机器学习——分类模型评估指标
分类模型是机器学习的一种类型,它的任务是通过学习样本的特征来预测样本的类别。
目录
分类模型是机器学习的一种类型,它的任务是通过学习样本的特征来预测样本的类别。
常见的分类模型评估指标
一、混淆矩阵
混淆矩阵是一个评估分类问题常用的工具,对于 k 元分类,其实它是一个k x k的表格,用来记录分类器的预测结果。例如对于常见的二分类,它的混淆矩阵是 2 x 2 的。
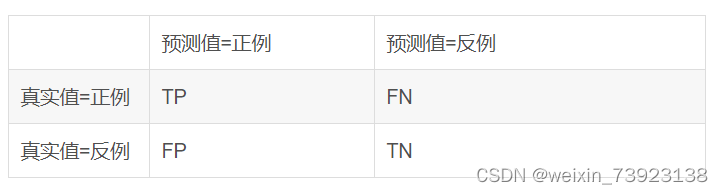
混淆矩阵通常包含四个主要部分:
1. **真阳性(TP)**:实际为正类,预测也为正类的数量。
2. **假阴性(FN)**:实际为负类,但预测为正类的数量。
3. **真阴性(TN)**:实际为负类,且预测为负类的数量。
4. **假阳性(FP)**:实际为负类,但预测为负类的数量。
二、准确率(Accuracy)
准确率是指分类正确的样本占总样本个数的比例。准确率是针对所有样本的统计量。它被定义为:
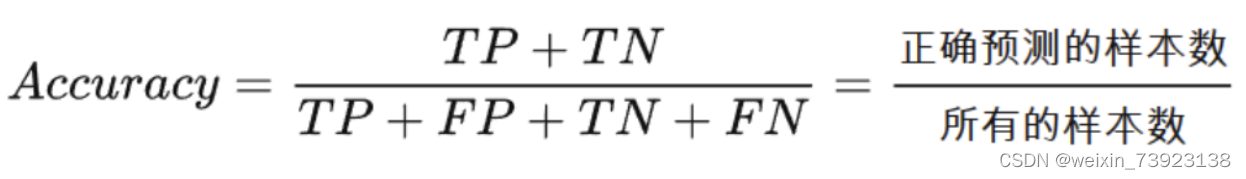
三、精确率
精确率又称为查准率,是针对预测结果而言的一个评价指标。指在分类正确的正样本个数占分类器判定为正样本的样本个数的比例。精确率是对部分样本的统计量,侧重对分类器判定为正类的数据的统计。它被定义为:

四、召回率(Recall)
召回率是指分类正确的正样本个数占真正的正样本个数的比例。召回率也是对部分样本的统计量,侧重对真实的正类样本的统计。它被定义为:
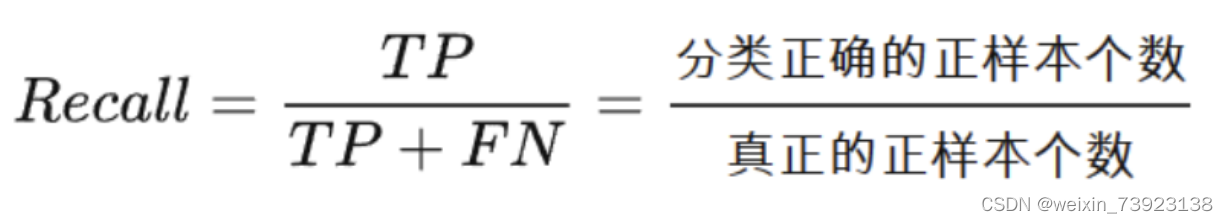
Precision 与 Recall 的权衡
精确率高,意味着分类器要尽量在 “更有把握” 的情况下才将样本预测为正样本, 这意味着精确率能够很好的体现模型对于负样本的区分能力,精确率越高,则模型对负样本区分能力越强。
召回率高,意味着分类器尽可能将有可能为正样本的样本预测为正样本,这意味着召回率能够很好的体现模型对于正样本的区分能力,召回率越高,则模型对正样本的区分能力越强。
五、F1分数(F1 Score)
F1 Score是精准率和召回率的调和平均值,它同时兼顾了分类模型的准确率和召回率,是统计学中用来衡量二分类(或多任务二分类)模型精确度的一种指标。它的最大值是1,最小值是0,值越大意味着模型越好。 它定义为:
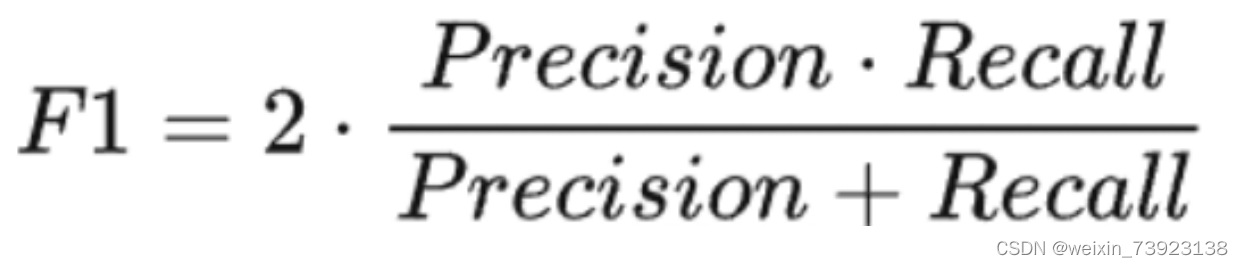
F-Beta Score
更一般的Fβ,它的物理意义就是将准确率和召回率这两个分值合并为一个分值,在合并的过程中,召回率的权重是准确率的β倍。我们定义Fβ分数为:
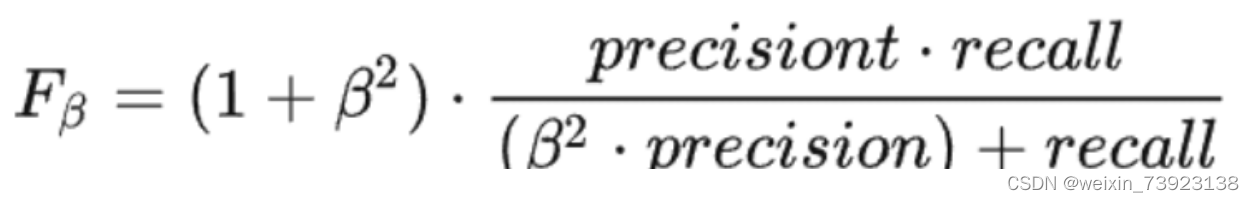
ROC曲线与PR曲线
ROC曲线
ROC(Receiver Operating Characteristic)曲线是用于评估二分类模型的一个重要工具。它可以帮助我们选择最佳的分类阈值,以在不同情况下达到最佳的分类结果。
ROC曲线的横轴是假阳性率(FPR),纵轴是真阳性率(TPR),其中:
真阳性率(TPR)= 将正例预测为正例的数量 / 实际正例的数量,即
假阳性率(FPR)= 将负例预测为正例的数量 / 实际负例的数量,即
在ROC曲线中,每个点代表不同的分类阈值下模型的FPR和TPR。曲线上的点越靠近左上角即代表模型在各种分类阈值下表现越优秀。如果模型的ROC曲线完全处于对角线上,则表示模型无法区分正例和负例。
