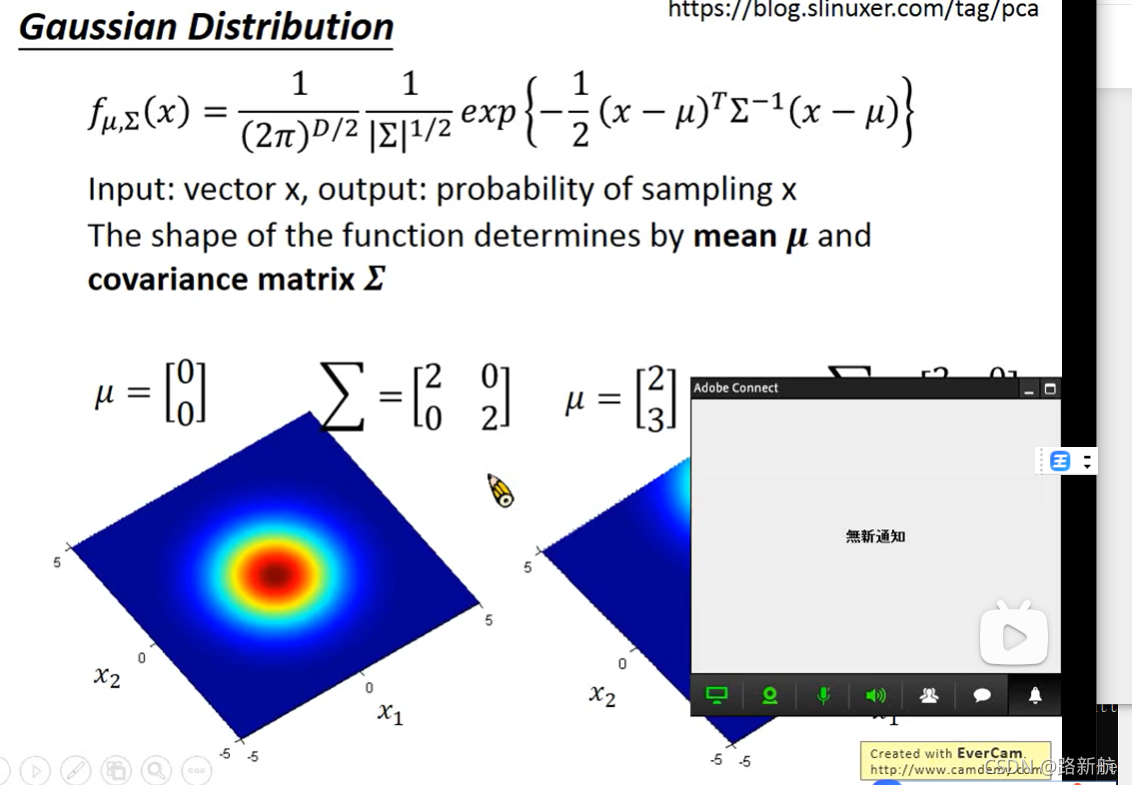
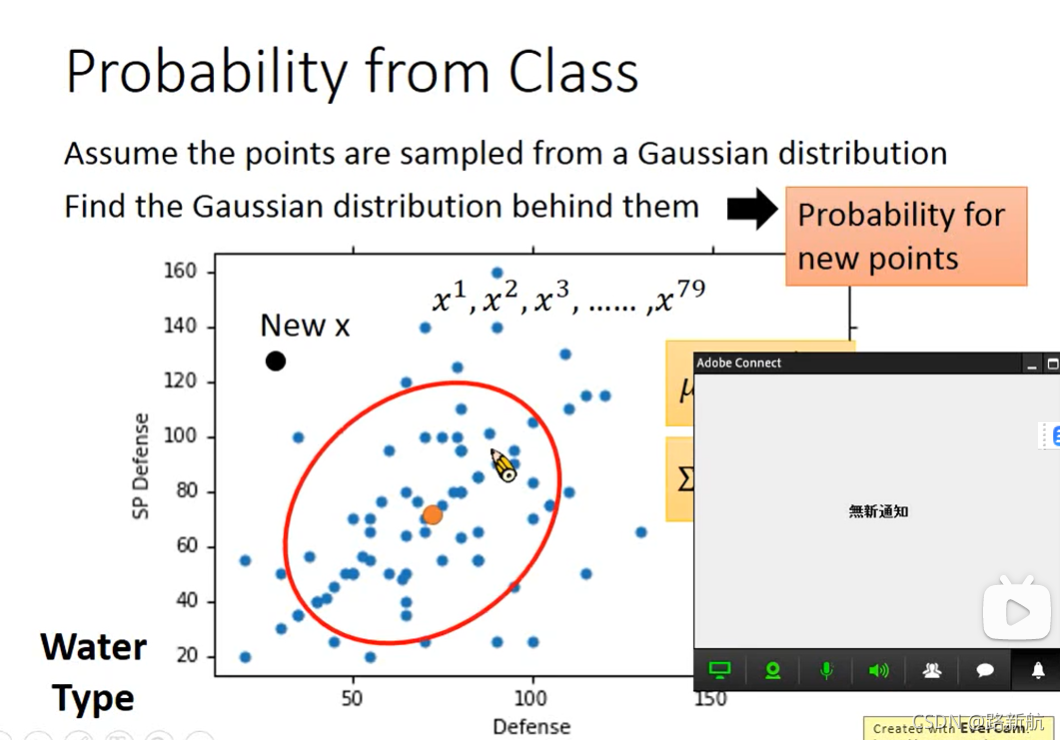
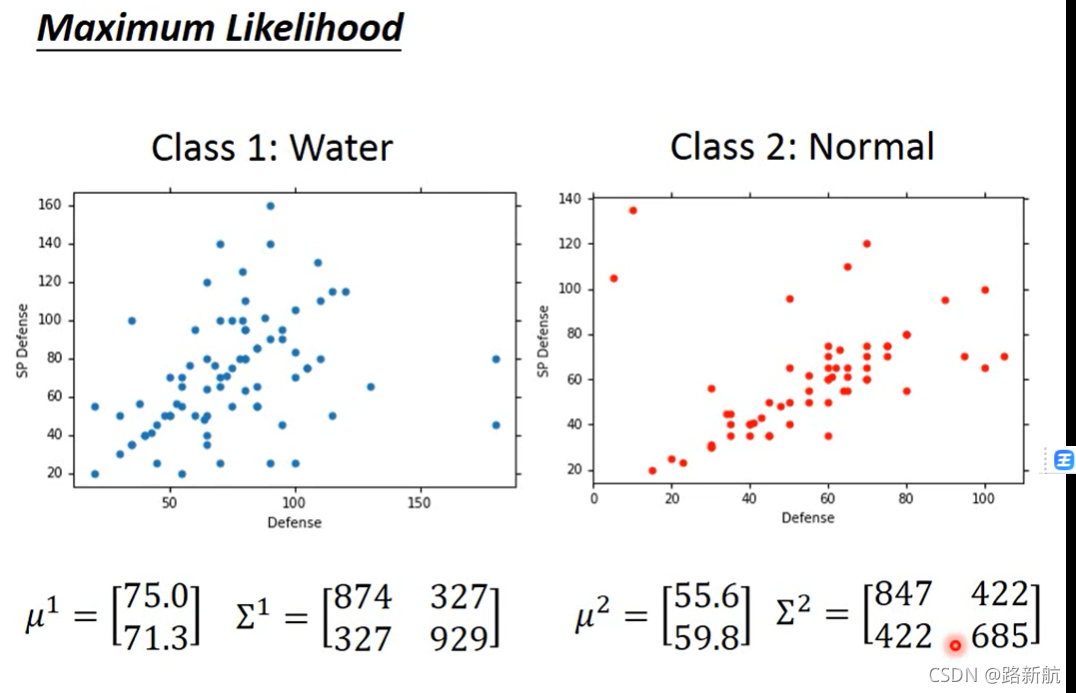
极大似然函数maximun likelihood

