仅需单卡14G显存!手把手教你训练+推理爆火开源模型 DeepSeek-R1
Deepseek RI最近火爆全网,甚至影响到了全球经济走势和政治格局,不得不说AI依然在迅猛的发展,R1的内置COT理念——就是人类的慢思考。人的大脑有两个系统:系统一基于潜意识,快速做出判断,称为“快思考”;系统二则相反,处理复杂问题,但需要专注力和精力,称为“慢思考”。两者相互影响,大多数偏见来自系统一,但可以通过训练改善。R1开始让AI有了”系统二“的能力,是一种高阶的智慧,最先让AI有慢
Deepseek RI最近火爆全网,甚至影响到了全球经济走势和政治格局,不得不说AI依然在迅猛的发展,R1的内置COT理念——就是人类的慢思考。
人的大脑有两个系统:系统一基于潜意识,快速做出判断,称为“快思考”;系统二则相反,处理复杂问题,但需要专注力和精力,称为“慢思考”。两者相互影响,大多数偏见来自系统一,但可以通过训练改善。
R1开始让AI有了”系统二“的能力,是一种高阶的智慧,最先让AI有慢思考能力的是openai的o1模型,不过o1不仅昂贵,而且是闭源的,是少数人才能接触到的资源。Deepseek R1 通过大量的创新,通过极低的成本训练出来有推理能力(慢思考能力)的AI,同时将训练方法进行了开源,引爆了整个技术和非技术圈。
今天笔者采用colab免费14G显存的单卡在qwen2.5-7B上面简单复现一下Deepseek RI的推理能力。
效果展示
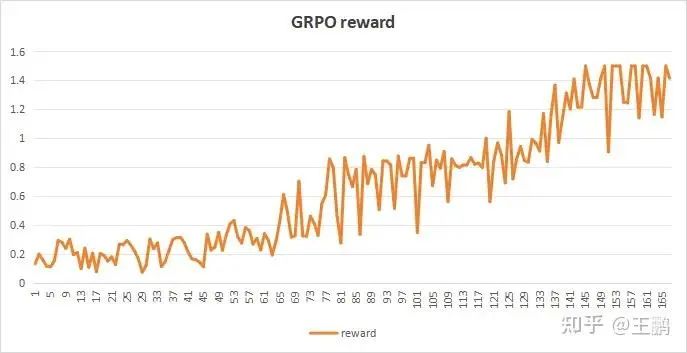
训练了100step后的效果,模型已经能够通过推理解答数学题目了,同时可以看到此时GRPO的reward得分也在提升到一个新的水平。
Question:哈利的图书馆里有 50 本书。他的妹妹弗洛拉(Flora)拥有的书籍数量是哈利的两倍,而他们的表弟加里(Gary)拥有的书籍数量是哈利的一半。他们三人总共拥有多少本书? (Answer: 175) Response:<reasoning>哈利有50本书。弗洛拉拥有的书籍数量是哈利的两倍,即100本。加里拥有的书籍数量是哈利的一半,即25本。他们三人共有的书籍数量是50 + 100 + 25 = 175本。</reasoning><answer>175</answer>Question:由于新冠病毒的限制,当地商店老板特伦特先生将店内商品的价格每件提高了15%,以维持与之前相同的收入。如果购买一个橙子的价格为 40 美元,购买一个芒果的价格为 50 美元,请计算现在以新价格购买 10 个橙子和 10 个芒果总共需要花费多少钱。 (Answer:1035 )Response:<reasoning>原价总和:10 * 40 + 10 * 50 = 400 + 500 = 900提价幅度:15%提价后总和:900 * (1 + 15%) = 900 * 1.15 = 1035</reasoning><answer>1035</answer>grpo reward
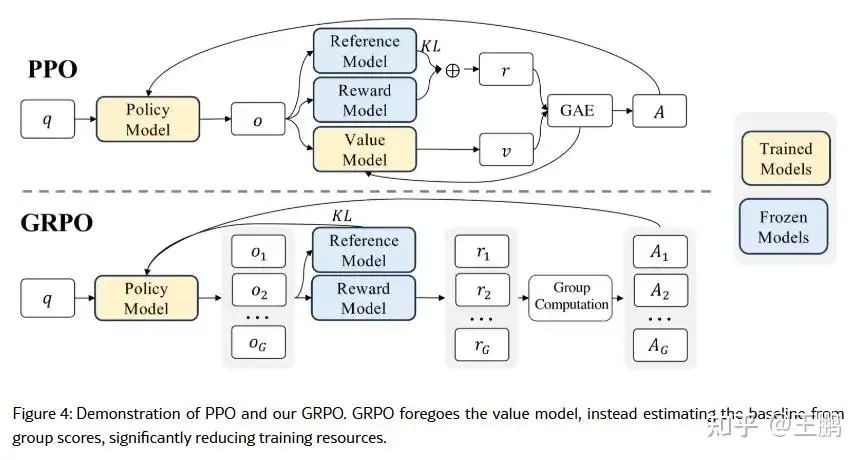
GRPO算法简介
DeepseekR1的推理能力,是从强化学习GRPO进行冷启动的,没有采用大量的标注数据,直接通过强化学习就让模型有了很强的推理能力。那GRPO到底是个什么呢。如下图所示, 在传统的近端策略优化算法(PPO)中,通常需要同时训练策略模型和价值模型,后者用于估计每个状态的期望回报,并以此作为优势函数的基线。对于大型语言模型来说,训练与策略模型规模相当的价值网络不仅增加了计算量,还会带来显著的内存开销。为了解决这一问题,GRPO 提出了利用“组内”生成数据的思路:
-
多样本生成:对于每个输入(例如一个问题),模型根据旧策略生成多个候选输出。
-
奖励评估: 对每个候选输出采用特定的奖励函数进行评估,奖励可以包括答案正确性、格式符合要求、推理过程合理等指标(例如 DeepSeek 系列中常用的准确性奖励和格式奖励)
-
组内优势计算: 将这组输出的奖励视为一个样本集,直接计算其均值和标准差,并将每个输出的奖励进行标准化(即减去均值、除以标准差),从而获得组内相对优势。这种方式能够反映出同一问题下各个候选答案的“相对好坏”,而不需要单独训练一个价值模型。
其优势省去价值网络,占用资源少,同时训练稳定性较PPO要高。
训练过程
加载模型:
安装必要的包,同时加载量化后的模型,同时增加lora参数作为训练参数,这里使用的qwen2.5-7B。
