机器学习(二):白话对数几率回归(logistic regression)
一.对数几率回归的定义1.1 广义线性模型在之前的机器学习(一):深入解析线性回归模型一文中所介绍的线性模型都是基于y=wTx+by=w^Tx+by=wTx+b这种形式的。但对于某些数据集虽然其自变量xxx与因变量yyy并不满足一元函数关系,但是可以通过某些函数g(.)g(.)g(.)让输入空间xxx到输出空间yyy的非线性函数映射转换成输入空间xxx到输出空间g(y)g(y)g(y)的线性函数映
一.对数几率回归的定义
1.1 广义线性模型
在之前的机器学习(一):深入解析线性回归模型一文中所介绍的线性模型都是基于 y = w T x + b y=w^Tx+b y=wTx+b这种形式的。但对于某些数据集虽然其自变量 x x x与因变量 y y y并不满足一元函数关系,但是可以通过某些函数 g ( . ) g(.) g(.)让输入空间 x x x到输出空间 y y y的非线性函数映射转换成输入空间 x x x到输出空间 g ( y ) g(y) g(y)的线性函数映射,即:
y = g − 1 ( w T x + b ) y=g^{-1}(w^Tx+b) y=g−1(wTx+b)
其中, g ( . ) g(.) g(.)为单调可微函数。为了方便理解这里也给出一个例子:当 y y y在指数尺度上变化时,我们可以让 l n y lny lny作为线性模型逼近的目标,即 l n y = w T x + b lny=w^Tx+b lny=wTx+b,这就是所谓的对数线性回归,其对应的示意图如下:
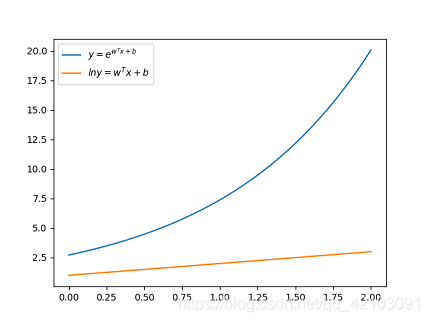
可知在上述例子中 l n ( . ) ln(.) ln(.)函数即为 g ( . ) g(.) g(.) ,它起到了将线性回归模型的预测值与真实标记联系起来的作用。
1.2 对数几率回归的概念
线性回归模型帮助我们用最简单的线性方程实现了对数据的拟合,然而,这只能完成回归任务,无法完成分类任务,若要做分类任务则可以通过寻找一个单调可微函数 g ( . ) g(.) g(.)将分类任务的真实标记 y y y与线性回归模型的预测值联系起来。以二分类任务为例,其输出标记 y ∈ { 0 , 1 } y \in \lbrace 0,1 \rbrace y∈{0,1},而线性回归模型产生的预测值 z = w T x + b z=w^Tx+b z=wTx+b是实值,因此需要将实值 z z z转换为0/1值,而对数几率函数 y = 1 1 + e − z y=\frac{1}{1+e^{-z}} y=1+e−z1正是这样一个符合条件的单调可微函数,其图像如下所示:
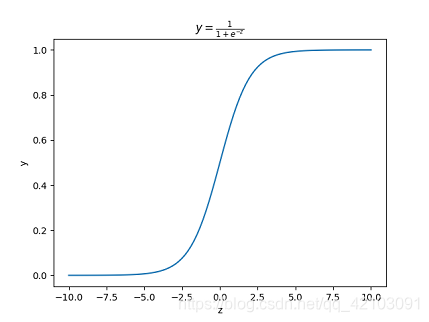
可知对数几率函数将 z z z值转化为一个接近0或1的 y y y值,并且其输出在 z = 0 z=0 z=0附近变化很陡。将 z = w T x + b z=w^Tx+b z=wTx+b带入对数几率函数 y = 1 1 + e − z y=\frac{1}{1+e^{-z}} y=1+e−z1可得:
y = 1 1 + e − ( w T x + b ) y=\frac{1}{1+e^{-(w^Tx+b)}} y=1+e−(wTx+b)1
将 y y y看作样本 x x x作为正例的概率, 1 − y 1-y 1−y是其为反例的概率,两者的比值 y 1 − y = 1 e − ( w T x + b ) = e − ( w T x + b ) \frac{y}{1-y}=\frac{1}{e^{-(w^Tx+b)}}=e^{-(w^Tx+b)} 1−yy=e−(wTx+b)1=e−(wTx+b)称为几率,几率反映了 x x x作为正例的相对可能性,对几率取对数得到对数几率如下:
l n y 1 − y = w T x + b ln\frac{y}{1-y}=w^Tx+b ln1−yy=wTx+b
可知上述公式实际上是使用线性回归模型的预测结果逼近真实标记的对数几率,因此该模型被称为对数几率回归(logistic regression)。由对数几率回归模型可知,当 y > 1 − y y>1-y y>1−y时,则 y 1 − y > 1 \frac{y}{1-y}>1 1−yy>1, l n y 1 − y > 0 ln\frac{y}{1-y}>0 ln1−yy>0;当 y < 1 − y y<1-y y<1−y时,则 y 1 − y < 1 \frac{y}{1-y}<1 1−yy<1, l n y 1 − y < 0 ln\frac{y}{1-y}<0 ln1−yy<0。因此对数几率大于0时判为正例,当对数几率小于0时判为反例,否则可以任意判别。
二.模型参数确定
2.1 极大似然估计