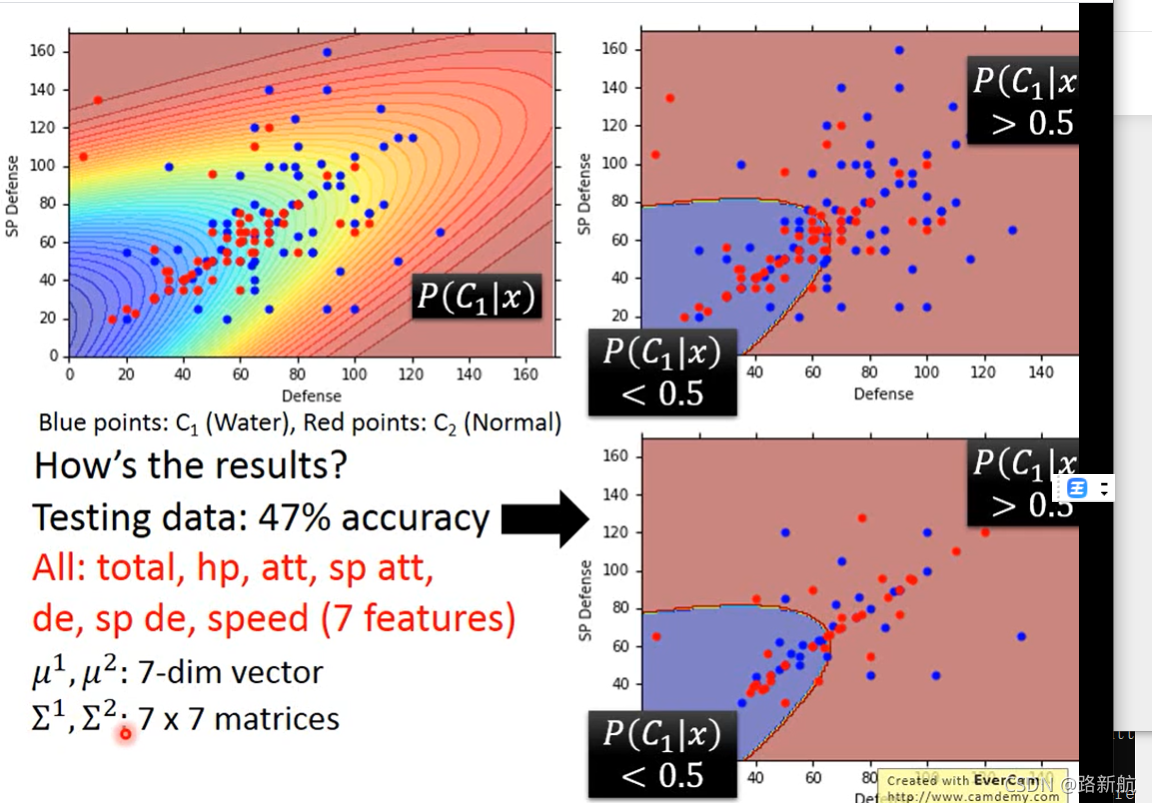
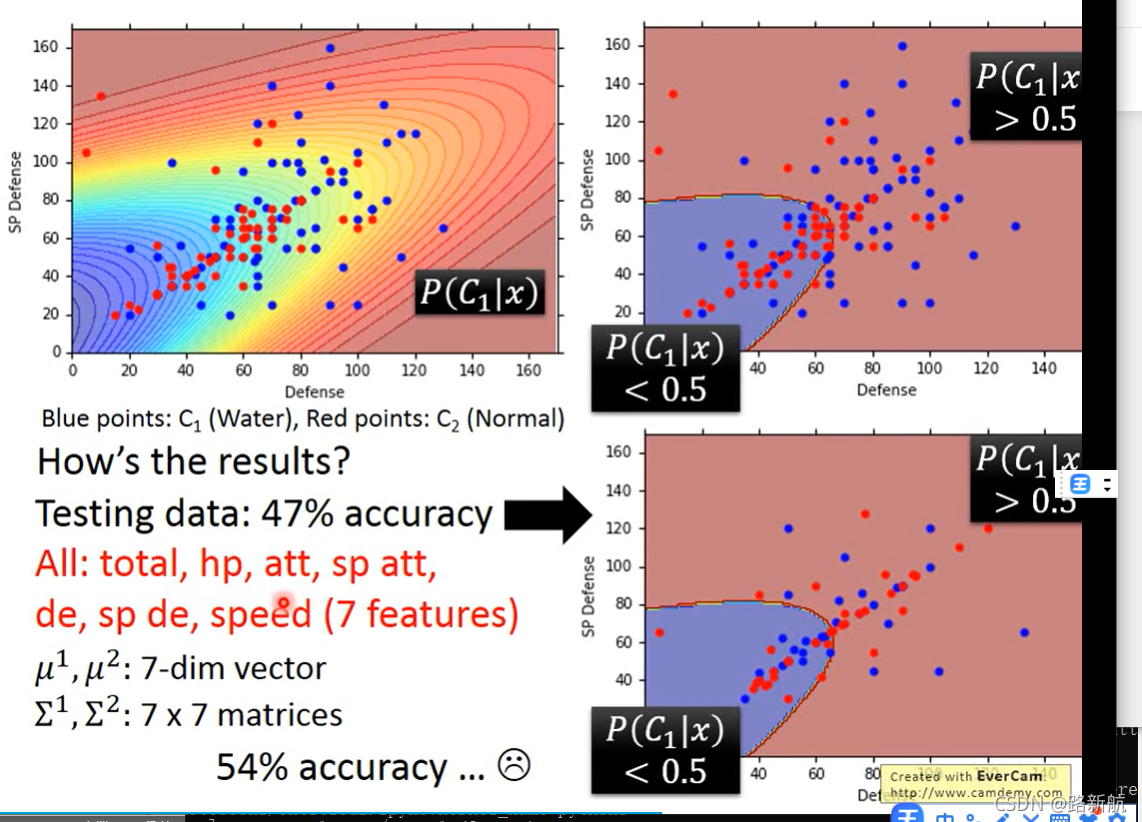
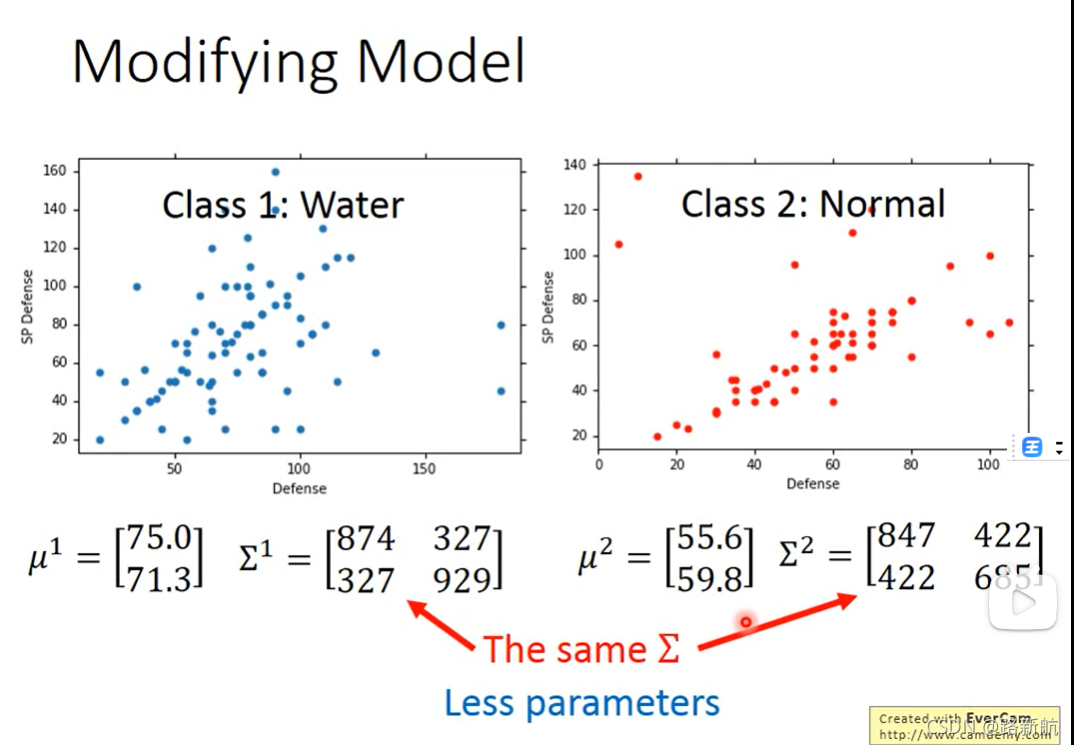
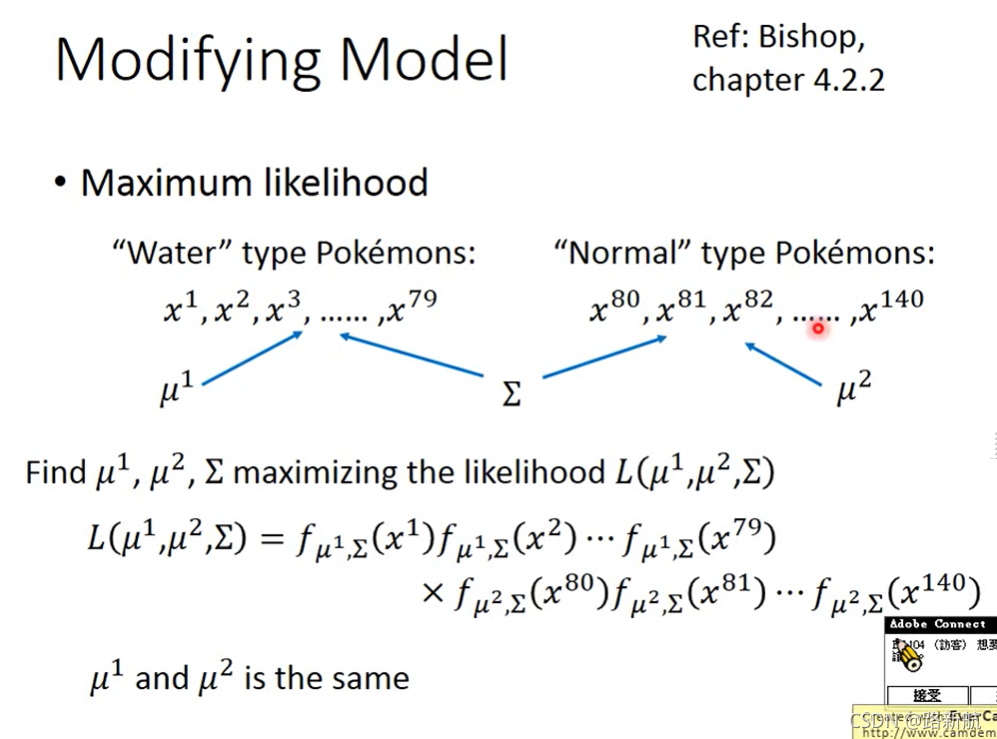