%%capture# Skip restarting message in Colabimport sys; modules = list(sys.modules.keys())for x in modules: sys.modules.pop(x) if "PIL" in x or "google" in x else None!pip install unsloth vllm!pip install --upgrade pillow# If you are running this notebook on local, you need to install `diffusers` too# !pip install diffusers# Temporarily install a specific TRL nightly version!pip install git+https://github.com/huggingface/trl.git@e95f9fb74a3c3647b86f251b7e230ec51c64b72bfrom unsloth import FastLanguageModel, PatchFastRLPatchFastRL("GRPO", FastLanguageModel)from unsloth import is_bfloat16_supportedimport torchmax_seq_length = 1024 # Can increase for longer reasoning traceslora_rank = 32 # Larger rank = smarter, but slowermodel, tokenizer = FastLanguageModel.from_pretrained( model_name = "Qwen/Qwen2.5-7B-Instruct", max_seq_length = max_seq_length, load_in_4bit = True, # False for LoRA 16bit fast_inference = True, # Enable vLLM fast inference max_lora_rank = lora_rank, gpu_memory_utilization = 0.6, # Reduce if out of memory)model = FastLanguageModel.get_peft_model( model, r = lora_rank, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128 target_modules = [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", ], # Remove QKVO if out of memory lora_alpha = lora_rank, use_gradient_checkpointing = "unsloth", # Enable long context finetuning random_state = 3407,)加载数据:
数据长这样,就是一个数学问题,一个答案,答案是数字。没有任何推理数据,后面靠强化学习让模型学会推理。
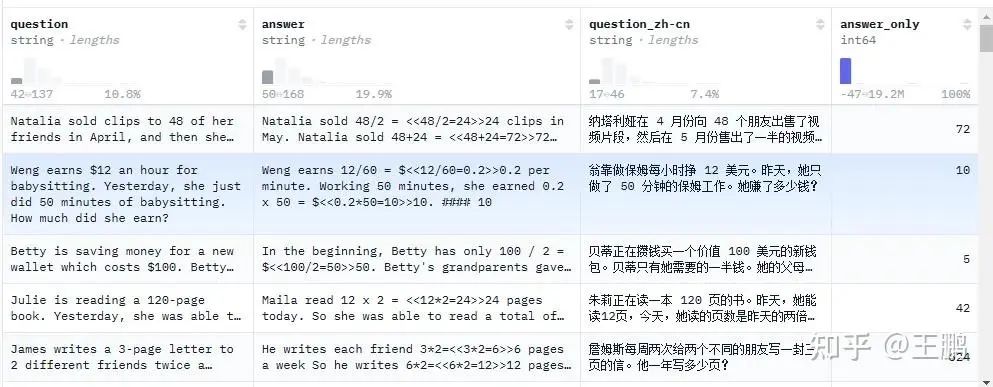
import refrom datasets import load_dataset, Dataset# Load and prep datasetSYSTEM_PROMPT = """采用下方格式回复用户问题:<reasoning>...</reasoning><answer>...</answer>"""XML_COT_FORMAT = """\\<reasoning>{reasoning}</reasoning><answer>{answer}</answer>"""def extract_xml_answer(text: str) -> str: answer = text.split("<answer>")[-1] answer = answer.split("</answer>")[0] return answer.strip()def extract_hash_answer(text: str) -> str | None: if "####" not in text: return None return text.split("####")[1].strip()# uncomment middle messages for 1-shot promptingdef get_gsm8k_questions(split = "train") -> Dataset: data = load_dataset('swulling/gsm8k_chinese')[split] # type: ignore data = data.map(lambda x: { # type: ignore 'prompt': [ {'role': 'system', 'content': SYSTEM_PROMPT}, {'role': 'user', 'content': x['question_zh-cn']} ], 'answer': x['answer_only'] }) # type: ignore return data # type: ignoredataset = get_gsm8k_questions()定义奖励函数:
