数据中心GPU芯片性能参数速查表(Nvidia+国产算力卡)
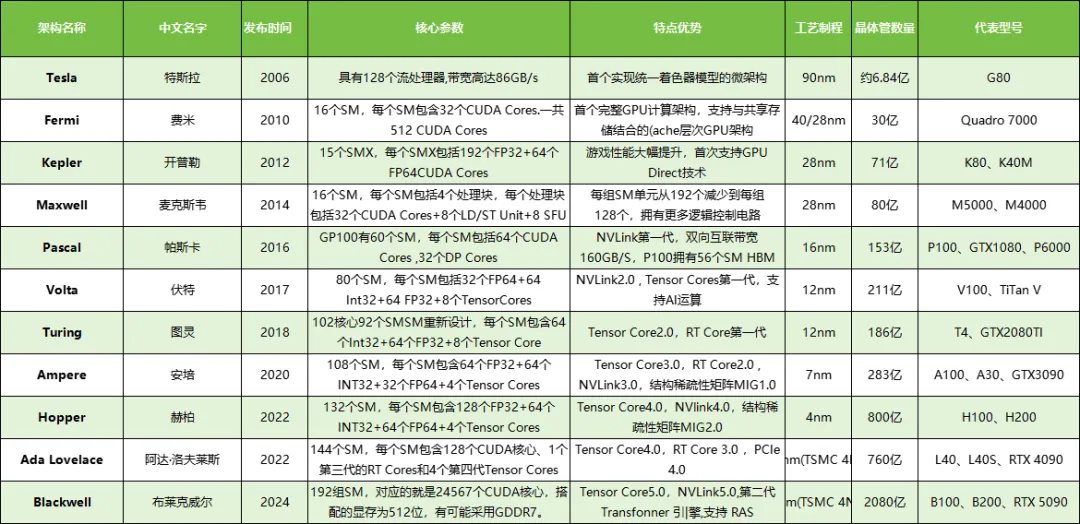
Nvidia的数据中心用GPU芯片,不断更新迭代新的架构。不同架构下的 GPU芯片,其性能参数大相径庭。在计算能力方面,从早期架构到如今的先进架构,CUDA 核心数量不断增加,如从 Kepler 架构开始,SM 单元中的 CUDA 核心数大幅提升,这使得通用计算能力得到极大增强。每代的架构,都会以一个著名科学家的名字命名,截止目前,已经有 11 款芯片架构代号取自科学家名字。如下所示:
前言:在算力即生产力的时代,数据中心GPU已成为驱动人工智能、科学计算、图形渲染、大数据分析等核心业务的关键引擎。为了帮助广大科研人员、工程师、技术爱好者以及相关从业者能够快速、准确地了解不同 GPU 芯片的性能参数,以便更好地选择适合自身需求的产品,本文将涵盖 Nvidia 和国产各系列数据中心 GPU 芯片的关键性能指标,如计算能力、显存容量与带宽、多实例 