先举个栗子吧:猎人师傅和徒弟一同去打猎,遇到一只兔子,师傅和徒弟同时放枪,兔子被击中一枪,那么是师傅打中的,还是徒弟打中的?显然一般我们都会猜测是师傅打中的,因为师傅的枪法一般高于徒弟。而这样猜测是基于一个理论:概率最大的事件,最可能发生,这其中体现的就是极大似然估计的数学思想。通俗来理解,极大似然估计就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值!
这里从数学上再给出一个例子:设一批产品中有合格品和不合格品,我们现在需要计算一批产品的不合格品率 p p p。从中任取一个产品,用随机变量 X X X表示其合格与否, X = 0 X=0 X=0表示该产品是合格品, X = 1 X=1 X=1表示该产品是不合格品,则 X X X服从两点分布 B ( 1 , p ) B(1,p) B(1,p),现随机选取 n n n个产品 X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X1,X2,...,Xn检查其是否合格,得到样本的观测值 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn,其概率为:
P { X 1 = x 1 , X 2 = x 2 , . . . , X n = x n } = ∏ i = 1 n p x i ( 1 − p ) 1 − x i = p ∑ i = 1 n x i ( 1 − p ) n − ∑ i = 1 n x i P\lbrace X_1=x_1,X_2=x_2,...,Xn=x_n \rbrace=\prod_{i=1}^n p^{x_i}(1-p)^{1-x_i}=p^{\sum_{i=1}^nx_i}(1-p)^{n-\sum_{i=1}^nx_i} P{X1=x1,X2=x2,...,Xn=xn}=i=1∏npxi(1−p)1−xi=p∑i=1nxi(1−p)n−∑i=1nxi
在这个例子中,我们已知的是一组 n n n个产品的观测值 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn,未知的是不合格品率 p p p,那么我们如何选择参数 p p p呢,根据概率最大的事件最可能发生的思想,我们只需要找到使得上述概率 P P P最大所对应的 p p p即可。
2.2 w w w和 b b b的确定
前面提过可以把 y y y理解为一个样本是正例的概率,把 1 − y 1-y 1−y理解为一个样本是反例的概率,若将 y y y和 1 − y 1−y 1−y分别视为类后验概率估计 p ( y = 1 ∣ x ) p(y=1|x) p(y=1∣x)和 p ( y = 0 ∣ x ) p(y=0|x) p(y=0∣x),则显然有:
p ( y = 1 ∣ x ) = 1 1 + e − ( w T x + b ) = e w T x + b 1 + e ( w T x + b ) p ( y = 0 ∣ x ) = 1 − P ( y = 1 ∣ x ) = 1 1 + e w T x + b p(y=1|x) = \frac{1}{1+e^{-(w^Tx+b)}}=\frac{e^{w^Tx+b}}{1+e^(w^Tx+b)} \\ p(y=0|x) = 1 - P(y=1|x) = \frac{1}{1 + e^{w^Tx+b}} p(y=1∣x)=1+e−(wTx+b)1=1+e(wTx+b)ewTx+bp(y=0∣x)=1−P(y=1∣x)=1+ewTx+b1
假设给定的数据集为 D = { ( x i , y i ) } ( i ∈ [ 1 , m ] ) D=\lbrace (x_i,y_i) \rbrace (i \in [1,m]) D={(xi,yi)}(i∈[1,m]),再用 p ( y i ∣ x i ; w , b ) p(yi|xi;w,b) p(yi∣xi;w,b)表示参数为 w w w和 b b b下,已知自变量为 x i x_i xi,而预测值为 y i y_i yi的概率,则根据极大似然估计法我们可以得出:
P = ∏ i = 1 m p ( y i ∣ x i ; w , b ) P= \prod_{i=1}^m p(yi|xi;w,b) P=i=1∏mp(yi∣xi;w,b)
但是由于预测概率都是小于1的,如果直接对所有样本的预测概率求积,所得的数会非常小,当样例数较多时,会超出精度限制。所以,一般来说会对概率取对数,得到对数似然 ℓ ( w , b ) ℓ(w,b) ℓ(w,b),此时求所有样本的预测概率之积就变成了求所有样本的对数似然之和,即:
ℓ ( w , b ) = ∑ i = 1 m l n ( p ( y i ∣ x i ; w , b ) ) ℓ(w,b)=\sum_{i=1}^m ln(p(yi|xi;w,b)) ℓ(w,b)=i=1∑mln(p(yi∣xi;w,b))