主要是包含正确性奖励和格式奖励这种基于rule的奖励。奖励函数的定义对于最终的结果非常重要。
# Reward functionsdef correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]: responses = [completion[0]['content'] for completion in completions] q = prompts[0][-1]['content'] extracted_responses = [extract_xml_answer(r) for r in responses] print('-'*20, f"Question:\\n{q}", f"\\nAnswer:\\n{answer[0]}", f"\\nResponse:\\n{responses[0]}", f"\\nExtracted:\\n{extracted_responses[0]}") return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]def int_reward_func(completions, **kwargs) -> list[float]: responses = [completion[0]['content'] for completion in completions] extracted_responses = [extract_xml_answer(r) for r in responses] return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]def strict_format_reward_func(completions, **kwargs) -> list[float]: """Reward function that checks if the completion has a specific format.""" pattern = r"^<reasoning>\\n.*?\\n</reasoning>\\n<answer>\\n.*?\\n</answer>\\n$" responses = [completion[0]["content"] for completion in completions] matches = [re.match(pattern, r) for r in responses] return [0.5 if match else 0.0 for match in matches]def soft_format_reward_func(completions, **kwargs) -> list[float]: """Reward function that checks if the completion has a specific format.""" pattern = r"<reasoning>.*?</reasoning>\\s*<answer>.*?</answer>" responses = [completion[0]["content"] for completion in completions] matches = [re.match(pattern, r) for r in responses] return [0.5 if match else 0.0 for match in matches]def count_xml(text) -> float: count = 0.0 if text.count("<reasoning>\\n") == 1: count += 0.125 if text.count("\\n</reasoning>\\n") == 1: count += 0.125 if text.count("\\n<answer>\\n") == 1: count += 0.125 count -= len(text.split("\\n</answer>\\n")[-1])*0.001 if text.count("\\n</answer>") == 1: count += 0.125 count -= (len(text.split("\\n</answer>")[-1]) - 1)*0.001 return countdef xmlcount_reward_func(completions, **kwargs) -> list[float]: contents = [completion[0]["content"] for completion in completions] return [count_xml(c) for c in contents]1. correctness_reward_func(正确性奖励函数)
检查模型的输出是否与参考答案 (answer) 完全匹配,匹配则奖励 2.0,否则 0.0。
