具身智能方向,开源顶会方案大盘点(第一期)
点击下方卡片,关注「3D视觉工坊」公众号选择星标,干货第一时间送达来源:计算机视觉工坊添加小助理:cv3d008,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。扫描下方二维码,加入「3D视觉从入门到精通」知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研
点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:计算机视觉工坊
添加小助理:cv3d008,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。
扫描下方二维码,加入「3D视觉从入门到精通」知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
3D视觉工坊为您网罗最新的行业动态、学术论文、科研成果、产品发布、新闻政策!
1. GRUtopia:首个城市级具身智能仿真平台“浦源·桃源”
标题:GRUtopia: Dream General Robots in a City at Scale
作者:Hanqing Wang, Jiahe Chen, Wensi Huang, Qingwei Ben, Tai Wang, Boyu Mi, Tao Huang, Siheng Zhao, Yilun Chen, Sizhe Yang, Peizhou Cao, Wenye Yu, Zichao Ye, Jialun Li, Junfeng Long, Zirui Wang, Huiling Wang, Ying Zhao, Zhongying Tu, Yu Qiao, Dahua Lin, Jiangmiao Pang
机构:上海AI Lab、浙江大学、上海交通大学、清华大学、南京大学、香港中文大学、西电
原文链接:https://arxiv.org/abs/2407.10943
代码链接:https://github.com/OpenRobotLab/GRUtopia
摘要:近期的研究工作一直在探索具身人工智能(Embodied AI)领域的扩展定律。
鉴于收集现实世界数据的成本高昂,我们认为从模拟到现实(Sim2Real)的范式是扩展具身模型学习能力的关键步骤。本文介绍了GRUtopia项目,这是首个为各种机器人设计的模拟交互式3D社会。该项目具有以下几项重要进展:(a) 场景数据集GRScenes包含了10万个交互式、精细标注的场景,这些场景可以自由组合成城市规模的环境。与以往主要关注家庭环境的研究工作不同,GRScenes涵盖了89个不同的场景类别,填补了面向服务的环境(通用机器人最初部署的环境)之间的差距。(b) GRResidents是一个由大型语言模型(LLM)驱动的非玩家角色(NPC)系统,负责社交互动、任务生成和任务分配,从而模拟具身人工智能应用中的社交场景。(c) 基准测试集GRBench支持各种机器人,但主要关注以腿足机器人为主要代理的机器人,并提出了涉及对象定位导航、社交定位导航和定位操作等适度挑战性的任务。我们希望这项工作能够缓解该领域高质量数据的稀缺问题,并为具身人工智能研究提供更全面的评估。