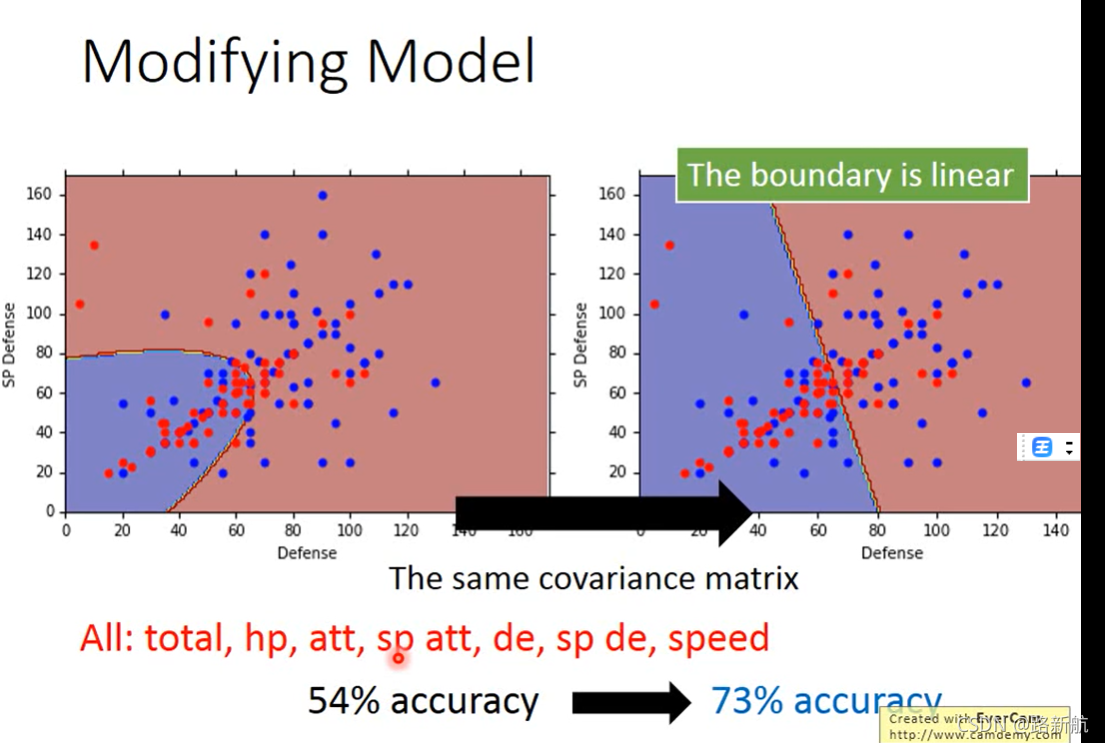
逻辑回归

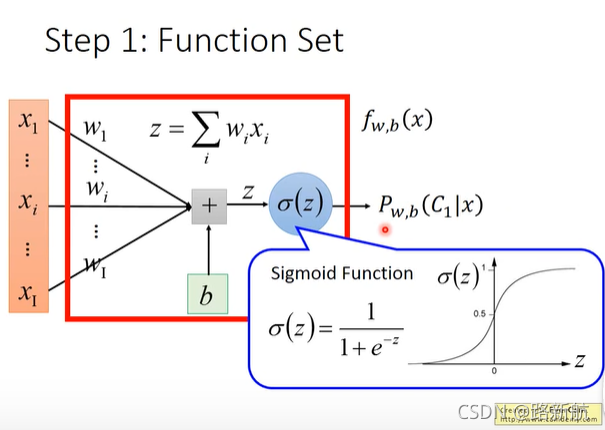






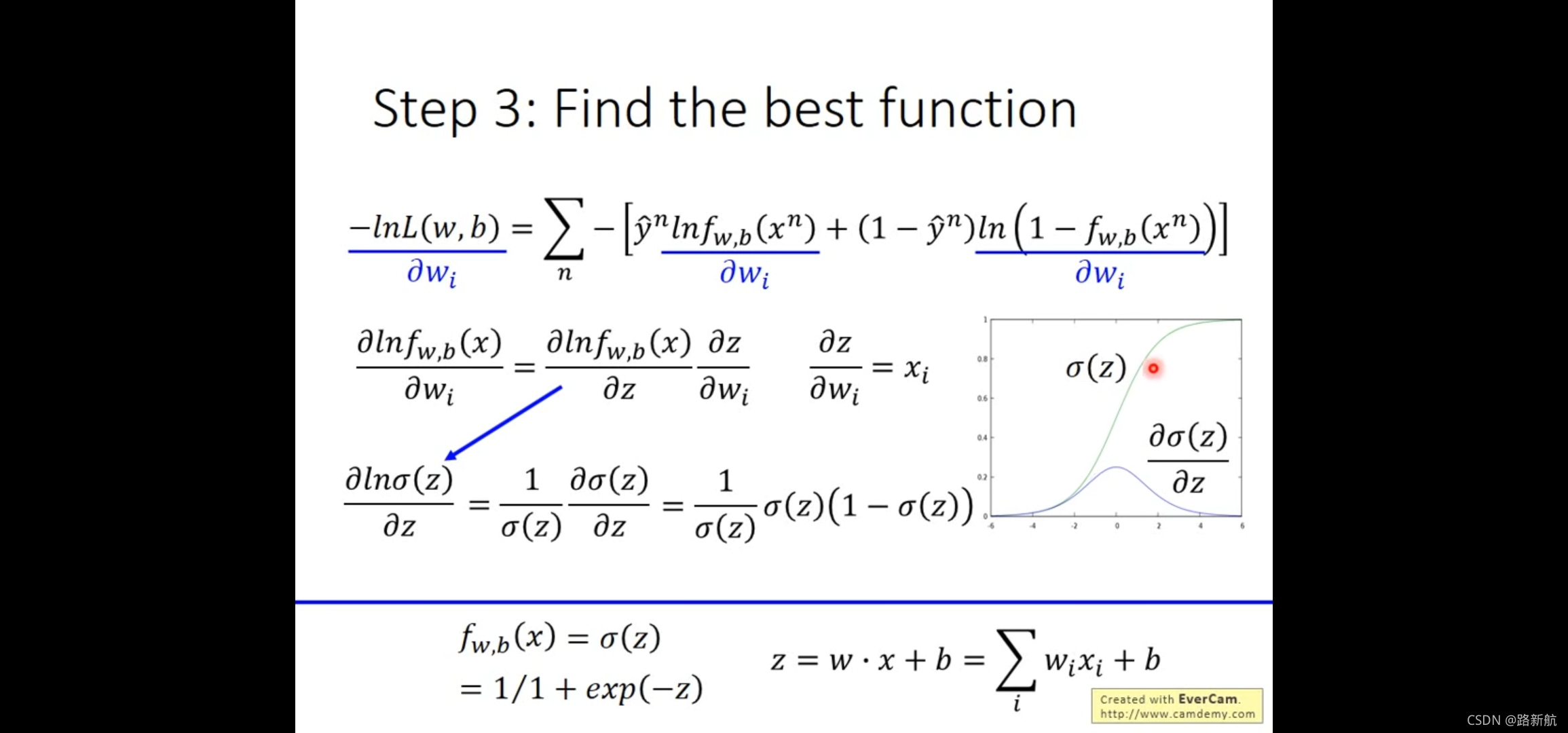

MSE与logistic函数作为loss对分类影响

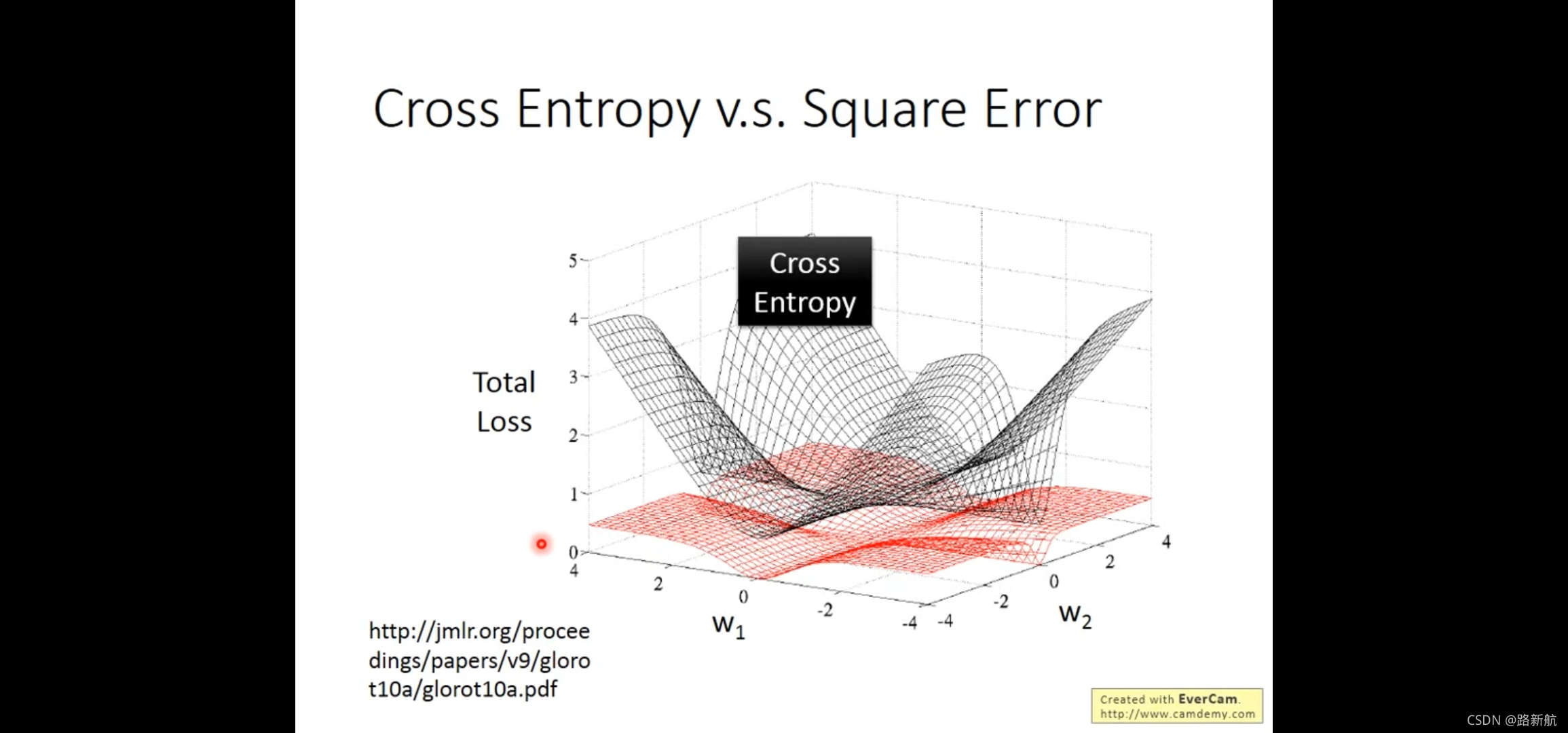
高斯分布 Generative 假设
logistic Discriminative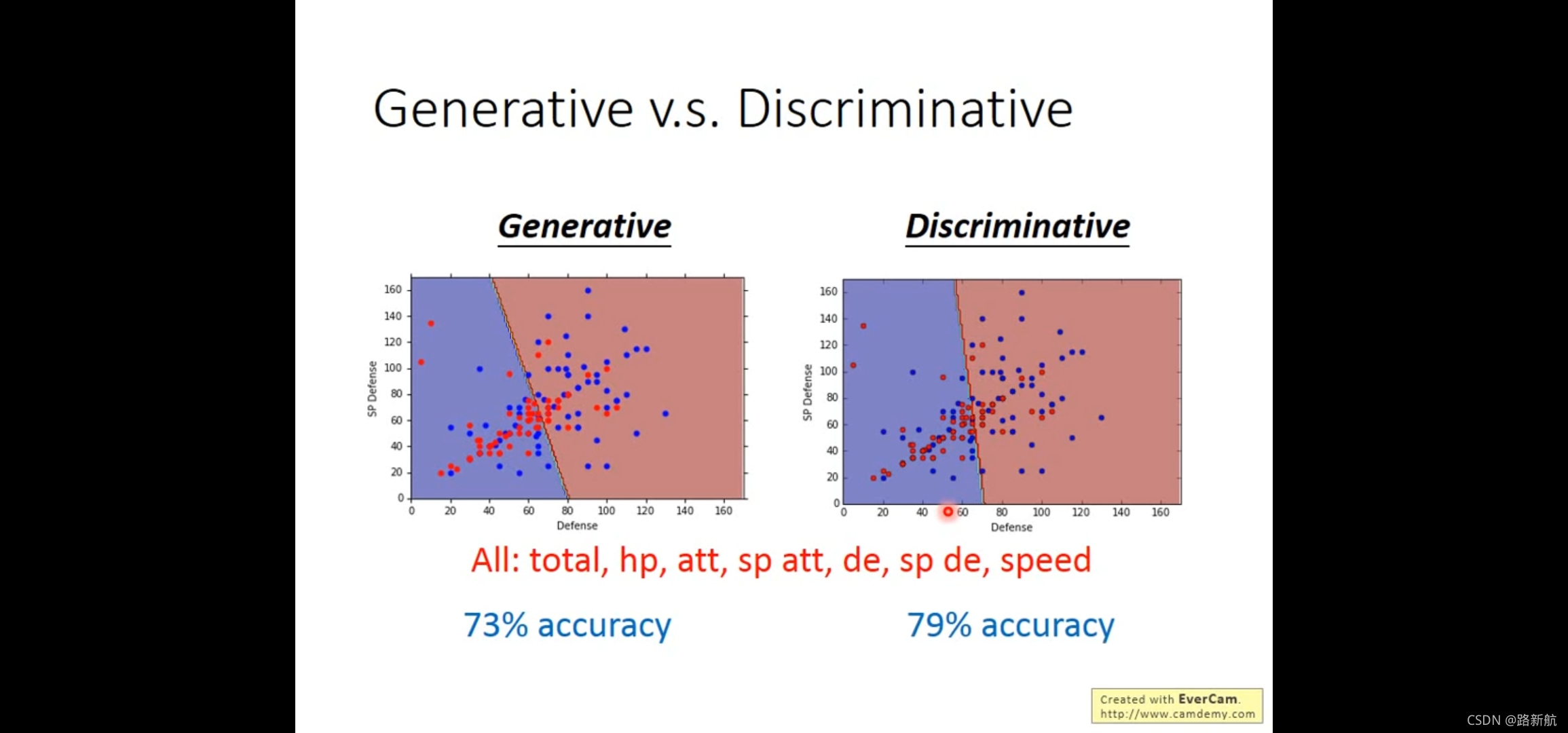
生成模型 vs Discriminative
生成模型优势:
需要更少数据
对噪音不敏感,更健壮
前置和类别可能性拆开可能性,可以来自不同来源