2. int_reward_func(整数检测奖励函数)
检查模型输出是否是纯数字(整数),是则奖励 0.5,否则 0.0。
3. strict_format_reward_func(严格格式奖励函数)
检查模型输出是否完全符合 **严格的 XML 格式,**符合格式的奖励 0.5,否则 0.0。
<reasoning>逻辑推理内容</reasoning><answer>答案内容</answer>4. soft_format_reward_func(宽松格式奖励函数)
允许更灵活的格式,只要包含 <reasoning>...</reasoning> 和 <answer>...</answer>,即奖励 0.5。
5. count_xml,xmlcount_reward_func(XML 结构评分函数)
计算模型输出 XML 结构的完整度,并给予相应奖励。奖励规则:
检查 XML 结构完整度:
每个正确的标签匹配增加 0.125 奖励:
-
<reasoning>\\n:+0.125 -
</reasoning>\\n:+0.125 -
<answer>\\n:+0.125 -
</answer>:+0.125
考虑额外文本的惩罚:
-
如果
</answer>后面有多余的内容,则减少奖励0.001× 额外字符数
模型训练
采用trl实现的grpo就可以开始训练了,可以看到奖励慢慢在增加。
from trl import GRPOConfig, GRPOTrainertraining_args = GRPOConfig( use_vllm = True, # use vLLM for fast inference! learning_rate = 5e-6, adam_beta1 = 0.9, adam_beta2 = 0.99, weight_decay = 0.1, warmup_ratio = 0.1, lr_scheduler_type = "cosine", optim = "paged_adamw_8bit", logging_steps = 1, bf16 = is_bfloat16_supported(), fp16 = not is_bfloat16_supported(), per_device_train_batch_size = 1, gradient_accumulation_steps = 1, # Increase to 4 for smoother training num_generations = 6, # Decrease if out of memory max_prompt_length = 256, max_completion_length = 200, # num_train_epochs = 1, # Set to 1 for a full training run max_steps = 250, save_steps = 250, max_grad_norm = 0.1, report_to = "none", # Can use Weights & Biases output_dir = "outputs",)trainer = GRPOTrainer( model = model, processing_class = tokenizer, reward_funcs = [ xmlcount_reward_func, soft_format_reward_func, strict_format_reward_func, int_reward_func, correctness_reward_func, ], args = training_args, train_dataset = dataset,)trainer.train()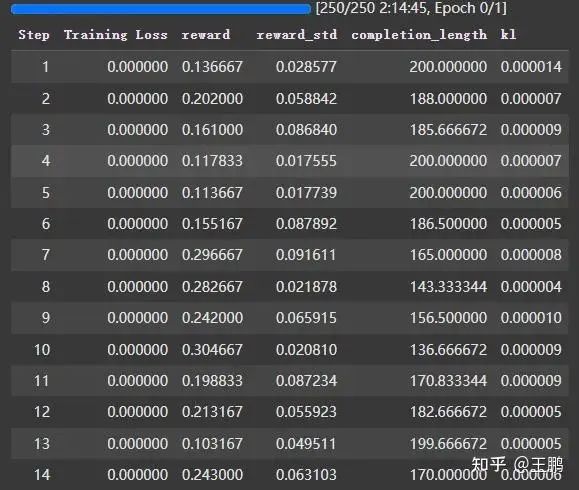
一套下来,模型就学会了思考,不得不说deepseek真牛皮,没有任何cot数据也能训练出推理模型。
参考
代码:https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.1_(8B)-GRPO.ipynb4
数据:https://huggingface.co/datasets/swulling/gsm8k_chinese
模型:https://huggingface.co/Qwen/Qwen2.5-7B-Instruct

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)