机器学习(7)--K-means 和DBSCAN
K-Means算法。
原理上来讲,K-Means算法其实是假设我们数据的分布是K个sigma相同的高斯分布的,每个分布里有N1,N2……Nk个样本,其均值分别是Mu1,Mu2……Muk,那么这样的话每个样本属于自己对应那个簇的似然概率就是
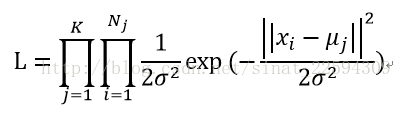
这个套路我们就很熟悉了,下面就是取对数似然概率,要求似然概率的最大值,给它加个负号就可以作为损失函数了,考虑到所有簇的sigma是相等的,所以我们就可到了K-Means的损失函数
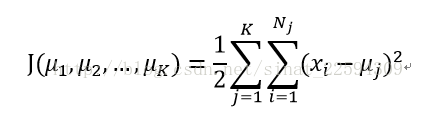
接着我们对损失函数求导数为0,就可以得到更新后最佳的簇中心了
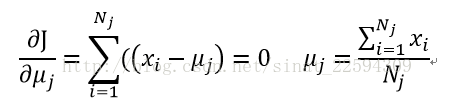
这样我们就得到了所谓的K-Means算法
1 初始选择K个类别中心。
2 将每个样本标记为距离类别中心最近的那个类别。
3 将每个类别中心更新为隶属该类别所有点的中心。
4 重复2,3两步若干次直至终止条件(迭代步数,簇中心变化率,MSE等等)
现在我们回过头来看看K-Means算法的问题。
首先,正如我刚开始介绍它的时候,它是假设数据服从sigma相同的混合高斯分布的,所以最后分类的结果肯定是若干个类圆形的区域,这就很大程度上限制了它的应用范围,如果我们的数据是那种比较奇葩的形状,比如什么扇形啊,圆环啊,你会发现K-Means的效果其实不是很叫人满意。
其次,你得给出这个分类的数目K啊,有一定的先验条件还好,如果是两眼一抹黑,怎么确定呢?猜呗,或者试呗,用一定的评价标准选择最佳那个就成。还有就是初始簇中心的选择,K-Means的结果对初值是敏感的,比如说样本分为三个簇,你一开始把两个中心定在某一个簇中,还有一个中心处在另外两个簇的中间,这样最后的结果很可能是那两个簇被划分成一类,还有一个簇被强行划分成两个簇这样。所以为了解决这个初值敏感问题,又提出了K-Means++算法,它的做法就是你先随机指定第一个簇中心,然后计算所有点到该簇中心的距离,以这个距离作为权值来选择下一个簇中心,一定程度上可以解决簇中心初值选择不合理的问题。
最后还有一个问题,就类似于上一篇我们讲的SVM一样,如果我们采用线性可分SVM方法,一个异常点就可以把我们的分割超平面带跑偏导致泛化能力被削弱。K-Means中我们采用均值来更新簇中心,同样的,一个异常点会导致新的这个簇中心发生比较大的偏离,而且再更新的时候我们还是要考虑那个异常点,所以就不会得到比较好的效果。
说了这么多K-Means的缺点都显得它一无是处了,我们还是要说K-Means作为一种最经典的聚类算法,它简单,快速,在应对大数据的时候相对优势会比较大,有的时候还可以作为其他聚类算法中的一步。
====================================================================
DBSCAN算法。
前面讲了K-Means算法主要针对那种类圆形区域数据的聚类,相对来说应用范围窄了一点。而密度聚类可以弥补这个缺点,可用于任何形状的聚类。这个算法需要我们调节两个参数,半径sigma,最小数目m,先介绍该算法的一些概念
核心对象:对于一个对象它的sigma领域内至少有m个对象,那我们就称之为核心对象
直接密度可达:如果一个对象处在一个核心对象的sigma领域内,那称这两个对象直接密度可达
密度可达(相连):如果一个对象a和b直接密度可达,对象b和c也是直接密度可达,那么我们称a和c是密度可达的,也称这两个对象是密度相连的。
DBSCAN的算法就是我们先找到一个核心对象,从它出发,确定若干个直接密度可达的对象,再从这若干个对象出发,寻找它们直接密度可达的点,直至最后没有可添加的对象了,那么一个簇的更新就完成了。我们也可以说,簇其实就是所有密度可达的点的集合。
它的优势在哪儿呢?