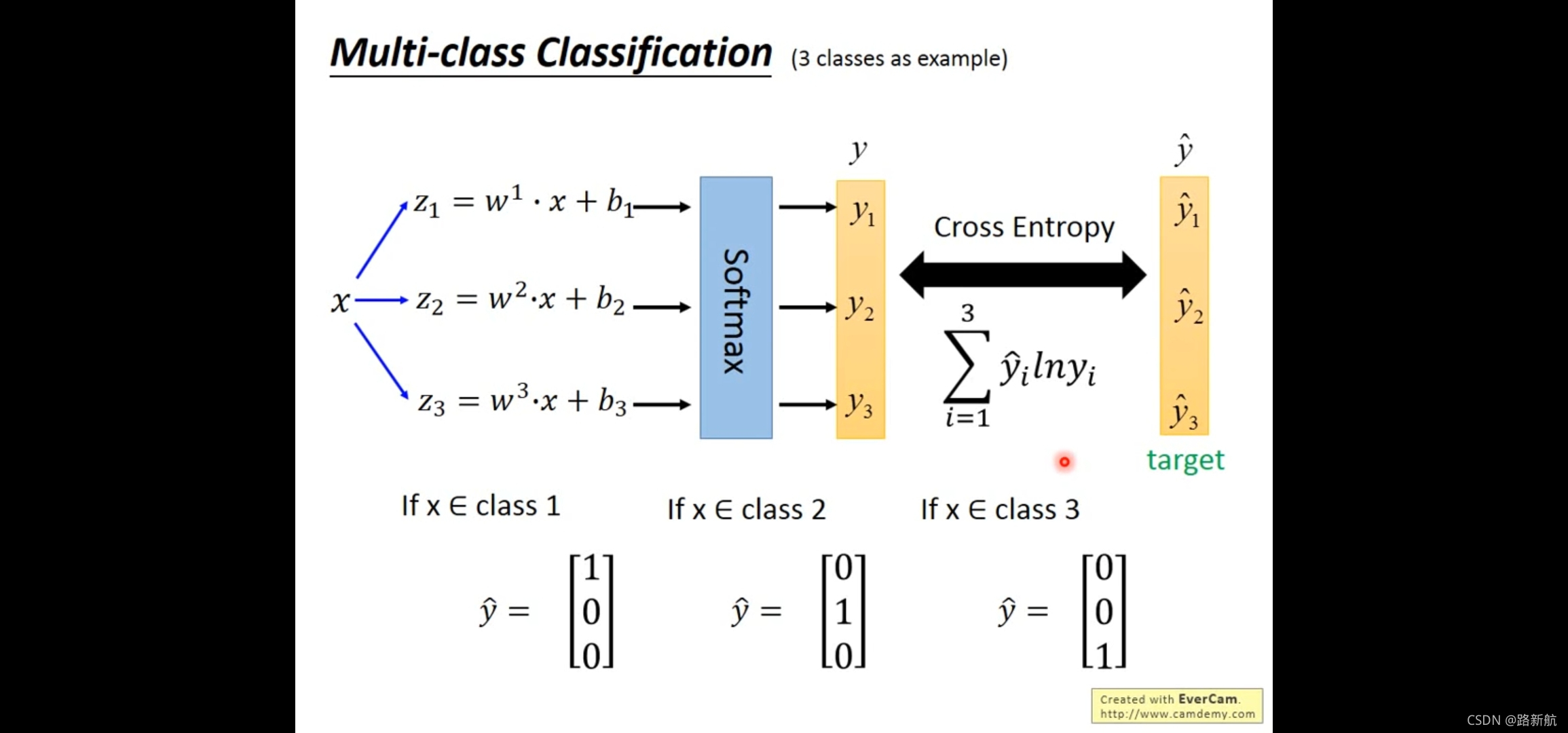
多类
每个类的概率和为1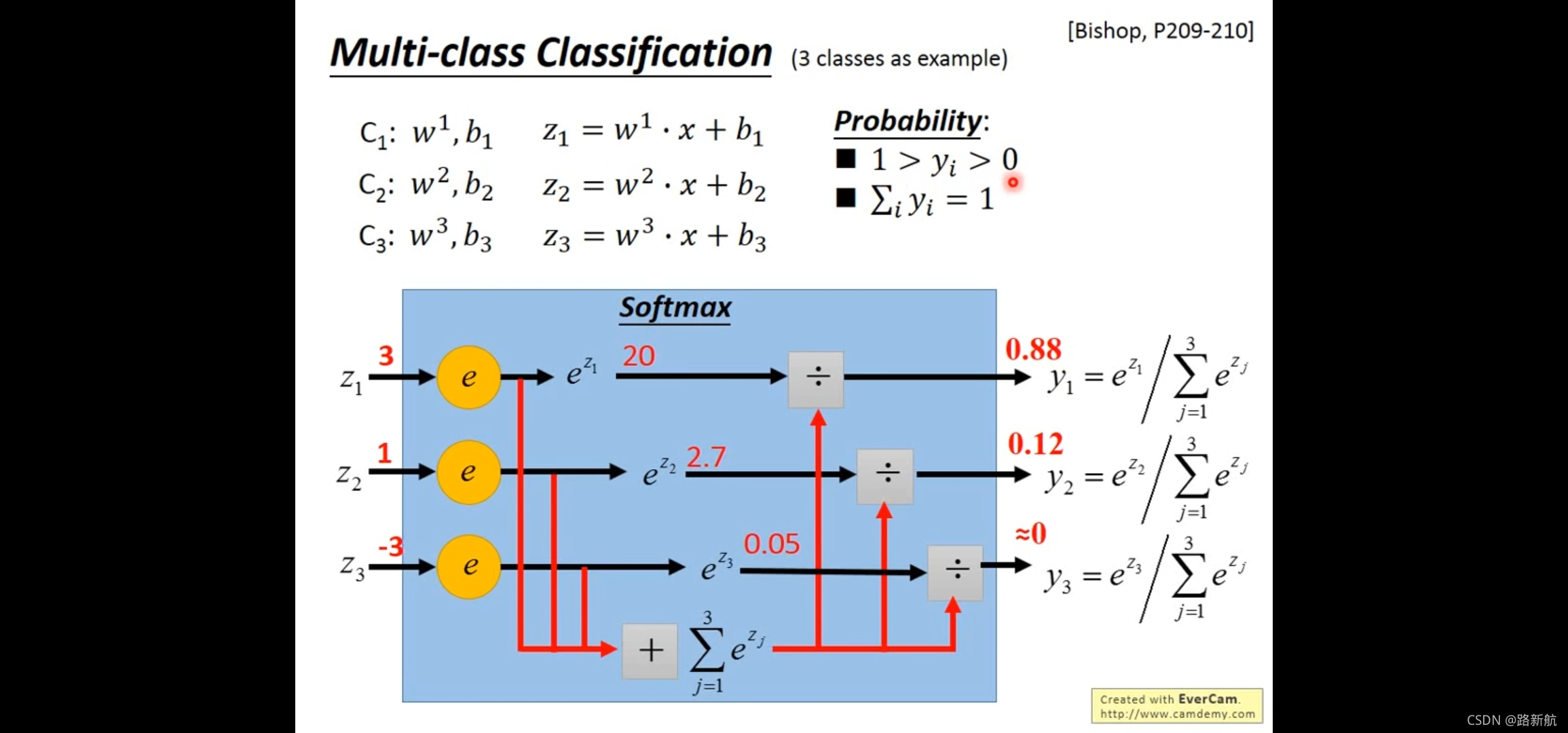
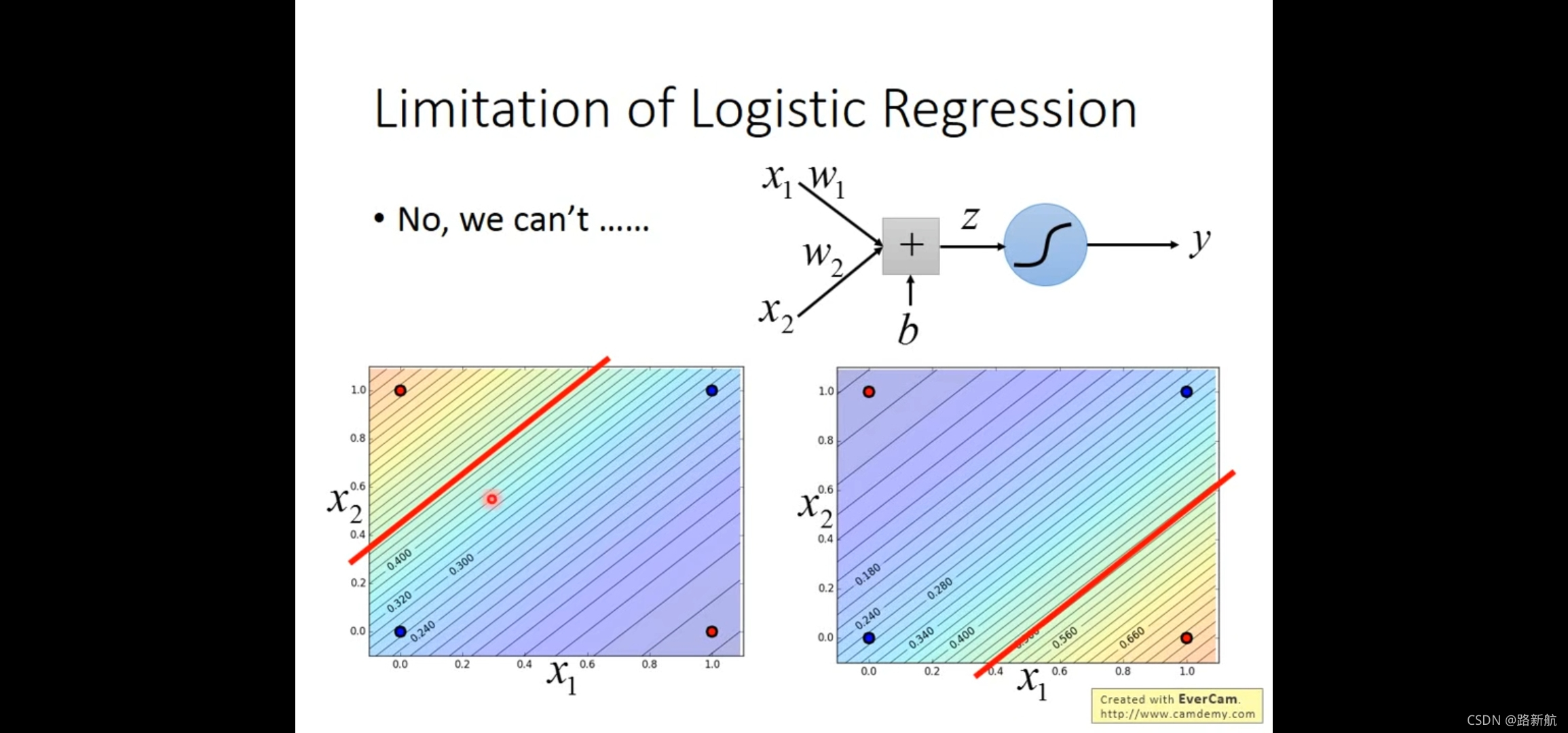
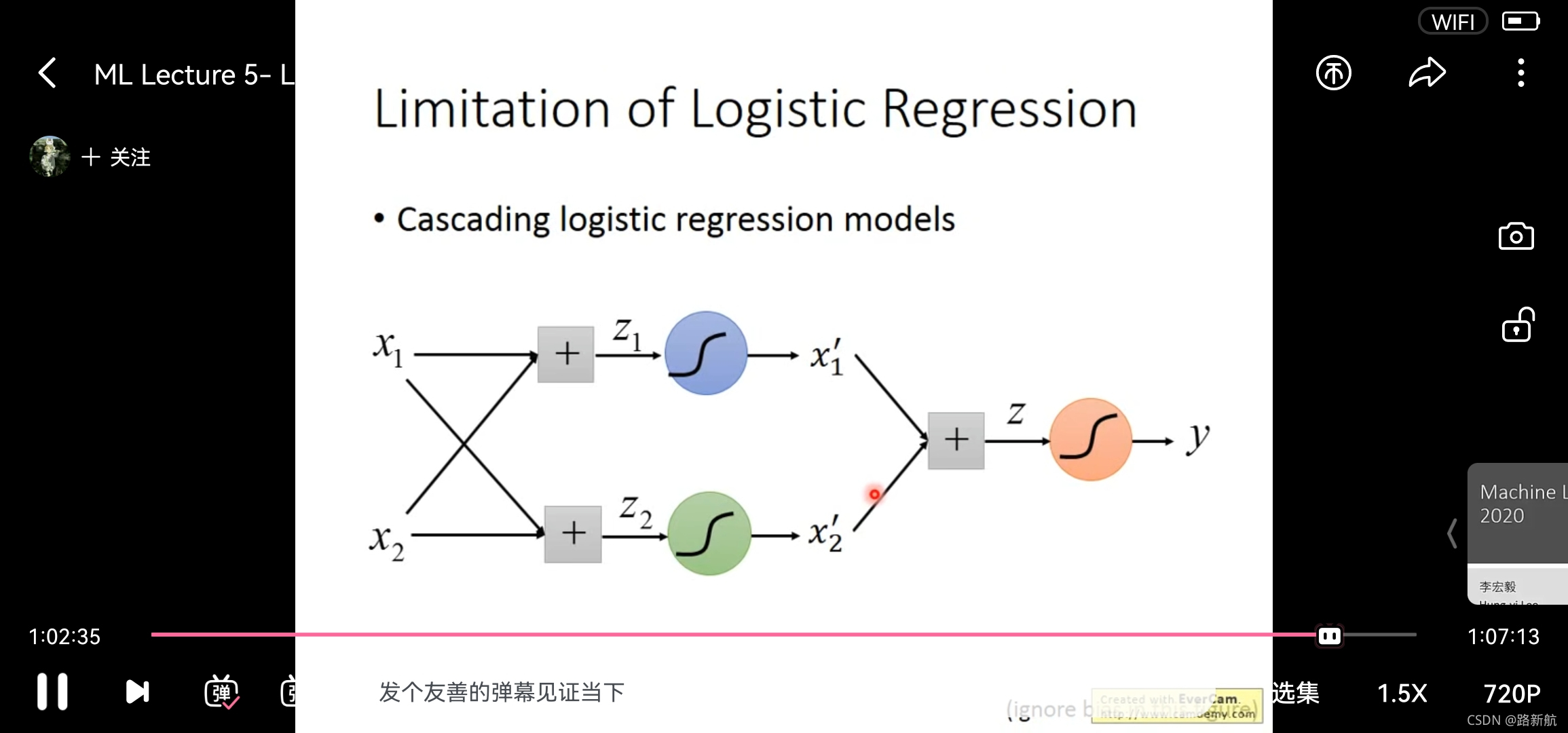
logistic 回归限制性
边界是线性的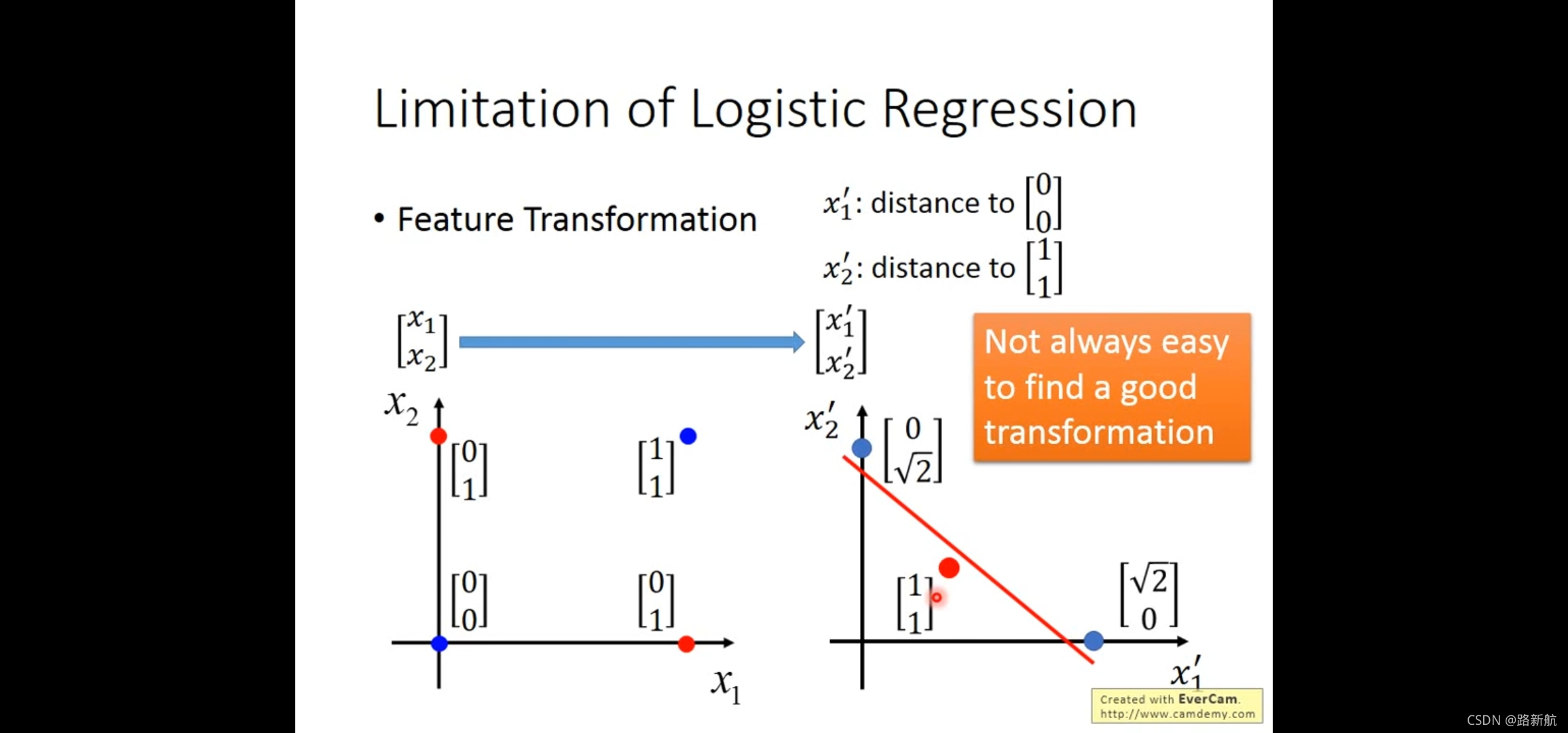
使用过个logistic回归组合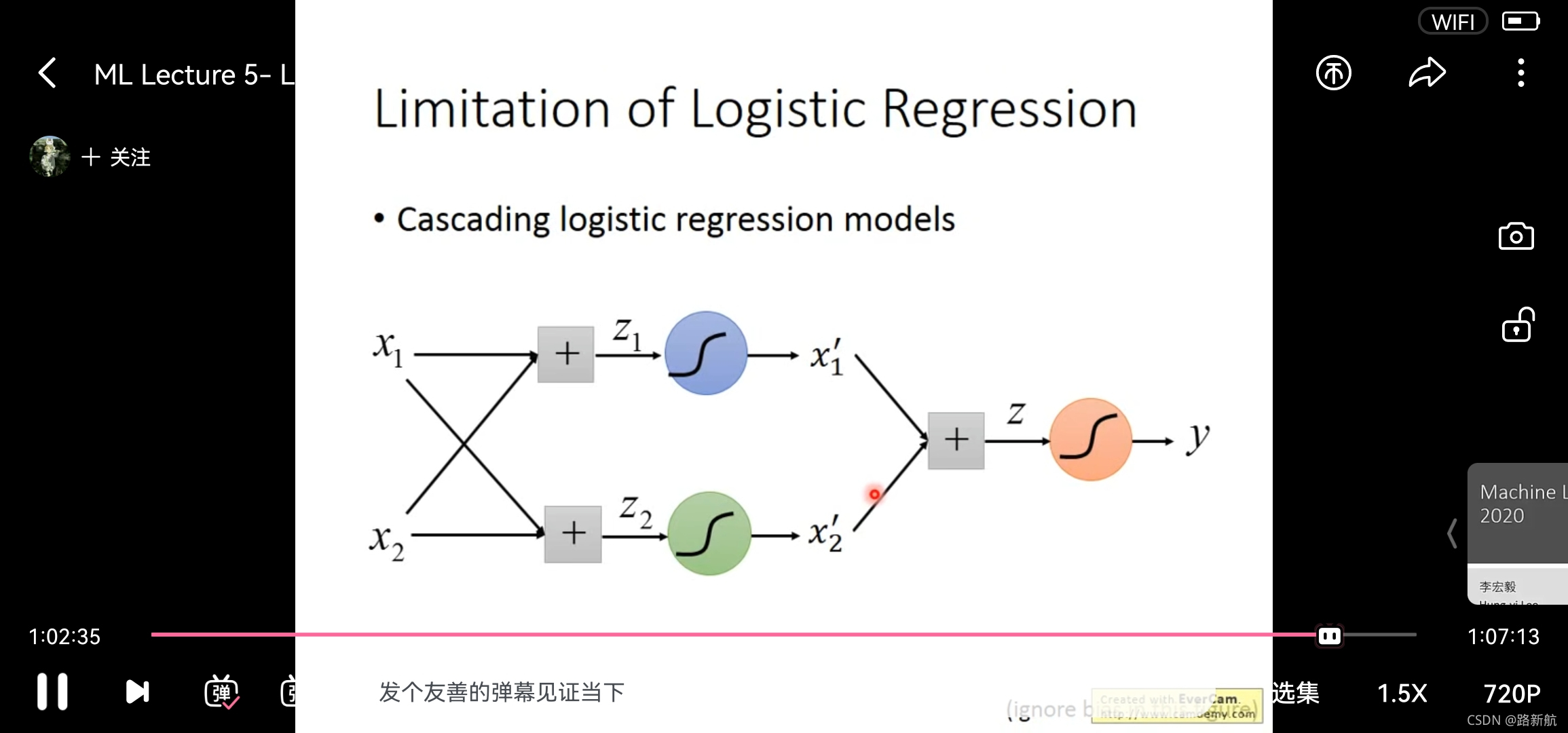
非监督学习
- 聚类和降维
- Generation无中生有
聚类
K均值聚类