根据ROC曲线可以计算出一个叫做AUC(Area Under the Curve)的值。AUC即ROC曲线下的面积。曲线越靠近左上角,意味着TPR>FPR,模型的整体表现也就越好。AUC值可以用来衡量模型的分类能力,越大越好,理想情况下AUC值为1。
PR曲线
PR曲线(Precision-Recall Curve)是一种用于评估分类模型性能的曲线图。在二分类问题中,我们通常关注两个指标:Precision(精确率)和Recall(召回率)。
PR曲线是以召回率为横轴,精确率为纵轴绘制的曲线。曲线上的每个点代表着不同的分类阈值下模型的精确率和召回率。
使用PR曲线可以直观地评估模型在不同分类阈值下的性能表现。曲线越靠近右上角,模型的性能越好。对于PR曲线而言,面积越大表示模型具有更好的分类性能。
二者的差异
PR曲线因为涉及到精确率precision计算,容易受到样本分布的影响。而ROC曲线本质上是正样本或者负样本召回率计算,不收样本分布的影响。PR曲线专门针对二分类问题,更注重精确率和召回率之间的平衡,而ROC曲线则更注重全局性能的评估。
KNN算法不同k值下的ROC曲线
代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import precision_recall_curve, roc_curve, auc
# 随机生成数据集
X, y = make_classification(n_samples=1000, n_classes=2, n_features=10)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 定义KNN分类器
k_values = [1,6,12]
plt.figure(figsize=(8, 6))
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
# 训练模型
knn.fit(X_train, y_train)
# 预测测试集
y_pred = knn.predict(X_test)
# 计算PR曲线和ROC曲线
precision, recall, _ = precision_recall_curve(y_test, y_pred)
fpr, tpr, _ = roc_curve(y_test, y_pred)
#传入FPR和TPR数组,计算出ROC曲线下的面积
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.plot(fpr, tpr, lw=2, label='ROC Curve for k=%d (AUC = %0.2f)' %(k,roc_auc))
plt.plot([0, 1], [0, 1], color='c', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curves at different k values')
plt.legend()
plt.show()运行结果:
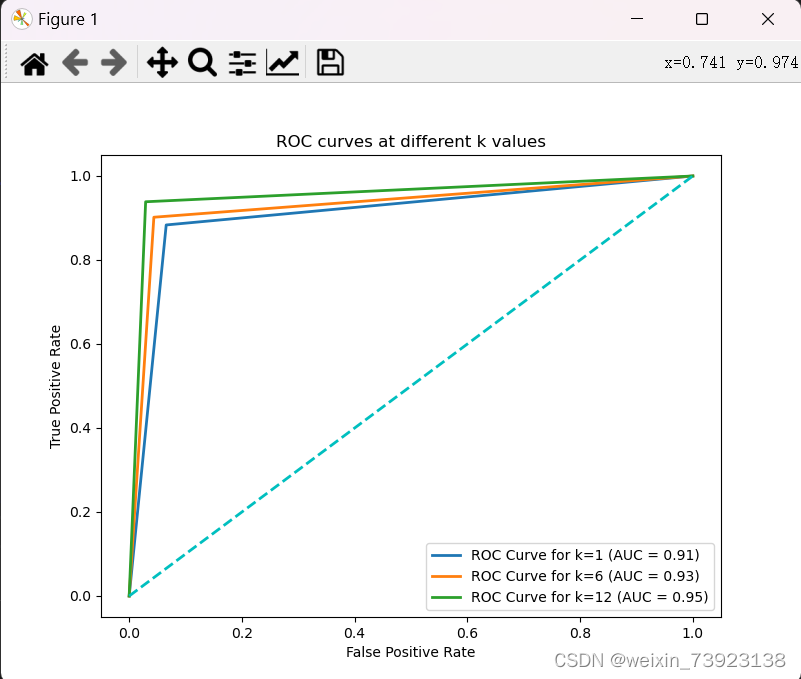
曲线上的点越靠近左上角,模型表现越优秀。由上图运行结果可见,三种情况中,当k=12时,绿色曲线最靠近左上角,AUC值最接近1,所以该分类模型是三种中最好的。
参考:

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)