而我们的目标就是最大化对数似然 ℓ ( w , b ) ℓ(w,b) ℓ(w,b),此时的 w w w和 b b b就是我们的最优解。参考周志华的《机器学习》中的表示,我们令 β = ( w ; b ) \beta=(w;b) β=(w;b), x ^ = ( x ; 1 ) \widehat{x}=(x;1) x
=(x;1),则 w T x + b w^Tx+b wTx+b可表示为 β T x ^ \beta^T \widehat x βTx
,再令 p 1 ( x ^ ; β ) = p ( y = 1 ∣ x ^ ; β ) p_1(\widehat x;\beta)=p(y=1|\widehat x;\beta) p1(x
;β)=p(y=1∣x
;β), p 0 ( x ^ ; β ) = p ( y = 0 ∣ x ^ ; β ) = 1 − p 1 ( x ^ ; β ) p_0(\widehat x;\beta)=p(y=0|\widehat x;\beta)=1-p_1(\widehat x;\beta) p0(x
;β)=p(y=0∣x
;β)=1−p1(x
;β),则 ℓ ( w , b ) ℓ(w,b) ℓ(w,b)可以重写为:
ℓ ( w , b ) = ℓ ( β ) = ∑ i = 1 m l n ( y i p 1 ( x i ^ ; β ) + ( 1 − y i ) p 0 ( x i ^ ; β ) ) = ∑ i = 1 m l n ( y i e β T x ^ i 1 + e β T x ^ i + 1 − y i 1 + e β T x ^ i ) = ∑ i = 1 m ( l n ( y i e β T x ^ i + 1 − y i ) − l n ( 1 + e β T x ^ i ) ) \begin{aligned} ℓ(w,b) = ℓ(\beta) & =\sum_{i=1}^m ln (y_ip_1(\widehat {x_i};\beta) + (1-y_i)p_0(\widehat {x_i};\beta))\\ & = \sum_{i=1}^m ln(\frac{y_ie^{\beta^T\widehat x_i}}{1+e^{\beta^T\widehat x_i}}+\frac{1-y_i}{1 + e^{\beta^T\widehat x_i}}) \\ & = \sum_{i=1}^m (ln(y_ie^{\beta^T\widehat x_i} + 1 - y_i) -ln(1 + e^{\beta^T\widehat x_i})) \end{aligned} ℓ(w,b)=ℓ(β)=i=1∑mln(yip1(xi
;β)+(1−yi)p0(xi
;β))=i=1∑mln(1+eβTx
iyieβTx
i+1+eβTx
i1−yi)=i=1∑m(ln(yieβTx
i+1−yi)−ln(1+eβTx
i))
考虑到 y i ∈ { 0 , 1 } y_i \in \lbrace 0,1 \rbrace yi∈{0,1}可得:
- 当 y i = 0 y_i=0 yi=0时, ℓ ( β ) = − l n ( 1 + e β T x ^ i ) ℓ(\beta)=-ln(1+e^{\beta^T\widehat x_i}) ℓ(β)=−ln(1+eβTx i)
- 当 y i = 1 时 y_i=1时 yi=1时, ℓ ( β ) = β T x ^ i − l n ( 1 + e β T x ^ i ) ℓ(\beta) = \beta^T\widehat x_i-ln(1+e^{\beta^T\widehat x_i}) ℓ(β)=βTx i−ln(1+eβTx i)
综上可得,只要在 y i = 1 y_i=1 yi=1时所对应的公式中的 β T x ^ i \beta^T\widehat x_i βTx
i项前加上 y i y_i yi就可以合并以上两种情况了,即:
ℓ ( β ) = ∑ i = 1 m ( y i β T x ^ i − l n ( 1 + e β T x ^ i ) ) ℓ(\beta) = \sum_{i=1}^m (y_i\beta^T\widehat x_i-ln(1+e^{\beta^T\widehat x_i})) ℓ(β)=i=1∑m(yiβTx
i−ln(1+eβTx
i))
但是为了能够求解,我们将 ℓ ( β ) ℓ(\beta) ℓ(β)的最大值转换成了求解 − ℓ ( β ) -ℓ(\beta) −ℓ(β)最小值,即:
ℓ ( β ) = ∑ i = 1 m ( − y i β T x ^ i + l n ( 1 + e β T x ^ i ) ) ℓ(\beta) = \sum_{i=1}^m (-y_i\beta^T\widehat x_i+ln(1+e^{\beta^T\widehat x_i})) ℓ(β)=i=1∑m(−yiβTx