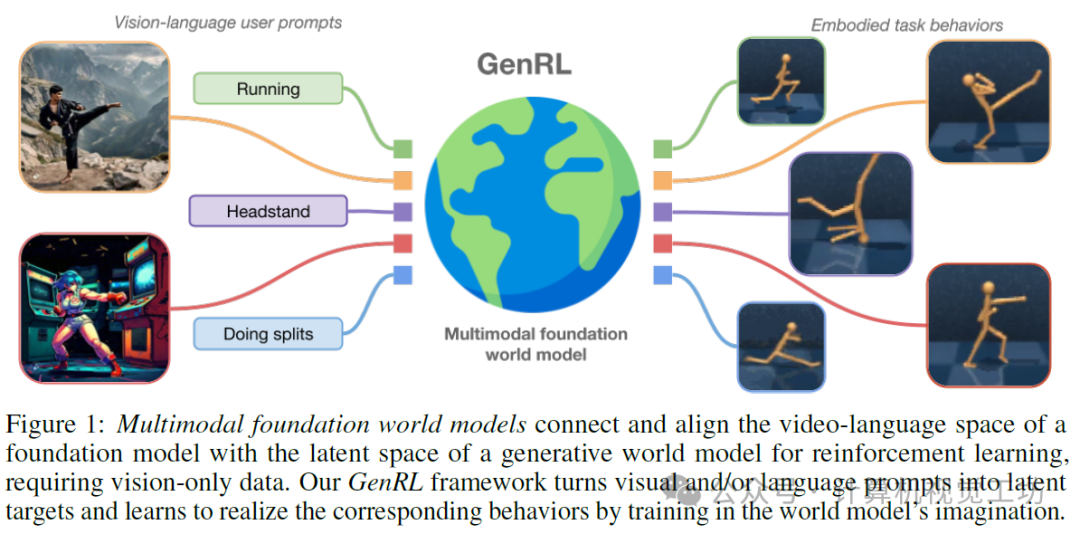
2. GenRL:利用世界模型学习任何行为!
标题:Multimodal foundation world models for generalist embodied agents
作者:Pietro Mazzaglia, Tim Verbelen, Bart Dhoedt, Aaron Courville, Sai Rajeswar
机构:Ghent University、VERSES AI Research Lab、University of Montreal、ServiceNow Research
原文链接:https://arxiv.org/abs/2406.18043
代码链接:https://github.com/mazpie/genrl
官方主页:https://mazpie.github.io/genrl
摘要:构建能够解决不同领域众多任务的通用具身智能体是一个长期存在的问题。强化学习(RL)难以扩展,因为它需要为每个任务设计复杂的奖励机制。相比之下,语言能够以更自然的方式指定任务。当前的视觉-语言基础模型(VLMs)通常需要进行微调或其他适应才能发挥作用,因为存在显著的领域差距。然而,在这些领域中缺乏多模态数据,成为开发用于具身应用的基础模型的障碍。在这项工作中,我们通过提出多模态基础世界模型来克服这些问题,这些模型能够在没有任何语言注释的情况下,将基础VLMs的表示与生成性世界模型的潜在空间进行连接和对齐,以用于RL。由此产生的智能体学习框架GenRL允许用户通过视觉和/或语言提示来指定任务,将这些任务与具身域的动态相结合,并在想象中学习相应的行为。通过大规模多任务基准测试评估,GenRL在多个运动和操作领域展示了强大的多任务泛化性能。此外,通过引入无数据RL策略,它为基于基础模型的RL在通用具身智能体中的应用奠定了基础。这项工作为构建能够灵活应对各种任务和环境的智能体提供了新的视角和工具。
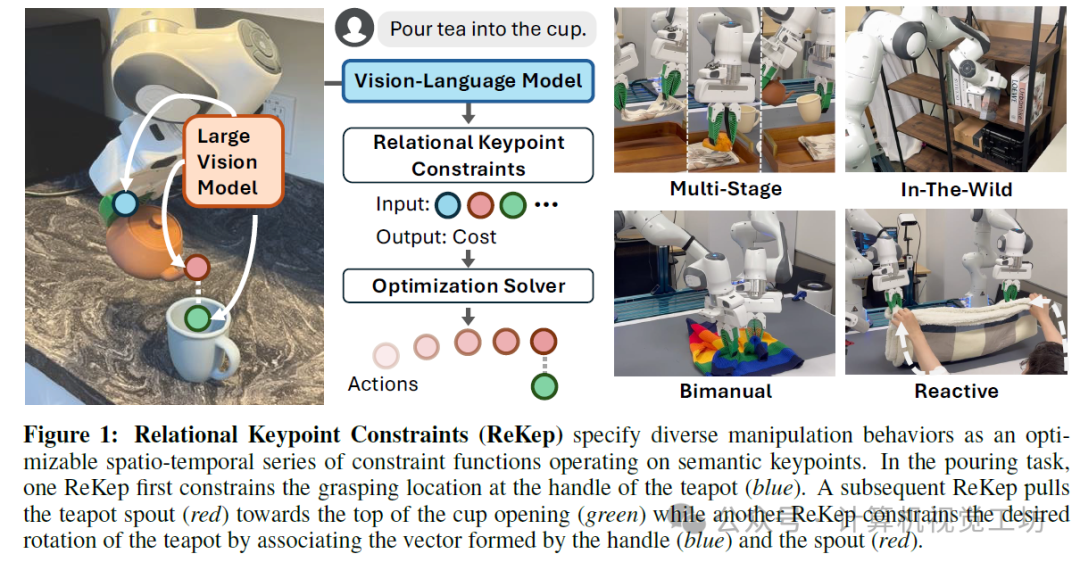
3. 李飞飞团队重磅开源ReKep:万能具身机器人!实时交互,还可搭载GPT-4o!