GPU 支持情况、互连技术等,无论是进行新系统规划、旧集群扩容,还是评估不同平台上的应用性能潜力,为技术选型、成本效益分析和性能预估提供数据基础。
Nvidia的数据中心用GPU芯片,不断更新迭代新的架构。不同架构下的 GPU芯片,其性能参数大相径庭。在计算能力方面,从早期架构到如今的先进架构,CUDA 核心数量不断增加,如从 Kepler 架构开始,SM 单元中的 CUDA 核心数大幅提升,这使得通用计算能力得到极大增强。每代的架构,都会以一个著名科学家的名字命名,截止目前,已经有 11 款芯片架构代号取自科学家名字。如下所示:
国内主要GPU芯片厂商有HW、海光、昆仑芯、寒武纪、摩尔线程、壁仞科技等。目前的主流型号在性能上虽与Nvidia先进架构芯片仍存在一定差距,但也在不断追赶。例如海光的某些型号芯片,其计算核心数量在逐步增加,浮点运算性能等关键指标也在持续优化,能够满足国内一些特定场景下的计算需求,像在部分数据中心的AI推理任务中,华为昇腾系已有较为成熟的应用案例。而摩尔线程等厂商也在积极投入研发,不断推出新的架构和型号,致力于提升GPU芯片在图形渲染、并行计算等多方面的性能,以更好地适配国内日益增长的高性能计算需求,推动国产GPU芯片产业的发展。
一、Nvidia系
算力计算大致方法
-
FP16 稀疏算力 = 2 x FP16 非稀疏算力 = 2 x TF32 算力。 -
FP16 非稀疏算力 = TF32 算力 -
在Hopper架构(如H100)上,关系类似,但具体数值大幅提升
1.Ampere
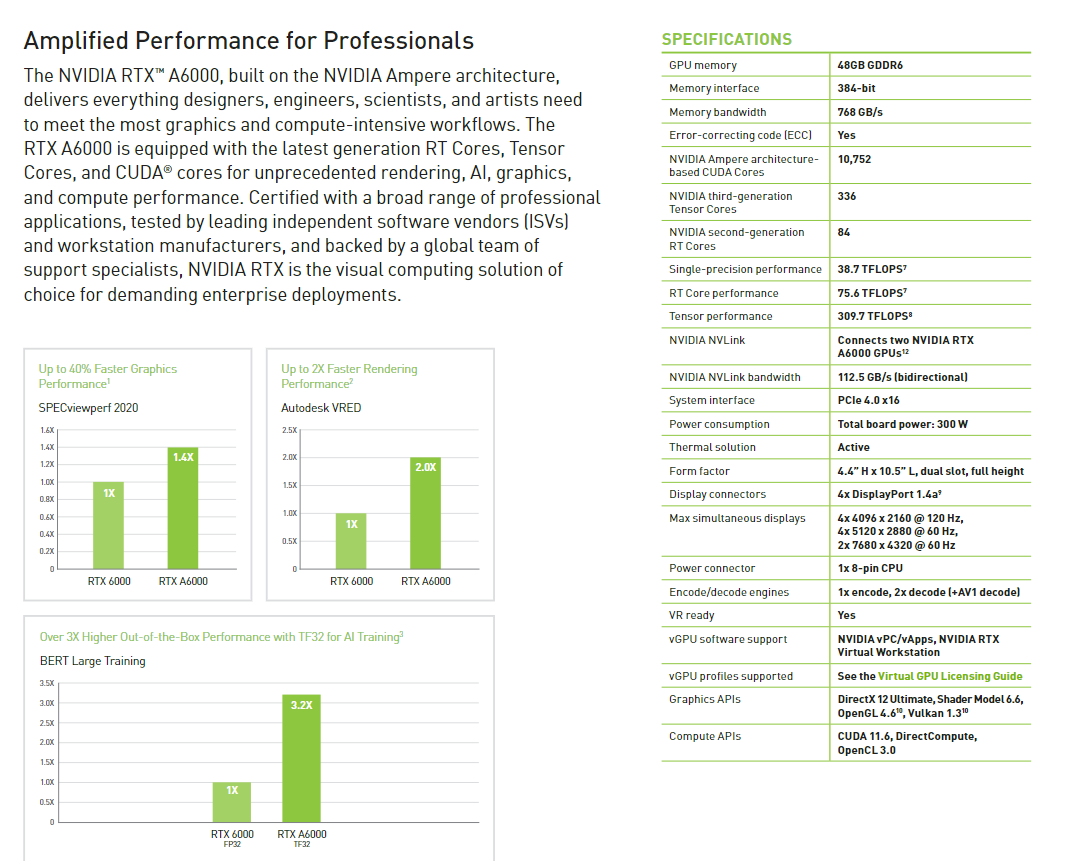
RTX A6000
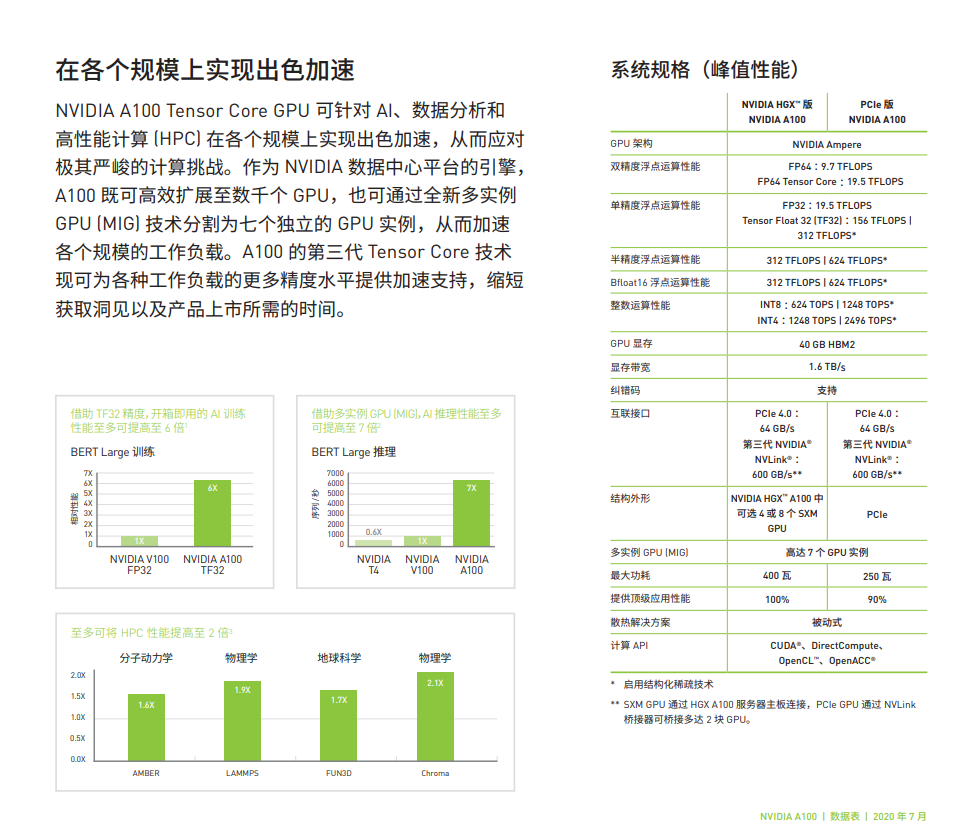
A100-40G
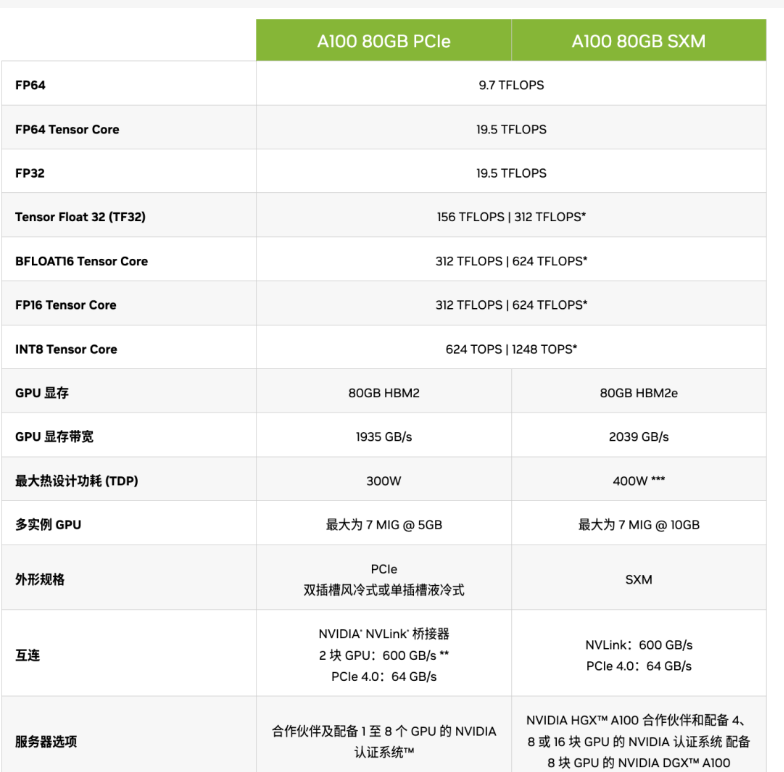
A100-80G
A800-40G
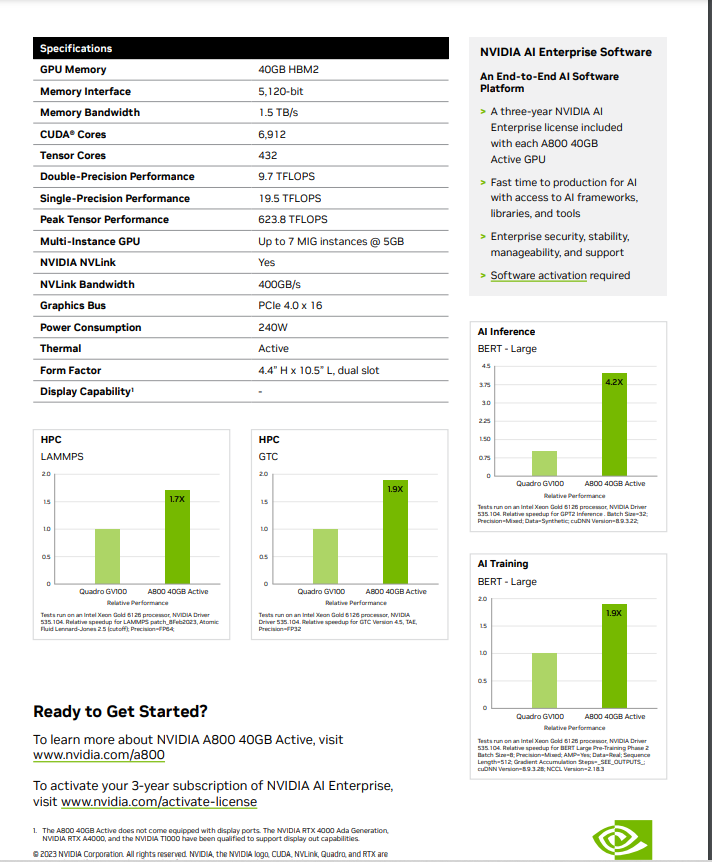
A800-80G

