【机器学习】最强回归算法模型,线性回归 !!
如果某些特征的值特别大(比如TAX=400)而某些特别小(比如CRIM=0.1),它会误以为数值大的特征更重要。我们把数据拆成训练集(80%)和测试集(20%),这是机器学习中的常规做法,用来评估模型在未见数据上的表现。比如:一名房产中介,想根据「房子的面积」来预测「房子的价格」。假设我们拥有一组历史房屋交易数据,想根据房子的特征(如面积、卧室数、地段评分等)预测它的售价。,这条直线能尽量靠近这些
这段时间,很多即将开学以及机器学习的初学者,想让分享通俗易懂的算法模型。~
什么是线性回归?
你可以把线性回归想象成“画一条最合适的直线”。
比如:一名房产中介,想根据「房子的面积」来预测「房子的价格」。你收集了很多房子的真实数据,比如:
-
80平米 → 100万
-
100平米 → 120万
-
120平米 → 140万
-
150平米 → 170万
你在纸上把这些数据点画出来,每个点代表一个房子。你发现这些点大致分布在一条直线附近,但不是完全一条直线。
这时,线性回归的目标,就是找到一条最合适的直线,这条直线能尽量靠近这些点,用来表示“房子的面积和价格之间的关系”。
之后,只要有人问:“一个110平米的房子大概多少钱?”你就可以看你那条线在110平米时的高度是多少,给出一个预测。
这,就是线性回归。
原理详解
1. 建立模型的假设(线性模型)
我们假设变量之间的关系是线性的,也就是说,因变量(比如价格)和自变量(比如面积)之间可以用一个直线关系来描述:
其中:
-
:我们要预测的值(比如房价)
-
:输入的值(比如面积)
-
:斜率,表示每增加1单位的 , 增加多少(房价每多一平米涨多少钱)
-
:截距,表示当 时, 是多少(可以理解为“基础价格”)
如果有多个变量,比如面积、卧室数量、楼层等,我们用向量表达为:
其中:
-
:输入特征向量
-
:权重系数向量
-
:偏置(仍然是截距)
为方便推理,我们可以把偏置 也合并进参数里(把 , ),统一成:
2. 目标是什么?(最小化预测误差)
我们有很多数据对:
线性回归的目标是:找到最好的 ,使得预测值 和真实值 之间的误差尽量小。
我们使用 均方误差(Mean Squared Error, MSE)作为误差度量方式:
这个公式的含义是:你预测得越准,误差越小,代价函数 就越小。
3. 如何求最优的 ?(解析解推导)
我们要求的是让 最小的 ,这是一个最优化问题。我们来推导一下解析解(即直接算出最优解的方法)。
用矩阵形式表达
设:
-
是 的数据矩阵,每一行是一个样本的特征
-
是 的标签向量
-
是 的权重向量
预测值向量就是:
损失函数(代价函数)写成矩阵形式:
我们对 求导:
令导数为0,找到极小值点:
推导得到解析解:
这就是线性回归最经典的解析解,前提是 可逆。
4. 另一种方式:梯度下降(迭代优化)
如果样本很多,或者特征很多,矩阵求逆计算成本高,这时我们使用梯度下降法迭代求最优参数。
梯度下降的基本流程:
-
初始化权重 为随机值或0
-
重复以下步骤直到收敛:
-
计算梯度:
-
更新参数:
其中 是学习率
-
最终得到收敛后的 ,即最佳拟合的参数
-
完整算法流程
我们把整个线性回归过程整理成一个清晰流程:
步骤一:准备数据
-
收集样本数据:每个样本有特征 和目标
-
可以标准化(归一化)特征,提高效果和收敛速度
步骤二:构建线性模型
假设模型为:
可以扩展为多特征的矩阵形式。
步骤三:定义损失函数
使用均方误差:
或矩阵形式:
步骤四:选择优化方法
-
如果样本不大,使用解析解:
-
如果样本多,使用梯度下降迭代优化
步骤五:训练模型
-
输入数据
-
计算预测
-
计算误差
-
优化权重参数
步骤六:使用模型预测
-
给定新的输入 ,计算:
就可以得到预测值
完整案例
假设我们拥有一组历史房屋交易数据,想根据房子的特征(如面积、卧室数、地段评分等)预测它的售价。
