机器学习/数据分析--Pandas常用50个基础操作
【代码】机器学习/数据分析--Pandas常用50个基础操作。
·
Python数据分析三大件基础入门已经跟新完毕
- 其余两篇如下:
- Matplotlib:Matplotlib基础入门
- Numpy: 《Python数据科学手册》—Numpy学习笔记(万字)
- 欢迎收藏 + 点赞 + 关注,下一步将更新机器学习/数据分析相关案例
前言
- pandas是python的数据分析库
- pandas学习需要结合实战,一下是pandas的常用操作,可以快速过一遍,留下印象,其他的可以在实战中学习
pandas核心基础操作
- 创建 DataFrame
- 查看数据前几行
- 查看数据后几行
- 查看数据基本信息
- 描述性统计信息
- 选择列
- 选择多列
- 选择行
- 选择特定行和列
- 条件选择
- 多条件选择
- 排序数据
- 处理缺失值
- 填充缺失值
- 新增列
- 删除列
- 重命名列
- 分组统计
- 合并DataFrame
- 横向合并DataFrame
- 合并DataFrame基于键
- 透视表
- 独热编码
- 字符串处理
- 日期时间处理
- 时间序列重采样
- 滑动窗口
- 绘制图标
- 保存DataFrame文件
- 从文件加载数据到DataFrame
- 使用apply函数对列进行操作
- 使用map函数进行值替换
- 使用cut函数进行分箱处理
- 使用groupby和transform进行组内操作
- 使用astype进行数据类型转换
- 使用isin进行过滤
- 使⽤ duplicated 和 drop_duplicates 处理重复值
- 使用nlargest和nsmallest获取最大值和最小值
- 使⽤ value_counts 计算唯⼀值的频率
- 使⽤ str.contains 进⾏模糊匹配
- 使⽤ replace 进⾏值替换
- 使⽤ pivot 进⾏数据透视
- 使⽤ merge 时处理重复列名
- 使⽤ at 和 iat 快速访问元素
- 使⽤ mask 进⾏条件替换
- 使⽤ query 进⾏条件查询
- 使⽤ crosstab 进⾏交叉表
- 使⽤ explode 展开列表
- 使⽤ agg 进⾏多个聚合操作
- 使⽤ pipe 进⾏链式操作
# 1、使用字典创建DataFrame
import pandas as pd
data = {
'ID': [101, 102, 103, 104, 105],
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'Salary': [50000, 60000, 45000, 75000, 55000],
'Status': ['Active', 'Inactive', 'Active', 'Active', 'Inactive']
}
df = pd.DataFrame(data)
df
结果:
| ID | Name | Salary | Status | |
|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | Active |
| 1 | 102 | Bob | 60000 | Inactive |
| 2 | 103 | Charlie | 45000 | Active |
| 3 | 104 | David | 75000 | Active |
| 4 | 105 | Eva | 55000 | Inactive |
# 2、查看数据前几行
df.head() #默认前5行
结果:
| ID | Name | Salary | Status | |
|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | Active |
| 1 | 102 | Bob | 60000 | Inactive |
| 2 | 103 | Charlie | 45000 | Active |
| 3 | 104 | David | 75000 | Active |
| 4 | 105 | Eva | 55000 | Inactive |
# 查看前3行数据
df.head(3)
结果:
| ID | Name | Salary | Status | |
|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | Active |
| 1 | 102 | Bob | 60000 | Inactive |
| 2 | 103 | Charlie | 45000 | Active |
# 3、查看后几行
df.tail() #默认后面5行
结果:
| ID | Name | Salary | Status | |
|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | Active |
| 1 | 102 | Bob | 60000 | Inactive |
| 2 | 103 | Charlie | 45000 | Active |
| 3 | 104 | David | 75000 | Active |
| 4 | 105 | Eva | 55000 | Inactive |
# 查看后3行数据
df.tail(3)
结果:
| ID | Name | Salary | Status | |
|---|---|---|---|---|
| 2 | 103 | Charlie | 45000 | Active |
| 3 | 104 | David | 75000 | Active |
| 4 | 105 | Eva | 55000 | Inactive |
# 4、查看数据基本信息
df.info() #提供DataFrame的基本信息
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 5 non-null int64
1 Name 5 non-null object
2 Salary 5 non-null int64
3 Status 5 non-null object
dtypes: int64(2), object(2)
memory usage: 292.0+ bytes
# 5、描述性统计信息
df.describe()
#提供DataFrame的描述性统计信息,
#包括均值、标准差、最小值、25%分位数、中位数(50%),75%分位数和最大值
结果:
| ID | Salary | |
|---|---|---|
| count | 5.000000 | 5.000000 |