2.Hopper
H100

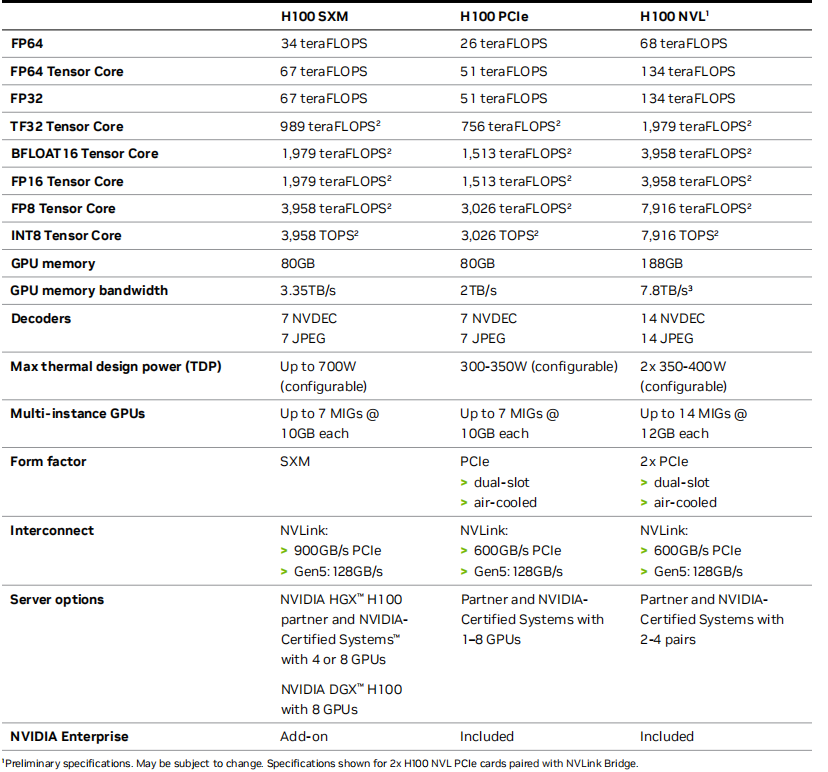
H800

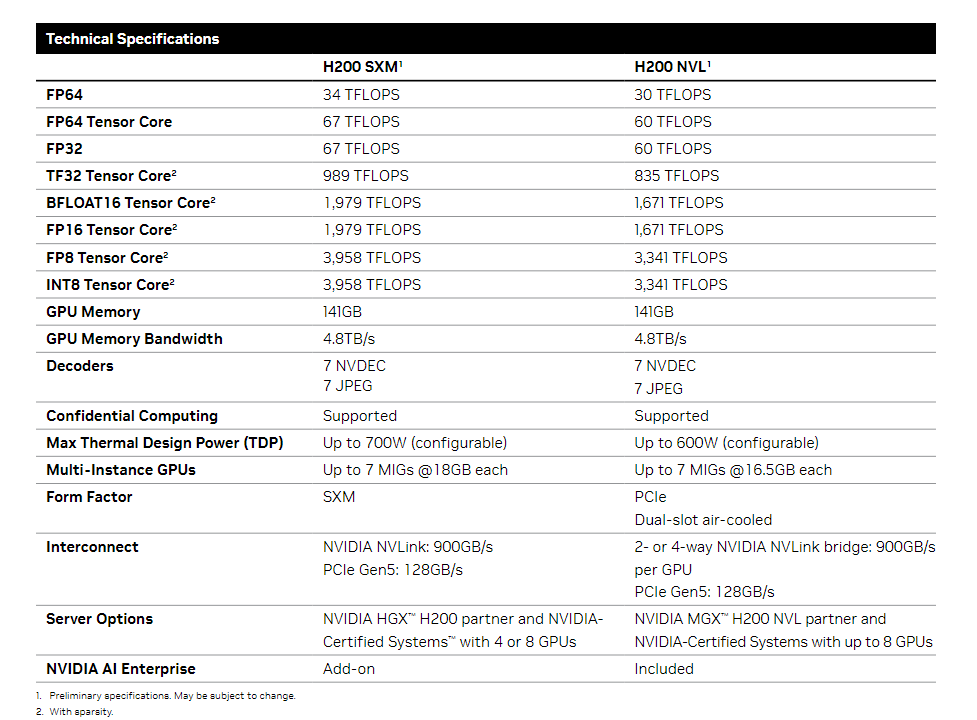
H200
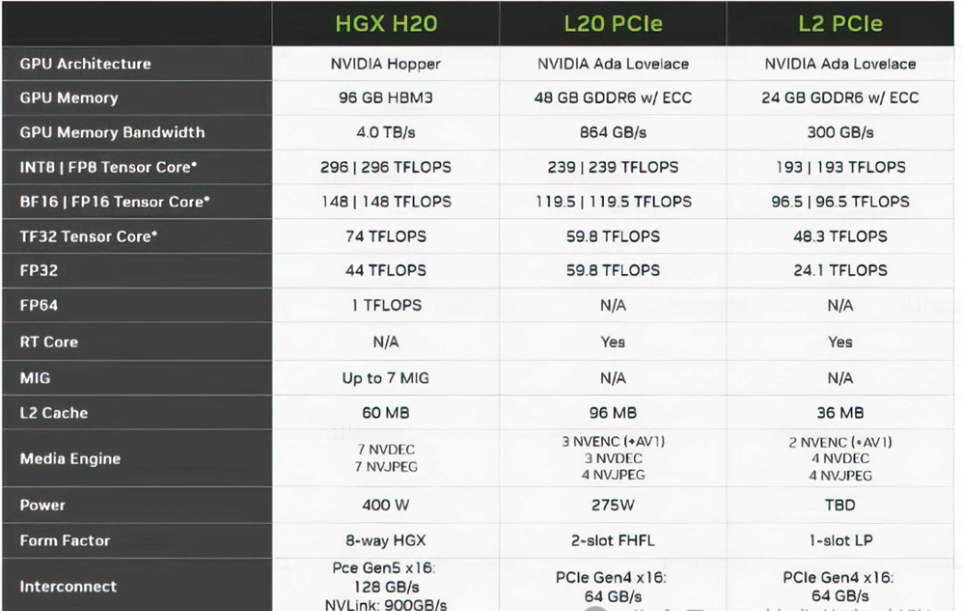
H20
3.Ada Lovelace
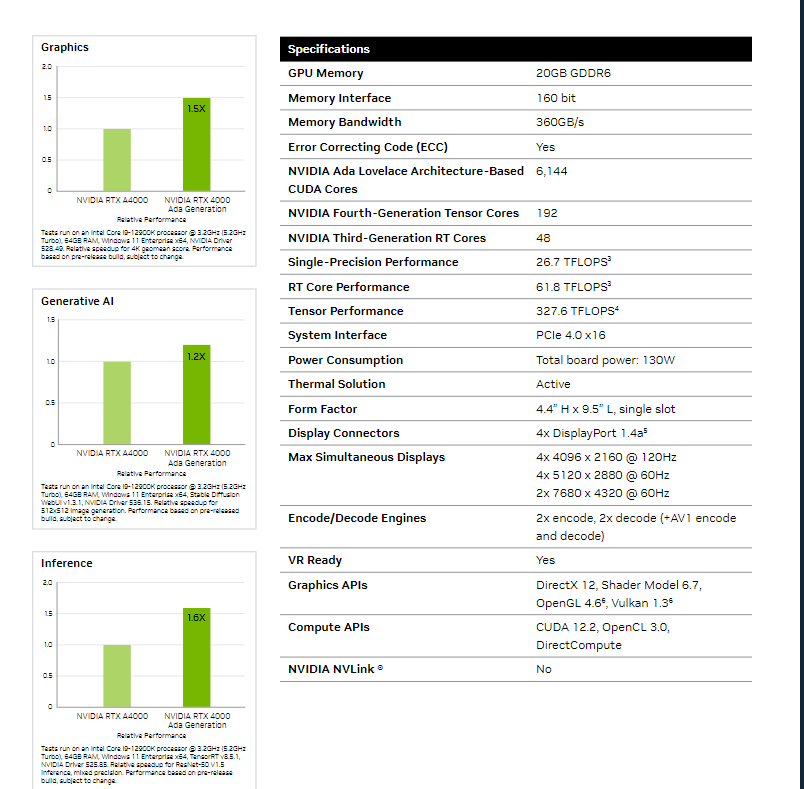
RTX 4000 Ada
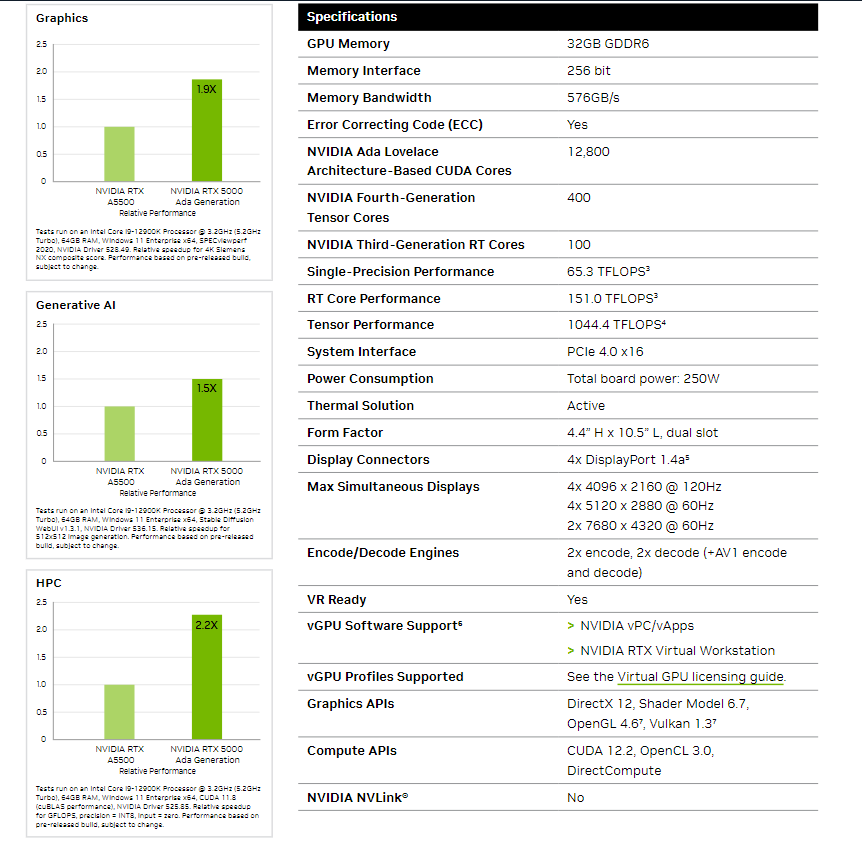
RXT 5000 Ada
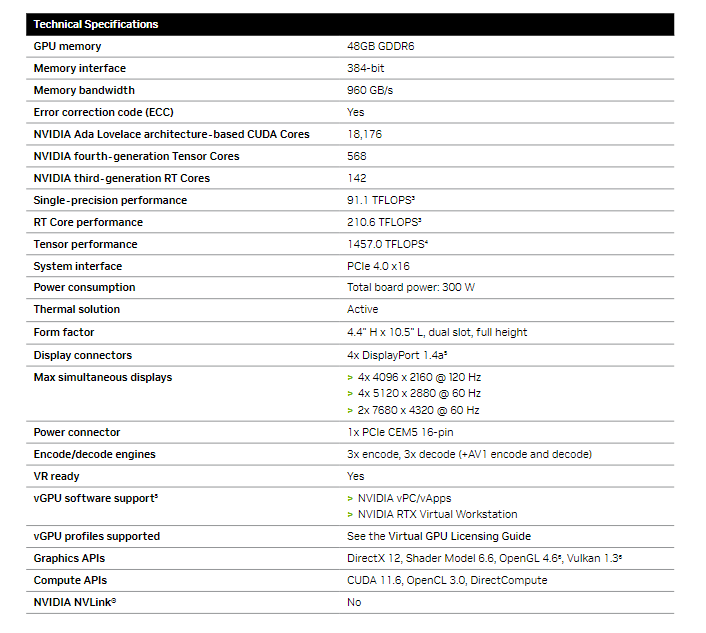
RTX 6000 Ada
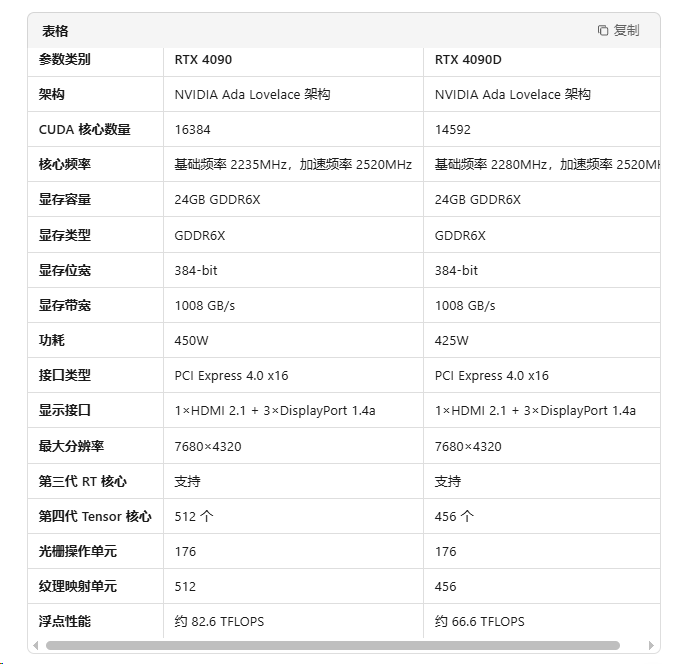
RXT 4090&4090D
性能对比总结
-
CUDA 核心:RTX 4090D 的 CUDA 核心数量减少了约 11%,从 16384 个减少到 14592 个。