项目目标:使用线性回归模型预测房价,并进行可视化与模型优化。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression, Ridge, Lasso from sklearn.metrics import mean_squared_error, r2_score from sklearn.preprocessing import StandardScaler # Step 1: 构造模拟数据(仿真实际房价数据) np.random.seed(42) n_samples = 5006 # 模拟特征 X = pd.DataFrame({ 'CRIM': np.random.exponential(scale=5, size=n_samples), # 犯罪率 'ZN': np.random.uniform(0, 100, size=n_samples), # 住宅用地比例 'INDUS': np.random.normal(10, 2, size=n_samples), # 工业用地比例 'RM': np.random.normal(6, 0.5, size=n_samples), # 房间数 'AGE': np.random.uniform(20, 100, size=n_samples), # 建造年代 'TAX': np.random.normal(400, 50, size=n_samples), # 房产税 'LSTAT': np.random.normal(12, 5, size=n_samples), # 低收入人口比例 }) # 模拟房价 y(带有一定线性关系 + 噪声) y = 24 + 0.3*X['RM'] - 0.2*X['LSTAT'] - 0.01*X['CRIM'] + \ 0.05*X['ZN'] - 0.04*X['AGE'] + 0.01*X['TAX'] + 0.1*X['INDUS'] + \ np.random.normal(0, 2, size=n_samples) X['PRICE'] = y # Step 2: 特征选择与划分训练集 features = ['CRIM', 'ZN', 'INDUS', 'RM', 'AGE', 'TAX', 'LSTAT'] X_data = X[features] y_data = X['PRICE'] X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=0) # Step 3: 数据标准化 scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # Step 4: 建立模型 model = LinearRegression() model.fit(X_train_scaled, y_train) # Step 5: 模型预测 y_pred = model.predict(X_test_scaled) # Step 6: 模型评估 mse = mean_squared_error(y_test, y_pred) r2 = r2_score(y_test, y_pred) print("MSE:", mse) print("R^2 Score:", r2) # Step 7: 可视化:真实值 vs 预测值 plt.figure(figsize=(10, 6)) plt.scatter(y_test, y_pred, c='crimson', edgecolors='black', alpha=0.7) plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='limegreen', linewidth=2) plt.title("Real vs Predicted Prices", fontsize=16) plt.xlabel("Actual Prices", fontsize=14) plt.ylabel("Predicted Prices", fontsize=14) plt.grid(True) plt.tight_layout() plt.show() # Step 8: 查看回归系数(特征影响) coefficients = pd.Series(model.coef_, index=features) plt.figure(figsize=(10, 