| mean | 103.000000 | 57000.000000 |
| std | 1.581139 | 11510.864433 |
| min | 101.000000 | 45000.000000 |
| 25% | 102.000000 | 50000.000000 |
| 50% | 103.000000 | 55000.000000 |
| 75% | 104.000000 | 60000.000000 |
| max | 105.000000 | 75000.000000 |
# 6、选择列
df['Salary']
结果:
0 50000
1 60000
2 45000
3 75000
4 55000
Name: Salary, dtype: int64
# 7、选择多行
df[['ID', 'Name']]
结果:
| ID | Name | |
|---|---|---|
| 0 | 101 | Alice |
| 1 | 102 | Bob |
| 2 | 103 | Charlie |
| 3 | 104 | David |
| 4 | 105 | Eva |
# 8、选择行
df.loc[2]
结果:
ID 103
Name Charlie
Salary 45000
Status Active
Name: 2, dtype: object
# 9、选择特定行和列
df.loc[1, 'Name']
结果:
'Bob'
# 10、条件选择
df[df['ID'] > 102]
结果:
| ID | Name | Salary | Status | |
|---|---|---|---|---|
| 2 | 103 | Charlie | 45000 | Active |
| 3 | 104 | David | 75000 | Active |
| 4 | 105 | Eva | 55000 | Inactive |
# 11、多条件选择
df[(df['ID'] > 101) & (df['ID'] < 104)]
结果:
| ID | Name | Salary | Status | |
|---|---|---|---|---|
| 1 | 102 | Bob | 60000 | Inactive |
| 2 | 103 | Charlie | 45000 | Active |
# 12、排序数据
df.sort_values(by='Salary', ascending=False) #按工资降序排序
结果:
| ID | Name | Salary | Status | |
|---|---|---|---|---|
| 3 | 104 | David | 75000 | Active |
| 1 | 102 | Bob | 60000 | Inactive |
| 4 | 105 | Eva | 55000 | Inactive |
| 0 | 101 | Alice | 50000 | Active |
| 2 | 103 | Charlie | 45000 | Active |
# 13、处理缺失值
# 删除缺失值行
df.dropna()
结果:
| ID | Name | Salary | Status | |
|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | Active |
| 1 | 102 | Bob | 60000 | Inactive |
| 2 | 103 | Charlie | 45000 | Active |
| 3 | 104 | David | 75000 | Active |
| 4 | 105 | Eva | 55000 | Inactive |
# 14、填充缺失值
#用均值填充所有缺失值
#df.fillna(df.mean())
#特定行进行填充
df['Salary'].fillna(df['Salary'].mean(skipna=True))
#用数值进行填充
#1、计算数值型列的均值
mean_values = df.select_dtypes(include='number').mean()
#2、用均值填充数值型列的缺失值
df[df.select_dtypes(include='number').columns] = df.select_dtypes(include='number').fillna(mean_values)
结果:
0 50000
1 60000
2 45000
3 75000
4 55000
Name: Salary, dtype: int64
# 15、新增列
df['age'] = [18, 19, 20, 21, 22] #列数要一样
# 16、删除列
df.drop('Status',axis=1) #只是显示不出来了而已,实际没有删除
结果:
| EmployeeID | Name | Salary | age | |
|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | 18 |
| 1 | 102 | Bob | 60000 | 19 |
| 2 | 103 | Charlie | 45000 | 20 |
| 3 | 104 | David | 75000 | 21 |
| 4 | 105 | Eva | 55000 | 22 |
# 17、重命名列
df.rename(columns={'ID': 'EmployeeID'}, inplace=True)
# 18、分组统计
# 语法df.groupby('ColumnName').agg({'Colums1': 'mean', 'Column2': 'sum'})
#按状态分组,计算平均年龄和总工资
df.groupby('Status').agg({'age': 'mean', 'Salary': 'sum'})
结果:
| age | Salary | |
|---|---|---|
| Status | ||
| Active | 19.666667 | 170000 |
| Inactive | 20.500000 | 115000 |
# 19、合并DataFrame
#垂直合并
pd.concat([df1, df2], axis=0)
# 20、横向合并DataFrame
pd.concat([df1, df2], axis=1)
# 21、合并DataFrame(基于键)
pd.merge(df1, df2, on='ID', how='inner')
#解释: on:连接键
# how:内连接
# 22、透视表
# 透视表:汇总数据
#创建透视表,计算不同状态下的平均工资