-
功耗:RTX 4090D 的功耗从 450W 降低到 425W。
-
显存与带宽:两者显存容量、类型、位宽和带宽完全一致,均为 24GB GDDR6X,384-bit 位宽,带宽为 1008 GB/s。
-
性能损失:尽管 CUDA 核心数量减少,但由于显存带宽相同,实际性能差距可能在 5%-10% 之间。
-
超频潜力:RTX 4090D 支持功耗墙解锁至 480W,超频后性能差距可缩小至 3% 以内。
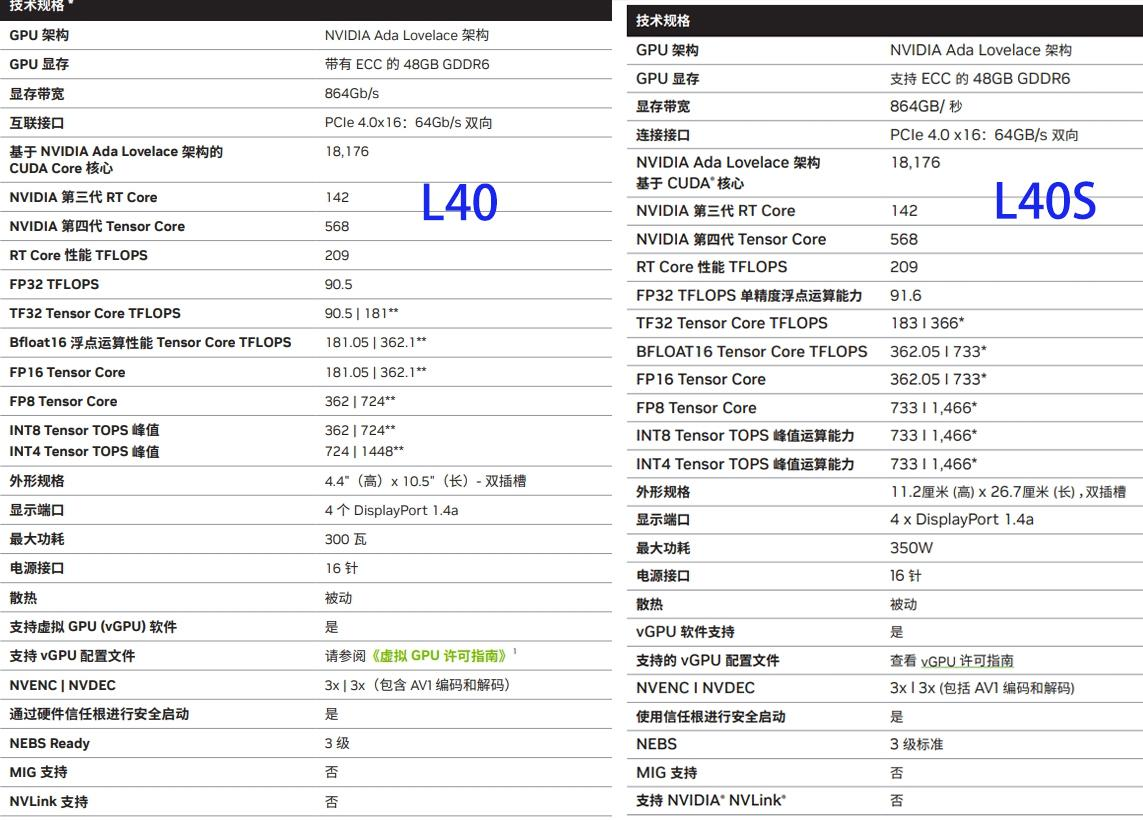
L40&L40S
L40S GPU 基于 NVIDIA Ada Lovelace 架构,采用 TSMC 4nm 制程工艺。该架构的主要特点包括:
-
第四代 Tensor Core:支持 FP8 精度转换,提供超过 1.45 PFLOPS 的张量处理能力。
-
第三代 RT Core:显著增强光线追踪性能,支持 AI 增强的加速图形处理。
-
