机器学习之特征提取
本文介绍了机器学习中特征提取的核心概念和方法。特征提取是将原始数据转换为模型可理解的数字形式的过程,类似烹饪中的食材预处理。对于结构化数据(如表格),介绍了数值型特征处理(分桶)、类别型特征处理(独热编码)和时间特征提取。对于非结构化数据(如文本和图像),讲解了词袋模型、TF-IDF等文本特征提取方法,以及手工特征和深度学习自动提取图像特征的技术。文章还分享了特征组合、特征选择等高级技巧,并提供了
作为机器学习初学者,理解特征提取(Feature Extraction)就像学做菜时学会“如何挑选和预处理食材”——它直接决定模型最终的味道(性能)。我会用生活中的例子+代码实例帮你彻底掌握这一核心技能。
一、特征提取的本质
核心目标:
将原始数据(如文本、图像、表格)转换为机器学习模型能理解的数字形式,同时保留关键信息。
类比:
-
原始数据 → 未经加工的食材(如整条鱼)
-
特征提取 → 去鳞、切片、腌制(变成可烹饪的状态)
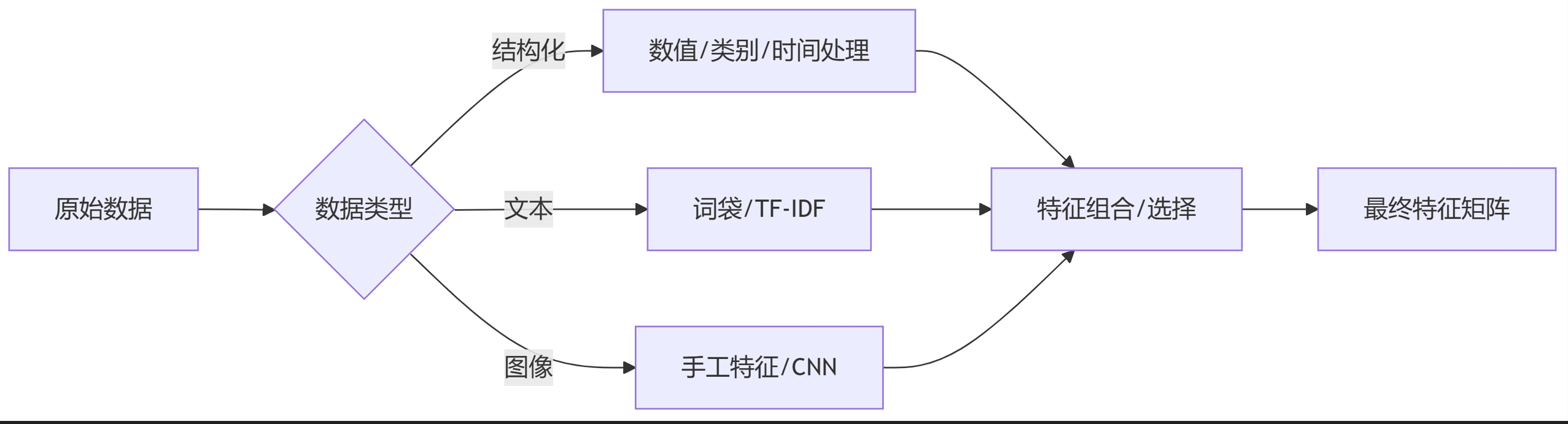
二、结构化数据的特征提取(表格数据)
案例:预测信用卡欺诈
| 交易ID | 交易金额 | 交易时间 | 商户类型 | 是否欺诈 |
|---|---|---|---|---|
| 1001 | 500 | 2023-01-01 | 电商 | 否 |
| 1002 | 9999 | 2023-01-02 | 珠宝店 | 是 |
1. 数值型特征处理
-
直接使用:
交易金额已经是数字,可直接作为特征 -
分桶(Binning):
将连续值分段 → 更鲁棒df['金额区间'] = pd.cut(df['交易金额'], bins=[0,1000,5000,10000])
2. 类别型特征处理
-
独热编码(One-Hot):
将类别转为二进制列pd.get_dummies(df['商户类型'], prefix='商户')结果:
商户_电商 商户_珠宝店 1 0 0 1
3. 时间特征提取
-
拆解日期:
df['交易小时'] = df['交易时间'].dt.hour
df['是否周末'] = df['交易时间'].dt.weekday > 5三、非结构化数据的特征提取
案例1:文本数据(情感分析)
原始句子:
"I love this movie! It's awesome."
1. 词袋模型(Bag of Words)
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(["I love this movie! It's awesome."])
print(vectorizer.get_feature_names_out())输出特征:['awesome', 'love', 'movie', 'this']
(忽略顺序和语法,只统计词频)
2. TF-IDF(更高级的文本特征)
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
X = tfidf.fit_transform(["I love this movie! It's awesome."])输出:加权后的词重要性(常用词如"this"权重降低)
案例2:图像数据(猫狗分类)
原始数据:一张图片的像素矩阵(如256x256x3)
1. 手工特征(传统方法)
-
边缘检测:用Sobel算子提取轮廓
-
颜色直方图:统计RGB分布
2. 深度学习方法(自动特征提取)
from tensorflow.keras.applications import VGG16
base_model = VGG16(weights='imagenet', include_top=False)
features = base_model.predict(image_array)(用预训练CNN提取高层特征如“耳朵形状”“毛发纹理”)
四、特征提取的高级技巧
1. 特征组合(Feature Crossing)
-
案例:在电商推荐中,将
用户年龄和商品类别组合成新特征df['年龄_商品组合'] = df['年龄分段'].astype(str) + "_" + df['商品类目']
2. 特征选择(降维)
-
方法:
-
方差阈值:删除方差接近0的特征(几乎无变化)
-
PCA:将多个相关特征压缩成少数主成分
from sklearn.decomposition import PCA pca = PCA(n_components=3) X_pca = pca.fit_transform(X) -
五、避坑指南
-
❌ 不要盲目增加特征:
→ 特征过多会导致“维度灾难”(尤其样本少时) -
✅ 优先理解业务逻辑:
→ 在金融风控中,交易次数/金额比值可能比单纯金额更重要 -
🔧 工具推荐:
-
结构化数据:Pandas + Scikit-learn
-
文本处理:NLTK/SpaCy
-
图像处理:OpenCV/Pillow
-
六、实战练习
假设你要分析用户购物行为,原始数据包含:用户ID、浏览页面URL、停留时间(秒)、是否购买
任务:提取有用的特征
-
答案示例:
-
从URL提取
页面类型(商品页/首页/促销页) -
创建
总浏览时长和平均每次停留时长 -
对
页面类型做独热编码
-
七、总结流程图

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)