标题:ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
作者:Wenlong Huang, Chen Wang, Yunzhu Li, Ruohan Zhang, Li Fei-Fei
机构:Stanford University、Columbia University
原文链接:https://arxiv.org/abs/2409.01652
代码链接:https://github.com/huangwl18/ReKep
官方主页:https://rekep-robot.github.io/
摘要:将机器人操作任务表示为将机器人与环境相关联的约束,是编码所需机器人行为的一种有前途的方法。然而,如何制定这些约束,使其能够1) 适用于多种任务,2) 无需手动标记,3) 可通过现成的求解器进行优化以实时生成机器人动作,这些问题尚不清楚。在本研究中,我们引入了关系关键点约束(ReKep),这是一种基于视觉的机器人操作约束表示方法。具体而言,ReKep 表示为 Python 函数,该函数将环境中的一组 3D 关键点映射到数值成本。我们证明了通过将操作任务表示为一系列关系关键点约束,我们可以采用分层优化过程来求解机器人动作(在 SE(3) 中表示为一系列末端执行器姿态),并以实时频率实现感知-动作循环。此外,为了避免对每个新任务手动指定 ReKep,我们设计了一种自动化程序,该程序利用大型视觉模型和视觉-语言模型从自由形式的语言指令和 RGB-D 观测结果中生成 ReKep。我们在轮式单臂平台和固定式双臂平台上实现了该系统,这些平台可以执行各种操作任务,包括多阶段、野外、双手和反应性行为,且无需特定任务的数据或环境模型。
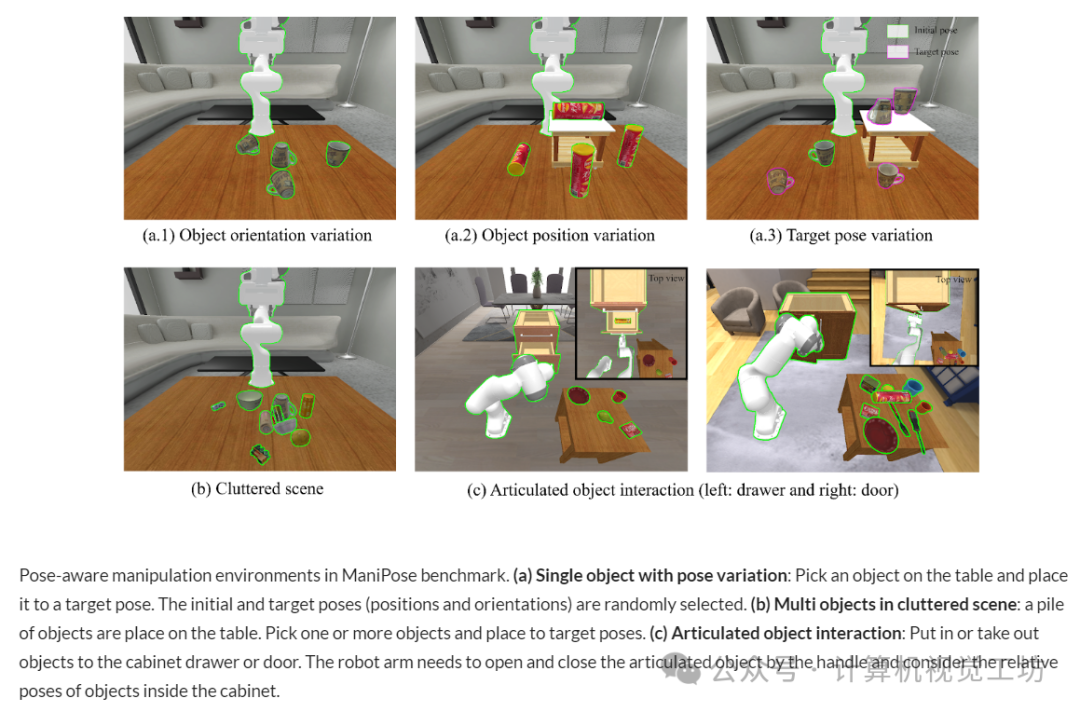
4. 机器人中姿态感知物体操作的综合基准
标题:ManiPose: A Comprehensive Benchmark for Pose-aware Object Manipulation in Robotics
作者:Qiaojun Yu, Ce Hao, Junbo Wang, Wenhai Liu, Liu Liu, Yao Mu, Yang You, Hengxu Yan, Cewu Lu
原文链接:https://arxiv.org/abs/2403.13365
代码链接:Coming soon
官方主页:https://sites.google.com/view/manipose