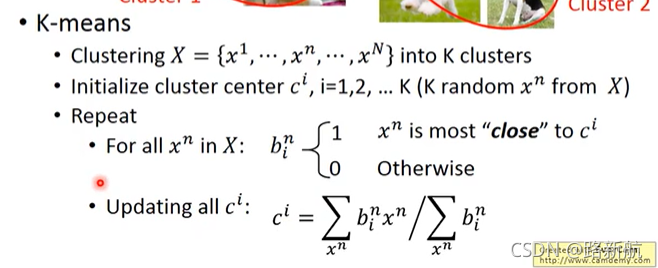
层次聚类
Hierarchical Agglomerative Clustering (HAC)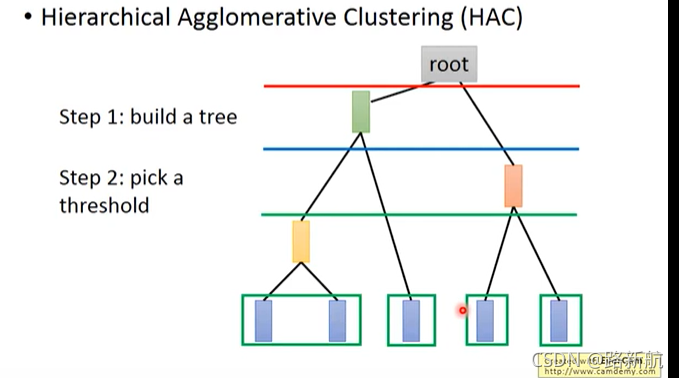
分布式表示 Distributed Representation
一个点一定是一个类,以偏概全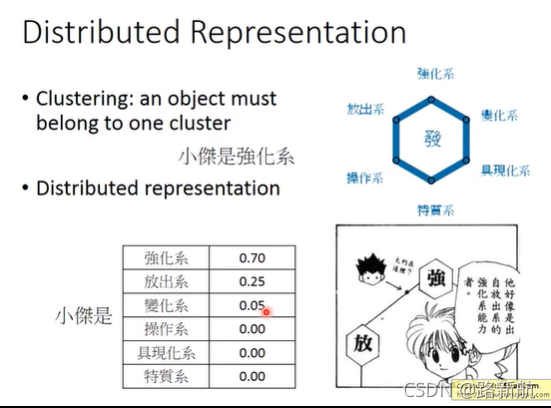
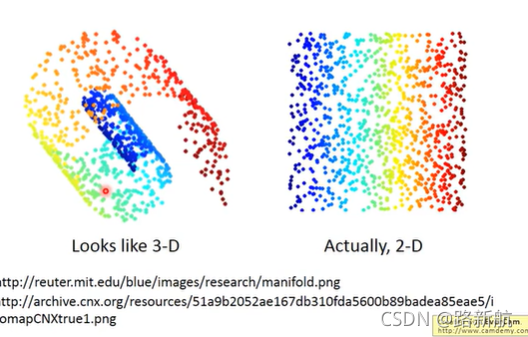
降维
特征选择、PCA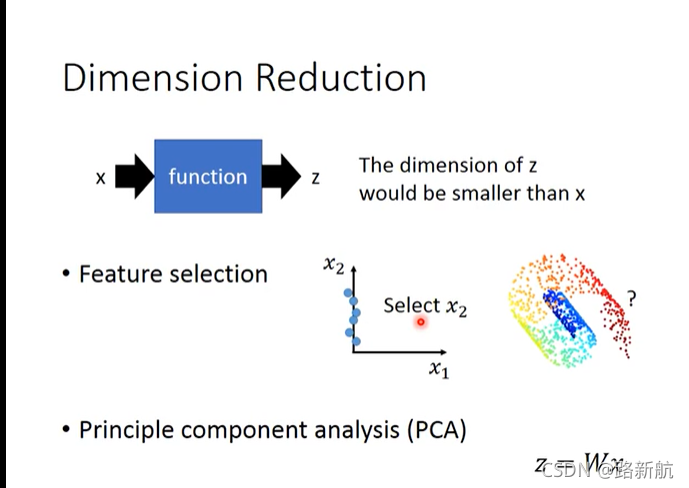
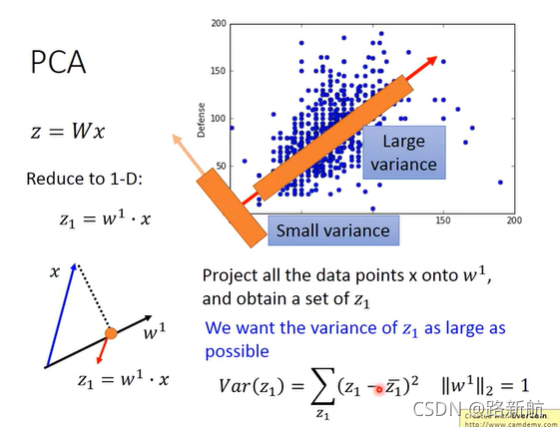

