学生党matlab哪个版本最好用,学生党福音!仅4个GPU打造自己的BigGAN,PyTorch代码已开源...
shs/ utils / prepare_data.sh默认情况下,ImageNet训练集被下载到此目录中的根文件夹中,并将以128x128像素分辨率准备缓存的HDF5。在s文件夹中,有多个bash脚本可以训练具有不同批量大小的BigGAN。假设您无法访问完整的TPU pod,因此通过梯度累积(在多个小批量下进行梯度平均,并且仅在N次累积后执行优化程序步骤),以此形式表示大批量。默认情况下,可以使
shs/ utils / prepare_data.sh
默认情况下,ImageNet训练集被下载到此目录中的根文件夹中,并将以128x128像素分辨率准备缓存的HDF5。
在s文件夹中,有多个bash脚本可以训练具有不同批量大小的BigGAN。假设您无法访问完整的TPU pod,因此通过梯度累积(在多个小批量下进行梯度平均,并且仅在N次累积后执行优化程序步骤),以此形式表示大批量。
默认情况下,可以使用launch_BigGAN_bs256x8.sh脚本训练一个全尺寸的BigGAN模型,批大小为256和8个梯度累积,总批量为2048。在8张V100上进行全精度训练(无张量),训练需要15天,期间共进行约150k次迭代。
首先需要确定设置可以支持的最大批量大小。这里提供的预训练模型是在8个V100上(每个显存16GB )上训练的,这个配置可以支持比默认使用的B1S256稍多一些的载荷。一旦确定了这一点,就应该修改脚本,使批大小乘以梯度累积的数量等于所需的总批量大小(BigGAN默认为2048)。
另外,此脚本使用--load_in_memarg,将整个(最大支持64GB)的I128.hdf5文件加载到RAM中,以加快数据的加载速度。如果没有足够的RAM做硬件支持(可能需要96GB以上的RAM),请删除此参数。
度量标准和抽样

在训练期间,脚本将输出带有训练指标和测试指标的日志,同时保存模型权重和优化程序参数的多个副本(前者保存最近的2个,后者保存5个最高得分),并且每次保存权重时将生成样本和插值。 logs文件夹包含处理这些日志的脚本,并使用MATLAB绘制结果。
训练之后,可以使用sample.py生成其他样本和插值,使用不同的截断值,批量大小,站立统计累积次数等进行测试。有关示例,请参阅sample_BigGAN_bs256x8.sh脚本。
默认情况下,所有内容都保存在weights/samples/logs/data文件夹中,这些文件夹设置与此repo位于同一文件夹中。可以使用--base_root参数将所有这些指向不同的基本文件夹,或者使用各自的参数(例如--logs_root)选择每个基础文件夹的特定位置。
此代码中包含了运行BigGAN-deep的脚本,但还没有完全训练使用它们的模型,因此用户可以视作这些模型尚未测试过。此外,我代码中还包括在CIFAR上运行模型的脚本,以及在ImageNet上运行SA-GAN(包括EMA)和SN-GAN的脚本。
SA-GAN代码假设用户配置在4张TitanX(或等同于该配置的GPU RAM),并且将以批量大小为128以及2个梯度累积运行。
关于初始度量标准的重要说明
本资源使用PyTorch内置的初始网络来计算IS和FID分数。这些分数与使用Tensorflow官方初始代码获得的分数不同,仅用于监控目的。使用--sample_npz参数在模型上运行sample.py,然后运行inception_tf13来计算实际的TensorFlow IS。请注意,需要安装TensorFlow 1.3或更早版本,因为1.4或更高版本会破坏原始的IS代码。
预训练模型
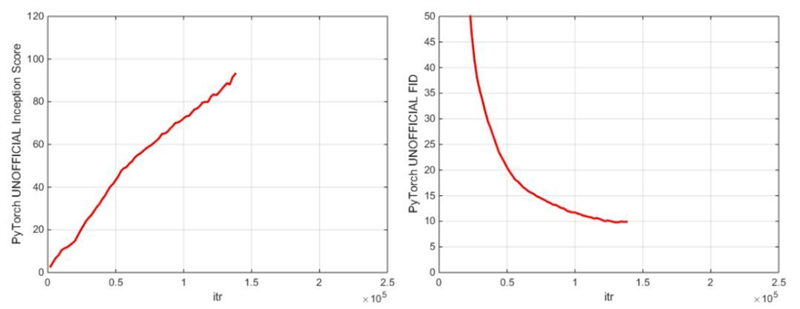
PyTorch初始分数和FID分数
我们引入了两个预训练模型检查点(使用G,D,G的EMA副本,优化器和状态dict):
主要检查点是在 128x128 ImageNet 图像上训练的 BigGAN,该模型使用 BS256 和 8 梯度累积,并在崩溃前实现,其 TF Inception Score 为 97.35 +/- 1.79,
详见:
https://drive.google.com/open?id=1nAle7FCVFZdix2—ks0r5JBkFnKw8ctW
第一个模型(100k G iters)的早期检查点,性能更高,在崩溃之前实现,可能更容易微调。
详见:
https://drive.google.com/open?id=1dmZrcVJUAWkPBGza_XgswSuT-UODXZcO。
另外,使用Places-365数据集的预训练模型即将推出。
此repo还包含用于将原始TF HubBigGAN 生成器权重的PyTorch的移植脚本。有关更多详细信息,请参阅TFHub文件夹中的脚本。
使用自己的数据集或创建新的训练函数微调模型

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)