pd.pivot_table(df, values='Salary', index='Status', aggfunc='mean')
结果:
| Salary | |
|---|---|
| Status | |
| Active | 56666.666667 |
| Inactive | 57500.000000 |
# 23、独热编码
# 将分类变量转化为独热编码
pd.get_dummies(df, columns=['Status']) #将Status列进行独热编码
#独热编码: https://blog.csdn.net/zyc88888/article/details/103819604
结果:
| EmployeeID | Name | Salary | age | Status_Active | Status_Inactive | |
|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | 18 | True | False |
| 1 | 102 | Bob | 60000 | 19 | False | True |
| 2 | 103 | Charlie | 45000 | 20 | True | False |
| 3 | 104 | David | 75000 | 21 | True | False |
| 4 | 105 | Eva | 55000 | 22 | False | True |
# 24、字符串处理
# 语法:df['StringColumn'].str.method() 对字符串列进行各种处理、切片、替换等
df['Name'].str.upper()
结果:
0 ALICE
1 BOB
2 CHARLIE
3 DAVID
4 EVA
Name: Name, dtype: object
# 25、日期时间处理
# 语法:df['DateTimeColumn] = pd.to_datetime(df['DateTimeColumn])
#将Data列转化为时间类型数据
df['Date'] = pd.to_datetime(df['Date'])
# 26、时间序列重采样
df.resample('D').sum() #将数据按天数重新采样并求和
# 27、滑动窗口
# 语法: df['Column'].rolling(window=size).mean() 求均值
df['Salary'].rolling(window=3).mean() #和算法中滑动窗口一样
结果:
0 NaN
1 NaN
2 51666.666667
3 60000.000000
4 58333.333333
Name: Salary, dtype: float64
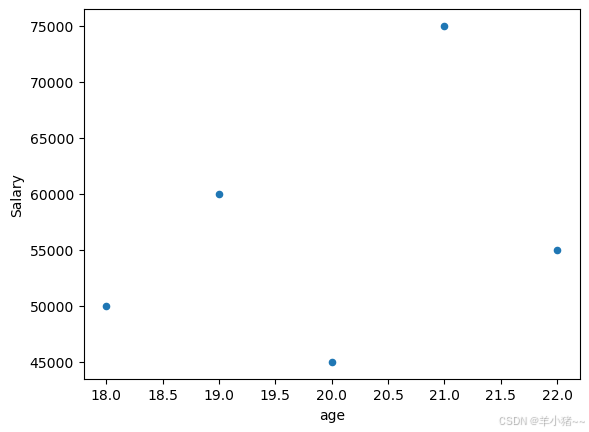
# 28、绘制图标
#用于绘制各种图标
df.plot(x='age', y='Salary', kind='scatter') #绘制散点图
结果:
# 29、保存DataFrame到文件
# 语法:df.to_csv('filename.csv', index=False)
df.to_csv('emplyee_data.csv', index=False)
# 30、从文件加载数据到DataFrame
df = pd.read_csv('emplyee_data.csv')
# 31、使用apply函数对列进行操作
# 语法:df['NewColumn] = df['Column'].apply(……)
#将age的每个元素 *2
df['DouleAge'] = df['age'].apply(lambda x : x * 2)
df
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | |
|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | Active | 18 | 36 |
| 1 | 102 | Bob | 60000 | Inactive | 19 | 38 |
| 2 | 103 | Charlie | 45000 | Active | 20 | 40 |
| 3 | 104 | David | 75000 | Active | 21 | 42 |
| 4 | 105 | Eva | 55000 | Inactive | 22 | 44 |
# 32、使用 map 函数进行值替换
# 语法:df['Status] = df['Status'].map({'Active': 1, 'Inactive': 0})
df['Status'] = df['Status'].map({'Active': 1, 'Inactive': 0})
df
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | |
|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | NaN | 18 | 36 |
| 1 | 102 | Bob | 60000 | NaN | 19 | 38 |
| 2 | 103 | Charlie | 45000 | NaN | 20 | 40 |
| 3 | 104 | David | 75000 | NaN | 21 | 42 |
| 4 | 105 | Eva | 55000 | NaN | 22 | 44 |
# 33、使用 cut 函数进行分箱处理
# cut函数将数值列分为不同的箱子,用标签表示
df['AgeGroup'] = pd.cut(df['age'], bins=[20, 30, 40, 50], labels=['20-30', '30-40', '40-50'])
# bins 分成不同范围的箱子,如: 20-30一个, 30-40一个, 40-50一个
df
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | AgeGroup | |
|---|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | NaN | 18 | 36 | NaN |
| 1 | 102 | Bob | 60000 | NaN | 19 | 38 | NaN |
| 2 | 103 | Charlie | 45000 | NaN | 20 | 40 | NaN |
| 3 | 104 | David | 75000 | NaN | 21 | 42 | 20-30 |
| 4 | 105 | Eva | 55000 | NaN | 22 | 44 | 20-30 |