i+ln(1+eβTx
i))
之所以要这样转换是因为 − ℓ ( β ) -ℓ(\beta) −ℓ(β)是高阶连续凸函数,它可以通过数值优化算法来求得最优解,常见的数值优化算法有梯度下降法,关于梯度下降这里推荐一篇超级好的博客——深入浅出–梯度下降法及其实现。
根据梯度下降法,首先需要对 ℓ ( β ) ℓ(\beta) ℓ(β)求导,其对应的结果如下:
∂ ℓ ( β ) ∂ β = ∑ i = 1 m − y i x ^ i + e β T x ^ i 1 + e β T x ^ i x ^ i = − ∑ i = 1 m x ^ i ( y i − p 1 ( x ^ i ; β ) ) \begin{aligned} \frac{\partial ℓ(\beta)}{\partial \beta} & = \sum_{i=1}^m -y_i\widehat x_i+\frac{e^{\beta^T\widehat x_i}}{1+e^{\beta^T\widehat x_i}}\widehat x_i \\ & = -\sum_{i=1}^m \widehat x_i(y_i-p_1(\widehat x_i;\beta)) \end{aligned} ∂β∂ℓ(β)=i=1∑m−yix
i+1+eβTx
ieβTx
ix
i=−i=1∑mx
i(yi−p1(x
i;β))
则参数更新过程中,第 t + 1 t+1 t+1轮迭代的更新公式为:
β t + 1 = β t − l r × ∂ ℓ ( β ) ∂ β \beta^{t+1}=\beta^t-lr\times \frac{\partial ℓ(\beta)}{\partial \beta} βt+1=βt−lr×∂β∂ℓ(β)
其中 l r lr lr为学习率。
三.模型实现
3.1 数据集的生成
首先通过numpy随机生成了一个数据集,数据集中包含1000个点,点分为两大类 { 0 , 1 } \lbrace 0,1 \rbrace {0,1},每类各包含500个点,数据集展示如下:
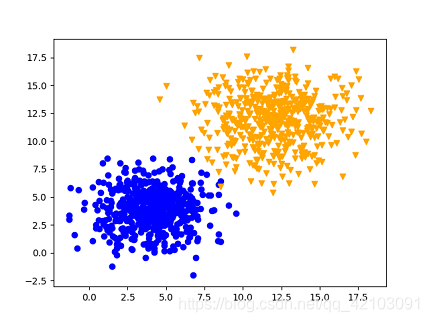
对应的数据集生成源码如下:
def generateDataset(train_rate=0.7,size=1000):
"""
功能:生成数据集并按7:3划分训练集和测试集
train_rate:训练集所占比例,剩下的即为测试集
size:数据集大小
"""
#两种标签的数据量各占一半
label_size = size // 2
#标签为0的数据点生成
x11 = np.random.normal(4,1.8,label_size).reshape(-1,1)
x12 = np.random.normal(4,1.8,label_size).reshape(-1,1)
y1 = np.zeros(shape=(label_size,1))
#标签为1的数据集点生成
x21 = np.random.normal(12,2.3,label_size).reshape(-1,1)
x22 = np.random.normal(12,2.3,label_size).reshape(-1,1)
y2 = np.ones(shape=(label_size,1))
#合并成完整的数据集
x1 = np.vstack((x11,x21))
x2 = np.vstack((x12,x22))
ones = np.ones(shape=(size,1))
x = np.hstack((x1,x2,ones))
y = np.vstack((y1,y2))
#输出两类标签的横纵坐标,是为了后面可视化展示方便
return (x11,x12,x21,x22),x,y
3.2 对数几率回归模型实现
我们的目标是寻找一条直线 w 1 x + w 2 y + b = 0 w_1x+w_2y+b=0 w1x+w2y+b=0,使得其刚好能够将上述两种标签的点分割开来,参照第二节的介绍对数几率回归实现如下,为了方便理解,这里给出一些参数说明:其中beta表示 β \beta β,beta_x表示 β T x ^ i \beta^T\widehat x_i βTx
i,lbeta表示 ℓ ( β ) ℓ(\beta) ℓ(β),dbeta表示 ∂ ℓ ( β ) ∂ β \frac{\partial ℓ(\beta)}{\partial \beta} ∂β∂ℓ(β):
import numpy as np
from numpy import linalg
from data import generateDataset,spiltDataset