W是正交矩阵

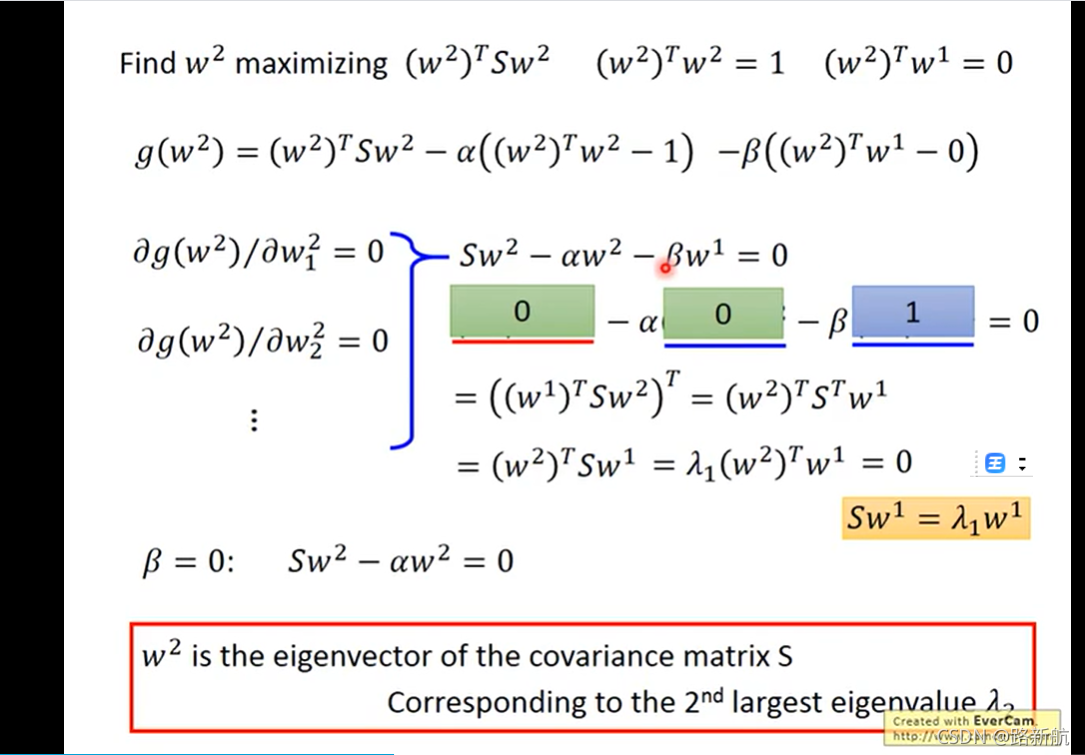
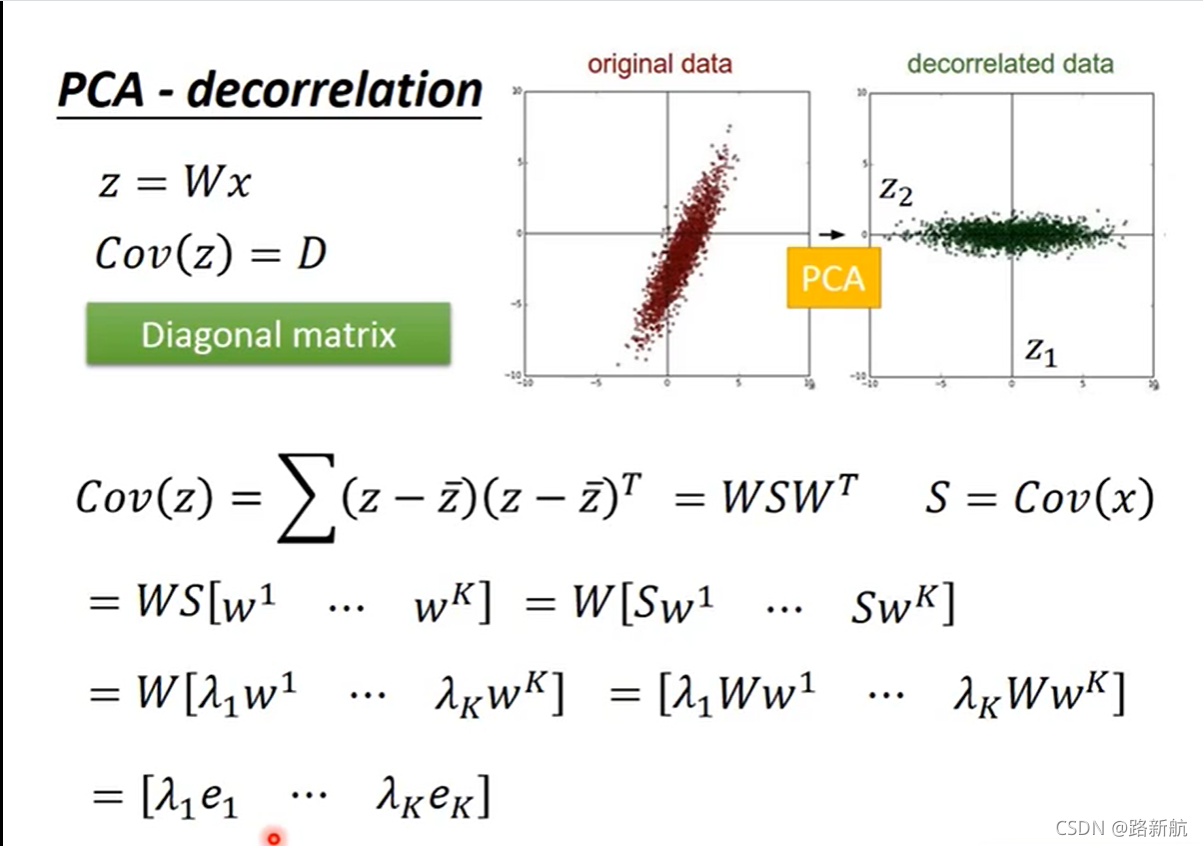
每次投影让方差最大
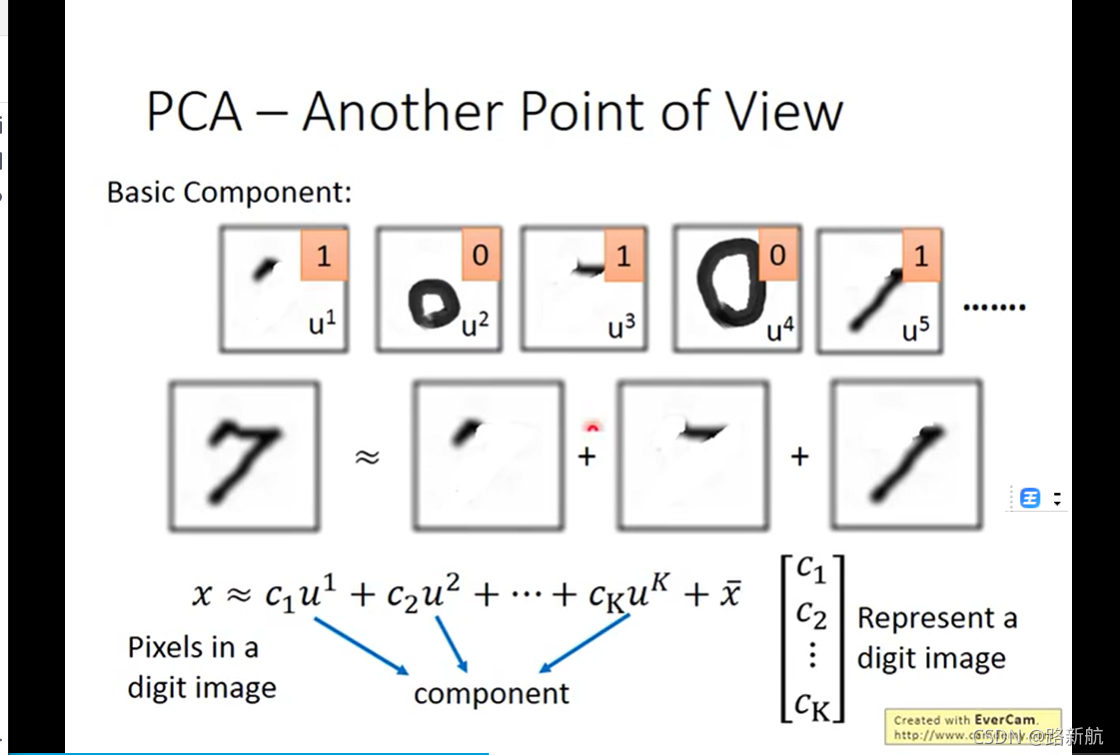

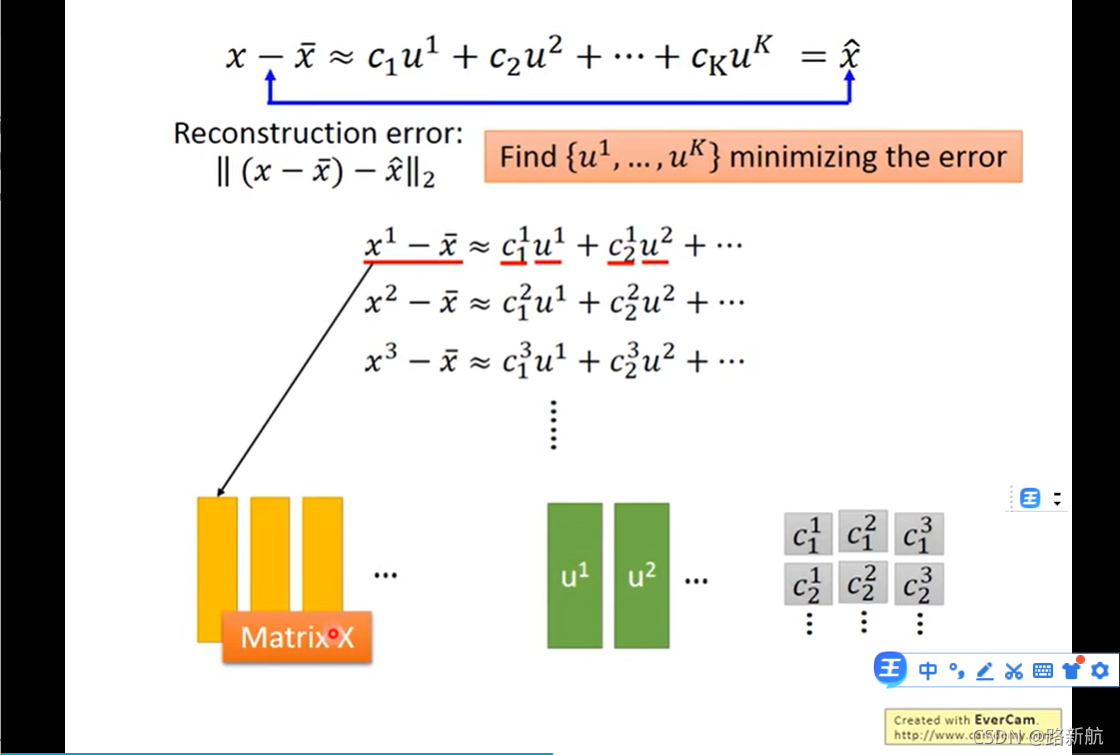
PCA Compnent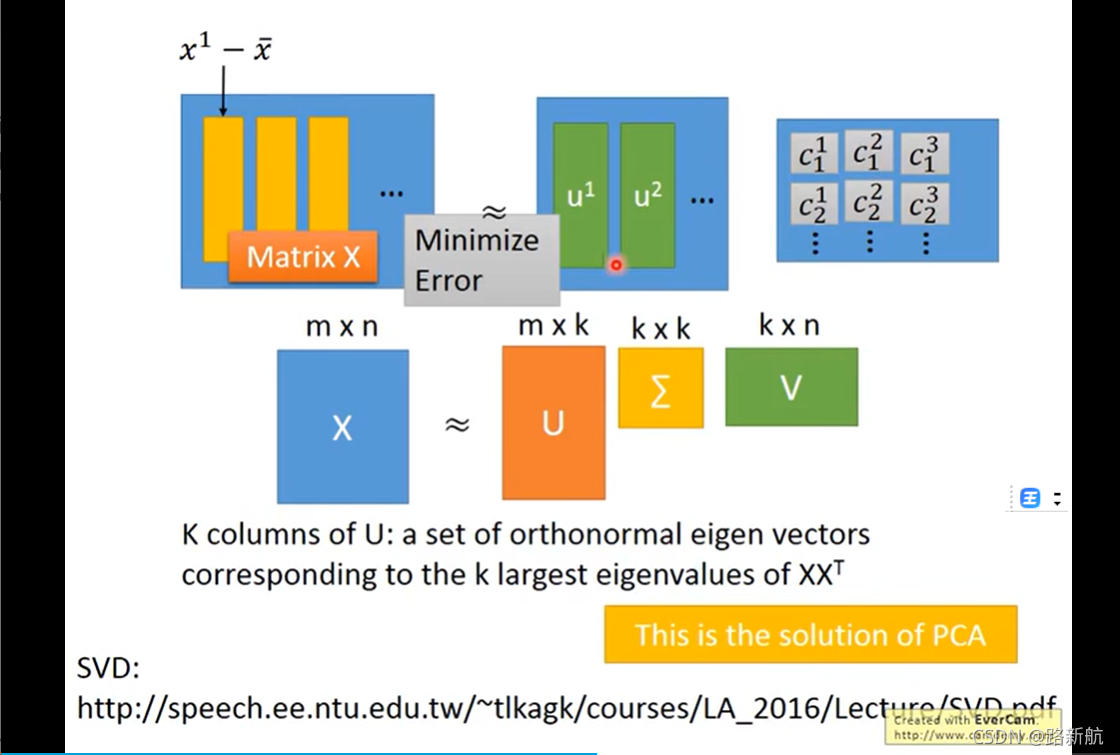
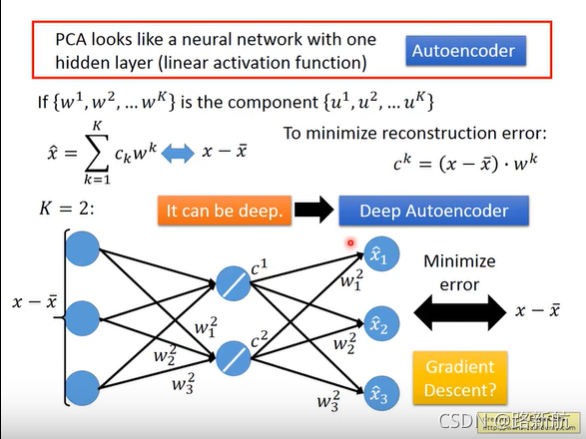
PCA与Neral 两组解
PCA缺点