高效能设计:专为数据中心和 AI 推理任务优化,支持 ECC 纠错功能,提高数据处理的稳定性和
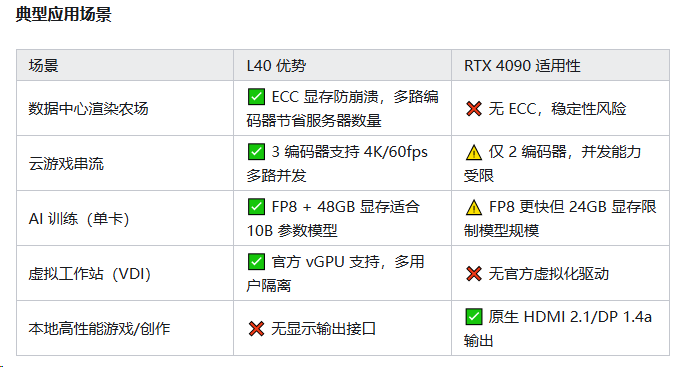
在渲染方面与4090对比优劣势:
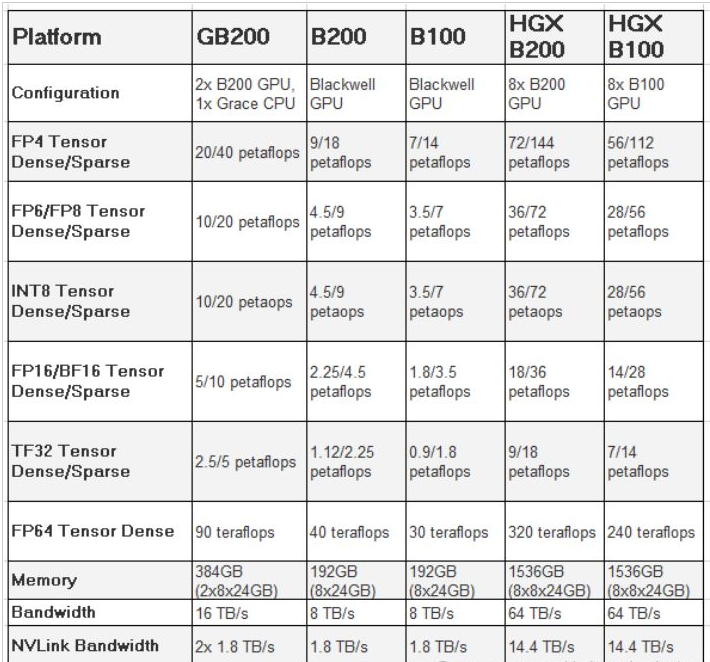
4.Blackwell
B200
二、HW-910β
910β系列内部分为4个型号,即B1\B2\B3\B4,在单卡算力和显存上有一定的区别,具体参数如下:
| NPU 型号 | FP16 算力 | 显存 | 对应整机型号 |
|---|---|---|---|
| shengteng Ascend 910β4 | 280T | 32GB/64GB | Atlas 800I A2 |
| shengteng Ascend 910β3 | 313T | 64GB HBM2 | Atlas 800T A2 |
| shengteng Ascend 910β2 | 376T | 64GB HBM2 | Atlas 9000A2 Pod |
