机器学习——垃圾邮件分类实战
随机森林算法作为一种强大的机器学习工具,在垃圾邮件系统构建中发挥着关键作用。其自身具有诸多突出优点,使得它适配垃圾邮件分类任务。一方面,它准确率较高,面对邮件文本中复杂的语言表达、多样的词汇组合等非线性关系,能精准判别垃圾邮件特征,集成多棵决策树的方式有效减少误判。同时,不易过拟合特性保证了在有限的邮件训练样本下,模型依然能稳定学习,对新邮件有良好泛化能力。处理高维数据优势显著,邮件内容包含众多词
一、实验数据环境及指标
编程语言:Python
算法:随机森林算法
数据集:UCI相关数据集

使用pandas库读取数据,sklearn库中的train_test_split函数划分训练集和测试集。
使用CountVectorizer或TfidfVectorizer将文本数据转换为数值特征。
模型训练:
使用随机森林分类器(RandomForestClassifier)进行训练。
模型评估:
使用准确率、召回率、F1 值等指标评估模型性能。
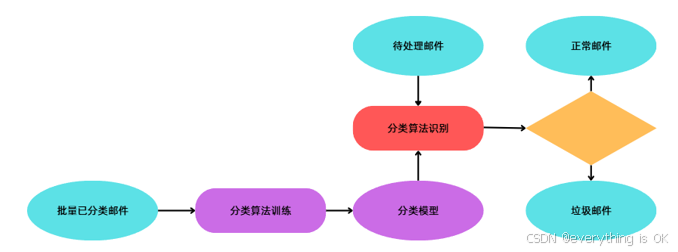
二、相关代码
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import matplotlib.pyplot as plt
# 确保文件路径正确,这里假设SMSSpamCollection在E:\code\python目录下
file_path = r'E:\code\python\SMSSpamCollection'
data = pd.read_table(file_path, sep='\t', names=['label','mem'])
print(data.head())
# 数据预处理
data['label'] = data.label.map({'ham': 0,'spam': 1}) # 0代表正常邮件,1代表垃圾邮件
# 划分训练集与测试集
x_train, x_test, y_train, y_test = train_test_split(data['mem'], data['label'], random_state = 1)
# 词袋模型 word of bag处理文本数据,获得稀疏矩阵表示
count_vector = CountVectorizer(stop_words='english')
train_data = count_vector.fit_transform(x_train)
test_data = count_vector.transform(x_test)
# 用于存储不同n_estimators下的评估指标
n_estimators_list = range(10, 201, 10)
accuracy_scores = []
precision_scores = []
recall_scores = []
f1_scores = []
for n_estimators in n_estimators_list:
random_forest = RandomForestClassifier(n_estimators=n_estimators, random_state = 42)
random_forest.fit(train_data, y_train)
predictions_rf = random_forest.predict(test_data)
accuracy_scores.append(accuracy_score(y_test, predictions_rf))
precision_scores.append(precision_score(y_test, predictions_rf))
recall_scores.append(recall_score(y_test, predictions_rf))
f1_scores.append(f1_score(y_test, predictions_rf))
# 绘制曲线
plt.figure(figsize=(12, 8))
plt.plot(n_estimators_list, accuracy_scores, label='Accuracy')
plt.plot(n_estimators_list, precision_scores, label='Precision')
plt.plot(n_estimators_list, recall_scores, label='Recall')
plt.plot(n_estimators_list, f1_scores, label='F1 - score')
plt.xlabel('Number of Estimators (n_estimators)')
plt.ylabel('Score')
plt.title('Model Performance vs n_estimators')
plt.legend()
plt.grid(True)
plt.show()
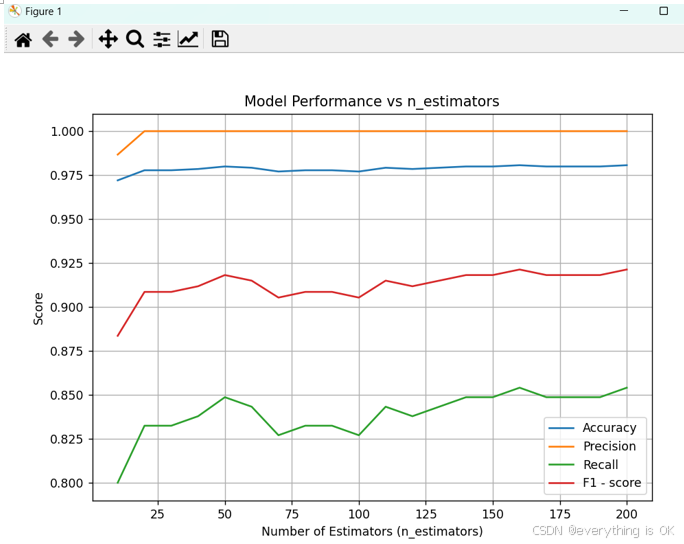
三、实验结果

random forest Accuracy score: 0.9864636209813875
random forest Precision score: 0.9890955740859525
random forest Recall score: 0.9903660886319846
random forest F1 score: 0.9897304236200256
random forest TCR score: 33.170212765957444
四、实验中遇到的关键问题
1、UCI 数据集中存在缺失值,导致随机森林算法无法直接处理。
2、数据集中不同类别的样本数量差异较大,导致随机森林模型对多数类的分类效果较好,而对少数类的分类效果较差。
3、随机森林模型在训练集上表现很好,但在测试集上表现不佳,即模型过度拟合了训练数据中的噪声和细节。
五、总结
随机森林算法作为一种强大的机器学习工具,在垃圾邮件系统构建中发挥着关键作用。其自身具有诸多突出优点,使得它适配垃圾邮件分类任务。一方面,它准确率较高,面对邮件文本中复杂的语言表达、多样的词汇组合等非线性关系,能精准判别垃圾邮件特征,集成多棵决策树的方式有效减少误判。同时,不易过拟合特性保证了在有限的邮件训练样本下,模型依然能稳定学习,对新邮件有良好泛化能力。处理高维数据优势显著,邮件内容包含众多词汇、语法等特征维度,它无需复杂前期处理即可挖掘关键信息用于分类。较强的鲁棒性让模型无惧邮件中偶尔出现的乱码、错误格式等噪声干扰。
不过,应用于垃圾邮件系统时,随机森林的缺点也需留意。模型复杂度高,训练大量决策树会占用可观的内存与计算资源,尤其在处理海量邮件数据时,对系统硬件要求提升。训练耗时久,若要频繁更新模型适应新的垃圾邮件形式,时间成本不可忽视。而且,若垃圾邮件刻意制造大量相似噪声、伪装特征,也可能干扰模型,影响准确率。但总体而言,通过合理调优参数、精心准备训练数据,随机森林可为垃圾邮件系统提供高效可靠的分类方案。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 37
37 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)