线性判别分析LDA:
参考:https://www.jianshu.com/p/13ec606fdd5f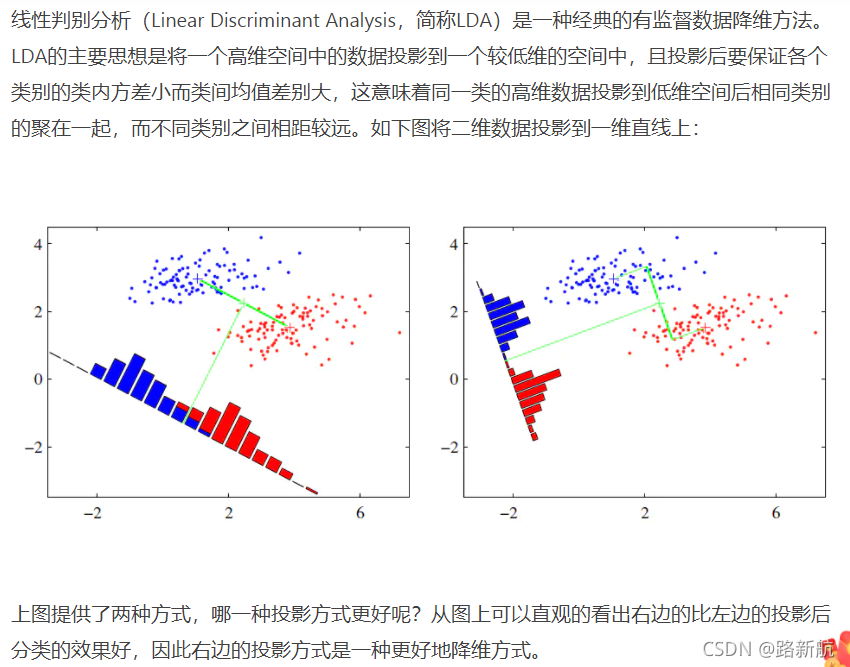
component 可以加,减

NMF on MNIST

矩阵分解
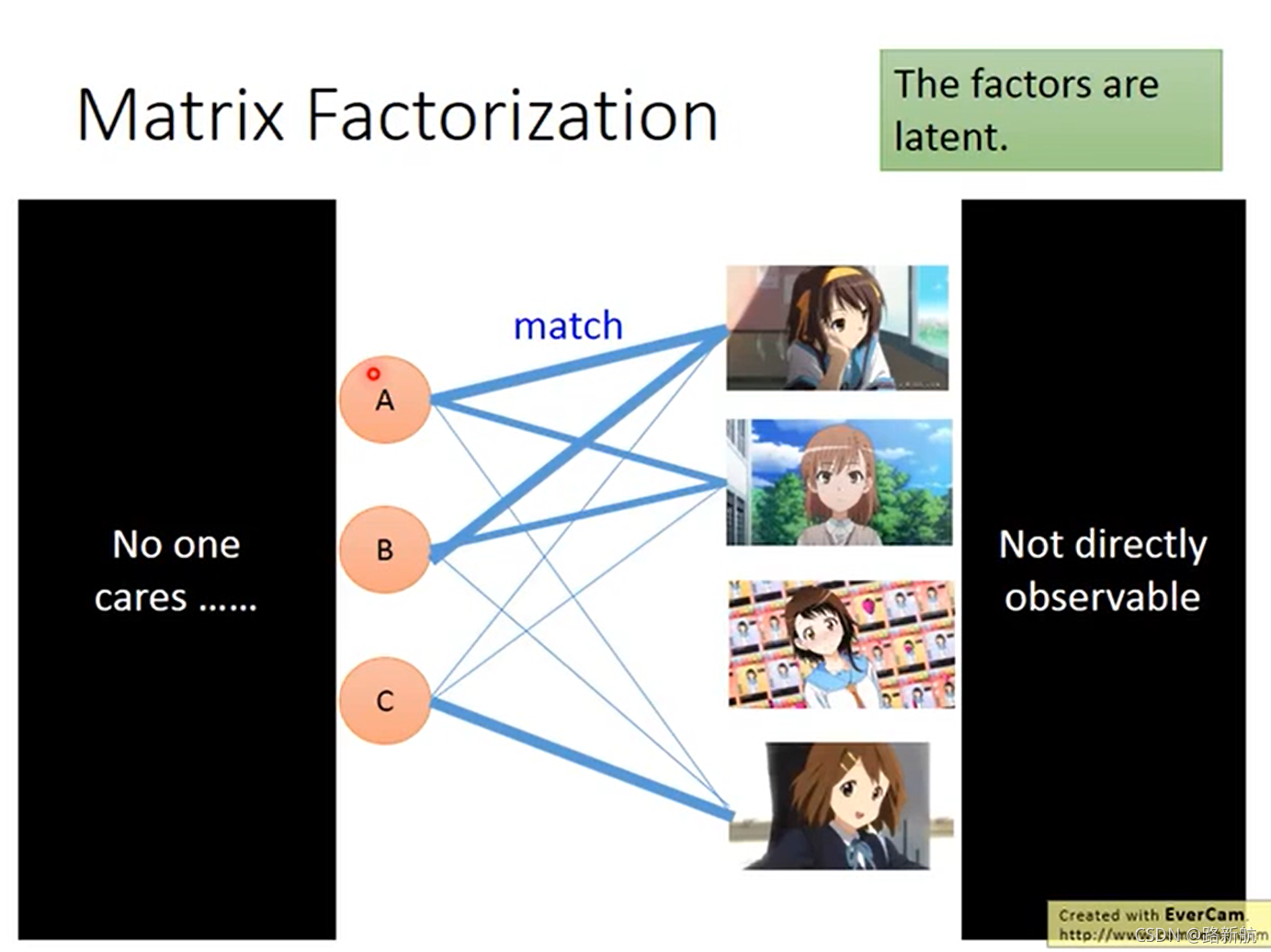
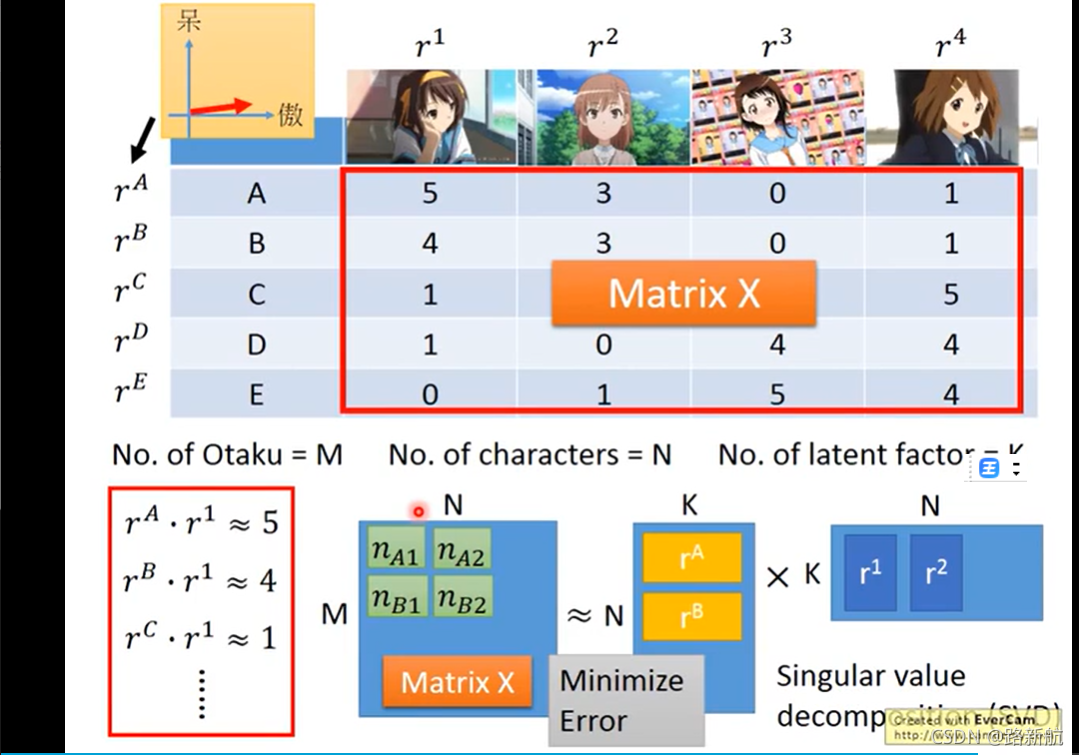
没有的值久不算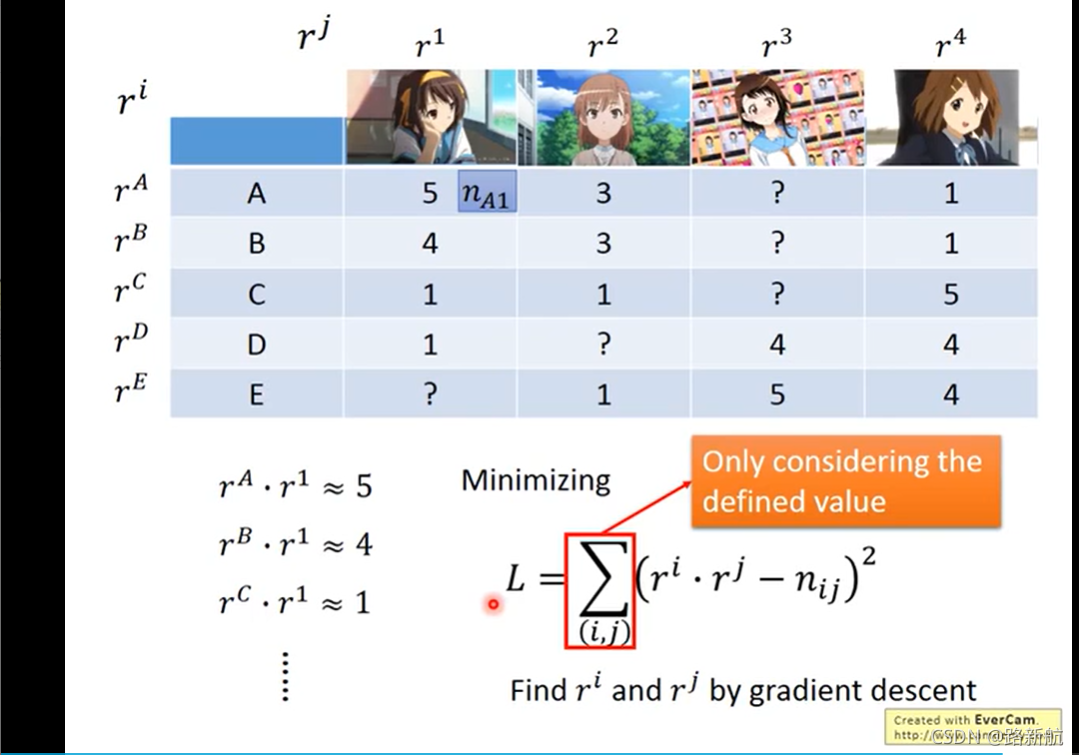
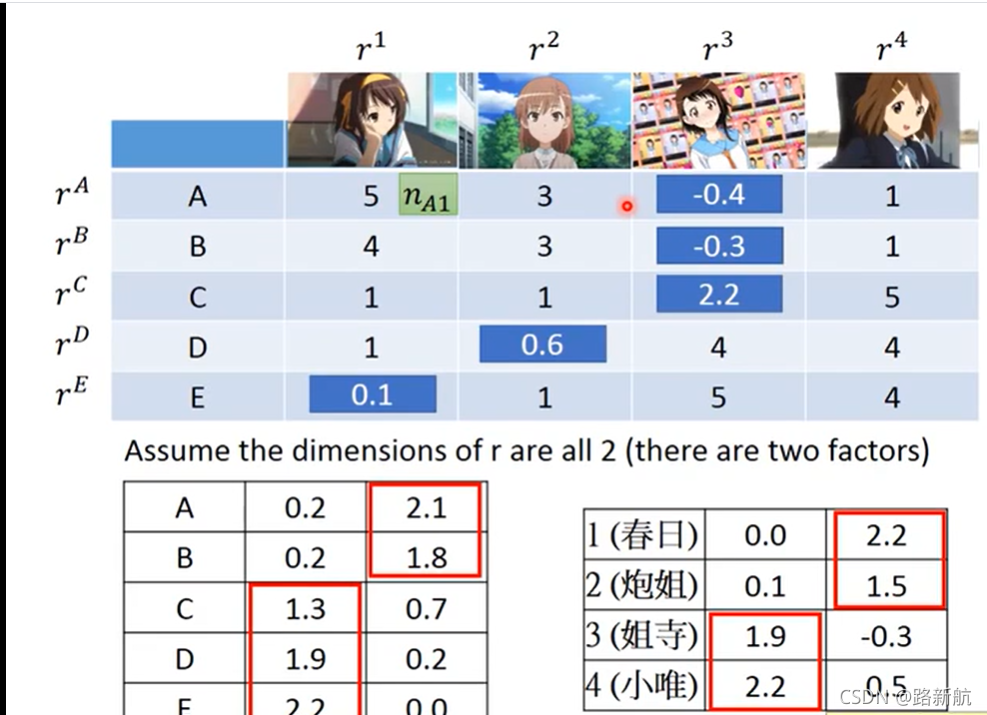