# 34、使用 groupby 和 transform 进行组内操作
# 计算每个年龄组的平均工资
df['MeanSalaryByAge'] = df.groupby('age')['Salary'].transform('mean')
df
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | AgeGroup | MeanSalaryByAge | |
|---|---|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | NaN | 18 | 36 | NaN | 50000.0 |
| 1 | 102 | Bob | 60000 | NaN | 19 | 38 | NaN | 60000.0 |
| 2 | 103 | Charlie | 45000 | NaN | 20 | 40 | NaN | 45000.0 |
| 3 | 104 | David | 75000 | NaN | 21 | 42 | 20-30 | 75000.0 |
| 4 | 105 | Eva | 55000 | NaN | 22 | 44 | 20-30 | 55000.0 |
# 35、使用astype进行数据类型转换
# 语法:df['NewColumn'] = df['Column'].astype(float)
df['age'] = df['age'].astype(float)
df
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | AgeGroup | MeanSalaryByAge | |
|---|---|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | NaN | 18.0 | 36 | NaN | 50000.0 |
| 1 | 102 | Bob | 60000 | NaN | 19.0 | 38 | NaN | 60000.0 |
| 2 | 103 | Charlie | 45000 | NaN | 20.0 | 40 | NaN | 45000.0 |
| 3 | 104 | David | 75000 | NaN | 21.0 | 42 | 20-30 | 75000.0 |
| 4 | 105 | Eva | 55000 | NaN | 22.0 | 44 | 20-30 | 55000.0 |
# 36、使用isin进行过滤
# 语法: df[df['Column].isin(['value1', 'value2'])]
# 选择 Namw 列包含特定值的行
df[df['Name'].isin(['Alice', 'Bob'])]
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | AgeGroup | MeanSalaryByAge | |
|---|---|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | NaN | 18.0 | 36 | NaN | 50000.0 |
| 1 | 102 | Bob | 60000 | NaN | 19.0 | 38 | NaN | 60000.0 |
# 37、使用 deplicated 和 drop_duplicates 处理重复值
# deplicated 检测重复值,使用drop_duplicates删除重复值
df.duplicated(subset=['Name'])
df.drop_duplicates(subset=['Name'], keep='first')
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | AgeGroup | MeanSalaryByAge | |
|---|---|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | NaN | 18.0 | 36 | NaN | 50000.0 |
| 1 | 102 | Bob | 60000 | NaN | 19.0 | 38 | NaN | 60000.0 |
| 2 | 103 | Charlie | 45000 | NaN | 20.0 | 40 | NaN | 45000.0 |
| 3 | 104 | David | 75000 | NaN | 21.0 | 42 | 20-30 | 75000.0 |
| 4 | 105 | Eva | 55000 | NaN | 22.0 | 44 | 20-30 | 55000.0 |
# 38、使用 nlargest 和 nsmallest 获取最大值和最小值
df.nlargest(5, 'Salary')
df.nsmallest(5, 'Salary')
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | AgeGroup | MeanSalaryByAge | |
|---|---|---|---|---|---|---|---|---|
| 2 | 103 | Charlie | 45000 | NaN | 20.0 | 40 | NaN | 45000.0 |
| 0 | 101 | Alice | 50000 | NaN | 18.0 | 36 | NaN | 50000.0 |
| 4 | 105 | Eva | 55000 | NaN | 22.0 | 44 | 20-30 | 55000.0 |
| 1 | 102 | Bob | 60000 | NaN | 19.0 | 38 | NaN | 60000.0 |
| 3 | 104 | David | 75000 | NaN | 21.0 | 42 | 20-30 | 75000.0 |
# 39、使用 value_counts 计算唯一的频率
# 作用:计算某一列中每个唯一值的个数
df['Status'].value_counts()
结果:
Series([], Name: count, dtype: int64)
# 40、使用 str.contains 进行模糊匹配
# 语法:df[df['Column].str.contains('pattern', case=False, na=False)]
# 可以指定大小写敏感和处理缺失值
df[df['Name'].str.contains('A', case=False, na=False)]