摘要:在日常场景中,特别是在非结构化环境中,机器人操作需要姿势感知对象操作(POM)技能,该技能根据对象的6D姿势来调整机器人的抓取和处理。识别对象的位置和方向对于有效的操作至关重要。例如,如果一个杯子侧躺着,抓住杯口比抓住把手更有效。尽管它很重要,但对POM技能的研究仍然有限,因为学习操纵技能需要姿势变化的模拟环境和数据集。本文介绍ManiPose,这是一个开创性的基准,旨在推进姿势变化操作任务的研究。ManiPose包括:POM特征任务的模拟环境,范围从单个物体的6D特定姿势的拾取和放置到杂乱的场景,还包括与关节式物体的交互。2)一个全面的数据集,包含2936个真实世界扫描的刚性对象和100个跨59个类别的关节对象的几何一致且面向操作的6D姿势标签。POM的基线,利用LLM(例如ChatGPT)的推理能力来分析6D姿态和任务特定要求之间的关系,提供增强的姿态感知抓取预测和运动规划能力。我们的基准测试展示了姿态估计、姿态感知操作和真实机器人技能转移方面的显著进步,为POM研究设定了新的标准。
5. 用低成本全身遥操作学习双手移动操作
标题:Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
作者:Zipeng Fu, Tony Z. Zhao, Chelsea Finn
机构:斯坦福大学
原文链接:http://arxiv.org/abs/2401.02117
代码链接:https://github.com/MarkFzp/act-plus-plus
官方主页:https://mobile-aloha.github.io/
摘要:从人类示范中进行的模仿学习在机器人学中表现令人印象深刻。然而,大多数结果集中于桌面操作,缺乏一般有用任务所必需的机动性和灵活性。在这项工作中,我们开发了一个系统,用于模拟双手操作和需要全身控制的移动操作任务。我们首先介绍了移动ALOHA,一个低成本和全身遥操作系统的数据收集。它用一个移动基座和一个全身遥控操作接口增强了ALOHA系统。使用移动ALOHA收集的数据,我们然后执行监督行为克隆,并发现与现有静态ALOHA数据集的共同训练提高了移动操作任务的性能。每项任务有50次演示,联合训练可以将成功率提高高达90%,使移动ALOHA能够自主完成复杂的移动操作任务,例如煎和端上一片虾,打开双门壁柜以存储沉重的烹饪锅,呼叫和进入电梯,以及使用厨房水龙头轻轻冲洗用过的锅。推荐课程:国内首个面向具身智能方向的理论与实战课程。

这里给大家推荐一门我们最新的课程《国内首个面向具身智能方向的理论与实战课程》:






课程亮点
-
本课程从学术研究和实际应用两方面,带你从零入门具身智能的原理学习、论文阅读、代码梳理等内容。
-
课程由具身智能领域的资深专家主讲,他们先后担任研究所、国企、大厂具身智能负责人,拥有丰富的理论知识和实践经验。
课程答疑
本课程答疑主要在本课程对应的鹅圈子中答疑,学员学习过程中,有任何问题,可以随时在鹅圈子中提问。



DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 13
13 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)