词嵌入
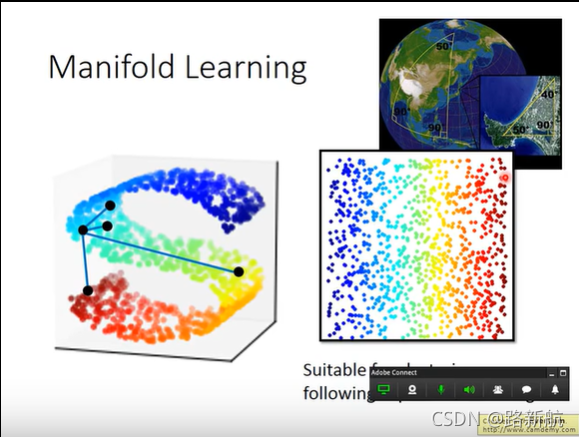
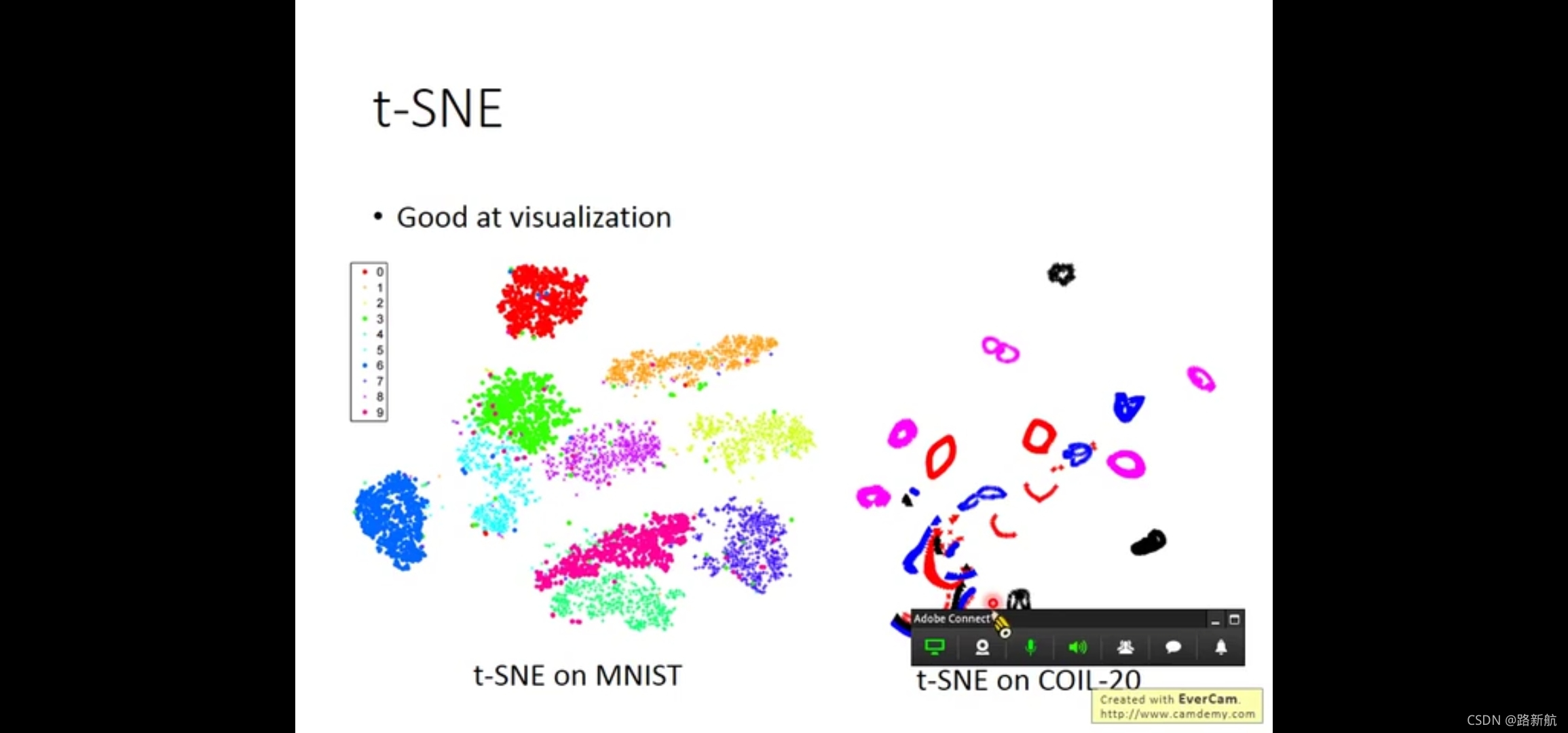
Neighbor Embedding
manifold learning
locally linear embedding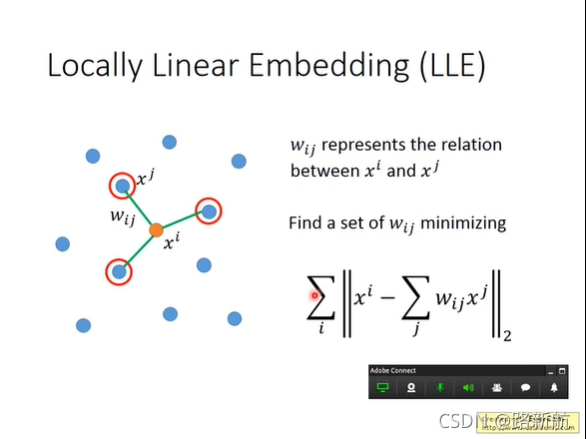
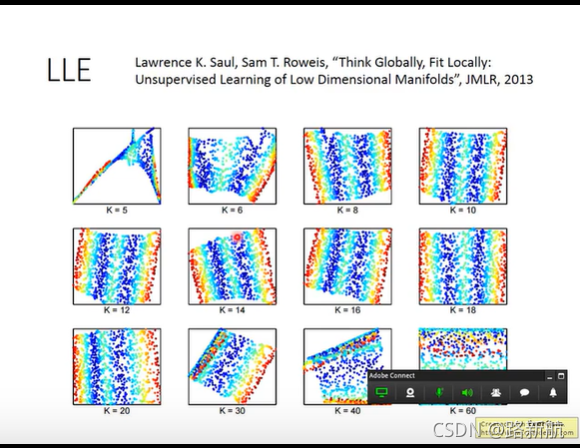
LLE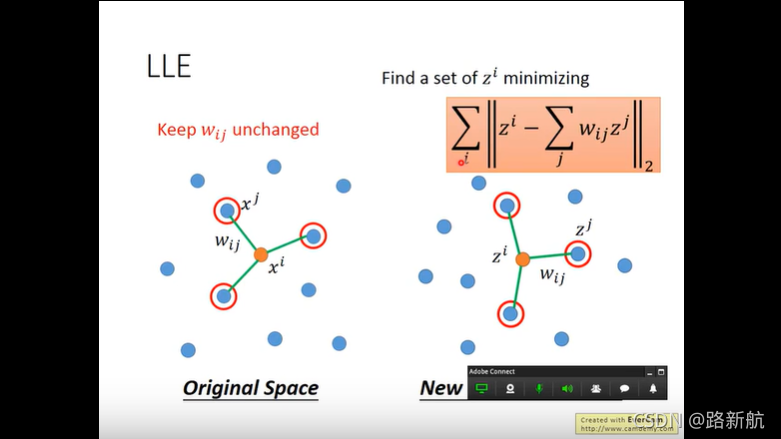

异常检测
如果数据符合高斯分布,均值为i,方差为sigma,
可以根据特征的值算概率值,判断是否异常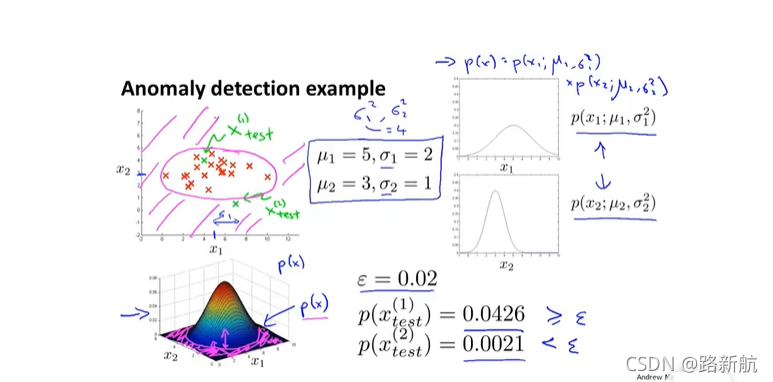
PCA应用建议
1.压缩数据,减少存储成本
2.加快计算

不建议:
1.防止过拟合
2.一开始就用PCA降维后的数据拟合模型,而不是完整的数据

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)