| shengteng Ascend 910β1 | 414T | 64GB HBM2 |
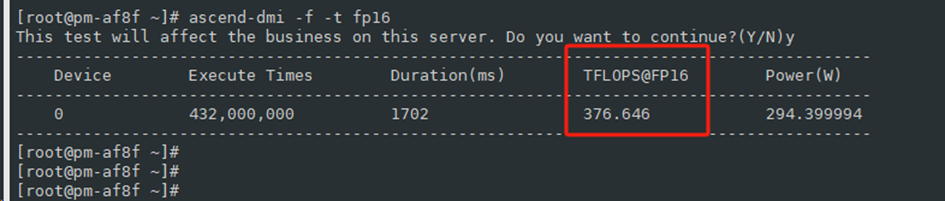
整机的910服务器配置8颗910 AI 处理器(NPU 模组),每个NPU 模组通过一路PCIe 4.0 x16 与CPU 主板对接,每个NPU 模组直出1*200GE,通过NPU 模组本身自带高速Serdes 接口完成。在计算整机算力时需要*8,以B2为例,单卡算力376TFLOPS,8卡整机提供的算力则为3.008PFLOPS。每个NPU 模组提供七路带宽双向为56GB/s 的HCCS,实现8 个NPU 模组Full Mesh 连接。提供最大392GB/s(56GB/s*7)能力。HBM最大支持480GB,带宽速率最大为1600GB/s。在服务器内通过此命令可以查看单卡算力:
# ascend-dmi -f -t fp16
三、海光-DCU
海光的K100/K100 AI是市面使用主要芯片,该芯片对标英伟达A800,对Hygon、AMD、Intel等平台整体兼容 / 国内外主流OS全面适配。DCU Tool Kit(DTK):全自主计算平台与主流生态高效兼容(CUDA/ROCM),支持自研算子和最新三方组件;AI框架层以上程序无需转码,直接编译运行。DTK最新版本24.04

四、寒武纪-LPU

寒武纪目前芯片架构已更新至第五代,板卡发布了四代,旗舰lpu为 思元590,支持FP32、BF16、FP16、FP19(TF32)及INT16、INT8、INT4算力,整机8卡,FP16等效算力,整机型号为 MLU-X2000,全面支持PCIe5.0,采用8卡8端口的400G MLU-RoCE交换机直连,最大3.2Tb/s的直出带宽。整机内存≥640GB,内存带宽≥16384GB/s,显存采用HB2e单卡80G。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)