首先,它对这个簇的形状没要求,只要这些点密度可达我们就把它归为一个簇,这样不管你的形状多奇葩,最后我们都能把它分到同一个簇当中。
其次,我们可以想一下那些异常点,它偏离正常对象很多,所以它既不是核心对象,然后对其它的点又不是密度可达的,所以最后就被剩了出来没被分类。因此DBSCAN算法还有一定的剔除异常值的功能,当然里,这里也要注意,如果我们的sigma值太大或者m太小,还是会导致一些异常值浑水摸鱼混进某些簇里或者自成一类等等,总而言之,还是要根据分类的结果进行调参,寻找最佳的分类方式。
Python实现:
from sklearn.cluster import KMeans
km=KMeans(k)#k为聚簇的数目
km.fit(X)iris上实现K-means
载入数据集
#导入iris的数据集
import pandas
iris =pandas.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header=None)
iris.columns=['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species']进行探索性数据分析,根据PetalWidthCm,PetalLengthCm绘制出三个类别的鸢尾花
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
g=sns.FacetGrid(iris,hue='Species')
g.set(xlim=(0,2.5),ylim=(0,7))
g.map(plt.scatter,'PetalWidthCm','PetalLengthCm').add_legend()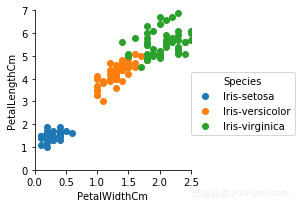
Kmeans聚类
1.设置分类数参数为2
from sklearn.cluster import KMeans
#选取iris聚类特征
X=iris[['PetalWidthCm','PetalLengthCm']]
#设定模型参数
km=KMeans(2)
#训练模型
km.fit(X)
#得到聚类结果
iris['cluster_k2']=km.predict(X)
km.predict(X)
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
g=sns.FacetGrid(iris,hue='cluster_k2')
g.set(xlim=(0,2.5),ylim=(0,7))
g.map(plt.scatter,'PetalWidthCm','PetalLengthCm').add_legend()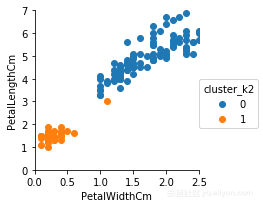
设置分类数参数为3
from sklearn.cluster import KMeans
#选取iris聚类特征
X=iris[['PetalWidthCm','PetalLengthCm']]
#设定模型参数
km=KMeans(3)
#训练模型
km.fit(X)
#得到聚类结果
iris['cluster_k2']=km.predict(X)
km.predict(X)
g=sns.FacetGrid(iris,hue='cluster_k2')
g.set(xlim=(0,2.5),ylim=(0,7))
g.map(plt.scatter,'PetalWidthCm','PetalLengthCm').add_legend()
#看看和之前的绘图结果有什么样的区别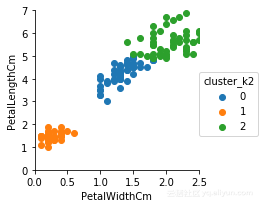
很ok,看看和一开始的那张图(也就是正确分类的图)比较一下,是不是很相似?
iris上实现DBSCAN
生成数据集
from sklearn import datasets
from pandas import DataFrame
noisy_circles=datasets.make_circles(n_samples=1000,factor=.5,noise=.05)
print(noisy_circles)
df=DataFrame()
df['x1']=noisy_circles[0][:,0]
df['x2']=noisy_circles[0][:,1]
df['label']=noisy_circles[1]
df.sample(10)(array([[ 0.67533655, -0.68506843],
[ 0.45998261, 0.21745649],
[ 0.89143489, -0.06072569],
...,
[ 0.5703842 , 0.87910732],
[ 0.5663019 , -0.75688068],
[ 1.03654422, 0.05237379]]), array([0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0,
1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0,
1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0,
1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1,
0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0,
0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0,
0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1,
0, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0,
1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1,
0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1,
1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 1,
1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0,
1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0,
1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0,
0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1,
0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1,
1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1,
1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0,
0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1,
1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0,
1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0,
0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1,
0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1,
1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1,
1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1,
1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1,
0, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0,
0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1,
0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1,
0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0,
1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0,
1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 0,
0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1,
1, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1,
1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0,
0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0,
1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0,
0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1,
1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1,
0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0], dtype=int64))
| x1 | x2 | label | |
|---|---|---|---|
| 554 | 0.951496 | -0.573552 | 0 |
| 509 | 0.176190 | 0.435655 | 1 |
| 612 | -0.267315 | -0.927010 | 0 |
| 983 | 0.476075 | 0.092146 | 1 |
| 729 | 0.795222 | -0.474817 | 0 |
| 928 | -0.351494 | -0.449584 | 1 |
| 313 | 0.493773 | 0.280621 | 1 |
| 204 | -0.073940 | -0.493139 | 1 |
| 984 | 0.080212 | -0.497828 | 1 |
| 796 | 0.725219 | 0.750190 | 0 |
进行探索性数据分析
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
g=sns.FacetGrid(df,hue='label')
g.map(plt.scatter,'x1','x2').add_legend()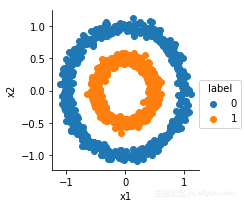
DBSCAN
from sklearn.cluster import DBSCAN
dbscan=DBSCAN(eps=0.2,min_samples=10)
X=df[['x1','x2']]
dbscan.fit(X)
df['dbscan_label']=dbscan.labels_
g=sns.FacetGrid(df,hue='dbscan_label')
g.map(plt.scatter,'x1','x2').add_legend()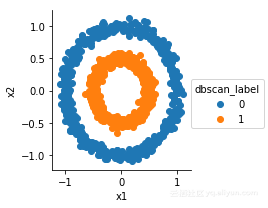
ok!很完美!
但是,DBSCAN对参数设置特别敏感
比如,我们可以尝试修改epsilon
from sklearn.cluster import DBSCAN
dbscan=DBSCAN(eps=0.1,min_samples=10)
X=df[['x1','x2']]
dbscan.fit(X)
df['dbscan_label']=dbscan.labels_
g=sns.FacetGrid(df,hue='dbscan_label')
g.map(plt.scatter,'x1','x2').add_legend()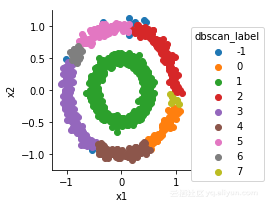
from sklearn.cluster import DBSCAN
dbscan=DBSCAN(eps=0.3,min_samples=10)
X=df[['x1','x2']]
dbscan.fit(X)
df['dbscan_label']=dbscan.labels_
g=sns.FacetGrid(df,hue='dbscan_label')
g.map(plt.scatter,'x1','x2').add_legend()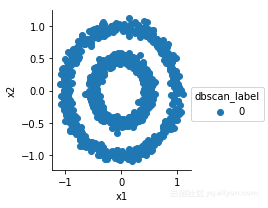

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)