import matplotlib.pyplot as plt
def initializeBeta(feature_nums):
"""
功能:初始化参数Beta=(w;b)
"""
beta = np.zeros(shape=(feature_nums,1))
beta[-1] = 1
return beta
def train(train_x,train_y,iterations=100,learning_rate=0.001):
"""
功能:模型训练
train_x,train_y:训练数据特征集,训练数据标签集
iterations:迭代次数
learning_rate
"""
train_x,train_y = train_x.T,train_y.reshape(-1)
#初始化beta参数
beta = initializeBeta(train_x.shape[0])
#开始训练
for i in range(iterations):
#beta与xi相乘
beta_x = np.dot(beta.T[0], train_x)
#计算l(beta)
lbeta = np.sum(-1 * train_y*beta_x + np.log(1 + np.exp(beta_x)))
#l(beta)对beta求偏导
dbeta = np.dot(train_x,-1*train_y + np.divide(np.exp(beta_x),1+np.exp(beta_x))).reshape(-1,1)
#更新beta
beta -= dbeta*learning_rate
#print('iteraing {} times lbeta is {}'.format(i + 1,lbeta))
return beta
def test(test_x,test_y,beta):
"""
功能:计算测似集的准确率
test_x,test_y:测试数据特征集,测试数据标签集
"""
#计算出预测值
pred_y = np.dot(beta.T[0],test_x)
#预测值y>0则为正例1,否则为反例0
pred_y[pred_y >= 0] = 1
pred_y[pred_y < 0] = 0
#计算预测的准确率
bingo = 0
for i,yi in enumerate(pred_y):
if yi == test_y[i]:#预测正确
bingo += 1
#print(bingo,test_y.shape[0])
return bingo / test_y.shape[0]
if __name__ == "__main__":
#生成数据集
points,x,y = generateDataset()
#划分训练集与测试集
train_x,test_x,train_y,test_y = spiltDataset(x,y)
#训练并获得超级参数
beta = train(train_x,train_y)
print(beta)
test_x,test_y = test_x.T,test_y.reshape(-1)
#测试模型在测试集上的准确率
acc = test(test_x,test_y,beta)
print('the acc of test dataset is {}'.format(acc))
x11,x12,x21,x22 = points
plt.scatter(x11,x12,c='b',marker='o')
plt.scatter(x21,x22,c='orange',marker='v')
x3 = np.random.randint(0,15,size=1000)
w1,w2,b = beta[0][0],beta[1][0],beta[2][0]
#w1x11 + w2x12 + b = 0即为我们要找的直线,且x12实际上就是y
y3 = -1*(w1*x3 + b) / w2
plt.plot(x3,y3,c='r')
plt.show()
上述代码的运行结果如下图所示,其中红色的线即为我们所求的直线 w 1 x + w 2 y + b = 0 w_1x+w_2y+b=0 w1x+w2y+b=0:
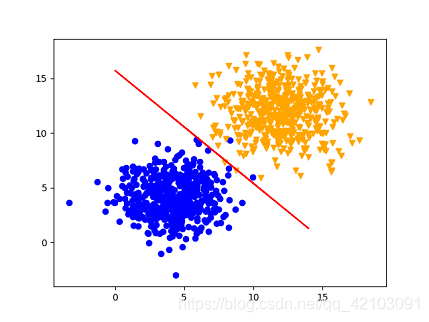
四.参考文献
- 对数几率回归 —— Logistic Regression
- 一文搞懂极大似然估计
- 对数几率回归(西瓜书公式推导)
- 用对数几率回归实现周志华《机器学习》习题3.3西瓜分类,python编程
- 《机器学习》——周志华
以上便是本文的全部内容,要是觉得不错的话,可以点个赞或关注一下博主,后续还会持续带来各种干货,当然要是有问题的话也请批评指正!!!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)