6)) coefficients.sort_values().plot(kind='barh', color='royalblue', edgecolor='black') plt.title("Feature Influence on Price", fontsize=16) plt.xlabel("Coefficient Value", fontsize=14) plt.grid(True) plt.tight_layout() plt.show() # Step 9: 模型优化 - 使用岭回归与Lasso ridge = Ridge(alpha=1.0) ridge.fit(X_train_scaled, y_train) ridge_pred = ridge.predict(X_test_scaled) lasso = Lasso(alpha=0.1) lasso.fit(X_train_scaled, y_train) lasso_pred = lasso.predict(X_test_scaled) print("Ridge R^2:", r2_score(y_test, ridge_pred)) print("Lasso R^2:", r2_score(y_test, lasso_pred))Step 1:模拟真实房价数据
我们创建了一个模拟数据集,模仿现实中的房价数据特征,比如:
-
犯罪率(CRIM)
-
住宅用地比例(ZN)
-
房间数量(RM)
-
房产税(TAX)
-
低收入人口比例(LSTAT)
这些特征在波士顿房价数据集中具有代表性,反映了现实生活中的购房考虑因素。
我们用一组公式加上随机噪声生成了房价(PRICE)数据,模拟现实中房价受到多重因素影响的情况。
Step 2:训练集与测试集划分
我们把数据拆成训练集(80%)和测试集(20%),这是机器学习中的常规做法,用来评估模型在未见数据上的表现。
Step 3:标准化(归一化)
线性回归对特征的尺度非常敏感。如果某些特征的值特别大(比如TAX=400)而某些特别小(比如CRIM=0.1),它会误以为数值大的特征更重要。
所以我们使用
StandardScaler把每列特征变换为均值为0,标准差为1,这有助于模型权重的稳定性和对各个特征公平看待。Step 4:线性回归建模
我们训练了一个线性回归模型,自动寻找最优的权重系数 和偏置 ,最小化预测值和真实值之间的均方误差(MSE)。
Step 5-6:预测与评估
我们用测试集数据来预测,并计算两项核心指标:
-
MSE(均方误差):预测值和实际值差异的平方平均,越小越好。
-
R²(判定系数):衡量预测值对真实值的解释能力,越接近1越好。
Step 7:预测效果图(Real vs Predicted)
我们绘制了真实房价和预测房价的对比散点图。理想情况下,所有点应该分布在绿色的对角线上(表示预测值 = 实际值)。
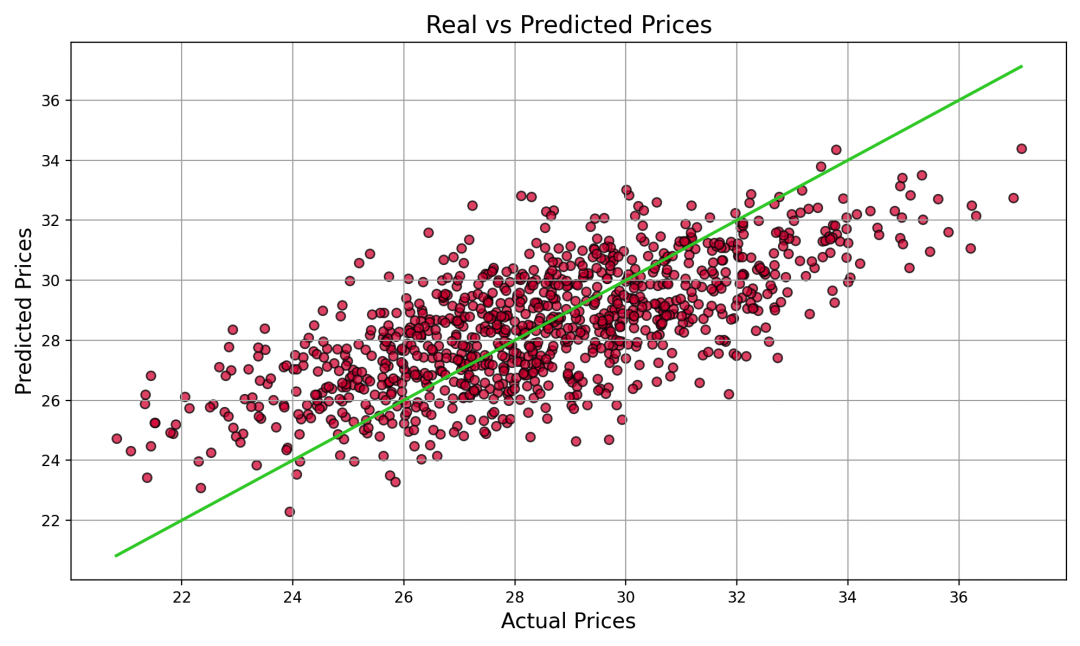
-
如果点大多靠近对角线,说明模型拟合得好。
-
如果点偏离很远,说明误差较大,需要进一步优化。
Step 8:回归系数可视化(Feature Importance)
我们画出了模型中每个特征的系数大小,解释每个变量对房价的正负影响。
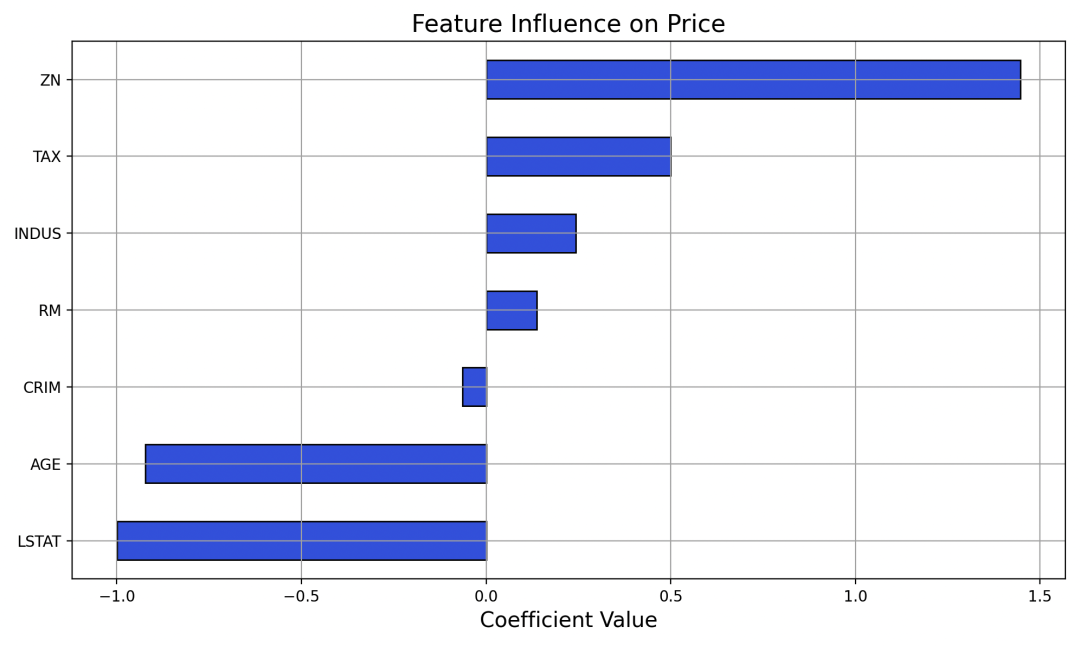
-
正系数:该特征越大,房价越高(如 RM:房间数)
-
负系数:该特征越大,房价越低(如 LSTAT:低收入比例)
-
系数的绝对值表示影响程度
Step 9:模型优化(正则化)
我们引入了两个优化模型:
-
Ridge 回归(岭回归):惩罚系数过大的模型,防止过拟合
-
Lasso 回归:具有稀疏性,会自动将不重要的特征系数压为 0,进行特征选择
我们用相同的训练集进行对比,观察预测性能是否提升。通常 Lasso 对于高维数据更适用。
最后如果本文对你有帮助,记得收藏、点赞、转发起来!
-

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献179条内容
已为社区贡献179条内容

所有评论(0)