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | AgeGroup | MeanSalaryByAge | |
|---|---|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | NaN | 18.0 | 36 | NaN | 50000.0 |
| 2 | 103 | Charlie | 45000 | NaN | 20.0 | 40 | NaN | 45000.0 |
| 3 | 104 | David | 75000 | NaN | 21.0 | 42 | 20-30 | 75000.0 |
| 4 | 105 | Eva | 55000 | NaN | 22.0 | 44 | 20-30 | 55000.0 |
# 41、使用replace
df.replace({'Active': 'ActiveStatus'}) # 旧值换成新值
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | AgeGroup | MeanSalaryByAge | |
|---|---|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | NaN | 18.0 | 36 | NaN | 50000.0 |
| 1 | 102 | Bob | 60000 | NaN | 19.0 | 38 | NaN | 60000.0 |
| 2 | 103 | Charlie | 45000 | NaN | 20.0 | 40 | NaN | 45000.0 |
| 3 | 104 | David | 75000 | NaN | 21.0 | 42 | 20-30 | 75000.0 |
| 4 | 105 | Eva | 55000 | NaN | 22.0 | 44 | 20-30 | 55000.0 |
# 42、使用pivot进行数据透视
df.pivot(index='EmployeeID', columns='Status', values='Salary')
结果:
| Status | NaN |
|---|---|
| EmployeeID | |
| 101 | 50000 |
| 102 | 60000 |
| 103 | 45000 |
| 104 | 75000 |
| 105 | 55000 |
# 43、使用merge时处理重复列名
pd.merge(df1, df2, left_on='ID', right_on='ID', suffixes=('_lsft', '_right'))
# left_on 左连接列名, right_on 右连接列名
# 44、使用 at 和 iat 快速访问元素
# 语法: df.at[index, 'ColumnName']
# 语法: df.iat[index, columnIndex]
df.at[1, 'Name']
结果:
'Bob'
# 45、使用 mask 进行条件替换
df['Bonus'] = df['Salary'].mask(df['Salary'] > 6000, 'HighBouns')
#最后一个参数是值
df
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | AgeGroup | MeanSalaryByAge | Bonus | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | NaN | 18.0 | 36 | NaN | 50000.0 | HighBouns |
| 1 | 102 | Bob | 60000 | NaN | 19.0 | 38 | NaN | 60000.0 | HighBouns |
| 2 | 103 | Charlie | 45000 | NaN | 20.0 | 40 | NaN | 45000.0 | HighBouns |
| 3 | 104 | David | 75000 | NaN | 21.0 | 42 | 20-30 | 75000.0 | HighBouns |
| 4 | 105 | Eva | 55000 | NaN | 22.0 | 44 | 20-30 | 55000.0 | HighBouns |
# 46、使用 query 进行条件查询
df.query('age > 15')
结果:
| EmployeeID | Name | Salary | Status | age | DouleAge | AgeGroup | MeanSalaryByAge | Bonus | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 101 | Alice | 50000 | NaN | 18.0 | 36 | NaN | 50000.0 | HighBouns |
| 1 | 102 | Bob | 60000 | NaN | 19.0 | 38 | NaN | 60000.0 | HighBouns |
| 2 | 103 | Charlie | 45000 | NaN | 20.0 | 40 | NaN | 45000.0 | HighBouns |
| 3 | 104 | David | 75000 | NaN | 21.0 | 42 | 20-30 | 75000.0 | HighBouns |
| 4 | 105 | Eva | 55000 | NaN | 22.0 | 44 | 20-30 | 55000.0 | HighBouns |
# 47、使用 crosstab 进行交叉表
pd.crosstab(df['Status'], df['age'])
结果:
| age |
|---|
| Status |
# 48、使用 explode 展开包含列表的列
df.explode('Hobbise') #展开“Hobbies”列的列表
# 49、使用agg进行多个聚合操作
df.groupby('Status').agg({'Salary': ['mean', 'min', 'max']})
结果:
| Salary | |||
|---|---|---|---|
| mean | min | max | |
| Status | |||
# 50、使用 pipe 进行链式操作
# pipe 调用多个自定义函数
df.pipe(func1).pipe(func2, arg1='value').pipe(func3)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)